
REST を用いたエンタープライズ統合
社内REST API の多くは、単一の統合ポイントのために構築された使い捨てAPI です。この記事では、非公開API における制約と柔軟性、そして複数のチームにまたがる大規模なRESTful 統合から得られた教訓について説明します。
2013年11月18日

ブランドン・バイアーズは、Thoughtworks のテクノロジスト兼プリンシパルコンサルタントです。大規模なエンゲージメントにおいてチームをリードした経験があり、システム思考をソフトウェア開発に適用することに関心を持っています。
エンタープライズ統合に REST を用いる理由
レガシーシステムの置き換えは困難です。実際、大規模なレガシーシステムの置き換えは、IT業界全体で最も難しい仕事だと断言できます。私たちの大半は、企業が何十年も依存し続けるソフトウェアを書くことはありませんが、そのようなソフトウェアは大規模なレガシーシステムの置き換えにおいて一般的であり、その作成者は称賛されるべきです。それにもかかわらず、そのようなソフトウェアは、私たちがデザイン、テスト、そして優れた運用方法について学んだことの多くに先行しており、そのため理解し変更することが非常に困難になる可能性があります。
私たちはしばしば、そのような置き換えにあたり、新しいシステムが持つであろう完璧なアーキテクチャを想像し、その取り組みの困難さを大幅に見積もり不足しがちです。非常に複雑で、カスタムビルドされ、変更が困難なレガシーシステムを背景に見てみると、特定のパターンが現れます。まず、社内開発の努力を統合に削減することを目標にベンダーパッケージを購入し、外部サポートのない特注システムに依存することを二度としないと誓います。次に、個々の部品の交換可能性を組み込み、避けられない将来のレガシーシステムの置き換えプロジェクトの痛みを軽減することを目標に、サービス指向アーキテクチャを採用します。
Thoughtworks は、いくつかの大規模なレガシーシステムの置き換えプロジェクトに関わってきましたが、常に公に話すことができるとは限りません。HTTP 上の REST は、そのような多くのプロジェクトにとって魅力的な選択肢であり、私たちが一般的に推奨するものです。使いやすく理解しやすく、開始するために重いフレームワークやツールチェーンは必要ありません。テストに適しており、運用上の懸念事項の多くをWebサイトの管理に使用されるものと同じ慣行に削減します。アーキテクチャ的には、REST はスケーラビリティが証明されており、ドメインモデリングにもうまく適合します。
REST に関する多くのオンライン議論は、コンテンツタイプやハイパーメディア・アズ・ザ・エンジン・オブ・アプリケーションステート (HATEOAS) についての詳細に踏み込んでいますが、大規模な統合プロジェクトで REST を機能させるために必要なエンジニアリングと管理の慣行に関するアドバイスは省かれています。私の仮説は、そのようなプロジェクトにおける成功は、HATEOAS のニュアンスを理解することよりも、デプロイメント戦略やテスト戦略などの側面を理解することの方がはるかに重要であるということです。以下は、大規模なRESTful統合を行う中で学んだ教訓です。
ニーズごとに論理環境を定義する
多くの大きなIT組織は、メインフレームや大規模なベンダーからのインストールから高価な環境を受け継ぎ、サービスを事前に定義された柔軟性のない環境のリストに無理やり押し込もうとしています。残念ながら、すべての開発者が使用するエンタープライズ全体の環境セットを管理すると、RESTful サービスの主な利点の1つである軽量な環境が失われます。サービスは、かなりの処理能力を必要とするアプリケーションの前にファサードになる可能性がありますが、サービス自体はデプロイとホストが簡単で、ブラウザとコマンドラインでテストできます。さらに、ATOMのようなイベントフィードを使用するなどの手法により、新しい環境を立ち上げる際の広範なミドルウェアインフラストラクチャの必要性を回避できます。重要な洞察は、論理環境の概念を理解することです。
論理環境とは、ビジネスまたは開発のニーズを満たすために必要な、相互に関連するアプリケーション、サービス、およびインフラストラクチャコンポーネントの適切に隔離されたセットです。
開発ニーズを満たすために必要なコンポーネントは、ビジネスニーズを満たすために必要なコンポーネントとは、さまざまなチームや役割にとってかなり異なる可能性があります。大企業の開発者のほとんどは、隔離されたフルスタック環境を実行することを期待しておらず、隔離は開発者を生産的にするための必要な範囲までしか行われるべきではありません。たとえば、小売プロジェクトでは、受注チームの開発者は、製品カタログと顧客管理のサービスを必要とするかもしれませんが、倉庫管理のサービスは必要ないかもしれません。本番環境では、それらのそれぞれに負荷分散されたクラスタがそれらをサポートしていますが、開発者とQAは、パフォーマンスと可用性よりも隔離を重視します。極端な例として、異なる開発者が同じVM上に異なる論理環境を持つ場合があります。この場合、隔離は、ポートとデータベース名を環境構成の一部にすることで実現できます。

図1:環境の隔離は、環境をホストするハードウェアとは独立しています
共有環境のもう1つの問題は、全員が同時にアップグレードされることです。これは、開発の混沌とした世界ではしばしば適切ではありません。はるかに良いのは、リリーススケジュールをそれに影響を受ける個人に委ねることであり、これは本番リリースの場合と同様に、サンドボックス環境で依存するサービスをアップグレードする開発者の場合にも当てはまります。これは、QAにとって特に重要であり、QAは論理環境内のリリースケイデンスを管理する必要がある役割です。テストには、関連するサービスの既知で安定したバージョンセットが必要であり、バージョンが既知であれば、開発者はバグの修正がはるかに容易になります。
ある大規模なエンゲージメントでは、Yamlを使用して環境の宣言的な記述を定義しました。最上位のキーは環境名を定義し、サブキーはその環境に必要なサービスを定義し、次のレベルのキーはサービスごとに環境固有の構成を定義します。
order-entry-dev:
product:
webservers: [localhost]
port: 8080
logPath: /var/log/product
dbserver: localhost
dbname: product
customer:
webservers: [localhost]
port: 9080
logPath: /var/log/customer
dbserver: localhost
dbname: customer
デプロイメントの自動化への徹底的な注意とインフラストラクチャへの適切な投資により、あるサービスが50を超える論理環境に存在するという、メインフレームに慣れている企業にとっては信じられないほどの数が実現しました。Ansible などのツールは、大きな初期投資なしで環境を宣言的に記述するのに役立ちます。開発者が使用するような軽量なアドホック環境を可能にするために、サーバー名としてlocalhostを持つ単一の環境を定義することが役立つことがよくあります。これは、Vagrant などを使用してローカル仮想マシンで起動できます。これにより、同じ環境構成と異なるVMを使用することで、環境の弾力性を実現できます。
パッケージはどうすれば良いか?
ベンダーパッケージは、簡単にデプロイでき、環境の弾力性があるように構築されていないことが多いため、環境の作成を複雑にします。それらの多くは、アップグレードごとに変更されるインストールドキュメントと、複数の環境で変更を確実に再現するメカニズムがない状態で出荷されます。ライセンスも障害になりますが、ほとんどのベンダーは低コストの開発ライセンスを許可します。
デプロイが困難なベンダーパッケージに悩まされている場合、いくつかの修正戦略があります。パッケージにインストール中に複雑なライセンスが不要な場合は、インストールとアップグレードを自動化するベンダーの作業を実行できる場合があります。あるいは、複製可能なVMを設定することもできます。これにより弾力性が得られますが、アップグレードが複雑になります。基本的に、これは構成管理の議論におけるベイク対フライの違いです。
どちらのオプションも利用できない場合、ある程度の隔離を実現する他の方法がありますが、実際の環境の隔離に匹敵するものは何もありません。アプリケーション内の自然なデータ境界を使用して、ある程度の開発者の隔離を可能にする方法があるかもしれません。異なるユーザーアカウントは簡単なデータ境界になりがちですが、ユーザーはグローバル状態を共有する傾向があります。さらに良いのは、マルチテナントアプリケーションはテナント間のトラフィックを防ぐように設計されているため、個々の開発者に異なるテナントを提供することです。このアプローチは明らかに回避策であり、スケーリング上の課題があり、リリーススケジュールの独立性を提供しません。
デプロイの容易さと環境管理は、パッケージを選択する際の基準の1つである必要があります。
もちろん、最善の解決策は、ベンダーの選定プロセス中にそのような運用上の考慮事項を精査することです。デプロイの容易さと環境管理は、パッケージを選択する際の基準の1つである必要があります。選定プロセスでは、機能セットと目的への適合性だけでなく、統合の容易さと統合開発者の生産性も考慮する必要があります。
バージョン管理は最終手段としてのみ使用する
論理環境の定義の重要な系は、凝集性の概念です。各環境には、特定のサービスのインスタンスが1つだけ存在する必要があります。残念ながら、各チームが異なるペースで動く大規模なプロジェクトでは、コンパイル時の依存関係に通常関連付けられている古典的なダイヤモンド依存関係の問題に遭遇することがよくあります。
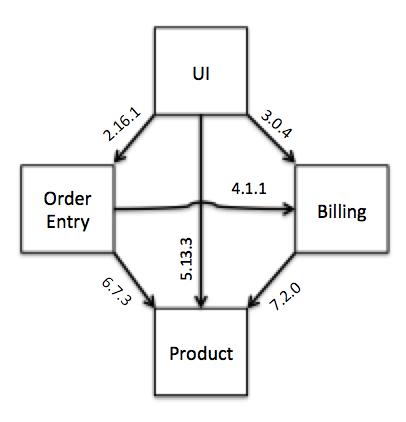
図2:互換性のないバージョン要件
私の経験では、RESTfulアーキテクトが最初に求めるソリューションの1つはバージョン管理です。私はより物議を醸す見解を持っています。Jamie Zawinski の有名な発言を借りるなら
ある人々は、問題に直面すると「バージョン管理を使えばいい」と考えます。すると、彼らは2.1.0個の問題を抱えることになります。
問題は、バージョン管理がシステムの理解、テスト、トラブルシューティングを大幅に複雑にする可能性があることです。複数のコンシューマによって使用される同じサービスの複数の互換性のないバージョンが存在するとすぐに、開発者はサポートされているすべてのバージョンでバグ修正を維持する必要があります。単一のコードベースで保守されている場合、開発者は、共有コードパスのためだけに、新しいバージョンに新しい機能を追加することで、古いバージョンを壊すリスクがあります。バージョンが独立してデプロイされている場合、運用上のフットプリントは監視とサポートがより複雑になります。この余分な複雑さは見過ごされるか、相互依存するサービスのリリースプロセスを簡素化することで正当化されます。しかし、リリースの複雑さは、コンシューマベーステスト(次のセクションで説明)の規律ある使用によって大幅に軽減できます。これは、公開APIでは利用できない、エンタープライズAPIで使用できる興味深いオプションです。
多くの種類の変更においては、バージョン管理を他の手法で回避できます。 Postelの法則 は、受け入れる際には寛大になり、送信する際には保守的になるべきだと述べています。これはサービス開発において賢明なアドバイスです。残念ながら、一部のデシリアライザのデフォルトの動作は、コンシューマから予期しないフィールドが提供された場合に例外をスローすることで、このアドバイスに反しています。これは不運なことです。なぜなら、それは単にコンシューマが消費を期待せずに追加の診断情報をワイヤ経由で渡しているだけかもしれないし、コンシューマがプロデューサの将来のアップデートに備えて、プロデューサが対応できるようになる前に新しいフィールドを渡しているかもしれないからです。プロデューサがレスポンスボディに新しいフィールドを追加し、コンシューマがそれを無視しても構わないという場合もあるでしょう。これらの状況のいずれも例外を正当化するものではありません。
自動デシリアライゼーションは通常、コンシューマとプロデューサを結合するという落とし穴に陥ります。
通常、デシリアライザをより寛容になるように構成することは可能です。主流のアドバイスではありませんが、私は自動デシリアライゼーションを完全に避けることを好みます。自動デシリアライゼーションは通常、静的なクラス構造を両方で複製することにより、コンシューマとプロデューサを結合するというWSDLの落とし穴に陥ります。手動でコーディングされたデシリアライゼーションは、入力データに対する仮定を少なくすることもできます。Martin FowlerがTolerant Readerで説明しているように、//orderのようなXPath式を使用すると、order要素の上位にあるネストされた変更がデシリアライゼーションを壊すことなく行えます。
サービス契約設計に関しては、少しの事前設計が大きなメリットをもたらします。あるプロジェクトでは、属性の大文字と小文字が不一致の契約(例:firstNameとLastName)が開発されていました。コンシューマチームの開発者は、その契約に基づいて開発する際に間違いなく心の中で悪態をついたでしょうが、その契約がその後予告なく「修正」されたときには、かなり大声で悪態をつきました。
大規模なSOAプロジェクトでは、サービス境界で多くのストーリーを作成することを好みます。これは、エンドツーエンドの機能がビジネス目標と整合していることを確認するという明らかな課題(後述)につながりますが、多くの利点があります。まず、それらは自然とテクニカルリードまたはアーキテクトを分析に巻き込む傾向があり、彼らに概念の粒度について考え、契約をモックアップしてリソースの一貫性のある説明を形成する時間を与えます。受入基準を作成するには、さまざまなエラー条件とレスポンスコードについて検討する必要があります。サービス境界でQAレビューを行うことで、先ほど述べた大文字と小文字の不一致のような明らかな間違いをキャッチする別の機会が得られます。最後に、テスト駆動開発が各クラスに少なくとも2つのコンシューマ(それが書かれたコンシューマとテスト)を持たせることで疎結合を促進するのと同じように、サービス境界のストーリーは、サービスエンドポイントが、最初に開発されたエンドツーエンドの機能に過度に固有のものではなく、再利用可能であることを保証するのに役立ちます。サービスエンドポイントを独立してテストできることで、それがサポートするエンドツーエンドのワークフローに過度に密結合されるのを防ぎます。
プロデューサは、セマンティックバージョニングを使用して、破壊的な変更を行う必要がある場合にもシグナルを送信できます。これは、MAJOR.MINOR.PATCH部分に既知の意味を追加するための簡単なスキームであり、破壊的な変更に対してMAJORバージョンを増分することを含みます。コンシューマ主導のテスト(後ほど説明)の規律正しいセットがあれば、同じリリースですべてのコンシューマをアップグレードできる場合があります。もちろん、それは常に可能とは限らず、ある時点で、同じサービスの複数のバージョンをサポートする複雑さが正当化される可能性があります。なぜなら、その依存関係のリリースを調整する方がさらに複雑だからです。バージョン管理を使用する必要がある時点になると、URLバージョン管理とHTTPヘッダーバージョン管理の2つの主要な手法から選択する必要があります。選択にあたっては、選択するバージョン管理スキームがまず第一にリリース管理戦略であることを理解することが重要です。
URLバージョン管理は、バージョン番号をURLに含めることを含みます(例:/customers/v1/… - セマンティックバージョニングのMAJORバージョンで十分です)。これにより、コンシューマはプロデューサがリリースされるまで待機する必要があります。URLバージョン管理は、非常に可視的で、ブラウザを介してテストできるという利点があります。それにもかかわらず、URLバージョン管理は、あるサービスが別のサービスへのリンクを提供し、コンシューマがそのリンクに従うことを期待する場合に重要な欠陥を抱えています(これは、ハイパーメディアを使用してワークフローを駆動しようとする際に最も一般的です)。ハイパーリンクされたサービスが新しいバージョンにアップグレードされた場合、このような依存関係全体のアップグレードを調整するのは困難になる可能性があります。たとえば、顧客サービスが製品サービスにリンクし、UIがそのリンクを盲目的に従う場合、バージョンが提供されたリンクに埋め込まれているため、製品のバージョニングを認識しません。製品サービスに後方互換性のないアップグレードを行う場合、最終的にはリンクを更新するために顧客サービスもアップグレードしたいと思いますが、まずUIをアップグレードする必要があります。この状況では、最も簡単な解決策は多くの場合、3つのコンポーネントすべてを同時にアップグレードすることです。これは、まったくバージョン管理を行わないことと同じリリース管理戦略です。
Duncan Beaumont Craggは、バージョン管理するのではなく、単にURL空間を拡張することを提案しています。非互換な変更を行う必要がある場合、既存のリソースをバージョン管理するのではなく、新しいリソースを作成するだけです。表面上、/customers/v2/profileと/customers/extendedProfileの間には小さな違いがあります。それらは同じように実装されている可能性もあります。しかし、コミュニケーションの観点からは、この2つの選択肢の間には大きな違いがあります。バージョン管理ははるかに広範なトピックであり、大規模な組織では、バージョン管理は多くの場合、アーキテクチャやリリース管理を含む複数の外部チームとの調整を必要とする可能性がありますが、チームは新しいリソースを追加することに対して自律性を持ちがちです。
HTTPヘッダーバージョン管理は、コンシューマが受け入れるバージョンを示す情報をHTTPヘッダーに配置します。これは、Content-Type(例:application/vnd.acme.customer-v1+json)と最も一般的に関連付けられており、コンテンツネゴシエーションによってバージョンを管理できます。クライアントは、サポートされているバージョンのリストをAcceptヘッダーで送信でき、サーバーはContent-Typeヘッダーで使用されているバージョンで応答するか、サポートされていないバージョンの要求に対して415 HTTPステータスコードを送信できます。これは純粋主義的なRESTafarianに訴えかけ、上記で述べたURLバージョン管理の欠陥の影響を受けません。なぜなら、最終的なコンシューマが要求するバージョンを決定できるからです。もちろん、ブラウザを介してテストするのが難しくなり、開発時に見落とされやすくなります。追加の可視性を提供するために、存在する場合、要求本文とレスポンス本文にもバージョン番号を追加することが役立ちます。ヘッダーバージョン管理は、キャッシングにも課題をもたらします。Varyヘッダーは、同じURLを異なる方法でキャッシュできるように設計されていますが、ネットワーク構成の複雑さが増し、Varyヘッダーを無視する誤って構成されたネットワークキャッシュに遭遇するリスクがあります。
コンシューマベーステストで統合問題を検出する
コンシューマベースのテストは、私が見た中で最も価値のあるプラクティスの1つであり、RESTをエンタープライズ内でスケーラブルにすることができますが、深く掘り下げる前に、デプロイメントパイプラインの概念を理解する必要があります。
デプロイメントパイプライン
継続的デリバリーに関する画期的な著書の中で、Jez HumbleとDave Farleyは、デプロイメントパイプラインをチェックインから本番環境へのコードの経路として描いています。大規模な組織でのチェックインから本番リリースまでの流れを追跡すると、次の手順が見つかる可能性があります。
- 開発者が新しいコードをチェックインします。
- 継続的インテグレーションツールが、ソースコードをコンパイル、パッケージ化し、ユニットテストを実行します(多くの場合、コミットステージと呼ばれます)。
- 継続的インテグレーションツールがサンドボックス環境にデプロイされ、デプロイされたサービスに対して自動テストを独立して実行します。
- アプリケーションチームがショーケース環境にデプロイし、ビジネスステークホルダーによる内部ユーザー受け入れテストが行われます。
- 中央QAチームがシステム統合テスト(SIT)環境にデプロイし、他のアプリケーションやサービスとともにテストを行います。
- リリース管理がプレプロダクションにデプロイし、アプリケーションチーム、セキュリティ、運用チームがリリースの品質に関する手動検証を実行します。
- リリース管理が本番環境にデプロイします。
一連のステージとしてそのワークフローをモデル化することで、デプロイメントパイプラインが得られ、パイプラインの各ステージにおけるサービスのバージョンを視覚化できます。

図3:単純なデプロイメントパイプライン
上記に示されたパイプラインは、単一サービスを独立してフローを説明しています。大規模なSOAプロジェクトの現実の世界は、統合を追加するとかなり複雑になります。
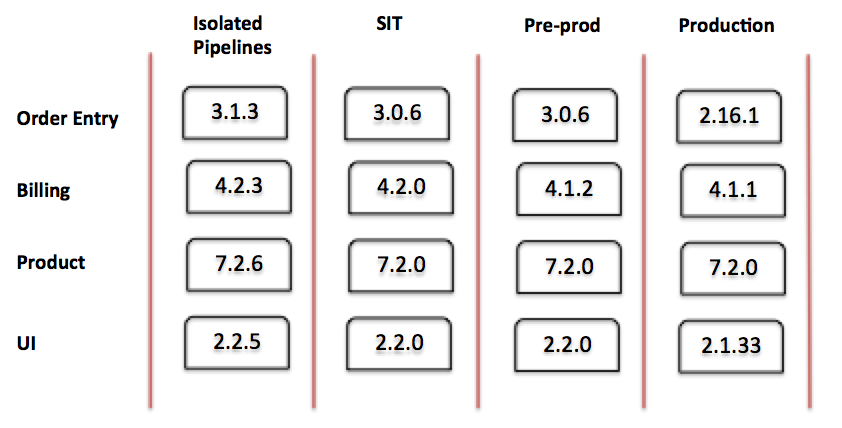
図4:統合されたデプロイメントパイプライン
統合されたパイプラインでは、初期ステージの多くの詳細を省略していることに注意してください。異なるチームは、チーム向けのパイプライン部分に異なるステージを持つことが多く、真の外部依存関係から分離されている可能性があります。たとえば、一部のチームは手動QAまたはパフォーマンステストステージを追加する場合があります。組織レベルのステージ(SIT、プレプロダクション、本番環境)では、すべてのコードが同じように進行し、それらのステージで統合されたサービスをテストするのが一般的です。パイプラインを下っていくほど、統合度が高くなり、本番環境に近い環境になります。
スタブへの投資は、パイプラインの初期段階で大きな利益をもたらす可能性があります。ビルドが失敗するのは、チーム内のコードの破損が原因であり、テスト中の環境の変化が原因ではないと分かれば安心できます。テストダブルを使用すると、テストにおける非決定性の主要な原因を取り除くことができます。VCRのようなライブラリを使用すると、実際のサービス呼び出しを記録し、後で自動テスト実行中に応答を再生できます。ただし、テストダブルを使用すると、統合の問題が発生する可能性があり、エンタープライズの大部分の複雑さは統合に関係しています。幸いにも、Ian Robinsonは統合の複雑さを解決するソリューションについて説明しており、これは私たちのデプロイメントパイプラインにうまく適合します。
コンシューマベーステスト
消費者ベースのテストは、生産者がテストを書くのではなく、消費者がテストを書くことに依存するため、直感に反します。契約テストを作成する場合、消費者は使用するサービスに対してテストを記述し、サービス契約が消費者のニーズを満たしていることを確認します。たとえば、受注チームは、製品サービスのコードと説明、および月額料金が数値であることに依存している可能性があり、次のようなテストを作成します。
[Test]
public void ValidateProductAttributes()
{
var url = UrlForTestProduct();
var response = new HttpResource(url)
.ThatAccepts("application/xml")
.Get();
Assert.That(response.StatusCode, Is.EqualTo(200));
AssertHasXPath(response.Body, "//productCode");
AssertHasXPath(response.Body, "//description");
AssertHasXPath(response.Body, "//monthlyCharge");
AssertNumeric(ValueFor(response.Body, "//monthlyCharge"));
}
これにより、デプロイメントパイプラインで巧妙なトリックが可能になります。個々のサービスが内部パイプラインを通過した後、すべてのサービスとコンシューマーは統一された契約テストステージを通過します。これは、コンシューマーがテストを変更した場合、またはプロデューサーがサービスに変更をコミットした場合にトリガーされる可能性があります。各コンシューマーは、変更されたサービスの新しいバージョンに対してテストを実行し、失敗した場合は、新しいバージョンがパイプラインで進行することを妨げます。
例として、受注サービスの新しいビルドが契約テストステージに進捗するとしましょう。
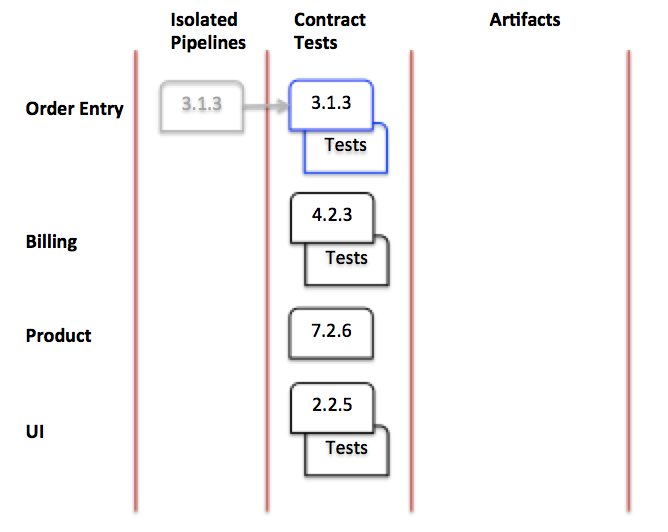
図5:契約テストステージ
これは製品サービスと課金サービスに依存しており、新しいコードによって契約テストが変更されている可能性があるため、契約テストステージに進むために、製品サービスと課金サービスの最終バージョンに対してテストを実行します。UIは受注サービスに依存しているため、契約テストステージのUIコードの最終バージョンは受注サービスに対してテストを実行します。これは、サービスとそのコンシューマーテストの両方が契約テストステージで必要であることを意味します。製品サービスには依存関係がないため、コンシューマーテストはありません。もう一度ダイヤモンドを見てみましょう。今回は、各サービスに依存するバージョンが1つだけであることに注意してください。
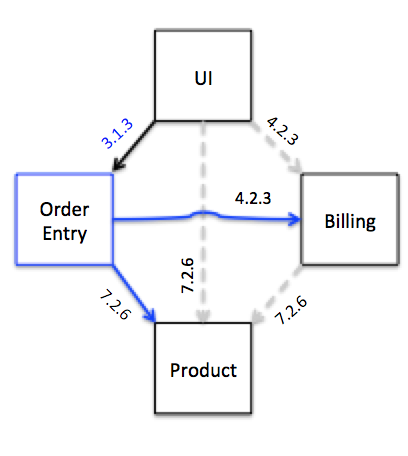
図6:契約テスト実行例
特定の変更に関連付けられたテストのみをトリガーすることは難しくなる可能性がありますが、新しいサービスがパイプラインの契約テストステージにデプロイされるたびに、すべての契約テストを実行するだけで、長い道のりを歩むことができます。図6の灰色の線は、導入された変更とは無関係です。これは、テスト実行の速度と、依存関係の管理をどの程度複雑にするかというトレードオフです。
{kind=link}
すべてのテストに合格した場合、連携して動作することが示されたサービスセットが得られます。それらをまとめて、それらの関連バージョンを記録することができます。
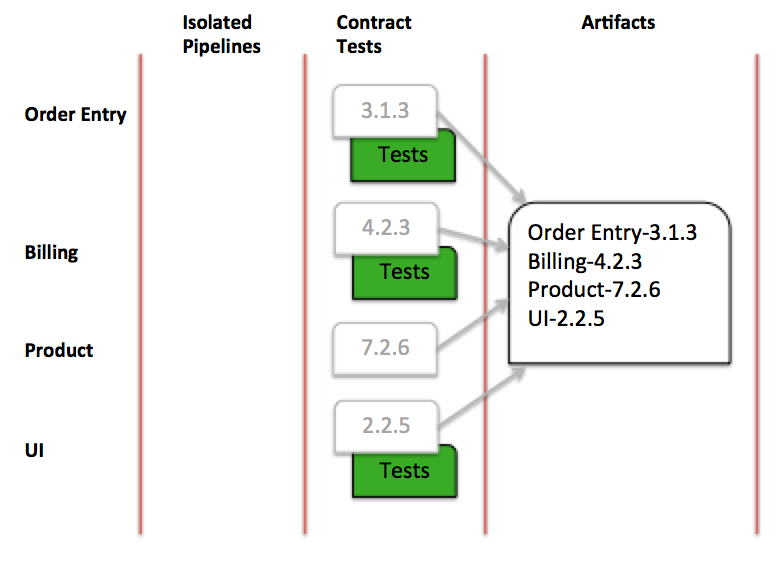
図7:契約テスト実行成功
この時点で、関連するサービスのすべてのバージョンは、単一のデプロイ可能なアーティファクトセット(DAS)にキャプチャされます。このDASは、デプロイメントパイプラインの上位ステージの単一のデプロイ可能なアーティファクトになることができます。あるいは、独立したリリースをサポートする必要がある場合は、互換性の参照を提供することもできます。どちらの場合でも、これは同じ言語を話すことが証明されたコンポーネントのセットを表します。
新しい受注コードがUIコンシューマーテストを壊した場合、結合されたアーティファクトは進行しません。これは必ずしもサービスの問題を示すわけではありません。消費者が契約を誤解している可能性があります。または、プロデューサーによる意図的な破壊的変更である可能性がありますが、セマンティックバージョニングのマナーによると、意図的な場合はMAJOR番号を増分する必要があります。いずれの場合も、契約テストの失敗は、消費者が環境を更新してから数日または数週間後ではなく、早期に両チーム間の会話をトリガーします。

図8:契約の破棄変更
データはどうすれば良いか?
包括的な消費者ベースのテストを取得する際のより難しい課題の1つは、貴重なテストデータを作成することです。上記の契約テストでは、既知のテスト製品を想定しています。この仮定をUrlForTestProductメソッドで隠しましたが、これはおそらく特定の製品のURLが必要であることを意味します。テスト時に利用可能なデータに関する仮定をハードコーディングすることは、将来その製品が存在し続ける保証がないため、脆弱なアプローチになる可能性があります。さらに、一部のエンドポイントは、機能するために複数のサービス間でデータの一貫性を必要とする場合があります。たとえば、受注は、一連の関連製品とともに課金に注文を送信する場合があります。課金エンドポイントは、一貫した製品データセットを持っている必要があります。
より堅牢な戦略の1つは、テスト実行中にテストデータを作成することです。これにより、使用する前にデータが存在することが保証されます。これは、各サービスが新しいリソースの作成を許可することを前提としていますが、常にそうとは限りません。ただし、あるクライアントでは、テストデータの作成を容易にするために、テスト専用のエンドポイントを追加しました。これらのエンドポイントは本番環境では公開されていませんでした。この戦略では、上記の課金例で複雑なテスト設定が必要になる場合があります。テスト製品を作成した後、受注サービスと課金サービスとの同期を強制する必要があります。これは、多くの場合、非同期です。別の戦略としては、各サービスが安定していることが保証されている、まとまりのあるゴールデンテストデータセットを公開することです。これは通常、より高レベルのデータ境界にカプセル化するのが最適です。たとえば、本番環境に影響を与えない偽のデータを提供する唯一の目的で、すべてのサービスを横断するテストマーケティングブランドまたは事業ラインを作成できます。いずれにせよ、テストデータの整理は、堅牢なサービスデプロイメントパイプラインを実現するための最優先事項である必要があります。
システムにリソースを独占させない
データ境界を適切に定義しないことは、アーキテクトが犯す最も高価な間違いの1つです。一般的なアンチパターンは、エンティティに関するすべての情報を単一のデータストアに格納し、必要に応じて依存システムにエクスポートしようとすることであり、これはマスターデータ管理(MDM)に対する表面的な誤解によって促進されています。このような戦略の問題点は、ソフトウェアアーキテクチャはそれを構築した組織の構造を反映するように縛られているというコンウェイの法則に違反することです。[1]
製品カタログの例を見てみましょう。レガシーシステムでは、あるチームが新しい製品コードとその関連レートを入力しました。プロビジョニングチームは別のツールを使用して、下流の電話プロビジョニングシステムに必要なコードなどの適切な構成を入力し、別のアプリケーションでテレビチャンネルをオンにするためのサービスコードを入力しました。財務チームは、財務ツールで製品に関する仕訳情報を記入し、請求チームは別のアプリケーションで特別な請求ルールを追加しました。これらのチーム間のコミュニケーションは、テクノロジーではなくビジネスによって管理されていました。
すべての製品データに対して単一のアプリケーションへの移行は、これらの異なるビジネスチームすべてが製品の定義が異なるため、壊滅的な作業になる可能性があります。顧客サービス担当者が単一製品と考えているものは、適切な会計をサポートするために2つに分割する必要がある場合があります。請求チームは、請求を簡素化することでコールレートを削減することに非常に関心があり、請求書に2つの製品コードを単一行にマージする必要があることがよくあります。そしてもちろん、常に製品を無謀に再定義するマーケティングがあります。製品のエンタープライズビュー全体を単一のカタログに合理化しようとすると、そのカタログは脆弱で非柔軟になります。事実上、変更を行うために、企業全体が製品カタログに降りてくる必要があります。変更の表面積が大幅に増加し、変更による波及効果を推論することが難しくなります。コンウェイの法則は違反されており、システムのコミュニケーションパスはもはや組織のコミュニケーションパスを表していません。
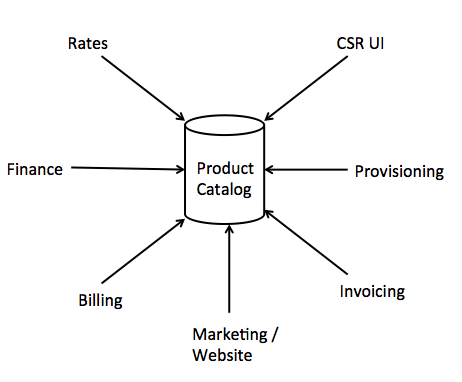
図9:データモデリングの災害
企業とその統合パートナー全体で製品のような重要なものの標準的な表現を標準化しようとする普遍的なデータモデルには、少し懐疑的です。電気通信業界は、TM Forum Shared Information/Data Model(TMF SID)と呼ばれるまさにそのようなデータモデルを作成しました。主張は、SIDを標準化することにより、異なる企業、または企業内の部門が、同じ論理エンティティを記述するために同じ用語を使用できることです。そのような大規模な取り組みは、いくつかの成功なしでは維持されないと思いますが、それらを見たことがありません。
Eric Evansのドメイン駆動設計を借用した推奨ソリューションは、各チームの製品の定義をバウンデッドコンテキストでラップすることです。バウンデッドコンテキストは、用語が使用される場所どこでも同じ意味を持つことが保証される言語的境界です。バウンデッドコンテキストの外では、そのような保証はなく、統合とビジネスプロセスの組み合わせによって変換を管理する必要があります。財務製品がプロビジョニング可能な製品とは異なることは、コンウェイの法則に従う方法でモデル化できるようになりました。
パッケージの周りに明確に定義されたバウンデッドコンテキストを提供することは、ファサードサービスの優れた用途です。ベンダーが複数のビジネスをサポートするためにパッケージを進化させるという自然な結果として、パッケージの機能セットは企業のニーズを超える可能性があります。ファサードサービスの背後にあるパッケージとのすべての通信をラップすることで、パッケージデータをビジネスプロセスが定義するバウンデッドコンテキストに制限して整形し、パッケージ固有の言葉遣いを企業によって定義された言語に変換するクリーンなAPIを提供できます。
中央集権的なエンティティにはデータの小さなサブセットを使用する
これを技術的に行う方法は、製品カタログに存在するマスターデータのセットを縮小し、それを他のシステムに複製して拡張することです。このテクニックは、時として「スイベルチェアインテグレーション」に関連付けられますが、同じではありません。真のスイベルチェアインテグレーションでは、同じ情報が、直接統合されていない複数のアプリケーションに入力されます。バウンデッドコンテキストでは、マスターデータが複製され、依存アプリケーションでコンテキストに応じて拡張および変換されます。
製品のような中央リソースエンティティを定義するための鍵は、新しい製品を作成するビジネスチームが製品をどのように考えているかを理解することです。私たちの仮説的な例では、製品はすべての部門で使用されるいくつかの基本的な料金と一般的な説明情報を定義すると決定しました。これにより、製品サービスでの製品の定義が得られます。製品とは、単一の料金を持つ顧客に販売できるものです。レガシーの世界では、製品を作成した後、製品チームは他の部門にメールを送信します。このイベントは自動化に値する可能性があり、サービスで公開されているキューまたは変更フィードで公開することで実行できます。ただし、このイベントがトリガーするビジネスプロセスを自動化できるふりをしたり、そのビジネスプロセスを中央カタログ内に移動したりしないでください。
財務部門がそれを受信すると、製品をどのように分解するかを決定する必要があります。たとえば、割引価格でTVスポーツチャンネルのバンドルパッケージであったとします。これは、製品チームの製品の定義にうまく適合する概念です。ただし、財務部門は、バンドル内の各スポーツ局がロイヤルティ料金を受け取れるようにする必要があるため、単一のレートを異なる仕訳勘定に送信する必要があります。これで、財務定義が得られました。製品とは、収益と仕訳勘定の関連付けです。このユースケースでは、財務アプリケーションがNewProductイベントを受信し、ユーザーが収益の一部を仕訳勘定に割り当てるためのインターフェースを提供すると想像できます。
各事業部門には、バウンデッドコンテキスト間の明示的な変換を伴う共通エンティティの異なるモデルがあります。
請求部門がイベントを受け取ると、パッケージを按分するかどうかを決定する必要があります。おそらく、あまりにも多くの顧客が按分されたスポーツチャンネルを注文して翌日にビッグゲームを見た後にキャンセルすることを懸念して、この特定のスポーツパッケージは、最初に1ヶ月分の支払いを必要とすることを決定しました。製品は顧客への定期的な請求ですという定義から始め、単純な月額料金を超える一連の潜在的に複雑な構成で拡張します。
請求書において、製品は「請求書の一行」として定義されます。マーケティング戦略などから、2つの異なるスポーツバンドルを購入した顧客には、「スーパー スポーツ パッケージ」という一行のみを請求書に表示し、金額を合計して表示することを決定する場合があります。同様に、NewProductイベントの受信を容易にするアプリケーションを想定することも、新しい製品が導入された際に開発者が新しいルールをコーディングすることを想定することもできます。
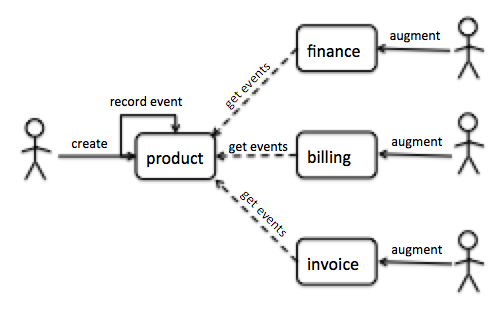
図10:境界コンテキストを使用した統合の例
この例は、4つの異なる境界コンテキストと、通知フィード(一般的なRESTfulアプローチ)を使用して伝播されるNewProductイベントを示しています。新しい製品が作成されると、製品サービスは新しい製品をイベントとして記録し、エンドポイントで公開します。コンシューマーはエンドポイントをポーリングして、最後にポーリングした時刻以降のすべてのイベントを受信します。エンドポイントは、/notifications?since=2013-10-01のような形式になる可能性があります。
ビジネス機能の調整にはエピックを使用する
以前、サービスエンドポイントをストーリーの境界として検討することを推奨しましたが、従来のアジャイルストーリーの利点、つまりビジネス機能と整合しているという利点を失う可能性があるという注意書きを付け加えました。チームは異なる優先順位で異なる速度で作業するため、この問題は、大規模SOAではさらに悪化し、全体像を見失うリスクがあります。製品の最初の月の請求を行うビジネス機能を想像してみてください。真のビジネスフローでは、その時点までに、顧客の作成、製品の検索、注文の作成、フィールド技術者の承認など、一連のサービス呼び出しが必要になる場合があります。大規模なシステムでは、これらのサービスエンドポイントは異なるチームによって実装されます。
アジャイルツールボックスには、単一のハイレベル機能に沿ってストーリーのグループを調整するためのエピックが常に含まれていました。大規模SOAのプログラム管理の第一級市民として扱うことをお勧めします。実際、ユーザーストーリーに付加する儀式の大部分は、このようなプロジェクトではエピックレベルで行われるべきだと考えています。なぜなら、エピックは多くの場合、要件のビジネスフレンドリーな説明の代わりとなるからです。
たとえば、「顧客作成」エピックには、顧客管理チームに加えて、注文入力チームと請求チームが関与し、それぞれが自分の作業を追跡するためのサービス指向またはアプリケーション固有のストーリーを持っています。個別のチームが開発したユーザーインターフェースによってサービスが使用されるという仮説の例では、完全なシステムフローを完了するまで、ビジネスに成果を示すことができない可能性があります。
エピックのケアと管理の一部は、小規模なエンゲージメントでのストーリーのプラクティスから引き継ぐことができます。クロスファンクショナルな要件を定義するためのエピックのアーキテクチャレビューと、受入要件を定義するためのビジネスアナリストは、全体像を把握するのに役立ちます。チーム間のショーケースはエピックレベルで管理する必要があり、実際のビジネスユーザーフローが示される最初のショーケースとなる可能性があります。
プログラムレベルの指標は、速度の追跡のための主要な指標としてエピックを維持します。チームのユーザーストーリーの速度は、進捗状況の誤った認識を与える可能性があります。
重要な考慮事項は、プログラムレベルの指標が速度の追跡のための主要な指標としてエピックを維持することです。チームのユーザーストーリーの速度は、進捗状況の誤った認識を与える可能性があります。注意すべき症状は、速度バーンアップがプログラムが予定通りに配信されていることを示しているのに、何も機能していないように見える場合です。私は、個々のチームが追跡する個々のストーリーの速度に基づいて、これが事実であったプロジェクトに携わっていました。いくつかのチームは時間通りに、他のチームはわずかに遅れていましたが、数ヶ月の開発の後でも、ビジネスに何も示すことができませんでした。プログラムレベルのバーンアップを、完了したストーリーの数ではなく、完了したエピックの数に変更するだけで、有益な情報が得られました。個々のチームは大幅な進捗を示していましたが、完了したのは1つのエピックだけでした。さらに悪いことに、リリースに必要なすべてのエピックの少なくとも3分の2からの少なくとも1つのストーリーが同時に進行していました。従来のソフトウェアカンバンアプローチは、ストーリーレベルでの作業中のアイテム数を制限しようとします。問題の規模を認識したとき、ストーリーの開発の順序を再調整して、同時に進行中のエピックの数を制限することで、修正することができました。
まとめ
テクノロジーやアーキテクチャに関係なく、ソフトウェア開発のスケーリングは難しい作業です。私たちはしばしば、「単なる統合」であると見せかけることで、そうではないと信じ込ませています。エリック・エバンスはかつて、大規模システムでは、その一部は設計が不十分になると述べています。高度なスキルを持つチームであっても、私の経験から、彼は正しいと確信しています。したがって、統合の主な目標は、他のサブシステムの設計から自分自身を保護することです。
私はRESTfulサービス統合戦略を支持しています。RESTにより、開発が簡素化され、RESTfulメッセージは自己記述的である傾向があるため、テストとトラブルシューティングも簡素化されると考えています。しかし、それは一部の人が想像するような万能薬からは程遠く、大規模なRESTful統合では、上記で説明した教訓に注意を払う必要があります。私の経験から、
- 環境の分離が重要です。デプロイメントの自動化に注意を払うことが重要です。適切なデプロイメントプラクティスを無視したパッケージを選択すると、そのパッケージと統合する必要があるすべての人が遅くなります。
- 早期のバージョン管理は、システムに不要な複雑さを追加します。寛容な逆シリアル化やエンドポイントベースのストーリー分析などのプラクティスは、バージョン管理を遅らせるのに役立ち、その後でセマンティックバージョン管理のサポートを追加する場合でも役立つプラクティスです。
- コンシューマテストを使用すると、相互依存するサービスのセットをアップグレードする際のリリース管理の複雑さが大幅に軽減され、バージョン管理の遅延にも役立ちます。
- エンティティに関するすべてのデータをサービスが制御できるようにしようとすると、悲惨な結果になります。ビジネスプロセスと、ビジネスがエンティティに対して持つさまざまな定義を無視しないでください。
- ビジネス機能の調整は、大規模なシステムではユーザーストーリーレベルでは起こりそうにありません。ビジネスリリースのシーケンスにはエピックが必要です。
ハイパーメディア、コンテンツネゴシエーション、統一インターフェースは、RESTfulな議論では注目を集めており、貴重なテクニックですが、統合ソリューションをスケーリングするには、RESTのメカニズムから離れて、社会的な問題と組織的な問題を見る必要があります。このような問題をうまく解決することは、個々のサービスやコンポーネントがうまく設計されることを意味するわけではありません。それは、ビジネス価値を段階的に提供し、統合レイヤーで適切な堅牢性を確保するための確実なプラクティスが導入されていることを意味します。これらのプラクティスは、成功したデリバリーと失敗したデリバリーの差を意味する可能性があります。
謝辞
この記事に対する初期のフィードバックをいただいたMartin Fowler、Damien Del Russo、Danilo Sato、Duncan Beaumont Cragg、Jennifer Smithに感謝いたします。多くのアイデアは、Thoughtworksの同僚をさまざまなプロジェクトのサウンドボードとして使用することで生まれました。ここで名前を挙げるには多すぎるため、Ryan Murray、Mike Mason、Manoj Mahalingamの特に大きな影響を挙げさせていただきます。
脚注
1: コンウェイの法則
コンウェイの法則にはいくつかの異なる見解があり、純粋に記述的な同語反復と見なす人もいます。私は、WikipediaがJames CoplienとNeil Harrisonに関連付けている変種とより一致した形で使用しています。それは組織内のソフトウェアの記述的な法則かもしれませんが、コンウェイの法則に反して機能しようとするソフトウェアは失敗する運命にあるためだと信じています。
重要な改訂
2013年11月18日:バージョン管理を回避するためのURL空間の拡張オプションと、コンウェイの法則の使用を明確にするための脚注を追加
2013年11月12日:エピックの使用に関するセクションを追加し、最初の公開を完了
2013年11月8日:システムがリソースを独占することを防ぐためのセクションを追加
2013年10月31日:コンシューマベースのテストに関するセクションを追加
2013年10月24日:バージョン管理に関するセクションを追加
2013年10月21日:論理環境セクションを含む第1版をリリース