私たちとThoughtworksの同僚がアジャイルプロジェクトを開始したとき、アーキテクチャの進化に合わせてデータベースを進化させる方法の問題を解決する必要があることに気づきました。私たちは2000年頃に、最終的に約600個のテーブルを持つデータベースを持つプロジェクトから始めました。このプロジェクトに取り組んでいるうちに、スキーマを変更し、既存のデータを快適に移行できる技術を開発しました。これにより、データベースを完全に柔軟かつ進化させることができました。私たちはこれらの技術をこの記事の以前のバージョンで説明しました。これは他のチームやツールセットにインスピレーションを与えた説明です。それ以来、私たちは小規模チームから大規模な多国籍プログラムまで、世界中の何百ものプロジェクトでこれらの技術を使用および開発してきました。この記事を最新の状態にすることを長い間意図しており、今回、適切に更新する機会を得ました。
Jenが新しいストーリーを実装する
このすべてがどのように機能するかを理解するために、開発者(Jen)が新しいユーザーストーリーを実装するためのコードを記述するときに何が起こるかを概説してみましょう。ストーリーでは、ユーザーは在庫にある製品の場所、バッチ、シリアル番号を表示、検索、更新できる必要があるとされています。データベーススキーマを見ると、Jenは現在、在庫テーブルにそのようなフィールドがなく、これらの3つのフィールドを連結した単一のinventory_codeフィールドしかないことに気づきます。彼女は、この単一のコードを取得し、それを3つの別々のフィールド、つまりlocation_code、batch_number、およびserial_numberに分割する必要があります。
彼女が実行する必要がある手順は次のとおりです
- 既存のスキーマの
inventoryテーブルに新しい列を追加する
- 既存の
inventory_code列からデータを分割し、location_code、batch_number、およびserial_number列を更新するデータ移行スクリプトを作成する。
- 新しい列を使用するようにアプリケーションコードを変更する
- ビュー、ストアドプロシージャ、トリガーなどのデータベースコードを、新しい列を使用するように変更する
inventory_code列に基づくインデックスを変更する- このデータベース移行スクリプトとすべてのアプリケーションコードの変更をバージョン管理システムにコミットする
新しい列を追加してデータを移行するために、Jenは現在のスキーマに対して実行できるSQL移行スクリプトを作成します。これにより、スキーマが変更され、在庫内のすべての既存のデータも移行されます。
ALTER TABLE inventory ADD location_code VARCHAR2(6) NULL;
ALTER TABLE inventory ADD batch_number VARCHAR2(6) NULL;
ALTER TABLE inventory ADD serial_number VARCHAR2(10) NULL;
UPDATE inventory SET location_code = SUBSTR(product_inventory_code,1,6);
UPDATE inventory SET batch_number = SUBSTR(product_inventory_code,7,6);
UPDATE inventory SET serial_number = SUBSTR(product_inventory_code,11,10);
DROP INDEX uidx_inventory_code;
CREATE UNIQUE INDEX uidx_inventory_identifier
ON inventory (location_code,batch_number,serial_number);
ALTER TABLE product_inventory DROP COLUMN inventory_code;
Jenはこの移行スクリプトをマシン上のデータベースのローカルコピーで実行します。次に、これらの新しい列を使用するようにアプリケーションコードの更新に進みます。これを行う際に、既存のテストスイートをこのコードに対して実行して、アプリケーションの動作の変更を検出します。結合された列に依存していたテスト、つまり更新する必要があるテストもあります。テストを追加する必要がある場合もあります。Jenがこれらすべてを行い、アプリケーションのすべてのテストがマシン上でグリーンになったら、Jenはすべての変更を共有プロジェクトバージョン管理リポジトリ(メインラインと呼びます)にプッシュします。これらの変更には、移行スクリプトとアプリケーションコードの変更が含まれます。
Jenがこの変更にあまり慣れていない場合、データベースに変更を加えるのはよくあることなので、幸運です。データベースリファクタリングブックで調べることができます。また、オンラインサマリーもあります。
変更がメインラインに追加されると、継続的インテグレーションサーバーによって取得されます。データベースのメインラインコピーで移行スクリプトを実行し、次にすべてのアプリケーショテストを実行します。すべてがグリーンの場合、このプロセスはQAおよびステージング環境を含むデプロイメントパイプライン全体で繰り返されます。最後に同じコードが本番環境に対して実行され、ライブデータベースのスキーマとデータが更新されます。
このような小さなユーザーストーリーには、データベースの移行が1つだけあります。大きなストーリーは、データベースの変更ごとにいくつかの個別の移行に分割されることがよくあります。私たちの通常のルールは、各データベースの変更をできるだけ小さくすることです。小さいほど、正しくなりやすく、エラーをすばやく発見してデバッグできます。このような移行は簡単に構成できるため、小さな移行を多数行うのが最善です。
変更への対処
2000年代初頭にアジャイル手法が普及するにつれて、その最も明白な特徴の1つは、変化への対応です。登場する前は、ソフトウェアプロセスに関する考え方のほとんどは、要件を早期に理解し、これらの要件に署名し、要件を設計の基礎として使用し、それに署名し、建設を進めることでした。これは計画主導型のサイクルであり、多くの場合(通常は嘲笑を込めて)ウォーターフォールアプローチと呼ばれます
このようなアプローチは、事前に広範な作業を行うことで変更を最小限に抑えようとします。初期の作業が完了すると、変更によって重大な問題が発生します。その結果、このようなアプローチは、要件が変更されている場合に問題が発生し、要件の変更は、このようなプロセスにとって大きな問題になります。
アジャイルプロセスは、変更に異なるアプローチをとります。開発プロジェクトの後半でも変更が発生することを許可し、変更を受け入れようとします。変更は制御されますが、プロセスの態度は、可能な限り変更を可能にすることです。これは partly は多くのプロジェクトにおける要件の固有の不安定性への対応であり、partly は競争圧力に合わせて変化させることによって動的なビジネス環境をより適切にサポートするためです。
これを機能させるには、設計に対する異なる態度が必要です。設計を、建設を開始する前にほとんど完了するフェーズと考える代わりに、建設、テスト、さらには配信とインターリーブされる継続的なプロセスと見なします。これは、計画された設計と進化的な設計のコントラストです。
アジャイル手法の重要な貢献の1つは、進化的な設計を制御された方法で機能させることができるプラクティスを考案したことです。そのため、設計が事前に計画されていない場合によく発生する一般的な混乱の代わりに、これらの方法では、進化的な設計を制御し、実用化するための手法が提供されます。
このアプローチの重要な部分は反復開発です。プロジェクトの存続期間中にソフトウェアライフサイクル全体を何度も実行します。アジャイルプロセスは、各反復で完全なライフサイクルを実行し、最終製品の要件の小さなサブセットに対して、動作し、テストされ、統合されたコードで反復を完了します。これらの反復は短く、数時間から数週間まで、より熟練したチームはより短い反復を使用します。
これらの手法の使用と関心が高まっている一方で、最大の疑問の1つは、データベースで進化的な設計をどのように機能させるかということです。長い間、データベースコミュニティの人々は、データベース設計を絶対に事前の計画が必要なものと考えていました。開発の後半でデータベーススキーマを変更すると、アプリケーションソフトウェアに広範囲にわたる破損が発生する傾向がありました。さらに、デプロイ後にスキーマを変更すると、データ移行に問題が発生しました。
過去15年間の間に、私たちは進化的なデータベース設計を使用し、それを機能させた多くの大きなプロジェクトに関与してきました。一部のプロジェクトには、世界中の複数のサイトで100人以上が参加しました。その他には、50万行以上のコード、500を超えるテーブルが含まれていました。一部には、本番環境で複数のバージョンのアプリケーションと、24時間365日の稼働時間が必要なアプリケーションがありました。これらのプロジェクト中に、1か月と1週間の反復が見られました。より短い反復の方がうまくいきました。以下で説明する手法は、これを実現するために使用した手法です。
初期の頃から、私たちはこれらの技術をより多くのプロジェクトに広め、より多くのケースからより多くの経験を積み、現在ではすべてのプロジェクトでこのアプローチを使用しています。また、他のアジャイル実践者からもインスピレーション、アイデア、経験を得ています。
Limitations(制限事項)
テクニックの詳細に入る前に、進化的なデータベース設計のすべて問題を解決したわけではないことを明確にしておくことが重要です。
私たちは、数百の小売店がそれぞれ独自のデータベースを持ち、すべてを一緒にアップグレードする必要があるプロジェクトを経験しました。しかし、このような大規模なサイト群で多くのカスタマイズが行われている状況については、まだ探求していません。例としては、スキーマのカスタマイズを可能にする小規模ビジネスアプリケーションを、数千の異なる小規模企業に展開する場合などが考えられます。
単一のデータベース環境の一部として複数のスキーマを使用する人が増えています。私たちは、このように少数のスキーマを使用するプロジェクトに取り組んできましたが、まだ数十または数百のスキーマにまで拡張していません。これは、今後数年間で対処しなければならないと予想される状況です。
私たちは、これらの問題が本質的に解決不可能だとは考えていません。結局のところ、この記事の最初のバージョンを書いたとき、私たちは24時間365日の稼働時間や統合データベースの問題を解決していませんでした。私たちはそれらに対処する方法を見つけました。そして、進化的なデータベース設計の限界もさらに押し広げられると予想しています。しかし、そうするまでは、そのような問題を解決できるとは主張しません。
The Practices(プラクティス)
進化的なデータベース設計への私たちのアプローチは、いくつかの重要なプラクティスに依存しています。
DBAは開発者と緊密に連携する
アジャイル手法の信条の1つは、異なるスキルとバックグラウンドを持つ人々が非常に緊密に協力する必要があるということです。彼らは、主に正式な会議や文書を通じてコミュニケーションすることはできません。代わりに、彼らは常に互いに話し合い、協力する必要があります。アナリスト、PM、ドメインエキスパート、開発者...そしてDBAなど、全員がこれに影響を受けます。
開発者が取り組むすべてのタスクは、潜在的にDBAの助けを必要とします。開発者とDBAの両方が、開発タスクがデータベーススキーマに大きな変更を加えるかどうかを検討する必要があります。もしそうなら、開発者はDBAと相談して、変更を加える方法を決定する必要があります。開発者はどのような新しい機能が必要かを知っており、DBAはアプリケーションやその他の周辺アプリケーションのデータの全体像を把握しています。多くの場合、開発者は自分が作業しているアプリケーションを把握していますが、スキーマに対するすべての上流または下流の依存関係を必ずしも把握しているわけではありません。単一のデータベースアプリケーションであっても、開発者が認識していないデータベースに依存関係が存在する可能性があります。
開発者はいつでもDBAに電話して、データベースの変更を整理するためにペアプログラミングを依頼できます。ペアプログラミングを行うことで、開発者はデータベースの仕組みについて学び、DBAはデータベースへの要求のコンテキストを学びます。ほとんどの変更について、変更によるデータベースへの影響が懸念される場合は、開発者がDBAに連絡する必要があります。しかし、DBAも率先して行動します。データに大きな影響を与える可能性のあるストーリーを見つけた場合、DBAは関係する開発者を探して、データベースへの影響について話し合うことができます。DBAは、バージョン管理にコミットされた移行をレビューすることもできます。移行を元に戻すのは面倒ですが、各移行が小さいことで、元に戻すのが容易になるという利点があります。
これを実現するために、DBAは自身に近づきやすく、利用しやすいようにする必要があります。開発者が数分間立ち寄って質問したり、SlackチャンネルやHipChatルーム、または開発者が使用しているコミュニケーション手段で質問したりできるようにする必要があります。プロジェクトスペースを設定する際には、DBAと開発者が簡単に集まれるように、近くに座るようにしてください。DBAが簡単に参加できるように、アプリケーション設計セッションについてDBAに知らせてください。多くの環境では、DBAとアプリケーション開発機能の間に障壁が立ちはだかっているのが見られます。進化的なデータベース設計プロセスを機能させるには、これらの障壁を取り除く必要があります。
すべてのデータベースアーティファクトはアプリケーションコードと共にバージョン管理される
開発者は、アプリケーションコード、単体テストと機能テスト、ビルドスクリプトなどの他のコード、環境を作成するために使用されるPuppetまたはChefスクリプトなど、すべての成果物にバージョン管理を使用することで大きなメリットを得ます。
同様に、すべてのデータベース成果物は、他のすべての人が使用しているのと同じリポジトリでバージョン管理する必要があります。これには次の利点があります。
- 見なければならない場所が1つだけなので、プロジェクトの誰でも簡単に見つけることができます。
- データベースへのすべての変更が保存されるため、問題が発生した場合に簡単に監査できます。データベースのすべてのデプロイメントを、スキーマとサポートデータの正確な状態まで追跡できます。
- データベースがアプリケーションと同期していないデプロイメントを防ぎ、データの取得と更新エラーを防ぎます。
- 開発、テスト、そして本番環境のために、新しい環境を簡単に作成できます。ソフトウェアの実行バージョンを作成するために必要なものはすべて単一のリポジトリに配置する必要があるため、すぐにチェックアウトしてビルドできます.
すべてのデータベース変更はマイグレーションである
多くの組織では、開発者がスキーマ編集ツールと定型データ用のアドホックSQLを使用して開発データベースに変更を加えるプロセスが見られます。開発タスクが完了したら、DBAは開発データベースと本番データベースを比較し、ソフトウェアを本番環境に昇格させる際に本番データベースに対応する変更を加えます。しかし、本番時にこれを行うのは、開発における変更のコンテキストが失われるため、注意が必要です。変更の目的は、別のグループの人々によって再び理解される必要があります。
これを回避するために、開発中に変更をキャプチャし、アプリケーションコードの変更と同じプロセスと制御を使用してテストおよび本番環境にデプロイできるファーストクラスの成果物として変更を保持することをお勧めします。これを行うために、データベースへのすべての変更をデータベース移行スクリプトとして表し、アプリケーションコードの変更とともにバージョン管理します。これらの移行スクリプトには、スキーマの変更、データベースコードの変更、参照データの更新、トランザクションデータの更新、バグによって引き起こされた本番データの問題の修正が含まれます。
equipment_typeテーブルにmin_insurance_valueとmax_insurance_valueをいくつかのデフォルト値とともに追加する変更を次に示します。
ALTER TABLE equipment_type ADD(
min_insurance_value NUMBER(10,2),
max_insurance_value NUMBER(10,2)
);
UPDATE equipment_type SET
min_insurance_value = 3000,
max_insurance_value = 10000000;
この変更により、locationテーブルとequipment_typeテーブルに定型データが追加されます。
-- Create new warehouse locations #Request 497
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('PA-PIT-01', 'Pittsburgh Warehouse', 4567,
'APP_ADMIN' , SYSDATE);
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('LA-MSY-01', 'New Orleans Warehouse', 7134,
'APP_ADMIN' , SYSDATE);
-- Create new equipment_type #Request 562
INSERT INTO equipment_type (equipment_type_id, name,
min_insurance_value, max_insurance_value, created_by, created_dt)
VALUES (seq_equipment_type.nextval, 'Lift Truck',
40000, 4000000, 'APP_ADMIN', SYSDATE);
Navicat、DBArtisan、SQL Developerなどのスキーマ編集ツールを使用してスキーマを変更したり、アドホックDDLまたはDMLを実行して定型データを追加したり、問題を修正したりすることはありません。アプリケーションソフトウェアによるデータベースの更新以外、すべての変更は移行によって行われます。
移行をSQLコマンドのセットとして定義することは、ストーリーの一部ですが、それらを適切に適用するには、それらを管理するため追加の事項が必要です。
- 各移行には、一意の識別が必要です.
- データベースに適用された移行を追跡する必要があります
- 移行間のシーケンス制約を管理する必要があります。上記の例では、最初に
ALTER TABLE移行を適用する必要があります。そうでないと、2番目の移行で機器タイプを挿入できません。
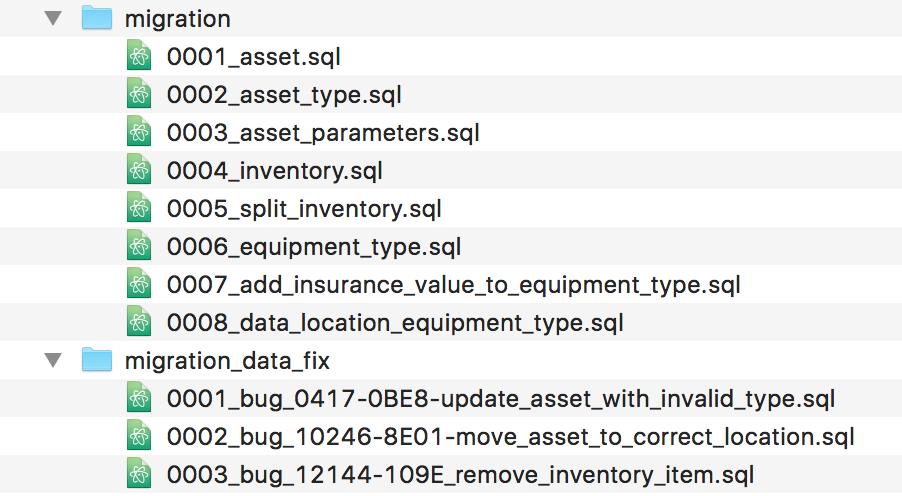
これらの要求を処理するために、各移行にシーケンス番号を付けます。これは一意の識別子として機能し、データベースに適用される順序を維持できるようにします。開発者が移行を作成するときは、プロジェクトのバージョン管理リポジトリ内の移行フォルダにあるテキストファイルにSQLを配置します。移行フォルダで現在使用されている最大の番号を調べ、その番号と説明を使用してファイルに名前を付けます。したがって、前の移行のペアは、0007_add_insurance_value_to_equipment_type.sqlおよび0008_data_location_equipment_typeと呼ばれる場合があります。
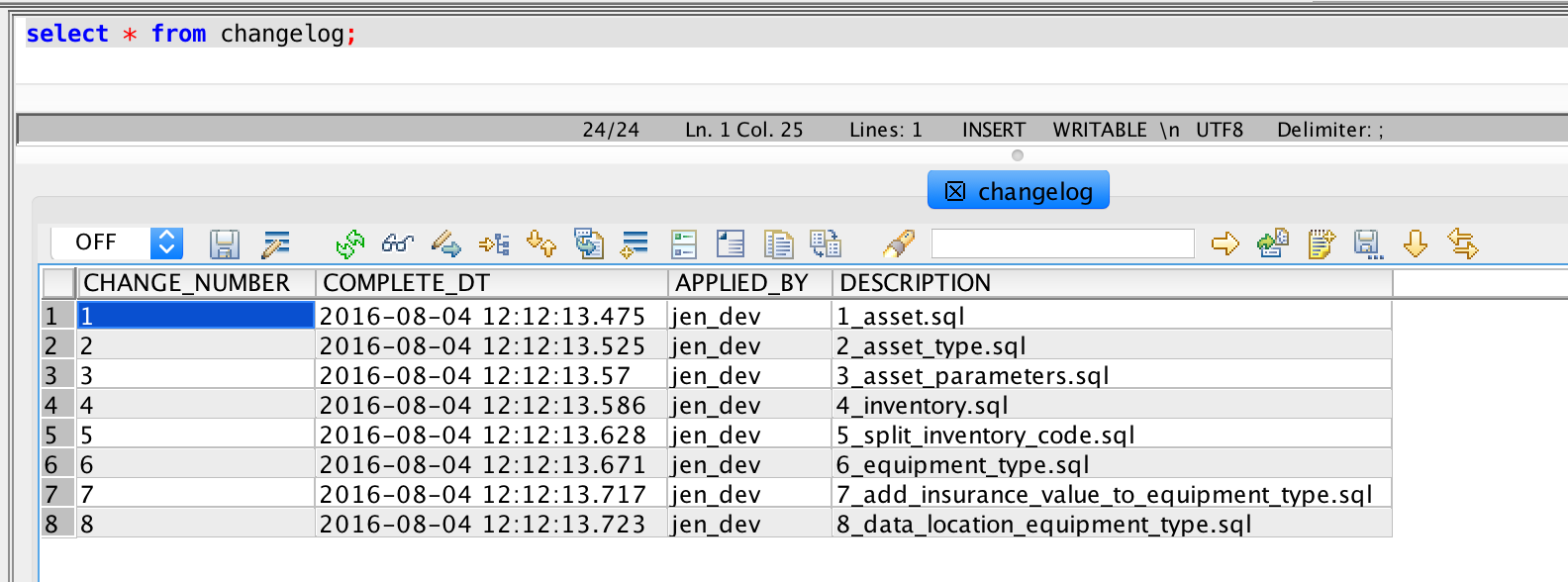
データベースへの移行の適用を追跡するために、changelogテーブルを使用します。データベース移行フレームワークは通常、このテーブルを作成し、移行が適用されるたびに自動的に更新します。こうすることで、データベースは常にどの移行と同期しているかを報告できます。そのようなフレームワークを使用しない場合、結局のところ、私たちがこれを始めたときには存在していませんでしたが、スクリプトでこれを自動化します。
この番号付けスキームがあれば、管理する多くのデータベースに適用される変更を追跡できます.
これらのデータ移行の一部は、新機能に関連する移行よりも頻繁にリリースする必要がある場合があります。そのシナリオでは、データ関連のバグ修正用に個別の移行リポジトリまたはフォルダを用意すると便利です。
これらの各フォルダは、Flyway、dbdeploy、MyBatisなどのデータベース移行ツール、または同様のツールによって個別に追跡でき、移行番号を格納するための個別のテーブルがあります。Flywayのプロパティflyway.tableは、移行メタデータが格納されているテーブルの名前を変更するために使用されます
全員が独自のデータベースインスタンスを持つ
ほとんどの開発組織は、組織のすべてのメンバーが使用する単一の開発データベースを共有しています。おそらくQAまたはステージングには別のデータベースが使用されますが、概念は実行中のデータベースの数を制限することです。このようなデータベースの共有は、データベースインスタンスの設定と管理が難しいため、組織がデータベースの数を最小限に抑えるようになった結果です。このような状況でスキーマを変更できるユーザーの制御はさまざまで、DBAチームを通じてすべての変更を加える必要がある場所もあれば、開発者が開発データベースのスキーマを変更できる場所もあり、変更が下流にプロモートされるとDBAが関与します。
アジャイルデータベースプロジェクトで作業を開始したとき、アプリケーション開発者は通常、コードのプライベートワーキングコピーで作業するというパターンに従っていることに気付きました。人々は試してみることで学ぶので、プログラミングの観点から、開発者は特定の機能を実装する方法を試して、1つを選択する前に数回試行することがあります。プライベートワークスペースで実験し、状況がより安定したら共有エリアにプッシュできることが重要です。誰もが共有エリアで作業している場合、彼らは未完成の変更で常に互いに邪魔をしています。数時間以内に統合が行われる継続的インテグレーションを支持しますが、プライベートワーキングコピーは依然として重要です。バージョン管理システムはこの作業をサポートし、開発者が独立して作業できるようにすると同時に、メインラインコピーに作業を統合することをサポートします。
この独立した作業はファイルで機能しますが、データベースでも機能します。各開発者は、他のユーザーの作業に触れることなく自由に修正できる独自のデータベースインスタンスを取得します。準備ができたら、次のセクションで説明するように、変更をプッシュして共有できます。
これらの個別のデータベースは、共有サーバー上の個別のスキーマにすることも、最近ではより一般的に、開発者のラップトップまたはワークステーションで実行されている個別のデータベースにすることもできます。10年前、データベースのライセンスコストにより、個々のデータベースインスタンスは法外に高価になる可能性がありましたが、最近では、特にオープンソースデータベースの人気が高まっているため、このようなことはめったにありません。開発者のマシンで実行されている仮想マシンでデータベースを実行すると便利であることがわかりました。データベースVMのビルドはVagrantとInfrastructure As Codeを使用して定義するため、開発者はデータベースVMの設定の詳細を知る必要も、手動で行う必要もありません。
多くのDBAは、複数のデータベースを忌み嫌うべきもの、実際には扱うのが難しいものと見なしていますが、私たちは100個程度のアプリケーションデータベースインスタンスを簡単に管理できることを発見しました。重要なのは、ファイルを操作するのと同じようにデータベースを操作できるツールを用意することです。
<target name="create_schema"
description="create a schema as defined in the user properties">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Creating Schema: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
CREATE USER ${db.username} IDENTIFIED BY ${db.password} DEFAULT TABLESPACE ${db.tablespace};
GRANT CONNECT,RESOURCE, UNLIMITED TABLESPACE TO ${db.username};
GRANT CREATE VIEW TO ${db.username};
ALTER USER ${db.username} DEFAULT ROLE ALL;
</sql>
</target>
開発者スキーマの作成は、ビルドスクリプトを使用してDBAの作業負荷を軽減することで自動化できます。この自動化は、開発環境のみに制限することもできます。
<target name="drop_schema">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Working UserName: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
DROP USER ${db.username} CASCADE;
</sql>
</target>
たとえば、開発者がプロジェクトに参加し、コードベースをチェックアウトして、ローカル開発環境のセットアップを開始するとします。彼女はテンプレートの `build.properties` ファイルを使用し、`db.username` を `Jen` に設定するなど、残りの設定を行います。これらの設定が完了したら、`ant create_schema` を実行するだけで、チーム開発データベースサーバーまたはラップトップ上のデータベースサーバーに独自のスキーマを取得できます。
スキーマが作成されると、データベースマイグレーションスクリプトを実行して、データベースインスタンスにすべてのデータベースコンテンツ(テーブル、インデックス、ビュー、シーケンス、ストアドプロシージャ、トリガー、シノニム、その他のデータベース固有のオブジェクト)を作成できます。
同様に、スキーマを削除するためのスクリプトもあります。不要になった場合、または開発者がクリーンアップして新しいスキーマからやり直したい場合などです。データベース環境は不死鳥(Phoenixes)であるべきです。定期的に焼き尽くし、自由に再構築します。そうすることで、再現不可能な、または監査されていない特性が環境に蓄積される危険性が少なくなります。
このプライベートワークスペースの必要性は、開発者だけでなく、チームの他のすべての人にも当てはまります。QAスタッフは独自のデータベースを作成する必要があります。そうすることで、知識外の変更によって混乱する危険性なしに作業できます。DBAは、モデリングオプションやパフォーマンチューニングを検討する際に、独自のデータベースコピーで実験できる必要があります。
開発者はデータベースの変更を継続的に統合する
開発者は自分のサンドボックスで頻繁に実験できますが、継続的インテグレーション(CI)を使用して、さまざまな変更を頻繁に統合することが不可欠です。CIには、メインラインソフトウェアを自動的にビルドおよびテストする統合サーバーのセットアップが含まれます。私たちの経験則では、各開発者は少なくとも1日に1回はメインラインに統合する必要があります。CIを支援する多くのツールが存在します。たとえば、GoCD、Snap CI、Jenkins、Bamboo、Travis CIなどです。
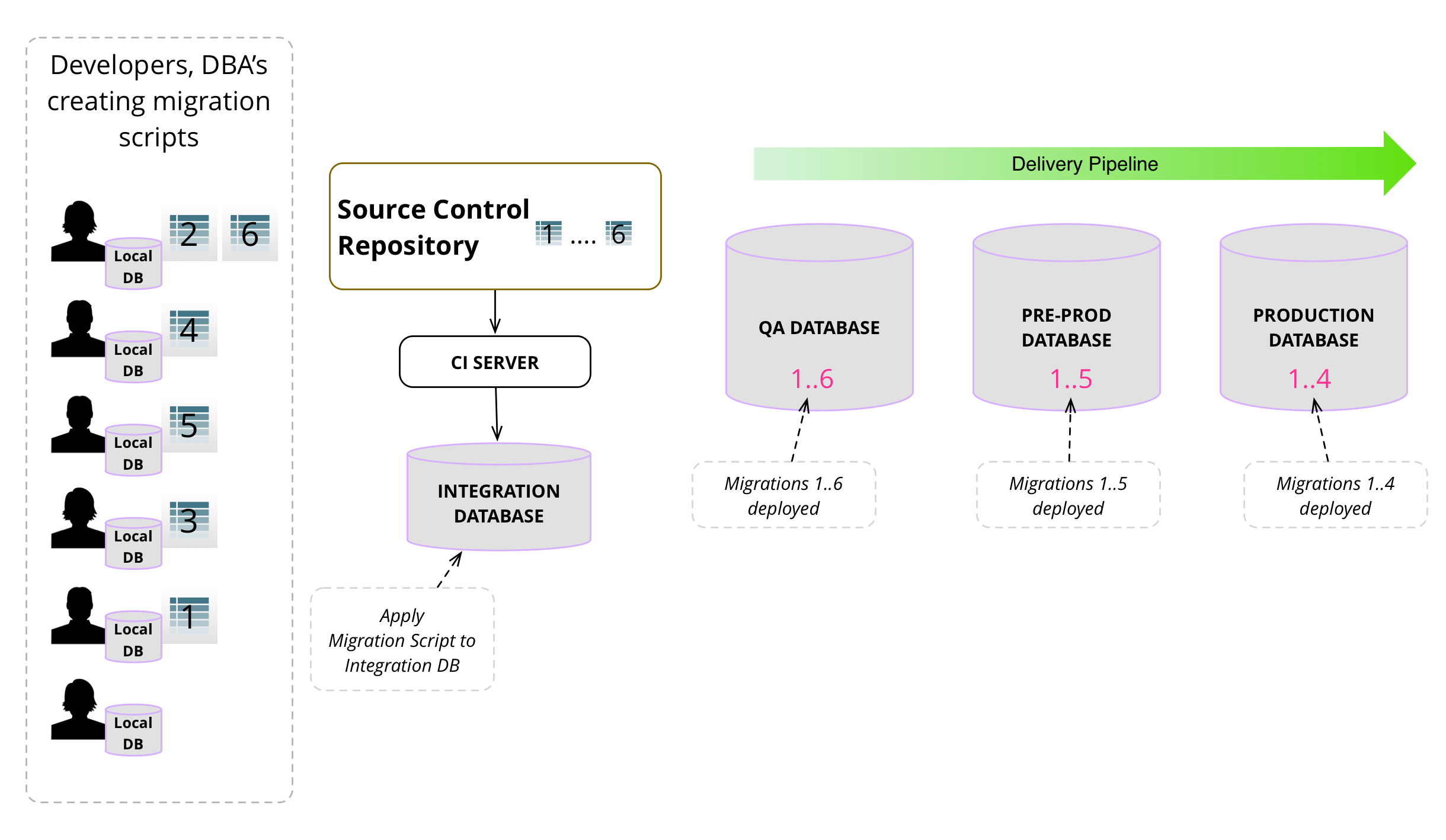
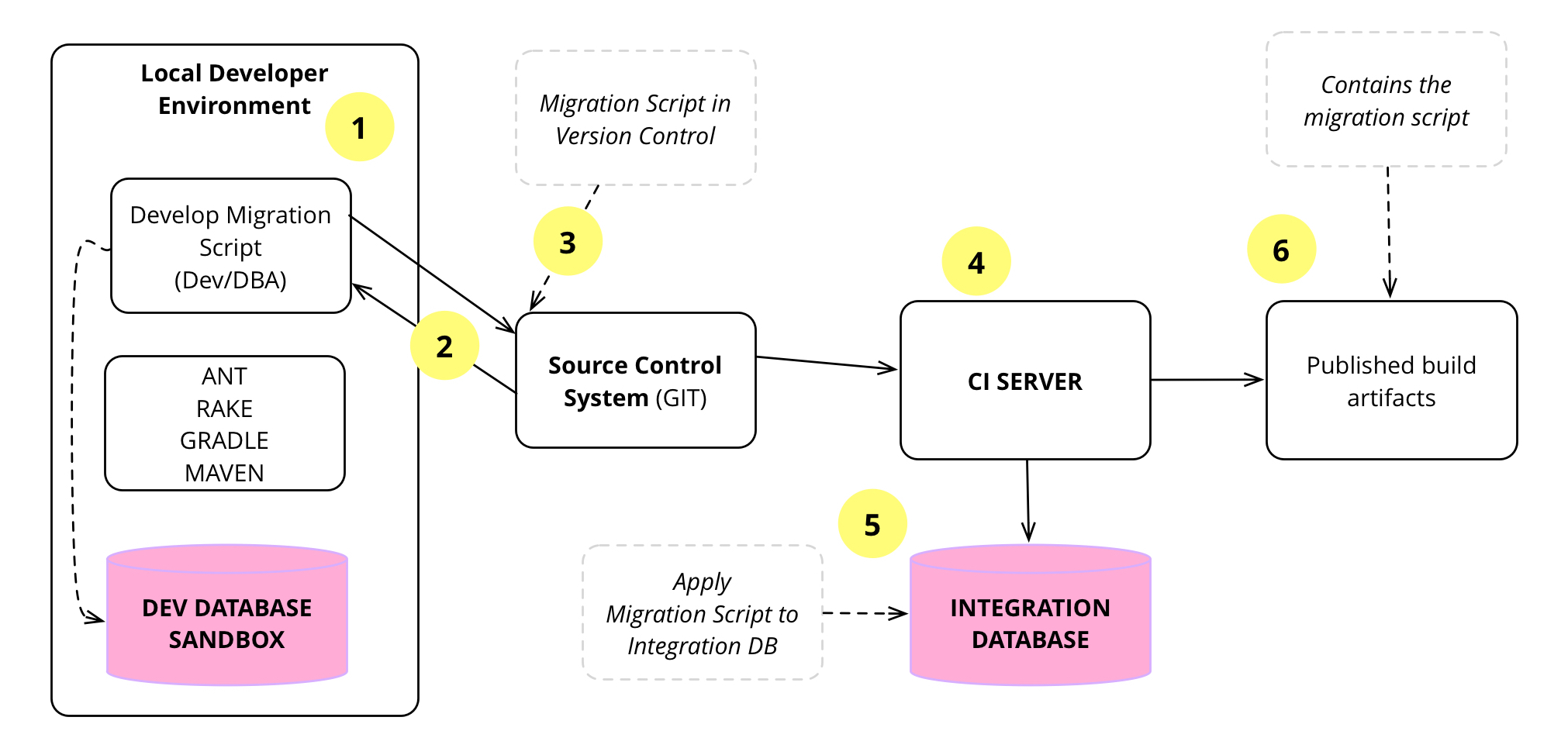
図7は、データベースマイグレーションがどのように開発、ローカルでテスト、ソース管理にチェックイン、CIサーバーによって取得され、統合データベースに適用、再テスト、そしてダウンストリームで使用するためにパッケージ化されるかの流れを示しています。
例を見てみましょう
1
Jenはデータベーススキーマの変更を含む開発を開始します。列の追加など、変更が簡単な場合は、Jenは変更を直接行う方法を決定します。複雑な場合は、DBAに相談します。
変更内容が整理できたら、マイグレーションを作成します。
ALTER TABLE project ADD projecttypeid NUMBER(10) NULL;
ALTER TABLE project ADD (CONSTRAINT fk_project_projecttype
FOREIGN KEY (projecttypeid)
REFERENCES projecttype DEFERRABLE INITIALLY DEFERRED);
UPDATE project
SET projecttypeid = (SELECT projecttypeid
FROM projecttype
WHERE name='Integration');
NULL可能な列の追加は後方互換性のある変更であるため、アプリケーションコードを変更することなく変更を統合できます。ただし、テーブルの分割など、後方互換性のない変更の場合は、Jenはアプリケーションコードも変更する必要があります。
2
Jenが変更を完了すると、統合の準備が整います。統合の最初のステップは、ローカルコピーをメインラインから更新することです。これらは、彼女がタスクに取り組んでいる間にチームの他のメンバーが行った変更です。次に、データベースを再構築し、すべてのテストを実行することにより、これらの更新で変更が機能することを確認します。
他の開発者の変更が彼女の変更と干渉するために問題が発生した場合は、コピーでそれらの問題を修正する必要があります。通常、このような衝突は簡単に解決できますが、場合によってはより複雑になります。多くの場合、これらのより複雑な競合は、Jenと彼女のチームメイトの間の会話を引き起こし、重複する変更を解決する方法を整理できます。
ローカルコピーが再び機能するようになったら、作業中にさらに変更がマスターにプッシュされたかどうかを確認します。プッシュされた場合は、新しい変更を使用して統合を繰り返す必要があります。ただし、通常、コードがメインラインと完全に統合されるまで、これらのサイクルは1つか2つ以上かかりません。
3
Jenは変更をメインラインにプッシュします。変更は既存のアプリケーションコードと後方互換性があるため、アプリケーションコードを更新して使用する前にデータベースの変更を統合できます。これは、並列変更の一般的な例です。
4
CIサーバーはメインラインの変更を検出し、データベースマイグレーションを含む新しいビルドを開始します。
5
CIサーバーはビルドに独自のデータベースコピーを使用するため、データベースマイグレーションスクリプトをこのデータベースに適用して、マイグレーションの変更を適用します。さらに、残りのビルド手順(コンパイル、単体テスト、機能テストなど)を実行します。
6
ビルドが正常に完了すると、CIサーバーはビルドアーティファクトをパッケージ化して公開します。これらのビルドアーティファクトにはデータベースマイグレーションスクリプトが含まれているため、デプロイメントパイプラインなどのダウンストリーム環境のデータベースに適用できます。ビルドアーティファクトには、jar、war、dllなどにパッケージ化されたアプリケーションコードも含まれています。
これはまさに、アプリケーションソースコード管理で一般的に使用される継続的インテグレーションの実践です。上記の手順は、データベースコードを別のソースコードとして扱うことについてです。そのため、データベースコード(DDL、DML、データ、ビュー、トリガー、ストアドプロシージャ)は、ソースコードと同じ方法で構成管理下に置かれます。データベースアーティファクトをアプリケーションアーティファクトとともにパッケージ化することにより、ビルドが成功するたびに、アプリケーションとデータベースの両方について完全で同期されたバージョン履歴が得られます。
アプリケーションソースコードでは、変更との統合の苦労の多くは、ソースコード管理システムとローカル環境でのさまざまなテストを使用することで処理できます。データベースの場合、ビジネスの意味を保持する必要があるデータ(状態)がデータベースにあるため、もう少し労力がかかります。(このような自動化されたデータベースリファクタリングについては、後で詳しく説明します。)さらに、DBAはデータベースの変更を調べ、データベーススキーマとデータアーキテクチャの全体的なスキームに適合することを確認する必要があります。これがすべてスムーズに機能するためには、統合時に大きな変更が驚きとなってはなりません。そのため、DBAは開発者と緊密に連携する必要があります。
頻繁に統合することをお勧めします。これは、まれに大きな統合を行うよりも、頻繁に小さな統合を行う方がはるかに簡単だからです。頻度が困難さを軽減するというケースです。統合の苦痛は統合のサイズとともに指数関数的に増加するため、多くの小さな変更を行う方が、直感に反するように見える場合でも、実際にははるかに簡単です。
データベースはスキーマとデータで構成される
ここでデータベースについて話すとき、データベースのスキーマとデータベースコードだけでなく、かなりの量のデータも意味します。このデータは、アプリケーションの一般的な固定データ(すべての州、国、通貨、住所の種類、およびさまざまなアプリケーション固有のデータの避けられないリストなど)で構成されます。また、サンプルの顧客、注文など、いくつかのサンプルテストデータを含める場合もあります。このサンプルデータは、サニティテストまたはセマンティックモニタリングに特に必要でない限り、本番環境にはなりません。
このデータが存在するのには、いくつかの理由があります。主な理由はテストを可能にすることです。私たちは、アプリケーションの開発を安定させるために、大量の自動テストを使用することを強く信じています。このようなテストの体系は、アジャイルメソッドでは一般的なアプローチです。これらのテストを効率的に機能させるには、いくつかのサンプルテストデータがシードされたデータベースで作業するのが理にかなっています。すべてのテストは、実行前にサンプルテストデータが配置されていると想定できます。
このサンプルデータはバージョン管理する必要があるため、新しいデータベースを作成する必要がある場合にどこを探せばよいかがわかり、テストとアプリケーションコードと同期された変更の記録があります。
コードのテストに加えて、このサンプルテストデータを使用すると、データベースのスキーマを変更するときにマイグレーションをテストすることもできます。サンプルデータを持つことにより、スキーマの変更がサンプルデータも処理することを保証する必要があります。
ほとんどのプロジェクトで、このサンプルデータは架空のものであることがわかりました。ただし、いくつかのプロジェクトでは、サンプルに実際のデータを使用している人がいます。これらの場合、このデータは、自動データ変換スクリプトを使用して、以前のレガシーシステムから抽出されました。初期のイテレーションでは新しいデータベースのごく一部しか実際に構築されていないため、明らかにすべてのデータをすぐに変換することはできません。ただし、増分移行を使用して変換スクリプトを開発し、必要なデータをジャストインタイムで提供できます。
これは、データ変換の問題を早期に洗い出すのに役立つだけでなく、ドメインエキスパートが見ているデータに精通しており、データベースとアプリケーションの設計に問題を引き起こす可能性のあるケースを特定するのに役立つため、成長するシステムで作業する方がはるかに簡単になります。その結果、プロジェクトの最初のイテレーションから実際のデータを導入するようにしてください。 Jailerはこのプロセスに役立つツールであることがわかりました。
すべてのデータベース変更はデータベースリファクタリングである
データベースに加える変更は、データベースが情報を格納する方法を変更したり、情報を格納する新しい方法を導入したり、不要になったストレージを削除したりします。しかし、データベースの変更だけでは、ソフトウェアの全体的な動作は変わりません。したがって、それらはリファクタリングの定義に適合すると見なすことができます。
観測可能な動作を変更することなく、ソフトウェアの内部構造を理解しやすく、変更のコストを削減するために加えられた変更
-- リファクタリング(第2章)
これを認識して、これらのリファクタリングの多くを収集して文書化しました。このようなカタログを作成することで、以前に正常に使用した手順に従うことができるため、これらの変更を正しく行うことが容易になります。
データベースリファクタリングの大きな違いの1つは、一緒に実行する必要がある3つの異なる変更が含まれていることです。
- データベーススキーマの変更
- データベース内のデータの移行
- データベースアクセスコードの変更
したがって、データベースリファクタリングについて説明する場合は、変更の3つの側面すべてについて説明し、他のリファクタリングを適用する前に3つすべてが適用されていることを確認する必要があります。
コードリファクタリングと同様に、データベースリファクタリングは非常に小さいです。一連の非常に小さな変更を連鎖させるという概念は、データベースの場合もコードの場合とほぼ同じです。変更の3次元性は、小さな変更を維持することをさらに重要にします。
多くのデータベースリファクタリング(新しいカラムの導入など)は、システムにアクセスするすべてのコードを更新することなく実行できます。コードが新しいスキーマを認識せずに使用する場合、そのカラムは単に使用されないだけです。しかし、多くの変更はこの特性を持たず、これを**破壊的な変更**と呼びます。破壊的な変更は、より注意深く行う必要があります。その程度は、変更による破壊の程度によって異なります。
軽微な破壊的変更の例として、NULL許容カラムをNULL非許容に変更するカラムをNULL非許容にするがあります。これは、既存のコードで値が設定されていない場合にエラーが発生するため、破壊的な変更です。また、既存のデータにNULL値がある場合にも問題が発生します。
NULL値を持つすべての行にデフォルトデータを割り当てることで、既存のNULL値に関する問題を回避できます(ただし、わずかに異なる問題が発生する可能性があります)。アプリケーションコードが値を割り当てない(またはNULLを割り当てる)問題については、2つの選択肢があります。1つは、カラムにデフォルト値を設定することです。
ALTER TABLE customer
MODIFY last_usage_date DEFAULT sysdate;
UPDATE customer
SET last_usage_date =
(SELECT MAX(order_date) FROM order
WHERE order.customer_id = customer.customer_id)
WHERE last_usage_date IS NULL;
UPDATE customer
SET last_usage_date = last_updated_date
WHERE last_usage_date IS NULL;
ALTER TABLE customer
MODIFY last_usage_date NOT NULL;
値が割り当てられない問題に対処するもう1つの方法は、リファクタリングの一環としてアプリケーションコードを変更することです。これは、データベースを更新するすべてのコードに確実にアクセスできる場合に推奨されるオプションです。これは通常、データベースが単一のアプリケーションによってのみ使用される場合は簡単ですが、共有データベースの場合は困難です。
より複雑なケースは、テーブルの分割です。特に、テーブルへのアクセスがアプリケーションコード全体に広く分散している場合です。この場合、変更が予定されていることを全員に知らせて、準備できるようにすることが重要です。イテレーションの開始など、比較的静かな時期を待つことも賢明かもしれません。
データベースアクセスがすべてシステムの少数のモジュールを介して行われる場合、破壊的な変更ははるかに容易になります。これにより、データベースアクセスコードを見つけて更新することが容易になります。
全体的に重要なのは、行っている変更の種類に適した手順を選択することです。疑問がある場合は、変更を容易にする方に傾けてください。私たちの経験では、多くの人が考えるほど頻繁に問題が発生することはありませんでした。システム全体の強力な構成管理があれば、最悪の事態が発生した場合でも、元に戻すことは難しくありません。
開発中にDDL、DML、データ移行を含むデータベースの変更に対応することで、データチームに最も多くのコンテキストを提供し、デプロイメント時にデータチームがコンテキストなしですべての変更を一括移行することを回避できます。
移行フェーズ
破壊的なデータベースリファクタリングを実行し、アクセスコードを簡単に変更できない場合に発生する困難については、既に触れました。これらの問題は、多くのアプリケーションやレポートで使用されている可能性のある共有データベースがある場合、より深刻になります。このような状況では、テーブル名の変更など、より注意深く行う必要があります。このような問題から身を守るために、移行フェーズに移行します。
**移行フェーズ**とは、データベースが古いアクセス パターンと新しいアクセス パターンの両方を同時にサポートする期間です。これにより、古いシステムは自分のペースで新しい構造に移行する時間が得られます。
ALTER TABLE customer RENAME to client;
CREATE VIEW customer AS
SELECT id, first_name, last_name FROM client;
テーブル名の変更の例では、開発者はテーブル`customer`の名前を`client`に変更するスクリプトを作成し、既存のアプリケーションが使用できる`customer`という名前の`view`も作成します。この並列変更は、新旧両方のアクセスをサポートします。複雑さが増すため、ダウンストリームシステムが移行する時間を確保したら、削除することが重要です。組織によっては、これは数か月で完了する場合もあれば、数年かかる場合もあります。
ビューは、移行フェーズを有効にするための1つの手法です。カラム名の変更などに便利なデータベーストリガーも使用します。
リファクタリングを自動化する
リファクタリングがアプリケーションコードでよく知られるようになって以来、多くの言語で自動リファクタリングがサポートされるようになりました。これらは、人間がミスをすることなくさまざまな手順を迅速に実行することで、リファクタリングを簡素化し、高速化します。このような自動化はデータベースでも利用できます。LiquibaseやActive Record Migrationsなどのフレームワークは、データベースリファクタリングを適用するためのDSLを提供し、データベースマイグレーションを適用するための標準的な方法を可能にします。
ただし、データ移行とレガシーデータを処理するためのルールはチームの特定のコンテキストに大きく依存するため、この種の標準化されたリファクタリングはデータベースではうまく機能しません。そのため、移行用のスクリプトを作成し、適用方法を自動化するツールに焦点を当てることで、データベースリファクタリングを処理することをお勧めします。
これまですべて示してきたように、SQL DDL(スキーマ変更用)とDML(データ移行用)を組み合わせて、結果をバージョン管理リポジトリのフォルダーに配置することで、各スクリプトを作成します。自動化により、これらの変更を手動で適用することはありません。自動化ツールによってのみ適用されます。こうすることで、リファクタリングの順序を維持し、データベースメタデータを更新します。
リファクタリングは任意のデータベースインスタンスに適用して、最新のマスターまたは以前のバージョンに更新できます。このツールは、データベースのメタデータ情報を使用して現在のバージョンを特定し、現在のバージョンと目的のバージョンとの間の各リファクタリングを適用します。このアプローチを使用して、開発インスタンス、テストインスタンス、本番データベースを更新できます。
本番データベースの更新はテストデータベースと変わりません。異なるデータに対して同じスクリプトセットを実行します。更新を小さく保つために頻繁にリリースすることをお勧めします。これは、更新がより迅速に行われ、発生する可能性のある問題に対処しやすくなるためです。これらの更新を行う最も簡単な方法は、更新を適用している間、本番データベースを停止することです。これはほとんどの状況でうまく機能します。アプリケーションを稼働させたまま更新する必要がある場合は可能ですが、使用する手法については別の記事で説明する必要があります。
これまでのところ、この手法は非常にうまく機能していることがわかりました。すべてのデータベースの変更を小さく、単純な変更のシーケンスに分割することにより、問題なく本番データに非常に大きな変更を加えることができました。
前方変更の自動化に加えて、各リファクタリングのリバース変更の自動化を検討できます。これを行うと、同じ自動化された方法でデータベースの変更を元に戻すことができます。私たちは、これが費用対効果が高く、常に試みるのに十分なメリットがあるとは考えていません。また、それほど需要もありませんが、基本的な原則は同じです。全体として、データベースアクセスセクションがデータベースの新旧両方のバージョンで動作するように、マイグレーションを作成することをお勧めします。これにより、将来のニーズをサポートするようにデータベースを更新して稼働させ、本番環境でしばらく実行してから、新しいデータ構造を使用する更新を、問題なく安定していることが確認された後にのみプッシュできます。
最近では、Flyway、Liquibase、MyBatis migrations、DBDeployなど、データベースマイグレーションの適用を自動化するツールが多数あります。Flywayでマイグレーションを適用する方法は次のとおりです。
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 9 migrations (execution time 00:00.021s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Successfully applied 9 migrations to schema "JEN_DEV" (execution time 00:00.394s).
psadalag:flyway-4 $
開発者はオンデマンドでデータベースを更新できる
上記で説明したように、変更をメインラインに統合する最初のステップは、作業中に発生した変更をすべてプルすることです。これは、統合ステップ中に不可欠であるだけでなく、完了する前に役立つことがよくあります。そのため、同僚が話している変更の影響を評価できます。どちらの場合も、メインラインから変更を簡単にプルしてローカルデータベースに適用できることが重要です。
まず、メインラインからローカルワークスペースに変更をプルすることから始めます。多くの場合、これは非常に簡単ですが、作業中に同僚がマイグレーションをメインラインにプッシュしたことに気付く場合があります。シーケンス番号`8`でマイグレーションを作成した場合、マイグレーションフォルダーにその番号の別のマイグレーションが表示されます。マイグレーションツールを実行すると、これが検出されます
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
ERROR: Found more than one migration with version 8
Offenders:
-> /Users/psadalag/flyway-4/sql/V8__data_location_equipment_type.sql (SQL)
-> /Users/psadalag/flyway-4/sql/V8__introduce_fuel_type.sql (SQL)
psadalag:flyway-4 $
衝突が発生したことがわかったら、最初のステップは簡単です。メインラインの新しいマイグレーションの上に適用されるように、マイグレーションの番号を`9`に変更する必要があります。番号を変更したら、マイグレーション間に競合がないことをテストする必要があります。これを行うには、データベースをクリーンアップし、新しい`8`と番号が変更された`9`を含むすべてのマイグレーションを空のデータベースコピーに適用します。
psadalag:flyway-4 $ mv sql/V8__introduce_fuel_type.sql sql/V9__introduce_fuel_type.sql
psadalag:flyway-4 $ ./flyway clean
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully cleaned schema "JEN_DEV" (execution time 00:00.031s)
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 10 migrations (execution time 00:00.013s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Migrating schema "JEN_DEV" to version 9 - introduce fuel type
Successfully applied 10 migrations to schema "JEN_DEV" (execution time 00:00.435s).
psadalag:flyway-4 $
通常、これは正常に機能しますが、場合によっては競合が発生することがあります。たとえば、他の開発者が変更を加えているテーブルの名前を変更した可能性があります。その場合は、競合を解決する方法を理解する必要があります。ここでは、マイグレーションの規模が小さいため、競合の発見と対処が容易になります。
最後に、データベースの変更が統合されたら、メインラインから取得したマイグレーションによってテストが中断される場合に備えて、アプリケーションテストスイートを再実行する必要があります。
この手順により、ネットワーク接続がなくても短期間独立して作業し、都合の良いときに統合できます。この統合をいつ、どのくらいの頻度で行うかは、メインラインにプッシュする前に同期していることを確認する限り、完全に私たち次第です。
すべてのデータベースアクセスコードを明確に分離する
データベースリファクタリングの結果を理解するには、アプリケーションがデータベースをどのように使用しているかを確認できることが重要です。SQLがコードベース全体に散らばっていると、これは非常に困難です。そのため、データベースがどこでどのように使用されているかを示す明確なデータベースアクセスレイヤーを用意することが重要です。これを行うために、P ofEAAのデータソースアーキテクチャパターンのいずれかに従うことをお勧めします。
明確なデータベースレイヤーを用意することには、多くの貴重な副次的なメリットがあります。開発者がデータベースを操作するためにSQLの知識を必要とするシステムの領域を最小限に抑えることができます。これにより、SQLに特に精通していない開発者の作業が楽になります。DBAにとっては、データベースの使用方法を確認できるコードの明確なセクションが提供されます。これは、インデックスの準備、データベースの最適化、およびSQLのパフォーマンスを向上させるための再構成方法の検討に役立ちます。これにより、DBAはデータベースの使用方法をより深く理解できます。
頻繁にリリースする
私たちがこの記事の最初のバージョンを10年以上前に書いたとき、ソフトウェアを本番環境に頻繁にリリースすべきだという考えに対する支持はほとんどありませんでした。それ以来、インターネット大手の台頭は、リリースの迅速な連続が成功するデジタル戦略の重要な部分であることを示しています。
すべての変更がマイグレーションに捕捉されるため、新しい変更をテスト環境と本番環境に簡単にデプロイできます。ここで説明する進化型のデータベース設計は、頻繁なリリースを可能にするための重要な要素であると同時に、ソフトウェアが実際に使用されている様子からのフィードバックから得られる学習からもメリットがあります。






{kind=link}