
ドキュメントをロードするためのコードのリファクタリング
最近の多くのWebサーバーコードは、JSONデータを返すアップストリームサービスと通信し、そのJSONデータを少し修正して、流行のシングルページアプリケーションフレームワークを使用してリッチクライアントWebページに送信します。このようなシステムを使用している人々と話していると、これらのJSONドキュメントを操作するために必要な作業量に不満を感じているという話をよく聞きます。この不満の多くは、ロード戦略の組み合わせをカプセル化することで回避できる可能性があります。
2015年12月17日

JSON、XML、またはその他の階層的なデータであるかどうかにかかわらず、ドキュメントをロードするときは、プログラム内でどのように表現するかを選択する必要があります。ロードコードを自分で記述することはあまりありません。そのためのライブラリはたくさんありますが、それでもデータがどこに最終的に格納されるかを選択する必要があります。その選択は、データをどのように使用するかに基づく必要があります。しかし、すべてを複雑なオブジェクト構造にロードするプログラムによく遭遇し、その結果、最新の状態に保つのが面倒な不要なコードが作成されることがよくあります。
初期コード
いくつかの異なるアプローチを示すために、音楽アルバムのアソートメントに関する情報を提供するサンプルサービスを使用します。消費するデータは、次のようなものです。
{
"albums": [
{
"title": "Isla",
"artist": "Portico Quartet",
"tracks": [
{"title": "Paper Scissors Stone", "lengthInSeconds": 327},
{"title": "The Visitor", "lengthInSeconds": 330},
{"title": "Dawn Patrol", "lengthInSeconds": 359},
{"title": "Line", "lengthInSeconds": 449},
{"title": "Life Mask (Interlude)", "lengthInSeconds": 75},
{"title": "Clipper", "lengthInSeconds": 392},
{"title": "Life Mask", "lengthInSeconds": 436},
{"title": "Isla", "lengthInSeconds": 310},
{"title": "Shed Song (Improv No 1)", "lengthInSeconds": 503},
{"title": "Su-Bo's Mental Meltdown", "lengthInSeconds": 347}
]
},
{
"title": "Horizon",
"artist": "Eyot",
"tracks": [
{"title": "Far Afield", "lengthInSeconds": 423},
{"title": "Stone upon stone upon stone", "lengthInSeconds": 479},
{"title": "If I could say what I want to", "lengthInSeconds": 167},
{"title": "All I want to say", "lengthInSeconds": 337},
{"title": "Surge", "lengthInSeconds": 620},
{"title": "3 Months later", "lengthInSeconds": 516},
{"title": "Horizon", "lengthInSeconds": 616},
{"title": "Whale song", "lengthInSeconds": 344},
{"title": "It's time to go home", "lengthInSeconds": 539}
]
}
]
}
このサービスはJavaで記述されており、JSONを読み取るためにJacksonライブラリを使用しています。これを行う通常の方法は、一連のJavaクラスを定義し、Jacksonの優れたデータバインディング機能を使用して、JSONデータをクラスのフィールドにマッピングすることです。このデータを処理するには、これらのクラスが必要です。
class Assortment…
private List<Album> albums;
public List<Album> getAlbums() {
return Collections.unmodifiableList(albums);
}
class Album…
private String artist;
private String title;
private List<Track> tracks;
public String getArtist() {
return artist;
}
public String getTitle() {
return title;
}
public List<Track> getTracks() {
return Collections.unmodifiableList(tracks);
}
class Track…
private String title;
private int lengthInSeconds;
public String getTitle() {
return title;
}
public int getLengthInSeconds() {
return lengthInSeconds;
}
Jacksonはリフレクションを使用して、JSONデータを対応するJavaオブジェクトに自動的にマッピングします。このおかげで、オブジェクトをロードするためのコードを記述する必要はありません。ただし、JSONがロードされるオブジェクトを定義する必要があります。
パブリックフィールドまたはパブリックゲッターを持つプライベートフィールドを使用できます。ゲッターを使用するとコードが冗長になりますが、一様アクセス原則に従うのが好きなので、ゲッターを使用することを好みます。IntelliJがゲッターを書いてくれるので、さらに煩わしさが軽減されます。
このようにクラスを定義すると、JSONデータをロードするのは簡単なメソッド呼び出しになります
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
JSONデータは、dataSource.getAlbum(query)の呼び出しを介して何らかのデータソースから取得されます。これは、別のサービスへの呼び出し、JSON指向のデータベースへのアクセス、ファイルからの読み取り、または現時点では関係のないその他のソースである可能性があります。
class Json…
public static ObjectMapper mapper() {
JsonFactory f = new JsonFactory().enable(JsonParser.Feature.ALLOW_COMMENTS);
return new ObjectMapper(f);
}
JSONデータからオブジェクトをロードするコードを記述する必要はありませんが、オブジェクト定義を記述する必要があります。この場合はそれほど多くありませんが、JSONデータを表すために100個のクラスが必要なケースに遭遇したことがあります。これらのオブジェクトがあまり使用されていない場合は、このようなクラス定義を記述するのは煩わしい作業です。
正当化されるケースは、データバインディングで定義されたすべてのオブジェクトとメソッドを使用している場合です。したがって、10個のクラスと200個のパブリックメソッドを定義し、そのうち5個しか使用していない場合、それは何かが間違っている兆候です。代替案を検討するには、いくつかの異なるケースを見て、採用できるさまざまな代替ルートを検討する必要があります。
しかし、代替案が何であれ、私は同じ最初のステップから始めます。
アソートメントのカプセル化
リファクタリングを行うときは常に、適切なメソッドの背後に変更の大部分をカプセル化することで、変更の可視性をどのように低減できるかを確認します。アソートメントを扱っているので、これはアソートメントとJSONとの間でアソートメントを変換する責任をアソートメント自体に移動することを意味します。
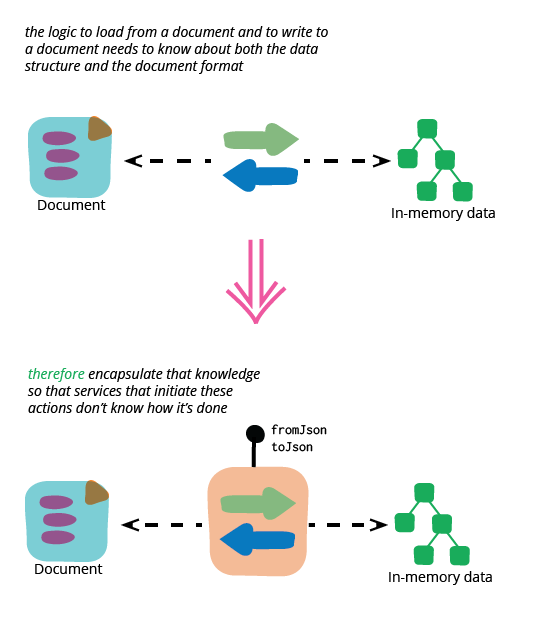
私は、アソートメントをロードするコードでメソッド抽出を使用してこれを開始します。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = loadAssortment(query);
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
private Assortment loadAssortment(String query) throws java.io.IOException {
return Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
}
私はチェック例外が好きではないので、デフォルトでは、醜い頭を出すとすぐにランタイム例外でそれらをラップします。
class Service…
private Assortment loadAssortment(String query) {
try {
return Json.mapper().readValue(dataSource.getAlbumList(query), Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
新しいメソッドにJSONデータの文字列を取得させたいので、新しいメソッドの引数を調整します。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = loadAssortment(dataSource.getAlbumList(query));
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
private Assortment loadAssortment(String json) {
try {
return Json.mapper().readValue(json, Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
動作がうまく抽出されたら、ファクトリメソッドとしてアソートメントクラスに移動できます。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Assortment.fromJson(dataSource.getAlbumList(query));
return Json.mapper().writeValueAsString(data);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
class Assortment…
public static Assortment fromJson(String json) {
try {
return Json.mapper().readValue(json, Assortment.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
IntelliJのメソッド移動リファクタリングを使用してこれを行うことはできませんでしたが、手動で行うのは簡単でした。
JSONを出力するコードを抽出して移動するために、同じ一連の手順を使用しました。
class Service…
public String tuesdayMusic(String query) {
try {
Assortment data = Assortment.fromJson(dataSource.getAlbumList(query));
return data.toJson();
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
class Assortment…
public String toJson() {
try {
return Json.mapper().writeValueAsString(this);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
このようにアソートメントを使用していた他のサービスメソッドがある場合は、これらの新しいメソッドを使用するようにすべての呼び出しを調整します。完了したら、シリアル化のメカニズムをカプセル化するオブジェクトがあり、変更がはるかに簡単になります。
カプセル化の本質は、設計上の決定を秘密に変えることです
「シリアル化のメカニズムをカプセル化する」というフレーズを使用したことを奇妙に思う人もいるかもしれません。オブジェクト指向について教えられるとき、データはカプセル化されているとよく言われるため、このように動作をカプセル化する必要があるものとして考えるのは奇妙に聞こえるかもしれません。ただし、カプセル化の重要な点は、動作またはデータ構造の選択である可能性のある決定を、カプセル化境界の背後で何が起こっているのかを知る必要のない外部から隠された秘密に変えることです。この場合、アソートメントの外側のコードがアソートメントとJSONの関係を知っていることを望まないため、ロードを行うコードをアソートメントクラス内にカプセル化します。
JSONの受け渡し
アソートメントのJSON処理をカプセル化したので、使用方法に応じてリファクタリングできるさまざまな方法を検討できます。
最も単純なケースは、サービスがアソートメントに提供されたJSONと同じJSONのみを必要とする場合です。この場合、JSON文字列自体をアソートメントに格納し、jacksonをまったく使用しないようにすることができます。
class Assortment…
private String json;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
result.json = json;
return result;
}
public String toJson() {
return json;
}
その後、アルバムとトラックのクラスを完全に削除できます。
実際、この場合はアソートメントクラスを完全に削除し、サービスがデータソース呼び出しの結果を直接返すだけです。
class Service…
public String tuesdayMusic(String query) {
try {
return dataSource.getAlbumList(query);
} catch (Exception e) {
log(e);
throw new RuntimeException(e);
}
}
内部クライアント
次に、サーバープロセスに、JSONデータから収集された情報の一部を必要とするクライアントがあるケースを検討します。
class SomeClient…
public List<String> doSomething(Assortment anAssortment) {
List<String> titles = anAssortment.getAlbums().stream()
.map(a -> a.getTitle())
.collect(Collectors.toList());
return somethingCleverWith(titles);
}
このケースでは、JavaコードでJSONデータを操作する必要があるため、文字列以上のものが必要です。ただし、これが唯一のクライアントである場合は、前に示したオブジェクトツリー全体を構築する必要はありません。代わりに、次のようなJavaクラスを持つことができます。
class Assortment…
private List<Album> albums;
public List<Album> getAlbums() {
return Collections.unmodifiableList(albums);
}
class Album…
private String title;
public String getTitle() {
return title;
}
トラッククラスを完全に削除できます。
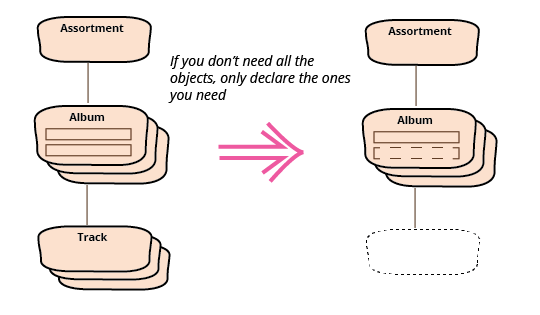
JSONデータの一部のみが必要な場合は、すべてをインポートする意味がありません。データバインディングを介して必要なビットのみを指定することは、このように削減されたデータセットを取得する非常に優れた方法です。このようなデータバインディングを使用するライブラリには、データバインディングがターゲットレコードにバインディングがないJSONのフィールドをどのように処理するかを示す構成パラメーターが通常あります。デフォルトでは、JacksonはUnrecognizedPropertyExceptionをスローしますが、次のような呼び出しでFAIL_ON_UNKNOWN_PROPERTIES機能を無効にすることで、簡単に変更できます
anObjectMapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)
必要なプロパティのみを持つクラス構造を宣言することで、不要な労力を避けることができます。プロパティを宣言する行為は、必要なフィールドを選ぶのと同じくらい良い方法です。
これは、別のJavaクラスがJava API呼び出しでアソートメントのアルバムタイトルを取得したい場合の例です。同様の例として、クライアントがJSONデータの一部を必要とする場合があり、通常のtoJson呼び出しではアルバムタイトルのみが返されるようになります。
{"albums":[
{"title":"Isla"},
{"title":"Horizon"}
]}
入力ドキュメントからデータの一部のみを使用している場合、通常は使用しているデータのみに依存するように整理するのが最善です。マッピングする完全なオブジェクト構造を定義すると、サプライヤーが安全に無視できるフィールドをJSONに追加した場合に、コードが壊れてしまいます。使用する構造のみを定義することで、寛容なリーダーを作成し、入力データの変更に対するプログラムの回復力を高めます。
Java APIと完全なJSON
これは当然ながら、3番目のケース、つまりサービス呼び出しで完全なJSONドキュメントを返したいが、同時にJava APIを通じてアルバムタイトルのリストを取得したい場合はどうするか、という疑問につながります。
このケースに対する答えは、前の2つのケースの組み合わせで、元のJSON文字列と、APIに必要なJavaオブジェクトの両方を保存します。したがって、このケースでは、文字列をファクトリーメソッドに追加します。
class Assortment…
private String doc;
public static Assortment fromJson(String json) {
try {
final Assortment result = Json.mapper()
.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)
.readValue(json, Assortment.class);
result.doc = json;
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public String toJson() {
return doc;
}
それが完了したら、Java APIのみを使用した場合と同様に、不要なメソッドとクラスをJavaデータ構造から削除できます。
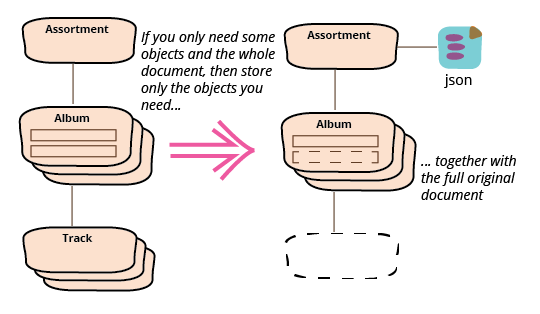
出力JSONドキュメントのエンリッチメント
ここまでのシナリオでは、JSONドキュメントを必要な情報の完全なキャリアとして扱ってきましたが、サーバープロセスを使用して情報を充実させることもあります。各アルバムの長さに関する情報が必要な場合を考えてみましょう。完全なオブジェクト構造を使用すると、これは簡単です。
class Album…
public int getLengthInSeconds() {
return tracks.stream().collect(Collectors.summingInt(Track::getLengthInSeconds));
}
このメソッドは、Javaメソッド呼び出しを使用してJavaクライアントに情報を提供すると同時に、jacksonのデータバインディングを使用して出力JSONを作成するときに、自動的にJSON出力に追加します。唯一の問題は、これにより、JSON構造全体をJavaクラスとして宣言する必要があることです。この小さな例では大きな問題ではありませんが、数百または数千もの不要なクラス定義がある場合は問題になります。ドキュメントモデルを使用および充実させることで、これを回避できます。
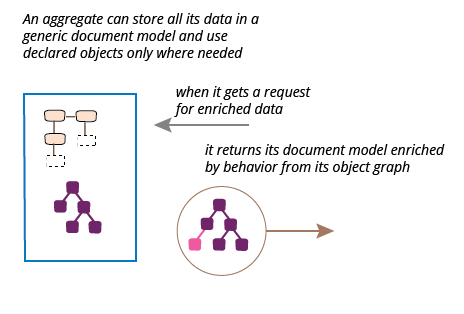
完全なクラス定義セットとアルバムの長さのメソッドという、元の開始点からリファクタリングを開始します。最初のステップは、前の例と同様に、読み取り時に追加のJSONドキュメントを追加することです。ただし、今回はJacksonツリーモデルとして読み取り、出力コードはまだ変更しません。
class Assortment…
private List<Album> albums; private JsonNode doc; public List<Album> getAlbums() { return Collections.unmodifiableList(albums); } public static Assortment fromJson(String json) { try { final Assortment result = Json.mapper().readValue(json, Assortment.class); result.doc = Json.mapper().readTree(json); return result; } catch (IOException e) { throw new RuntimeException(e); } } public String toJson() { try { return Json.mapper().writeValueAsString(this); } catch (JsonProcessingException e) { throw new RuntimeException(e); } }
次のステップは、間もなく充実されるJSONドキュメントモデルを出力するメソッドを作成することです。まず、単純なアクセサーから始め、現在のドキュメントを出力することを確認します。
class Assortment…
public String enrichedJson() {
return doc.toString();
}
class Tester…
@Test
public void enrichedJson() throws Exception {
JsonNode expected = Json.mapper().readTree(new File("src/test/enrichedJson.json"));
JsonNode actual = Json.mapper().readTree(getAssortment().enrichedJson());
assertEquals(expected, actual);
}
今のところ、テストでは出力ドキュメントが入力と同じであることを確認するだけですが、これで、出力に徐々にステップを追加できるフックができました。ここでは1つだけなので大したことではありませんが、ドキュメントにいくつかの充実化がある場合は、そのようなテストで一度に1つずつ追加できます。
それでは、充実化コードを設定する時が来ました。
class Assortment…
public String enrichedJson() {
JsonNode result = doc.deepCopy();
getAlbums().forEach(a -> a.enrichJson(result));
return result.toString();
}
class Album…
public void enrichJson(JsonNode parent) {
final ObjectNode albumNode = matchingNode(parent);
albumNode.put("lengthInSeconds", getLengthInSeconds());
}
private ObjectNode matchingNode(JsonNode parent) {
final Stream<JsonNode> albumNodes = StreamSupport.stream(parent.path("albums").spliterator(), false);
return (ObjectNode) albumNodes
.filter(n -> n.path("title").asText().equals(title))
.findFirst()
.get()
;
}
充実化の基本的なアプローチは、Javaレコードをトラバースし、それぞれに対応するツリーノードを充実化するように要求することです。
一般的に、可能な限りコレクションパイプラインを使用することを好みますが、StreamSupportとspliteratorに関するすべての処理は非常に面倒です。できれば、時間の経過とともにJacksonがストリームを直接サポートし、これを行う必要がなくなることを願っています。
アソートメントに埋め込まれたドキュメントを変更するのではなく、新しいドキュメントを作成することを好みます。一般的に、データは読み取り時のままにして、必要に応じて更新することを好みます。新しいJSONドキュメントを構築するコストが高い場合は、常に結果をキャッシュできます。
多数の充実化がある場合は、このメカニズムを使用して一度に1つずつ追加し、変更ごとに新しいデータをテストできます。それが完了したら、データバインドされた出力を充実化されたドキュメントに交換できます。
class Assortment…
public String toJson() {
JsonNode result = doc.deepCopy();
getAlbums().forEach(a -> a.enrichJson(result));
return result.toString();
}
それが完了したら、クラス構造を意気揚々と刈り込み、未使用のデータ、メソッド、およびクラスという、今や無用の長物となったものをすべて削除できます。この例ではそれほど多くはありませんが、このようにしてコードから37個のクラスを削除するのは楽しいものです。
ツリーモデルのみの使用
ツリーモデルを充実化の基礎として使用することで、Javaクラス宣言からさらに削除できます。このアプローチでは、ドキュメントのツリーをたどるだけで、ドメインオブジェクトをまったく関与させずに充実化を行います。この場合、充実化コードは次のようになります。
class Assortment…
public String toJson() {
JsonNode result = doc.deepCopy();
enrichDoc(result);
return result.toString();
}
private void enrichDoc(JsonNode doc) {
for(JsonNode n : doc.path("albums")) enrichAlbum((ObjectNode)n);
}
private void enrichAlbum(ObjectNode albumNode) {
int length = 0;
for (JsonNode n : albumNode.path("tracks")) length += n.path("lengthInSeconds").asInt();
albumNode.put("lengthInSeconds", length);
}
この種のコードは、動的言語でリストとハッシュを操作することに慣れている人にはおなじみのはずです。しかし、全体として、私はこれをJavaで好んで使用しません。Javaオブジェクトを持ち、使用することが、一般的に動作を配置するのに最適な場所です。特に、その規模と複雑さが増すにつれて。
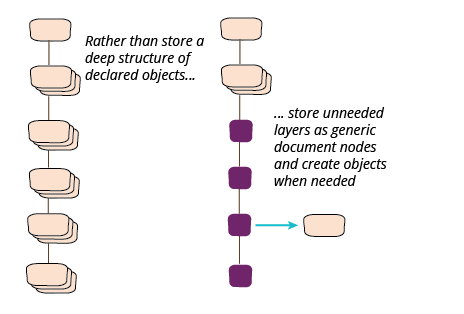
ただし、このスタイルを使用する例外が1つあります。それは、そうでなければ不要なクラスのレイヤーを通して階層をナビゲートする多くのレイヤーがある場合です。ただし、そこでは、下位レベルのノードのみを使用してオブジェクトを作成する傾向があるでしょう。
ドキュメント構造の深い場所にオブジェクトを作成する
表現するために多くのクラスが必要となるような大きなドキュメントがあり、そのほとんどが不要だが、ツリーの葉に近い場所にいくつかの重要なものがある場合はどうなるでしょうか?アルバムタイトルのリストに関する前の例では、JSONデータの一部にデータバインディングすることでそれらをサポートし、トラックを削減できました。しかし、もっと下にあるものが欲しい場合はどうでしょうか?
私の例では、トラックのリストが必要なクライアントを想像してみましょう。トラックとアソートメントの間にはアルバムクラスしかないので、データバインディングでそのケースを処理します。しかし、途中に12個の不要なレイヤーがあると仮定しましょう。その場合はどうすればよいでしょうか?
そのような状況では、これらのレイヤーをすべてデータバインディングすることを避けたいのですが、クライアントには適切なオブジェクトが必要です。これをどのように処理するかを示すために、これまでのところ、クライアントはJSON文字列全体のみを必要としていると仮定し、以前のリファクタリングパスに従い、アソートメントにはそれのみを格納します。
class Assortment…
private String json;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
result.json = json;
return result;
}
public String toJson() {
return json;
}
それは良いことです。問題に対する適切な最小限のソリューションです。しかし、その後、ドキュメント上で新しいJava APIを必要とする新しい機能が得られます。
class SomeClient…
public String doSomething(Assortment anAssortment) {
final List<Track> tracks = anAssortment.getTracks();
return somethingCleverWith(tracks);
}
繰り返しますが、このドキュメントの場合、データバインディングに切り替えるだけですが、代わりに、アソートメントとトラックの間に1つのアルバムクラスではなく、実際には12個の要素があり、データバインディングを思いとどまらせるのに十分な数であるという前提を維持します。
ドキュメントツリーを使用したいので、最初のステップは、文字列からツリーにリファクタリングすることです。
class Assortment…
private JsonNode doc;
public static Assortment fromJson(String json) {
Assortment result = new Assortment();
try {
result.doc = Json.mapper().readTree(json);
} catch (IOException e) {
throw new RuntimeException(e);
}
return result;
}
public String toJson() {
return doc.toString();
}
この準備的なリファクタリングが完了したら、トラックを作成することを検討できます。これを行うには、トラックノードのみを選択し、トラックノードをソースとしてデータバインディングを使用します。
class Assortment…
public List<Track> getTracks() {
return StreamSupport.stream(doc.path("albums").spliterator(), false)
.map(a -> a.path("tracks"))
.flatMap(i -> StreamSupport.stream(i.spliterator(), false))
.map(Track::fromJson)
.collect(Collectors.toList())
;
}
class Track…
private String title;
private int lengthInSeconds;
public String getTitle() {
return title;
}
public int getLengthInSeconds() {
return lengthInSeconds;
}
public static Track fromJson (JsonNode node) {
try {
return Json.mapper().treeToValue(node, Track.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
単一のレコードでこれを示しましたが、小さなサブツリーでも同じように簡単に行うことができ、大きなドキュメントから重要な情報を少しずつ抜き出すことができます。このアプローチは、ドキュメントのより深刻な再構築を行う場合に便利です。これらの種類のローカルAPIをデータソースとして使用して、適切な出力表現にシリアル化できる出力データ転送オブジェクトを構築できます。
完全なデータバインドモデルから同様のリファクタリングを行うこともできます。
まとめ
プログラミング作業の大部分は、階層的なデータのドキュメントを通じて入ってくるデータの操作と処理にあります。この情報を処理する方法がいくつかあり、コードベースを小さく柔軟に保つために適切な組み合わせを選択することを覚えておくとよいでしょう。人々がカプセル化とはデータ構造と処理メソッドを隠すことを意味することを忘れがちであり、モジュールのインターフェイスがその内部ストレージに対応していると期待すべきではありません。
謝辞
同僚のカールライル・デイビス、クリス・バーチ、ピーター・ホジソンが、この記事の草稿を作成中に私と議論しました。
重要な改訂
2015年12月17日:最初の最終版を公開
2015年12月15日:出力JSONの充実化セクションを公開
2015年12月14日:最初の版を公開