
ループとコレクションパイプラインを用いたリファクタリング
ループはコレクションを処理する古典的な方法ですが、プログラミング言語で第一級関数がより多く採用されるようになるにつれて、コレクションパイプラインは魅力的な代替手段となっています。この記事では、一連の小さな例を用いて、ループをコレクションパイプラインにリファクタリングする方法を検討します。
2015年7月14日

プログラミングにおける一般的なタスクは、オブジェクトのリストを処理することです。ほとんどのプログラマーは、最初のプログラムで学ぶ基本的な制御構造の1つであるため、当然のことながらループを使用してこれを行います。しかし、ループはリスト処理を表す唯一の方法ではなく、近年では、私がコレクションパイプラインと呼ぶ別のアプローチを利用する人が増えています。このスタイルは、しばしば関数型プログラミングの一部と見なされますが、Smalltalkで多用していました。OO言語がラムダと第一級関数をより簡単にプログラミングできるライブラリをサポートするようになると、コレクションパイプラインは魅力的な選択肢になります。
単純なループをパイプラインにリファクタリングする
ループの簡単な例から始めて、ループをコレクションパイプラインにリファクタリングする基本的な方法を紹介します。
それぞれが次のデータ構造を持つ著者のリストがあるとします。
class Author...
public string Name { get; set; }
public string TwitterHandle { get; set;}
public string Company { get; set;}
この例ではC#を使用しています
これがループです。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
foreach (Author a in authors) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
ループをコレクションパイプラインにリファクタリングする最初のステップは、ループコレクションに
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors;
foreach (Author a in loopStart) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
この変数は、パイプライン操作の開始点となります。今のところ良い名前がないので、後で名前を変更することを期待して、今のところ意味のある名前を使用します。
次に、ループ内の動作の一部を見ていきます。最初に目にするのは条件チェックです。これをフィルタ操作を使用してパイプラインに移動できます。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company);
foreach (Author a in loopStart) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
ループの次の部分は著者ではなくTwitterハンドルで動作していることがわかるので、マップ操作 [2]を使用できます。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle);
foreach (string handle in loopStart) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
return result;
}
ループの次に別の条件があるので、これもフィルタ操作に移動できます。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
foreach (string handle in loopStart) {
if (handle != null)
result.Add(handle);
}
return result;
}
これでループが行うことは、ループコレクション内のすべてを結果コレクションに追加することだけなので、ループを削除してパイプラインの結果を返すことができます。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
return authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
foreach (string handle in loopStart) {
result.Add(handle);
}
return result;
}
これがコードの最終状態です
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
}
コレクションパイプラインの良い点は、リストの要素がパイプラインを通過する際のロジックの流れを見ることができることです。私にとっては、ループの結果を定義する方法と非常によく似ています。「著者を取得し、会社を持っている著者を選択し、nullハンドルを削除してTwitterハンドルを取得する」。
さらに、このスタイルのコードは、異なる構文と異なるパイプライン演算子の名前を持つ異なる言語でもなじみがあります。[3]
Java
public List<String> twitterHandles(List<Author> authors, String company) {
return authors.stream()
.filter(a -> a.getCompany().equals(company))
.map(a -> a.getTwitterHandle())
.filter(h -> null != h)
.collect(toList());
}
Ruby
def twitter_handles authors, company
authors
.select {|a| company == a.company}
.map {|a| a.twitter_handle}
.reject {|h| h.nil?}
end
これは他の例と一致していますが、最後のrejectをcompactに置き換えます
Clojure
(defn twitter-handles [authors company]
(->> authors
(filter #(= company (:company %)))
(map :twitter-handle)
(remove nil?)))
F#
let twitterHandles (authors : seq<Author>, company : string) =
authors
|> Seq.filter(fun a -> a.Company = company)
|> Seq.map(fun a -> a.TwitterHandle)
|> Seq.choose (fun h -> h)
ここでも、他の例の構造と一致させることを気にしない場合は、mapとchooseを1つのステップにまとめます
パイプラインの観点から考えることに慣れると、なじみのない言語でもすぐに適用できることがわかりました。基本的なアプローチが同じなので、なじみのない構文や関数名からでも比較的簡単に変換できます。
パイプライン内、および内包表記へのリファクタリング
動作がパイプラインとして表現されると、パイプラインの手順を並べ替えることによって実行できる潜在的なリファクタリングがあります。そのような移動の1つは、マップの後にフィルタがある場合、通常、次のようにマップの前にフィルタを移動できることです。
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company)
.Where (a => a.TwitterHandle != null)
.Select(a => a.TwitterHandle);
}
隣接する2つのフィルタがある場合は、接続詞を使用してそれらを組み合わせることができます。[4]
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company && a.TwitterHandle != null)
.Select(a => a.TwitterHandle);
}
C#コレクションパイプラインをこのような単純なフィルタとマップの形式にすると、Linq式に置き換えることができます
class Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return from a in authors where a.Company == company && a.TwitterHandle != null select a.TwitterHandle;
}
Linq式はリスト内包表記の一種と考えており、同様に、リスト内包表記をサポートする言語であれば、このようなことができます。リスト内包表記形式とパイプライン形式のどちらを好むかは好みの問題です(私はパイプラインを好みます)。一般に、パイプラインはより強力です。すべてのパイプラインを内包表記にリファクタリングできるわけではありません。
ネストされたループ - 書籍の読者
2番目の例として、単純な二重ネストループをリファクタリングします。読者が本を読ることができるオンラインシステムがあると仮定します。特定の日に各読者がどの本を読んだかを教えてくれるデータサービスがあります。このサービスは、キーが読者の識別子であり、値が書籍の識別子のコレクションであるハッシュを返します
interface DataService…
Map<String, Collection<String>> getBooksReadOn(Date date);
この例では、先頭が大文字のメソッド名にうんうんざりしているので、Javaに切り替えます
これがループです
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
for (Map.Entry<String, Collection<String>> e : data.entrySet()) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey())) {
result.add(e.getKey());
}
}
}
return result;
}
いつもの最初のステップであるループコレクションに
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet();
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey())) {
result.add(e.getKey());
}
}
}
return result;
}
このような動きをするたびに、IntelliJの自動リファクタリングのおかげで、その厄介な型式をタイプする必要がなくなるので、とても嬉しいです。
初期コレクションを変数に格納したら、ループの動作の要素に取り組むことができます。すべての作業は条件内で行われているため、その条件の2番目の句から始めて、そのロジックをフィルタに移動します。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey()))) {
result.add(e.getKey());
}
}
}
return result;
}
Javaのストリームライブラリでは、パイプラインはターミナル(コレクターなど)で終了する必要があります
もう一方の句は、内部ループ変数を参照しているため、移動するのがより複雑です。この句は、マップエントリの値に、メソッドパラメーターの書籍のリストにも含まれる書籍が含まれているかどうかをテストしています。これは、集合の共通部分を使用することで実行できます。Javaのコアクラスには、集合の共通部分メソッドは含まれていません。GuavaやApache Commonsなど、Javaの一般的なコレクション指向アドインの1つを使用することで対処できます。これは単純な教育的な例なので、簡単な実装を記述します。
class Utils...
public static <T> Set<T> intersection (Collection<T> a, Collection<T> b) {
Set<T> result = new HashSet<T>(a);
result.retainAll(b);
return result;
}
これはここでは機能しますが、重要なプロジェクトの場合は、共通ライブラリを使用します。
これで、句をループからパイプラインに移動できます。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) ) {
result.add(e.getKey());
}
}
}
return result;
}
これでループが行うことはマップエントリのキーを返すことだけなので、マップ操作をパイプラインに追加することでループの残りの部分を削除できます
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
result = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.map(e -> e.getKey())
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
result.add(e.getKey());
}
}
return result;
}
次に、resultで一時変数のインライン化を使用できます。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
return data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.map(e -> e.getKey())
.collect(Collectors.toSet());
return result;
}
共通部分の使用方法を見ると、かなり複雑で、読むときに何をしているのかを理解する必要があります。つまり、抽出する必要があります。[5]
class Utils...
public static <T> boolean hasIntersection(Collection<T> a, Collection<T> b) {
return !intersection(a,b).isEmpty();
}
class Service...
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
return data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> Utils.hasIntersection(e.getValue(), books))
.map(e -> e.getKey())
.collect(Collectors.toSet());
}
オブジェクト指向のアプローチは、このようなことをする必要がある場合に不利になります。静的ユーティリティメソッドとオブジェクトの通常のメソッドを切り替えるのは面倒です。一部の言語では、ストリームクラスのメソッドのように読ませる方法がありますが、Javaにはそのオプションがありません。
この問題にもかかわらず、パイプラインバージョンの方が理解しやすいと思います。フィルターを単一の接続詞に組み合わせることはできますが、通常は各フィルターを単一の要素として理解する方が簡単です。
機器の提供
次のビットの例では、いくつかの簡単な基準を使用して、特定の地域向けの推奨機器をマークします。何をしているのかを理解するには、ドメインモデルを説明する必要があります。さまざまな地域で機器を利用できるようにする組織があります。機器をリクエストすると、必要なものを正確に手に入れることができる場合がありますが、多くの場合、代用品を提供されることになります。代用品は、必要なことはほとんどできますが、それほど優れていない場合があります。かなり無理な例を挙げると、ボストンにいて除雪機が必要ですが、店にない場合は、代わりに雪かきを提供される場合があります。ただし、マイアミにいる場合は、除雪機は提供されていないため、入手できるのは雪かきだけです。データモデルは、3つのクラスを通じてこれをキャプチャします。
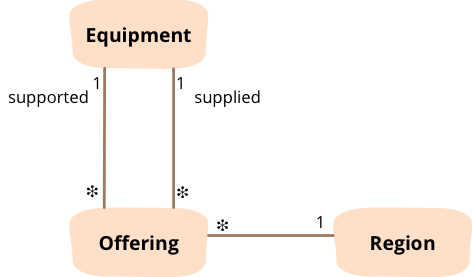
図1:提供の各インスタンスは、特定の種類の機器が地域で提供されて、ある種類の機器のニーズをサポートしているという事実を表しています。
そのため、次のようなデータが表示される場合があります
products: ['snow-blower', 'snow-shovel']
regions: ['boston', 'miami']
offerings:
- {region: 'boston', supported: 'snow-blower', supplied: 'snow-blower'}
- {region: 'boston', supported: 'snow-blower', supplied: 'snow-shovel'}
- {region: 'miami', supported: 'snow-blower', supplied: 'snow-shovel'}
これから見ていくコードは、これらのオファリングの一部を推奨としてマークするコードです。つまり、このオファリングは、地域のある機器の推奨オファリングです。
class Service...
var checkedRegions = new HashSet<Region>();
foreach (Offering o1 in equipment.AllOfferings()) {
Region r = o1.Region;
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
この例はC#です。なぜなら、私は優柔不断だからです。
私の疑いでは、このループが何をしているのかについては、簡単に理解できるロジックがあります。リファクタリングすることで、うまくいけばそのロジックを表面化できるはずです。
最初のステップは、外側のループから始めて、初期ループ変数に
class Service...
var loopStart = equipment.AllOfferings(); var checkedRegions = new HashSet<Region>(); foreach (Offering o1 in loopStart) { Region r = o1.Region; if (checkedRegions.Contains(r)) { continue; } Offering possPref = null; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break; } else { if (o2.isMatch || possPref == null) { possPref = o2; } } } possPref.isPreferred = true; checkedRegions.Add(r); }
次に、ループの最初の部分を見ていきます。制御変数checkedRegionsがあり、ループはこれを使用して、すでに処理された地域を追跡し、同じ地域を複数回処理しないようにします。それはまさににおいますが、ループ変数o1は地域rに到達するための中継ぎにすぎないことも示唆しています。エディターでo1を強調表示することで、それを確認します。それがわかったら、マップでこれを簡略化できることがわかります。
class Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region);
var checkedRegions = new HashSet<Region>();
foreach (Region r in loopStart) {
Region r = o1.Region;
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
これで、checkedRegions制御変数について説明できます。ループはこれを使用して、地域を複数回処理しないようにします。地域のチェックが冪等かどうかはまだわかりません。冪等であれば、このチェックを完全に回避できるかもしれません(そして、パフォーマンスに大きな影響があるかどうかを測定します)。わからないので、特にパイプラインで重複を回避するのは簡単なので、そのロジックを保持することにしました。
class Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
var checkedRegions = new HashSet<Region>();
foreach (Region r in loopStart) {
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
次のステップは、possPref変数を決定することです。これは独自のメソッドとして扱う方が簡単だと思うので、メソッドの抽出を適用します
class Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
foreach (Region r in loopStart) {
var possPref = possiblePreference(equipment, r);
possPref.isPreferred = true;
}
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
foreach (var o2 in equipment.AllOfferings(region)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
ループコレクションを変数に抽出します。
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
ループが独自の関数になったので、breakではなくreturnを使用できます。
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
return o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
最初の条件は、条件に合格する最初のオファリング(存在する場合)を探しています。それは検出操作(C#ではFirstと呼ばれます)の仕事です。[6]
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
return o2;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
最後の条件は少しトリッキーです。 possPref をリストの最初の要素に設定しますが、いずれかの要素が isMatch テストに合格した場合、その値は上書きされます。しかし、ループは isMatch の成功で中断されないため、後続の isMatch を満たす要素は、その一致を上書きします。そのため、この動作を複製するには、LastOrDefault を使用する必要があります。 [7]
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
possPref = allOfferings.LastOrDefault(o => o.isMatch);
if (null != possPref) return possPref;
foreach (var o2 in allOfferings) {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
return possPref;
}
ループの残りの最後の部分は、最初の項目を返すだけです。
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
possPref = allOfferings.LastOrDefault(o => o.isMatch);
if (null != possPref) return possPref;
return allOfferings.First();
foreach (var o2 in allOfferings) {
if (possPref == null) {
possPref = o2;
}
}
return possPref;
}
私の個人的な慣習では、関数内の戻り値に使用される変数の名前には result を使用するため、名前を変更します。
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering result = null;
var allOfferings = equipment.AllOfferings(region);
result = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != result) return result;
result = allOfferings.LastOrDefault(o => o.isMatch);
if (null != result) return result;
return allOfferings.First();
}
possiblePreference にはかなり満足しています。ドメイン内で意味のある方法でロジックを明確に示していると思います。コードの意図を理解するために、コードが何をしているのかを理解する必要がなくなりました。
しかし、C# を使用しているので、null 合体演算子(??)を使用して、さらに読みやすくすることができます。これにより、複数の式を連結し、null でない最初の式を返すことができます。
class Service...
static Offering possiblePreference(Equipment equipment, Region region) {
var allOfferings = equipment.AllOfferings(region);
return allOfferings.FirstOrDefault(o => o.isPreferred)
?? allOfferings.LastOrDefault(o => o.isMatch)
?? allOfferings.First();
}
null を偽の値として扱う、厳密に型指定されていない言語では、「or」演算子を使用して同じことを行います。別の方法としては、ファーストクラス関数を構成する方法があります(ただし、これはまったく別のトピックです)。
それでは、現在はこのように見える外側のループに戻りましょう。
class Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
foreach (Region r in loopStart) {
var possPref = possiblePreference(equipment, r);
possPref.isPreferred = true;
}
パイプラインで possiblePreference を使用できます。
class Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
;
foreach (Offering o in loopStart) {
var possPref = possiblePreference(product, r);
o.isPreferred = true;
}
セミコロンを単独の行に配置するスタイルに注意してください。長いパイプラインでは、パイプラインの操作が容易になるため、よくこれを行います。
最初のループ変数の名前を変更すると、結果は明確に読み取れます。
class Service...
var preferredOfferings = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
;
foreach (Offering o in preferredOfferings) {
o.isPreferred = true;
}
この状態のままでも問題ありませんが、forEach の動作を次のようにパイプラインに移動することもできます。
class Service...
equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
.ToList()
.ForEach(o => o.isPreferred = true)
;
これは、より議論の余地のある手順です。多くの人は、パイプラインで副作用のある関数を使用することを好みません。そのため、ForEach は IEnumerable では使用できないため、中間的な ToList を使用する必要があります。副作用に関する問題に加えて、ToList を使用すると、副作用を使用するたびにパイプの評価における遅延性も失われることがわかります(これは、パイプの目的全体が変更のためにいくつかのオブジェクトを選択することであるため、ここでは問題になりません)。
いずれにせよ、元のループよりもはるかに明確であることがわかります。以前のループの例は、追跡するにはかなり明確でしたが、これは何をしているのかを理解するために少し考える必要がありました。確かに possiblePreference を抽出することは、それを明確にするための大きな要因であり、ループを保持しながらそれを行うことができますが、重複する領域を回避するためにロジックをいじくり回すことは避けたいでしょう。
フライト記録のグループ化
この例では、フライトの遅延情報を要約するコードを見ていきます。コードは、定刻飛行性能の記録から始まり、元々は米国運輸省の 運輸統計局 から提供されています。いくつかの予備的な調整の後、結果のデータは次のようになります
[
{
"origin":"BOS","dest":"LAX","date":"2015-01-12",
"number":"25","carrier":"AA","delay":0.0,"cancelled":false
},
{
"origin":"BOS","dest":"LAX","date":"2015-01-13",
"number":"25","carrier":"AA","delay":0.0,"cancelled":false
},
…
これがそれを処理するループです
export function airportData() {
const data = flightData();
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++ ;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]);
result[i].cancellationRate = cancellations[i] / count[i];
}
return result;
}
この例では、最近はすべてがJavascriptで記述する必要があるため、Javascript(node上のes6)を使用しています。
ループは、目的地の空港(dest)別にフライトデータを要約し、キャンセル率と平均遅延を計算します。ここでの主要なアクティビティは、フライトデータを目的地別にグループ化することであり、これはパイプラインの グループ演算子 に適しています。そのため、最初のステップは、このグループ化をキャプチャする変数を作成することです。
import _ from 'underscore';
export function airportData() {
const data = flightData();
const working = _.groupBy(data, r => r.dest);
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]);
result[i].cancellationRate = cancellations[i] / count[i];
}
return result;
}
このステップについていくつか注意点があります。まず、適切な名前がまだ思い浮かばないので、単に working と呼びます。次に、javascriptにはArray に優れたコレクションパイプライン演算子のセットがありますが、グループ化演算子がありません。自分で書くこともできますが、代わりにJavascriptの世界で長い間便利なツールとなっている underscoreライブラリ を利用します。
count変数は、各目的地の空港にいくつのフライトレコードがあるかをキャプチャします。 マップ操作 を使用して、パイプラインでこれを簡単に計算できます。
export function airportData() {
const data = flightData();
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => {return {count: val.length}})
.value()
;
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - cancellations[i]);
result[i].cancellationRate = cancellations[i] / working[i].count;
}
return result;
}
アンダースコアでこのようなマルチステップパイプラインを実行するには、chain 関数でパイプラインを開始する必要があります。これにより、パイプラインの各ステップがアンダースコア内にラップされるため、 メソッドチェーン を使用してパイプラインを構築できます。欠点は、最後に value を使用して、基礎となる配列を取得する必要があることです。
マップ操作は標準マップではありません。Javascriptオブジェクト(本質的にはハッシュマップ)の内容を操作するため、マッピング関数はキーと値のペアに対して機能します。アンダースコアでは、mapObject 関数を使用してこれを行います。
通常、動作をパイプラインに移動するときは、制御変数を完全に削除することを好みますが、必要なキーの追跡にも役割を果たしているため、他の計算を処理するまでしばらくそのままにしておきます。 。
次に、キャンセル変数を処理します。今回は削除できます。
export function airportData() {
const data = flightData();
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => {
return {
count: val.length,
cancellations: val.filter(r => r.cancelled).length
}
})
.value()
;
const count = {};
const cancellations = {};
const totalDelay = {};
const cancellations = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
マッピング関数がかなり長くなってきたので、 メソッドの抽出 を使用する時期だと思います。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
const totalDelay = {}
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
関数を全体的な関数内の変数に割り当てることは、javascriptで関数の定義をネストして、そのスコープを airportData 関数に限定する方法です。この関数はより広く役立つと想像できますが、それは後で検討するリファクタリングです。
次に、合計遅延の計算を処理します。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).reduce((acc,each) => acc + each.delay, 0)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
const totalDelay = {}
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
合計遅延のラムダ式は、元の式を反映しており、 reduce操作 を使用して合計を計算します。最初にマップを使用する方が読みやすいことがよくあります。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
その再定式化は大したことではありませんが、私はますますそれを好むようになっています。そのラムダも少し長いですが、抽出する必要があると感じるほどではありません。
また、ラムダを置き換えて、summarize を呼び出す代わりに、単に関数の名前を付けることにしました。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
すべての依存データが削除されたので、count を削除する準備ができました。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in working) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
次に、2番目のループに注目します。これは本質的に マップ を実行して2つの値を計算しています。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const formResult = function(row) {
return {
meanDelay: row.totalDelay / (row.count - row.cancellations),
cancellationRate: row.cancellations / row.count
}
}
let working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.mapObject(formResult)
.value()
;
return working;
let result = {};
for (let i in working) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
すべてが終わったら、working で インライン一時変数 を使用して、名前の変更と整理をもう少し行うことができます。
export function airportData() {
const data = flightData();
const summarize = function(flights) {
return {
numFlights: flights.length,
numCancellations: flights.filter(f => f.cancelled).length,
totalDelay: flights.filter(f => !f.cancelled).map(f => f.delay).reduce((a,b) => a + b)
}
}
const formResult = function(airport) {
return {
meanDelay: airport.totalDelay / (airport.numFlights - airport.numCancellations),
cancellationRate: airport.numCancellations / airport.numFlights
}
}
return _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.mapObject(formResult)
.value()
;
}
よくあることですが、最終的な関数の可読性が向上した理由の多くは、関数を抽出したことによるものです。しかし、グループ化演算子は関数の目的を明確にするのに役立ち、抽出の設定に役立つことがわかりました。
データがリレーショナルデータベースからのもので、パフォーマンスの問題が発生している場合、このリファクタリングには別の潜在的な利点があります。ループからコレクションパイプラインにリファクタリングすることにより、SQLに非常に似た形式で変換を表しています。このタスクの場合、データベースから大量のデータをプルしている可能性がありますが、リファクタリングされたコードにより、グループ化と最初のレベルの集計ロジックをSQLに移動することを検討しやすくなります。これにより、ネットワーク経由で送信する必要があるデータ量が削減されます。通常、SQLではなくアプリケーションコードにロジックを保持することを好むため、このような移動はパフォーマンスの最適化として扱い、パフォーマンスの大幅な向上が測定できる場合にのみこれを行います。しかし、これは、 明確なコードを使用して作業する場合、最適化を行う方がはるかに簡単である という点を強化しています。そのため、私が知っているすべてのパフォーマンスウィザードは、パフォーマンスの高いコードの基盤として、明確さを第一に考えることの重要性を強調しています。
識別子
次の例では、人が必要な識別子のセットを持っていることを確認するコードを見ていきます。システムが、顧客IDなど、うまくいけば一意のIDを使用して人を識別することに依存することはよくあります。多くのドメインでは、多くの異なる識別スキームを処理する必要があり、人は複数のスキームで識別子を持っている必要があります。そのため、町の政府は、人が町のID、州のID、国のIDを持っていることを期待するかもしれません。

図2:人が異なるスキームで識別子を持つためのデータモデル
この状況のデータ構造は非常に単純です。personクラスには、識別子オブジェクトのコレクションがあります。識別子には、スキームと値のフィールドがあります。しかし、通常、データモデルのみでは強制できない制約がさらにあり、そのような制約は、次のような検証関数によってチェックされます。
クラスPerson ...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
この例はRubyで記述されています。Rubyでプログラミングするのが好きだからです。
このループをサポートする他のオブジェクトがいくつかあります。Identifierクラスは、そのスキーム、値、およびそれが無効かどうか(論理的には削除されていますが、データベースにはまだ保持されています)を知っています。また、エラーを追跡するための 通知 もあります。
class Identifier
attr_reader :scheme, :value
def void?
…
class Notification
def add_error e
…
このルーチンにおける私にとって最大の臭いは、ループが2つのことを同時に行っていることです。重複する識別子(dups に収集)と不足している必要なスキーム(required_schemes に)の両方を見つけます。プログラマーが同じオブジェクトのコレクションで2つのことを行う必要がある場合、同じループで両方のことを行うことを決定することは非常に一般的です。1つの理由は、ループを設定するために必要なコードであり、2回書くのはもったいないようです。最新のループ構造とパイプラインは、その負担を取り除きます。より有害な理由は、パフォーマンスに関する懸念です。確かに、多くのパフォーマンスホットスポットにはループが含まれており、ループを融合して問題を改善できる場合があります。しかし、これらは私たちが書くすべてのループのごく一部にすぎないため、プログラミングの通常の原則に従う必要があります。測定された重大なパフォーマンスの問題がない限り、パフォーマンスよりも明確さに焦点を当てます。そのような問題がある場合は、それを修正することが明確さよりも優先されますが、そのような場合はまれです。
測定された重大なパフォーマンスの問題がない限り、パフォーマンスよりも明確さに焦点を当てます。
そのため、2つのことを行うループに直面した場合、明確さを向上させるためにループを複製することをためらいません。パフォーマンス分析によってそのリファクタリングが逆転することは非常にまれです。
そのため、最初のステップは、分割ループと呼ばれるリファクタリングを使用することです。これを行うときは、まずループとそれを接続しているコードをコヒーレントなコードブロックに取得し、 メソッドの抽出 を適用します。
クラスPerson ...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
return inner_check_valid_ids required_schemes, note: note
end
def inner_check_valid_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
この抽出されたメソッドは2つのことを行っているため、今度はそれを複製して、2つの個別のメソッドの足場を形成します。それぞれが1つのことだけを実行します。複製してそれぞれを呼び出すと、累積する通知にエラーが2倍発生します。重複のそれぞれから無関係の更新を削除することで、これを回避できます。
クラスPerson ...
def check_valid_ids required_schemes, note: nil note ||= Notification.new note.add_error "has no ids" if @ids.size < 1 check_no_duplicate_ids required_schemes, note: note check_all_required_schemes required_schemes, note: note end def check_no_duplicate_ids required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", ") end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end def check_all_required_schemes required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", ") end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
二重更新を削除することが重要です。そうすれば、リファクタリング中はすべてのテストに合格し続けます。
結果はかなり醜いですが、これで各メソッドを個別に操作して、各メソッドの目的に関係のないものをすべて削除できます。
重複チェックのリファクタリング
重複なしのケースから始めます。いくつかのステップでコードの塊を切り取って、それぞれをテストして間違いがないことを確認できます。最初に、最後に required_schemes を使用するコードを削除することから始めます
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
end
return note
end
次に、不要な条件の分岐を取り除きます
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
この時点で、不要になった `required_schemes` パラメータを削除することも、おそらく削除すべきだったかもしれません。しかし、私はそうしませんでした。最終的にそれがどのように解決されるかを見ていくことになります。
私はいつものように変数の抽出を行います。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
for id in input
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
それから、入力変数にフィルタを追加し、無効な識別子をスキップする行を削除できます。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids.reject{|id| id.void?}
for id in input
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
ループ内をさらに見ていくと、IDではなくスキームを使用していることがわかります。そのため、パイプラインのステップにIDをスキームにマップする処理を追加できます。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
for scheme in input
if used.include?(scheme)
dups << scheme
end
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
この時点で、ループ本体は単純な重複削除の動作にまで縮小されました。重複を見つけるためのパイプラインの方法があります。それは、スキームをそれ自体でグループ化し、複数回出現するものをフィルタリングすることです。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
for scheme in input
if used.include?(scheme)
dups << scheme
end
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
これでパイプラインの出力は重複になります。そのため、入力変数を削除し、パイプラインを変数に代入できます(そして、不要になった `used` 変数を削除します)。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
for scheme in input
dups << scheme
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
これで素晴らしいパイプラインができましたが、厄介な要素があります。パイプラインの最後の3つのステップは重複を削除するためのもので、その知識はコードではなく私の頭の中にあります。メソッドの抽出を使用して、コードに移動する必要があります。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
class Array…
def duplicates
self
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
end
ここでは、既存のクラスにメソッドを追加するRubyの機能(モンキーパッチとして知られています)を使用しました。最新のRubyバージョンでは、RubyのRefinement機能を使用することもできます。しかし、多くのオブジェクト指向言語はモンキーパッチをサポートしていません。その場合は、次のようなローカルで定義された関数を使用する必要があります。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
schemes = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
if duplicates(schemes).size > 0
note.add_error "duplicate schemes: " + duplicates(schemes).join(", ")
end
return note
end
def duplicates anArray
anArray
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
end
personにメソッドを定義するのは、配列に配置するのほどパイプラインには適していません。しかし、多くの場合、言語がモンキーパッチを含んでいない、プロジェクト標準でそれが容易ではない、または汎用リストクラスに配置するには十分に汎用的ではないメソッドであるため、配列にメソッドを配置できません。これは、オブジェクト指向のアプローチが邪魔になり、メソッドをオブジェクトにバインドしない関数型アプローチの方がうまくいくケースです。
このようなローカル変数があるときはいつでも、一時変数をクエリに置き換えるを使用して変数をメソッドに変えることを検討します。その結果、次のようになります。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
if duplicate_identity_schemes.size > 0
note.add_error "duplicate schemes: " + duplicate_identity_schemes.join(", ")
end
return note
end
def duplicate_identity_schemes
@ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
end
`duplicate_identity_schemes` の動作がpersonクラスの他のメソッドに役立つかどうかで、この決定を下します。しかし、クエリメソッドを作成する方を好むという事実にもかかわらず、この場合はローカル変数として保持する方を好みます。
必要なスキームがすべて揃っているかどうかのチェックのリファクタリング
重複がないことのチェックをクリーンアップしたので、必要なすべてのスキームがあることのチェックに取り組むことができます。現在のメソッドは次のとおりです。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
前のメソッドと同様に、最初のステップは重複のチェックに関連するものをすべて削除することです。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
この関数の核心に迫るために、`found_required` 変数を見ていきます。重複チェックの場合と同様に、主に無効でない識別子を持つスキームに興味があるので、スキームを変数にキャプチャし、IDではなくそれらを使用することから始めたいと思います。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil
found_required = []
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
for s in schemes
next if id.void?
for req in required_schemes
if s == req
found_required << req
required_schemes.delete req
next
end
end
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
`found_required` の目的は、`required_schemes` リストとIDからのスキームの両方にあるスキームをキャプチャすることです。それは集合の共通部分のように聞こえます。そして、それは、まともなコレクションであれば期待できる関数です。そのため、それを使って `found_required` を決定できるはずです。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil found_required = [] schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} for s in schemes for req in required_schemes if s == req found_required << req required_schemes.delete req next end end end found_required = schemes & required_schemes if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
残念ながら、その変更はテストに失敗しました。今度はコードをよく見て、`found_required` は後のコードではまったく使用されていないことに気づきました。これは、かつて何かに使用されていたゾンビ変数ですが、その使用は後に放棄され、変数はコードから削除されませんでした。そのため、行ったばかりの変更を元に戻して削除します。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil
found_required = []
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
for s in schemes
for req in required_schemes
if s == req
found_required << req
required_schemes.delete req
next
end
end
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
これで、ループがパラメータ `required_schemes` から要素を削除していることがわかります。このようなパラメータの変更は、収集パラメータ(ノートなど)でない限り、私にとって厳禁です。そのため、すぐにパラメータへの代入の削除を適用します。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes.dup schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} for s in schemes for req in required_schemes if s == req missing_schemes.delete req next end end end if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
これを行うことで、ループが列挙しているリストから項目を削除していることも明らかになりました。これはパラメータを変更するよりもさらに悪いことです。
これが明確になったので、集合演算が適切であることがわかりますが、必要なことは、集合の差分演算を使用して、必要なリストから持っているスキームを削除することです。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes.dup schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} missing_schemes = required_schemes - schemes for s in schemes for req in required_schemes if s == req missing_schemes.delete req next end end end if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
次に、2番目のループ、エラーメッセージの形成を見ていきます。これは単にスキームを文字列に変換し、コンマで結合するだけです。これは文字列結合操作の仕事です。
クラスPerson ...
def check_all_required_schemes required_schemes, note: nil
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
missing_schemes = required_schemes - schemes
if missing_schemes.size > 0
missing_names = missing_schemes.join(", ")
for req in missing_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
2つのメソッドの統合
両方のメソッドがクリーンアップされ、1つのことだけを実行し、何をしているかが明確になりました。どちらも無効でない識別子のスキームのリストが必要なので、メソッドの抽出を使用したいと考えています。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
dups = identity_schemes.duplicates
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
missing_schemes = required_schemes - identity_schemes
if missing_schemes.size > 0
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_names
end
return note
end
def identity_schemes
@ids
.reject{|i| i.void?}
.map {|i| i.scheme}
end
次に、いくつかの小さなクリーンアップをしたいと思っています。まず、コレクションが空かどうかをサイズをチェックすることでテストしています。私は常に、より意図を明らかにする空のメソッドを好みます。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_names
end
return note
end
このリファクタリングの名前がありません。「実装を明らかにするメソッドを意図を明らかにするメソッドに置き換える」のようなものにする必要があります。
`missing_names` 変数は役に立っていないので、一時変数のインライン化を使用します。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_schemes.join(", ")
end
return note
end
また、これら両方を単一行の条件付き構文を使用するように変換したいと考えています。
クラスPerson ...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ") unless dups.empty?
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
note.add_error "missing schemes: " + missing_schemes.join(", ") unless missing_schemes.empty?
end
return note
end
繰り返しますが、 dafürには定義されたリファクタリングがなく、それは非常にruby固有のものになります。
これで、メソッドはもはや価値がないと思うので、それらをインライン化し、抽出された `identity_schemes` メソッドを呼び出し元にインライン化します。
クラスPerson ...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
identity_schemes = @ids.reject{|i| i.void?}.map {|i| i.scheme}
dups = identity_schemes.duplicates
note.add_error("duplicate schemes: " + dups.join(", ")) unless dups.empty?
missing_schemes = required_schemes - identity_schemes
note.add_error "missing schemes: " + missing_schemes.join(", ") unless missing_schemes.empty?
return note
end
最終的なメソッドは通常よりも少し長くなりますが、その凝集性が気に入っています。 much größerになったら、メソッドをメソッドオブジェクトに置き換えるを使用して分割したい場合があります。たとえそれが長くても、検証がチェックしているエラーを伝える方がはるかに明確になります。
最後に
これで、このリファクタリングの例は終わりです。コレクションパイプラインがコレクションを操作するコードのロジックをどのように明確にするか、そしてループをコレクションパイプラインにリファクタリングすることがいかに簡単なことであるかをよく理解していただけたでしょうか。
すべてのリファクタリングと同様に、コレクションパイプラインをループに変換するための同様の逆リファクタリングがありますが、私はほとんどそれを行うことはありません。
最近では、ほとんどの最新の言語がファーストクラス関数とコレクションパイプラインに必要な操作を含むコレクションライブラリを提供しています。コレクションパイプラインに慣れていない場合は、遭遇するループを取得してこのようにリファクタリングすることをお勧めします。最終的なパイプラインが元のループよりも明確でない場合は、完了したらいつでもリファクタリングを元に戻すことができます。リファクタリングを元に戻した場合でも、この演習からこの手法について多くのことを学ぶことができます。私は長い間このプログラミングパターンを使用しており、自分のコードを読むのに役立つ貴重な方法だと考えています。そのため、チームが同様の結論に達するかどうかを確認するために、調査する価値があると思います。
脚注
1: 実際には、私の最初の動きは、ループでメソッドの抽出を適用することを検討することです。ループを独自の関数に分離すると、ループを操作するのが簡単なことが多いためです。
2: map演算子が「Select」と呼ばれているのを見るのは、私には奇妙です。理由は、C#のパイプラインメソッドがLinqに由来し、その主な目的はデータベースアクセスを抽象化することであるため、メソッド名はSQLと似ているように選択されたためです。「Select」はSQLの射影演算子であり、列を選択すると考えると理にかなっていますが、関数のマッピングと考えると奇妙な名前です。
3: もちろん、これはコレクションパイプラインを実行できるすべての言語の包括的なリストではないため、Javascript、Scala、またはWhatever ++を表示していないといういつもの苦情が殺到すると予想されます。ここでは膨大な言語リストではなく、コレクションパイプラインがなじみのない言語で簡単に理解できるという概念を伝えるのに十分なほど多様な小さなセットが必要です。
4: 場合によっては、短絡するものが必要になりますが、ここではそうではありません。
5: 私はしばしばこれを否定的なブール値で見つけます。これは、否定(`!`)が式の先頭にあるのに対し、述語(`isEmpty`)が末尾にあるためです。2つの間に実質的な式があると、結果は解析が困難になります。(少なくとも私にとっては。)
6: これを演算子カタログにまだ入れていません。
7: 述語を渡す最後の項目を検出する操作がない言語を使用している場合は、最初に反転してから最初の項目を検出できます。
謝辞
Kit Easonは、F#の例をもう少し慣用的にするのに役立ちました。Les Ramerは、C#の改善に役立ちました。Richard Warburtonは、Javaの表現のあいまいさを修正しました。Daniel Sandbeckerは、ルビーの例でエラーを発見しました。Andrew Kiellor、Bruno Trecenti、David Johnston、Duncan Cragg、Karel Alfonso、Korny Sietsma、Matteo Vaccari、Pete Hodgson、Piyush Srivastava、Scott Robinson、Steven Lowe、Vijay Aravamudhanは、Thoughtworksメーリングリストでこの記事の草稿について話し合いました。
重要な改訂
2015年7月14日:識別子の例と最終的な考えを追加しました
2015年7月7日:フライトデータのグループ化の例を追加しました
2015年6月30日:機器提供の例を追加しました。
2015年6月25日:ネストされたループの分割払いを追加しました
2015年6月23日:最初の分割払いを公開しました