
言語ワークベンチ:ドメイン固有言語のキラーアプリ?
ソフトウェア開発における新しいアイデアのほとんどは、古いアイデアの新しいバリエーションにすぎません。この記事では、私が言語ワークベンチと呼ぶツール群の、ますます成長しているアイデアについて説明します。その例としては、Intentional Software、JetBrainsのMeta Programming System、MicrosoftのSoftware Factoriesなどが挙げられます。これらのツールは、言語指向プログラミングという古い開発スタイルを採用し、IDEツールを使用して、言語指向プログラミングを実現可能なアプローチにしようと試みています。これらのツールがその野心に成功するかどうかを予言するほど私は予言者ではありませんが、これらのツールはソフトウェア開発の地平線上で最も興味深いものの1つであると思います。少なくとも概要を説明するために、それらがどのように機能し、その将来の有用性に関する主な問題を説明しようと、このエッセイを書くのに十分興味深いのです。
2005年6月12日

長い間、ソフトウェアシステムをドメイン固有言語の集合を使用して記述しようとするソフトウェア開発スタイルが存在してきました。これは、lexとyaccを介してコードを生成する「リトル言語」というUnixの伝統に見られます。Lispコミュニティでは、Lispのマクロの助けを借りて、Lisp内で開発された言語に見られます。このようなアプローチは、その支持者によって非常に好まれていますが、この考え方は、これらの人々の多くが望んでいるほど普及していません。
ここ数年、新しいクラスのソフトウェアツールを通じて、このスタイルの開発をサポートする試みが行われています。これらの最も初期のもので最もよく知られているのは、Intentional Programmingです。これはもともと、Microsoft在籍中にCharles Simonyiによって開発されました。しかし、同様のことを行っている他の人々もおり、このアプローチへの関心を高めるのに十分な勢いを生み出しています。
ここで、このエッセイの残りの部分で使用する用語をいくつか作成します。いつものように、この分野には標準的な用語がないため、私が使用する用語が他の場所で使用されるとは考えないでください。ここで簡単な定義を示しますが、エッセイが進むにつれて、それらについてさらに詳しく説明します。したがって、定義をすぐに理解できなくても心配しないでください。
この記事で特に私が造語する2つの主な用語は、「言語指向プログラミング」と「言語ワークベンチ」です。私は、ソフトウェアをドメイン固有言語のセットを中心に構築するというアイデアに基づいて動作する一般的な開発スタイルを意味するために、言語指向プログラミングを使用します。私は、この新しいタイプのツールの総称として言語ワークベンチを使用します。したがって、言語ワークベンチは言語指向プログラミングを行う1つの方法です。また、ドメイン固有言語(通常はDSLと略記)という用語に馴染みがないかもしれません。これは、特定の問題クラス向けに設計されたコンピュータ言語の限定的な形式です。一部のコミュニティでは、DSLを問題ドメイン言語にのみ使用することを好みますが、私は任意の限定ドメインにDSLを使用するという用法に従います。
まず、例を挙げて、さまざまな種類の概要、およびアプローチの長所と短所に関するさまざまな議論とともに、言語指向プログラミングの現在の世界について簡単に説明することから始めます。言語指向プログラミングに慣れている場合は、この部分をスキップしてもかまいませんが、多くの、実際にはほとんどの開発者がこれらのアイデアにそれほど馴染みがないことがわかりました。これらを説明したら、それらを基にして、言語ワークベンチとは何か、そしてそれらがトレードオフをどのように変更するかを説明します。
この記事を書いているうちに、1つの記事には多すぎることが判明したため、議論の一部を他の記事に分けました。テキストの中で、読むのに適している場所で言及します。それらは目次のすぐ下にもリンクされています。特に、MPSを使用した例を見てください。これは、現在の言語ワークベンチの1つを使用して構築されたDSLの例を示しており、それらがどのようなものになるかを把握するのに最適な方法である可能性があります。これが理解できるためには、まずここで言語ワークベンチの一般的な説明を理解する必要があります。
言語指向プログラミングの簡単な例
まず、言語指向プログラミングの非常に簡単な例と、それに至る状況の種類から始めます。ファイルを読み取り、これらのファイルに基づいてオブジェクトを作成する必要があるシステムがあると想像してください。ファイル形式は、1行あたり1つのオブジェクトです。各行は異なるクラスにマップでき、クラスは行の先頭にある4文字のコードで示されます。行の残りの部分には、クラスのフィールドのデータが含まれており、これらは対象のクラスによって異なります。フィールドは、区切り文字ではなく位置によって示されます。したがって、顧客ID番号は4〜8文字になる可能性があります。
以下にいくつかのサンプルデータを示します
#123456789012345678901234567890123456789012345678901234567890 SVCLFOWLER 10101MS0120050313......................... SVCLHOHPE 10201DX0320050315........................ SVCLTWO x10301MRP220050329.............................. USGE10301TWO x50214..7050329...............................
ドットは、つまらないデータのいくつかを示しています。上部のコメント行は、文字位置を確認するのに役立ちます。最初の4文字は、データの種類を示します。SVCLはサービスコールを示し、USGEは使用状況の記録を示します。その後の文字は、オブジェクトのデータを表します。したがって、サービスコールの5〜18文字は、顧客の名前を示します。
これらをオブジェクトに変換するには、それぞれの場合に特定のコードを作成したくなるかもしれませんが、数回実行すると、各クラスのフィールドの詳細を使用してパラメーター化できる単一のリーダークラスを作成してタスクを簡略化したいと思うでしょう。
ここに、これを行う簡単なクラスがあります。リーダーはファイルを読み取ります。リーダーは、ターゲットクラスごとに1つずつ、リーダー戦略クラスのコレクションを使用してパラメーター化できます。したがって、この例では、サービスコールに1つの戦略、使用状況に別の戦略があるでしょう。コードでキー設定されたマップに戦略を保持します。
ファイルを処理するコードは次のとおりです
class Reader...
public IList Process(StreamReader input) {
IList result = new ArrayList();
string line;
while ((line = input.ReadLine()) != null)
ProcessLine(line, result);
return result;
}
private void ProcessLine(string line, IList result) {
if (isBlank(line)) return;
if (isComment(line)) return;
string typeCode = GetTypeCode(line);
IReaderStrategy strategy = (IReaderStrategy)_strategies[typeCode];
if (null == strategy)
throw new Exception("Unable to find strategy");
result.Add(strategy.Process(line));
}
private static bool isComment(string line) {
return line[0] == '#';
}
private static bool isBlank(string line) {
return line == "";
}
private string GetTypeCode(string line) {
return line.Substring(0,4);
}
IDictionary _strategies = new Hashtable();
public void AddStrategy(IReaderStrategy arg) {
_strategies[arg.Code] = arg;
}
行をループ処理し、どの戦略を呼び出すかを判断するのに十分な情報を読み取り、次に戦略に処理を渡します。リーダーにジョブを実行させるには、新しいリーダーを作成し、戦略をロードして、処理するファイルで実行させます。
戦略もパラメーター化できます。1つの戦略クラスだけが必要であり、インスタンス化すると、コード、ターゲットクラス、および入力のどの文字位置がターゲットクラスのどのフィールドにマップされるかの詳細でパラメーター化できます。後者をフィールドエクストラクタークラスのリストに保持します。
class ReaderStrategy...
private string _code;
private Type _target;
private IList extractors = new ArrayList();
public ReaderStrategy(string code, Type target) {
_code = code;
this._target = target;
}
public string Code {
get { return _code; }
}
インスタンス化したら、戦略にフィールドエクストラクターを追加できます。
class ReaderStrategy...
public void AddFieldExtractor(int begin, int end, string target) {
if (!targetPropertyNames().Contains(target))
throw new NoFieldInTargetException(target, _target.FullName);
extractors.Add(new FieldExtractor(begin, end, target));
}
private IList targetPropertyNames() {
IList result = new ArrayList();
foreach (PropertyInfo p in _target.GetProperties())
result.Add(p.Name);
return result;
}
行を処理するために、戦略はターゲットクラスを作成し、エクストラクターを使用してフィールドデータを取得します。
class ReaderStrategy...
public object Process(string line) {
object result = Activator.CreateInstance(_target);
foreach (FieldExtractor ex in extractors)
ex.extractField(line, result);
return result;
}
エクストラクターは、行の適切なビットからデータを引き出し、リフレクションを使用して値をターゲットオブジェクトに配置します。
class FieldExtractor...
private int _begin, _end;
private string _targetPropertyName;
public FieldExtractor(int begin, int end, string target) {
_begin = begin;
_end = end;
_targetPropertyName = target;
}
public void extractField(string line, object targetObject) {
string value = line.Substring(_begin, _end - _begin + 1);
setValue(targetObject, value);
}
private void setValue(object targetObject, string value) {
PropertyInfo prop = targetObject.GetType().GetProperty(_targetPropertyName);
prop.SetValue(targetObject, value, null);
}
これまで説明したことは、この種の処理を行うための非常に単純なライブラリです。基本的に、具体的な作業を指定するために使用できる抽象化を構築しました。抽象化を使用するには、戦略を構成してリーダーにロードする必要があります。次に、2つの例のケースの例を示します。
public void Configure(Reader target) {
target.AddStrategy(ConfigureServiceCall());
target.AddStrategy(ConfigureUsage());
}
private ReaderStrategy ConfigureServiceCall() {
ReaderStrategy result = new ReaderStrategy("SVCL", typeof (ServiceCall));
result.AddFieldExtractor(4, 18, "CustomerName");
result.AddFieldExtractor(19, 23, "CustomerID");
result.AddFieldExtractor(24, 27, "CallTypeCode");
result.AddFieldExtractor(28, 35, "DateOfCallString");
return result;
}
private ReaderStrategy ConfigureUsage() {
ReaderStrategy result = new ReaderStrategy("USGE", typeof (Usage));
result.AddFieldExtractor(4, 8, "CustomerID");
result.AddFieldExtractor(9, 22, "CustomerName");
result.AddFieldExtractor(30, 30, "Cycle");
result.AddFieldExtractor(31, 36, "ReadDate");
return result;
}
私はこれを2つの異なるスタイルのコードとして見ています。ReaderクラスとStrategyクラスは抽象化であり、この最後のビットのコードは構成です。これらの種類のライブラリクラスを構築するときは、抽象化と構成という2つの部分を考えると役立つことがよくあります。抽象化は、クラスライブラリ、フレームワーク、または単なる関数呼び出しのセットである場合があります。抽象化は多くのプロジェクトで再利用可能である可能性がありますが、必須ではありません。構成コードは、特定のものである傾向があります。かなりシンプルで、直接的なコードです。
構成は非常に単純で、抽象化よりも変更される可能性が高いため、一般的なアプローチは、それをさらに分離し、構成をC#から完全に取り出すことです。現在の流行は、それをXMLファイルに入れることです。
<ReaderConfiguration>
<Mapping Code = "SVCL" TargetClass = "dsl.ServiceCall">
<Field name = "CustomerName" start = "4" end = "18"/>
<Field name = "CustomerID" start = "19" end = "23"/>
<Field name = "CallTypeCode" start = "24" end = "27"/>
<Field name = "DateOfCallString" start = "28" end = "35"/>
</Mapping>
<Mapping Code = "USGE" TargetClass = "dsl.Usage">
<Field name = "CustomerID" start = "4" end = "8"/>
<Field name = "CustomerName" start = "9" end = "22"/>
<Field name = "Cycle" start = "30" end = "30"/>
<Field name = "ReadDate" start = "31" end = "36"/>
</Mapping>
</ReaderConfiguration>
XMLには用途がありますが、正確に読みやすいとは言えません。カスタム構文を使用することで、何が起こっているのかをより簡単に把握できます。おそらくこのようなものです
mapping SVCL dsl.ServiceCall 4-18: CustomerName 19-23: CustomerID 24-27 : CallTypeCode 28-35 : DateOfCallString mapping USGE dsl.Usage 4-8 : CustomerID 9-22: CustomerName 30-30: Cycle 31-36: ReadDate
これで問題に慣れたので、私の助けなしに構文を読めるはずです。
この最後の例を見ると、ここにあるのは非常に小さなプログラミング言語、つまり、固定長のフィールドをクラスにマッピングする目的(のみ)に適した言語であることがわかります。これは、'リトル言語'というUnixの伝統の典型的な例です。これは、タスクのためのドメイン固有言語です。
この言語はドメイン固有言語であり、DSLの多くの特性を共有しています。第一に、非常に狭い目的にのみ適しています。これらの特定の固定長のレコードをクラスにマッピングする以外に何も実行できません。結果として、DSLは非常に単純です。制御構造やその他の機能はありません。チューリング完全でさえありません。この言語でアプリケーション全体を作成することはできません。できるのは、アプリケーションの小さな側面を記述することだけです。結果として、DSLは何かを行うために他の言語と組み合わせる必要があります。しかし、DSLの単純さは、編集と翻訳が簡単であることを意味します(DSLの長所と短所については後で詳しく説明します)。
ここで、XML表現をもう一度見てください。これはDSLですか?そうだと私は主張します。それはXML構文の中にありますが、それでもDSLです。実際、多くの点で前の例と同じDSLです。
これは、プログラミング言語の分野でよく見られる一般的な区別、つまり、抽象構文と具象構文の区別を紹介するのに良い機会です。言語の具象構文とは、表示される表現における構文のことです。XMLファイルとカスタム言語ファイルには、異なる具象構文があります。ただし、どちらも同じ基本構造を共有しています。つまり、複数のマッピングがあり、それぞれにコード、ターゲットクラス名、およびフィールドのセットがあります。この基本構造が抽象構文です。ほとんどの開発者はプログラミング言語の構文について考えるとき、この分離を行いませんが、DSLを使用する場合は重要です。これは2つの方法で考えることができます。1つの言語に2つの具象構文があると言うことも、同じ抽象構文を共有する2つの言語があると言うこともできます。
この例は、DSLにカスタムの具象構文を使用するのが良いか、それともXMLの具象構文を使用するのが良いかという設計上の問題提起となっています。XML構文は、利用可能なXMLツールが多数あるため、解析が容易な場合があります。ただし、このケースでは、カスタム構文の方が実際には簡単でした。少なくともこのケースでは、カスタム構文の方がはるかに読みやすいと私は主張します。しかし、この選択をどのように考えるかに関わらず、DSLに関する本質的なトレードオフは同じです。実際、XML構成ファイルはすべて、本質的にDSLであると主張することもできます。
さらに一歩戻って、C#の構成コードに戻りましょう。これはDSLなのでしょうか?
それを考えている間に、このコードを見てください。これは、この問題に対するDSLのように見えますか?
mapping('SVCL', ServiceCall) do
extract 4..18, 'customer_name'
extract 19..23, 'customer_ID'
extract 24..27, 'call_type_code'
extract 28..35, 'date_of_call_string'
end
mapping('USGE', Usage) do
extract 9..22, 'customer_name'
extract 4..8, 'customer_ID'
extract 30..30, 'cycle'
extract 31..36, 'read_date'
end
この2番目のコードは、C#のコードに関連しています。私の言語の好みをよく知っている人なら、最後の例が実際にはRubyコードであることに気づいたでしょう。実際、C#の例と全く同じ意味を持っています。Rubyのさまざまな機能(最小限に抑えられた構文、範囲のリテラル、柔軟なランタイム評価)により、カスタムDSLのように見えます。これは、ランタイム時にオブジェクトインスタンスのスコープ内で読み込んで評価できる完全な構成ファイルです。しかし、これは依然として純粋なRubyであり、フレームワークコードとは、C#の例のAddStrategyとAddFieldExtractorに対応するメソッド呼び出しmappingとextractを通じてやり取りします。
私は、C#とRubyの例の両方がDSLであると主張します。どちらの場合も、ホスト言語の機能のサブセットを使用し、XMLやカスタム構文と同じアイデアを捉えています。本質的に、私たちはDSLをホスト言語に埋め込み、ホスト言語のサブセットを抽象言語のカスタム構文として使用しています。これは、ある程度、他の何よりも態度に関わる問題です。私は、C#とRubyのコードを言語指向プログラミングの観点から見ています。しかし、これは長い伝統を持つ観点です。Lispプログラマーは、Lisp内でDSLを作成することを考えることがよくあります。これらの内部DSLのトレードオフは、外部DSLのトレードオフとは明らかに異なりますが、多くの類似点が残っています。(これらのトレードオフについても後で詳しく説明します。)
これでDSLの例を示したので、言語指向プログラミングをより適切に定義できます。言語指向プログラミングとは、複数のDSLを通じてシステムを記述することです。これは段階的なものであり、システムの一部の機能がDSLで表現されているシステムでは少しの言語指向プログラミングを使用できます。または、ほとんどの機能をDSLで表現し、多くの言語指向プログラミングを使用することもできます。言語指向プログラミングをどれだけ使用するかを測定することは困難です。特に、言語内のDSLを使用する場合はそうです。通常、再利用可能なコードと同様に、自分でDSLをいくつか記述し、他の場所から別のDSLを使用します。
言語指向プログラミングの伝統
私の例が示すように、言語指向プログラミングは新しいものではありません。人々はかなり前から言語指向プログラミングを行っています。したがって、言語ワークベンチが何をもたらすのかを見る前に、現在の言語指向プログラミングの現状を見てみる価値があります。
言語指向プログラミングには、いくつかのスタイルが存在します。ここでそれらをいくつか要約するのが良いでしょう。
Unixのリトル言語
最も明らかにDSL的な領域の1つは、Unixの小さな言語を書くという伝統です。これらは外部DSLシステムであり、通常はUnixの組み込みツールを使用して翻訳を支援します。大学時代に、私はlexとyaccを少し使ってみました。同様のツールは、Unixツールチェーンの一般的な一部です。これらのツールを使用すると、小さな言語のパーサーを記述してコード(多くの場合C言語)を生成することが容易になります。Awkは、この種のミニ言語の良い例です。
Lisp
Lispは、言語自体で直接DSLを表現する最も強力な例でしょう。シンボリック処理は、Lispの慣習だけでなく名前にも埋め込まれています。これを行うのは、Lispの機能(最小限の構文、クロージャー、マクロ)によって助けられます。Paul Grahamはこのスタイルの開発について多くを書いています。Smalltalkにも、このスタイルの開発の強い伝統があります。
アクティブデータモデル
より洗練されたデータモデラータイプに遭遇した場合、システムの高度に可変な部分をデータベーステーブル(多くの場合、メタデータテーブルまたはテーブル駆動プログラムと呼ばれる)のデータによってエンコードする方法を示すでしょう。その後、コードはテーブル内のデータを解釈して動作を実行できます。
これは本質的に、具象構文がデータベーステーブルであるDSLです。多くの場合、これらのテーブルは、このアクティブなデータを編集するための何らかの形式のGUIインターフェースを通じて管理されます。通常、これを行う人々は言語の作成について考えておらず、通常、関係型の具象構文を扱うことの難しさが、言語を小さく焦点を絞った状態に保つのに役立ちます。
適応型オブジェクトモデル
ハードコアなオブジェクトプログラマーと十分に話すと、オブジェクトの構成を柔軟で強力な環境に依存するシステムについて語ってくれるでしょう。このようなシステムは、複雑なケースの範囲を処理するためにオブジェクトを構成に結び付けることで動作のほとんどが発生する、洗練されたドメインモデルで構築されています。OOの人はアダプティブオブジェクトモデルを強化されたアクティブデータモデルとして扱います。
このようなアダプティブモデルは、言語内のDSLです。これまでの経験から、モデルが開発されて落ち着くと、アダプティブモデルに精通している人は非常に生産的になることが示されています。悪い面は、このようなモデルを新しい人が理解するのが非常に難しいことが多いということです。
XML構成ファイル
最新のJavaプロジェクトにアクセスすると、システムにJavaよりも多くのXMLがあると思っても無理はありません。エンタープライズJavaシステムは、さまざまなフレームワークを使用しており、そのほとんどが複雑なXML構成ファイルを誇っています。これらのファイルは本質的にDSLです。XMLは解析を容易にしますが、カスタム形式ほど読みやすいとは限りません。角度付きの括弧が目に痛いと感じる人のために、XMLファイルを操作するのに役立つIDE用のプラグインが作成されています。
GUIビルダー
人々がGUIを構築し始めて以来、コントロールのドラッグアンドドロップを通じてGUIをレイアウトできるシステムが登場しています。Visual Basicはおそらく最も有名な例ですが、GUIが一般的になるずっと前に、私は文字画面用の同様のスクリーンビルダーを使用したことがあります。これらのツールは、レイアウトを実行に適したコードを生成するクローズド形式で保存するか、必要なすべての情報を生成されたコードに入れようとします。見た目は良いものの、魅力的デモにはなるものの、このスタイルの対話には限界があることがますますわかってきました。そのため、経験豊富なGUI開発者の多くは、比較的複雑なアプリケーションにはGUIビルダーを使用することを推奨していません。
GUIビルダーは一種のDSLですが、編集体験は私たちが慣れているテキストプログラミング言語とはかなり異なります。したがって、それらを構築する人々は、言語とはみなさないことが多く、それが問題の一部であると考える人もいます。
言語指向プログラミングの長所と短所
これらのスタイルを振り返ると、さまざまな形式の言語指向プログラミングが非常に普及していることがわかります。大まかに一般化すると、それらを2つのより広範なスタイルに分けると便利だと感じます。外部DSLは、アプリケーションのメイン(ホスト)言語とは異なる言語で記述され、何らかの形式のコンパイラまたはインタープリターを使用して変換されます。Unixの小さな言語、アクティブデータモデル、XML構成ファイルはすべてこのカテゴリに分類されます。内部DSLは、ホスト言語自体をDSLに変えます。Lispの伝統がこの最良の例です。
私はこの記事のために外部/内部という用語を作成しました。私が有用だと感じる区別に対する明確な用語のペアがないためです。内部DSLは「埋め込みDSL」と呼ばれることもよくありますが、「埋め込み」という用語は、アプリケーションに埋め込まれた言語(Wordに埋め込まれたVBAなど、どちらかといえば外部DSLである)と混同されるため、避けてきました。ただし、DSLに関する他の記事を調べると、埋め込みという用語に遭遇する可能性があります。
外部DSLと内部DSLのトレードオフはかなり異なるため、個別に検討するのが最善です。
外部DSL
私は、外部DSLを、単純な例の最後の2つの形式など、アプリケーションのメイン言語とは異なる言語で記述されたものとして定義します。Unixの小さな言語とXML構成ファイルは、このスタイルの良い例です。
外部DSLの主な強みは、好きな形式を自由に使用できることです。その結果、ドメインを可能な限り読みやすく、変更しやすい形式で表現する能力が大幅に向上します。形式は、構成ファイルを解析して、実行可能なもの(通常はベース言語で)を生成できるトランスレーターを構築する能力によってのみ制限されます。
したがって、明白な欠点は、このトランスレーターを構築する必要があるということです。上で示したような単純な言語の場合、これは難しくありません。より複雑な言語はより困難になりますが、それでもそれほど悪くはありません。パーサージェネレーターとコンパイラコンパイラツールは、非常に複雑な言語を操作するのに役立ちます。もちろん、DSL全体のポイントは、通常は非常に単純であるということです。XMLはDSLの形式を制限しますが、解析は非常に簡単になります。
外部DSLの大きな欠点は、私がシンボリック統合と呼ぶものが欠けていることです。つまり、DSLは実際にはベース言語にリンクされていません。ベース言語環境は、私たちが行っていることを認識していません。プログラミング環境がますます高度になるにつれて、これはますます問題になっています。
簡単な例として、単純な例でターゲットクラスのプロパティの名前を変更したい場合を考えてみましょう。一流の最新IDEでは、名前変更の自動リファクタリングは日常的です。しかし、このような名前変更はDSLには伝播されません。C#の世界とファイルマッピングDSLの間には、私がシンボリックバリアと呼ぶものが存在します。マッピングをC#に変換することはできますが、このバリアはプログラム全体の操作能力を制限します。
この統合の欠如は、ツールを使用する際にさまざまな方法で私たちに影響を与えます。まず、DSLをどのように編集しますか?テキストエディターでジョブを実行できますが、最新のIDEはテキストエディターをますます原始的に見せています。フィールド名に関するポップアップリストと補完が表示され、文字範囲が重複している場合は赤い波線が表示されるはずです。しかし、これを行うには、DSLのセマンティクスを理解するエディターが必要です。
セマンティックエディターがなくてもやっていけるかもしれません。しかし、次にデバッグについて考えてみましょう。デバッガーはC#の変換にステップインできますが、真のソース自体にはステップインできません。本当に欲しいのは、DSL用の本格的なIDEです。テキストエディターと単純なデバッガーの時代には、これは大きな問題ではありませんでしたが、私たちは今、ポストIntelliJの世界に住んでいます。
外部DSLに対するよくある異論として、言語の不協和音問題があります。これは、言語を習得するのが難しいため、多くの言語を使用すると単一の言語を使用するよりもはるかに複雑になるという懸念です。ある程度、この懸念はDSLに関する誤解に基づいています。この懸念を抱く人々は、しばしば複数の汎用プログラミング言語を想像し、それは確かに不協和音を生み出す可能性があります。しかし、DSLは限定的で単純な傾向があり、習得が容易です。これは、DSLがドメインに近いことによって強化されます。DSLは通常のプログラミング言語のようには見えません。
基本的に、適切な規模のプログラムでは、入門例のファイル読み込みのように、操作する必要がある多くの抽象化を扱います。一般的に、これらの抽象化はオブジェクトとメソッドを使用して操作します。これは機能しますが、表現したいことを表現するための文法は限られています(ただし、どの程度制限されるかは基本言語に依存します)。外部DSLを使用すると、操作が容易な文法を持つ機会が得られます。問題は、外部DSLによる操作の容易さが、そもそも新しいDSLを理解するコストよりも大きいかどうかです。
この問題に関連して、DSLの設計の難しさに関する懸念もあります。言語設計は難しいため、複数のDSLを設計することはほとんどのプロジェクトにとって難しすぎます。ここでも、この異論は、DSLではなく汎用プログラミング言語について考えていることに起因することがよくあります。ここで、根本的な問題は、良い抽象化を得ることだと考えています。それがタスクの難しい部分です。API設計とDSL設計の違いは非常に小さいため、DSLの設計は優れたAPIの設計よりも著しく難しいとは思えません。
多くの人にとって、外部DSLの大きな強みの1つは、DSLをランタイムで評価できることです。これにより、頻繁に変更されるパラメータをプログラムを再コンパイルすることなく変更できます。これは、Javaの世界でXML構成ファイルが非常に人気になった大きな理由です。これは静的にコンパイルされる言語では重要な問題ですが、多くの言語がランタイムで式を簡単に評価できることを覚えておくことが重要です。そのため、それらの言語では問題ではありません。また、.NETのIronPythonなど、コンパイル時言語とランタイム言語を混在させることへの関心も高まっています。これにより、主にC#システムの中でIronPythonの内部DSLを評価できるようになります。これは、C/C++とスクリプト言語を組み合わせたUnixの世界では一般的な手法です。
内部DSL
内部DSLは、外部言語DSLの長所と短所を反転させます。基本言語との記号的な障壁を解消します。また、基本言語に存在するすべてのツールとともに、常に基本言語のすべての能力を使用できます。Lispや適応オブジェクトモデルは、内部DSLの例です。
この議論における問題の1つは、主流の波括弧プログラミング言語(C、C++、Java、C#)と、内部DSLに特に適したLispのような言語との間に大きな違いがあることです。内部DSLスタイルは、JavaやC#よりもLispやSmalltalkの方がはるかに実現可能です。実際、動的言語の支持者は、これを彼らの大きな強みの1つとして指摘しています。スクリプト言語でこの点が再発見されつつあります。Rubyのメタプログラミング機能と、それがRailsフレームワークでどのように使用されているかを考えてみてください。この問題は、多くのプログラマーが動的言語を真剣に使用したことがないため、動的言語の能力(および真の制限)を理解していないという事実によってさらに悪化します。
内部DSLは、基本言語の構文と構造によって制限されます。より動的な言語は、制限の影響をあまり受けません。それらは、主流の波括弧言語よりも優れた働きをする、最小限の侵入的な構文(Lisp、Smalltalk、スクリプト言語など)を持っています。これは、C#とRubyの例を比較すると非常によくわかります。クロージャやマクロなどの言語機能も役立ちます。このメカニズムの多くはCベースの言語には欠けていますが、この考え方をサポートできる機能が見られ始めています。アノテーション(C#の属性)は、この種の目的には非常に役立つ可能性のある、この種の言語機能の良い例です。
基本言語のツールは利用できますが、この基本言語は実際にはDSLで何をしようとしているのかを認識していません。そのため、ツールはDSLを完全にサポートしていません。テキストエディタよりはマシですが、改善の余地はたくさんあります。
DSLで言語のすべての能力を利用できることは、諸刃の剣です。基本言語に精通していれば、すべてうまくいきます。ただし、DSLの強みの1つは、基本言語全体を知らなくてもDSLでプログラミングできることであり、ドメイン固有の情報をレイプログラマーがシステムに直接入力することを容易にしています。内部DSLは、ユーザーが基本言語全体に精通していないと混乱する可能性のある場所が多いため、これを行うのが難しくなる可能性があります。
これについて考える1つの方法は、汎用プログラミング言語は多くのツールを提供しますが、DSLはこれらのツールのほんの一部しか使用しないということです。必要なツールよりも多くのツールを持つと、必要なツールが何であるかを把握する前に、すべてのツールが何であるかを学ぶ必要があるため、多くの場合、物事が難しくなります。理想的には、自分の仕事に必要な実際のツールだけが必要です。間違いなく少なくはありませんが、ほんの少しだけ多く必要です。(Charles Simonyiは、このアイデアを自由度の概念で説明しました。)
オフィスツールの例えがあります。多くの人は、最新のワードプロセッサは、単一の人が必要とするよりもはるかに多くの数百もの機能があるため、非常に使いにくいと不満を言います。しかし、これらの機能はすべて誰かに必要とされているため、オフィスプログラムは大規模なシステムを構築することによってすべての人を満足させることになります。代わりに、単一のタスクに焦点を当てた複数のオフィスツールを持つこともできます。これらの各ツールは、習得と使用がはるかに簡単になります。もちろん問題は、これらの特殊なオフィスツールをすべて構築するには費用がかかることです。これは、汎用プログラミング言語(内部DSLを使用)と外部DSLの間にある、非常に類似したトレードオフです。
内部DSLはプログラミング言語に近い場合、プログラミング言語自体にうまくマッピングされないものを表現したいときに問題が生じる可能性があります。たとえば、エンタープライズアプリケーションでは、レイヤーの概念を持つのが一般的です。これらのレイヤーは、プログラミング言語のパッケージ構造を使用して大部分を定義できますが、レイヤー間の依存関係ルールを定義するのは困難です。したがって、すべてのUIコードをMyApp.Presentationに、ドメインロジックをMyApp.Domainに配置できますが、MyApp.DomainのクラスがMyApp.Presentationのクラスを参照してはならないことを示すメカニズムは、内部DSLにはありません。ある程度、これは一般的な言語の限定的な動的性も反映しています。この種のことは、メタレベルへのより深いアクセスがあるため、Smalltalkでは可能でした。
(比較として、これらの動的言語の1つで開発された私のより複雑な例を見てみるのは興味深いでしょう。おそらく私には無理でしょうが、誰かがやってくれるのではないかと思います。その場合は、参考資料を更新します。)
非プログラマーの関与
言語指向プログラミングの両方の形式に絶えず絡み合っているテーマの1つは、レイプログラマーの関与です。これは、専門のプログラマーではなく、開発作業の一環としてDSLでプログラミングを行うドメイン専門家です。レイプログラミングの目標は、ソフトウェアの世界で常に目標とされてきました。実際、初期の高水準言語(COBOLとFORTRAN)は、ユーザーがそれらを使用するため、プログラマーの終わりを告げると信じられていました。これは私がCOBOL推論と呼ぶものを思い出させます。これは、プロのプログラマーを排除することになっているほとんどの技術は、そのようなことを何もしていないというものです。
COBOL推論にもかかわらず、人々は時々、プログラムへの直接的なユーザー入力を取得することに成功します。これを行う1つの方法は、ユーザーがこの空間で安全かつ快適にプログラミングできるほど簡単で制限された問題の一部を切り出すことです。次に、これらのユーザーがプログラミング可能な領域をそれぞれDSLに変えます。これらのDSLは非常に洗練されている場合があります。MatLabは、ドメインに焦点を当てているため機能する、非常に複雑なDSLの良い例です。
ユーザーがプログラミング可能なDSLの外部DSLの利点は、ホスト言語のすべての重荷を捨てて、ユーザーにとって非常に明確なものを提示できることです。これは、より制限的な構文を持つ言語に特に重要です。しかし、単純な言語であっても、ユーザーが言語では理にかなっているが、DSLの範囲外であるようなことを簡単に行う可能性があるという問題が、内部DSLにはあります。これにより、ユーザーは奇妙な動作と謎めいたエラーメッセージが表示されるように見えるため、混乱します。
言語指向プログラミングの多くの支持者は、システムのすべてのドメインロジックがユーザーによって行われる未来を思い描いています。プログラマーは、これらのプログラムを編集およびコンパイルできるようにするために必要なサポートツールを作成します。これはプロのプログラマーの終わりを意味するものではありませんが、必要なプログラマーの数を大幅に減らし(これらのツールの多くは再利用可能であるため)、今日のソフトウェア開発を遅らせるコミュニケーションの問題の多くを解消します。このレイプログラマーのビジョンは魅力的ですが、COBOL推論はそれをあざけり笑います。
最終的に、私はレイプログラミングを取得する価値のあるものだと考えていますが、言語指向プログラミングのすべてではありません。優れたDSLは、ユーザープログラマーに受け入れられなくても、プロのプログラマーの生産性を向上させます。優れたDSLは、プロのプログラマーが作成することになるかもしれませんが、ドメイン専門家による有用なレビューが可能になります。
レイプログラマーの議論は、リスクの高い賭けです。誰かが主に大規模なユーザープログラミングを可能にすることに基づいて何らかの技術を正当化する場合、私は懐疑的になります。しかし、そのようなアプローチが成功すれば、非常に大きなメリットが得られるでしょう。これはプロのプログラマーを排除することからではなく、ドメイン専門家とプログラマーの間のしばしば悲惨なコミュニケーション状態を改善することから生まれるでしょう。このコミュニケーションの欠如は、ソフトウェア開発プロジェクトにおける最大の障害となることがよくあります。
言語指向プログラミングにおけるトレードオフの要約
私にとって、言語指向プログラミングにおける根本的な問題は、DSLを使用することの利点と、それらを効果的にサポートするために必要なツールを構築するコストとの比較です。内部DSLを使用するとツールのコストが削減されますが、DSL自体の制約もメリットを大幅に低下させる可能性があります。特に、Cベースの言語に限定されている場合はそうです。外部DSLは、メリットを実現する最大の可能性を提供しますが、言語の設計、トランスレータの構築、およびプログラミングをサポートするツールを検討するためのコストがより大きくなります。
これが、言語指向プログラミングがあまり普及していない理由です。インラングとエクスラングの両方の手法には、重大な欠点があります。結果として、DSLで現在よりも多くのことができるはずだという感覚、つまり、不満なギャップがあります。
これは、言語ワークベンチの正当化につながります。基本的に、言語ワークベンチの約束は、セマンティックな障壁なしに外部DSLの柔軟性を提供することです。さらに、最新のIDEの最高のものに匹敵するツールを簡単に構築できます。その結果、言語指向プログラミングの構築とサポートがはるかに容易になり、多くの人にとって言語指向プログラミングを非常に扱いにくくした障壁が低くなります。
今日の言語ワークベンチ
まず最初に、この言語ワークベンチのカテゴリーに当てはまるツールについて、いくつか簡単に触れておきます。これらのツールはすべて開発の初期段階にあることを覚えておいてください。大規模なソフトウェア開発に利用できる言語ワークベンチが登場するには、まだ数年かかるでしょう。
Intentional Software
これらのツールのゴッドファーザーは、Intentional Programming(意図的なプログラミング)です。Intentional Programmingは、もともとMicrosoft ResearchのCharles Simonyi氏によって開発されました。数年前、Simonyi氏はマイクロソフトを離れ、Intentional Softwareを独自に開発するために自分の会社を設立しました。このようなスタートアップによくあるように、開発状況についてはあまりオープンではありません。そのため、Intentional Softwareの内容や使用方法に関する情報は不足しています。
私はIntentional Softwareを少しだけ触る機会があり、Thoughtworksの同僚の何人かはここ1年ほどIntentional社と密接に協力してきました。その結果、私はIntentionalのカーテンの裏側を覗き見ることができましたが、そこで見たことについて話せる範囲は限られています。幸いなことに、彼らは今後1年ほどで自分たちの仕事についてオープンにし始める予定です。
(用語についての注意点として、Intentionalの人々は、マイクロソフトで行っていた古い仕事を指すときに「Intentional Programming」という用語を使い、それ以降に行っていることを指すときに「Intentional Software」という用語を使っています。)
メタプログラミングシステム
より新しいイニシアチブとしては、Meta Programming System(メタプログラミングシステム)が、JetBrainsによって開発されています。JetBrainsは、優れたIDEツールのおかげで、ソフトウェア開発者の間で高い評価を得ています。
JetBrainsのIDEに関する経験は、言語ワークベンチにいくつかの点で関連しています。まず、IntelliJでの成功は、技術力と実用性の両面で、ツール業界における彼らの信頼性を高めています。第二に、言語ワークベンチの機能の多くは、IntelliJ以降のIDEを非常に有能なものにしている機能と密接に結びついています。
JetBrainsは、FabriqueというWebアプリケーションを開発するための洗練された環境を構築するために数年を費やしました。Fabriqueを構築した経験から、今後このようなツールをより効果的に構築するためのプラットフォームが必要であると確信しました。この欲求が、彼らがMPSを開発するきっかけとなりました。
MPSは、Intentional Softwareについて公開されている情報に強く影響を受けています。Intentionalの仕事よりも開発期間ははるかに短いですが、JetBrainsは非常にオープンな開発サイクルを信じています。彼らは、使用可能なものができた時点で、Early Access Programの下でMPSを利用できるようにしました。現在、彼らはこれを2005年の前半に実現したいと考えています。
私は最近、MPSのリーダーであるSergey Dmitriev氏と非常に緊密に協力することができて幸運でした。MPSの活動は、JetBrainsのマサチューセッツオフィスから出てきているため、私が彼らを訪問しやすいということも手伝っています。この地理的な類似性と彼らのオープンさのおかげで、私はいくつかの詳細な例を説明するのにMPSを使用しました(ただし、この記事をもう少し進めるまで、あまり意味がわからないでしょう。その時になったら、またリンクを貼りますのでご心配なく)。
ソフトウェアファクトリー
Software Factories(ソフトウェアファクトリー)は、MicrosoftのJack Greenfield氏とKeith Short氏が率いるイニシアチブです。ソフトウェアファクトリーにはいくつかの要素がありますが、ここでは詳しく説明しません(ひどい名前で躊躇しないでください、ということ以外は)。この記事に関連するのは、DSL(ドメイン固有言語)の取り組みです。言語指向プログラミングは、ソフトウェアファクトリーにおいて重要な役割を果たしています。
ソフトウェアファクトリーのチームは、モデル駆動開発のバックグラウンドを持っています。彼らには、CASEツール開発に積極的に関わってきた人々や、イギリスのOOコミュニティの多くの著名人も含まれています。そのため、彼らのDSLはよりグラフィカルなアプローチをとる傾向があることは驚くことではありません。しかし、ほとんどのCASEツールの人々と異なり、彼らはセマンティクスとコード生成の制御に真剣な関心を持っています。
ここでの議論の多くは、アプリケーションの従来のプログラミングについて言及しています。特にソフトウェアファクトリーのチームは、デプロイメント、テスト、ドキュメントなど、自動化されないことが多いソフトウェア開発の他の分野でDSLを使用することにも非常に関心を持っています。彼らは、開発中にDSLを直接実行したくない状況(デプロイメントDSLなど)のためのシミュレーターも模索しています。
マイクロソフトのDSLチームは、Visual Studio 2005 Team Systemの一部として、数ヶ月間ダウンロードを提供しています。
モデル駆動型アーキテクチャ(MDA)
OMGのMDA(モデル駆動アーキテクチャ)を追跡してきた方なら、私が言語ワークベンチについて述べてきたこととMDAのビジョンに多くの類似点があることに気づくでしょう。これは物議を醸す問題ですが、今のところは、MDAのいくつかのビジョンは言語ワークベンチの一形態であると言えますが、すべてではありません。また、MDAの上に言語ワークベンチを構築することは非常に欠陥があると考えています。この点について詳しく議論するために関連記事を書きましたが、この記事を読み終えるまではあまり意味がわからないでしょう。
言語ワークベンチの要素
これらのツールはすべて異なりますが、いくつかの共通の特徴と類似した部分を共有しています。
言語ワークベンチの最も強力な特性の1つは、プログラムの編集とコンパイルの関係を変えることです。本質的に、テキストファイルの編集からプログラムの抽象表現の編集へと移行します。この最後の文を説明するために、いくつか段落を費やしましょう。
従来のプログラミングでは、テキストファイル上のテキストエディターを使用してプログラムのテキストを編集します。次に、そのファイルを、コンピュータが理解して実行できるものに変換するトランスレータを実行して、実行可能にします。その変換は、PythonやRubyのようなスクリプト言語のように実行時に行われることもあれば、Java、C#、Cのようなコンパイル言語のように別々のステップとして行われることもあります。
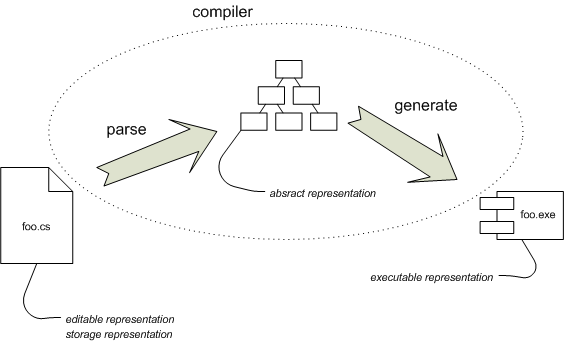
図1:従来のコンパイルの概要。
このプロセスを少し分解してみましょう。図1は、コンパイルプロセスを簡略化したものです。foo.csを実行可能なものにするには、コンパイラを実行します。この議論のために、コンパイルプロセスを2つのステップに分解することができます。最初のステップでは、ファイルfoo.csからテキストを取得し、抽象構文木(AST)に解析します。2番目のステップでは、この木をたどり、アセンブリ(exeファイル)に入れるCLRバイトコードを生成します。
{kind=link}
プログラムには、コンパイラが表現の間で変換を行う多くの表現があると考えられます。ソースファイルは編集可能な表現です。つまり、プログラムを変更したいときに操作する表現です。また、ストレージ表現でもあります。これは、ソースコード管理に保持され、プログラムに再度アクセスしたい場合に使用されます。コンパイラを実行すると、最初のフェーズでは編集可能な表現が抽象表現(抽象構文木)にマッピングされ、次にコードジェネレーターがそれを実行可能な表現(CLRバイトコード)に変換します。
(実行可能コードになるまでには、実行可能コードに対してさらに多くの変換が行われます。しかし、バイトコードを手に入れた時点でコンパイラの作業は完了し、残りはすべてコンパイラの範囲外の後の段階で行われます。)
抽象表現は非常に一時的なものであり、コンパイラが実行されている間のみ存在し、コンパイルを2つの論理ステップに分離する役割を果たすだけです。この一時性は、もちろん、外部DSL間でシンボリック統合を行うのが非常に難しい理由の大部分を占めています。各言語は別々のコンパイルを通過するため、抽象表現間のリンクはありません。重要な抽象化が失われた時点で、生成されたコードで初めて物事がまとまります。
より洗練されたIntelliJ以降のIDEは、このモデルに大きな変化をもたらします。IDEがファイルをロードすると、ファイル編集を支援するために、インメモリに抽象表現が作成されます。(Smalltalkもこの限定版を行っていました。)この抽象表現は、メソッド名の補完のような単純なものから、リファクタリングのような洗練されたものまでを支援します(自動リファクタリングは抽象表現に対する変換です)。
私の同僚であるMatt Foemmelは、IntelliJで作業中にこのことがどのように彼を襲ったかを語っています。彼はこれらの機能によって強力に支援された変更を行い、突然、テキストを入力しているのではなく、抽象表現に対してコマンドを実行していることに気づきました。IDEは、抽象表現でのこれらの変更をテキストに変換しましたが、実際に操作していたのは抽象表現でした。最新のIDEで作業中に同じような感覚を味わったことがあるなら、言語ワークベンチが何をするのかがわかるでしょう。
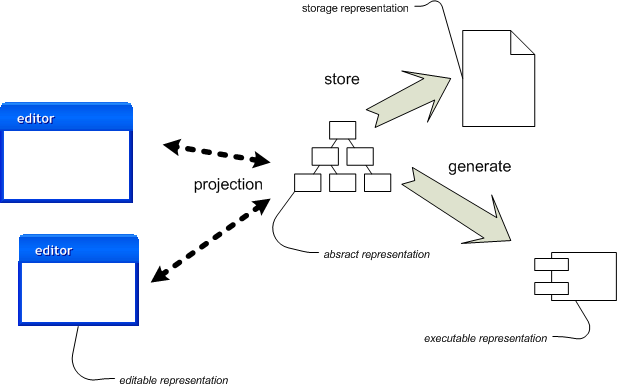
図2:言語ワークベンチによる表現の操作。
図2は、言語ワークベンチでこのプロセスがどのように機能するかを示しています。ここでの重要な違いは、「ソース」が編集可能なテキストファイルではなくなったことです。操作する主要なソースは、抽象表現自体です。編集するために、言語ワークベンチは抽象表現を何らかの形式の編集可能な表現に投影します。しかし、この編集可能な表現は純粋に一時的なものであり、人間の助けとなるためだけに存在します。真のソースは、永続的な抽象表現です。
{kind=link}
編集可能な表現が抽象表現の単なる投影であるという事実は、いくつかのポイントにつながります。おそらく最も重要なのは、編集可能な表現が完全である必要がないということです。つまり、目の前のタスクにとって重要でない場合は、抽象表現の一部の側面が欠落している可能性があります。さらに、複数の投影を持つことができ、それぞれが抽象表現の異なる側面を示しています。投影は言語ワークベンチ内にあるため、編集可能な表現はテキストファイルよりもはるかにアクティブです。この投影エディターは言語自体と密接に結びついています。その結果、編集可能な表現について考える際には、エディターがどのようにそれらと連携するかを積極的に考えます。これにより、テキストのような純粋に受動的な編集可能な表現から得られるものとは異なるアイデアが得られます。
言語ワークベンチは、ストレージ表現と編集可能な表現を分離します。ストレージ表現は、抽象表現のシリアライズになりました。これを行う一般的な方法はXMLですが、このXMLは人間が編集するように設計されていません。ストレージ表現としてXMLを持つことは、ツールの相互運用性に役立ちますが、そのような相互運用性は非常に難しい可能性があります。
コード生成はほぼ同じですが、このようなツールは従来のソースを実行可能な表現として扱う傾向があります。通常の言語ソースファイルを生成する場合は、これらのファイルは実際にはソースではなく、他の生成されたコードと同様に直接編集しないでください。言語ワークベンチが成熟するにつれて、バイトコードのような編集不可能な構造の生成への依存度が高まるはずです。
言語ワークベンチにおいて、自明ではない重要な機能の一つは、抽象表現がエラーや曖昧さに対応できる必要があるということです。従来、抽象表現を持つのであれば、それを正しく保つ必要があり、誤った情報を入れるべきではないと考えられてきました。しかし、この前提は使い勝手の悪さにつながりました。IntelliJ以降のIDEはこれを認識し、エラー状態にうまく対応しています。例えば、コンパイルエラーがあるプログラムでもリファクタリングを実行できます(これは使いやすさのために非常に重要です)。
複数のソースから複雑な情報を取得したい場合は、さらに重要になります。すべてを常に一貫して正しく保つことはできません。そのため、曖昧でエラーのある状態に対処し、入力を拒否するのではなくエラーを強調表示する必要があります。また、計算不能な情報(ドキュメントなど)をモデルに簡単に入力できるようにする必要があります。これにより、スキャンしたメモ書きを結果のDSLコードに直接リンクできます。
新しいDSLの定義
このような設定が整っていれば、新しいDSLを定義する主な部分は3つあります。
- 抽象構文、つまり抽象表現のスキーマを定義します。
- 投影を通じて抽象表現を操作するためのエディターを定義します。
- ジェネレーターを定義します。これは、抽象表現を実行可能な表現に変換する方法を記述します。実際には、ジェネレーターがDSLのセマンティクスを定義します。
これが主要な3つですが、バリエーションはあります。前述したように、1つのDSLに対して複数のエディターやジェネレーターを持つことは可能です。複数のエディターは一般的になる可能性があります。人によって異なる編集体験を好むかもしれません。例えば、Intentionalのエディターでは、同じモデルの異なる投影を簡単に切り替えることができるため、階層的なデータ構造をlispのようなリスト、ネストされたボックス、またはツリーとして表示できます。
複数のジェネレーターは、いくつかの理由で登場する可能性があります。同様のことを行う異なるフレームワークに対してバインドしたい場合があります。良い例としては、厄介なほど多くのSQLの方言です。もう一つの理由は、異なるパフォーマンス特性やライブラリ依存関係を持つ、異なる実装のトレードオフのためです。3つ目の理由は、異なる言語を生成するためです。例えば、1つのDSLでJavaまたはC#のどちらかを生成できるようにすることです。
別のオプションとして、ストレージ表現のトランスレーターを定義することもできます。言語ワークベンチには、抽象表現のシリアライズを自動的に処理するデフォルトのストレージスキーマが付属していると想定できます。ただし、相互運用性やツール間の転送のために、代替のストレージ表現を生成したい場合もあります。ジェネレーターとは異なり、これは双方向の表現である必要があります。
異なる種類のジェネレーターは、人間が読めるドキュメントを定義します。これは、言語ワークベンチにおけるjavadocと同等のものです。言語ワークベンチとのほとんどの対話はエディターを通じて行われますが、Webまたは紙のドキュメントを生成する必要は依然としてあります。
言語ワークベンチの定義
言語ワークベンチを構成する要素についての一般的に受け入れられている定義はありません。この記事のために私がこの用語を作ったばかりなので、驚くことではありません!しかし、ソフトウェア業界の多くのトピック(例:コンポーネント、サービス指向アーキテクチャ)を取り巻く蔓延する曖昧さを回避するために、言語ワークベンチの本質的な特性について最初に試してみるべきだと感じています。必要な背景を提供したので、簡単に述べることができます。
- ユーザーは、相互に完全に統合された新しい言語を自由に定義できます。
- 情報の主要なソースは、永続的な抽象表現です。
- 言語設計者は、DSLをスキーマ、エディター(複数可)、およびジェネレーター(複数可)の3つの主要な部分で定義します。
- 言語ユーザーは、投影型エディターを通じてDSLを操作します。
- 言語ワークベンチは、不完全または矛盾する情報を抽象表現に永続化できます。
言語ワークベンチが言語指向プログラミングのトレードオフをどのように変えるか。
少し前に、言語指向プログラミングのトレードオフについて議論しました。言語ワークベンチは、考慮すべき多くの新しい要素とともに、そのトレードオフに明らかに影響を与えます。
言語ワークベンチが方程式にもたらす最も明白な変化は、外部DSLの作成の容易さです。パーサーを作成する必要はもうありません。抽象構文を定義する必要がありますが、それは実際には非常に簡単なデータモデリングのステップです。さらに、DSLには強力なIDEが与えられます。ただし、エディターの定義にはある程度の時間が必要です。ジェネレーターは依然として行う必要があるものであり、私の感覚では以前よりはそれほど簡単ではありません。しかし、優れたシンプルなDSLのジェネレーターを構築することは、演習の中で最も簡単な部分の1つです。
言語ワークベンチの2つ目の大きな利点は、シンボリック統合が得られることです。Excelのような数式言語を取り入れて、それを独自の専門言語にプラグインできることは非常に便利です。また、1つの言語でシンボルを変更し、それらの変更をシステム全体に波及させることもできます。これは、言語ワークベンチでは考えられることです(まだそれを行うことができるものがあるかどうかはわかりません)。
リファクタリングの問題は、言語ワークベンチにおける大きな問題の1つです。言語ワークベンチの使用を説明する際、「最初にDSLを定義し、次にそれを使用して何かを構築する」という罠に陥りやすいです。過去に私が書いたものを読んだことがあるなら、その概念は多くの警鐘を鳴らすはずです。私は進化的なデザインの大ファンです。この文脈では、DSLとDSLで構築されたコードを一緒に進化させることができる必要があることを意味します。それは難しい問題ですが、Intentionalの開発の初期段階から認識されていました。成熟した言語ワークベンチでDSLをその使用と並行して進化させることがどれほどうまくいくかはまだわかりませんが、この機能の欠如はそれらに対する大きなマイナスになるでしょう。
私が言語ワークベンチで見ている最大の短期的な問題は、ベンダーロックインのリスクです。スキーマ、エディター、およびジェネレーターの3つを定義するための標準はありません。言語ワークベンチで言語を定義すると、その言語ワークベンチに縛られます。異なる言語ワークベンチ間のインターチェンジの標準はありません。言語ワークベンチを変更したい場合は、3つを再実装する必要があります。時間が経つにつれて、DSLをインターチェンジするために設計された特別なストレージ表現、つまりインターチェンジ表現が見られる可能性があります。しかし、ここで堅牢な話が現れない限り、ベンダーロックインは依然として大きなリスクです。(MDAはこれに対する答えを提供すると主張していますが、せいぜい部分的です。)
これに対する緩和策の1つは、言語ワークベンチをソースの生成を支援するツールと見なすことです。この例としては、言語ワークベンチを使用して、すべてのJava XML構成ファイルを管理下に置くことです。最悪の事態が発生し、言語ワークベンチを放棄する必要がある場合でも、生成された構成ファイルは残っています。生成されたファイルの見栄えに注意を払えば、自分で書くよりも悪くなることはないかもしれません。より深い機能についても、構造化されたJavaコードを生成できます。これによりリスクはある程度軽減されますが、少なくとも完全に途方に暮れることはありません。ただし、ベンダーロックインは依然として考慮すべきことです。
ツールに関するこの問題は、ソースとしてテキストファイルから離れることの結果の1つです。他の問題が発生します。テキストでは解決できたが、抽象表現の中心的な役割で再考する必要がある問題です。リストの最上位にあるのは、バージョン管理です。テキストソースに対して、優れたdiffおよびマージ機能を備えた効果的なバージョン管理を行う方法を知っています。効果的な言語ワークベンチでは、抽象表現自体のdiffとマージを提供できる必要があります。理論的にはこれは解決可能であり、真のセマンティックdiffの機会を開きます(シンボルの名前変更が、テキストで行うようにその結果から推測する必要があるだけではなく、その行為として理解される場合)。Intentionalはここで良い解決策を持っているように見えますが、まだ実際に試していません。
ポジティブな点に戻ると、カスタム言語とエディターの組み合わせにより、DSLをプログラマー以外の人も編集できるようになるかもしれません。さらに、シンボリック統合により、ユーザーコードとコアプログラムの同期が取れなくなるという問題が解消されます。エディターの使用は、COBOL推論を打破するのに役立つ最大のツールである可能性があります。つまり、ツールがユーザーインタラクション用にカスタマイズされた環境を提供することです。
ドメインエキスパートを開発作業に直接参加させるというこの約束は、おそらく言語ワークベンチの約束の中で最も魅力的な部分です。プログラマーが生産性を向上させるためにどのようなツールを使用しても、アイドルループを最適化しているという感覚があることが何度もわかります。私が訪問するほとんどのプロジェクトでは、最大の問題は開発者とビジネス間のコミュニケーションです。それがうまくいっていれば、二流の技術でも進歩することができます。その関係が壊れていれば、Smalltalkでも救うことはできません。
言語指向プログラミングの支持者のほとんどは、ドメインエキスパートをもっと関与させることについて話します。実際、秘書がLispの内部DSLで楽しそうにプログラミングしているという主張さえ聞いたことがあります。しかし、ほとんどの場合、これらの努力は本当にうまくいきませんでした。焦点を絞った外部DSLの利点と、洗練されたエディターおよび開発環境を組み合わせることで、この問題についに取り組み始めることができるかもしれません。もしそうなら、その見返りは莫大になるでしょう。実際、このユーザーの関与が、Charles Simonyiの仕事の主な原動力であり、Intentional Softwareのほとんどの決定を支えていることがどれほど重要であるかは驚くべきことです。
これらのツールの最大の短期的制限は成熟度です。これらのツールが開発者の最先端に到達するまでにはしばらく時間がかかるでしょう。しかし、ご存知のとおり、それはすぐに変わる可能性があります。10年前のツールや言語の選択を今と比較してみてください。
DSLの概念を変える
この記事で使用した例は、実際にはDSLの非常に面白くない例です。それらは、話しやすく構築しやすかったため使用しました。しかし、より複雑な合意DSLでさえ非常に慣例的です。それが従来のテキストDSLとしてどのように行われるかは簡単にわかります。多くの人はグラフィカルDSLの作成を考えていますが、これらでさえその可能性を十分に捉えているわけではありません。「言語」という用語を使用する上で最大の危険性は、言語ワークベンチで実際に何ができるかのポイントを見逃してしまう可能性があるということです。
OOPSLA 2004について同僚と話していたとき、最大の話題はJonathon EdwardsによるExample Centric Programmingのデモンストレーションでした。重要なアイデアは、プログラムコードだけでなく、そのコードでのサンプル実行の結果も示すエディターでした。私たちは抽象化を操作しますが、具体的なケースで考える方が簡単であることが多いという考えでした。例に傾倒することは、テスト駆動開発の魅力の大部分です。私はそれをSpecification by Exampleと呼んでいます。
エドワーズは、自身のアイデアをさらに発展させ、Subtextというツールを開発しました。Subtextは、言語ワークベンチのいくつかの原則、特にテキスト形式のソースコードからの脱却という考え方を共有しています。Subtextは、新しい言語を簡単に定義するという点ではそれほど興味深いものではありませんが、言語ワークベンチが言語とツールを深く絡み合ったものとして考えさせるようになるにつれて、どのような思考が発展する可能性があるのかを示す興味深い一例となります。
実際、これが言語ワークベンチがCOBOLの推論による悪影響を回避できる最も強力な理由かもしれません。以前に述べたように、私たちは常にユーザーをアマチュアプログラマーとして力を与える技術を生み出してきましたが、定期的に失敗しています。アマチュアプログラマーを効果的に成功させている技術の1つであるスプレッドシートを考えてみましょう。
ほとんどのプログラマーはスプレッドシートをプログラミング環境とは考えていません。しかし、多くのアマチュアプログラマーはそれらを使用して高度なシステムを作成しています。スプレッドシートは、アマチュアプログラミングツールに必要な特性を示唆する、魅力的なプログラミング環境です。
- 即時フィードバック - 計算例の結果をすぐに表示することを含みます。
- ツールと言語の深い統合
- テキスト形式のソースがない
- すべての情報を常に表示する必要がない - 数式はそれらを含むセルを編集するときにのみ表示され、それ以外の場合は値が表示されます。
スプレッドシートは非常にフラストレーションがたまるものでもあります。それらの構造の欠如は実験を促しますが、少し構造があれば特定の問題をより簡単に処理できると感じることがよくあります。
したがって、言語ワークベンチのDSLについて考えるとき、ここで示してきたような言語やモデラーに愛されるグラフィカル言語を考えるのではなく、次世代のスプレッドシートのようなものを考えるべきです。
結論
この記事を書いた主な目的は、言語ワークベンチの概要を紹介することでした。少なくとも、もしあなたのマネージャーがプログラミング環境全体をそれらに置き換えるように求めてきた場合に、それに対応できる程度には理解していただけたことを願っています。
私の見るところ、言語ワークベンチは2つの主な利点を提供します。1つは、より良いツールを開発者に提供することによって、プログラマーの生産性を向上させることです。もう1つは、ドメインエキスパートが開発ベースに直接貢献する機会を増やすことによって、ドメインエキスパートとのより密接な関係を築き、開発の生産性を向上させることです。これらの利点が実際に実現するかどうかは、時間が経てばわかるでしょう。2つを見ると、生産性の向上がより可能性が高いと思いますが、影響は少ないと思います。言語ワークベンチが開発とドメインエキスパートの関係に深刻な影響を与えれば、それは計り知れない効果をもたらす可能性がありますが、成功するためにはCOBOLの推論を克服する必要があります。
おそらく、私が気づいた最も興味深いことは、言語ワークベンチの経験を積んだ後、DSLがどのようなものになるのか、おそらくほとんど見当もつかないということです。これまでのところ、私の考えは、テキスト形式およびグラフィカルな言語がどのようなものであるかという考えに大きく制約されています。しかし、エディターとスキーマの相互作用は、ほとんどの人が外部DSLについて持っている考えとはまったく異なる可能性を切り開きます。言語ワークベンチが期待に応えることができれば、10年後には、私たちが今DSLはどうあるべきだと考えているかを振り返って笑うでしょう。
私が示唆したように、言語ワークベンチはまだ開発の非常に初期段階にあります。本格的にそれらを試すことができるようになるには、数年かかるでしょう。私は、それらがその支持者が期待するように、ソフトウェア開発の様相を変えるかどうかについて予測をするつもりはありません。私はテクノロジー未来学者ではありません。私が信じているのは、言語ワークベンチが私たちの視野の端にある最も興味深いアイデアの1つであるということです。もしそれらがその潜在能力を実現すれば、私たちの職業に間違いなく大きな影響を与えるでしょう。たとえそうでないとしても、私はそれらが多くの興味深いアイデアにつながると確信しています。
ですから、この分野に注目しておくことをお勧めします。それは興味深い分野であり、長年にわたって興味を持ち続けるのに十分な活気があります。私はここ数ヶ月でそれらをよく見て、これからも関心を持ち続けるつもりです。
さらに読む
さらに読むための参考資料を私のblikiに置くことにしました。これにより、更新を追跡しやすくなります。
謝辞
同僚のThoughtWorkerであるMatt Foemmelに心から感謝します。Mattは長年Thoughtworksの中核となるツール職人であり、常に開発作業を前進させる方法を探し続けています。彼は2004年初頭にインテンショナルプログラミングに興味を持ち始め、私は彼の調査から多大な恩恵を受けてきました。彼のこの1年間のインテンショナルソフトウェアでの開発への積極的な関与は、この環境を理解する上で非常に役立ちました。
私が賞賛する数少ないソフトウェアツール企業の1つがこの分野で取り組んでいると聞いたとき、私はすぐに興味を持ちました。セルゲイ・ドミトリエフが私から数マイル離れたボストンに拠点を置いているという事実は、さらに良いことでした。セルゲイは、MPSの開発を進める中で、私に驚くべきアクセスを提供してくれました。彼と彼のチームは、この合意例を取り上げ、それをMPSに実装してくれたので、私は完全に実体のないものではない何かを説明することができました。イゴール・アルシャニコフは、開発中のソフトウェアで必然的に発生する問題を抱えたときに、私を助けてくれました。
インテンショナルソフトウェアは、アイデアを開発している間、ここ数年は非常に静かでした。チャールズ・シモニーは、彼らのツールと計画への驚くべきアクセスを私に許可してくれました。また、現在インテンショナルに所属しているマグナス・クリスターソンとのコラボレーションを再開することもできました。
80年代と90年代の英国の多くの人々と同じように、私はスティーブ・クック率いるOOコミュニティから多大な恩恵を受けました。それ以来、彼はUML仕様の難解な部分を乗り越えるのを助けてくれており、この記事のために、彼はマイクロソフトのソフトウェアファクトリーイニシアチブに関する情報を提供してくれました。キース・ショート、ジャック・グリーンフィールド、アラン・ウィルズ、スチュアート・ケントなど、長年の友人がこのプロジェクトに関わってくれたのは素晴らしいことでした。
ダニエル・ジャクソン教授のおかげで、MITへの楽しい訪問を何度かしました。特に、彼は私にジョナサン・エドワーズを紹介してくれました。初めて見たとき、私はその劇的なアイデアをあまり理解していませんでしたが、最終的には理解するようになりました。
Thoughtworksにいることの最大の利点の1つは、興味深いことをしている非常に才能のある人々にすぐにアクセスできることです。この場合、インテンショナルツールと密接に連携している人々(マット・フォメル、ジェレミー・ステッル=スミス、ジェイソン・ワズワース)にアクセスできたことは非常に役立ちました。
そして、同僚のThoughtWorkerであるレベッカ・パーソンズとデイブ・ライスは、私の考えを軌道に乗せるのに不可欠な、素晴らしい知的議論の場を提供してくれました。
この記事を書くためのこのような背景情報を提供してくれただけでなく、レベッカ・パーソンズ、デイブ「ベダーラ」トーマス、スティーブ・クック、ジャック・グリーンフィールド、ビル・カプト、オビー・フェルナンデス、マグナス・クリスターソン、イゴール・アルシャニコフから、初期のドラフトについて役立つレビューもいただきました。
ルーベン・ヤゲル、デイブ・フーバー、ラビ・モハンに、タイプミスを見つけて送ってくれたことに感謝します。
重要な改訂
2005年6月12日: 初回公開。