
実践的なテストピラミッド
「テストピラミッド」とは、ソフトウェアテストを異なる粒度のバケットにグループ化することを示すメタファーです。また、各グループにいくつのテストを行うべきかを示す指針でもあります。テストピラミッドの概念は以前から存在していますが、チームは依然として適切に実践するのに苦労しています。この記事では、テストピラミッドの本来の概念を再検討し、実践する方法を説明します。ピラミッドの各レベルでどのような種類のテストを探す必要があるかを示し、実装方法の実例を示します。
2018年2月26日

ハムは、ドイツのThoughtworksのソフトウェア開発者兼コンサルタントです。午前3時にソフトウェアを手動でデプロイすることにうんざりし、継続的デリバリーと入念な自動化をツールボックスに追加し、チームが高品質のソフトウェアを確実かつ効率的に提供できるように支援することに着手しました。彼は、そのおかげで生まれた時間を、人々をふざけた行動で悩ませることで埋め合わせています。

本番環境に対応したソフトウェアは、本番環境に投入する前にテストが必要です。ソフトウェア開発の分野が成熟するにつれて、ソフトウェアテストのアプローチも成熟してきました。無数の手動ソフトウェアテスターを抱える代わりに、開発チームはテスト作業の大部分を自動化することに移行しました。テストを自動化することで、チームはソフトウェアに問題があるかどうかを数日または数週間ではなく、数秒または数分で知ることができます。
自動テストによって劇的に短縮されたフィードバックループは、アジャイル開発プラクティス、継続的デリバリー、DevOps文化と密接に関連しています。効果的なソフトウェアテストアプローチを採用することで、チームは迅速かつ自信を持って行動できます。
この記事では、マイクロサービスアーキテクチャ、モバイルアプリ、IoTエコシステムのいずれを構築しているかに関係なく、応答性、信頼性、保守性に優れたテストポートフォリオがどのようなものであるべきかを検討します。また、効果的で読みやすい自動テストを構築する方法についても詳しく説明します。
(テスト)自動化の重要性
ソフトウェアは、私たちが住む世界の不可欠な一部となりました。ビジネスの効率化を図るという初期の唯一の目的を超えて成長しました。今日、企業は一流のデジタル企業になる方法を見つけようとしています。ユーザーとして、私たちは皆、毎日増加する量のソフトウェアと対話しています。イノベーションの輪はますます速く回転しています。
ペースを維持したい場合は、品質を犠牲にすることなくソフトウェアをより迅速に提供する方法を検討する必要があります。ソフトウェアをいつでも本番環境にリリースできるように自動的にするプラクティスである**継続的デリバリー**は、そのために役立ちます。継続的デリバリーでは、**ビルドパイプライン**を使用してソフトウェアを自動的にテストし、テスト環境と本番環境にデプロイします。
増加し続ける量のソフトウェアを手動でビルド、テスト、デプロイすることは、すぐに不可能になります。作業中のソフトウェアを提供する代わりに、手動の反復作業にすべての時間を費やしたい場合を除きます。ビルドからテスト、デプロイ、インフラストラクチャまですべてを自動化することが、唯一の前進の道です。

図1:ビルドパイプラインを使用して、ソフトウェアを自動的かつ確実に本番環境に導入する
従来のソフトウェアテストは、アプリケーションをテスト環境にデプロイし、ブラックボックステストを実行することによって行われる、過度に手動の作業でした。たとえば、ユーザーインターフェースをクリックして、何かが壊れていないかを確認します。多くの場合、これらのテストは、テスターが一貫したチェックを行うことを保証するために、テストスクリプトによって指定されます。
すべての変更を手動でテストすることは、時間と労力がかかり、反復的で退屈であることは明らかです。反復的な作業は退屈であり、退屈はミスにつながり、週末までに別の仕事を探させることになります。
幸いなことに、反復的なタスクには解決策があります。それは*自動化*です。
反復的なテストを自動化することは、ソフトウェア開発者としての生活に大きな変化をもたらす可能性があります。これらのテストを自動化すれば、ソフトウェアがまだ正しく機能するかどうかを確認するために、クリックプロトコルに盲目的に従う必要はもうありません。テストを自動化すれば、ためらうことなくコードベースを変更できます。適切なテストスイートなしで大規模なリファクタリングを試みたことがあるなら、それがどれほど恐ろしい経験になるかご存知でしょう。途中で誤って何かを壊してしまった場合、どうすればわかるでしょうか?そうですね、すべての手動テストケースをクリックするのです。しかし、正直に言って、本当にそれを楽しんでいますか?大規模な変更を行っても、コーヒーを飲みながら数秒以内に何かが壊れたかどうかを知ることができるというのはどうでしょうか?私にとっては、こちらの方が楽しいように聞こえます。
テストピラミッド
ソフトウェアの自動テストを真剣に検討したい場合は、知っておくべき重要な概念が1つあります。それは**テストピラミッド**です。Mike Cohn(マイク・コーン)は、彼の著書*Succeeding with Agile(アジャイルで成功する)*でこの概念を提唱しました。これは、テストのさまざまなレイヤーについて考えるように指示する優れた視覚的メタファーです。また、各レイヤーでどの程度のテストを行うべきかを示しています。
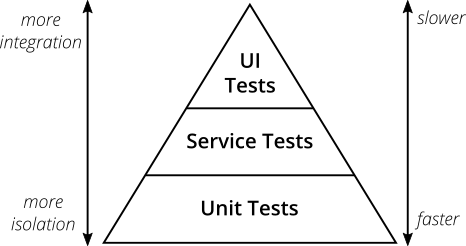
図2:テストピラミッド
マイク・コーンの元のテストピラミッドは、テストスイートを構成する3つのレイヤー(下から上)で構成されています。
- ユニットテスト
- サービステスト
- ユーザーインターフェイステスト
残念ながら、よく見ると、テストピラミッドの概念はやや不足しています。マイク・コーンのテストピラミッドの命名または概念的な側面のいくつかは理想的ではないと主張する人もおり、私はそれに同意せざるを得ません。現代の観点から見ると、テストピラミッドは過度に単純化されているため、誤解を招く可能性があります。
それでも、そのシンプルさのために、テストピラミッドの本質は、独自のテストスイートを確立する際の優れた経験則として役立ちます。コーンの元のテストピラミッドから覚えておくべきことは2つあります。
- 異なる粒度のテストを書く
- レベルが高くなるほど、テストの数は少なくなる
健全で高速、かつ保守しやすいテストスイートを作成するには、ピラミッドの形状を維持してください。*多数*の小さく高速な*ユニットテスト*を作成します。もう少し粗い粒度のテストを*いくつか*書き、アプリケーションをエンドツーエンドでテストする高レベルのテストは*ごくわずか*にします。保守が非常に困難で、実行に時間がかかりすぎる テストアイスクリームコーンにならないように注意してください。
コーンのテストピラミッドの個々のレイヤーの名前にこだわりすぎないでください。実際、それらは非常に誤解を招く可能性があります。*サービステスト*は理解しにくい用語です(コーン自身は、 多くの開発者がこのレイヤーを完全に無視しているという観察について語っています)。react、angular、ember.jsなどのシングルページアプリケーションフレームワークの時代では、*UIテスト*がピラミッドの最上位レベルにある必要はないことが明らかになります。これらのフレームワークのすべてでUIのユニットテストを完全に実行できます。
元の名前には欠点があるため、コードベースとチームの議論内で一貫性を保っている限り、テストレイヤーに他の名前を付けるのはまったく問題ありません。
使用するツールとライブラリ
サンプルアプリケーション
テストピラミッドのさまざまなレイヤーのテストを含むテストスイートを含むシンプルなマイクロサービスを作成しました。
サンプルアプリケーションは、典型的なマイクロサービスの特徴を示しています。RESTインターフェースを提供し、データベースと通信し、サードパーティのRESTサービスから情報を取得します。Spring Boot で実装されており、Spring Bootを使用したことがなくても理解できるはずです。
Githubのコードを確認してください。readmeには、アプリケーションとその自動テストをマシンで実行するために必要な手順が記載されています。
機能
アプリケーションの機能はシンプルです。3つのエンドポイントを持つRESTインターフェースを提供します。
| GET /hello | *"Hello World"*を返します。常に。 |
| GET /hello/{lastname} | 指定された姓を持つ人物を検索します。人物が既知の場合は、*"Hello {Firstname} {Lastname}"*を返します。 |
| GET /weather | *ドイツ、ハンブルク*の現在の気象条件を返します。 |
高レベル構造
高レベルでは、システムは次の構造になっています。
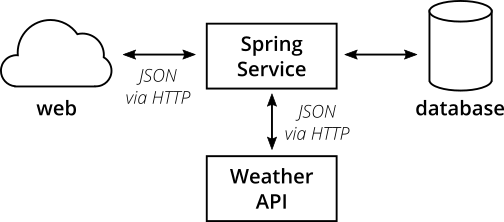
図3:マイクロサービスシステムの高レベル構造
マイクロサービスは、HTTP経由で呼び出すことができるRESTインターフェースを提供します。一部のエンドポイントでは、サービスはデータベースから情報を取得します。他の場合、サービスはHTTP経由で外部の気象APIを呼び出して、現在の気象条件を取得して表示します。
内部アーキテクチャ
内部的には、SpringサービスはSpringに典型的なアーキテクチャを備えています。
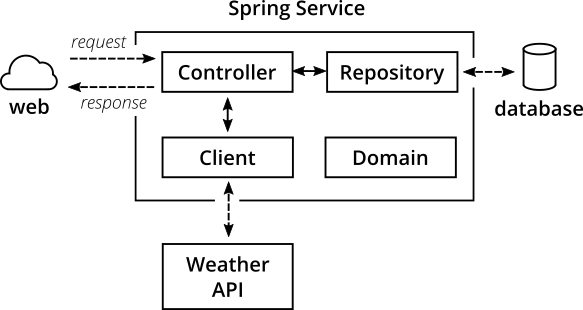
図4:マイクロサービスの内部構造
- `Controller` クラスは*REST*エンドポイントを提供し、*HTTP*リクエストとレスポンスを処理します
- `Repository` クラスは*データベース*とインターフェースし、永続ストレージへのデータの書き込みと読み取りを処理します
- `Client` クラスは他のAPIと通信します。この場合は、darksky.net気象APIから*HTTPS*経由で*JSON*を取得します
ドメインクラスは、ドメインロジック(公平を期すために言えば、この場合は非常に些細なものですが)を含む、ドメインモデルを捉えます。
経験豊富なSpring開発者は、ここで頻繁に使用される層が欠落していることに気付くかもしれません。ドメイン駆動設計に影響を受けて、多くの開発者は`サービス`クラスで構成される*サービス層*を構築します。このアプリケーションにはサービス層を含めないことにしました。1つの理由は、アプリケーションが単純であるため、サービス層は不要な間接レベルになるからです。もう1つの理由は、サービス層を使いすぎている人が多いと思うからです。ビジネスロジック全体がサービス クラス内にカプセル化されているコードベースによく遭遇します。ドメインモデルは、振る舞いではなく、データの層にすぎなくなります(貧血ドメインモデル)。重要でないアプリケーションの場合、これはコードを適切に構造化してテスト可能にするための多くの可能性を無駄にし、オブジェクト指向の力を最大限に活用していません。
私たちのリポジトリは単純明快で、シンプルなCRUD機能を提供します。コードをシンプルにするために、Spring Dataを使用しました。Spring Dataは、独自に実装する代わりに使用できる、シンプルで汎用的なCRUDリポジトリ実装を提供します。また、本番環境のように実際のPostgreSQLデータベースを使用する代わりに、テスト用にインメモリデータベースを起動します。
コードベースを見て、内部構造に慣れてください。次のステップであるアプリケーションのテストに役立ちます。
ユニットテスト
テストスイートの基盤は、単体テストで構成されます。単体テストは、コードベースの特定のユニット(*テスト対象*)が意図したとおりに機能することを確認します。単体テストは、テストスイート内の他のすべてのタイプのテストよりも範囲が狭いです。テストスイート内の単体テストの数は、他のどのタイプのテストよりもはるかに多くなります。

図5:単体テストでは通常、外部のコラボレーターをテストダブルに置き換えます
ユニットとは何か?
単体テストのコンテキストで*「ユニット」*が何を意味するのかを3人の異なる人に尋ねると、おそらく4つの異なる、わずかにニュアンスのある回答が得られるでしょう。ある程度は、それはあなた自身の定義の問題であり、標準的な答えがないことは問題ありません。
関数型言語で作業している場合、*ユニット*は単一の関数になる可能性が高くなります。単体テストは、さまざまなパラメーターを使用して関数を呼び出し、期待値が返されることを確認します。オブジェクト指向言語では、ユニットは単一のメソッドからクラス全体まで及ぶ可能性があります。
社交的と孤独
テスト対象のコラボレーター(たとえば、テスト対象のクラスによって呼び出される他のクラス)はすべて、*モック*または*スタブ*に置き換えて、完全な分離を実現し、副作用や複雑なテスト設定を回避する必要があると主張する人もいます。低速であるか、大きな副作用があるコラボレーター(たとえば、データベースにアクセスしたり、ネットワーク呼び出しを行うクラス)のみをスタブまたはモックする必要があると主張する人もいます。
場合によっては、これら2種類のテストは、すべてのコラボレーターをスタブするテストの**孤独な単体テスト**と、実際のコラボレーターとの通信を許可するテストの**社交的な単体テスト**としてラベル付けされます(Jay Fieldsの単体テストを効果的に使用するはこれらの用語を作り出しました)。時間があれば、さまざまな考え方の長所と短所について詳しく読むことができます。
結局のところ、孤独な単体テストと社交的な単体テストのどちらを選択するかは重要ではありません。重要なのは、自動テストを書くことです。個人的には、常に両方のアプローチを使用しています。実際のコラボレーターを使用するのが難しい場合は、モックとスタブを惜しみなく使用します。実際のコラボレーターを巻き込むことでテストへの自信が高まると感じる場合は、サービスの最も外側の部分のみをスタブします。
モッキングとスタビング
モックとスタブは、2種類のテストダブルです(これら2つ以外にもあります)。多くの人がモックとスタブという用語を同じ意味で使用しています。正確さを期し、それぞれの具体的な特性を念頭に置いておくことが良いと思います。テストダブルを使用して、本番環境で使用するオブジェクトを、テストに役立つ実装に置き換えることができます。簡単に言えば、それは、実際の物(たとえば、クラス、モジュール、または関数)をその物の偽のバージョンに置き換えることを意味します。偽のバージョンは本物のように見え、動作しますが(同じメソッド呼び出しに応答します)、単体テストの開始時に自分で定義した既製の応答で応答します。
テストダブルの使用は、単体テストに限定されません。より精巧なテストダブルを使用して、システム全体の一部を制御された方法でシミュレートできます。ただし、単体テストでは、多くの最新の言語とライブラリでモックとスタブを簡単に設定できるため、多くのモックとスタブに遭遇する可能性が高くなります(社交的な開発者か孤独な開発者かによって異なります)。
テクノロジーの選択に関係なく、言語の標準ライブラリまたは一般的なサードパーティライブラリが、モックを設定するための洗練された方法を提供する可能性が高くなります。また、独自のモックを最初から作成する場合でも、実際のものと同じシグネチャを持つ偽のクラス/モジュール/関数を作成し、テストで偽を設定するだけです。
単体テストは非常に高速に実行されます。まともなマシンでは、数分以内に数千の単体テストを実行できます。コードベースの小さな部分を個別にテストし、データベース、ファイルシステムへのアクセス、またはHTTPクエリの発行を回避して(これらの部分にモックとスタブを使用することにより)、テストを高速に保ちます。
単体テストの作成に慣れると、作成がますます流暢になります。外部のコラボレーターをスタブアウトし、入力データを設定し、テスト対象を呼び出し、返された値が期待どおりであることを確認します。テスト駆動開発を調べて、単体テストで開発をガイドします。正しく適用すれば、優れた流れに入り、優れた保守性の高い設計を考案しながら、包括的で完全に自動化されたテストスイートを自動的に生成するのに役立ちます。それでも、万能薬ではありません。さあ、本当のチャンスを与えて、それがあなたに適しているかどうかを確認してください。
何をテストすべきか?
単体テストの良い点は、機能や内部構造のどのレイヤーに属しているかに関係なく、すべての本番コードクラスに対して作成できることです。リポジトリ、ドメインクラス、またはファイルリーダーを単体テストできるのと同じように、コントローラーを単体テストできます。**本番クラスごとに1つのテストクラス**の経験則に従うだけで、順調に開始できます。
単体テストクラスは、少なくとも**クラスの*パブリック*インターフェイスをテストする**必要があります。プライベートメソッドは、別のテストクラスから呼び出すことができないため、とにかくテストできません。*保護*または*パッケージプライベート*はテストクラスからアクセスできます(テストクラスのパッケージ構造が本番クラスと同じである場合)が、これらのメソッドをテストすると行き過ぎになる可能性があります。
単体テストの作成には微妙な境界線があります。重要なコードパスがすべてテストされていること(ハッピーパスとエッジケースを含む)を確認する必要があります。同時に、実装に密接に結びついていてはなりません。
それはなぜですか?
本番コードに近すぎるテストはすぐに面倒になります。本番コードをリファクタリングするとすぐに(簡単な要約:リファクタリングとは、外部から見える動作を変更せずにコードの内部構造を変更することを意味します)、単体テストは失敗します。
このようにして、単体テストの大きな利点の1つである、コード変更のセーフティネットとしての役割を失います。あなたはむしろ、リファクタリングするたびにこれらの愚かなテストが失敗することにうんざりし、役に立つよりも多くの作業を引き起こします。そして、この愚かなテストのアイデアは誰のものだったのでしょうか?
代わりに何をしますか?単体テスト内で内部コード構造を反映しないでください。代わりに、観察可能な動作をテストします。次のように考えてください
値`x`と`y`を入力すると、結果は`z`になりますか?
の代わりに
`x`と`y`を入力すると、メソッドは最初にクラスAを呼び出し、次にクラスBを呼び出し、次にクラスAの結果とクラスBの結果を返しますか?
プライベートメソッドは、一般的に実装の詳細と見なされる必要があります。そのため、テストする必要すらありません。
単体テスト(またはTDD)の反対者が、高いテストカバレッジを実現するためにすべてのメソッドをテストする必要があるため、単体テストの作成が無意味な作業になると主張しているのをよく耳にします。彼らはしばしば、熱心すぎるチームリーダーが、100%のテストカバレッジを実現するために、ゲッターとセッター、およびその他すべての種類の些細なコードの単体テストを作成することを強制したシナリオを引用します。
それは間違っています。
はい、*パブリックインターフェイスをテストする*必要があります。しかし、さらに重要なのは、**些細なコードをテストしない**ことです。心配しないで、ケントベックは大丈夫だと言いました。単純な*ゲッター*または*セッター*、またはその他の些細な実装(たとえば、条件付きロジックがない)をテストしても何も得られません。時間を節約してください。それはあなたが参加できるもう1つの会議です。万歳!
テスト構造
すべてのテストに適した構造(これは単体テストに限定されません)は次のとおりです。
- テストデータを設定する
- テスト対象のメソッドを呼び出す
- 期待される結果が返されることをアサートする
この構造を覚えるための素晴らしいニーモニックがあります: *「準備、実行、アサート」*。使用できるもう1つは、BDDからヒントを得ています。それは*「given」*、*「when」*、*「then」*のトライアドであり、*given*はセットアップ、*when*はメソッド呼び出し、*then*はアサーション部分を反映しています。
このパターンは、他のより高レベルのテストにも適用できます。いずれの場合も、テストが読みやすく、一貫性を保つことができます。その上、この構造を念頭に置いて作成されたテストは、より短く、より表現力豊かになる傾向があります。
ユニットテストの実装
何をテストし、ユニットテストをどのように構成するかを理解したので、実際の例を確認できます。
ExampleControllerクラスの簡略版を見てみましょう
@RestController
public class ExampleController {
private final PersonRepository personRepo;
@Autowired
public ExampleController(final PersonRepository personRepo) {
this.personRepo = personRepo;
}
@GetMapping("/hello/{lastName}")
public String hello(@PathVariable final String lastName) {
Optional<Person> foundPerson = personRepo.findByLastName(lastName);
return foundPerson
.map(person -> String.format("Hello %s %s!",
person.getFirstName(),
person.getLastName()))
.orElse(String.format("Who is this '%s' you're talking about?",
lastName));
}
}
hello(lastname)メソッドのユニットテストは次のようになります
public class ExampleControllerTest {
private ExampleController subject;
@Mock
private PersonRepository personRepo;
@Before
public void setUp() throws Exception {
initMocks(this);
subject = new ExampleController(personRepo);
}
@Test
public void shouldReturnFullNameOfAPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
given(personRepo.findByLastName("Pan"))
.willReturn(Optional.of(peter));
String greeting = subject.hello("Pan");
assertThat(greeting, is("Hello Peter Pan!"));
}
@Test
public void shouldTellIfPersonIsUnknown() throws Exception {
given(personRepo.findByLastName(anyString()))
.willReturn(Optional.empty());
String greeting = subject.hello("Pan");
assertThat(greeting, is("Who is this 'Pan' you're talking about?"));
}
}
JavaのデファクトスタンダードのテストフレームワークであるJUnitを使用してユニットテストを作成しています。Mockitoを使用して、実際のPersonRepositoryクラスをテスト用のスタブに置き換えます。このスタブを使用すると、スタブ化されたメソッドがこのテストで返す必要がある既定の応答を定義できます。スタブを使用すると、テストがよりシンプルで予測可能になり、テストデータを簡単に設定できます。
準備、実行、アサートの構造に従って、2つのユニットテスト(肯定的なケースと、検索対象の人物が見つからないケース)を作成します。最初の肯定的なテストケースは、新しいpersonオブジェクトを作成し、lastNameパラメータの値として"Pan"を使用して呼び出されたときに、このオブジェクトを返すようにモックリポジトリに指示します。次に、テスト対象のメソッドを呼び出します。最後に、応答が期待される応答と等しいことをアサートします。
2番目のテストも同様に機能しますが、テスト対象のメソッドが指定されたパラメータの人物を見つけられないシナリオをテストします。
統合テスト
すべての重要なアプリケーションは、他のいくつかの部分(データベース、ファイルシステム、他のアプリケーションへのネットワーク呼び出し)と統合されます。ユニットテストを作成する場合、これらは通常、より良い分離とより高速なテストを実現するために省略する部分です。それでも、アプリケーションは他の部分と対話し、これをテストする必要があります。統合テストは、そのためにあります。アプリケーションと、アプリケーションの外部にあるすべての部分との統合をテストします。
自動テストの場合、これは独自のアプリケーションだけでなく、統合しているコンポーネントも実行する必要があることを意味します。データベースとの統合をテストする場合は、テストを実行するときにデータベースを実行する必要があります。ディスクからファイルを読み取ることができることをテストするには、ファイルをディスクに保存し、統合テストでロードする必要があります。
前に「ユニットテスト」は曖昧な用語であると述べましたが、これは「統合テスト」にはさらに当てはまります。一部の人にとって、統合テストとは、システム内の他のアプリケーションに接続されたアプリケーションのスタック全体をテストすることを意味します。統合テストをより狭義に扱い、個別のサービスとデータベースをテストダブルに置き換えることで、一度に1つの統合ポイントをテストすることを好みます。コントラクトテストと、テストダブルと実際の実装に対するコントラクトテストの実行を組み合わせることで、より高速で、より独立しており、通常はより簡単に理解できる統合テストを作成できます。
狭い統合テストは、サービスの境界にあります。概念的には、常に外部部分(ファイルシステム、データベース、個別のサービス)との統合につながるアクションをトリガーすることです。データベース統合テストは次のようになります
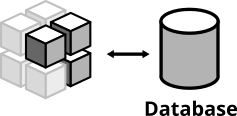
図6:データベース統合テストは、コードを実際のデータベースと統合します
- データベースを起動する
- アプリケーションをデータベースに接続する
- コード内でデータをデータベースに書き込む関数をトリガーする
- データベースからデータを読み取って、予想されるデータがデータベースに書き込まれたことを確認する
別の例として、サービスがREST APIを介して別のサービスと統合されていることをテストする方法は次のようになります
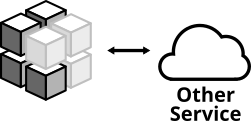
図7:この種類の統合テストでは、アプリケーションが別のサービスと正しく通信できることを確認します
- アプリケーションを起動する
- 別のサービスのインスタンス(または同じインターフェースを持つテストダブル)を起動する
- コード内で別のサービスのAPIから読み取る関数をトリガーする
- アプリケーションが応答を正しく解析できることを確認する
統合テストは、ユニットテストと同様に、かなりホワイトボックスにすることができます。一部のフレームワークでは、アプリケーションの他の部分をモックしながらアプリケーションを起動できるため、正しいインタラクションが発生したことを確認できます。
データをシリアル化またはデシリアライズするすべてのコード部分に対して統合テストを作成します。これは、あなたが思っているよりも頻繁に発生します。以下のことについて考えてみてください
- サービスのREST APIへの呼び出し
- データベースの読み取りと書き込み
- 他のアプリケーションのAPIの呼び出し
- キューの読み取りと書き込み
- ファイルシステムへの書き込み
これらの境界の周囲に統合テストを作成すると、これらの外部コラボレーターへのデータの書き込みとデータの読み取りが正常に機能することが保証されます。
狭い統合テストを作成する場合は、外部依存関係をローカルで実行することを目指す必要があります。ローカルのMySQLデータベースを起動し、ローカルのext4ファイルシステムに対してテストします。別のサービスと統合する場合は、そのサービスのインスタンスをローカルで実行するか、実際のサービスの動作を模倣する偽のバージョンをビルドして実行します。
サードパーティサービスをローカルで実行する方法がない場合は、専用のテストインスタンスを実行し、統合テストを実行するときにこのテストインスタンスを指す必要があります。自動テストで実際の運用システムと統合することは避けてください。運用システムに対して何千ものテストリクエストを送信すると、ログが乱雑になる(最良の場合)か、サービスのDoS攻撃が発生する(最悪の場合)ため、確実に人々が怒ります。ネットワークを介したサービスとの統合は、広範な統合テストの典型的な特徴であり、テストの速度が低下し、通常は作成が難しくなります。
テストピラミッドに関しては、統合テストはユニットテストよりも高いレベルにあります。ファイルシステムやデータベースなどの低速な部分を統合すると、これらの部分をスタブアウトしたユニットテストを実行するよりもはるかに遅くなる傾向があります。また、小さくて隔離されたユニットテストよりも作成が難しい場合もあります。結局のところ、テストの一部として外部部分をスピンアップする必要があります。それでも、アプリケーションが通信する必要があるすべての外部部分と正しく連携できるという自信が得られるという利点があります。ユニットテストでは、それはできません。
データベース統合
PersonRepositoryは、コードベースで唯一のリポジトリクラスです。Spring Dataに依存しており、実際の実装はありません。CrudRepositoryインターフェースを拡張し、単一のメソッドヘッダーを提供するだけです。残りはSpringマジックです。
public interface PersonRepository extends CrudRepository<Person, String> {
Optional<Person> findByLastName(String lastName);
}
CrudRepositoryインターフェースを使用すると、Spring Bootは、findOne、findAll、save、update、およびdeleteメソッドを備えた完全に機能するCRUDリポジトリを提供します。カスタムメソッド定義(findByLastName())はこの基本機能を拡張し、姓でPersonを取得する方法を提供します。Spring Dataは、メソッドの戻り値の型とそのメソッド名を分析し、命名規則に照らしてメソッド名をチェックして、何をするかを判断します。
Spring Dataはデータベースリポジトリの実装の面倒な作業を行いますが、それでもデータベース統合テストを作成しました。これはフレームワークのテストであり、テストしているのは私たちのコードではないため、避けるべきだと主張するかもしれません。それでも、ここに少なくとも1つの統合テストを用意することが重要だと考えています。まず、カスタムのfindByLastNameメソッドが実際に期待どおりに動作することをテストします。次に、リポジトリがSpringの配線を正しく使用し、データベースに接続できることを証明します。
(PostgreSQLデータベースをインストールしなくても)マシンでテストを実行しやすくするために、テストはインメモリH2データベースに接続します。
build.gradleファイルにH2をテスト依存関係として定義しました。テストディレクトリのapplication.propertiesは、spring.datasourceプロパティを定義していません。これは、Spring Dataにインメモリデータベースを使用するように指示します。クラスパスでH2が見つかるため、テストの実行時に単純にH2を使用します。
intプロファイルで実際のアプリケーションを実行する場合(たとえば、環境変数としてSPRING_PROFILES_ACTIVE=intを設定することにより)、application-int.propertiesで定義されているPostgreSQLデータベースに接続します。
それは、知って理解するには非常に多くのSpringの仕様です。そこに到達するには、多くのドキュメントを詳しく調べる必要があります。結果のコードは一見簡単ですが、Springの詳細を知らないと理解するのは困難です。
その上、インメモリデータベースを使用することは危険なビジネスです。結局のところ、統合テストは、本番環境とは異なるタイプのデータベースに対して実行されます。Springマジックとシンプルなコードを、明示的ではるかに冗長な実装よりも好むかどうか、自分で判断してください。
説明はこれで十分です。Personをデータベースに保存し、姓で検索する簡単な統合テストを次に示します
@RunWith(SpringRunner.class)
@DataJpaTest
public class PersonRepositoryIntegrationTest {
@Autowired
private PersonRepository subject;
@After
public void tearDown() throws Exception {
subject.deleteAll();
}
@Test
public void shouldSaveAndFetchPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
subject.save(peter);
Optional<Person> maybePeter = subject.findByLastName("Pan");
assertThat(maybePeter, is(Optional.of(peter)));
}
}
統合テストは、ユニットテストと同じ準備、実行、アサート構造に従っていることがわかります。これが普遍的な概念だと言ったじゃないですか!
独立したサービスとの統合
マイクロサービスは、気象REST APIであるdarksky.netと通信します。もちろん、サービスがリクエストを送信し、レスポンスを正しく解析することを確認したいと考えています。
自動テストを実行するときに、実際のdarkskyサーバーにアクセスすることは避けたいと考えています。無料プランのクォータ制限は、その理由の一部にすぎません。本当の理由は分離です。テストは、darksky.netの素晴らしい人々が何をしているかに関係なく、独立して実行される必要があります。マシンがdarkskyサーバーにアクセスできない場合や、darkskyサーバーがメンテナンスのためにダウンしている場合でもです。
統合テストの実行中に独自の偽のdarkskyサーバーを実行することで、実際のdarkskyサーバーへのアクセスを回避できます。これは非常に大変な作業のように聞こえるかもしれません。Wiremockのようなツールのおかげで、それは簡単です。これを見てください
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeatherClientIntegrationTest {
@Autowired
private WeatherClient subject;
@Rule
public WireMockRule wireMockRule = new WireMockRule(8089);
@Test
public void shouldCallWeatherService() throws Exception {
wireMockRule.stubFor(get(urlPathEqualTo("/some-test-api-key/53.5511,9.9937"))
.willReturn(aResponse()
.withBody(FileLoader.read("classpath:weatherApiResponse.json"))
.withHeader(CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.withStatus(200)));
Optional<WeatherResponse> weatherResponse = subject.fetchWeather();
Optional<WeatherResponse> expectedResponse = Optional.of(new WeatherResponse("Rain"));
assertThat(weatherResponse, is(expectedResponse));
}
}
Wiremockを使用するには、固定ポート(`8089`)で`WireMockRule`をインスタンス化します。DSLを使用して、Wiremockサーバーをセットアップし、リッスンするエンドポイントを定義し、応答するべき固定レスポンスを設定できます。
次に、テストしたいメソッド、つまりサードパーティサービスを呼び出すメソッドを呼び出し、結果が正しく解析されているかどうかを確認します。
テストが、実際の*darksky* APIの代わりに偽のWiremockサーバーを呼び出すべきことをどのように認識しているかを理解することが重要です。秘密は、`src/test/resources`に含まれる`application.properties`ファイルにあります。これは、Springがテストを実行するときにロードするプロパティファイルです。このファイルでは、APIキーやURLなどの設定を、テストの目的に適した値(たとえば、実際のサーバーではなく偽のWiremockサーバーを呼び出すなど)で上書きします。
weather.url = https://:8089
ここで定義するポートは、テストで`WireMockRule`をインスタンス化するときに定義するポートと同じである必要があることに注意してください。テストで実際の天気APIのURLを偽のURLに置き換えることは、`WeatherClient`クラスのコンストラクターにURLを注入することで可能になります。
@Autowired
public WeatherClient(final RestTemplate restTemplate,
@Value("${weather.url}") final String weatherServiceUrl,
@Value("${weather.api_key}") final String weatherServiceApiKey) {
this.restTemplate = restTemplate;
this.weatherServiceUrl = weatherServiceUrl;
this.weatherServiceApiKey = weatherServiceApiKey;
}
このようにして、`WeatherClient`に、アプリケーションプロパティで定義した`weather.url`プロパティから`weatherUrl`パラメータの値を読み取るように指示します。
Wiremockのようなツールを使用すると、個別のサービスの*狭義の統合テスト*を簡単に記述できます。残念ながら、このアプローチには欠点があります。セットアップした偽のサーバーが実際のサーバーのように動作することをどのように保証できるでしょうか?現在の実装では、個別のサービスがAPIを変更しても、テストは合格する可能性があります。今は、`WeatherClient`が偽のサーバーから送信されたレスポンスを解析できることをテストしているだけです。それは始まりですが、非常に脆いです。*エンドツーエンドテスト*を使用して、偽のサービスを使用する代わりに実際のサービスのテストインスタンスに対してテストを実行すると、この問題は解決しますが、テストサービスの可用性に依存することになります。幸いなことに、このジレンマに対するより良い解決策があります。偽のサーバーと実際のサーバーに対してコントラクトテストを実行することで、統合テストで使用する偽のサーバーが忠実なテストダブルであることを保証できます。次に、これがどのように機能するかを見てみましょう。
コントラクトテスト
より近代的なソフトウェア開発組織は、システムの開発をさまざまなチームに分散させることで、開発の取り組みを拡大する方法を見つけました。個々のチームは、互いに干渉することなく、個々の疎結合サービスを構築し、これらのサービスを大きくまとまりのあるシステムに統合します。マイクロサービスに関する最近の話題は、まさにそれを中心に展開しています。
システムを多くの小さなサービスに分割すると、多くの場合、これらのサービスは特定の(うまく定義されていることが望ましいですが、偶発的に成長することもある)インターフェースを介して互いに通信する必要があります。
異なるアプリケーション間のインターフェースは、さまざまな形状とテクノロジーで提供されます。一般的なものは次のとおりです。
- HTTPSを介したRESTとJSON
- `gRPC`のようなものを使用したRPC
- キューを使用したイベント駆動型アーキテクチャの構築
各インターフェースには、プロバイダーとコンシューマーの2つの関係者がいます。**プロバイダー**はコンシューマーにデータを提供します。**コンシューマー**は、プロバイダーから取得したデータを処理します。RESTの世界では、プロバイダーは必要なすべてのエンドポイントを備えたREST APIを構築します。コンシューマーはこのREST APIを呼び出して、データをフェッチしたり、他のサービスの変更をトリガーしたりします。非同期イベント駆動型の世界では、プロバイダー(多くの場合、**パブリッシャー**と呼ばれます)はキューにデータを公開します。コンシューマー(多くの場合、**サブスクライバー**と呼ばれます)はこれらのキューにサブスクライブし、データを読み取って処理します。
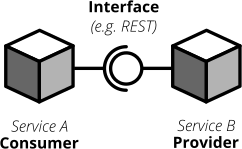
図8:各インターフェースには、提供(または公開)側と消費(またはサブスクライブ)側があります。インターフェースの仕様はコントラクトと見なすことができます。
消費サービスと提供サービスを異なるチームに分散させることが多いため、これらのサービス間のインターフェース(いわゆる**コントラクト**)を明確に指定する必要があるという状況に陥ります。従来、企業はこの問題に次のように対処してきました。
- 詳細なインターフェース仕様(*コントラクト*)を作成する
- 定義されたコントラクトに従って提供サービスを実装する
- インターフェース仕様を消費チームに渡す
- 彼らがインターフェースを消費する部分を実装するまで待つ
- 大規模な手動システムテストを実行して、すべてが機能するかどうかを確認する
- 両方のチームがインターフェース定義に永遠に固執し、失敗しないことを願う
より近代的なソフトウェア開発チームは、手順5と6をより自動化されたものに置き換えています。自動化されたコントラクトテストは、コンシューマー側とプロバイダー側の実装が定義されたコントラクトに準拠していることを確認します。優れた回帰テストスイートとして機能し、コントラクトからの逸 desviaciones が早期に認識されるようにします。
より機敏な組織では、より効率的で無駄の少ないルートを選択する必要があります。同じ組織内でアプリケーションを構築します。過度に詳細なドキュメントを渡す代わりに、他のサービスの開発者と直接話すことはそれほど難しいことではありません。結局のところ、彼らはあなたの同僚であり、カスタマーサポートや法的に防弾された契約を通じてのみ話すことができるサードパーティベンダーではありません。
**コンシューマー主導のコントラクトテスト**(CDCテスト)では、コンシューマーがコントラクトの実装を主導します。CDCを使用すると、インターフェースのコンシューマーは、そのインターフェースから必要なすべてのデータについてインターフェースをチェックするテストを作成します。次に、消費チームはこれらのテストを公開するため、公開チームはこれらのテストを簡単にフェッチして実行できます。提供チームは、CDCテストを実行することでAPIを開発できるようになりました。すべてのテストに合格すると、消費チームが必要とするすべてを実装したことがわかります。
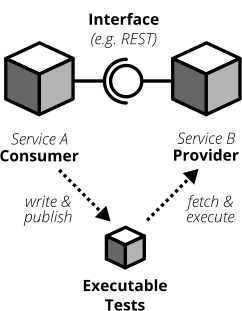
図9:コントラクトテストは、インターフェースのプロバイダーとすべてのコンシューマーが定義されたインターフェースコントラクトに準拠していることを保証します。CDCテストでは、インターフェースのコンシューマーが自動テストの形式で要件を公開します。プロバイダーはこれらのテストを継続的にフェッチして実行します
このアプローチにより、提供チームは本当に必要なものだけを実装できます(物事をシンプルに保ち、YAGNIなど)。インターフェースを提供するチームは、これらのCDCテストを継続的に(ビルドパイプラインで)フェッチして実行し、重大な変更をすぐに発見する必要があります。インターフェースを壊すと、CDCテストが失敗し、重大な変更が公開されるのを防ぎます。テストがグリーンのままである限り、チームは他のチームを心配することなく、好きな変更を加えることができます。コンシューマー主導のコントラクトアプローチでは、次のようなプロセスになります。
- 消費チームは、すべてのコンシューマーの期待を込めた自動テストを作成します
- 提供チームのためにテストを公開します
- 提供チームはCDCテストを継続的に実行し、グリーンに保ちます
- CDCテストが失敗すると、両方のチームが互いに話し合います
組織がマイクロサービスアプローチを採用する場合、CDCテストを実施することは、自律型チームを確立するための大きな一歩となります。CDCテストは、チームのコミュニケーションを促進する自動化された方法です。チーム間のインターフェースが常に機能していることを保証します。CDCテストの失敗は、影響を受けるチームに連絡し、今後のAPIの変更について話し合い、前進する方法を理解する必要があることを示す良い指標です。
CDCテストの単純な実装は、APIに対してリクエストを発行し、レスポンスに必要なものがすべて含まれていることをアサートするのと同じくらい簡単です。次に、これらのテストを実行可能ファイル(.gem、.jar、.sh)としてパッケージ化し、他のチームがフェッチできる場所にアップロードします(たとえば、Artifactoryのようなアーティファクトリポジトリ)。
ここ数年で、CDCアプローチはますます普及し、記述と交換を容易にするためのいくつかのツールが構築されてきました。
Pactはおそらく最近最も有名なものです。コンシューマー側とプロバイダー側のテストを作成するための洗練されたアプローチがあり、すぐに使える個別のサービスのスタブを提供し、他のチームとCDCテストを交換できます。Pactは多くのプラットフォームにポーティングされており、JVM言語、Ruby、.NET、JavaScriptなど、多くの言語で使用できます。
CDCを始めたいが方法がわからない場合は、Pactが賢明な選択です。ドキュメントは最初は圧倒されるかもしれません。辛抱強く、それをやり遂げてください。CDCをしっかりと理解するのに役立ち、他のチームと協力するときにCDCの使用を提唱しやすくなります。
コンシューマー主導のコントラクトテストは、自信を持って迅速に移動できる自律型チームを確立するための真のゲームチェンジャーとなる可能性があります。ご自身のために、その概念を読んで試してみてください。堅牢なCDCテストスイートは、他のサービスを壊したり、他のチームに多くのフラストレーションを引き起こしたりすることなく、迅速に移動できるために非常に貴重です。
コンシューマーテスト(自チーム)
私たちのマイクロサービスは天気APIを使用します。そのため、マイクロサービスと気象サービス間の契約(API)に対する期待を定義する**コンシューマーテスト**を作成するのは私たちの責任です。
最初に、`build.gradle`にpactコンシューマーテストを作成するためのライブラリを含めます。
testCompile('au.com.dius:pact-jvm-consumer-junit_2.11:3.5.5')
このライブラリのおかげで、コンシューマーテストを実装し、pactのモックサービスを使用できます。
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeatherClientConsumerTest {
@Autowired
private WeatherClient weatherClient;
@Rule
public PactProviderRuleMk2 weatherProvider =
new PactProviderRuleMk2("weather_provider", "localhost", 8089, this);
@Pact(consumer="test_consumer")
public RequestResponsePact createPact(PactDslWithProvider builder) throws IOException {
return builder
.given("weather forecast data")
.uponReceiving("a request for a weather request for Hamburg")
.path("/some-test-api-key/53.5511,9.9937")
.method("GET")
.willRespondWith()
.status(200)
.body(FileLoader.read("classpath:weatherApiResponse.json"),
ContentType.APPLICATION_JSON)
.toPact();
}
@Test
@PactVerification("weather_provider")
public void shouldFetchWeatherInformation() throws Exception {
Optional<WeatherResponse> weatherResponse = weatherClient.fetchWeather();
assertThat(weatherResponse.isPresent(), is(true));
assertThat(weatherResponse.get().getSummary(), is("Rain"));
}
}
よく見ると、`WeatherClientConsumerTest`は`WeatherClientIntegrationTest`と非常によく似ていることがわかります。サーバースタブにWiremockを使用する代わりに、今回はPactを使用します。実際、コンシューマーテストは統合テストとまったく同じように機能します。実際のサードパーティサーバーをスタブに置き換え、期待されるレスポンスを定義し、クライアントがレスポンスを正しく解析できることを確認します。この意味で、`WeatherClientConsumerTest`はそれ自体が狭い統合テストです。wiremockベースのテストよりも優れている点は、このテストが実行されるたびに*pactファイル*(`target/pacts/&pact-name>.json`にあります)が生成されることです。このpactファイルは、特別なJSON形式でコントラクトに対する期待を記述しています。このpactファイルを使用して、スタブサーバーが実際のサーバーのように動作することを確認できます。pactファイルを取得して、インターフェースを提供するチームに渡すことができます。彼らは、このpactファイルを取得し、そこに定義されている期待を使用してプロバイダーテストを作成します。このようにして、APIがすべての期待を満たしているかどうかをテストします。
これがCDCの*コンシューマー主導*の部分の由来であることがわかります。コンシューマーは、期待を記述することにより、インターフェースの実装を推進します。プロバイダーは、すべての期待を満たしていることを確認する必要があり、完了です。金メッキ、YAGNI、その他のものはありません。
提供チームにpactファイルを取得するには、複数の方法があります。簡単な方法は、バージョン管理にチェックインし、提供チームに常にpactファイルの最新バージョンをフェッチするように指示することです。より高度な方法は、アーティファクトリポジトリ、AmazonのS3やpactブローカーなどのサービスを使用することです。シンプルに始めて、必要に応じて成長させてください。
実際のアプリケーションでは、クライアントクラスに対して*統合テスト*と*コンシューマーテスト*の両方は必要ありません。サンプルコードベースには、どちらを使用する方法を示すために両方が含まれています。pactを使用してCDCテストを作成する場合は、後者を使用することをお勧めします。テストの作成に必要な労力は同じです。pactを使用する利点は、他のチームがプロバイダーテストを簡単に実装するために使用できるコントラクトに対する期待を含むpactファイルを自動的に取得できることです。もちろん、これは他のチームにもpactの使用を納得させられる場合にのみ意味があります。これがうまくいかない場合は、*統合テスト*とWiremockの組み合わせが妥当な代替案です。
プロバイダーテスト(他チーム)
プロバイダーテストは、気象APIを提供する担当者が実装する必要があります。私たちは、darksky.netによって提供されるパブリックAPIを使用しています。理論的には、darkskyチームは、アプリケーションとサービス間の契約に違反していないことを確認するために、プロバイダーテストを独自に実装します。
明らかに、彼らは私たちの貧弱なサンプルアプリケーションに関心がなく、私たちのためにCDCテストを実装することはありません。これは、公開APIとマイクロサービスを採用する組織との大きな違いです。公開APIは、そこにいるすべてのコンシューマーを考慮することはできません。そうしないと、前進できなくなります。組織内では、そうすることができますし、そうすべきです。あなたのアプリは、おそらく少数の、おそらく最大で数十のコンシューマーにサービスを提供するでしょう。安定したシステムを維持するために、これらのインターフェースのプロバイダーテストを作成しても問題ありません。
提供チームは、pactファイルを取得し、提供サービスに対して実行します。そのためには、pactファイルを読み取り、テストデータをスタブアウトし、pactファイルで定義された期待をサービスに対して実行するプロバイダーテストを実装します。
pactの作成者は、プロバイダーテストを実装するためのライブラリをいくつか作成しています。彼らのメインのGitHubリポジトリは、どのコンシューマーとどのプロバイダーライブラリが利用可能かについての優れた概要を提供しています。あなたの技術スタックに最も合うものを選んでください。
簡単にするために、darksky APIもSpring Bootで実装されていると仮定しましょう。この場合、彼らはSpringのMockMVCメカニズムとうまく連携するSpring pactプロバイダーを使用できます。darksky.netチームが実装するであろう仮説的なプロバイダーテストは次のようになります。
@RunWith(RestPactRunner.class)
@Provider("weather_provider") // same as the "provider_name" in our clientConsumerTest
@PactFolder("target/pacts") // tells pact where to load the pact files from
public class WeatherProviderTest {
@InjectMocks
private ForecastController forecastController = new ForecastController();
@Mock
private ForecastService forecastService;
@TestTarget
public final MockMvcTarget target = new MockMvcTarget();
@Before
public void before() {
initMocks(this);
target.setControllers(forecastController);
}
@State("weather forecast data") // same as the "given()" in our clientConsumerTest
public void weatherForecastData() {
when(forecastService.fetchForecastFor(any(String.class), any(String.class)))
.thenReturn(weatherForecast("Rain"));
}
}
プロバイダーテストが行う必要があるのは、pactファイルを読み込むこと(たとえば、以前にダウンロードしたpactファイルを読み込むために `@PactFolder` アノテーションを使用する)と、事前定義された状態のテストデータをどのように提供するかを定義すること(たとえば、Mockitoモックを使用する)だけです。実装するカスタムテストはありません。これらはすべてpactファイルから派生しています。プロバイダーテストには、コンシューマーテストで宣言された*プロバイダー名*と*状態*に対応するものが存在することが重要です。
プロバイダーテスト(自チーム)
サービスと気象プロバイダー間の契約をテストする方法を見てきました。このインターフェースでは、サービスはコンシューマーとして機能し、気象サービスはプロバイダーとして機能します。もう少し考えてみると、私たちのサービスも他のサービスのプロバイダーとして機能していることがわかります。私たちは、他のサービスが利用できるエンドポイントをいくつか提供するREST APIを提供しています。
契約テストが流行していることを知ったので、もちろんこの契約の契約テストも作成します。幸いなことに、コンシューマー主導の契約を使用しているので、すべてのコンシューマーチームがREST APIのプロバイダーテストを実装するために使用できるPactを送信してくれます。
まず、Spring用のPactプロバイダーライブラリをプロジェクトに追加しましょう。
testCompile('au.com.dius:pact-jvm-provider-spring_2.12:3.5.5')
プロバイダーテストの実装は、前述のパターンと同じです。簡単にするために、単純なコンシューマーからのpactファイルをサービスのリポジトリにチェックインしました。これは、私たちの目的を容易にします。実際のシナリオでは、おそらくpactファイルを配布するためのより洗練されたメカニズムを使用するでしょう。
@RunWith(RestPactRunner.class)
@Provider("person_provider")// same as in the "provider_name" part in our pact file
@PactFolder("target/pacts") // tells pact where to load the pact files from
public class ExampleProviderTest {
@Mock
private PersonRepository personRepository;
@Mock
private WeatherClient weatherClient;
private ExampleController exampleController;
@TestTarget
public final MockMvcTarget target = new MockMvcTarget();
@Before
public void before() {
initMocks(this);
exampleController = new ExampleController(personRepository, weatherClient);
target.setControllers(exampleController);
}
@State("person data") // same as the "given()" part in our consumer test
public void personData() {
Person peterPan = new Person("Peter", "Pan");
when(personRepository.findByLastName("Pan")).thenReturn(Optional.of
(peterPan));
}
}
示されている `ExampleProviderTest` は、提供されたpactファイルに従って状態を提供する必要があります。それだけです。プロバイダーテストを実行すると、Pactはpactファイルを取得し、サービスに対してHTTPリクエストを送信します。サービスは、設定した状態に従って応答します。
UIテスト
ほとんどのアプリケーションには、何らかのユーザーインターフェースがあります。通常、Webアプリケーションのコンテキストでは、Webインターフェースについて話しています。REST APIまたはコマンドラインインターフェースは、派手なWebユーザーインターフェースと同じくらいユーザーインターフェースであることを人々はしばしば忘れています。
*UIテスト*は、アプリケーションのユーザーインターフェースが正しく機能することをテストします。ユーザー入力は正しいアクションをトリガーし、データはユーザーに提示され、UIの状態は期待どおりに変化するはずです。
UIテストとエンドツーエンドテストは、(Mike Cohnの場合のように)同じものであると言われることがあります。私にとって、これはむしろ直交する2つの概念を混同しています。
はい、アプリケーションをエンドツーエンドでテストするということは、多くの場合、ユーザーインターフェースを介してテストを実行することを意味します。しかし、逆は真ではありません。
ユーザーインターフェースのテストは、エンドツーエンド方式で行う必要はありません。使用するテクノロジーによっては、ユーザーインターフェースのテストは、バックエンドをスタブアウトしたフロントエンドのJavaScriptコードの単体テストを作成するのと同じくらい簡単です。
従来のWebアプリケーションでは、ユーザーインターフェースのテストは、Seleniumなどのツールを使用して実現できます。REST APIをユーザーインターフェースと見なす場合は、APIに関する適切な統合テストを作成することで必要なすべてが揃っているはずです。
Webインターフェースには、UIに関してテストしたいと思う側面がいくつかあります。動作、レイアウト、使いやすさ、または企業デザインの順守は、ほんの一例です。
幸いなことに、ユーザーインターフェースの*動作*をテストするのは非常に簡単です。ここでクリックし、そこにデータを入力すると、ユーザーインターフェースの状態がそれに応じて変化します。最新のシングルページアプリケーションフレームワーク(react、vue.js、Angularなど)には、これらのインタラクションを非常に低レベル(単体テスト)で徹底的にテストできる独自のツールとヘルパーが付属していることがよくあります。バニラJavaScriptを使用して独自のフロントエンド実装を展開する場合でも、JasmineやMochaなどの通常のテストツールを使用できます。より伝統的なサーバーサイドレンダリングアプリケーションでは、Seleniumベースのテストが最適です。
Webアプリケーションの*レイアウト*が変更されていないことをテストするのは少し難しいです。アプリケーションとユーザーのニーズによっては、コード変更によってWebサイトのレイアウトが誤って壊れないようにしたい場合があります。
問題は、コンピューターは何かが「見栄えが良い」かどうかをチェックするのが非常に苦手だということです(おそらく、将来、巧妙な機械学習アルゴリズムがそれを変えることができるかもしれません)。
ビルドパイプラインでWebアプリケーションのデザインを自動的にチェックしたい場合に試してみるツールがいくつかあります。これらのツールのほとんどは、Seleniumを利用してWebアプリケーションをさまざまなブラウザや形式で開き、スクリーンショットを撮り、これらを以前に撮ったスクリーンショットと比較します。古いスクリーンショットと新しいスクリーンショットが予期しない方法で異なる場合、ツールはそれを知らせます。
Galenは、これらのツールの1つです。特別な要件がある場合でも、独自のソリューションを展開することはそれほど難しくありません。私が一緒に仕事をしたことのあるチームの中には、同様のことを実現するためにlineupとそのJavaベースのいとこであるjlineupを構築したチームもあります。どちらのツールも、前述のSeleniumベースのアプローチを採用しています。
*使いやすさ*と「見栄えが良い」要素をテストしたい場合は、自動テストの領域を離れます。これは、探索的テスト、ユーザビリティテスト(これは廊下テストほど簡単な場合もあります)、およびユーザーとのショーケースに頼って、ユーザーが製品の使用を気に入っているかどうか、イライラしたりイライラしたりすることなくすべての機能を使用できるかどうかを確認する必要がある領域です。
エンドツーエンドテスト
デプロイされたアプリケーションをユーザーインターフェースを介してテストすることは、アプリケーションをテストできる最もエンドツーエンドの方法です。前述のwebdriver駆動UIテストは、エンドツーエンドテストの良い例です。
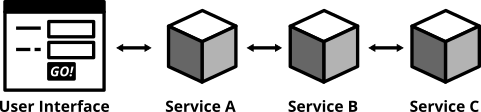
図11:エンドツーエンドテストは、完全に統合されたシステム全体をテストします
エンドツーエンドテスト(ブロードスタックテストとも呼ばれます)は、ソフトウェアが機能しているかどうかを判断する必要がある場合に、最大の自信を与えてくれます。SeleniumとWebDriverプロトコルを使用すると、デプロイされたサービスに対して(ヘッドレス)ブラウザを自動的に駆動し、クリックを実行し、データを入力し、ユーザーインターフェースの状態を確認することで、テストを自動化できます。Seleniumを直接使用することも、Seleniumの上に構築されたツールを使用することもできます。Nightwatchはその1つです。
エンドツーエンドテストには、独自の問題があります。それらは悪名高く不安定であり、予期せず予見できない理由で失敗することがよくあります。多くの場合、それらの失敗は誤検知です。ユーザーインターフェースが洗練されているほど、テストは不安定になる傾向があります。ブラウザの癖、タイミングの問題、アニメーション、予期しないポップアップダイアログは、私が認めたくないほどデバッグに時間を費やした理由のほんの一部です。
マイクロサービスの世界では、誰がこれらのテストの作成を担当するのかという大きな疑問もあります。それらは複数のサービス(システム全体)に及ぶため、エンドツーエンドテストの作成を担当する単一のチームはありません。
集中型の*品質保証*チームがある場合、彼らは適任のように見えます。しかし、集中型のQAチームを持つことは大きなアンチパターンであり、チームが真にクロスファンクショナルであることを意図しているDevOpsの世界には存在すべきではありません。エンドツーエンドテストを誰が所有すべきかについての簡単な答えはありません。おそらくあなたの組織には、これらを処理できる実践コミュニティまたは*品質ギルド*があるでしょう。正しい答えを見つけることは、あなたの組織に大きく依存します。
さらに、エンドツーエンドテストには多くのメンテナンスが必要であり、実行速度が非常に遅くなります。いくつかのマイクロサービスが配置されている以上のランドスケープについて考えると、エンドツーエンドテストをローカルで実行することさえできません。これは、すべてのマイクロサービスもローカルで起動する必要があるためです。RAMを揚げることなく、開発マシンで数百のアプリケーションをスピンアップしてみてください。
メンテナンスコストが高いため、エンドツーエンドテストの数を最小限に抑える必要があります。
ユーザーがアプリケーションとどのように対話するかを検討してください。製品のコアバリューを定義するユーザー体験を考案し、これらのユーザー体験の最も重要なステップを自動化されたエンドツーエンドテストに変換してみてください。
Eコマースサイトを構築する場合、最も重要なカスタマージャーニーは、ユーザーが商品を検索し、ショッピングカートに入れて、チェックアウトを行うことです。それだけです。このジャーニーが機能し続ける限り、大きな問題にはなりません。エンドツーエンドテストに変換できる重要なカスタマージャーニーがもう1つまたは2つ見つかるかもしれません。それ以上のことは、役に立つよりも苦痛になる可能性があります。
覚えておいてください:テストピラミッドには、あらゆる種類のエッジケースやシステムの他の部分との統合をすでにテストした、より低いレベルがたくさんあります。これらのテストをより高いレベルで繰り返す必要はありません。メンテナンスの手間と多くの誤検知は、開発速度を低下させ、遅かれ早かれテストへの信頼を失う原因になります。
ユーザーインターフェースエンドツーエンドテスト
エンドツーエンドテストでは、Selenium と WebDriver プロトコルが多くの開発者にとって最適なツールです。Seleniumを使用すると、好きなブラウザを選択し、自動的にWebサイトを呼び出し、あちこちをクリックし、データを入力し、ユーザーインターフェイスで内容が変更されていることを確認できます。
Seleniumは、テストの実行に起動して使用できるブラウザが必要です。使用できるさまざまなブラウザ用のいわゆる「ドライバー」が複数あります。1つ(または複数)を選択し、build.gradleに追加します。どのブラウザを選択しても、チームのすべての開発者とCIサーバーが正しいバージョンのブラウザをローカルにインストールしていることを確認する必要があります。これを同期させるのは非常に面倒な場合があります。Javaの場合、webdrivermanager という便利な小さなライブラリがあり、使用するブラウザの正しいバージョンのダウンロードと設定を自動化できます。これらの2つの依存関係をbuild.gradleに追加すれば、準備完了です。
testCompile('org.seleniumhq.selenium:selenium-chrome-driver:2.53.1')
testCompile('io.github.bonigarcia:webdrivermanager:1.7.2')
テストスイートで本格的なブラウザを実行するのは面倒な場合があります。特に継続的デリバリーを使用する場合、パイプラインを実行しているサーバーは、ユーザーインターフェイスを含むブラウザを起動できない場合があります(たとえば、Xサーバーがないため)。xvfbのような仮想Xサーバーを起動することで、この問題の回避策をとることができます。
より最近のアプローチは、ヘッドレスブラウザ(つまり、ユーザーインターフェイスのないブラウザ)を使用してwebdriverテストを実行することです。最近まで、PhantomJS はブラウザの自動化に使用される主要なヘッドレスブラウザでした。Chromium と Firefox の両方がブラウザにヘッドレスモードを実装したことを発表して以来、PhantomJSは突然時代遅れになりました。結局のところ、開発者にとって便利だからという理由だけで人工的なブラウザを使用するのではなく、ユーザーが実際に使用しているブラウザ(FirefoxやChromeなど)でWebサイトをテストする方が良いでしょう。
ヘッドレスFirefoxとChromeはどちらもまったく新しく、webdriverテストの実装にはまだ広く採用されていません。ここでは物事をシンプルに保ちたいと思います。最先端のヘッドレスモードを使用しようと苦労するのではなく、Seleniumと通常のブラウザを使用した従来の方法に固執しましょう。Chromeを起動し、サービスに移動して、Webサイトのコンテンツを確認する簡単なエンドツーエンドテストは次のようになります。
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class HelloE2ESeleniumTest {
private WebDriver driver;
@LocalServerPort
private int port;
@BeforeClass
public static void setUpClass() throws Exception {
ChromeDriverManager.getInstance().setup();
}
@Before
public void setUp() throws Exception {
driver = new ChromeDriver();
}
@After
public void tearDown() {
driver.close();
}
@Test
public void helloPageHasTextHelloWorld() {
driver.get(String.format("http://127.0.0.1:%s/hello", port));
assertThat(driver.findElement(By.tagName("body")).getText(), containsString("Hello World!"));
}
}
このテストは、このテストを実行するシステム(ローカルマシン、CIサーバー)にChromeがインストールされている場合にのみシステムで実行されることに注意してください。
テストは簡単です。@SpringBootTestを使用して、ランダムなポートでSpringアプリケーション全体を起動します。次に、新しいChrome webdriverをインスタンス化し、マイクロサービスの/helloエンドポイントに移動して、ブラウザウィンドウに「Hello World!」と表示されることを確認します。素晴らしい!Webインターフェースを使用していない場合でも、エンドツーエンドテストとしては十分すぎるほどです。
REST APIエンドツーエンドテスト
アプリケーションをテストする際にグラフィカルユーザーインターフェイスを回避することは、アプリケーションスタックの広い部分をカバーしながら、完全なエンドツーエンドテストよりも不安定性の低いテストを作成するための良いアイデアになる可能性があります。これは、アプリケーションのWebインターフェイスを介したテストが特に難しい場合に役立ちます。Web UIがなくてもREST APIを提供している場合(シングルページアプリケーションがそのAPIと通信しているため、または単に素晴らしいものがすべて嫌いなため)、グラフィカルユーザーインターフェイスのすぐ下をテストし、自信を損なうことなく非常に遠くまで到達できる皮下テストが役立ちます。私たちのサンプルコードのようにREST APIを提供している場合に最適です。
@RestController
public class ExampleController {
private final PersonRepository personRepository;
// shortened for clarity
@GetMapping("/hello/{lastName}")
public String hello(@PathVariable final String lastName) {
Optional<Person> foundPerson = personRepository.findByLastName(lastName);
return foundPerson
.map(person -> String.format("Hello %s %s!",
person.getFirstName(),
person.getLastName()))
.orElse(String.format("Who is this '%s' you're talking about?",
lastName));
}
}
REST APIを提供するサービスをテストする際に役立つライブラリをもう1つご紹介します。REST-assured は、APIに対して実際のHTTPリクエストを発行し、受信したレスポンスを評価するための優れたDSLを提供するライブラリです。
まず最初に、依存関係をbuild.gradleに追加します。
testCompile('io.rest-assured:rest-assured:3.0.3')
このライブラリを使用すると、REST APIのエンドツーエンドテストを実装できます。
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class HelloE2ERestTest {
@Autowired
private PersonRepository personRepository;
@LocalServerPort
private int port;
@After
public void tearDown() throws Exception {
personRepository.deleteAll();
}
@Test
public void shouldReturnGreeting() throws Exception {
Person peter = new Person("Peter", "Pan");
personRepository.save(peter);
when()
.get(String.format("https://:%s/hello/Pan", port))
.then()
.statusCode(is(200))
.body(containsString("Hello Peter Pan!"));
}
}
ここでも、@SpringBootTestを使用してSpringアプリケーション全体を起動します。この場合、PersonRepositoryを@Autowireして、テストデータをデータベースに簡単に書き込めるようにします。REST APIに「Mr Pan」への挨拶を依頼すると、素敵な挨拶が表示されます。素晴らしい!Webインターフェースを使用していない場合でも、エンドツーエンドテストとしては十分すぎるほどです。
受け入れテスト — 機能は正しく動作するか?
テストピラミッドを上に移動するほど、構築している機能がユーザーの観点から正しく機能するかどうかをテストする可能性が高くなります。アプリケーションをブラックボックスとして扱い、テストの焦点を次のように変更できます。
値xとyを入力すると、戻り値はzになります。
から
前提条件:ログインしているユーザーがいる
かつ「自転車」という記事がある
操作:ユーザーが「自転車」の記事の詳細ページに移動する
かつ「カートに追加」ボタンをクリックする
結果:「自転車」の記事がショッピングカートにある
このようなテストを機能テストまたは受け入れテストと呼ぶことがあります。機能テストと受け入れテストは異なるものであると言う人もいます。用語が混同されることもあります。言葉遣いや定義について延々と議論する人もいます。多くの場合、この議論は非常に大きな混乱の原因となります。
重要なのは、ある時点で、ソフトウェアが技術的な観点からだけでなく、ユーザーの観点から正しく機能することを確認する必要があるということです。これらのテストを何と呼ぶかはそれほど重要ではありません。ただし、これらのテストを用意することは重要です。用語を選び、それに固執し、それらのテストを作成します。
これは、人々がBDDと、BDD方式でテストを実装できるツールについて話すときでもあります。BDDまたはBDDスタイルのテスト作成方法は、実装の詳細からユーザーのニーズへと考え方を変えるための素晴らしいトリックです。試してみてください。
Cucumberのような本格的なBDDツールを採用する必要はありません(ただし、採用することもできます)。chai.jsなどの一部のアサーションライブラリでは、shouldスタイルのキーワードを使用してアサーションを作成できるため、テストをBDDのように読むことができます。この表記を提供するライブラリを使用していなくても、巧妙で適切にファクタリングされたコードを使用すると、ユーザーの行動に焦点を当てたテストを作成できます。いくつかのヘルパーメソッド/関数を使用すれば、非常に長い道のりを歩むことができます。
# a sample acceptance test in Python
def test_add_to_basket():
# given
user = a_user_with_empty_basket()
user.login()
bicycle = article(name="bicycle", price=100)
# when
article_page.add_to_.basket(bicycle)
# then
assert user.basket.contains(bicycle)
受け入れテストは、さまざまなレベルの粒度で提供できます。ほとんどの場合、それらはかなり高レベルであり、ユーザーインターフェイスを通じてサービスをテストします。ただし、技術的にはテストピラミッドの最高レベルで受け入れテストを作成する必要はないことを理解しておくことが重要です。アプリケーションの設計と手元のシナリオで、より低いレベルで受け入れテストを作成できる場合は、そうしてください。低レベルのテストを用意する方が、高レベルのテストを用意するよりも優れています。機能がユーザーにとって正しく機能することを証明するという受け入れテストの概念は、テストピラミッドとは完全に直交しています。
探索的テスト
最も熱心なテスト自動化の取り組みでさえ完璧ではありません。自動テストで特定のエッジケースを見逃してしまうことがあります。ユニットテストを作成することで特定のバグを検出することがほぼ不可能な場合があります。特定の品質問題は、自動テスト内では明らかになりません(設計や使いやすさを考えてみてください)。テスト自動化に関する最善の意図にもかかわらず、何らかの手動テストは依然として良い考えです。
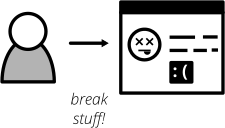
図12:探索的テストを使用して、ビルドパイプラインで見落とされたすべての品質問題を特定します。
テストポートフォリオに探索的テストを含めます。これは、実行中のシステムで品質問題を発見するためのテスターの自由と創造性を重視する手動テストアプローチです。定期的に時間を取り、袖をまくってアプリケーションを壊してみてください。破壊的な考え方を使用し、アプリケーションで問題やエラーを引き起こす方法を考え出します。見つかったものはすべて後で文書化します。バグ、設計上の問題、応答時間の遅延、欠落または誤解を招くエラーメッセージ、およびソフトウェアのユーザーとして気になるその他のすべてに注意してください。
良いニュースは、発見のほとんどを自動テストで自動化できることです。発見したバグの自動テストを作成すると、将来そのバグが再発しないようになります。さらに、バグ修正中にその問題の根本原因を絞り込むのに役立ちます。
探索的テスト中に、ビルドパイプラインに気づかれずにすり抜けた問題が見つかります。落胆しないでください。これは、ビルドパイプラインの成熟度に関する素晴らしいフィードバックです。他のフィードバックと同様に、必ず対応してください。将来これらの種類の問題を回避するために何ができるかを考えてください。特定の自動テストセットを見逃している可能性があります。この反復では自動テストがずさんだっただけで、将来的にはより徹底的にテストする必要があるかもしれません。将来これらの問題を回避するために、パイプラインで使用できる素晴らしい新しいツールやアプローチがあるかもしれません。必ず対応してください。そうすれば、パイプラインとソフトウェア配信全体は、長く続けるほど成熟していきます。
テスト用語に関する混乱
さまざまなテスト分類について話すのは常に困難です。私がユニットテストについて話すときの意味は、あなたの理解とは少し異なる場合があります。統合テストではさらに悪化します。一部の人々にとって、統合テストは、システム全体の多くの異なる部分をテストする非常に幅広いアクティビティです。私にとって、それはかなり狭いものであり、一度に1つの外部部分との統合のみをテストします。それらを統合テストと呼ぶ人もいれば、コンポーネントテストと呼ぶ人もいれば、サービステストという用語を好む人もいます。さらに、これら3つの用語はすべてまったく異なるものであると主張する人もいます。正しいか間違っているかはありません。ソフトウェア開発コミュニティは、テストに関する明確な用語に落ち着くことができていません。
曖昧な用語に固執しすぎるのはやめましょう。エンドツーエンドテスト、ブロードスタックテスト、機能テストなど、何と呼ぶかは問題ではありません。あなたの統合テストが、他の会社の担当者とは異なる意味を持つとしても、問題ありません。私たちの業界が明確に定義された用語に落ち着き、皆がそれに従うことができれば、本当に素晴らしいことです。残念ながら、これはまだ実現していません。また、テストの作成には多くのニュアンスがあるため、実際には、いくつかの個別のバケットではなく、スペクトルのようなものです。そのため、一貫した命名はさらに困難になります。
重要なのは、あなたとあなたのチームにとって有効な用語を見つけることです。作成するさまざまな種類のテストについて明確にしてください。チーム内で命名について合意し、各タイプのテストの範囲についてコンセンサスを得ます。チーム内(あるいは組織内でも)で一貫性を保つことができれば、それで十分です。 Simon Stewart氏は、Googleで使用しているアプローチを説明した際に、これを非常にうまくまとめています。そして、名前や命名規則に固執しすぎるのは、面倒なだけで価値がないことを完璧に示していると思います。
デプロイメントパイプラインへのテストの組み込み
継続的インテグレーションまたは継続的デリバリーを使用している場合は、ソフトウェアに変更を加えるたびに自動テストを実行するデプロイメントパイプラインが用意されています。通常、このパイプラインは、ソフトウェアが本番環境にデプロイできるという確信を徐々に高めるためのいくつかのステージに分割されます。これらのさまざまな種類のテストについて聞いたことがある方は、デプロイメントパイプライン内でそれらをどのように配置すべきか疑問に思っているかもしれません。これに対する答えは、継続的デリバリーの非常に基本的な価値(実際には、エクストリームプログラミングおよびアジャイルソフトウェア開発のコアバリューの1つ)である迅速なフィードバックについて考えることです。
優れたビルドパイプラインは、ミスをできるだけ早く教えてくれます。最新の変更によって単純な単体テストが失敗したことを知るために、1時間も待ちたくはありません。パイプラインがフィードバックを提供するまでにそれほど時間がかかる場合、おそらくあなたはすでに帰宅しているでしょう。高速に実行されるテストをパイプラインの初期段階に配置することで、この情報を数秒、あるいは数分で得ることができます。逆に、実行時間の長いテスト(通常は範囲の広いテスト)を後の段階に配置して、高速に実行されるテストからのフィードバックを遅らせないようにします。デプロイメントパイプラインのステージの定義は、テストの種類ではなく、速度と範囲によって決まることがわかります。それを念頭に置いて、非常に狭い範囲で高速に実行される統合テストの一部を単体テストと同じステージに配置することは、非常に合理的な決定となる可能性があります。これは、単に高速なフィードバックが得られるためであり、テストの正式な種類によって線を引くためではありません。
テストの重複を避ける
さまざまな種類のテストを作成する必要があることがわかったので、もう1つ避けるべき落とし穴があります。それは、ピラミッドのさまざまな層でテストを重複させることです。直感的には、テストが多すぎるということはないと思うかもしれませんが、実際にはあります。テストスイート内のすべてのテストは追加の負担であり、無料ではありません。テストの作成と保守には時間がかかります。他の人のテストを読んで理解するのにも時間がかかります。そしてもちろん、テストの実行にも時間がかかります。
本番コードと同様に、シンプルさを追求し、重複を避ける必要があります。テストピラミッドを実装する際には、次の2つの経験則を念頭に置いてください。
- 上位レベルのテストでエラーが発見され、下位レベルのテストが失敗していない場合は、下位レベルのテストを作成する必要があります。
- テストをできるだけテストピラミッドの下位にプッシュします。
最初のルールは重要です。なぜなら、下位レベルのテストでは、エラーをより絞り込み、分離して再現できるからです。これらのテストはより高速に実行され、問題をデバッグする際に肥大化しません。そして、将来の回帰テストとして役立ちます。2番目のルールは、テストスイートを高速に保つために重要です。下位レベルのテストですべての条件を確実にテストした場合は、上位レベルのテストをテストスイートに保持する必要はありません。すべてが機能しているという確信が高まるわけではありません。冗長なテストがあると、日々の作業で煩わしくなります。テストスイートの速度が低下し、コードの動作を変更するときに、より多くのテストを変更する必要があります。
別の言い方をしましょう。上位レベルのテストによってアプリケーションが正しく機能しているという確信が高まる場合は、そのテストを行う必要があります。`Controller`クラスの単体テストを作成すると、コントローラー自体のロジックをテストするのに役立ちます。それでも、このコントローラーが提供するRESTエンドポイントが実際にHTTPリクエストに応答するかどうかはわかりません。そのため、テストピラミッドを上に移動し、まさにそれをチェックするテストを追加します。それ以上のことはしません。下位レベルのテストで既に網羅されている条件付きロジックやエッジケースを、上位レベルのテストで再度テストすることはありません。上位レベルのテストでは、下位レベルのテストでは網羅できなかった部分に焦点を当てるようにしてください。
私は、価値を提供しないテストを排除することに関しては厳格です。下位レベルで既に網羅されている上位レベルのテストは削除します(追加の価値を提供しない場合)。可能であれば、上位レベルのテストを下位レベルのテストに置き換えます。時には、特にテストの作成に苦労したことがわかっている場合は、難しいこともあります。サンクコストの誤謬に注意して、削除キーを押してください。価値を提供しなくなったテストに貴重な時間を無駄にする理由はありません。
クリーンなテストコードを書く
一般的にコードを書くのと同様に、優れたクリーンなテストコードを作成するには、細心の注意が必要です。自動テストスイートをハッキングする前に、保守可能なテストコードを作成するためのヒントをいくつか紹介します。
- テストコードは本番コードと同じくらい重要です。同じレベルの注意と配慮を払いましょう。「これはテストコードに過ぎない」というのは、ずさんなコードを正当化する有効な言い訳ではありません。
- テストごとに1つの条件をテストします。これは、テストを短く、理解しやすくするのに役立ちます。
- 「準備、実行、アサーション」または「前提、時、結果」は、テストを適切に構造化するのに役立つニーモニックです。
- 読みやすさが重要です。過度にDRYになろうとしないでください。読みやすさが向上するのであれば、重複は問題ありません。 DRYとDAMP コードのバランスを見つけるようにしてください。
- リファクタリングする時期を決定する際には、3の法則を使用してください。再利用する前に使用する
結論
以上です!ソフトウェアをテストする理由と方法を説明するために、これは長く、難しい内容だったと思います。幸いなことに、この情報は非常に時代を超越しており、どのような種類のソフトウェアを構築しているかとは無関係です。マイクロサービス環境、IoTデバイス、モバイルアプリ、Webアプリケーションなど、どのようなものであっても、この記事の教訓はすべてに適用できます。
この記事が少しでも役に立てば幸いです。さあ、サンプルコードをチェックして、ここで説明した概念のいくつかをテストポートフォリオに取り入れてみてください。堅実なテストポートフォリオを構築するには、ある程度の努力が必要です。長期的には報われ、開発者としての生活がより平和なものになるでしょう。信じてください。
謝辞
この記事の初期の草稿にフィードバックと提案を提供してくれたClare Sudbery、Chris Ford、Martha Rohte、Andrew Jones-Weiss David Swallow、Aiko Klostermann、Bastian Stein、Sebastian Roidl、Birgitta Böckelerに感謝します。アドバイス、洞察、そしてサポートを提供してくれたMartin Fowlerに感謝します。
主な改訂
2018年2月26日:UIテストを含む記事を公開
2018年2月22日:コントラクトテストを含む記事を公開
2018年2月20日:統合テストを含む記事を公開
2018年2月15日:単体テストを含む記事を公開
2018年2月14日:ピラミッドとサンプルアプリケーションを紹介する最初の分割払い