
リチャードソン成熟度モデル
RESTの栄光へのステップ
RESTアプローチの主要な要素を3つのステップに分類するモデル(レナード・リチャードソンによって開発)。これらは、リソース、HTTP動詞、およびハイパーメディア制御を導入します。
2010年3月18日

最近、同僚数名が執筆しているRest In Practiceの草稿を読んでいます。その目的は、企業が直面する多くの統合問題に対処するために、RESTful Webサービスをどのように使用するかを説明することです。本書の中心となる概念は、Webが非常にうまく機能する大規模なスケーラブルな分散システムの存在証明であり、そこからアイデアを取り入れて、統合システムをより簡単に構築できるということです。
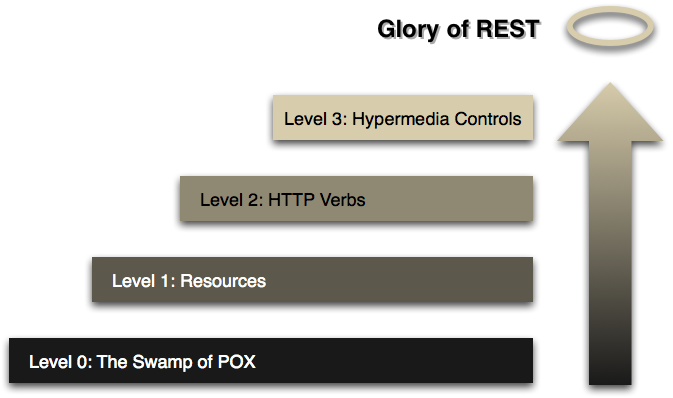
図1:RESTへのステップ
Webスタイルシステムの特定のプロパティを説明するために、著者はレナード・リチャードソンによって開発され、QConの講演で説明されたRESTの成熟度モデルを使用しています。このモデルは、これらのテクニックを使用する方法を考える上で優れた方法なので、独自の解釈を試みようと思いました。(ここのプロトコル例は例示のみです。コーディングとテストを行う価値は感じなかったので、詳細に問題があるかもしれません。)
レベル0
このモデルの出発点は、HTTPをリモートインタラクションのトランスポートシステムとして使用することですが、Webのメカニズムは使用しません。基本的に、ここではHTTPを独自の遠隔相互作用メカニズム(通常はリモートプロシージャコールに基づく)のためのトンネリングメカニズムとして使用しています。
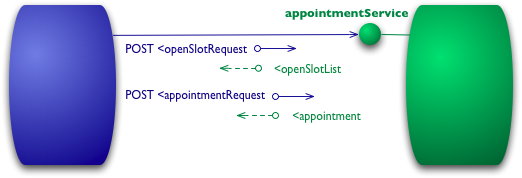
図2:レベル0でのインタラクション例
医師との予約を入れたいとしましょう。私の予約ソフトウェアはまず、医師が特定の日にどのような空いている枠を持っているかを知る必要があるため、その情報を取得するために病院の予約システムにリクエストを送信します。レベル0のシナリオでは、病院は特定のURIにサービスエンドポイントを公開します。その後、そのエンドポイントに、リクエストの詳細を含むドキュメントをPOSTします。
POST /appointmentService HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04" doctor = "mjones"/>
サーバーは、この情報を提供するドキュメントを返します。
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot start = "1400" end = "1450">
<doctor id = "mjones"/>
</slot>
<slot start = "1600" end = "1650">
<doctor id = "mjones"/>
</slot>
</openSlotList>
ここでは例としてXMLを使用していますが、コンテンツは実際には何でもかまいません。JSON、YAML、キーバリューペア、または任意のカスタムフォーマットです。
次のステップは予約を入れることで、これもエンドポイントにドキュメントをPOSTすることで行うことができます。
POST /appointmentService HTTP/1.1 [various other headers] <appointmentRequest> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointmentRequest>
すべてうまくいけば、予約が完了したという応答が得られます。
HTTP/1.1 200 OK [various headers] <appointment> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
問題が発生した場合、たとえば他の誰かが先に予約した場合、返信本文に何らかのエラーメッセージが表示されます。
HTTP/1.1 200 OK [various headers] <appointmentRequestFailure> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> <reason>Slot not available</reason> </appointmentRequestFailure>
今のところ、これは単純なRPCスタイルのシステムです。単純なプレーンなXML(POX)をやり取りするだけなので簡単です。SOAPまたはXML-RPCを使用する場合、基本的には同じメカニズムであり、唯一の違いは、XMLメッセージを何らかのエンベロープでラップすることです。
レベル1 - リソース
RMMにおけるRESTの栄光への最初のステップは、リソースを導入することです。したがって、すべてのリクエストを単一のサービスエンドポイントに行うのではなく、個々のリソースと通信し始めます。
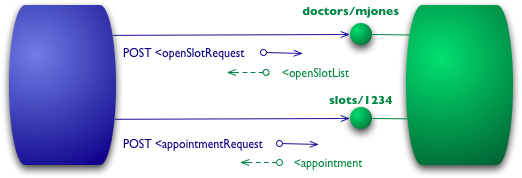
図3:レベル1でリソースを追加
最初のクエリでは、特定の医師のリソースがあるかもしれません。
POST /doctors/mjones HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04"/>
返信は同じ基本情報を運びますが、各スロットは個別にアドレス指定できるリソースになります。
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
特定のリソースを使用すると、予約を入れることは特定のスロットへのPOSTを意味します。
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
すべてうまくいけば、以前と同様の返信が得られます。
HTTP/1.1 200 OK [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
違いは、誰かが予約について何かをする必要がある場合(検査の予約など)、まず`http://royalhope.nhs.uk/slots/1234/appointment`のようなURIを持つ予約リソースを取得し、そのリソースにPOSTすることです。
私のようなオブジェクト指向プログラマーにとって、これはオブジェクト同一性の概念に似ています。エーテルにある関数を呼び出して引数を渡すのではなく、特定のオブジェクトのメソッドを呼び出して、他の情報の引数を提供します。
レベル2 - HTTP動詞
ここではレベル0と1のすべてのインタラクションにHTTP POST動詞を使用していますが、一部の人はGETも使用するか、または代わりに使用します。これらのレベルでは、それほど違いはありません。どちらもHTTPを介してインタラクションをトンネリングできるトンネリングメカニズムとして使用されています。レベル2はこれから離れ、HTTP動詞をHTTP自体で使用されている方法にできるだけ近づけて使用します。
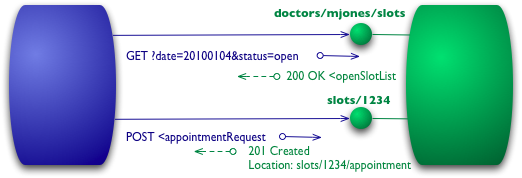
図4:レベル2でHTTP動詞を追加
スロットのリストの場合、GETを使用する必要があります。
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
返信は、POSTの場合と同じです。
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
レベル2では、このようなリクエストに対するGETの使用が重要です。HTTPはGETを安全な操作として定義しています。つまり、何かの状態に重要な変更を加えません。これにより、GETを任意の回数、任意の順序で安全に呼び出して、毎回同じ結果を得ることができます。この重要な結果は、リクエストのルーティングに参加するすべての参加者がキャッシングを使用できるようになることです。これは、Webがそのようにうまく機能する上で重要な要素です。HTTPにはキャッシングをサポートするさまざまな手段が含まれており、通信に参加するすべての参加者で使用できます。HTTPのルールに従うことで、その機能を利用できます。
予約を入れるには、状態を変更するHTTP動詞、POSTまたはPUTが必要です。以前と同じPOSTを使用します。
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
ここでPOSTとPUTを使用することのトレードオフは、ここで説明するよりも多くあります。いつか別の記事でそれらについて説明するかもしれません。しかし、POST/PUTと作成/更新を誤って対応付ける人がいることを指摘しておきたいと思います。それらの選択は、それとはかなり異なります。
レベル1と同じPOSTを使用する場合でも、リモートサービスが応答する方法に別の重要な違いがあります。すべてうまくいけば、サービスは新しいリソースが世界にあることを示す201の応答コードで応答します。
HTTP/1.1 201 Created Location: slots/1234/appointment [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>
201応答には、クライアントが将来そのリソースの現在の状態を取得するために使用できるURIを含むlocation属性が含まれています。この応答には、クライアントがすぐに追加の呼び出しを行う必要がないように、そのリソースの表現も含まれています。
他の誰かがセッションを予約するなど、何か問題が発生した場合にも、別の違いがあります。
HTTP/1.1 409 Conflict [various headers] <openSlotList> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>
この応答の重要な部分は、何か問題が発生したことを示すHTTP応答コードの使用です。この場合、他の誰かが既にリソースを非互換な方法で更新したことを示すには、409が適切な選択肢のようです。200の戻りコードを使用するのではなく、エラー応答を含める代わりに、レベル2では、このような何らかのエラー応答を明示的に使用します。使用するコードを決定するのはプロトコル設計者ですが、エラーが発生した場合は、2xx以外の応答がある必要があります。レベル2では、HTTP動詞とHTTP応答コードの使用が導入されます。
ここに矛盾が忍び寄っています。RESTの支持者は、すべてのHTTP動詞を使用することについて話します。また、RESTはWebの実用的な成功から学ぶことを試みていると言って、そのアプローチを正当化しています。しかし、ワールドワイドウェブは実際にはPUTやDELETEをあまり使用していません。PUTとDELETEをより多く使用するための妥当な理由がありますが、Webの存在証明はその一つではありません。
Webの存在によってサポートされている重要な要素は、安全な操作(例:GET)と安全ではない操作の強力な分離と、発生するエラーの種類を伝えるのに役立つステータスコードの使用です。
レベル3 - ハイパーメディア制御
最後のレベルでは、しばしば醜い頭字語HATEOAS(Hypertext As The Engine Of Application State)と呼ばれるものが導入されます。これは、空いているスロットのリストから予約方法を知る方法という問題に対処します。

図5:レベル3でハイパーメディア制御を追加
レベル2で送信したのと同じ最初のGETから始めます。
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk
しかし、応答には新しい要素があります。
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450">
<link rel = "/linkrels/slot/book"
uri = "/slots/1234"/>
</slot>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650">
<link rel = "/linkrels/slot/book"
uri = "/slots/5678"/>
</slot>
</openSlotList>
各スロットには、予約方法を知らせるURIを含むlink要素が追加されました。
ハイパーメディア制御のポイントは、次に何ができるか、そしてそれを実行するために操作する必要があるリソースのURIを教えてくれることです。予約リクエストをどこに投稿する必要があるかを知る必要がない代わりに、応答内のハイパーメディア制御がその方法を教えてくれます。
POSTはレベル2のものと同様になります。
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>
そして、返信には、次に実行できるさまざまなアクションのハイパーメディア制御が含まれています。
HTTP/1.1 201 Created
Location: http://royalhope.nhs.uk/slots/1234/appointment
[various headers]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
<link rel = "/linkrels/appointment/cancel"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/addTest"
uri = "/slots/1234/appointment/tests"/>
<link rel = "self"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/changeTime"
uri = "/doctors/mjones/slots?date=20100104&status=open"/>
<link rel = "/linkrels/appointment/updateContactInfo"
uri = "/patients/jsmith/contactInfo"/>
<link rel = "/linkrels/help"
uri = "/help/appointment"/>
</appointment>
ハイパーメディア制御の明白な利点の1つは、サーバーがURIスキームを変更してもクライアントが壊れないことです。「addTest」リンクURIを検索する限り、サーバーチームは最初のエントリポイント以外のすべてのURIを調整できます。
さらなる利点は、クライアント開発者がプロトコルを探索するのに役立つことです。リンクは、クライアント開発者に次に何が可能になるかを示唆します。すべての情報を提供するわけではありません。「self」コントロールと「cancel」コントロールはどちらも同じURIを指しています。それらがGETとDELETEのどちらであるかを理解する必要があります。しかし、少なくとも、より多くの情報について考え、プロトコルドキュメントで同様のURIを探すための出発点を提供します。
同様に、サーバーチームは、応答に新しいリンクを追加することで、新しい機能を宣伝できます。クライアント開発者が不明なリンクに注目している場合、これらのリンクはさらなる調査のきっかけになります。
ハイパーメディア制御を表す方法に関する絶対的な標準はありません。ここでは、RFC 4287に従う、REST in Practiceチームの現在の推奨事項を使用しています。ターゲットURIの`uri`属性と関係の種類を記述する`rel`属性を持つ`<link>`要素を使用します。よく知られている関係(要素自体への参照である`self`など)はそのままですが、サーバー固有のものは完全に修飾されたURIです。ATOMでは、よく知られているlinkrelの定義は関係リンクのレジストリです。私がこれらを記述している時点では、ATOMによって行われているものに限られており、一般的にレベル3のRESTfulnessのリーダーと見なされています。
レベルの意味
RMMは、RESTの要素について考える上で良い方法ですが、REST自体のレベルの定義ではないことを強調する必要があります。ロイ・フィールディングは、レベル3のRMMはRESTの前提条件であることを明確にしています。ソフトウェアの多くの用語と同様に、RESTには多くの定義がありますが、ロイ・フィールディングがその用語を作り出したため、彼の定義はほとんどの定義よりも重みがあるはずです。
このRMMの有用な点は、RESTful思考の背後にある基本的な概念を段階的に理解できる点です。そのため、これは概念を学ぶためのツールであり、何らかの評価メカニズムで使用すべきものではないと考えています。RESTfulアプローチがシステム統合の正しい方法であると断言できるだけの十分な例はまだないと考えますが、非常に魅力的なアプローチであり、ほとんどの場合に推奨するアプローチです。
Ian Robinson氏との議論の中で、彼はLeonard Richardson氏が最初にこのモデルを発表した際、魅力的だと感じた点として、一般的な設計手法との関連性を強調していました。
- レベル1は、分割統治を用いて複雑さを処理するという問題に取り組み、大きなサービスエンドポイントを複数のリソースに分割します。
- レベル2は、標準的な動詞セットを導入することで、同様の状況を同じ方法で処理し、不必要なばらつきを排除します。
- レベル3は、検出可能性を導入し、プロトコルをより自己記述的にするための方法を提供します。
その結果、提供したいHTTPサービスの種類について考え、それとのやり取りを望む人々の期待を明確にするためのモデルが得られます。
謝辞
Savas Parastatidis氏、Ian Robinson氏、Jim Webber氏は草案について重要なコメントを寄稿してくれました。Leonard Richardson氏は私の質問に非常に丁寧に答えてくれ、彼の考えの誤解を最小限に抑えることができました。Aaron Swartz氏はレベル3のURIに関するいくつかの誤りを修正してくれました。
重要な改訂
2010年3月18日:初回投稿