
Boba AI の構築
LLM駆動の生成型アプリケーションの構築で学んだ教訓とパターン
私たちは「Boba」と呼ばれる製品戦略と生成的なアイデア出しのための実験的なAIコパイロットを構築しています。その過程で、このようなアプリケーションを構築する方法についていくつかの有用な教訓を学び、それをパターンとしてまとめました。これらのパターンにより、アプリケーションはユーザーがより効果的に大規模言語モデル(LLM)と対話できるようになり、プロンプトを調整してより良い結果を得たり、ユーザーが複雑な会話の流れを辿ったり、LLMが利用できない知識を統合したりすることができます。
2023年6月29日

FarooqはカナダのThoughtworksの製品戦略プリンシパルです。製品管理、戦略、ソフトウェア開発の実務経験を持つ専門的なジェネラリストとして、Farooqはデザイン、ビジネス、テクノロジーの交差点にある困難な問題を解決するためにクライアントと協力することを楽しみとしています。
Bobaは、創造的なアイデア出しプロセスを強化するために設計された、製品戦略と生成的なアイデア出しのための実験的なAIコパイロットです。これは、私たちが学習するために構築しているLLM駆動のアプリケーションです。
- LLMを搭載した、チャットを超える生成的なエクスペリエンスを設計および構築する方法
- AIを使用して、製品および戦略プロセスを強化し、作成する方法
AIコパイロットとは、さまざまなタスクでユーザーを支援するために設計された人工知能駆動のアシスタントのことで、多くの場合、さまざまなコンテキストでガイダンス、サポート、自動化を提供します。その応用例としては、ナビゲーションシステム、デジタルアシスタント、ソフトウェア開発環境などがあります。私たちは、コパイロットを、ユーザーが特定のタスクドメインを実行するために協力できる効果的なパートナーだと考えています。
AIコパイロットとしてのBobaは、発散的思考(生成的なアイデア出しとも呼ばれる)の急速なサイクルに大きく依存する、戦略的なアイデア出しと概念生成の初期段階を強化するように設計されています。私たちは通常、同僚、顧客、および専門家と緊密に協力して生成的なアイデア出しを実施し、顧客のジョブ、ペイン、ゲインに対処する革新的なアイデアを策定およびテストできるようにしています。これは、AIも同じプロセスに参加できるとしたらどうなるだろうかという疑問につながります。AIとの連携により、より多くの、より良いアイデアをより迅速に生成および評価できるとしたらどうなるでしょうか?Bobaは、OpenAIのLLMを使用して、創造的な思考プロセスを拡張および加速するのに役立つアイデアを生成し、質問に答えることで、これを可能にし始めます。Bobaの最初のプロトタイプでは、次の機能の基本的なバージョンに焦点を当てることにしました。
1. リサーチシグナルとトレンド:次のような定性的なリサーチの質問に答えるのに役立つ記事やニュースをウェブで検索します。
- 現在、ホテル業界では生成AIがどのように活用されていますか?
- 2023年以降、小売業者が直面している主な課題は何ですか?
- 製薬会社は、AIをどのように使用して創薬を加速させていますか?
- ナイキの最新の決算発表の主なポイントは何でしたか?
- Redditの人々は、Lululemonの製品についてどのように感じていますか?"
2. クリエイティブマトリックス:クリエイティブマトリックスは、異なるカテゴリまたはディメンションの交差点で新しいアイデアを生み出すための概念化手法です。これには、戦略的なプロンプト(多くの場合、「どのようにすれば~できるか」という質問)を記述し、各ディメンションの交差点にあるアイデアの組み合わせ/順列ごとにその質問に答えることが含まれます。たとえば、
- 戦略的プロンプト:「生成AIを使用して資産管理を変革するにはどうすればよいか?」
- ディメンション1 - バリューチェーンの段階:顧客獲得、財務計画、ポートフォリオ構築、投資実行、パフォーマンス監視、リスク管理、報告とコミュニケーション
- ディメンション2 - さまざまなペルソナ:従業員向け、顧客向け、パートナー向け
3. シナリオ構築:シナリオ構築は、ビジネス、文化、テクノロジーにおける変化の兆候を調査して、将来志向のストーリーを生成するプロセスです。シナリオは、コンテキスト化されたナラティブで学習を社会化したり、発散的な製品思考を促したり、回復力/望ましさのテストを実施したり、戦略計画に情報を提供したりするために使用されます。たとえば、Bobaに次のようなプロンプトを入力すると、さまざまな時間軸と楽観主義と現実主義のレベルに基づいた将来のシナリオのセットが得られます。
- 「ホテル業界は、生成AIを使用してゲストエクスペリエンスを変革しています」
- 「ファイザーは、生成AIを使用して創薬を加速しています」
- 「10年後の決済の未来を見せてください」
4. 戦略的なアイデア出し:戦略のフレームワーク「Playing to Win」を使用して、戦略的なプロンプトと可能な将来のシナリオに基づいて、「どこでプレイするか」と「どのように勝つか」の選択肢をブレインストーミングします。たとえば、次のようなプロンプトを入力できます。
- ナイキは生成AIを使用して、ビジネスモデルを変革するにはどうすればよいか?
- グローブアンドメール紙は、読者数とエンゲージメントを増やすにはどうすればよいか?
5. コンセプトの生成:「どのようにすれば~できるか」という質問のような戦略的なプロンプトに基づいて、価値提案のピッチとテストする仮説を含む、複数の製品または機能のコンセプトを生成します。
- 高齢者にとって旅行をより便利にするにはどうすればよいか?
- 買い物をよりソーシャルにするにはどうすればよいか?
6. ストーリーボード:現在の状態または将来の状態のシナリオに基づいて、簡単なプロンプトまたは詳細なナラティブに基づいて、視覚的なストーリーボードを生成します。主な機能は次のとおりです。
- 顧客の旅を説明するイラスト付きのシーンを生成する
- スタイルとイラストをカスタマイズする
- 生成されたシナリオから直接ストーリーボードを生成する
Boba の使用
Bobaは、人間ユーザーと大規模言語モデル(現在はGPT 3.5)間の対話を仲介するWebアプリケーションです。LLMへのシンプルなWebフロントエンドは、ユーザーがLLMと会話する機能を提供するだけです。これは便利ですが、ユーザーがLLMと効果的に対話する方法を学ぶ必要があることを意味します。LLMが世間の関心を集めている短い期間でさえ、有用な回答を得るためにLLMへのプロンプトを構築するにはかなりのスキルが必要であることがわかり、「プロンプトエンジニア」という概念につながっています。Bobaのようなコパイロットアプリケーションは、会話を構造化するさまざまなUI要素を追加します。これにより、ユーザーはアプリケーションが操作できる単純なプロンプトを作成し、単純なリクエストを、LLMからより良い応答が得られる要素で強化できます。
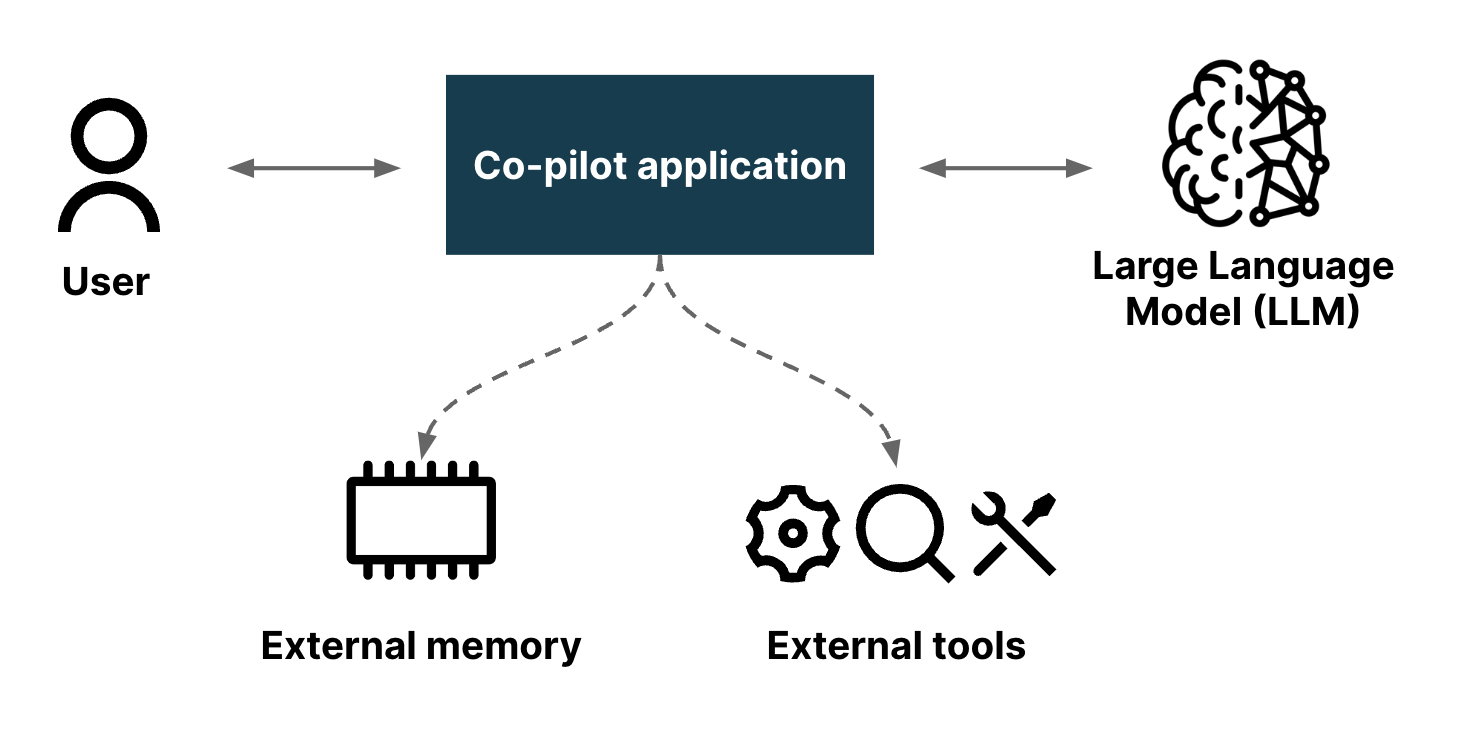
Bobaは、さまざまな製品戦略タスクを支援できます。ここでは、それらすべてを説明するのではなく、Bobaが何を行うのかを理解し、記事の後半にあるパターンのコンテキストを提供するために、十分に説明します。
ユーザーがBobaアプリケーションに移動すると、次のような初期画面が表示されます。
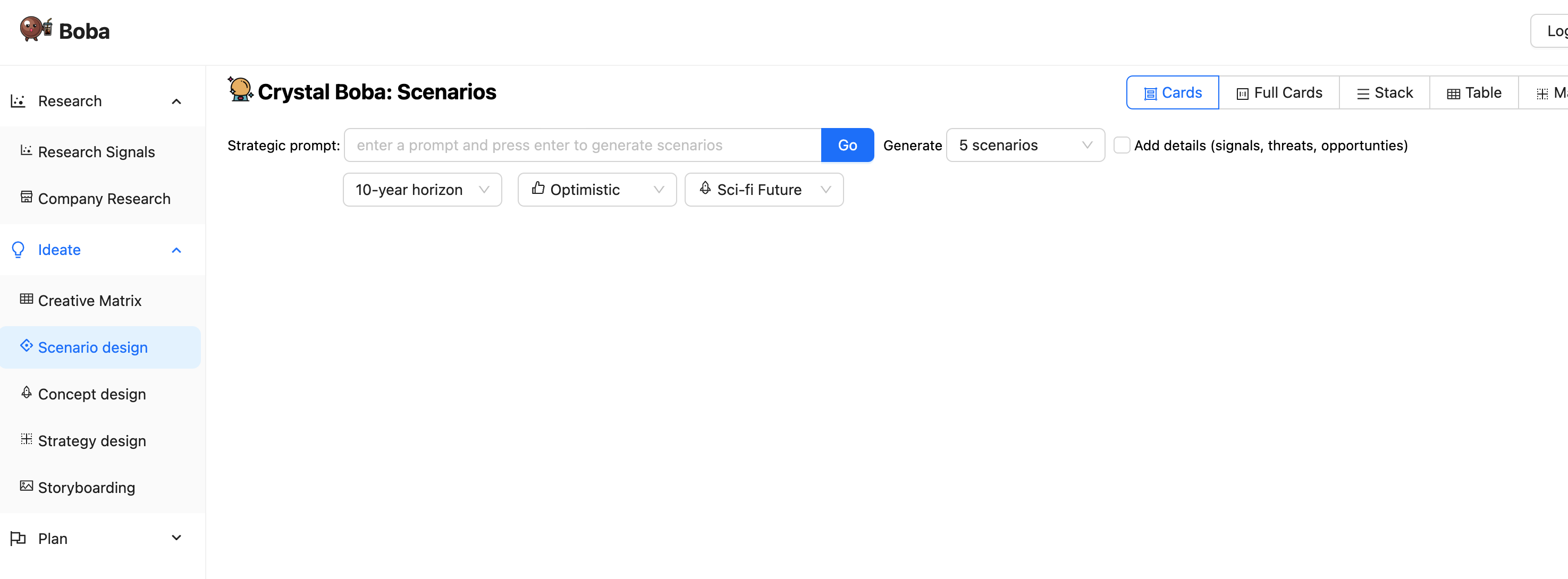
左側のパネルには、Bobaがサポートするさまざまな製品戦略タスクがリストされています。これらのいずれかをクリックすると、メインパネルがそのタスクのUIに変わります。残りのスクリーンショットでは、左側のタスクパネルは無視します。
上記のスクリーンショットは、シナリオ設計タスクを示しています。これにより、ユーザーは「小売業の未来を見せてください」などのプロンプトを入力できます。
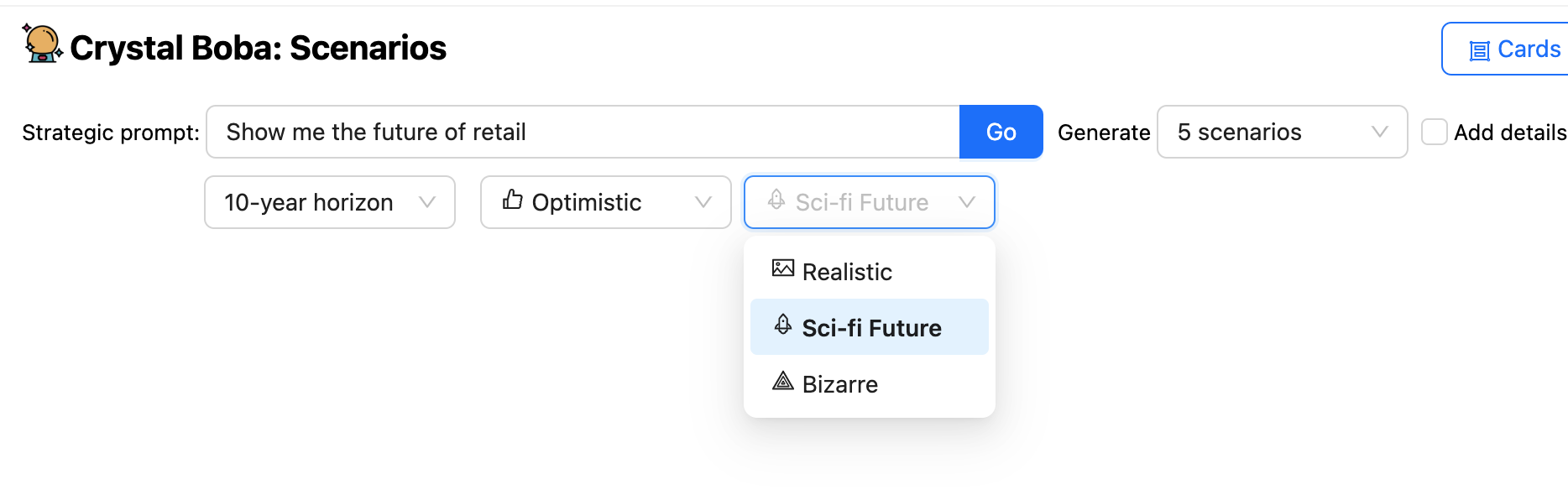
UIは、プロンプトに加えて、時間軸と予測の性質を提案できるようにする多くのドロップダウンを提供します。次にBobaは、テンプレート化されたプロンプトを使用して、シナリオ構築タスクの一般的な知識と、UIでのユーザーの選択から得られた追加要素を使用して、ユーザーのプロンプトを豊かにすることで、LLMにシナリオを生成するように依頼します。
Bobaは、LLMから構造化された応答を受け取り、結果を各シナリオのUI要素のセットとして表示します。
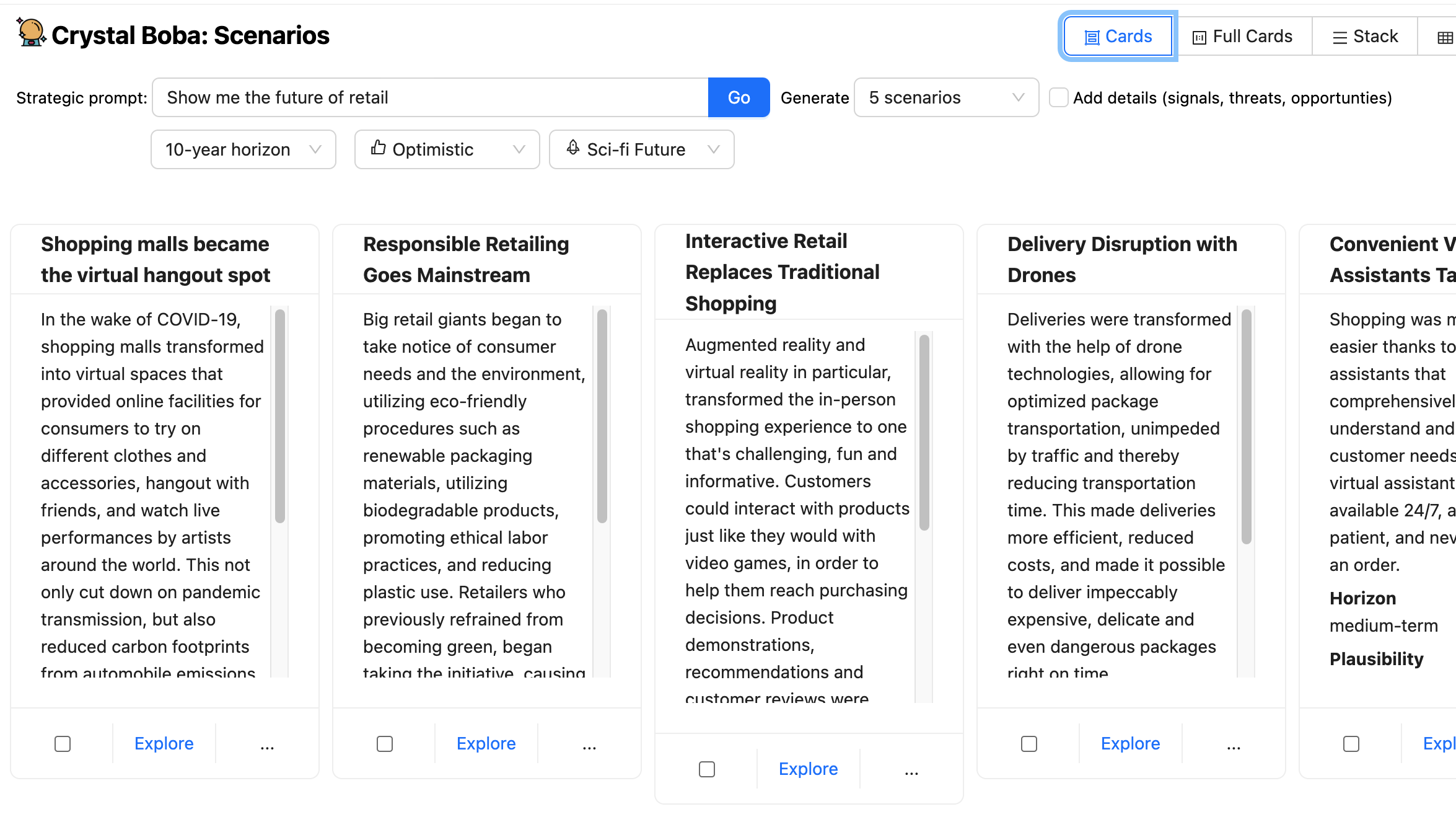
次に、ユーザーはこれらのシナリオの1つを選択して[探索]ボタンをクリックすると、Bobaとのコンテキストに基づいた会話を行うための追加のプロンプトが表示された新しいパネルが表示されます。
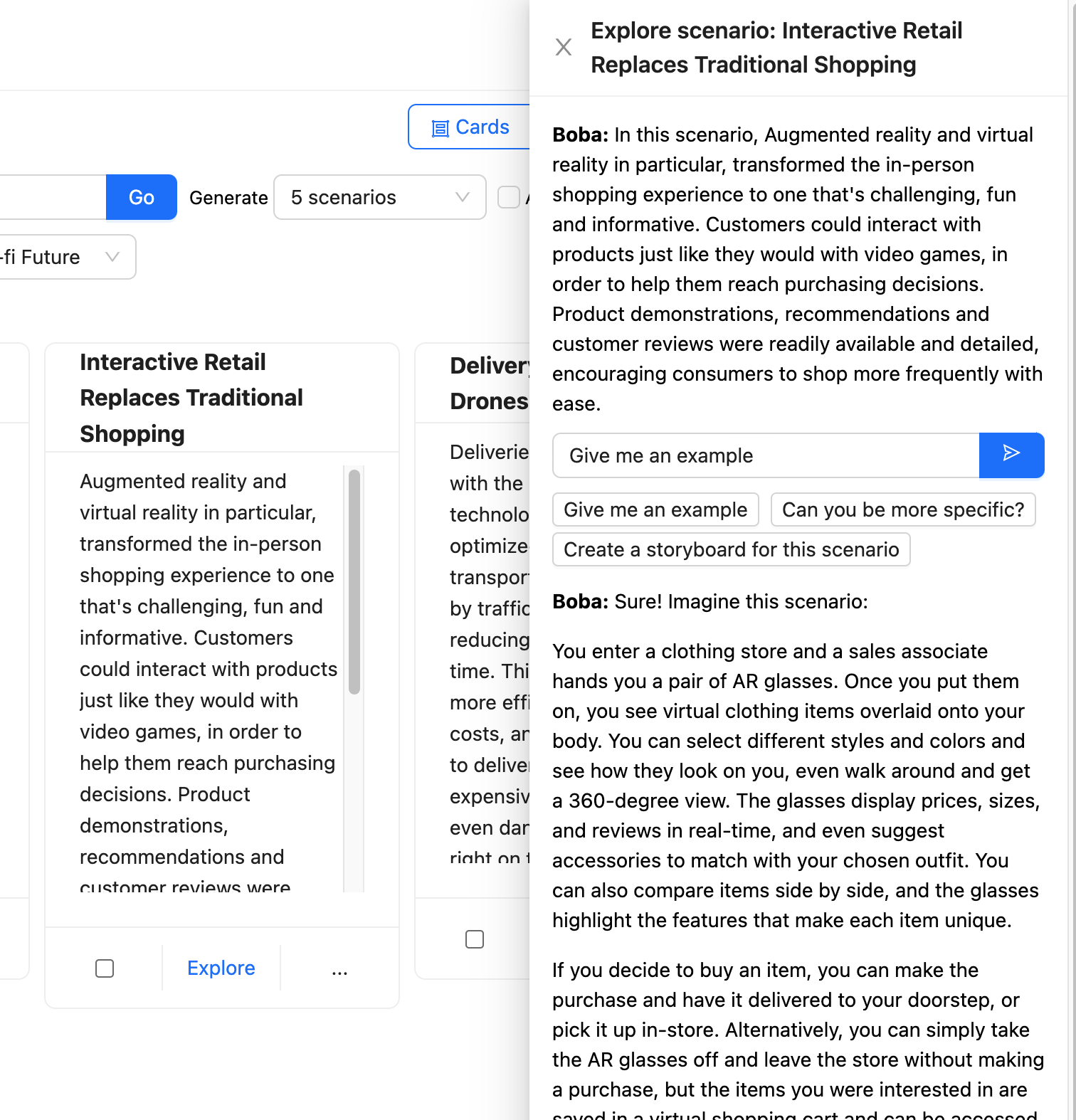
Bobaは、このプロンプトを取得し、LLMに送信する前に、選択したシナリオのコンテキストに焦点を当てるためにプロンプトを豊かにします。
Bobaは、コンテキストの選択と保持を使用して、ユーザーとLLMのやり取りのさまざまな部分を保持し、ユーザーが各やり取りに適切なコンテキストを提供することを心配することなく、複数の方向に探索できるようにします。
LLMを使用する際の難しさの1つは、過去のある時点までのデータのみでトレーニングされているため、最新の情報を使用するのに効果的ではないということです。Bobaには、埋め込まれた外部知識を使用して、LLMと通常の検索機能を組み合わせるリサーチシグナルと呼ばれる機能があります。これは、「現在、ホテル業界では生成AIがどのように活用されていますか?」などのプロンプトされた調査クエリを取得し、そのクエリの強化バージョンを検索エンジンに送信し、提案された記事を取得し、各記事をLLMに送信して要約します。
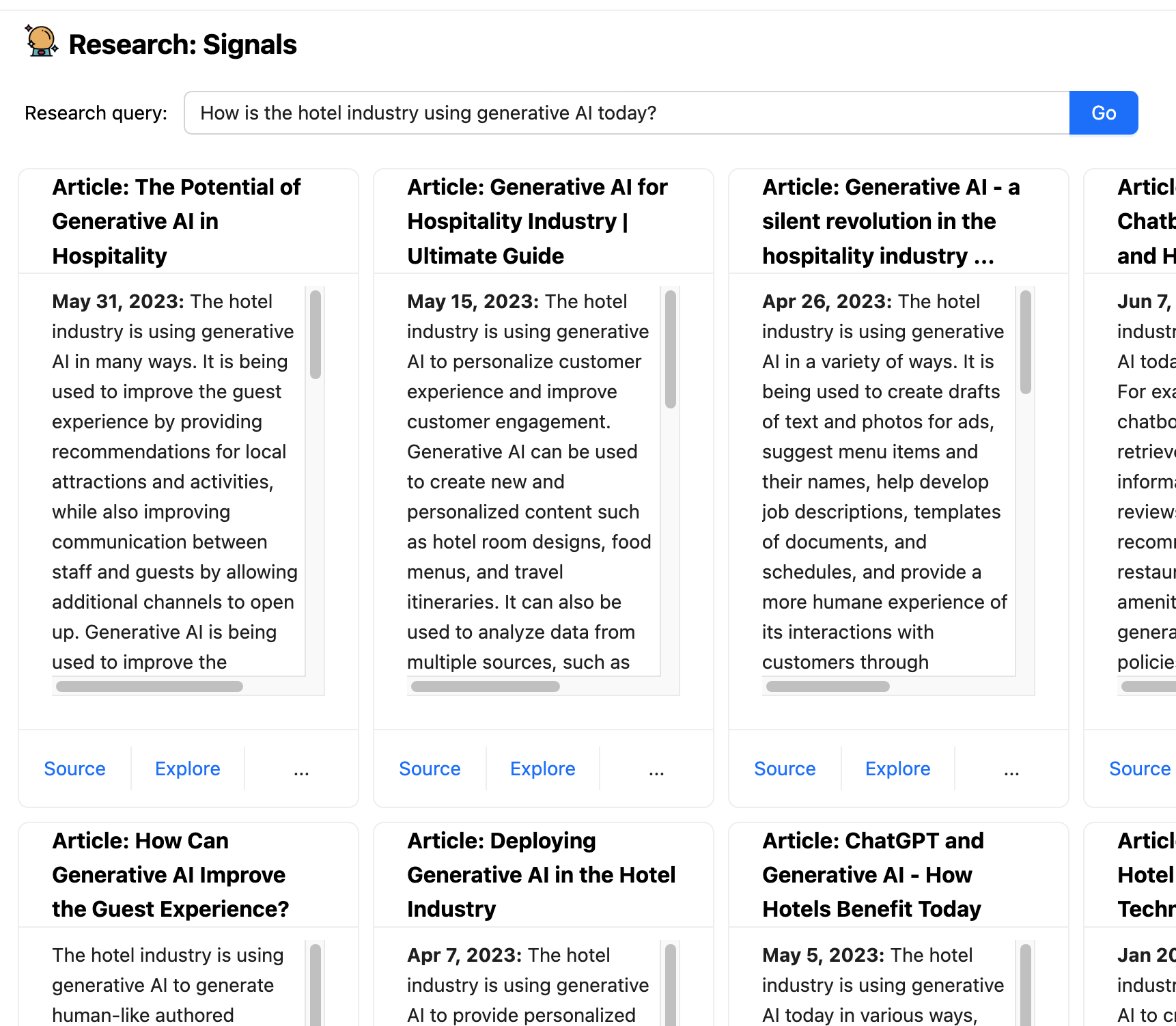
これは、コパイロットアプリケーションがLLMだけでは適切ではないアクティビティを含むやり取りを処理する方法の一例です。これにより、最新の情報が提供されるだけでなく、ユーザーにソースリンクを提供することもできます。また、検索エンジンが間違ったキノコの一部ではない限り、それらのリンクは幻覚ではありません。
生成型コパイロットアプリケーションを構築するためのいくつかのパターン
Bobaの構築において、ユーザーとLLM(特にOpen AIのGPT3.5/4)間の会話を仲介するためのさまざまなパターンとアプローチについて多くを学びました。このパターンのリストは網羅的ではなく、Bobaの構築中にこれまでに学んだ教訓に限定されています。
テンプレート化されたプロンプト
テキストテンプレートを使用して、コンテキストと構造でプロンプトを強化する
最初で最も単純なパターンは、プロンプトに文字列テンプレートを使用することです。これは、チェイニングとも呼ばれます。私たちは、一般的なアプリケーション向けのチェーンとエンドツーエンドのチェーンの標準インターフェースを提供するライブラリであるLangchainを使用しています。以前にNunjucks、EJS、HandlebarsなどのJavascriptテンプレートエンジンを使用したことがある場合、Langchainはまさにそれを提供しますが、関数入力変数、少数のショットプロンプトテンプレート、プロンプト検証、およびより高度な構成可能なプロンプトチェーンなどの機能を備えた、一般的なプロンプトエンジニアリングワークフロー向けに特別に設計されています。
たとえば、Bobaで潜在的な将来のシナリオをブレインストーミングするには、「決済の未来を見せてください」などの戦略的なプロンプトや、単に会社名のような単純なプロンプトを入力できます。ユーザーインターフェースは次のようになります。

この生成を強化するプロンプトテンプレートは、次のようになります。
You are a visionary futurist. Given a strategic prompt, you will create
{num_scenarios} futuristic, hypothetical scenarios that happen
{time_horizon} from now. Each scenario must be a {optimism} version of the
future. Each scenario must be {realism}.
Strategic prompt: {strategic_prompt}
ご想像のとおり、LLMの応答はプロンプトそのものの質に左右されるため、優れたプロンプトエンジニアリングが必要になります。この記事はプロンプトエンジニアリングの入門編ではありませんが、ここでいくつかのテクニックが使われていることに気づくでしょう。例えば、LLMにペルソナを採用させ、具体的には先見の明のある未来学者をペルソナとさせています。これは、より関連性が高く、有用な補完を生成するために、アプリケーションのさまざまな部分で多用したテクニックです。
テストアンドラーン型のプロンプトエンジニアリングのワークフローの一環として、ChatGPTでプロンプトを直接反復することが、アイデアから実験までの最短経路であり、プロンプトに対する信頼性を迅速に構築できることがわかりました。そうは言っても、AI自体(約20%)よりもユーザーインターフェース(約80%)の方に、特にプロンプトのエンジニアリングにおいて、はるかに多くの時間を費やしていることもわかりました。
また、プロンプトテンプレートは、条件文を排除して可能な限りシンプルに保ちました。ユーザーが「詳細(シグナル、脅威、機会)を追加」をクリックした場合など、ユーザー入力に基づいてプロンプトを大幅に変更する必要がある場合は、プロンプトテンプレートが複雑になりすぎて保守が困難になるのを防ぐために、別のプロンプトテンプレートをまとめて実行することにしました。
構造化された応答
LLMに構造化されたデータ形式で応答するように指示する
LLMを使用して構築するほぼすべてのアプリケーションでは、ユーザーの代わりにさらに操作するために、LLMの出力を解析して構造化されたデータまたは半構造化されたデータを作成する必要があるでしょう。Bobaの場合、可能な限りJSONを操作したかったため、GPTに適切にフォーマットされたJSONを返すさまざまなバリエーションを試しました。GPTがプロンプトの指示に基づいて、適切にフォーマットされたJSONをどれほど適切かつ一貫して返すかに非常に驚きました。たとえば、シナリオ生成の応答指示は次のようになります。
You will respond with only a valid JSON array of scenario objects.
Each scenario object will have the following schema:
"title": <string>, //Must be a complete sentence written in the past tense
"summary": <string>, //Scenario description
"plausibility": <string>, //Plausibility of scenario
"horizon": <string>
擬似コードで応答スキーマを記述した場合でも、かなり複雑なネストされたJSONスキーマをサポートできるという事実にも同様に驚きました。戦略生成のためにネストされた応答を記述する方法の例を次に示します。
You will respond in JSON format containing two keys, "questions" and "strategies", with the respective schemas below:
"questions": [<list of question objects, with each containing the following keys:>]
"question": <string>,
"answer": <string>
"strategies": [<list of strategy objects, with each containing the following keys:>]
"title": <string>,
"summary": <string>,
"problem_diagnosis": <string>,
"winning_aspiration": <string>,
"where_to_play": <string>,
"how_to_win": <string>,
"assumptions": <string>
JSON応答スキーマを記述することの興味深い副作用は、LLMに出力でより関連性の高い応答を提供するように促すこともできたことです。たとえば、クリエイティブマトリックスの場合、LLMには、さまざまな側面(プロンプト、行、列、および各行と列の交点にあるプロンプトに応答する各アイデア)について検討してもらいたいと考えています。
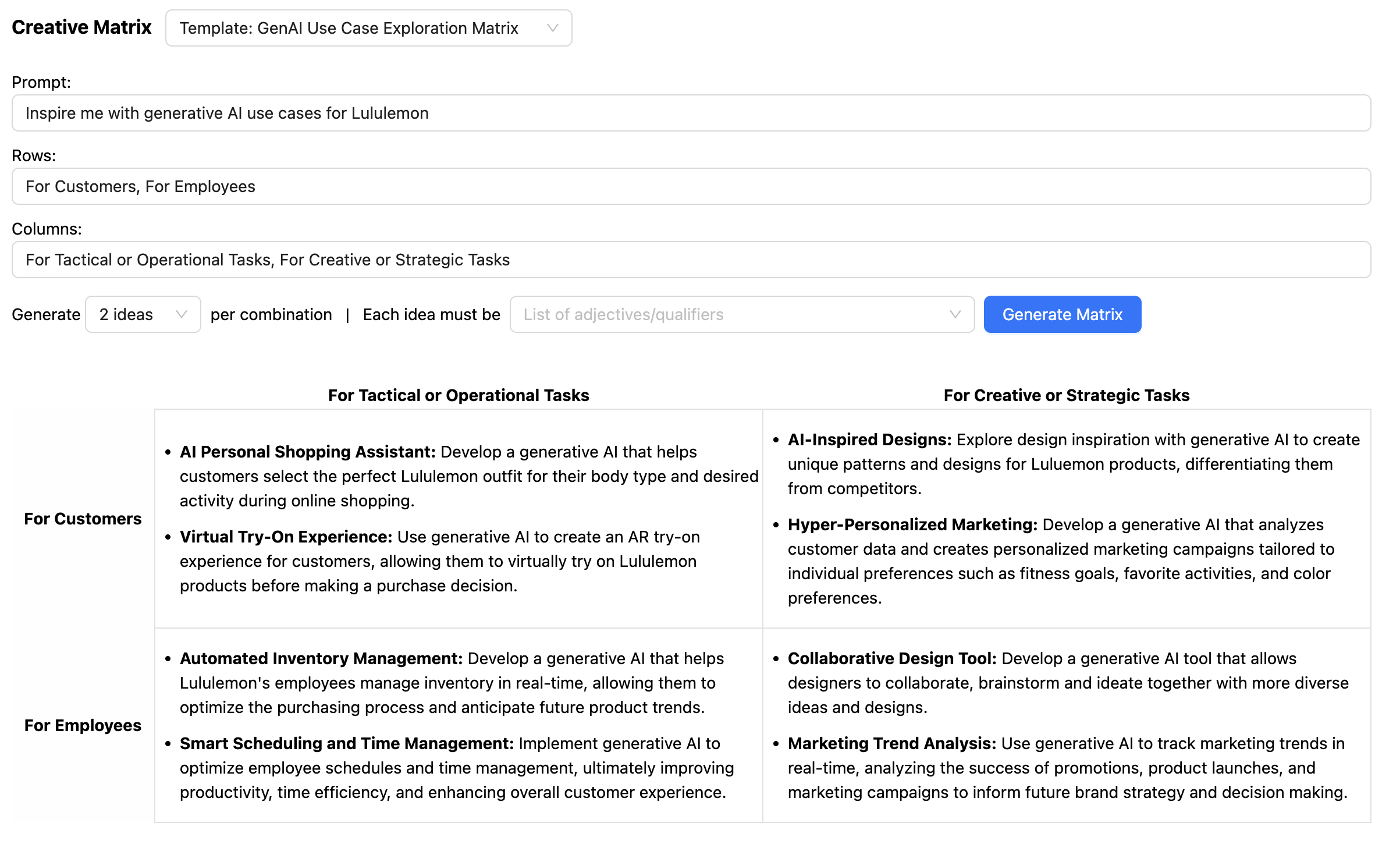
出力スキーマの具体的な例を含むfew-shotプロンプトを提供することで、LLMが各アイデアに対して適切なコンテキスト(プロンプト、行、列)で「考える」ようにさせることができました。
You will respond with a valid JSON array, by row by column by idea. For example:
If Rows = "row 0, row 1" and Columns = "column 0, column 1" then you will respond
with the following:
[
{{
"row": "row 0",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 0",
"description": "idea 0 for prompt and row 0 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 1",
"description": "idea 0 for prompt and row 0 and column 1"
}}
]
}},
]
}},
{{
"row": "row 1",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 0",
"description": "idea 0 for prompt and row 1 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 1",
"description": "idea 0 for prompt and row 1 and column 1"
}}
]
}}
]
}}
]
スキーマをより簡潔かつ一般的に記述することもできましたが、例をより詳細かつ具体的にすることで、LLMの応答の質を私たちが望む方向にうまく促すことができました。これは、LLMがトークンで「思考」し、アイデアを出力する前に行と列の値を(つまり、繰り返して)出力することで、生成されるアイデアのコンテキストがより正確になるためだと考えています。
この記事の執筆時点では、OpenAIはFunction Callingという新しい機能をリリースしています。これは、応答のフォーマットという目標を達成するための別の方法を提供します。このアプローチでは、開発者は呼び出し可能な関数のシグネチャとそれぞれのスキーマをJSONとして記述し、LLMにそのスキーマに準拠するJSONで提供されたそれぞれのパラメータを持つ関数呼び出しを返すように指示することができます。これは、Web検索を実行したり、プロンプトに応答してAPIを呼び出したりするなど、外部ツールを呼び出したい場合に特に役立ちます。Langchainも同様の機能を提供していますが、彼らはすぐに外部ツールAPIとOpenAI関数呼び出しAPIの間のネイティブ統合を提供すると思います。
リアルタイム進捗
ユーザーが進捗状況を監視できるように、応答をUIにストリームする
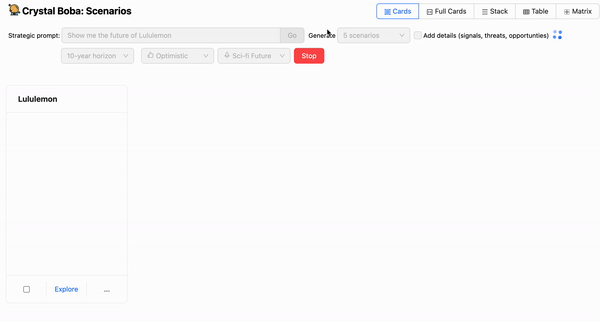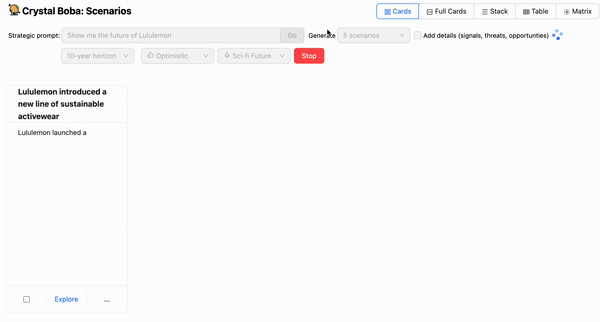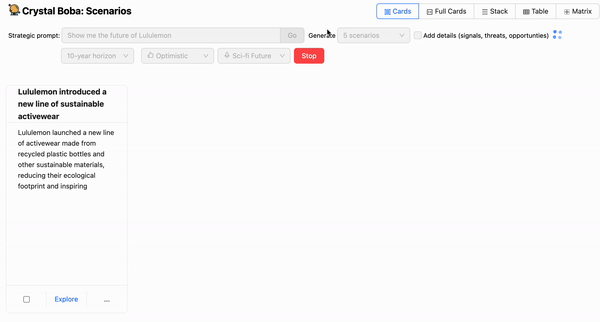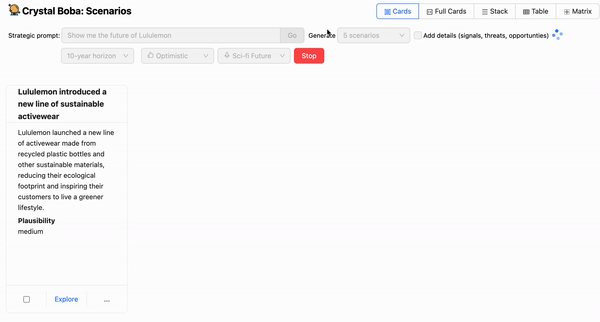
LLMの上にグラフィカルユーザーインターフェースを実装するときに最初に気づくことの1つは、応答全体が完了するのを待つには時間がかかりすぎることです。ChatGPTでは、文字単位で応答がストリーミングされるため、これにあまり気づきません。これは、ユーザーが我慢できなくなる前にスピナーを待っていられる時間には限りがあるという経験から、留意しておくべき重要なユーザーインタラクションパターンです。私たちの場合は、たとえ部分的なものであっても、ユーザーが応答を見始めるまでに数秒以上待たせたくありませんでした。
したがって、コパイロットエクスペリエンスを実装する場合は、完了までに数秒以上かかるプロンプトの実行中にリアルタイムの進捗状況を表示することを強くお勧めします。私たちの場合、これはLLMからUIまでフルスタックでリアルタイムに生成をストリーミングすることを意味しました。幸いなことに、LangchainとOpenAIのAPIは、まさにそれを実行する機能を提供します。
const chat = new ChatOpenAI({
temperature: 1,
modelName: 'gpt-3.5-turbo',
streaming: true,
callbackManager: onTokenStream ?
CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
onTokenStream(token)
},
}) : undefined
});
これにより、ユーザーの期待に一致しないアイデアが生成された場合に、完了途中で生成を停止する機能を含め、ユーザーにとってよりスムーズなエクスペリエンスを作成するために必要なリアルタイムの進捗状況を提供できました。
ただし、そうすることで、特にビューとコントローラーのアプリケーションロジックに多くの複雑さが追加されます。Bobaの場合、JSONの最善の解析を実行し、LLM呼び出しの実行中に一時的な状態を維持する必要もありました。この記事の執筆時点では、Web開発者がこれを容易にするための新しい有望なライブラリがいくつか登場しています。たとえば、Vercel AI SDKは、エッジ対応のAI搭載ストリーミングテキストおよびチャットUIを構築するためのライブラリです。
コンテキストを選択して持ち込む
関連するコンテキスト情報をキャプチャして、後続のアクションに追加する
チャットインターフェースの最大の制限の1つは、ユーザーがシングルスレッドコンテキスト、つまり会話チャットウィンドウに限定されることです。コパイロットエクスペリエンスを設計する場合は、実際のアクションや説明の文脈で何かを指し示すという私たちの自然な傾向と同様に、選択のコンテキスト内でアクションを実行するためのUXアフォーダンスを設計する方法について深く考えることをお勧めします。
コンテキストを選択して持ち込むことで、ユーザーは後続のタスク(タスクコンテキストとも呼ばれます)を実行するために、インタラクションの範囲を絞ったり広げたりできます。これは通常、ユーザーインターフェイスで1つまたは複数の要素を選択し、それらに対してアクションを実行することで行われます。たとえば、Bobaの場合、このパターンを使用して、ユーザーがアイデア(シナリオ、戦略、プロトタイプコンセプトなど)を選択して、アイデアに関するより絞り込んだ会話をしたり、コンセプトのバリエーションを選択して生成したりできるようにしています。まず、ユーザーがアイデアを選択します(チェックボックスで明示的に、またはリンクをクリックして暗黙的に)。
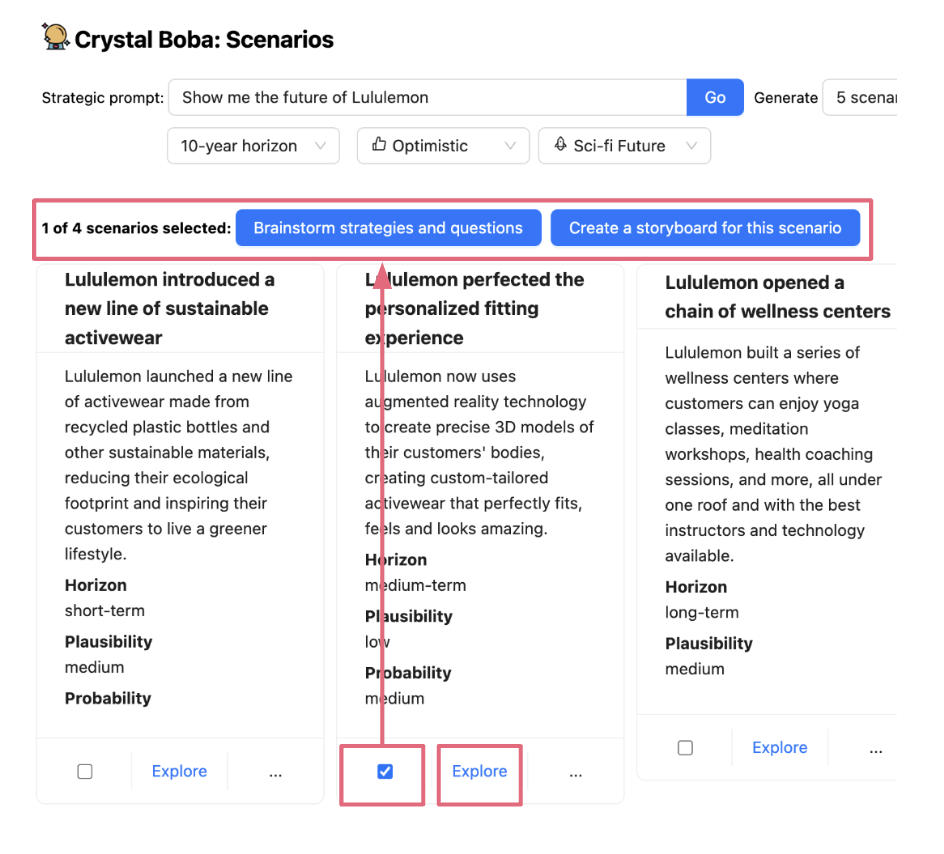
次に、ユーザーが選択に対してアクションを実行すると、選択された項目が新しいタスクのコンテキストとして引き継がれます。たとえば、ユーザーが「このシナリオの戦略と質問をブレインストーミングする」をクリックした場合は戦略生成のシナリオサブプロンプトとして、またはユーザーが「探索」をクリックした場合は自然言語会話のコンテキストとして。
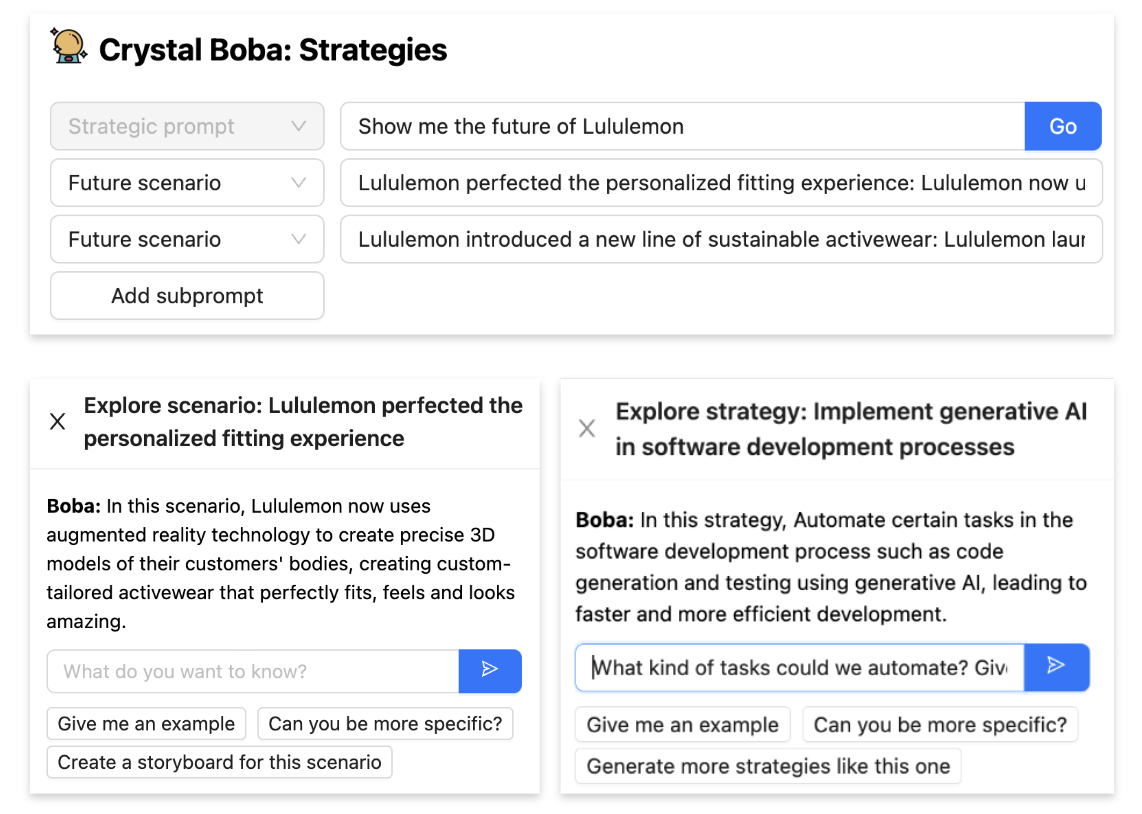
会話/インタラクションのセグメントに確立したいコンテキストの性質と長さによっては、コンテキストを選択して持ち込むの実装は非常に簡単な場合から非常に難しい場合があります。コンテキストが短く、単一のLLMコンテキストウィンドウ(LLMがサポートするプロンプトの最大サイズ)に収まる場合は、プロンプトエンジニアリングだけで実装できます。たとえば、上で示したBobaでは、アイデアの「探索」をクリックして、そのアイデアについてBobaと会話できます。バックエンドでのこの実装方法は、複数メッセージのチャット会話を作成することです。
const chatPrompt = ChatPromptTemplate.fromPromptMessages([
HumanMessagePromptTemplate.fromTemplate(contextPrompt),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]);
const formattedPrompt = await chatPrompt.formatPromptValue({
input: input
})
コンテキストを選択して持ち込むを実装するもう1つのテクニックは、以下に示すように、タグ区切り文字内でコンテキストを提供することで、プロンプト内で実行することです。この場合、ユーザーは複数のシナリオを選択しており、それらのシナリオに対する戦略を生成したいと考えています(シナリオの作成やアイデアのストレステストでよく使用されるテクニック)。戦略生成に持ち込みたいコンテキストは、選択されたシナリオのコレクションです。
Your questions and strategies must be specific to realizing the following
potential future scenarios (if any)
<scenarios>
{scenarios_subprompt}
</scenarios>
ただし、コンテキストがLLMのコンテキストウィンドウを超える場合、または過去のインタラクションのより洗練されたチェーンを提供する必要がある場合は、外部の短期メモリ(通常はベクターストア(インメモリまたは外部)を使用)を使用する必要がある場合があります。同様の操作を実行する方法の例を、埋め込み外部知識で示します。
生成アプリケーションにおける選択とコンテキストの有効な使用方法についてさらに学習したい場合は、NotionのLinus Lee氏がLLMs in Productionカンファレンスで行った講演「チャットを超えた生成エクスペリエンス」を強くお勧めします。
コンテキストに応じた会話
コンテキスト内でLLMとの直接会話を許可する。
これはコンテキストを選択して持ち込むの特別なケースです。Bobaは可能な限りチャットウィンドウインタラクションモデルから脱却させたいと考えていましたが、ユーザーがLLMと直接会話するための「フォールバック」チャネルを提供することは依然として非常に役立つことがわかりました。これにより、UIでサポートしていないインタラクションに対する会話エクスペリエンスを提供したり、テキストによる自然言語会話がユーザーにとって最も理にかなっている場合をサポートしたりできます。
以下の例では、ユーザーはRogers Sportsnetが提供するパーソナライズされたハイライトリールのコンセプトについてBobaとチャットしています。完全なコンテキストはチャットメッセージ(「このコンセプトでは、あなたが愛するスポーツの世界を発見してください...」)として言及されており、ユーザーはBobaにコンセプトのユーザー体験を作成するように求めています。LLMからの応答はフォーマットされ、Markdownとしてレンダリングされます。
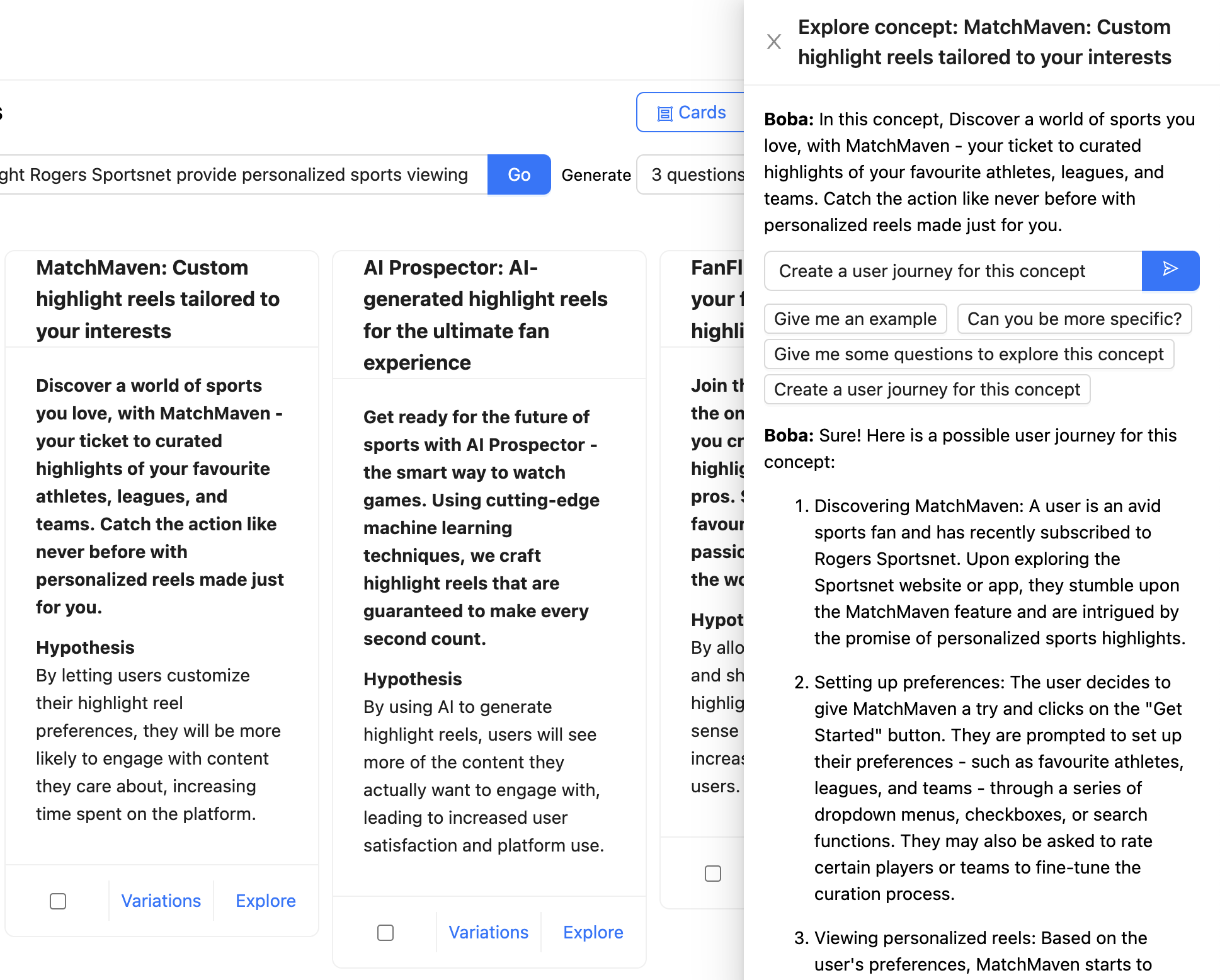
生成コパイロットエクスペリエンスを設計する場合は、アプリケーションとのコンテキストに応じた会話をサポートすることを強くお勧めします。ユーザーがどのような会話をできるかを知るために、ユーザーがアプリケーションに送信できる便利なメッセージの例を必ず提供してください。上のスクリーンショットに示すように、Bobaの場合、これらの例は入力ボックスの下にメッセージテンプレートとして(「もっと詳しく説明できますか?」など)提供されています。
声に出して考える
回答中に中間結果を生成するようにLLMに指示する
LLMは実際には「考える」わけではありませんが、OpenAIのAndrei Karpathy氏の「LLMはトークンで『考える』」という言葉を比喩的に捉えることは有益です。彼が意味するところは、GPTは質問にすぐに答えようとするよりも、より多くの時間(つまり、より多くのトークン)を与えて「考え」させた方が、推論エラーが少なくなる傾向があるということです。Bobaの開発において、Chain of Thought(CoT)プロンプティング、より具体的には、回答の前に推論の連鎖を求めることが、LLMがより質の高い、より関連性の高い回答を導き出すのに役立つことがわかりました。
Bobaの一部の機能、例えば戦略やコンセプトの生成では、LLMに、アイデア(この場合は戦略やコンセプト)を生成する前に、ユーザーの入力プロンプトを拡張する一連の質問を生成するように指示します。
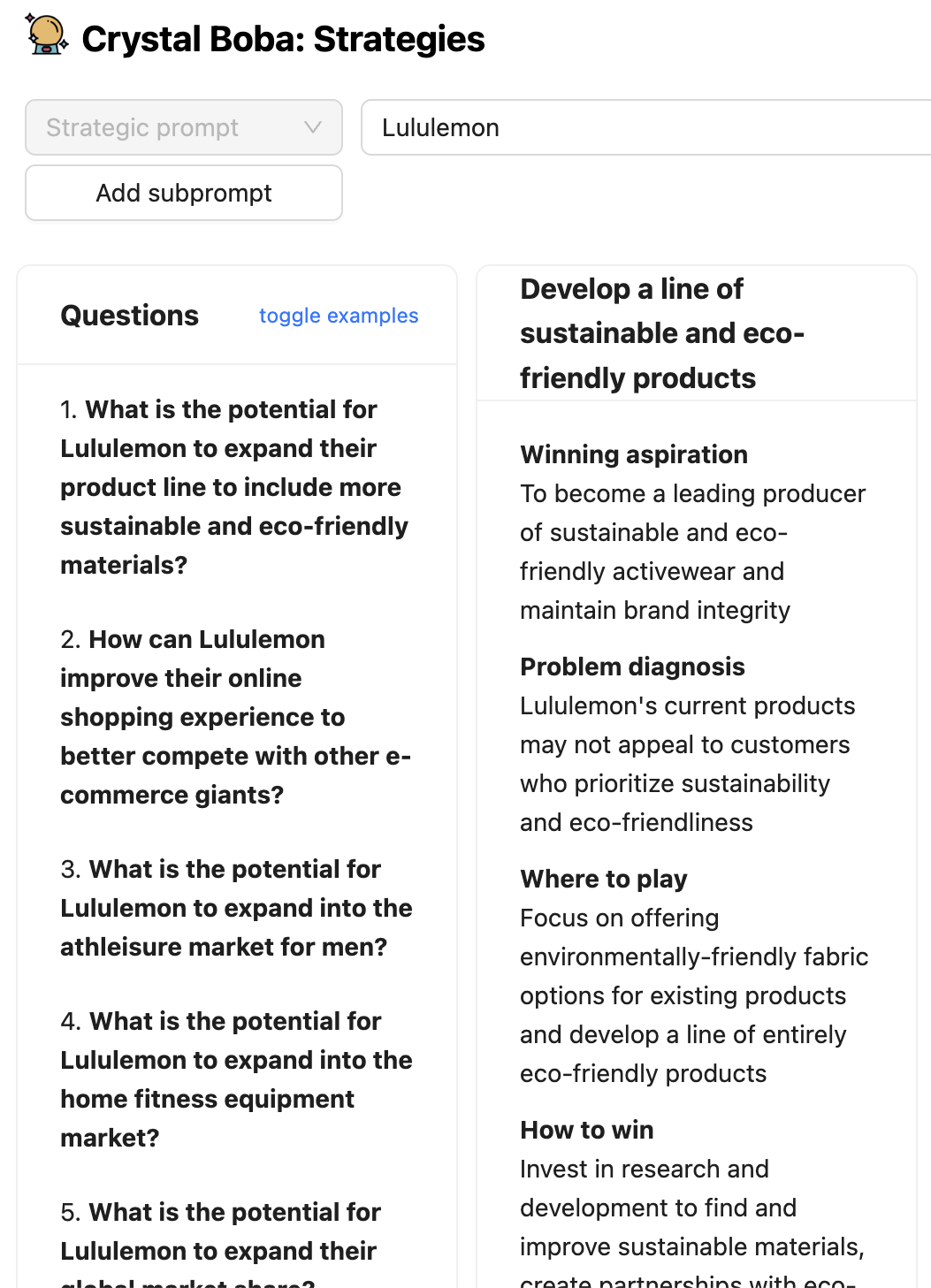
LLMによって生成された質問は表示しますが、このパターンの同様に有効なバリエーションとして、ユーザーに公開しない内部モノローグを実装することが挙げられます。この場合、LLMに回答を検討させ、その内部モノローグをレスポンスの別の部分に格納し、ユーザーに表示する結果から解析して無視することができます。このパターンのより詳細な説明は、OpenAIのGPTのベストプラクティスガイドの「GPTに『考える』時間を与える」のセクションにあります。
ジェネレーティブアプリケーションのユーザーエクスペリエンスパターンとして、ユーザーが次のアクションやプロンプトを反復する上で役立つ追加のコンテキストを提供するために、適切な場合は推論プロセスをユーザーと共有することが役立つとわかりました。例えば、Bobaでは、Bobaがどのような種類の質問を考えたかを知ることで、ユーザーは探索すべき、または探索すべきでない発散的な領域についてより多くのアイデアを得ることができます。また、ユーザーは、次のイテレーションで特定の種類アイデアを除外するようにBobaに要求することもできます。この方法を採用する場合は、上記のBobaの例のように、モノローグや思考の連鎖を隠すためのUIアフォーダンスを作成することをお勧めします。
反復的な応答
ユーザーがコパイロットと双方向のやり取りをするためのアフォーダンスを提供する
LLMはユーザーの意図を誤解したり、単にユーザーの期待に応えない応答を生成したりする可能性があります。したがって、あなたのジェネレーティブアプリケーションも同様です。ChatGPTを従来のチャットボットと区別する最も強力な機能の1つは、会話の方向を柔軟に反復して改善し、それによって生成される応答の品質と関連性を向上させる機能です。
同様に、ジェネレーティブコパイロットエクスペリエンスの質は、ユーザーがコパイロットとスムーズな双方向のやり取りができるかどうかにかかっていると考えています。これが私たちが「応答の反復」パターンと呼ぶものです。これにはいくつかのアプローチが考えられます。
- アプリケーション/LLMに提供された元の入力を修正する
- ユーザーへのコパイロットの応答の一部を洗練させる
- アプリケーションを異なる方向に誘導するためのフィードバックを提供する
Bobaで反復的な応答を実装した例の1つは、ストーリーボードです。短いプロンプトでも詳細なプロンプトでも、Bobaは、複数のシーン、各シーンにはナラティブスクリプトとStable Diffusionで生成された画像を含むビジュアルストーリーボードを生成できます。例えば、以下は「未来のホテル」の体験を描いた部分的なストーリーボードです。
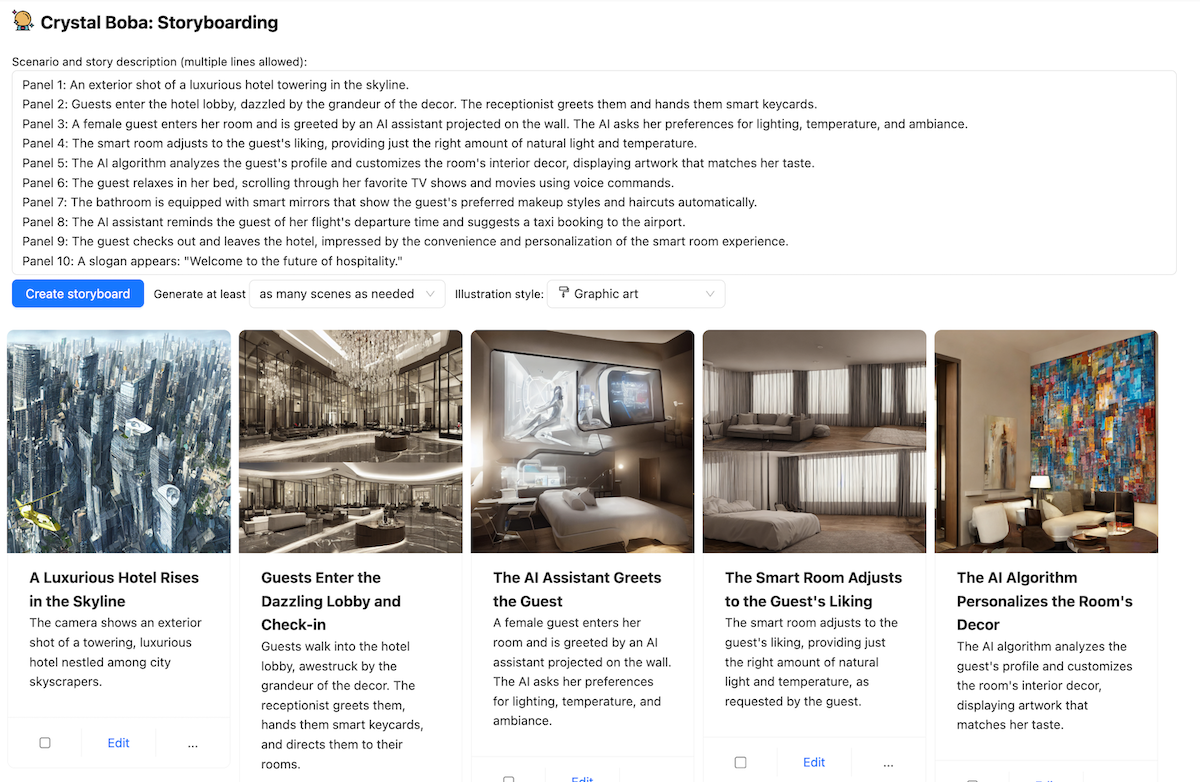
BobaはLLMを使用してStable Diffusionプロンプトを生成するため、画像がどれだけうまく表示されるかはわかりません。そのため、この機能では少し当たり外れがあります。これを補うために、ユーザーが画像プロンプトを反復して特定のシーンの画像を洗練できるようにすることにしました。ユーザーは、単に画像をクリックし、Stable Diffusionプロンプトを更新して、「完了」を押すだけで、Bobaは更新されたプロンプトで新しい画像を生成し、ストーリーボードの残りの部分は維持します。

現在開発中の反復的な応答のもう1つの例は、ユーザーが生成されたアイデアの品質に関してBobaにフィードバックを提供する機能です。これは、コンテキストを選択して保持と反復的な応答の組み合わせになります。1つのアプローチは、アイデアに賛成または反対の評価を与え、Bobaにそのフィードバックを新しいまたは次の推奨事項に組み込ませることです。別のアプローチは、自然言語の形で会話的なフィードバックを提供することです。どちらの方法でも、強化学習をサポートするスタイル(より多くのフィードバックを提供するとアイデアが向上する)でこれを行いたいと考えています。この良い例はGithub Copilotでしょう。Github Copilotは、ユーザーによって無視されたコード提案を次の最良のコード提案のランキングで格下げします。
これは、効果的なジェネレーティブエクスペリエンスを実装するための最も重要で、一般的ではありますが、パターンの1つであると考えています。難しいのは、フィードバックのコンテキストを後続の応答に組み込むことです。これには、コンテキストウィンドウのサイズが限られているため、多くの場合、アプリケーションに短期または長期のメモリを実装する必要があります。
埋め込まれた外部知識
LLMを他の情報源と組み合わせて、LLMのトレーニングセットを超えるデータにアクセスする
この記事の前半で述べたように、ジェネレーティブアプリケーションでは、多くの場合、LLMに外部ツール(API呼び出しなど)や外部メモリ(短期または長期)を組み込む必要があります。Bobaの「リサーチ」機能を実装した際にこのシナリオに遭遇しました。この機能を使用すると、例えば「今日のホテル業界はジェネレーティブAIをどのように利用していますか?」など、ウェブ上で公開されている情報に基づいて定性的なリサーチの質問に答えることができます。
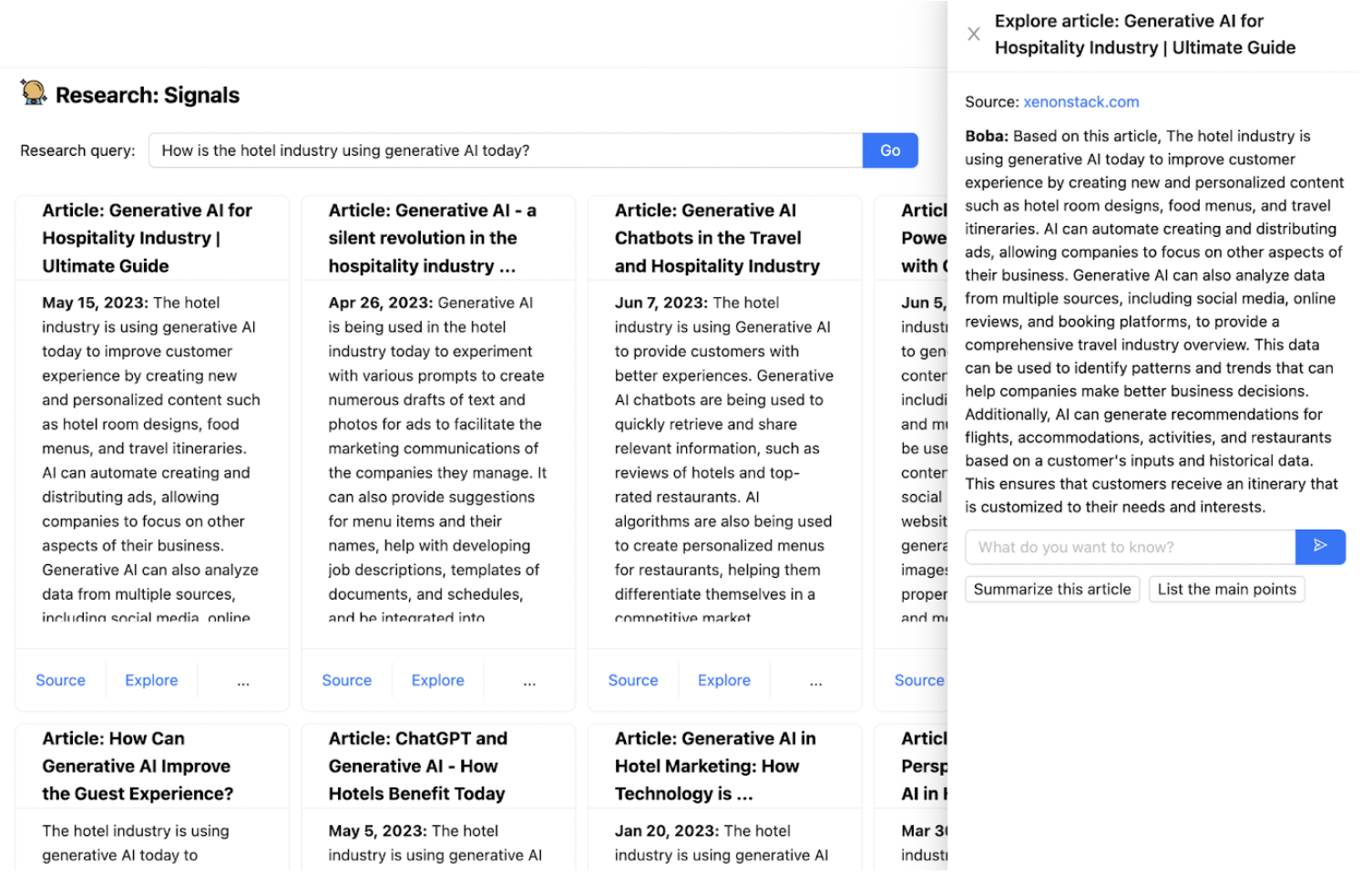
これを実装するために、LLMにGoogleを外部のウェブ検索ツールとして「装備」し、プロンプトのコンテキストウィンドウに収まらない可能性のある長い記事を読めるようにする必要がありました。また、Bobaがユーザーが見つけた関連のある記事についてユーザーとチャットできるようにしたいと考えました。そのためには、短期メモリの一種を実装する必要がありました。最後に、ユーザーの調査質問に回答するために使用された適切なリンクと参照をユーザーに提供したかったのです。
Bobaでこれを実装した方法は次のとおりです。
- Google SERP APIを使用して、ユーザーのクエリに基づいてウェブ検索を実行し、上位10件の記事(検索結果)を取得します。
- Extract APIを使用して、各記事の全文を読みます。
- 各記事の内容を短期メモリ、具体的にはインメモリベクターストアに保存します。ベクターストアの埋め込みは、OpenAI APIを使用して生成され、各記事全体を埋め込むのではなく、各記事のチャンクに基づいて生成されます。
- ユーザーの検索クエリの埋め込みを生成します。
- 検索クエリの埋め込みを使用して、ベクターストアをクエリします。
- ベクターストアクエリの結果をコンテキストとしてLLMプロンプトにプレフィックスを付けながら、LLMにユーザーの元のクエリに自然言語で回答するように指示します。
これは多くのステップのように聞こえるかもしれませんが、Langchainのようなツールを使用すると、プロセスをスピードアップできます。特に、LangchainにはVectorDBQAChainというエンドツーエンドのチェーンがあり、これを使用して質問応答を実行すると、Bobaでわずか数行のコードで済みました。
const researchArticle = async (article, prompt) => {
const model = new OpenAI({});
const text = article.text;
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const res = await chain.call({
input_documents: docs,
query: prompt + ". Be detailed in your response.",
});
return { research_answer: res.text };
};
記事のテキストには記事の全内容が含まれており、1つのプロンプトに収まらない場合があります。そのため、上記の手順を実行します。ご覧のとおり、HNSWLib(階層型ナビゲーション可能スモールワールド)と呼ばれるインメモリベクターストアを使用しました。HNSWグラフは、ベクトル類似性検索においてトップクラスのパフォーマンスを発揮するインデックスの1つです。ただし、大規模なユースケースや長期メモリの場合には、PineconeやWeaviateのような外部ベクトルDBを使用することをお勧めします。
また、Langchainの外部ツールAPIを使用してGoogle検索を実行することで、ワークフローをさらに合理化することもできましたが、Langchainに意思決定を委ねすぎるため、結果が混在し、遅く、解析が難しくなったため、そうしないことにしました。外部ツールを実装する別の方法は、Open AIが最近リリースした関数呼び出しAPIを使用することです。これについてはこの記事の前半で言及しました。
要約すると、埋め込まれた外部知識を実装するために、2つの異なる手法を組み合わせました。
- 外部ツールを使用する:Google SERPとExtract APIを使用して記事を検索して読みます。
- 外部メモリを使用する:インメモリベクターストア(HNSWLib)を使用した短期メモリ
今後の計画とパターン
これまでのところ、Bobaのプロトタイプと、製品戦略とジェネレーティブアイデア生成のためのジェネレーティブコパイロットがどのようなものになるかについては、表面をなぞった程度です。LLMを活用したジェネレーティブコパイロットアプリケーションを構築する技術については、まだ学ぶべきこと、共有すべきことがたくさんあり、今後数か月でそうしていきたいと考えています。この新しいクラスのアプリケーションやエクスペリエンスに取り組むには刺激的な時期であり、多くの原則、パターン、プラクティスがまだ発見されていないと信じています。
重要な改訂
2023年6月29日: 初公開