
Micro Frontends
Good frontend development is hard. Scaling frontend development so that many teams can work simultaneously on a large and complex product is even harder. In this article we'll describe a recent trend of breaking up frontend monoliths into many smaller, more manageable pieces, and how this architecture can increase the effectiveness and efficiency of teams working on frontend code. As well as talking about the various benefits and costs, we'll cover some of the implementation options that are available, and we'll dive deep into a full example application that demonstrates the technique.
19 June 2019
Cam Jackson is a full-stack web developer and consultant at Thoughtworks, with a particular interest in how large organisations scale their frontend development process and practices. He has worked with clients across multiple industries and countries, helping them to deliver web applications more efficiently and effectively.
In recent years, microservices have exploded in popularity, with many organisations using this architectural style to avoid the limitations of large, monolithic backends. While much has been written about this style of building server-side software, many companies continue to struggle with monolithic frontend codebases.
Perhaps you want to build a progressive or responsive web application, but can't find an easy place to start integrating these features into the existing code. Perhaps you want to start using new JavaScript language features (or one of the myriad languages that can compile to JavaScript), but you can't fit the necessary build tools into your existing build process. Or maybe you just want to scale your development so that multiple teams can work on a single product simultaneously, but the coupling and complexity in the existing monolith means that everyone is stepping on each other's toes. These are all real problems that can all negatively affect your ability to efficiently deliver high quality experiences to your customers.
Lately we are seeing more and more attention being paid to the overall architecture and organisational structures that are necessary for complex, modern web development. In particular, we're seeing patterns emerge for decomposing frontend monoliths into smaller, simpler chunks that can be developed, tested and deployed independently, while still appearing to customers as a single cohesive product. We call this technique micro frontends, which we define as
"An architectural style where independently deliverable frontend applications are composed into a greater whole"
In the November 2016 issue of the Thoughtworks technology radar, we listed micro frontends as a technique that organisations should Assess. We later promoted it into Trial, and finally into Adopt, which means that we see it as a proven approach that you should be using when it makes sense to do so.
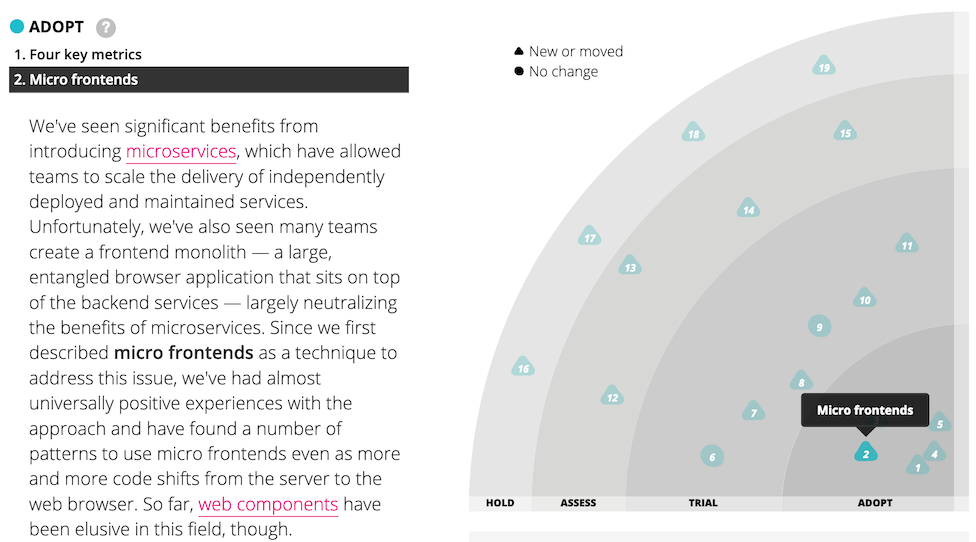
Figure 1: Micro frontends has appeared on the tech radar several times.
Some of the key benefits that we've seen from micro frontends are
- smaller, more cohesive and maintainable codebases
- more scalable organisations with decoupled, autonomous teams
- the ability to upgrade, update, or even rewrite parts of the frontend in a more incremental fashion than was previously possible
It is no coincidence that these headlining advantages are some of the same ones that microservices can provide.
Of course, there are no free lunches when it comes to software architecture - everything comes with a cost. Some micro frontend implementations can lead to duplication of dependencies, increasing the number of bytes our users must download. In addition, the dramatic increase in team autonomy can cause fragmentation in the way your teams work. Nonetheless, we believe that these risks can be managed, and that the benefits of micro frontends often outweigh the costs.
Benefits
Rather than defining micro frontends in terms of specific technical approaches or implementation details, we instead place emphasis on the attributes that emerge and the benefits they give.
Incremental upgrades
For many organisations this is the beginning of their micro frontends journey. The old, large, frontend monolith is being held back by yesteryear's tech stack, or by code written under delivery pressure, and it's getting to the point where a total rewrite is tempting. In order to avoid the perils of a full rewrite, we'd much prefer to strangle the old application piece by piece, and in the meantime continue to deliver new features to our customers without being weighed down by the monolith.
This often leads towards a micro frontends architecture. Once one team has had the experience of getting a feature all the way to production with little modification to the old world, other teams will want to join the new world as well. The existing code still needs to be maintained, and in some cases it may make sense to continue to add new features to it, but now the choice is available.
The endgame here is that we're afforded more freedom to make case-by-case decisions on individual parts of our product, and to make incremental upgrades to our architecture, our dependencies, and our user experience. If there is a major breaking change in our main framework, each micro frontend can be upgraded whenever it makes sense, rather than being forced to stop the world and upgrade everything at once. If we want to experiment with new technology, or new modes of interaction, we can do it in a more isolated fashion than we could before.
Simple, decoupled codebases
The source code for each individual micro frontend will by definition be much smaller than the source code of a single monolithic frontend. These smaller codebases tend to be simpler and easier for developers to work with. In particular, we avoid the complexity arising from unintentional and inappropriate coupling between components that should not know about each other. By drawing thicker lines around the bounded contexts of the application, we make it harder for such accidental coupling to arise.
Of course, a single, high-level architectural decision (i.e. "let's do micro frontends"), is not a substitute for good old fashioned clean code. We're not trying to exempt ourselves from thinking about our code and putting effort into its quality. Instead, we're trying to set ourselves up to fall into the pit of success by making bad decisions hard, and good ones easy. For example, sharing domain models across bounded contexts becomes more difficult, so developers are less likely to do so. Similarly, micro frontends push you to be explicit and deliberate about how data and events flow between different parts of the application, which is something that we should have been doing anyway!
Independent deployment
Just as with microservices, independent deployability of micro frontends is key. This reduces the scope of any given deployment, which in turn reduces the associated risk. Regardless of how or where your frontend code is hosted, each micro frontend should have its own continuous delivery pipeline, which builds, tests and deploys it all the way to production. We should be able to deploy each micro frontend with very little thought given to the current state of other codebases or pipelines. It shouldn't matter if the old monolith is on a fixed, manual, quarterly release cycle, or if the team next door has pushed a half-finished or broken feature into their master branch. If a given micro frontend is ready to go to production, it should be able to do so, and that decision should be up to the team who build and maintain it.
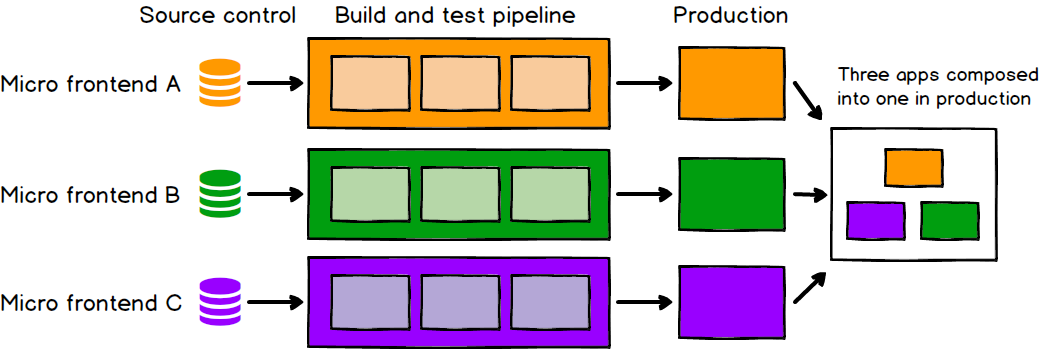
Figure 2: Each micro frontend is deployed to production independently
Autonomous teams
As a higher-order benefit of decoupling both our codebases and our release cycles, we get a long way towards having fully independent teams, who can own a section of a product from ideation through to production and beyond. Teams can have full ownership of everything they need to deliver value to customers, which enables them to move quickly and effectively. For this to work, our teams need to be formed around vertical slices of business functionality, rather than around technical capabilities. An easy way to do this is to carve up the product based on what end users will see, so each micro frontend encapsulates a single page of the application, and is owned end-to-end by a single team. This brings higher cohesiveness of the teams' work than if teams were formed around technical or “horizontal” concerns like styling, forms, or validation.
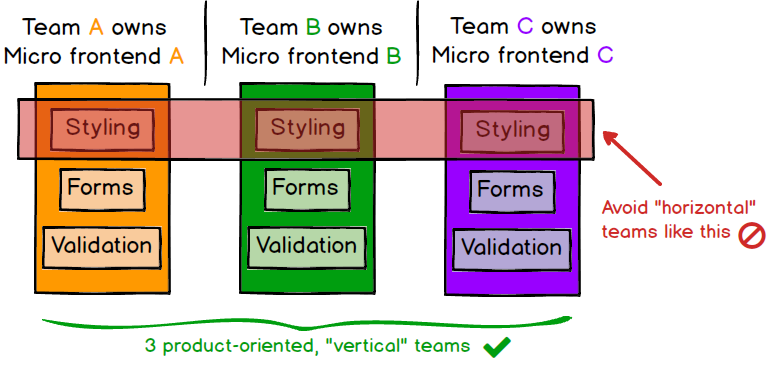
Figure 3: Each application should be owned by a single team
In a nutshell
In short, micro frontends are all about slicing up big and scary things into smaller, more manageable pieces, and then being explicit about the dependencies between them. Our technology choices, our codebases, our teams, and our release processes should all be able to operate and evolve independently of each other, without excessive coordination.
The example
Imagine a website where customers can order food for delivery. On the surface it's a fairly simple concept, but there's a surprising amount of detail if you want to do it well
- There should be a landing page where customers can browse and search for restaurants. The restaurants should be searchable and filterable by any number of attributes including price, cuisine, or what a customer has ordered previously
- Each restaurant needs its own page that shows its menu items, and allows a customer to choose what they want to eat, with discounts, meal deals, and special requests
- 顧客は、注文履歴の確認、配送状況の追跡、支払い方法のカスタマイズなどが可能なプロフィールページを持つ必要があります。
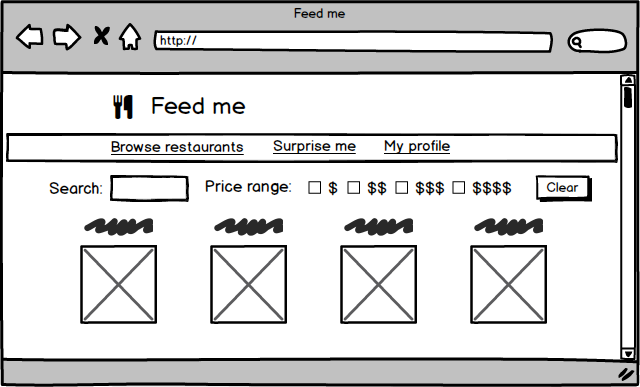
図4:フードデリバリーウェブサイトには、いくつかの比較的複雑なページが存在する可能性があります。
各ページには十分な複雑性があり、各ページに専任チームを配置することは容易に正当化できます。そして、これらの各チームは、他のすべてのチームとは独立して自分のページに取り組むことができるはずです。彼らは、他のチームとの競合や調整を心配することなく、コードの開発、テスト、デプロイ、保守を行うことができる必要があります。しかし、顧客は依然として単一のシームレスなウェブサイトを見る必要があります。
この記事の残りの部分では、例としてコードやシナリオが必要な場合は常に、この例となるアプリケーションを使用します。
Integration approaches
上記の定義がかなり緩やかなものであるため、マイクロフロントエンドと合理的に呼ばれることができるアプローチは多数存在します。このセクションでは、いくつかの例を示し、そのトレードオフについて説明します。すべてのアプローチを通じて、自然なアーキテクチャが出現します。一般的に、アプリケーションの各ページにマイクロフロントエンドがあり、単一の**コンテナアプリケーション**があり、
- ヘッダーやフッターなどの共通ページ要素をレンダリングします。
- 認証やナビゲーションなどのクロスカットに関する問題に対処します。
- さまざまなマイクロフロントエンドをページにまとめて配置し、各マイクロフロントエンドにいつどこで自身をレンダリングするかを指示します。
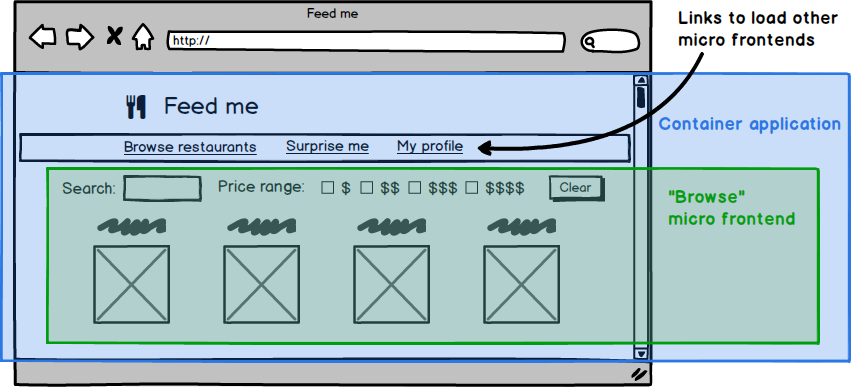
図5:通常、ページの視覚構造からアーキテクチャを導き出すことができます。
Server-side template composition
フロントエンド開発に対する明らかに新しいものではないアプローチから始めます。つまり、複数のテンプレートまたはフラグメントからサーバー上でHTMLをレンダリングすることです。共通のページ要素を含むindex.htmlがあり、サーバーサイドインクルードを使用して、フラグメントHTMLファイルからページ固有のコンテンツを挿入します。
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title>Feed me</title>
</head>
<body>
<h1>🍽 Feed me</h1>
<!--# include file="$PAGE.html" -->
</body>
</html>
このファイルはNginxを使用して提供し、要求されているURLと照合することで$PAGE変数を設定します。
server {
listen 8080;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
ssi on;
# Redirect / to /browse
rewrite ^/$ https://:8080/browse redirect;
# Decide which HTML fragment to insert based on the URL
location /browse {
set $PAGE 'browse';
}
location /order {
set $PAGE 'order';
}
location /profile {
set $PAGE 'profile'
}
# All locations should render through index.html
error_page 404 /index.html;
}
これはかなり標準的なサーバーサイドコンポジションです。これをマイクロフロントエンドと正当に呼ぶことができる理由は、コードを分割して、各部分が独立したチームによって配信できる自己完結型のドメイン概念を表すようにしたことです。ここでは、さまざまなHTMLファイルがどのようにWebサーバーに配置されるかは示されていませんが、それぞれ独自のデプロイメントパイプラインを持ち、他のページに影響を与えたり、考慮したりすることなく、1つのページへの変更をデプロイできることが前提となっています。
さらに独立性を高めるために、各マイクロフロントエンドのレンダリングと提供を担当する個別のサーバーを設け、その前に1つのサーバーを配置して他のサーバーにリクエストを行うことができます。応答を注意深くキャッシュすることにより、レイテンシに影響を与えることなくこれを実行できます。
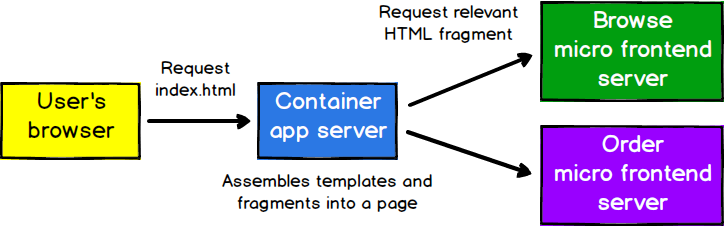
図6:これらのサーバーはそれぞれ独立して構築およびデプロイできます。
この例は、マイクロフロントエンドが必ずしも新しい技術ではなく、複雑である必要がないことを示しています。設計上の決定がコードベースとチームの自律性にどのように影響するかを注意深く検討すれば、テクノロジースタックに関係なく、多くの同じメリットを実現できます。
Build-time integration
時々見かけるアプローチの1つは、各マイクロフロントエンドをパッケージとして公開し、コンテナアプリケーションですべてをライブラリ依存関係として含めることです。例として、コンテナのpackage.jsonは次のようになります。
{
"name": "@feed-me/container",
"version": "1.0.0",
"description": "A food delivery web app",
"dependencies": {
"@feed-me/browse-restaurants": "^1.2.3",
"@feed-me/order-food": "^4.5.6",
"@feed-me/user-profile": "^7.8.9"
}
}
最初は、これは理にかなっているように見えます。通常どおり、単一のデプロイ可能なJavaScriptバンドルを作成することで、さまざまなアプリケーションから共通の依存関係を重複排除できます。ただし、このアプローチでは、製品の個々の部分に変更を加えるために、すべてのマイクロフロントエンドを再コンパイルしてリリースする必要があります。マイクロサービスと同様に、このような**段階的リリースプロセス**によって引き起こされる十分な問題を目撃してきたため、この種のマイクロフロントエンドのアプローチを強くお勧めしません。
独立して開発およびテストできる個別のコードベースにアプリケーションを分割するという苦労をした後、リリース段階でそのカップリングをすべて再導入しないようにしましょう。ビルド時ではなく、実行時にマイクロフロントエンドを統合する方法を見つける必要があります。
Run-time integration via iframes
ブラウザでアプリケーションを組み立てる最も単純なアプローチの1つは、控えめなiframeです。本質的に、iframeを使用すると、独立したサブページからページを簡単に構築できます。また、スタイリングやグローバル変数が互いに干渉しないという点で、高い分離度を提供します。
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<iframe id="micro-frontend-container"></iframe>
<script type="text/javascript">
const microFrontendsByRoute = {
'/': 'https://browse.example.com/index.html',
'/order-food': 'https://order.example.com/index.html',
'/user-profile': 'https://profile.example.com/index.html',
};
const iframe = document.getElementById('micro-frontend-container');
iframe.src = microFrontendsByRoute[window.location.pathname];
</script>
</body>
</html>
サーバーサイドインクルードオプションと同様に、iframeからページを構築することは新しい技術ではなく、それほどエキサイティングではないように見えるかもしれません。しかし、前にリストされたマイクロフロントエンドの主な利点を再検討すると、アプリケーションのスライス方法とチームの構成に注意すれば、iframeはほとんどの場合、条件を満たします。
iframeを選択することに抵抗を示すことが多いです。その抵抗の一部は、iframeが少し「気持ち悪い」という直感的な感覚に起因しているように見えますが、人々がiframeを避けるいくつかの正当な理由があります。上記で説明した簡単な分離は、他のオプションよりも柔軟性が低くなる傾向があります。アプリケーションの異なる部分間の統合を構築するのは困難な場合があり、ルーティング、履歴、ディープリンクをより複雑にし、ページを完全にレスポンシブにする際に追加の課題が生じます。
Run-time integration via JavaScript
次に説明するアプローチはおそらく最も柔軟性があり、チームが最も頻繁に採用しているアプローチです。各マイクロフロントエンドは<script>タグを使用してページに含まれ、ロード時にグローバル関数を入力点として公開します。次に、コンテナアプリケーションは、どのマイクロフロントエンドをマウントするべきかを判断し、関連する関数を呼び出して、マイクロフロントエンドにいつどこで自身をレンダリングするかを指示します。
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<!-- These scripts don't render anything immediately -->
<!-- Instead they attach entry-point functions to `window` -->
<script src="https://browse.example.com/bundle.js"></script>
<script src="https://order.example.com/bundle.js"></script>
<script src="https://profile.example.com/bundle.js"></script>
<div id="micro-frontend-root"></div>
<script type="text/javascript">
// These global functions are attached to window by the above scripts
const microFrontendsByRoute = {
'/': window.renderBrowseRestaurants,
'/order-food': window.renderOrderFood,
'/user-profile': window.renderUserProfile,
};
const renderFunction = microFrontendsByRoute[window.location.pathname];
// Having determined the entry-point function, we now call it,
// giving it the ID of the element where it should render itself
renderFunction('micro-frontend-root');
</script>
</body>
</html>
上記は明らかに原始的な例ですが、基本的なテクニックを示しています。ビルド時の統合とは異なり、各bundle.jsファイルを個別にデプロイできます。また、iframeとは異なり、マイクロフロントエンド間で自由に統合を構築できます。たとえば、必要に応じて各JavaScriptバンドルをダウンロードするだけにするか、マイクロフロントエンドをレンダリングするときにデータを入出力するかなど、上記のコードをさまざまな方法で拡張できます。
このアプローチの柔軟性と独立したデプロイ可能性を組み合わせることで、デフォルトの選択肢となり、実際に最も頻繁に見られるものとなっています。 完全な例に入ったら、さらに詳しく調べます。
Run-time integration via Web Components
前述のアプローチの1つのバリエーションは、各マイクロフロントエンドがコンテナが呼び出すグローバル関数を定義する代わりに、コンテナがインスタンス化するHTMLカスタム要素を定義することです。
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<!-- These scripts don't render anything immediately -->
<!-- Instead they each define a custom element type -->
<script src="https://browse.example.com/bundle.js"></script>
<script src="https://order.example.com/bundle.js"></script>
<script src="https://profile.example.com/bundle.js"></script>
<div id="micro-frontend-root"></div>
<script type="text/javascript">
// These element types are defined by the above scripts
const webComponentsByRoute = {
'/': 'micro-frontend-browse-restaurants',
'/order-food': 'micro-frontend-order-food',
'/user-profile': 'micro-frontend-user-profile',
};
const webComponentType = webComponentsByRoute[window.location.pathname];
// Having determined the right web component custom element type,
// we now create an instance of it and attach it to the document
const root = document.getElementById('micro-frontend-root');
const webComponent = document.createElement(webComponentType);
root.appendChild(webComponent);
</script>
</body>
</html>
ここでの最終結果は、前の例と非常によく似ており、主な違いは、「Webコンポーネントの方法」で作業することを選択していることです。Webコンポーネントの仕様が好きで、ブラウザが提供する機能を使用するというアイデアが好きであれば、これは良い選択肢です。コンテナアプリケーションとマイクロフロントエンド間の独自のインターフェースを定義することを好む場合は、代わりに前の例を好むかもしれません。
Styling
CSSは言語として本質的にグローバル、継承、カスケードであり、伝統的にはモジュールシステム、名前空間、カプセル化がありません。これらの機能の一部は現在存在しますが、ブラウザのサポートが不足していることがよくあります。マイクロフロントエンドの環境では、これらの問題の多くがさらに悪化します。たとえば、あるチームのマイクロフロントエンドにh2 { color: black; }というスタイルシートがあり、別のチームにh2 { color: blue; }というスタイルシートがあり、これらのセレクターの両方が同じページに添付されている場合、誰かが失望することになります!これは新しい問題ではありませんが、これらのセレクターが異なるチームによって異なる時期に記述されており、コードがおそらく個別のリポジトリに分割されているため、発見がより困難になるという事実によって悪化しています。
長年にわたり、CSSをより管理しやすくするための多くのアプローチが発明されてきました。一部の人は、BEMなどの厳格な命名規則を使用して、セレクターが意図した場所にのみ適用されるようにします。他の人は、開発者の規律のみに依存することを好まず、SASSなどのプリプロセッサを使用します。そのセレクターのネストは名前空間の一種として使用できます。新しいアプローチとしては、CSS modulesまたはさまざまなCSS-in-JSライブラリのいずれかを使用して、すべてのスタイルをプログラムで適用することで、開発者が意図した場所にのみスタイルが直接適用されるようにします。または、よりプラットフォームベースのアプローチとして、シャドウDOMもスタイルの分離を提供します。
開発者が互いに独立してスタイルを記述し、単一のアプリケーションに合成されたときにコードが予測可能な動作をするという自信を持つことができる方法を見つける限り、選択するアプローチはそれほど重要ではありません。
Cross-application communication
マイクロフロントエンドに関する最もよくある質問の1つは、それらをどのように連携させるかです。一般的に、可能な限り少ない通信量にすることをお勧めします。なぜなら、そうすることで、そもそも回避しようとしている不適切な結合を再導入してしまうことが多いからです。
とはいえ、アプリ間の通信は一定のレベルで必要になることがよくあります。カスタムイベントを使用すると、マイクロフロントエンドを間接的に通信させることができます。これは直接的な結合を最小限に抑える良い方法ですが、マイクロフロントエンド間に存在する契約を決定および強制するのが難しくなります。あるいは、コールバックとデータを下方向に渡すReactモデル(この場合はコンテナアプリケーションからマイクロフロントエンドへ下方向)も、契約をより明確にする良い解決策です。3番目の選択肢として、アドレスバーを通信メカニズムとして使用する方法があり、これは後で詳しく説明します。
どのようなアプローチを選択する場合でも、マイクロフロントエンドは互いにメッセージやイベントを送信することで通信し、共有状態を持たないようにする必要があります。マイクロサービス間でデータベースを共有することと同様に、データ構造とドメインモデルを共有するとすぐに、大量の結合が作成され、変更が非常に困難になります。
スタイルと同様に、ここでうまく機能するいくつかの異なるアプローチがあります。最も重要なことは、導入しようとしている結合の種類と、その契約を時間をかけてどのように維持するかについて、よく考えることです。マイクロサービス間の統合と同様に、異なるアプリケーションとチーム全体で調整されたアップグレードプロセスがない限り、統合に対する破壊的な変更を行うことはできません。
また、統合が壊れていないことを自動的に検証する方法についても検討する必要があります。機能テストは1つのアプローチですが、実装と保守のコストのために、書く機能テストの数を制限することを好みます。あるいは、コンシューマ駆動契約の一種を実装して、各マイクロフロントエンドが他のマイクロフロントエンドに何を要求するかを指定できるようにします。ブラウザで全てを統合して実行する必要はありません。
Backend communication
フロントエンドアプリケーションで別々のチームが独立して作業している場合、バックエンド開発はどうでしょうか?私たちは、ビジュアルコードからAPI開発、データベース、インフラストラクチャコードに至るまで、アプリケーションの開発を所有するフルスタックチームの価値を強く信じています。ここで役立つパターンは、BFFパターンです。各フロントエンドアプリケーションには、そのフロントエンドのニーズのみを満たすことを目的とした対応するバックエンドがあります。BFFパターンは元々、各フロントエンドチャネル(Web、モバイルなど)専用のバックエンドを意味していましたが、各マイクロフロントエンドのバックエンドを意味するように簡単に拡張できます。
ここで考慮すべき変数はたくさんあります。BFFは独自のビジネスロジックとデータベースを持つ独立したものであっても、下流サービスのアグリゲータであっても構いません。下流サービスがある場合、マイクロフロントエンドとそのBFFを所有するチームが、それらのサービスの一部も所有するかどうかは意味を持つ場合があります。マイクロフロントエンドが通信するAPIが1つだけで、そのAPIがかなり安定している場合、BFFを構築することの価値はそれほど高くないかもしれません。ここの指針は、特定のマイクロフロントエンドを構築しているチームが、他のチームが何かを構築するのを待つ必要がないことです。そのため、マイクロフロントエンドに追加された新しい機能ごとにバックエンドの変更が必要になる場合、それは同じチームが所有するBFFの強力な根拠となります。
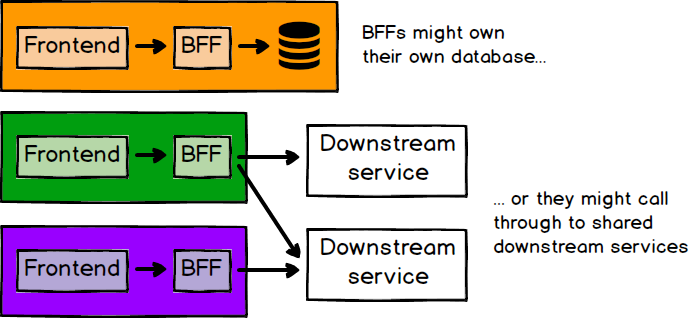
図7:フロントエンド/バックエンドの関係を構造化するには、多くの異なる方法があります。
もう1つのよくある質問は、マイクロフロントエンドアプリケーションのユーザーをどのようにサーバーで認証および承認するかです。明らかに、顧客は一度だけ認証する必要があるため、認証は通常、コンテナアプリケーションが所有するべきクロスカット懸念事項のカテゴリに分類されます。コンテナはおそらく何らかのログインフォームを持っており、そこから何らかのトークンを取得します。そのトークンはコンテナによって所有され、初期化時に各マイクロフロントエンドに注入できます。最後に、マイクロフロントエンドはサーバーにリクエストを行うたびにトークンを送信でき、サーバーは必要な検証を実行できます。
Testing
モノリシックフロントエンドとマイクロフロントエンドでは、テストに関して大きな違いは見られません。一般的に、モノリシックフロントエンドをテストするために使用している戦略は、個々のマイクロフロントエンド全体で再現できます。つまり、各マイクロフロントエンドには、コードの品質と正確性を確保する包括的な自動テストスイートが必要です。
明白なギャップは、コンテナアプリケーションとのさまざまなマイクロフロントエンドの統合テストになります。これは、お好みの機能/エンドツーエンドテストツール(SeleniumやCypressなど)を使用して実行できますが、やりすぎないようにしてください。機能テストは、より低いレベルのテストピラミッドでテストできない側面のみをカバーする必要があります。つまり、ユニットテストを使用して低レベルのビジネスロジックとレンダリングロジックをカバーし、機能テストを使用してページが正しくアセンブルされていることを検証します。たとえば、特定のURLで完全に統合されたアプリケーションをロードし、関連するマイクロフロントエンドのハードコードされたタイトルがページに存在することをアサートできます。
マイクロフロントエンドにまたがるユーザージャーニーがある場合、機能テストを使用してそれらをカバーできますが、機能テストはフロントエンドの統合を検証することに重点を置き、ユニットテストですでにカバーされている各マイクロフロントエンドの内部ビジネスロジックには重点を置かないようにしてください。上記のように、コンシューマ駆動契約は、統合環境と機能テストの不安定性なしに、マイクロフロントエンド間で発生するインタラクションを直接指定するのに役立ちます。
The example in detail
この記事の残りの大部分は、例示的なアプリケーションを実装できる方法の1つについての詳細な説明です。コンテナアプリケーションとマイクロフロントエンドがJavaScriptを使用してどのように統合されるかに重点を置きます。これはおそらく最も興味深く複雑な部分だからです。https://demo.microfrontends.comで展開された最終結果を確認でき、完全なソースコードはGithubで確認できます。
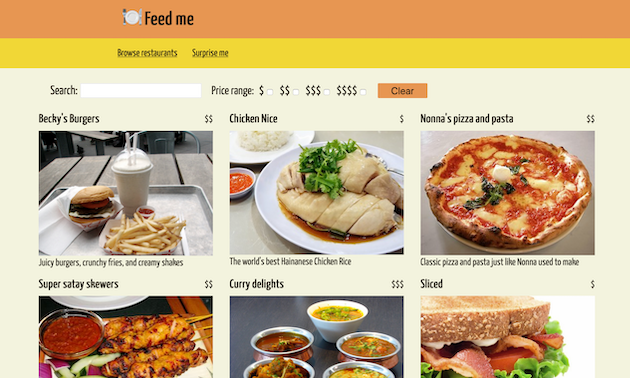
図8:完全なマイクロフロントエンドデモアプリケーションの「参照」ランディングページ
デモはすべてReact.jsを使用して構築されているため、Reactがこのアーキテクチャを独占しているわけではないことを指摘しておく価値があります。マイクロフロントエンドは、多くの異なるツールやフレームワークで実装できます。ここでは、その人気と私たち自身の馴染み深さからReactを選択しました。
The container
顧客のエントリポイントであるコンテナから始めましょう。その`package.json`から何が学べるか見てみましょう。
{
"name": "@micro-frontends-demo/container",
"description": "Entry point and container for a micro frontends demo",
"scripts": {
"start": "PORT=3000 react-app-rewired start",
"build": "react-app-rewired build",
"test": "react-app-rewired test"
},
"dependencies": {
"react": "^16.4.0",
"react-dom": "^16.4.0",
"react-router-dom": "^4.2.2",
"react-scripts": "^2.1.8"
},
"devDependencies": {
"enzyme": "^3.3.0",
"enzyme-adapter-react-16": "^1.1.1",
"jest-enzyme": "^6.0.2",
"react-app-rewire-micro-frontends": "^0.0.1",
"react-app-rewired": "^2.1.1"
},
"config-overrides-path": "node_modules/react-app-rewire-micro-frontends"
}
`react`と`react-scripts`の依存関係から、`create-react-app`を使用して作成されたReact.jsアプリケーションであると結論付けることができます。さらに興味深いのは、そこにないもの、つまり最終的なアプリケーションを形成するために合成するマイクロフロントエンドの言及がないことです。ここでそれらをライブラリ依存関係として指定すると、前に述べたように、リリースサイクルで問題のある結合につながるビルド時統合の道に進むことになります。
マイクロフロントエンドの選択と表示方法を確認するには、`App.js`を見てみましょう。React Routerを使用して現在のURLを事前に定義されたルートのリストと照合し、対応するコンポーネントをレンダリングします。
<Switch>
<Route exact path="/" component={Browse} />
<Route exact path="/restaurant/:id" component={Restaurant} />
<Route exact path="/random" render={Random} />
</Switch>
`Random`コンポーネントはそれほど興味深いものではありません。ランダムに選択されたレストランのURLにページをリダイレクトするだけです。`Browse`コンポーネントと`Restaurant`コンポーネントは次のようになります。
const Browse = ({ history }) => (
<MicroFrontend history={history} name="Browse" host={browseHost} />
);
const Restaurant = ({ history }) => (
<MicroFrontend history={history} name="Restaurant" host={restaurantHost} />
);
どちらの場合も、`MicroFrontend`コンポーネントをレンダリングします。historyオブジェクト(後で重要になります)とは別に、アプリケーションの一意の名前と、そのバンドルをダウンロードできるホストを指定します。この構成駆動型のURLは、ローカルで実行する場合は`https://:3001`のようになり、本番環境では`https://browse.demo.microfrontends.com`のようになります。
`App.js`でマイクロフロントエンドを選択したので、今度は`MicroFrontend.js`でレンダリングします。これは単なる別のReactコンポーネントです。
class MicroFrontend extends React.Component {
render() {
return <main id={`${this.props.name}-container`} />;
}
}
これはクラス全体ではありません。そのメソッドについては後で詳しく説明します。
レンダリングする際に、マイクロフロントエンドに固有のIDを持つコンテナ要素をページに配置するだけです。ここで、マイクロフロントエンドにそれ自体をレンダリングするように指示します。Reactの`componentDidMount`を、マイクロフロントエンドのダウンロードとマウントのトリガーとして使用します。
class MicroFrontend…
componentDidMount() {
const { name, host } = this.props;
const scriptId = `micro-frontend-script-${name}`;
if (document.getElementById(scriptId)) {
this.renderMicroFrontend();
return;
}
fetch(`${host}/asset-manifest.json`)
.then(res => res.json())
.then(manifest => {
const script = document.createElement('script');
script.id = scriptId;
script.src = `${host}${manifest['main.js']}`;
script.onload = this.renderMicroFrontend;
document.head.appendChild(script);
});
}
まず、関連するスクリプト(一意のIDを持つ)が既にダウンロードされているかどうかを確認します。その場合、すぐにレンダリングできます。そうでない場合は、適切なホストから`asset-manifest.json`ファイルをフェッチして、メインスクリプトアセットの完全なURLを調べます。スクリプトのURLを設定したら、残りはそれをドキュメントにアタッチし、マイクロフロントエンドをレンダリングする`onload`ハンドラをアタッチすることだけです。
class MicroFrontend…
renderMicroFrontend = () => {
const { name, history } = this.props;
window[`render${name}`](`${name}-container`, history);
// E.g.: window.renderBrowse('browse-container', history);
};
上記のコードでは、`window.renderBrowse`のようなグローバル関数を呼び出しています。これは、まさにダウンロードしたスクリプトによって配置されました。マイクロフロントエンドが自身をレンダリングするべき`
最後に残っているのはクリーンアップ処理です。MicroFrontendコンポーネントがアンマウント(DOMから削除)されるとき、関連するマイクロフロントエンドもアンマウントする必要があります。この目的のために、各マイクロフロントエンドによって対応するグローバル関数が定義されており、適切なReactライフサイクルメソッドから呼び出します。
class MicroFrontend…
componentWillUnmount() {
const { name } = this.props;
window[`unmount${name}`](`${name}-container`);
}
コンテナ自体が直接レンダリングするコンテンツは、サイトの上部ヘッダーとナビゲーションバーのみです。これらはすべてのページで共通だからです。これらの要素のCSSは、ヘッダー内の要素のみをスタイルするように注意深く記述されているため、マイクロフロントエンド内のスタイルコードと競合することはありません。
これでコンテナアプリケーションは終わりです!かなり基本的なものですが、これにより、実行時にマイクロフロントエンドを動的にダウンロードし、それらを単一ページで統合されたものにするシェルが得られます。これらのマイクロフロントエンドは、他のマイクロフロントエンドやコンテナ自体に変更を加えることなく、本番環境まで独立してデプロイできます。
The micro frontends
この話の続きとして論理的なのは、繰り返し参照しているグローバルレンダリング関数です。アプリケーションのホームページは、レストランのフィルタリング可能なリストであり、そのエントリポイントは次のようになります。
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import registerServiceWorker from './registerServiceWorker';
window.renderBrowse = (containerId, history) => {
ReactDOM.render(<App history={history} />, document.getElementById(containerId));
registerServiceWorker();
};
window.unmountBrowse = containerId => {
ReactDOM.unmountComponentAtNode(document.getElementById(containerId));
};
通常、React.jsアプリケーションでは、ReactDOM.renderの呼び出しはトップレベルスコープで行われます。つまり、このスクリプトファイルがロードされるとすぐに、ハードコードされたDOM要素へのレンダリングが開始されます。このアプリケーションでは、レンダリングのタイミングと場所の両方を制御する必要があるため、DOM要素のIDをパラメーターとして受け取る関数でラップし、その関数をグローバルwindowオブジェクトにアタッチします。クリーンアップに使用される対応するアンマウント関数も確認できます。
マイクロフロントエンドがコンテナアプリケーション全体に統合される際のこの関数の呼び出し方法については既に説明しましたが、ここで成功するための最大の基準の1つは、マイクロフロントエンドを独立して開発および実行できることです。そのため、各マイクロフロントエンドには、コンテナの外側、「スタンドアロン」モードでアプリケーションをレンダリングするためのインラインスクリプトを含む独自のindex.htmlもあります。
<html lang="en">
<head>
<title>Restaurant order</title>
</head>
<body>
<main id="container"></main>
<script type="text/javascript">
window.onload = () => {
window.renderRestaurant('container');
};
</script>
</body>
</html>
図9:各マイクロフロントエンドは、コンテナの外側でスタンドアロンアプリケーションとして実行できます。
この時点以降、マイクロフロントエンドはほとんど通常のReactアプリです。'browse'アプリケーションはバックエンドからレストランのリストを取得し、レストランの検索とフィルタリングのための<input>要素を提供し、特定のレストランに移動するReact Router <Link>要素をレンダリングします。その時点で、メニュー付きのレストランを1つレンダリングする2番目の'order'マイクロフロントエンドに切り替えます。
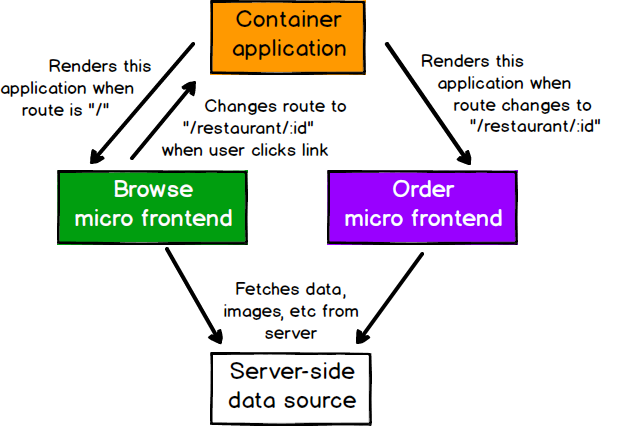
図10:これらのマイクロフロントエンドは、直接ではなく、ルートの変更を介してのみ相互作用します。
マイクロフロントエンドについて最後に言及する価値のあることは、両方がスタイリングにstyled-componentsを使用していることです。このCSS-in-JSライブラリを使用すると、スタイルを特定のコンポーネントに簡単に関連付けることができるため、マイクロフロントエンドのスタイルが外部に漏れ出て、コンテナまたは別のマイクロフロントエンドに影響を与えることがなくなります。
Cross-application communication via routing
アプリケーション間の通信は最小限に抑える必要があることを前述しました。この例では、ブラウジングページがレストランページにどのレストランを読み込むかを伝える必要があるという要件しかありません。ここでは、クライアントサイドルーティングを使用してこの問題を解決する方法を示します。
ここで使用されている3つのReactアプリケーションはすべて、宣言型ルーティングにReact Routerを使用していますが、初期化方法はわずかに異なります。コンテナアプリケーションでは、内部的にhistoryオブジェクトをインスタンス化する<BrowserRouter>を作成します。これは、これまで説明してきたhistoryオブジェクトと同じです。このオブジェクトを使用してクライアント側の履歴を操作し、複数のReact Routerをリンクさせることもできます。マイクロフロントエンド内では、Routerを次のように初期化します。
<Router history={this.props.history}>
この場合、React Routerが別のhistoryオブジェクトをインスタンス化させるのではなく、コンテナアプリケーションによって渡されたインスタンスを提供します。すべての<Router>インスタンスが接続されるため、いずれかでトリガーされたルートの変更はすべてに反映されます。これにより、URLを介して、あるマイクロフロントエンドから別のマイクロフロントエンドに「パラメーター」を渡す簡単な方法が得られます。たとえば、browseマイクロフロントエンドには次のようなリンクがあります。
<Link to={`/restaurant/${restaurant.id}`}>
このリンクをクリックすると、ルートがコンテナで更新され、新しいURLが表示され、レストランマイクロフロントエンドをマウントしてレンダリングする必要があることがわかります。その後、マイクロフロントエンド自身のルーティングロジックがURLからレストランIDを抽出し、正しい情報をレンダリングします。
この例の流れが、単純なURLの柔軟性と能力を示していることを願っています。共有とブックマークに役立つことに加えて、この特定のアーキテクチャでは、マイクロフロントエンド間で意図を伝えるための便利な方法となります。この目的でページURLを使用することは、多くの利点があります。
- その構造は明確に定義されたオープンスタンダードです。
- ページ上の任意のコードからグローバルにアクセスできます。
- サイズが小さいため、少量のデータのみを送信できます。
- ユーザー向けであるため、ドメインを忠実にモデル化する構造が促進されます。
- 命令型ではなく、宣言型です。つまり、「これが私たちの場所です」ではなく、「このことをしてください」です。
- マイクロフロントエンドが間接的に通信し、互いに直接知り合ったり依存したりしないように強制します。
ルーティングをマイクロフロントエンド間の通信モードとして使用する場合、選択するルートは契約を構成します。この場合、レストランは/restaurant/:restaurantIdで表示できると確立されており、参照するすべてのアプリケーションを更新せずにそのルートを変更することはできません。この契約の重要性を考慮して、契約が遵守されていることを確認する自動テストが必要です。
Common content
チームとマイクロフロントエンドをできるだけ独立させたい一方で、共通にする必要があるものもあります。共有コンポーネントライブラリがマイクロフロントエンド全体の一貫性にどのように役立つかについて前述しましたが、この小さなデモでは、コンポーネントライブラリは過剰です。そのため、代わりに、画像、JSONデータ、CSSなど、すべてのマイクロフロントエンドにネットワーク経由で提供される共通コンテンツの小さなリポジトリを用意しています。
マイクロフロントエンド間で共有することを選択できるもう1つのものがあります。ライブラリ依存関係です。すぐに説明するように、依存関係の重複はマイクロフロントエンドの一般的な欠点です。それらの依存関係をアプリケーション間で共有することには独自の困難が伴いますが、このデモアプリケーションでは、その方法について説明する価値があります。
最初のステップは、共有する依存関係を選択することです。コンパイル済みコードの簡単な分析により、バンドルの約50%がreactとreact-domによって提供されていることがわかりました。サイズに加えて、これらの2つのライブラリは最も「コア」な依存関係であるため、すべてのマイクロフロントエンドがそれらを抽出してメリットを得られることがわかっています。最後に、これらは安定した成熟したライブラリであり、通常は2つのメジャーバージョンで破壊的な変更が導入されるため、アプリケーション間のアップグレードの努力はそれほど困難ではありません。
実際の抽出に関しては、externalsとしてライブラリをwebpack構成でマークするだけで済みます。前述したものと同様の再配線を使用して行うことができます。
module.exports = (config, env) => {
config.externals = {
react: 'React',
'react-dom': 'ReactDOM'
}
return config;
};
次に、共有コンテンツサーバーから2つのライブラリを取得するために、各index.htmlファイルにいくつかのscriptタグを追加します。
<body>
<noscript>
You need to enable JavaScript to run this app.
</noscript>
<div id="root"></div>
<script src="%REACT_APP_CONTENT_HOST%/react.prod-16.8.6.min.js"></script>
<script src="%REACT_APP_CONTENT_HOST%/react-dom.prod-16.8.6.min.js"></script>
</body>
チーム間でコードを共有することは、常にうまく行うのが難しいことです。本当に共通させたいもの、複数の場所で一度に変更したいものだけを共有するようにする必要があります。ただし、共有するものとしないものを注意深く選択すれば、真のメリットを得ることができます。
Infrastructure
アプリケーションはAWSでホストされており、コアインフラストラクチャ(S3バケット、CloudFrontディストリビューション、ドメイン、証明書など)は、Terraformコードの中央集約型リポジトリを使用して一度にすべてプロビジョニングされます。その後、各マイクロフロントエンドには独自のソースリポジトリがあり、Travis CIで独自の継続的デプロイメントパイプラインがあり、静的アセットをそれらのS3バケットにビルド、テスト、デプロイします。これにより、中央集約型インフラストラクチャ管理の利便性と、独立したデプロイの柔軟性がバランスよく実現されます。
各マイクロフロントエンド(とコンテナ)には独自のバケットが割り当てられることに注意してください。つまり、そこに何が含まれるかについて自由に制御でき、別のチームやアプリケーションからのオブジェクト名の競合や、アクセス管理ルールの競合を心配する必要はありません。
Downsides
この記事の冒頭で、マイクロフロントエンドには、他のアーキテクチャと同様に、トレードオフがあると述べました。言及したメリットにはコストが伴い、ここで説明します。
Payload size
独立して構築されたJavaScriptバンドルは、共通の依存関係の重複を引き起こし、エンドユーザーにネットワーク経由で送信するバイト数を増やす可能性があります。たとえば、すべてのマイクロフロントエンドに独自のReactのコピーが含まれている場合、顧客にReactをn回ダウンロードさせることになります。ページのパフォーマンスとユーザーエンゲージメント/コンバージョンには直接的な関係があり、世界の大部分は先進国の都市の人々が慣れているよりもはるかに遅いインターネットインフラストラクチャで動作しているため、ダウンロードサイズを気にする多くの理由があります。
この問題は簡単に解決できません。チームがアプリケーションを独立してコンパイルして自律的に作業できるようにしたいという願望と、共通の依存関係を共有できるようにアプリケーションを構築したいという願望の間には、本質的な緊張があります。1つのアプローチは、コンパイル済みバンドルから共通の依存関係を外部化することです。デモアプリケーションについて説明したように。ただし、この方法を使用するとすぐに、マイクロフロントエンドにビルド時の結合が再導入されます。これで、それらの間には、「これらの依存関係のこれらの正確なバージョンをすべて使用する必要があります」という暗黙の契約があります。依存関係に破壊的な変更がある場合、大規模な調整されたアップグレード作業と、一括リリースイベントが必要になる可能性があります。これは、マイクロフロントエンドで最初に回避しようとしていたものです!
この本質的な緊張は難しいものですが、すべて悪いニュースではありません。まず、重複する依存関係について何も行わなくても、単一のモノリシックフロントエンドを構築した場合よりも、各ページの読み込み速度が速くなる可能性があります。その理由は、各ページを個別にコンパイルすることで、独自のコード分割形式を実装したためです。従来のモノリスでは、アプリケーション内の任意のページが読み込まれると、多くの場合、すべてのページのソースコードと依存関係が一度にダウンロードされます。独立して構築することで、単一のページの読み込みでは、そのページのソースと依存関係のみがダウンロードされます。これにより、最初のページの読み込み速度が速くなる可能性がありますが、ユーザーは各ページで同じ依存関係を再ダウンロードするため、その後のナビゲーション速度が遅くなる可能性があります。マイクロフロントエンドに不必要な依存関係を含ませないようにするか、ユーザーがアプリケーション内の1つか2つのページに固執していることがわかっている場合は、重複する依存関係があっても、パフォーマンスの面で正味の向上を達成できる可能性があります。
前の段落には「〜かもしれない」「おそらく〜」といった表現が多く含まれていますが、これはあらゆるアプリケーションが固有のパフォーマンス特性を持つことを強調しています。特定の変更がパフォーマンスにどのような影響を与えるかを確実に知りたい場合は、現実世界の測定、理想的には本番環境での測定に代わるものはありません。いくつかのキロバイトのJavaScriptを巡ってチームが苦悩しているにもかかわらず、多くのメガバイトの高解像度画像をダウンロードしたり、非常に遅いデータベースに対して高コストのクエリを実行したりする事例を見てきました。したがって、あらゆるアーキテクチャ上の決定のパフォーマンスへの影響を考慮することは重要ですが、真のボトルネックがどこにあるのかを確実に把握することが重要です。
Environment differences
他のチームが開発する他のマイクロフロントエンドを考慮することなく、単一のマイクロフロントエンドを開発できるはずです。本番環境で配置されるコンテナアプリケーション内ではなく、「スタンドアロン」モードで、空白ページ上でマイクロフロントエンドを実行できる場合もあります。これは、特に実際のコンテナが複雑なレガシーコードベースである場合(マイクロフロントエンドを使用して旧システムから新システムへの段階的な移行を行う場合によくあることです)、開発を大幅に簡素化できます。ただし、本番環境とはかなり異なる環境で開発することにはリスクが伴います。開発時のコンテナと本番環境のコンテナの挙動が異なる場合、マイクロフロントエンドが壊れたり、本番環境にデプロイしたときに挙動が異なったりすることがあります。特に懸念されるのは、コンテナまたは他のマイクロフロントエンドによって持ち込まれる可能性のあるグローバルスタイルです。
この解決策は、環境の違いを懸念する必要がある他の状況とは大きく変わりません。本番環境と類似していない環境でローカルに開発している場合は、定期的にマイクロフロントエンドを本番環境と類似した環境に統合およびデプロイし、これらの環境で(手動および自動)テストを実行して、統合の問題をできるだけ早く検出する必要があります。これにより問題は完全に解決するわけではありませんが、最終的には、検討しなければならないトレードオフのもう一つです。簡素化された開発環境による生産性向上は、統合問題のリスクに見合う価値があるでしょうか?答えはプロジェクトによって異なります!
Operational and governance complexity
最後の欠点は、マイクロサービスと直接的な類似点があります。より分散されたアーキテクチャとして、マイクロフロントエンドは必然的に管理するものが増加します—リポジトリ、ツール、ビルド/デプロイパイプライン、サーバー、ドメインなどが多くなります。そのため、このようなアーキテクチャを採用する前に、考慮すべき点がいくつかあります。
- 追加で必要なインフラストラクチャを現実的にプロビジョニングおよび管理するための十分な自動化が整っていますか?
- フロントエンドの開発、テスト、およびリリースプロセスは、多くのアプリケーションにスケールしますか?
- ツールの選定と開発プラクティスに関する意思決定が、より分散化され、制御性が低下することに抵抗がありませんか?
- 多くの独立したフロントエンドコードベース全体で、最低限の品質、一貫性、またはガバナンスをどのように確保しますか?
これらのトピックについて議論するのに、もう1つの記事全体を費やすことができるでしょう。私たちが伝えたい主な点は、マイクロフロントエンドを選択すると、定義上、1つの大きなものよりも多くの小さなものを作成することを選択することです。カオスを生み出さずにこのようなアプローチを採用するために必要な技術的および組織的な成熟度があるかどうかを検討する必要があります。
Conclusion
長年にわたってフロントエンドコードベースがますます複雑になるにつれて、よりスケーラブルなアーキテクチャの必要性が高まっていると考えています。技術エンティティとドメインエンティティ間の適切なカップリングと凝集性のレベルを確立する明確な境界線を引くことができる必要があります。独立した自律的なチーム全体でソフトウェアデリバリーをスケールアップできる必要があります。
唯一のアプローチとは程遠いですが、マイクロフロントエンドがこれらのメリットをもたらす多くの現実世界の事例を見てきました。また、この手法をレガシーコードベースと新しいコードベースの両方に時間をかけて段階的に適用することができました。マイクロフロントエンドがあなたとあなたの組織にとって適切なアプローチであるかどうかにかかわらず、これはフロントエンドエンジニアリングとアーキテクチャが当然持つべき重要性で扱われる継続的なトレンドの一部になることを願っています。
謝辞
綿密なレビューと詳細なフィードバックをいただいたCharles Korn、Andy Marks、Willem Van Ketwichに多大な感謝を申し上げます。
Thoughtworks社内メーリングリストで意見をいただいたBill Codding、Michael Strasser、Shirish Padalkarにも感謝いたします。
Martin Fowlerにもフィードバックをいただき、この記事を彼のウェブサイトに掲載していただいたことに感謝します。
そして最後に、励ましとサポートをいただいたEvan BottcherとLiauw Fendyに感謝します。
大幅な改訂
2019年6月19日: 欠点に関する最終回を公開
2019年6月17日: 例を含む回を公開
2019年6月13日: スタイルからテストまでのセクションを含む回を公開
2019年6月11日: 統合アプローチに関する回を公開
2019年6月10日: 最初の回を公開:メリットを網羅