ここに至るまで
私が依存性逆転の原則 を最初に知ったのは、1994年頃のRobert (Uncle Bob) Martinからでした。これは、SOLID原則 のほとんどと同様に、記述するのは簡単ですが、応用は奥深いです。以下は、私が実際のプロジェクトで使用した最近の応用例です。私が議論するすべてのものは、2012年6月から本番環境にあり、2013年中旬現在も本番環境にあります。これらのいくつかはさらに古いものですが、戻ってくるたびに、基本が重要であることを思い出させられます。
DIPの概要
依存性逆転の原則を表現する方法はたくさんあります
抽象化は詳細に依存すべきではない
コードは、同じまたはより高いレベルの抽象化のものに依存すべきである
高レベルのポリシーは低レベルの詳細に依存すべきではない
低レベルの依存関係をドメイン関連の抽象化でキャプチャする
これらすべての共通点は、システムのある部分から別の部分への視点に関するものです。依存関係をより高レベル(ドメインに近い)の抽象化に向かって移動させるように努めてください。
ドメイン分析:プラトン的理想主義の問題点
私は90年代初頭にドメイン分析を正式に紹介されました。私に強い影響を与えた最初のソースは、オブジェクト指向開発:フュージョンメソッド でした。
当時、私は検討中の問題とは無関係にドメイン分析を行っていました。その後、その10年のうちに、ドメイン分析は問題を考慮した場合の方がうまく機能するという結論にゆっくりと達しました。なぜでしょうか?なぜなら、最終的にはすべてが複数の方法で他のすべてに関連しているからです。ドメイン分析はモデリング の一種です。モデリングの重要な点は、少なくとも私にとっては、重要な詳細のみを検討しているということです。何が重要かをどのように判断しますか?達成する必要があることに関連するドメインの部分のみを検討します。
ここには鶏が先か卵が先かという問題があります。ドメインは問題によって知らされ、その逆もまた然りです。システム境界も影響します。これらの相互依存関係をすべて処理するために、三角測量を行います。問題、ドメイン、システム境界についてより良いアイデアが得られるようになると、特定の抽象化の適切性を検討するのに有利な立場になります。
この記事全体で、ドメインについて言及するとき、私はそのようなコンテキストの外に存在する神話的なドメインではなく、いくつかの機能セットによって制限されたドメインを意味します。ある意味、これはドメイン分析に適用されたYAGNI です。
なぜ依存関係を気にするのか?
依存関係はリスクです。たとえば、私のシステムでJava Runtime Environment(JRE)がインストールされている必要があり、インストールされていない場合、私のシステムは動作しません。私のシステムは、おそらく何らかのオペレーティングシステムも必要とします。ユーザーがWeb経由でシステムにアクセスする場合、ユーザーはブラウザを持っている必要があります。これらの依存関係の一部は制御または制限できますが、無視できるものもあります。たとえば、
JREの要件の場合、デプロイ環境に適切なバージョンのJREがインストールされていることを確認できます。または、環境が固定されている場合は、JREに合わせてコードを調整できます。Puppetなどのツールを使用して環境を制御し、より単純で既知の開始イメージから環境を構築できます。いずれにせよ、結果は深刻ですが、それを軽減するためのいくつかのオプションが十分に理解されています。(私の個人的な好みは、スペクトルのCD の最後に傾いています。)
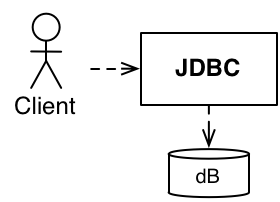
システムでStringクラスを使用する場合、おそらくその依存関係を反転させません。たとえば、Stringをプリミティブ(厳密にはそうではありませんが、十分に近いです)と考える場合、多くのStringを操作することはプリミティブ強迫観念 に似てきます。Stringの周りに型を導入し、Stringメソッドを単純に公開するのではなく、それらのStringの使用法に意味のあるメソッドを追加する場合、結果の型がStringよりもドメインに近い限り、それは一種の依存性逆転のように見え始めます。
ブラウザの場合、最新のエクスペリエンスが必要な場合は、すべてのブラウザをサポートするのが難しいでしょう。すべてのブラウザとバージョンを許可しようとしたり、比較的最新のブラウザにサポートを限定したり、機能低下を導入したりできます。この種の依存関係は複雑であり、おそらく解決には多面的なアプローチが必要です。
依存関係はリスクを表します。そのリスクに対処するにはコストがかかります。経験、試行錯誤、またはチームの集団的な知恵を通じて、そのリスクを明示的に軽減するかどうかを選択します。
何と比較しての反転か?
反転は方向の逆転ですが、何と比較しての逆転でしょうか?構造化分析と設計 の設計部分です。
構造化分析と設計では、高レベルの問題から始めて、それをより小さな部分に分割します。「大きすぎる」ままの小さな部分については、分割を続けます。高レベルの概念/要件/問題は、より小さく、より小さな部分に分割されます。高レベルの設計は、これらのより小さく、より詳細な部分の観点から記述されるため、より小さく、より詳細な部分に直接依存します。これは、トップダウン設計とも呼ばれます。この問題の説明を考えてみてください(やや理想化され、整理されていますが、それ以外は野生で見つかるものです)。
エネルギー節約レポート
データを収集する
接続を開く
SQLを実行する
ResultSetを翻訳する
ベースラインを計算する
ベースライングループを決定する
時間シーケンスデータを投影する
日付範囲全体を計算する
製品レポート
非ベースライングループを決定する
時間シーケンスデータを投影する
データ範囲全体を計算する
ベースラインからのデルタを計算する
結果をフォーマットする
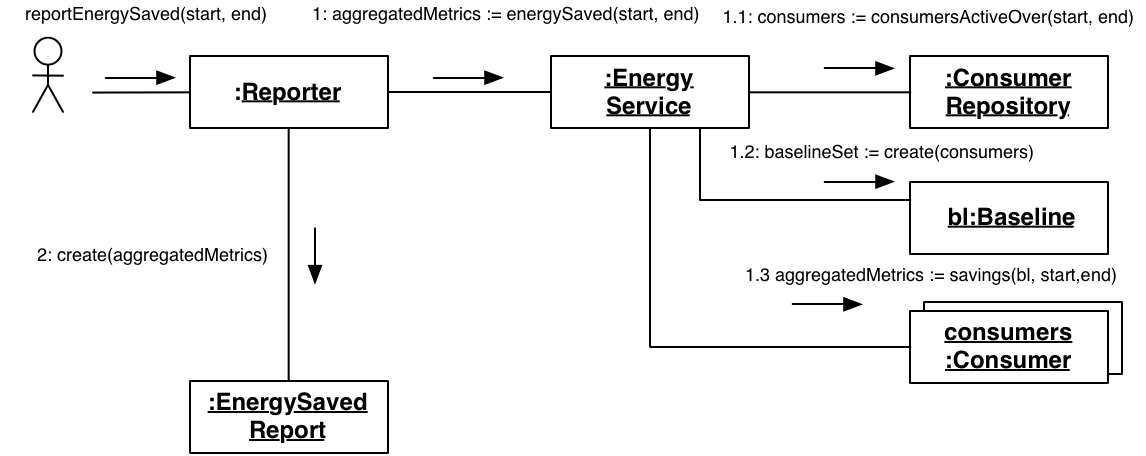
エネルギー節約に関するレポートというビジネス要件は、データ収集に依存し、データ収集はSQLの実行に依存します。依存関係が問題の分解方法に従っていることに注意してください。何かが詳細であればあるほど、変更される可能性が高くなります。私たちは、変更される可能性が高いものに依存する高レベルのアイデアを持っています。さらに、手順はより高いレベルでの変更に非常に敏感です。これは、要件が変更される傾向があるため、問題です。私たちは、その種の分解に関して依存関係を反転させたいと考えています。
それをボトムアップ構成と対比させてください。ドメインに存在する論理的な概念を見つけて、それらを組み合わせて高レベルの目標を達成することができます。たとえば、電力を使用するものが多数あるので、それらを消費者と呼びます。それらについてはあまり知らないので、コンシューマーリポジトリ を介してそれらにアクセスします。ドメインにベースラインと呼ばれるものがあり、それを決定する必要があります。消費者はエネルギー使用量を計算できるため、ベースラインとすべての消費者が使用したエネルギーを比較して、エネルギー節約を判断できます。
私たちが行う作業は最初は同じかもしれませんが、この再考では、もう少し作業することで、詳細を達成するためのさまざまな方法を導入する機会があります。
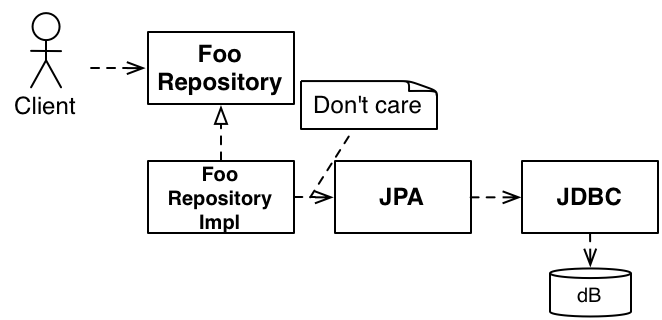
リポジトリを別のストレージメカニズムに切り替えます。そのインターフェースにはSQLに関する言及がないため、インメモリソリューション、NoSqlソリューション、またはRESTfulサービスを使用できます。
ベースラインを構築する代わりに、抽象ファクトリー を使用します。これにより、複数の種類のベースライン計算がサポートされ、これは特定のドメインの現実を実際に反映します。
これを読むと、このすべてにオープン/クローズ原則 の概念が含まれていることに気づくかもしれません。それは確かに関連しています。最初に、問題をドメインで示唆されている論理的なブロックに分割します。システムが成長するにつれて、これらのブロックを使用するか、それらを何らかの方法で拡張して、追加のシナリオに対応します。
それは一体どういう意味なのか?
DIPが抽象化を指す場合、多くの人が抽象化を次のようなものと混同していることに気づきました
インターフェイス
抽象基本クラス
制約として与えられたもの(例:外部システムアーキテクチャ)
解決策として述べられている要件と呼ばれるもの
実際、これらのいずれも誤解を招く可能性があります
インターフェース — java.sql.Connectionを見てみましょう。あなたのビジネスドメインと、getAutoCommit()、createStatement()、getHoldability()のようなメソッドを比較してみてください。これらはデータベース接続には妥当かもしれませんが、あなたのシステムのユーザーがやりたいこととどのように関連するでしょうか?その関連性はせいぜい薄弱です。
抽象基底クラス — 抽象基底クラスはインターフェースと同じ問題を抱えています。メソッドがあなたのドメインにとって意味をなすなら、それは良いかもしれません。メソッドがソフトウェアライブラリにとって意味をなすなら、そうではないかもしれません。例えば、java.util.AbstractListを考えてみましょう。歴史的出来事の順序付けられたリストが常に増え続けるドメインを想像してみてください。この仮説的なドメインでは、歴史的記録からアイテムをremove()することは決して意味をなしません。List抽象は、あなたの問題ではなく一般的な問題を解決するため、少なくともあなたのドメインでは意味をなさないこの1つの機能を提供します。AbstractList(または他のListクラス)をサブクラス化することはできますが、そうすることで、そのクラスの使用にとって意味をなさないメソッド(おそらく複数)が依然として公開されます。不必要なメソッドをクライアントに見せることを許容し始めるとすぐに、DIPとリスコフの置換原則 の両方に違反する可能性が高いでしょう。
制約/要件 — 私たちに与えられた仕事は、問題の解決方法について語るのではなく、動機と目標を提供しているでしょうか?あなたの要件は、統合のためにメッセージ指向ミドルウェアを使用しなければならないとか、仕事を完了するためにどのデータベースフィールドを更新するかについて語っているでしょうか?たとえアクター の目標の説明が与えられていても、それらの目標は、そもそもそれらのプロセスを不要にするシステムを構築できる現在の現状のプロセスを単に再記述しているだけでしょうか?
それは依存性逆転のことですよね?
2004年、Martin Fowlerは依存性注入(DI)と制御の反転(IoC)に関する記事を発表しました 。DIPはDIやIoCと同じでしょうか?いいえ、しかしそれらはうまく連携します。Robert Martinが最初にDIPについて議論したとき、彼はそれをオープン・クローズドの原則 とリスコフの置換原則 の一級の組み合わせであると見なし、独自の名称を付けるのに十分なほど重要だとしました。以下は、いくつかの例を使用して、3つの用語すべてを要約したものです。
依存性注入
依存性注入とは、あるオブジェクトが別の依存オブジェクトについてどのように知っているかということです。例えば、モノポリーでは、プレイヤーは一組のサイコロを振ります。ソフトウェアプレイヤーが、ソフトウェアの一組のサイコロにroll()メッセージを送信する必要があると想像してみてください。プレイヤーオブジェクトはどのようにサイコロオブジェクトへの参照を取得するのでしょうか?ゲームがプレイヤーにtakeATurn(:Dice)を指示し、サイコロを渡すと想像してみてください。ゲームがプレイヤーにターンを指示し、サイコロを渡すことは、メソッドレベルの依存性注入の一例です。Playerクラスが代わりにDiceの必要性を表現し、Springのような、いわゆるIoCコンテナのようなものによって自動的に配線されるシステムを想像してください。この最近の例は、2013年第1四半期現在、私が作業しているシステムにあります。それはSpringプロファイルの使用に関係しています。デモ、テスト、qa、prodの4つの名前付きプロファイルがあります。デフォルトのプロファイルはデモで、10個のシミュレートされたデバイスと特定のテストポイントが有効になった状態でシステムを起動します。テストプロファイルは、シミュレートされたデバイスなしで、テストポイントが有効になった状態でシステムを起動します。qaとprodはどちらも、システムが携帯電話ネットワーク経由で実際のデバイスに接続するようにシステムを起動し、テストポイントはロードされないため、本番コンポーネントがテストポイントを使用しようとすると、システムは起動に失敗します。もう1つの例は、JavaとC++を混在させるアプリケーションから来ています。システムがJVM経由で起動された場合、C++レイヤーをシミュレートするように構成されます。代わりにC++経由で起動された場合(次にJVMを起動します)、システムはC++レイヤーにヒットするように構成されます。これらはすべて依存性注入の一種です。
制御の反転
制御の反転とは、誰がメッセージを開始するかということです。あなたのコードがフレームワークを呼び出すのか、それともフレームワークに何かをプラグインして、その後フレームワークがコールバックするのでしょうか?これは、ハリウッドの法則 とも呼ばれます。「私に電話しないで、私があなたに電話する」ということです。例えば、SwingのButtonListenerを作成するとき、インターフェースの実装を提供します。ボタンが押されると、Swingはそれに気づき、提供したコードをコールバックします。モノポリーシステムが多数のプレイヤーで作成されたと想像してみてください。ゲームはプレイヤー間のやり取りを調整します。プレイヤーがターンを取る時間になると、ゲームはプレイヤーに、家やホテルを売るなどの移動前の行動があるかどうかを尋ねるかもしれません。その後、ゲームはサイコロの出目に基づいてプレイヤーを移動させます(現実の世界では、物理的なプレイヤーがサイコロを振って自分のトークンを移動させますが、それはボードゲームがコンピューターではないことのアーティファクトです。つまり、それは何が起こっているかの存在論的な説明ではなく、現象学的な説明です)。ゲームはプレイヤーがいつ意思決定できるかを知っており、プレイヤーが意思決定をするのではなく、それに応じてプレイヤーに促すことに注目してください。最後の例として、SpringメッセージBeanまたはJEEメッセージBeanは、コンテナに登録されたインターフェースの実装です。メッセージがキューに到着すると、コンテナはBeanを呼び出してメッセージを処理します。コンテナは、Beanの応答に基づいてメッセージを削除するかどうかも決定します。
依存性逆転の原則
依存性逆転とは、コードが依存するオブジェクトの形状に関するものです。DIPはIoCおよびDIとどのように関連するのでしょうか?DIを使用して抽象度の低い依存性を注入した場合に何が起こるかを考えてみましょう。例えば、モノポリーゲームにJDBC接続を注入して、DB2からモノポリーボードを読み取るためにSQLステートメントを使用できるようにすることができます。これはDIの例ですが、私の問題のドメインよりも著しく低い抽象レベルで存在する依存性を注入する(おそらく)問題のある例です。モノポリーの場合、SQLデータベースが存在する数十年前から作成されていたため、SQLデータベースに結合すると、不必要で偶発的な依存関係が導入されます。モノポリーに注入する方が良いのは、ボードリポジトリです。そのようなリポジトリのインターフェースは、SQL接続の観点から記述されるのではなく、モノポリーのドメインに適しています。IoCは誰が呼び出しシーケンスを開始するかに関わるため、設計が不十分なコールバックインターフェースは、フレームワークにプラグインするために記述するコードに低レベルの詳細(フレームワーク)の詳細を強制する可能性があります。その場合は、コールバックメソッドからビジネス関連のものをほとんど除外し、代わりにPOJOに配置するようにしてください。
DIは、あるオブジェクトがどのように依存性を取得するかということです。依存性が外部から提供される場合、システムはDIを使用しています。IoCは、誰が呼び出しを開始するかということです。あなたのコードが呼び出しを開始する場合、それはIoCではなく、コンテナ/システム/ライブラリがあなたが提供したコードをコールバックする場合、それはIoCです。
一方、DIPは、コードから呼び出しているものに送信されるメッセージの抽象レベルに関するものです。確かに、DIPでDIまたはIoCを使用すると、より表現力豊かで強力になり、ドメインに適合する傾向がありますが、それらは全体的な問題における異なる次元、つまり力に関するものです。DIは配線に関し、IoCは方向に関し、DIPは形状に関わります。
今後の展開は?
依存性逆転の原則の定義を理解したら、DIPの実例に移りましょう。以下は、すべて共通のスレッドを共有するいくつかの例です。システムのニーズによって制限される範囲で、依存性の抽象レベルをドメインにより近づけることです。
柔軟性にはコストがかかる
私がよくやってきたことであり、見てきたことは、現在の問題を解決するために必要なメソッドよりも多くのメソッドを追加して、クラスを「使いやすく」することです。「念のため」という考え方から生じているのかもしれません。おそらく、変更が困難なコードベースにつながる過去の実践から来ているのでしょう。つまり、今入れることは、後で必要な場合に追加するよりも簡単だと認識されています。残念ながら、メソッドが多いほど、不正確なコードを作成する可能性が高くなり、検証が必要な実行パスが増え、「使いやすい」インターフェースを使用する際の規律が必要になります。クラスの表面積が大きいほど、そのクラスを正しく使用することが難しくなる可能性が高くなります。実際、表面積が大きいほど、クラスを正しく使用するよりも、誤って使用する方が簡単になる可能性が高くなります。
どのハンマーを使うべきか?
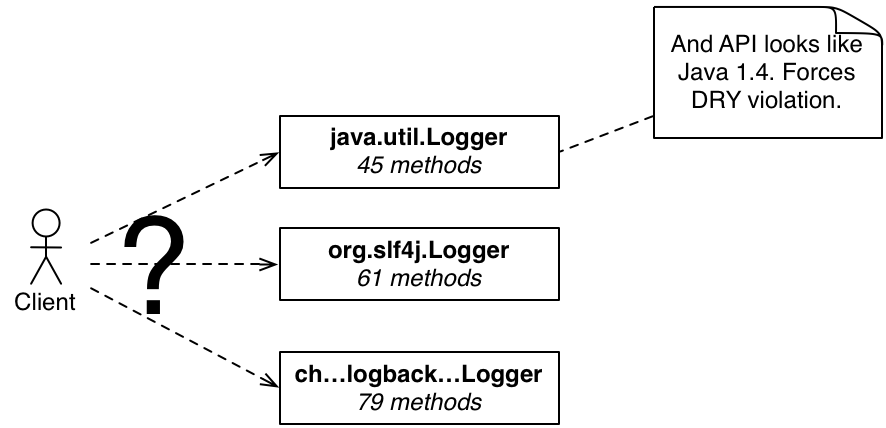
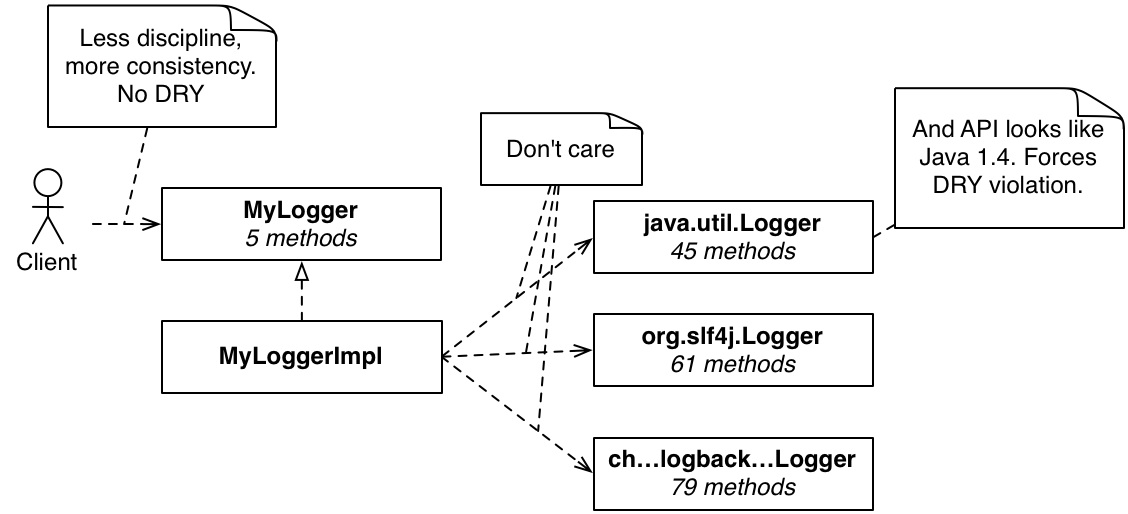
ロギングを考えてみましょう。ロギングは必ずしもDevOpsを実行するための最良の方法ではありませんが、物事を行うための広く実践されている方法であるようです。私が最近取り組んだいくつかのプロジェクトでは、ロギングが最終的に問題になりました。問題は様々でした
多すぎる
足りない
何かをログに記録すべきレベルに関する意見の不一致
どのロギングメソッドを使用するかに関する意見の不一致
どのロギングフレームワークを使用するかに関する意見の不一致
Loggerクラスの不整合な使用
プロジェクトで使用されているすべてのオープンソースプロジェクトで使用されている、様々なオープンソースロギングライブラリ全体でのロギングの不正確/不整合な構成
使用中の異なるオープンソースプロジェクトで使用される複数のロギングフレームワーク
ログの使用を困難にする、一貫性のないロギングメッセージ
ここであなたの特定の経験を挿入してください...
これは包括的なリストではありませんが、中規模のプロジェクトに携わっていて、これらのトピックの一部について議論したことがないとは思いません。
与えられたものをそのまま受け入れない
ここまでの例では、システムの一部を解決するために使用される抽象化レイヤーのレベルについて説明してきました。次の例も同様ですが、実際には異なる見方をされているようです。要件として隠された解決策が与えられた場合はどうなるでしょうか?
提供された解決策
次の部分では、私が参加していたチームに与えられたものから始めます。
もう少し詳しく説明します。
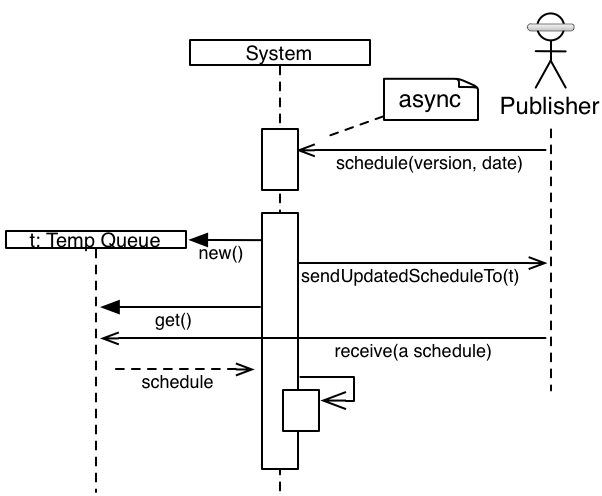
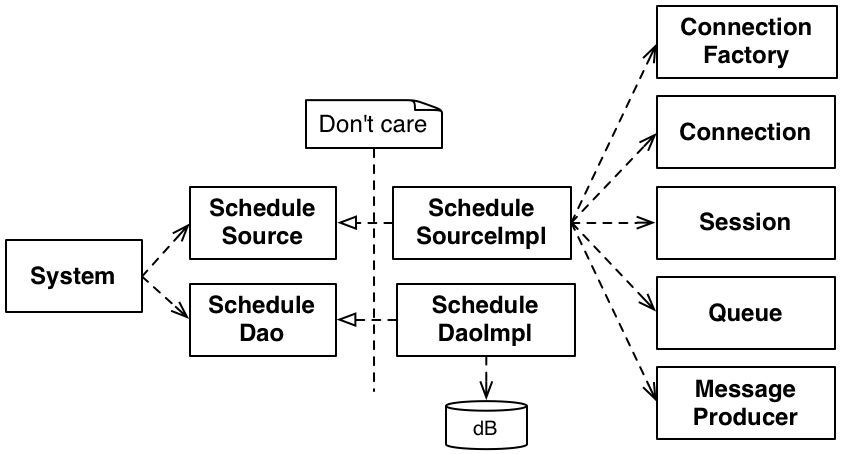
外部システムが、非同期のパブリッシュ/サブスクライブキューを使用して、スケジュールが更新されたという事実をブロードキャストします。
その後、ある時点で、私たちのシステムはその通知を受け取り、それに基づいて行動するかどうかを決定する必要があります。たとえば、特定のスケジュールが複数回送信される可能性があるため、すでにそのスケジュールを持っている可能性があります。この特定の例では、システムはスケジュールに関心があるため、スケジュールを要求します。
システムは一時キューを作成します。これは、システムがパブリッシャーに完全なスケジュールを送信するように要求する場所です。システムは、元のパブリッシャーに非同期メッセージを送信します(実際には、同じプロセス空間で処理される別のキューに送信します)。
システムは、スケジュールが配信されるのを一時キューで待機します。永遠にブロックするわけではありません。実際には、システムがこのプロセス全体の中でシャットダウンすると判断した場合に備えて、時々ウェイクアップします。また、プロパティ駆動の分数で設定された時間が経過すると諦めます。
最終的に(ハッピーパス)、スケジュールが到着し、システムはスケジュールを受け取ります。いくつかの処理を行い、その後、システムはスケジュールを永続化します。
どうやってそれに取り組んだのか?
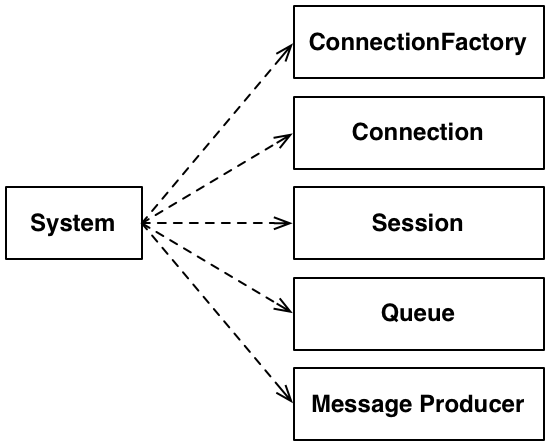
チームがこれに取り組んでいたとき、私たちは共有のペアリングステーションとオープンな環境を持っていました。問題に取り組んでいるペアの会話を聞き、彼らがJMXに直接依存しているのか、DIP(言い換えたものですが、実話です)に従っているのか尋ねました。彼らは問題解決に真っ先に取り掛かり、与えられたものをすべて本質的なものとして捉えていました。そして、これが彼らがやっていたことです。
これは、簡単で、典型的で、よくある対応です。詳細が多いため、何が実際にあるのかを見分けるのが難しい場合があります。この問題において、非同期のインタラクションは本質的なものですか、それとも付随的なものですか?この特定のケースでは、メカニズム全体が私たちに押し付けられた設計上の決定でした。私たちはそれに従う必要がありましたが(それは合理的なアプローチです)、その設計を私たちの設計の消えない一部にする必要はありませんでした。ほとんどの場合、それは同様だと思います。少し弱いガイドラインは、そうでないと示されない限り、付随的なものと仮定することです。
非同期のようなものが本質的であるケースはありますか?はい。ワークアイテムに1つ以上のハンドオフがあるワークフローを想像してください。つまり、私がそれを終えたら、あなたがそれを受け継ぎます。私は自分の作業を行い、その後終了します。私が責任を負う最後のステップは完了しましたが、特定のアイテムのワークフロー全体は完了していません。概念的には、この種のフロー用に私が設計するインターフェースは、すべての作業が1人の人間によって1回で行われるインターフェースとは同じようには見えないでしょう。ただし、設計の原動力は、ドメインに大きく影響される必要があります。
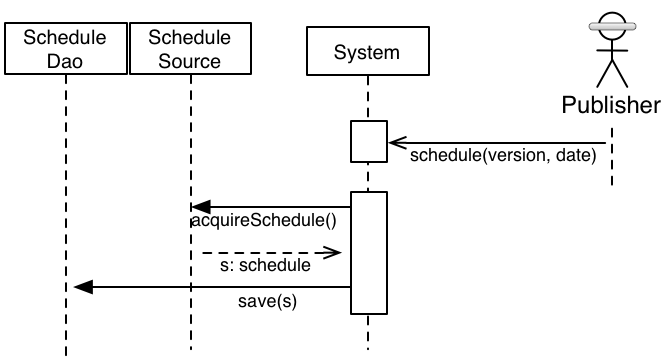
この特定の状況では、生の形式でスケジュールを取得し、XMLからスケジュールに変換し、それを永続化するという、3つの主要なことを行う必要がありました。2番目と3番目のステップはしばらく前にすでに記述されていたため、この作業が開始されたとき、取得を処理する必要がありました。私たちのシステムが実際に元の生の表現を必要とするケースはなかったので、取得の結果がスケジュールになる方が、システム内の他の場所でXML表現を見るよりも優れていました。
これを簡単に想像すると次のようになります。
さまざまなJMSインターフェースへの依存関係がなくなったわけではないことに注意してください。それは、もう一段階の間接層の背後に移動しただけです。私たちのシステムレベルの視点は、スケジュールを取得できるものがあるということでした。それが正確にどのように行われるかは、特定の実装に任されました。実際、私たちは当初、Active MQを使用して初期探索中に単純なフェイク を作成しました。後で、Mockito を使用して、テストごとのスタブ も作成しました。
結果として得られた高レベルのインタラクションは、少しだけ理解しやすくなりました。
これらすべてが、多くの理由で重要になりました。
Tibcoへのアクセスには時間がかかりましたが、早い段階で具体的な例がありました。
生の形式からスケジュールへの変換には、追加の作業が必要でしたが、私たちは待つことなくそれを行うことができました。
Spring 3.xの内部動作をいくつか学ぶ必要がありましたが、ActiveMQでこれを行うことで、Tibcoへのアクセスを待っている間に、おそらく90%を達成しました。
私たちはTibcoを制御できませんでした。それは別のグループの責任であり(そして、政治的に変わるものではありませんでした)-これはDIPがあなたの味方になるという大きな兆候です。
私たちは継続的インテグレーション を実践していました。これは、1日に60回以上、頻繁にテストを実行することを意味します。最大5組のペア、複数のチェックイン、チェックイン前の複数の開発者実行、その後、各チェックインのビルドボックス、パフォーマンステストなどです。
テストキューは共有されていました。
テストキューは、他のテストによってバッファが満たされているため、利用できないことがよくありました。
テストキューには、すべてのメッセージを飲み込んでしまう可能性のあるコンシューマーがいて、私たちの制御が及ばない何かが原因でテストが失敗する可能性があります。
どれほどひどかったのか?
これらのリスクすべてにより、Tibco固有の問題に直接関連しないロジックの大部分を検証できるようになることが不可欠になりました。実際、JMSを操作するロジックは、TibcoとActiveMQの違いを、コードの問題ではなく、厳密に構成の問題にしました。ActiveMQを使用したときは、インプロセスキューを指しました。Tibcoを使用したときは、QAキューを使用するか、本番キューを使用するかによって、多数のキューの1つを指しました。(ActiveMQの方が少し寛容でしたが)多少の違いはありましたが、両方のライブラリを処理する1つのパスをなんとか作成しました。
これが重々しく聞こえるかもしれませんが、そうではありませんでした。実際の設計は簡単です。設計について考えることは、数日間の努力ではなく、数分の作業でした。設計の実装にはかなりの時間がかかりましたが、そのほとんどは、私たちの多くがJMSに慣れていなかったため、発見のためでした(私はいつもそれに慣れていません。Googleを頼りに生きています。)
真の勝利は、QAと本番環境の複製でこれが機能してから数か月後に訪れました。ある時点で、私たちのシステムはQAで動作しなくなりましたが、複製された本番環境を含む他のすべての環境では動作しました。すぐに、キューの構成が異なるのではないかと推測しました。私たちは尋ねましたが、キューの構成は同じであると確信しました。テストがあったため、誰かと協力して、誰かがキューを見ている間にテストを実行することができました。私たちはデューデリジェンスを行い、それが私たちではないと確信していましたが、1つのTibcoインスタンスと別のインスタンスの使用に関連する識別可能な変数だけを考慮すると、できる限り確信していると言いました。約1週間半後、彼らはQAキューが異なるように構成されていることを発見しました。このすべてが行われている間、私たちのチームは、この問題全体のパーツの作業を妨げられませんでした。
結論
実装するソリューションが与えられたり、既存の外部環境の考慮事項によってソリューションが制約されたりすることはよくあります。これらの与えられた制約の具体性に対処するためにコードを記述しますが、それらの詳細がシステムの他の部分全体に拡散するべきではありません。実装を1か所に隠し、ドメインの目標の観点から記述されたインターフェースを与えます。詳細を隠します。
昏睡状態だったのですが、いつのことですか?
日付や時間を気にするシステムで作業したことはありますか?現在の日付にどのようにアクセスしましたか?時間の経過をどのように処理しましたか?ほとんどのシステムは時間を気にします。Javaでは、現在の日付や時刻を取得する方法はたくさんありますが、それらはすべて実行中のシステムの時刻を使用する傾向があります。
あなたのスケジュールはここにあります
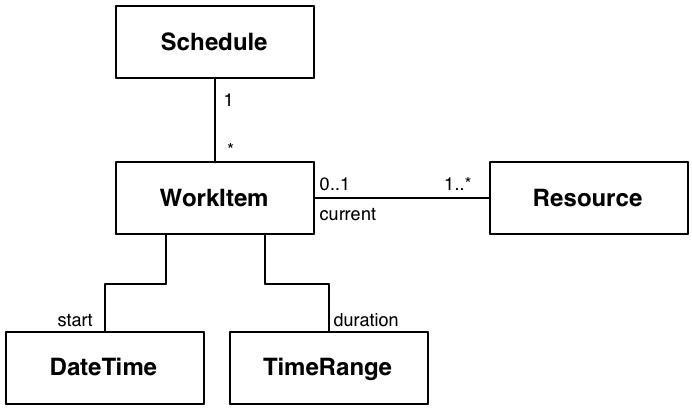
いくつかのワークアイテムを持つシステムを想像してください。各ワークアイテムはいくつかのリソースを使用します。各アイテムは、スケジュールされているか、実行中であるか、または実行が終了しています。2つのワークアイテムが同じリソースを使用しようとすると、競合が発生し、システムが競合を正しく処理するようにする必要があります。システムが競合を適切に管理していることをどのように検証しますか?
図14:ワークアイテムを処理する必要がある
ドメイン分解
この説明には、いくつかの重要な概念があります。ワークアイテム、競合、時間です。
ワークアイテムは比較的単純で、名前、説明、開始日時、期間、1つ以上のリソースがあります。
競合の処理は興味深い問題のように聞こえ、競合を処理する方法はたくさんあるかもしれません。最初は先着順になるかもしれませんが、後で最も価値のあるものを優先するようなものになるかもしれません。いずれにしても、競合解決のアイデアを取り上げ、システムで最優先のものに昇格させる必要があります。
ここまでは順調です。時間についてはどうですか?
時間は興味深い概念です。ほとんどの場合、私たちは時間を当たり前のものと見なしており、考えてもいません。何もしなければ、システムはおそらく時間を持つでしょう。時間は壁の時計のように経過するでしょう。それは常にそこにあり、変化の速度はあまり変化しないようです。しかし、現実とは異なるペースで動かしたい場合はどうでしょうか。日付を実際の日付とは異なるように表示させたらどうでしょうか。時間のセクション全体をスキップするのはどうでしょうか。時間についての重要な点は、ユーザーの介入なしに変化することですが、時間を所有したい場合はどうでしょうか?それは一体何を意味するのでしょうか?
異なるペースで移動する
秒、分、日の時間枠で何かが起こる時間依存システムがあります。時間の経過に伴うシステムを見たいのですが、毎時トップに発生する何かが発生するのを1時間待つ必要はありません。
現在の日付とは異なる日付
日付固有の実際の本番データを使用して、テストベッドでシステムを実行しています。現在、日付は未来にありますが、明日、昨日の1週間前、または来年の場合に何が起こるかを確認したいと考えています。本番データのコピーを変更するか、システムに実際の日付とは異なる日付であると思わせることができます。
時間のセクション全体をスキップする
あなたのシステムでは、物事は離散的な時間で発生します。あなたは、適切なことが適切な時間に起こるようにしたいと考えています。これらのことを、システムを実行することを選択した時間に基づいて設定することもできますし、単に時間を設定して何が起こるかを確認することもできます。
タイムロードを訓練する方法
時間は他のビジネス概念と同じようなものですか?少し敬意を払うに値する第一級市民として扱うべきでしょうか?それはどのようなものになるでしょうか?それは何を提供するでしょうか?スケジューリングの例を見てみましょう。
スケジューリングの例
機能: スケジューリングの競合の処理
オペレーターとして、機能の競合が適切なポリシーによって管理されるようにしたい。
背景
前提: かつ かつ かつ かつ
シナリオ: 何も起こっていない
ならば
シナリオ: 1つのアイテムがアクティブ
ならば
シナリオ:
ならば かつ
シナリオ:
ならば かつ
シナリオ:
ならば
このスケジューリングの例は、私が取り組んだいくつかの実際のシステムに基づいて、この記事のために書き直された仮想的なシステムの説明です。これらの例は、Gherkin と呼ばれる言語で書かれており、Cucumber というツールで使用されています。この特定のドメイン固有言語 (DDDおよびBDDコミュニティがユビキタス言語 と呼ぶもの)を使用して、スケジューリングシステムの動作に関するいくつかの期待/事実/例を表現しました。
この一連の例は、明確に定義された開始点といくつかのフォローアップアクティビティが与えられた場合に、システムで何が起こるべきかを説明しようとしています。たとえば、「何も起こっていない」の例によると、9:59には何もアクティブであるべきではありません。その後、10:01には、いずれかのWorkItemがアクティブになるはずです。最初の競合は10:10に発生します。このとき、WorkItem Megatron_Torsoはまだ実行中で、Megatron_Headは共有リソース3d_printer_1の利用を待つ必要があります。
この種のシステム検証は一般的ですが、このアプローチはそれほど一般的ではありません。このドメインでは、時間が重要です。ほとんどの時間はシステムにとって重要ではなく、ワークスケジュールに基づく特定の時間のみが重要です。
どの時間が重要ですか?この例では、10:00に開始し、15分間続くワークアイテムが1つ、10:10に開始し、5分間続くワークアイテムがもう1つあると明示的に記述しています。 境界値分析 のようなものを使用してテストを検証するために、重要な時間の周囲の時間を選択します。
私がより典型的だと考えているのは、互いに近い時間を選択して、何かが起こるのを待つことです。たとえば、15分の代わりに15秒を使用します。この種のテスト設定は一般的ですが、システムが重要なドメイン概念である「時間」の所有権を取得していないことを示しています。
それを実現する例
Joda Timeを使用することを選択した場合、この種のことは簡単です。Joda Timeによって生成される時間を変更する簡単なJavaクラスを次に示します。
@Component
public class BusinessDateTimeAdjuster {
public void resetToSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = new MutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
DateTime result = dateTime.toDateTime();
return result;
}
}
さて、And the business time is 9:59のような式は、Cucumber-jvm を使用してこの例で実行しますが、次のメソッドを実行します。
public class ScheduleSteps {
@Given("^the business time is " + TIME + "$")
public void the_business_time_is(int hour, int minute) {
setTimeTo(hour, minute);
}
private void setTimeTo(int hour, int minute) {
BusinessDateTimeFactory.setTimeTo(hour, minute);
scheduleSystemExample.recalculate();
}
}
public class BusinessDateTimeFactory {
public static DateTime now() {
return new DateTime();
}
public static void restoreSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public static DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = now().toMutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
return dateTime.toDateTime();
}
public static void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
}
このコードは、時間を固定点に設定します。 Cucumber-jvmライブラリでは、テストの前後で実行するためのフックを使用できます。この場合、テスト後のフックは時間をシステム時間に戻します。
実際には、ビジネス時間のようなドメイン概念を導入するという考えは、多くの作業のように聞こえるかもしれませんが、実際にはそうではありません。私はプロジェクトの後半で、成熟したプロジェクトでもこの種のことを行ったことがありますが、この種の考え方を導入することは、システムのテストの観点から見て、節約できる時間ほど時間はかかりません。1つのデータポイントとして、単純な日付ファクトリの導入には数時間かかる可能性があります(日付は厄介な傾向があるため、テストします)。new Date()やそれに相当するコードが発生するすべての場所を見つけるには、正規表現と再帰的検索を使用します。前回これを行ったとき、コード内の410か所を修正するのに約2時間かかりました。したがって、成熟したシステムでは、半日程度です。Joda Timeを使用している場合は、new DateTime()を呼び出すコード内の場所を修正する必要さえありません。Joda Timeはそれを簡単にしますが、JavaのCalendarでもこれを行ってきました。この考え方は大きく聞こえますが、実際に導入して実装するための作業よりも、はるかに広範囲にわたります。
結論
私たちは多くのことを固定されたものとして受け入れています。さらに悪いことに、私たちはそれらについて考えることに慣れているため、重要な概念にさえ気づきません。私がこの考えにどこで出会ったのかは覚えていません。それは、数年前のプロジェクトからの観察だったと思います。ローカルデータベースで本番データのコピーを使用していました。本番データには日付付きのルールがありました。日付が将来にならなくなることがあり、異なる日付(別の問題)を含む本番データの新しいカットを取得することもよくありました。時間の経過後も日付を「修正」し続けましたが、この手動で反復的でエラーが発生しやすいアクティビティが時間の完全な浪費であることがついにわかりました。日付を変更していたので、明らかに日付を制御する必要がありました。私がこれを最初に試したときは、半日よりも少し時間がかかりました。それ以来、私はそれを少なくとも5つの異なる本番プロジェクトで5回行っており、今では早い段階で行うようになったため、ほとんど時間がかかりません。私と数人のQA担当者は、この種の機能が便利で、大幅な時間短縮になることを発見しました。
ただし、この例が示すのは、私たちのコードが時間という一見現実的なものに依存する必要はないということです。より一般的な考え方は次のとおりです。何かが問題を引き起こしている場合は、それを制御します。この場合、制御はライブラリによって簡単にサポートされることが判明しましたが、最終的なコード例を見ると、日付と時間の概念をキャプチャした単一の場所であるBusinessDateTimeFactoryを導入し、それに依存しています。
これで終わりです
DIPのいくつかの例を実例で見てきました。
メソッドが多すぎる扱いにくいAPIを使いやすくすること。
ライブラリの抽象化レベルとドメインの間の不一致を解消すること
特定のコミュニケーションスタイルを指示する外部制約を拒否すること
時間自体を制御すること
DIPの適用例が明確なものもあれば、他の設計原則に適合するように見えるものもあります。結局のところ、どちらの原則が状況により当てはまるかは関係ありません。ダニエル・ターホスト=ノースは、すべてのソフトウェアは負債である と主張して、この考えをうまく捉えています。開発者として、私の目標はコードを書くことのように思えます。しかし、それは歯列矯正医に矯正が必要かどうかを尋ねるようなものです。答えははい、ありがとう、私のボートの頭金をもう一度支払う必要があります、ということです。
私はコードを書いたり、新しいプログラミング言語を学んだり、そういったことをすべて楽しんでいます。しかし、問題を解決するために作業している場合は、ソフトウェアは通常、目的そのものではなく、目的を達成するための手段であることを覚えておくことが重要です。これは、アジャイルプラクティスだけでなく、設計原則にも当てはまります。理にかなっているのは、作業のポイントを覚えて、コンテキストが何を理にかなっているかを指示することです。特定の問題に対する解決策を構築する方法を探している場合は、DIPを知っておくと便利です。
より一般的には、特定のビジネス問題をより早く解決するのに役立つ原則とプラクティスは、そのコンテキストに適しています。それらは他のコンテキストでは機能しない可能性があります。私は、多くの場合、複数の報告構造によって行われた作業に依存する、長期間にわたるシステムで作業する傾向があります。これは、問題のある依存関係を特定し、DIPのような設計原則を使用してそれらを制御することが、私にとって繰り返し発生するテーマであることを意味します。これらのアイデアのいずれも、特定の問題にとってひどいものになる可能性があります。
もしあなたがソフトウェアの半減期 が短いものに取り組んでいる場合は、そのコンテキストに最適なのは、それらの依存関係に直接依存することでしょう。また、ロバート・マーティンが定義するようにTDD を実践している場合(単に自動テストを作成することは、TDDとはほとんど関係ありません)、おそらく必要に応じて包括的な変更を行うことができる立場にあるでしょう。この場合、DIPは初期設計ではなく、リファクタリングを知らせます。
依存関係を特定し、それらを明示的に処理する価値があるかどうか、また、処理する場合はどこで処理するかを決定するプラクティスは、練習する価値のあるスキルです。これらの特定の例を試すこと、作業をするときに探すべきもののガイドライン、または依存関係を制御するためにできる具体的なこととして捉えることができます。これらの例やDIPそのものが、役立つか害になるかは、解決しようとしている問題によって左右されます。