
ジェネレーティブAIを探求する

ジェネレーティブAI、特にLLM(大規模言語モデル)は、一般の意識の中に急速に広がっています。多くのソフトウェア開発者と同様に、私もその可能性に興味をそそられますが、長期的には私たちの職業にとって正確に何を意味するのか確信が持てません。現在、私はThoughtworksで、このテクノロジーがソフトウェアデリバリーの実践にどのように影響するかについての私たちの取り組みを調整する役割を担っています。同僚と私が学んで考えていることを説明するさまざまなメモをここに投稿する予定です。
過去のメモ
ツールチェーン(2023年7月26日)
中央値 - 3つの関数の物語(2023年7月27日)
インラインアシスタンス - より役立つのはいつか? (2023年8月1日)
インラインアシスタンス - どのように邪魔になるのか? (2023年8月3日)
コーディングアシスタントはペアプログラミングの代わりにはならない(2023年8月10日)
コーディングアシスタントはペアプログラミングの代わりにはならない
以前のメモで示されたように、私はGenAI搭載のコーディングアシスタントを開発者ツールチェーンへの非常に便利な追加物だと考えています。特定の場合にはコードの記述を明らかにスピードアップし、行き詰まった状態から抜け出し、より速く物事を覚えたり調べたりするのに役立ちます。これまでのメモは主にIDEでのインラインアシスタンスに関するものでしたが、チャットボットインターフェイスを追加すると、さらに便利なアシスタンスの可能性が広がります。特に強力なのは、IDEに統合されたチャットインターフェイスであり、プロンプトで明示する必要のないコードベースの追加コンテキストによって強化されています。
しかし、私はその可能性を認識していますが、正直なところ、コーディングアシスタントをペアプログラミングの代替として語る人々にかなり不満を感じます(GitHubは、Copilot製品を「あなたのAIペアプログラマー」とさえ呼んでいます)。Thoughtworksでは、チームをより効果的にするために、長年にわたってペアプログラミングとペアリング全般を強く支持してきました。それは、プロジェクトの開始点として使用する「理にかなったデフォルトプラクティス」の一部です。
コーディングアシスタントをペアプログラマーとして捉えることは、このプラクティスを軽視するものであり、ペアリングのメリットに対する広く普及している単純化された理解と誤解を助長します。私は、ペアリングについて語るために使用するスライドのセットと、このサイトで公開されている包括的な記事を振り返り、そこで言及しているすべてのメリットを1つのスライドにまとめました。
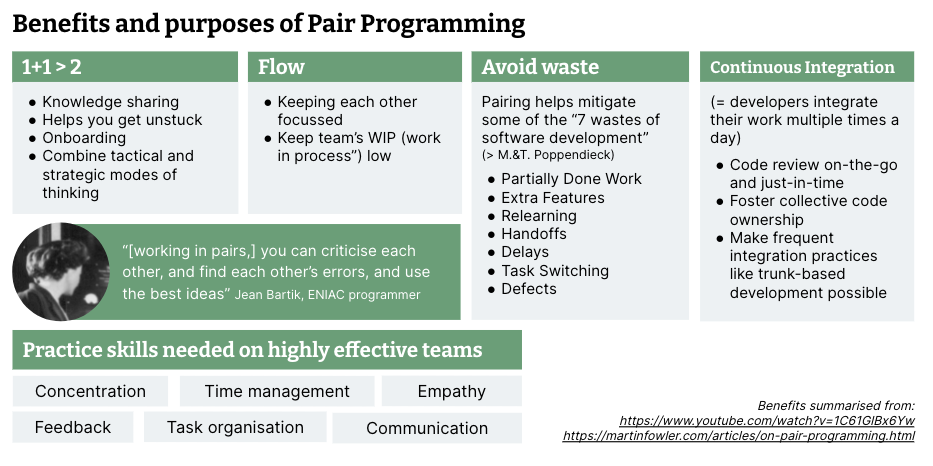
コーディングアシスタントがここで最も明確な影響を与えることができるのは、最初の「1 + 1 は 2 より大きい」という点です。それらは私たちが立ち往生しているときに助けになり、オンボーディングを改善し、戦術的な作業をより迅速に行うのに役立ち、全体的なソリューションの設計、つまり戦略的な面に集中できるようになります。また、「このテクノロジーはどのように機能するのか?」という意味で、知識の共有にも役立ちます。
しかし、ペアプログラミングは、集団的なコード所有権とコードベースの歴史に関する共有知識を生み出すタイプの知識共有についても含まれます。それは、どこにも書き留められていない、したがって大規模言語モデルも利用できない暗黙知を共有することです。ペアリングは、チームのフローを改善し、無駄をなくし、継続的インテグレーションを容易にするのにも役立ちます。コミュニケーション、共感、フィードバックのやり取りなどのコラボレーションスキルを実践するのに役立ちます。また、リモートファーストのチームでは、お互いの絆を深める貴重な機会を提供します。
結論
コーディングアシスタントは、ペアプログラミングの目標とメリットのごく一部しかカバーできません。それは、ペアリングが個々のコーダーだけでなく、チーム全体を改善するのに役立つプラクティスだからです。適切に行われれば、コミュニケーションとコラボレーションのレベルが向上し、フローと集団的なコード所有権が向上します。LLM支援コーディングのリスクは、ペアでこれらのツールを使用することで最も軽減されるとさえ主張できます(以前のメモの「どのように妨げになるか」を参照)。
ペアをより良くするためにコーディングアシスタントを使用し、ペアリングの代替として使用しないでください。
GitHub Copilotを使用したTDD(2023年8月17日)
GitHub Copilotを使用したTDD
作成者:Paul Sobocinski
GitHub CopilotのようなAIコーディングアシスタントの出現は、テストが不要になることを意味するのでしょうか?TDDは時代遅れになるのでしょうか?これに答えるために、ソフトウェア開発におけるTDDが役立つ2つの方法、つまり、優れたフィードバックを提供することと、問題を解決する際の「分割統治」の手段を調べてみましょう。
優れたフィードバックのためのTDD
優れたフィードバックは、迅速かつ正確です。どちらの点においても、適切に記述された単体テストから始めることに勝るものはありません。手動テストでも、ドキュメントでも、コードレビューでも、そして、ジェネレーティブAIでさえもです。実際、LLMは無関係な情報を提供し、ハルシネーション(幻覚)を起こすことさえあります。TDDは、AIコーディングアシスタントを使用する場合に特に必要です。私たちが記述するコードに迅速かつ正確なフィードバックが必要なのと同様に、AIコーディングアシスタントが記述するコードにも迅速かつ正確なフィードバックが必要です。
問題を分割統治するためのTDD
分割統治による問題解決とは、小さな問題を大きな問題よりも早く解決できることを意味します。これにより、継続的インテグレーション、トランクベース開発、そして最終的には継続的デリバリーが可能になります。しかし、AIアシスタントが私たちの代わりにコーディングを行う場合、これらすべてが本当に必要なのでしょうか?
はい。LLMが1つのプロンプトで必要な機能を正確に提供することはめったにありません。そのため、反復開発はまだなくなることはありません。また、LLMは、連鎖思考プロンプトを介して問題を段階的に解決すると、「推論を引き出す」(リンクされた調査を参照)ようです。LLMベースのAIコーディングアシスタントは、問題を分割統治する場合に最高のパフォーマンスを発揮し、TDDはソフトウェア開発でそれを行う方法です。
GitHub CopilotのTDDのヒント
Thoughtworksでは、年初からTDDでGitHub Copilotを使用してきました。私たちの目標は、ツールの使用に関する一連の効果的なプラクティスを実験、評価、進化させることです。
0. はじめに

空のテストファイルから始めることは、空のコンテキストから始めることを意味しません。私たちは多くの場合、いくつかの簡単なメモを含むユーザーストーリーから始めます。また、ペアリングパートナーと開始点について話し合います。
これはすべて、Copilotがオープンファイル(テストファイルの先頭など)に入れるまで「見え」ないコンテキストです。Copilotは、タイプミス、箇条書き、文法が不十分な場合でも機能します。しかし、空のファイルでは機能しません。
効果的だった開始コンテキストの例をいくつか示します。
- ASCIIアートのモックアップ
- 受け入れ基準
- 次のようなガイディング仮説
- 「GUIは不要」
- 「オブジェクト指向プログラミングを使用する」(関数型プログラミングではなく)
Copilotはオープンファイルをコンテキストとして使用するため、テストファイルと実装ファイルの両方をオープン(たとえば、横並び)にしておくと、Copilotのコード補完能力が大幅に向上します。
1. 赤
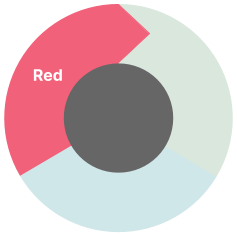
まず、説明的なテスト例の名前を記述することから始めます。名前が説明的であるほど、Copilotのコード補完のパフォーマンスが向上します。
Given-When-Then構造は、3つの点で役立つことがわかりました。まず、ビジネスコンテキストを提供するように促します。次に、Copilotがテスト例に対して豊富で表現力豊かな命名推奨を提供できるようにします。第三に、ファイルの先頭コンテキスト(前のセクションで説明)からCopilotが問題を「理解」していることを明らかにします。
たとえば、バックエンドコードに取り組んでいて、Copilotがテスト例の名前を「given the user…clicks the buy button」とコード補完する場合、これは、ファイルの先頭コンテキストを「GUIは想定しない」または、「このテストスイートはPython FlaskアプリのAPIエンドポイントとインターフェースする」と指定する必要があることを示しています。
注意すべきその他の「落とし穴」
- Copilotは、一度に複数のテストをコード補完する場合があります。これらのテストはしばしば役に立ちません(削除します)。
- テストを追加すると、Copilotは一度に1行ずつではなく複数行をコード補完します。多くの場合、テスト名から正しい「準備」ステップと「実行」ステップを推測します。
- 注意点:正しい「アサート」ステップを推測することはめったにないため、「グリーン」ステップに進む前に、新しいテストが正しく失敗していることに特に注意します。
2. グリーン
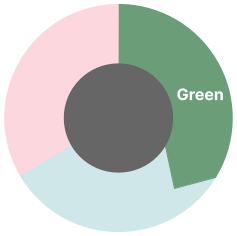
これで、実装でCopilotの助けを得る準備ができました。既存の、表現力豊かで読みやすいテストスイートは、このステップでCopilotの可能性を最大限に引き出します。
そうは言っても、Copilotはしばしば「小さなステップ」を踏むことに失敗します。たとえば、新しいメソッドを追加する場合、「小さなステップ」とは、テストに合格するハードコードされた値を返すことを意味します。現在まで、Copilotにこのアプローチを取らせることはできていません。
テストのバックフィル
「ベビーステップ」を踏む代わりに、Copilotは先回りして、しばしば関連性はあるものの、まだテストされていない機能を提供します。その対策として、私たちは不足しているテストを「後埋め」しています。これは標準的なTDDの流れからは逸脱していますが、この対策によって深刻な問題が発生したことはまだありません。
削除と再生成
更新が必要な実装コードについては、Copilotを活用する最も効果的な方法は、実装を削除し、コードを最初から再生成させることです。これがうまくいかない場合は、メソッドの内容を削除し、コードコメントを使用してステップバイステップのアプローチを記述すると役立つことがあります。それでもうまくいかない場合は、Copilotを一時的にオフにして、手動で解決策をコーディングするのが最善の方法かもしれません。
3. リファクタリング
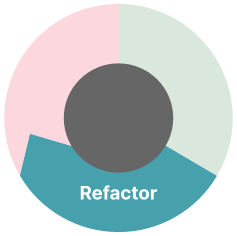
TDDにおけるリファクタリングとは、動作(および動作するコードベース)を維持しながら、コードベースの保守性と拡張性を向上させるための段階的な変更を行うことを意味します。
この点において、Copilotの能力は限定的であることがわかりました。2つのシナリオを考えてみましょう。
- 「試したいリファクタリングの動きがわかっている場合」:IDEのリファクタリングショートカットや、マルチカーソル選択などの機能を使う方が、Copilotよりも早く目的を達成できます。
- 「どのリファクタリングの動きをすべきかわからない場合」:Copilotのコード補完機能では、リファクタリングをガイドすることはできません。ただし、Copilot ChatはIDE内で直接、コード改善の提案を行うことができます。私たちはその機能を試行し始めており、小規模で局所的な範囲で有用な提案ができる可能性があると考えています。しかし、(単一のメソッド/関数を超える)大規模なリファクタリングの提案については、まだ大きな成功を収めていません。
リファクタリングの動きはわかっているものの、それを実行するために必要な構文がわからない場合があります。たとえば、依存関係を注入できるようにするテストモックを作成する場合です。このような状況では、コードコメントでプロンプトを入力すると、Copilotがインラインで回答を提供できます。これにより、ドキュメントやウェブ検索にコンテキストを切り替える手間が省けます。
結論
「ゴミを入れればゴミが出る」というよく言われる言葉は、データエンジニアリングだけでなく、生成AIやLLMにも当てはまります。言い換えれば、入力の質が高ければ高いほど、LLMの能力をより有効に活用できます。私たちの場合、TDDは高いレベルのコード品質を維持します。この高品質な入力によって、Copilotのパフォーマンスは、そうでない場合よりも向上します。
したがって、CopilotをTDDとともに使用することをお勧めします。上記のヒントが、その際に役立つことを願っています。
Thoughtworksカナダで始まった「Copilotとのアンサンブル」チームに感謝します。彼らは、このメモで取り上げた調査結果の主な情報源です。Om、Vivian、Nenad、Rishi、Zack、Eren、Janice、Yada、Geet、Matthew。
GenAIは他のコードジェネレーターとどう違うのか?(2023年9月19日)
GenAIは他のコードジェネレーターとどう違うのか?
キャリアの初期の頃、私はモデル駆動開発(MDD)の分野で多くの仕事をしていました。私たちは、ドメインやアプリケーションを表すモデリング言語を考案し、その言語でグラフィカルまたはテキスト形式(カスタマイズされたUML、またはDSL)で要件を記述していました。次に、これらのモデルをコードに変換するコードジェネレーターを構築し、開発者が実装およびカスタマイズする指定領域をコード内に残していました。
しかし、このスタイルのコード生成は、組み込み開発の一部の領域を除いて、あまり普及しませんでした。その理由は、抽象化のレベルが中途半端であり、ほとんどの場合、フレームワークやプラットフォームなどの他の抽象化レベルよりもコスト対効果が高くないためだと思います。
GenAIによるコード生成の何が違うのか?
ソフトウェアエンジニアリングの仕事で私たちが継続的に行う重要な決定の1つは、実装の労力と、ユースケースに必要なカスタマイズと制御のレベルとの間で適切なバランスをとるために、適切な抽象化レベルを選択することです。業界として、実装の労力を削減し、より効率的になるために、抽象化レベルを上げようとし続けています。しかし、それには、必要な制御のレベルによって制限される、一種の目に見えない力場があります。ローコードプラットフォームの例を挙げると、抽象化レベルを上げて開発労力を削減しますが、その結果、特定の種類のシンプルで簡単なアプリケーションに最も適しています。よりカスタムで複雑なことを行う必要があるとすぐに、力場にぶつかり、抽象化レベルを再び下げる必要があります。
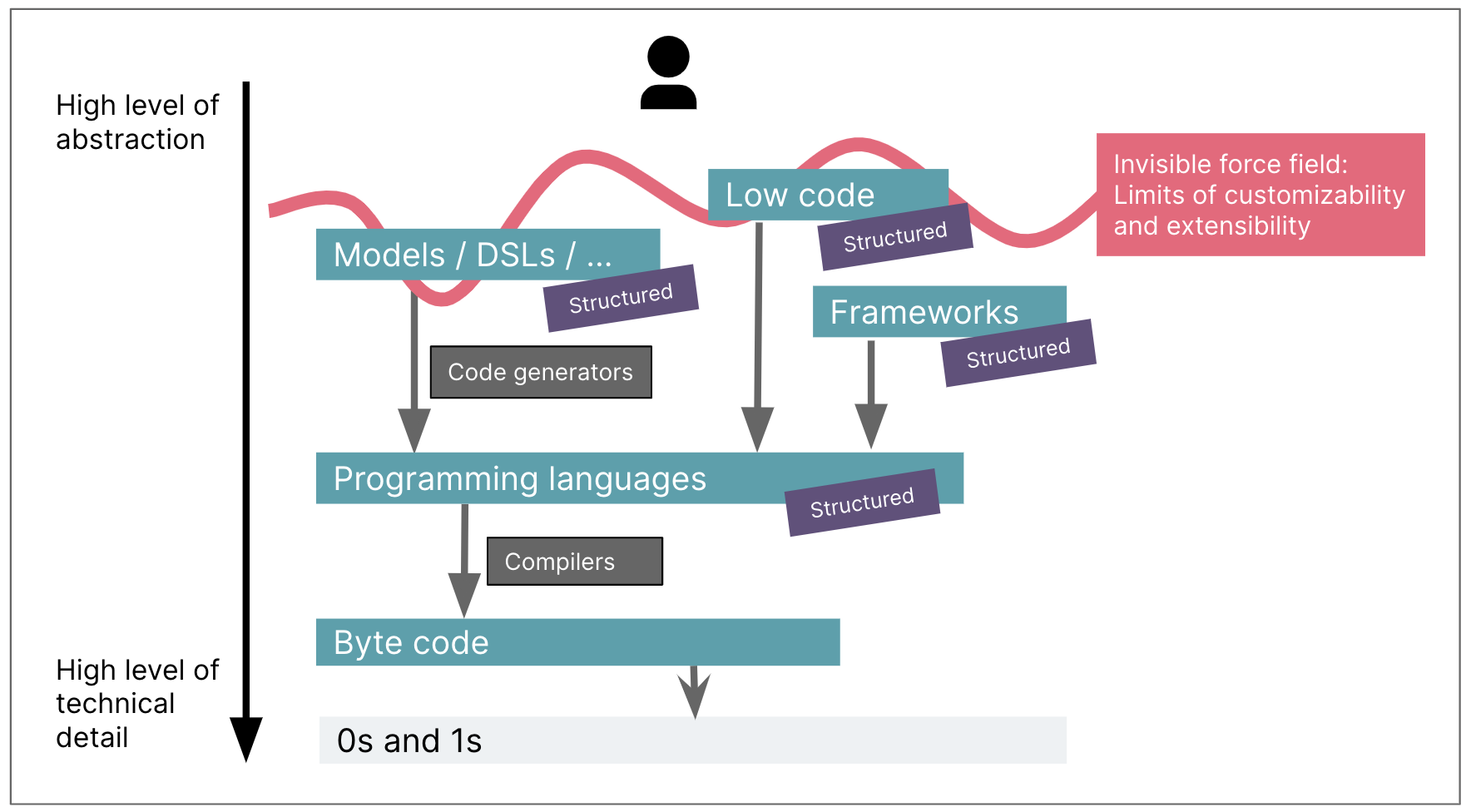
GenAIは、その力場を打ち砕こうとする別の試みではないため、新たな可能性を切り開きます。代わりに、コンパイラーやコードジェネレーターのような構造化された言語やトランスレーターを正式に定義する必要なく、すべての抽象化レベルで人間がより効果的になるようにすることができます。
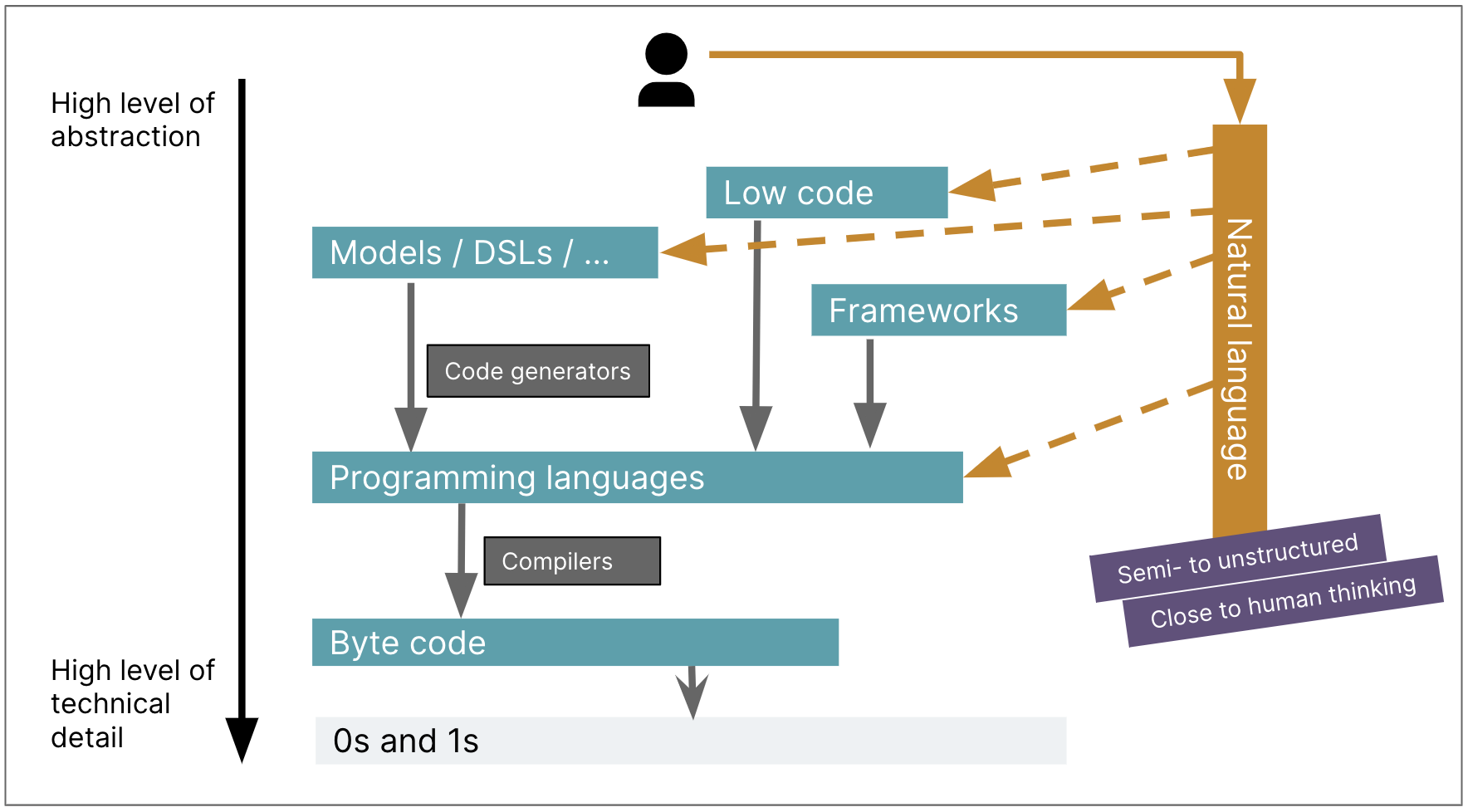
GenAIを適用するために抽象化レベルを高くすればするほど、ソフトウェアを構築するための全体的な労力は少なくなります。ローコードの例に戻ると、いくつかのプロンプトだけでフルアプリケーションを構築できることを示す素晴らしい例が、この分野にはいくつかあります。ただし、これは、カバーできるユースケースの点で、ローコード抽象化レベルの同じ制限が伴います。ユースケースがその力場にぶつかり、より多くの制御が必要な場合は、より低い抽象化レベルに戻り、より小さなプロンプト可能なユニットに戻る必要があります。
抽象化レベルを再考する必要があるか?
私がソフトウェアエンジニアリングにおけるGenAIの可能性について推測する際のアプローチの1つは、自然言語プロンプトと、ターゲットの抽象化レベルとの間の抽象化の距離について考えることです。上記でリンクしたGoogleのAppSheetデモでは、非常に高レベルのプロンプト(「チームが旅行リクエストを追跡するのに役立つアプリを作成する必要がある[…]フォームに入力[…]リクエストはマネージャーに送信する必要がある[…]」)を使用して、機能するローコードアプリケーションを作成しています。たとえば、SpringとReactのフレームワークコードで同じ結果を得るために、そのようなプロンプトで何段階下のターゲットレベルまでプッシュできるでしょうか?または、SpringとReactで同じ結果を得るために、プロンプトをどれだけ詳細に(そして抽象的でなく)する必要があるでしょうか?
ソフトウェアエンジニアリングにおいてGenAIの可能性をより有効に活用したいのであれば、GenAIが橋渡しするための「プロンプト可能」な距離を構築するために、従来の抽象化レベルを全体的に再考する必要があるかもしれません。
このメモに対する洞察に満ちたレビューコメントをいただいた、John Hearn、John King、Kevin Bralten、Mike Mason、Paul Sobocinskiに感謝します。
最新のメモ:コーディングアシスタントの信頼性の低さにどう対処するか
2023年11月29日
コーディングアシスタントの有用性のトレードオフの1つは、その信頼性の低さです。基盤となるモデルは非常に汎用的であり、手元のタスクに関連するデータと関連性のないデータを含む、膨大な量のトレーニングデータに基づいています。また、大規模言語モデルは物事を捏造し、一般的に「幻覚」と呼ばれるものを起こします。(余談ですが、「幻覚」という用語については、これがこれを説明するのに実際には正しい心理学的な比喩ではないということ、また、そもそもモデルを擬人化するため、心理学用語を使用すること自体について、多くの議論があります。)
その信頼性の低さは、2つの主なリスクを生み出します。コードの品質に悪影響を与える可能性があり、時間を浪費する可能性があります。これらのリスクを考慮すると、コーディングアシスタントの入力に対する信頼度を迅速かつ効果的に評価することが重要です。
アシスタントの入力に対する信頼度をどのように判断するか
以下は、提案を使用することの信頼性とリスクを評価しようとするときに、私の頭の中で通常浮かぶ質問の一部です。これは、コードを入力中の「自動補完」の提案と、チャットからの回答の両方に当てはまります。
迅速なフィードバックループがあるか?
回答または生成された情報が機能するかどうかをすぐに確認できればできるほど、アシスタントが時間を無駄にしているリスクは低くなります。
- IDEはフィードバックループを支援できるか?構文強調表示、コンパイラーまたはトランスパイラーの統合、リンティングプラグインがあるか?
- テスト、または提案されたコードを手動で実行する簡単な方法があるか?あるケースでは、HTMLページで折りたたみ可能なJSONデータ構造を最適に表示する方法を調査するために、コーディングアシスタントチャットを使用していました。チャットは、私が聞いたことのないHTML要素について教えてくれたので、それが存在するかどうか確信が持てませんでした。しかし、それをHTMLファイルに入れてブラウザで読み込むのは簡単だったので、確認できました。反対の例を挙げると、聞いたことのないインフラストラクチャコードの検証のためのフィードバックループは通常、はるかに長くなります。
信頼できるフィードバックループがあるか?
AI入力のフィードバックループの速度だけでなく、そのフィードバックループの信頼性についても考えています。
- テストがある場合、そのテストにどれほど自信があるか?
- 自分でテストを書いたか、それともAIアシスタントで生成したか?
- AIがテストを生成した場合、これらのテストの有効性をレビューする能力にどれほど自信があるか?書いている機能が比較的シンプルでルーチンであり、使い慣れた言語である場合は、より複雑または大規模な機能よりも、もちろんはるかに自信があります。
- アシスタントを使用しているときに誰かとペアリングしているか?彼らはAI入力に対して追加の意見とレビューを提供し、私の信頼を高めます。
- テストカバレッジに確信が持てない場合は、アシスタント自身を使用して自信を高め、テストするエッジケースをさらに要求することもできます。これは、以前のメモで説明した中央値関数の重要な欠落テストシナリオを見つけることができた方法です。
誤差範囲はどれくらいか?
また、行っていることに対する誤差範囲はどれくらいかについても考えています。誤差範囲が小さいほど、AI入力に対してより批判的になります。
- 新しいパターンを導入するときは、コードベースの全体的な設計にとって、より大きな影響範囲であると考えています。チームの他の開発者はそのパターンを採用し、コーディングアシスタントもコードに入ると、チーム全体でそのパターンを再現します。たとえば、CSSでは、GitHub Copilotがflexboxレイアウトを頻繁に提案することに気づきました。しかし、レイアウトアプローチを選択することは大きな決定であるため、これを使用する前にフロントエンドの専門家やチームの他のメンバーと相談したいと考えています。
- セキュリティに関連するものはすべて、当然、誤差範囲が小さくなります。たとえば、Webアプリケーションに取り組んでおり、「Content-Security-Policy」ヘッダーを設定する必要がありました。私はこの特定のヘッダーについては何も知らなかったので、最初にCopilotチャットに尋ねました。しかし、その主題の性質上、その回答に依存したくなかったので、代わりにインターネット上の信頼できるセキュリティ情報源に行きました。
- このコードはどのくらい長く使われるのか?プロトタイプや使い捨てのコードに取り組んでいる場合は、実稼働システムに取り組んでいる場合よりも、あまり疑問を持たずにAI入力を使用する可能性が高くなります。
非常に最新の情報が必要か?
回答がより最新で、より具体的(例:フレームワークのバージョン)である必要があるほど、その回答が間違っているリスクが高くなります。これは、探している情報がAIにとって利用できないか、区別できない可能性が高いためです。この評価では、手元のAIツールが、トレーニングデータだけでなく、より多くの情報にアクセスできるかどうかを知ることも重要です。チャットを使用している場合は、オンライン検索を考慮に入れる機能があるのか、それともトレーニングデータに限定されているのかを認識しておきたいと考えています。
アシスタントに時間制限を与える
時間を無駄にするリスクを軽減するために、私が採用するアプローチの1つは、一種の最後通告を与えることです。提案が少しの追加労力で私に価値をもたらさない場合は、先に進みます。入力がすぐに役に立たない場合は、アシスタントを擁護してさらに20分かけて機能させようとするのではなく、常にアシスタントについて最悪のことを想定します。
私が思い浮かべる例は、AIチャットを使ってmermaid.jsのクラス図を生成しようとしたときのことです。私はmermaid.jsの構文にあまり詳しくなく、提案されたものをなんとか動かそうと試行錯誤し、もしかしたらマークダウンファイルへの記述方法が間違っているのかと思っていました。結局のところ、構文が完全に間違っていたのですが、それには10分ほど経ってからオンラインドキュメントを確認してようやく気づきました。
アシスタントのペルソナを作る
このメモを準備するにあたり、アシスタントのペルソナを作ることで、責任を持って、できるだけ時間を無駄にせずに利用する方法を考えるのに役立つのではないかと思い始めました。もしかしたら、AIを擬人化することが、この場合には実際に役立つかもしれません。
信頼性の低さの種類について考えると、AIのペルソナは次のような特性を持つと想像できます。
- 手助けしたがっている
- 頑固
- 非常に博識だが、経験不足(ダンジョンズ&ドラゴンズのファン向けに言うと、知能は高いが、賢さは低い)
- 自分が何かを「知らない」ときにそれを認めない
私は画像生成ツールを使って、熱心なビーバーや頑固なロバのバリエーションをいくつか試しました。これが一番気に入ったものです(Midjourneyで「熱心な頑固なロバ、幸せな本、コンピューター、漫画風、ベクターベース、フラットな色面」)。

ペルソナに楽しい名前をつけて、チームで話すこともできます。「ダスティはセッション中にうるさい知ったかぶりだった、しばらくオフにしなければならなかった」とか、「ダスティがいてくれてよかった、昼食前にタスクが終わった」とか。しかし、「ダスティがそのインシデントを引き起こした!」とは絶対に言ってはいけません。なぜなら、ダスティは基本的に未成年であり、コミットする資格がないからです。私たちは最終的にコミットに責任を持つ親のようなものであり、「親は子供に対して責任を負う」のです。
結論
状況評価のリストは、コーディングアシスタントを使用するたびにすべて適用するには多すぎるように思えるかもしれません。しかし、これらのツールを使えば使うほど、私たちは皆、上達していくと信じています。私たちは、経験に基づいて、コーディングをするときに、このような多次元的な要素を考慮した迅速な評価を常に行っています。私は、上記のような状況に遭遇すればするほど、いつアシスタントを使用し、いつ信頼すべきかの判断がうまくなってきました。いわば、「熱いストーブに触れる」回数が増えるほどということです。
また、「もしAIアシスタントが信頼できないなら、なぜそもそもそれを使う必要があるのか?」と思うかもしれません。Generative AIツールを使用する際には、私たちが持つべき考え方の転換があります。「通常の」ソフトウェアと同じ期待を持って使用することはできません。GitHub Copilotは、必要なものを100%提供してくれる従来型のコードジェネレーターではありません。しかし、40〜60%の状況では、目的の40〜80%まで達成できます。これは依然として有用です。これらの期待を調整し、熱心なロバの行動と癖を理解する時間を与えれば、AIコーディングアシスタントからより多くのものを得られるでしょう。
フィードバックと意見をくれたBrandon Cook、Jörn Dinkla、Paul Sobocinski、Ryder Dainに感謝します。
このメモは、GitHub Copilotを有効にして、マークダウンファイルで書かれました。アイデアや言い回し、行き詰まった時に役立ちますが、提案が最終的なテキストに残ることはめったにありません。私はChatGPTを類語辞典として、そしてロバの良い名前を見つけるために使用しました。