
テスト影響分析の台頭
テスト影響分析(TIA)は、ビルドのテスト自動化フェーズを高速化する最新の手段です。これは、ソースコードのコールグラフを分析して、本番コードに変更を加えた後にどのテストを実行する必要があるかを判断することで機能します。Microsoftはこのアプローチに大規模な取り組みを行ってきましたが、開発チームも比較的安価に役立つものを実装することができます。
2017年8月22日

Paul Hammantは、継続的デリバリーとDevOpsに関してクライアントを支援する独立系コンサルタントです。彼は、トランクベース開発と依存性注入のためのツールと技術の開発において主導的な役割を果たしました。Thoughtworksで12年間勤務するなど、いくつかのテクノロジー組織で上級スタッフを務めてきました。
現代のソフトウェア開発の悩みの種は、チェックイン前にすべてを実行するには「多すぎる」テストがあることです。それが現実となると、開発者はローカルの開発ワークステーションでテストを実行しないというコストのかかる対処戦略を採用します。代わりに、統合サーバーで後で実行されるテストに依存します。そして、それらでさえしばしば使い物にならなくなりますが、これは開発チームにとってシフトライトが当たり前になると避けられません。
もちろん、統合前にテストするものはすべて、継続的インテグレーション(CI)インフラストラクチャで統合後にすぐにテストする必要があります。最高レベルの開発チームでさえ、リアルタイムでコミットが着陸することによるタイミングのずれから発生する障害を経験する可能性があります。これらのチームには、合意された統合プロセスを「節約」し、テストを実行したくない人がいる場合もあります。幸いなことに、CIサーバーと適切な一連のビルド手順により、これらの瞬間をすばやく捉えることができます。
テスト実行を高速化するためには、多くのマシンで並列に実行したり、低速なリモートサービスにテストダブルを使用したりするなど、さまざまな手法があります。しかし、この記事では、新しく追加されたバグを特定する可能性が最も高いテストを特定することにより、実行するテストの数を削減することに焦点を当てます。テストピラミッド構造では、通常は実行速度が速く、脆弱性が低く、より具体的なフィードバックを提供するため、単体テストをより頻繁に実行します。特に、CIの一部として実行する必要がある一連のテストを定義します:統合前と統合後。その後、デプロイメントパイプラインを作成して、後で低速なテストを実行します。
同じ問題を言い換えると、**テストが無限に高速に実行された場合、常にすべてのテストを実行しますが、そうではないため、テストを実行する際にはコストと価値のバランスを取る必要があります。**
この記事では、Microsoftが先導しているテスト関連のコンピュータサイエンスの新興分野、つまり、長いテスト自動化スイートを持つ企業が注目すべき分野について詳しく説明します。.NETエコシステムに精通している場合は、Microsoftの「テスト影響分析」に関する進歩からすぐに利益を得ることができるかもしれません。.NETを使用していない場合は、かなり安価に自分で何かを設計できなければなりません。私の以前の雇用主は、私が以下に示す概念実証作業に基づいて、独自に何かを設計しました。
テスト自動化を短縮するための従来の戦略
全体像を完成させるために、業界では依然として主流となっている従来の「テストのサブセットを実行する」戦略を要約します。まあ、並列テスト実行とサービス仮想化の新しい現実を踏まえてです。
スイートとタグの作成
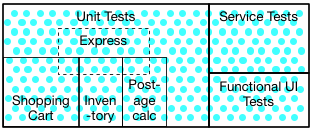
ユニット、サービス、機能UIの主要なグループ分け。単体テスト内では、他のサブセットをサンプリングする「エクスプレス」を含む、意味のあるサブグループのタグ。

「ショッピングカート」テストの実行後、1つを除いてすべて合格しました。
このアプローチは、Ant、Maven、MSBuild、Rakeなどの再帰的なビルドテクノロジーで機能します。
歴史的に、チームはテストを無限に高速化することを諦め、スイートまたはタグを使用して、いつでもテストのサブセットをターゲットにしてきました。スイートとタグを作成することで、テストのサブセットを言葉で説明できます。たとえば、「ショッピングカートのUIテスト」です。タグまたはスイートは、アプリケーションのビジネス分野、または技術的または階層的なグループ分けを暗示している可能性があります。タグとスイートを定義するには、専門家の設計上の創造性が必要です。少なくとも、最適なグループ分けを目指して努力するためには。これは、人間が判断するのが難しい場合でも、不十分、不正確、不正確にグループ化される可能性があることも意味します。同時に実行されるテストの数が少なすぎたり多すぎたりすると、1つのスイートのみを実行する可能性が高くなります。これは、コンピューティングリソースと時間の無駄遣いになり、バグが見落とされるリスクもあります。チームは、コミットごとに小さいスイートを使用するCIジョブと、すべてのテストを実行する夜間ビルドジョブを選択する場合があります。明らかに、それは悪いニュースを遅らせ、継続的インテグレーションの目的を無効にします。
しかし、スイートとタグは、ソフトウェア開発の世界の大部分がテストコードベースを整理してきた方法です。
ソースとテストの事前計算されたグラフ
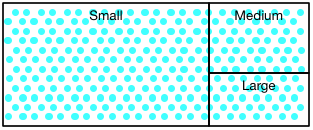
概念的な「サイズ」指定を持つ276のテスト。
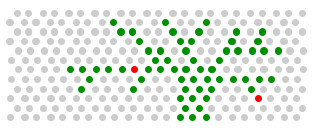
特定のコミットに対して実行されたもの。2つの障害が発生しました。たまたま、それらのいくつかは小さく、いくつかは中程度、いくつかは大きいことがわかりました。ツリー/フラクタルを描いたのは、概念を説明するのに役立つからです(実際にはそうではありません)。
Googleの伝説的な社内ビルドシステムBlazeは、長年にわたっていくつかのオープンソーステクノロジーにコピーされてきました。最も注目すべきは、FacebookのBuckとGoogleのBazelです。Twitter、Foursquare、SquareによるPants。Google内のBlazeは、モノレポ全体で単一の**有向グラフ**をナビゲートします。Blazeには、テストを本番コードに直接関連付けるメカニズムがあります。そのメカニズムは、本番ソースと関連するテストソースのきめ細かいディレクトリツリーです。チェックインされたBUILDファイルによる明示的な依存関係宣言があります。これらのBUILDファイルは、開発者によって維持および進化させることができますが、自動化ツールによって正しいか正しくないかを確認することもできます。このプロセスを時間をかけて繰り返すと、有向グラフが正確かつ効率的になります。
重要なことに、そのツールは依存関係に関する冗長な主張を指摘する可能性があります。したがって、特定のディレクトリ/パッケージ/名前空間の場合、開発者はテストのサブセットを非常に簡単に開始できますが、BUILDファイルから有向グラフを介して可能なものだけです。開発者にとって統合前と統合インフラストラクチャの両方にとって究極の時間の節約は、スケーリングされたCIインフラストラクチャ「Forge」(後のTAP)であり、この組み込みインテリジェンスに基づいて実行するテストの自動サブセット化でした。
Google規模の継続的テストの抑制には、驚くべき統計がたくさんあります。私の意見では、これはGoogleに数千万ドルの費用がかかりましたが、長年にわたって数十億ドルの利益をもたらしました。おそらく、収益:賃金の比率よりもはるかに大きいでしょう。
テスト影響分析
テスト影響分析(TIA)は、特定の変更セットに対してどのテストのサブセットを決定するのに役立つ手法です。
仮定の変更に対して実行するテストの同様の描写。
このアイデアの鍵は、すべてのテストがすべての本番ソースファイル(またはそのソースファイルから作成されたクラス)を実行するわけではないということです。テストの実行中のコードカバレッジまたはインストゥルメンテーションは、そのインテリジェンスが収集されるメカニズムです(詳細は以下)。そのインテリジェンスは、本番ソースとそれらを実行するテストのマップとして終わりますが、テストが実行する本番ソースのマップとして始まります。
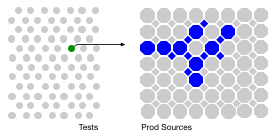
1つのテスト(多数の中から)が本番ソースのサブセットを実行します。

1つの本番ソースは、テストのサブセット(ユニット、統合、または機能)によって実行されます。
そのため、実行されたテストの定型化された図は、上記の有向グラフビルドテクノロジーと同じであることに注意してください。BUILDファイルのキュレーションは、時間の経過とともにTIAとほぼ同じ結果になるため、事実上同じです。
TIAマップは、実際には参照ポイントと比較した変更にのみ使用できます。これは、開発者がコミットする、またはコミットした作業と同じくらいシンプルです。複数のコミットにもなり得ます。たとえば、今日コミットされたすべて(夜間ビルド)、または最後のリリース以降のすべてです。
TIAアプローチを使用することによる1つの認識は、本番コードの同じセクションをカバーするテストが多すぎるということです。それらがまっすぐな複製である場合、テストとそのテストが実行する本番コードのパスを分析した後にテストを削除することは可能です。ただし、多くの場合そうではなく、テストしたいものに焦点を当て、コード内の推移的な依存関係にはまったく焦点を当てないようにテストする方法を理解することは、テストダブルと、より最近ではサービス仮想化(統合テスト用)の使用という確立されたプラクティスに必然的に依存する別の焦点領域です。
変更内容のリストを作成するための最小限のレベルは「変更された本番ソース」ですが、理想的には、どのメソッド/関数が変更されたかを判断し、それらを実行するテストのみにさらにサブセット化することです。しかし、今のところ、Microsoftからソースファイルレベルで動作する準備ができているテクノロジーが1つと、再利用可能なテクニック(私による)が1つあります。続きを読みます。
Microsoftによる広範なTIAの取り組み
Microsoftは、テスト影響分析のアイデアを製品化するために最も長く協調的な努力を続け、その概念にその名前とその頭字語を与えました。
これまでに、2017年3月から8月までのブログ記事シリーズがあります。**テスト影響分析による継続的テストの高速化-**パート1、パート2、パート3、およびパート4。
これに関する古い記事は8年前にさかのぼります
- Visual Studio 2010でのテスト影響分析 (2009)
- テスト影響分析によるテストプロセスの合理化) (2010)
- 前回のビルド以降、どのテストを実行する必要がありますか? (2010)
- 方法:コード変更後にどのテストを実行する必要があるかを確認するためのデータを収集する (2010)
- テスト影響分析 (2011)
MicrosoftのPratap Lakshmanは、彼らの実装の進化について詳しく説明しました。TIA技術の現在の進化に関して、Pratapは次のように述べています:[1]
影響を受けるテストと本番コードのマップは、トリガーされるビルドがあるときに再計算されます。それを行うジョブは、VSTSビルド定義内のVSTestタスクの一部として実行されます。
私たちのTIA実装は、各テストメソッドの動的依存関係を、テストメソッドの実行中に収集します。
概要は次のとおりです。テストの実行中に、さまざまなメソッドがカバーされます。これらのメソッドが存在するソースファイルは、追跡する動的依存関係です。
そのため、次のようなマッピングになります
Testcasemethod1 <--> a.cs, b.cs. d.cs
Testcasemethod2 <--> a.cs, k.cs, z.cs
など…
さて、たとえば、a.csへのコミットがあると、a.csを動的依存関係としていたすべてのTestcasemethod(s)を実行します。もちろん、新しく導入されたテスト(コミットの一部として提供される可能性があります)を処理し、以前に失敗したテストも引き継ぎます。
私たちのTIA実装はまだテストの優先順位付け(たとえば、最も頻繁に壊れるもの zuerst)を行っていません。それは私たちのレーダーにかかっており、コミュニティから十分な関心があれば検討します。
実際のTIAマップデータは、SQLServerデータベースとしてTFSに格納されます。コミットが発生すると、TIAはTFVC / Git APIを使用してコミットを開き、変更が加えられたファイルを確認します。ファイルが特定されると、TIAはマッピングを参照して、実行するテストを決定します。
もちろん、このTIAテクノロジーは、プルリクエスト(PR)および通常のCIワークフロー、そして開発者のワークステーションでの統合前でサポートされています。
ユーザーにはシフトレフトを採用し、できるだけ多くのテストをパイプラインの早期段階に移動することをお勧めします。これまで、お客様の中には、コミットごとに多くのテストを実行することになり、CIビルドに時間がかかるため、懸念を示す方もいらっしゃいました。TIAを使用することで、ユーザーにシフトレフトを促し、TIAが関連するテストのみを実行することで、パフォーマンスの側面を管理できるようにします。
TFSとVisual StudioにおけるTIAの最初の数年間について、彼は次のように述べています。
当時のTIAテクノロジーは、多くの点で大きく異なっていました。
- 影響を受けるテストを特定するだけでした。それらを明示的に実行するのはユーザー次第でした。
- テストとマッピングを生成するアプローチとして、ブロックレベルのコードカバレッジを使用していました。後続のビルドでは、以前のビルドとIL差分を実行して、変更されたブロックを特定し、マッピングを使用して影響を受けるテストを特定してリストしました。ただし、それらを自動的に実行するわけではありませんでした。
- 上記のアプローチは(現在の実装と比較して)速度が遅く、マッピング情報に(現在の実装と比較して)より多くのストレージが必要でした。
- 上記のアプローチはまた、現在の実装よりも安全性が低いものでした(場合によっては、影響を受けるテストの特定に失敗することがありました)。
- VSTSビルドワークフローをサポートしていませんでした(古いXAMLビルドシステムでのみサポートされていました)。
従来のコードカバレッジツールとスクリプトを使用したテスト影響分析
HedgeServで働いていたとき、最新の既製のコードカバレッジツールを同じ影響分析に活用するというアイデアがありました。そのアイデアから、2つの概念実証ブログエントリ(Githubに関連コードがあります)を作成しました。1つはMavenとJava[2]用、もう1つはPython[3]用です。eejitのように、斬新な発明をしたと思っていましたが、当時はこの分野にかなりの先行技術(上記のMicrosoft)があることを知りませんでした。私が示した手法は、CIインフラストラクチャ内で実行するのにコストがかかる場合でも、ツールチェーン内で開発するのに費用がかかりません。
テスト影響分析のアイデアの単純な実装では、1つの事前アクティビティが必要です。
- 単体テストを実行し、コードカバレッジを収集します。
- テストで扱われた本番ソースファイルから、本番ソース(キー)からテストパス/名前(値)への一時的なマップを作成します。
- マスターマップを含むソースファイルを更新し、そのテストの以前のエントリをすべて置き換えます。
- 変更されたマップソースファイルをVCSにコミットします(問題のCIジョブのみがこれを実行する権限を持つ必要があります)。
- カバレッジデータをクリアします(テストごとのカバレッジレポートが混同されないようにするため)。
- 次のテストについて#1に戻ります(最近変更されたソース/テストを最初に?)。
すべてのテストを一度に1つずつ実行すると、本番コードをカバーするテストに接続する包括的なマップが作成されます。
その後、本番コードに変更を加えた場合、どのテストがそのコードを実行したかを把握できるため、実行時に有益な情報が得られる可能性があります。生成されたテストの失敗は、加えられた変更から発生する可能性のある唯一のテストの失敗であることが証明できます。上記の2つの概念実証には、次のことを試みる少量のPythonコードが含まれています。
- 必要になる前にTIAマップを計算する
- 統合前の状況でTIAマップを使用する(わずかな変更を加えることで、CIジョブでも使用できます)
HedgeServのテストベースは、通常の迅速な単体テストと、Microsoft Excelスプレッドシートである統合テストで構成されており、これらは間接的にPythonを呼び出します。12,000件あります。これらのテストは、何時間もかかる広範で高度なアルゴリズムテストであり、「実行数を減らす」戦略なしでは、CIインフラストラクチャで統合ごとに行うことは不可能です。彼らのDevOpsチームは、概念実証を「Test Reducer」(私がこの技術に付けた最初の名前)として運用化し、最速の順列は現在10分です。素晴らしい改善です。開発者とテストエンジニアは統合前に実行でき、CIインフラストラクチャでも同じことができます。HedgeServのソフトウェア開発担当マネージングディレクターであるKevin Looは、「開発者はより迅速なテスト実行に依存しており、自信が高まったため開発ペースが向上した」と述べています。
汎用コードカバレッジツールが使用されているため、TIAの側面は一度に1つのテストを実行する必要があり、事前にコストがかかります。そのため、分析から得られたマップはソース管理にチェックインされ、段階的に更新されます。そのため、差分が簡潔で意味を持つように、テキスト形式で順序付けられている必要があります。マップをソース管理にチェックインすると、CIインフラストラクチャと、統合前(およびコードレビュー前)にテストの実行数を減らしたいと考えている個々の開発者にもメリットがあります。
このTIA設計には、コードカバレッジツールの性質による制限があります。正確な影響グラフを計算するには、一度に1つのテストのみを実行できます。マップデータを使用するには、「git status」(またはgit show >ハッシュ>)を実行し、出力を解析して「変更/追加/削除」された本番コードソースを見つける必要があります。そして、それらが影響マップのキーであり、実行するテストのリストになります。 「一度に1つのテスト」という制限があるのは、データ収集CIジョブのみであるため、多かれ少なかれ永続的に実行されていると見なします。
ご覧のとおり、テストテクノロジーは、本番コードの主要言語の選択とはまったく異なる場合があります。HedgeServの場合、アルゴリズムテストはソース管理下のMicrosoft Excelファイルにありました(BAも貢献しました)。それが可能であれば、SmartBearのTestComplete、HPのUnified Functional Testing(UFT-以前はQTP)、そしてもちろんSeleniumも可能です。唯一の要件は、テストを一度に1つずつ実行するようにスクリプト化できることです(TIAマップを作成している間)。また、最初の作成後、ある程度の頻度でマップを更新することをコミットする必要があります。CIインフラストラクチャを使用してください。
その後、そのマップデータをどこに格納するかを決定する必要があります。ファイル共有、ドキュメントストア、またはリレーショナルスキーマを選択できます。私は、本番ソース自体と同じリポジトリ/ブランチにあるディレクトリ内のテキストファイルを選択しました(お勧めします)。少なくとも、分岐が機能し(分岐モデルが何であれ)、コードの分岐性を反映した異なる影響マップを持つことができます。
最近、クライアント向けに、システムにKDBとQを使用しているプロジェクトを検討し、テスト時間を短縮する方法についてアドバイスしようとしていました。これらに対応するコードカバレッジ技術がないため、その会話はそこで終わりました。
VectorCAST/QA - アプリケーション
Vector Softwareは、 VectorCAST/QAと呼ばれる製品を開発しました。これは、コードカバレッジを同じ方法で活用して、影響を受けるテスト(およびその他)の実行数を減らすワンストップショップアプリケーションです。彼らのテクノロジーは、主にC、C ++、およびAdaソフトウェアを組み込んだ自動車(および関連)業界に販売されています。この動作モードで動作するVectorCASTも、私の*キッチンシンク*実験よりも前から存在します。Google検索スキルを向上させる必要があります!
VisualStudio用NCrunch
.NETチーム向けのNCrunchは、数年間の開発の後、2011年に立ち上げられました。これは、変更によって破損する可能性が最も高いものを予測するアルゴリズムに基づいて、テストの実行順序を最適化できる、Visual Studioの洗練されたプラグインです。2014年には、変更の影響を受けるテストのみにサブセット化できる追加機能が追加されました。また、2014年には、NCrunchはCIの使用全般と互換性を持つようになりました。具体的には、VisualStudio UIの外部でMsBuildの実行を調整することができ、期待どおりの経過時間の節約を実現できました。生の影響マップデータはバイナリであるためソース管理には保存されませんが、ネットワーク共有で開発者とCIインフラストラクチャ間で共有できます。NCrunchは商用ですが、妥当な開発者ごと(およびテストエンジニアごと)のライセンス料がかかります。CIノードは無料で、NCrunchの作成者であるRemco Mulderは、誰もが何かに2回支払うべきではない、または2017年にDockerなどでCIインフラを拡張したことでペナルティを受けるべきではないことに同意しています。
IDEでのTIAのサポート
Microsoftは、Visual Studioに強力なLive Unit Testing[4]機能も備えており、有効にすると、コードを編集している間でも、影響を受ける単体テストが自動的に実行されます。TIAに関連していますが、これはおそらく別の分析の価値があります。
先月、JetBrainsに機能リクエストを送信して、IDEと同等のTIA機能を作成することを検討しました。私が提起したチケットのトリアージ中に、JetBrainsはそれを2010年の同じトピックに関する別のチケットに接続し、その中でこの機能の一部がすでに実装されているという提案がありました。しかし、試してみても動作させることができませんでした☹️
定義
統合前と統合後
**統合前**アクティビティは、開発者がワークステーションで行うアクティビティであり、ローカル(できれば短期間の)機能ブランチ、小さなコミット(後で1つにまとめられる場合とまとめられない場合があります)、および編集/ビルドサイクルが含まれる場合があります。問題のストーリーカードの「完了」宣言の前です。コミットがコードレビューなどに渡される前です。
**統合後**は、その作業(1つ以上のコミット)がコードレビューを完了し、トランク/マスター/メインラインに戻っている段階です。その後まもなく、すべてのチームメイトがワークステーションにプルできるようになり、おそらくプルする必要があります。
シフトレフトとシフトライト
シフトレフトとは、ソフトウェア開発のバリューストリームの一部であるステップを、タイムライン上で前倒しするプロセスです。手動テストをテスト自動化に置き換えることがその一例です。別の例としては、プロダクトオーナーがバックログ(ストーリートラッカー)に入力する前に頭の中で欠陥を発見する場合が挙げられます。この場合、欠陥とは、トラッカーに機能リクエストとして登録され、最終的に誤った仕様と判断される製品アイデアであり、厳密にはバグではありません。これは偶然に起こることもありますが、新たなプロセスを導入して意図的に行う場合、それはシフトレフトのアジェンダの一部となります。バリー・ベームの「変更コスト曲線」は、このより大きなトピック、つまり、ミスは早期に発見するほど修正コストが低く、本番環境で発見された場合は修正コストが最も高くなることを示しています。実際、「シフトレフト」は業界でちょっとした流行語となっています。企業は、より安価で迅速な方法を模索するということを、別の言い方で説明するためにこの言葉を使用しています。特に継続的インテグレーション、そしてアジャイル、CDなど、一般的に同じ目標を追求しています。
シフトライトとは、単体テストの実行を統合CIビルドごとに高速化するのではなく、「夜間」ビルド(またはそれ以下の頻度)に移動するなど、非アジャイル的なことを行うことです。場合によっては、シフトレフト活動によってリスクが発生することがあり、追加のシフトライトステップによってのみ軽減できます。
この分野における過去の取り組み
Google-Testar (2006)
ミハイル "ミーシャ" ドミトリエフは、2006年にGoogle在籍中にTestarを開発しました。
ミーシャの目標:すべてのテストを実行しない一方で、「経験的にすべて実行する必要がないことを証明できる」と主張すること。
Testarは、バイトコードインストルメンテーションを使用して、各テストのコードカバレッジ、つまり各テストによってどのアプリケーションメソッドが実行されるかを記録します。この情報は、クラスとメソッドのチェックサムとともに、テストデータベース(TDB)に保存されます。以降の呼び出しでは、Testarは開発者がどのクラスとメソッドを変更したかを調べ、更新されたコードをカバーするテストのみを再実行します。実行されるコードが変更されていないため、以前合格した他のテストは再び合格すると想定されます。もちろん、以前不合格だったテストや、新しく追加されたテストは、Testarによって無条件に実行されます。
ミーシャは、「影響を受けない」テストを実行しないことで、平均60〜70%の時間節約になったと報告しています。しかし、この技術には問題がないわけではありません。第一に、節約効果は一定ではありません。たとえば、開発者がほとんどのテストで使用されるメソッドを繰り返し変更する場合、節約効果は小さくなります。第二に、テスト結果がコードだけでなく、リソースファイルなどの外部入力にも依存する場合、ユーザーはこれらのファイルをすべてTestarに明示的に指定する必要があります。このツールは、どのテストが特定のリソースファイルに依存しているかを自動的に判断できず、すべてのテスト、またはユーザーが明示的に指定したテストのみを再実行できます。
ミーシャの考察はこちら:[5]
当時、バイトコードインストルメンテーション用の既製のライブラリはそれほど洗練されておらず、柔軟性に欠けていました。私は、ライブラリが最高品質でない限り、事前に自分のコードをもう少し書いて、後でより多くの自由を得る方が理にかなっていることが多いことに気付きました。
Googleや他の企業での経験に関するミーシャの考察
最終的に、企業がさまざまなテストを実行し、十分なハードウェアリソースを持っている場合、Testarのような技術は最適な選択肢ではないと結論付けました。このシナリオでは、高度な並列化ですべてのテストを実行する方が信頼性が高くなります。ただし、Testarで行われているようなきめ細かい選択的テスト実行は、ニッチなケースでは依然として有効です。たとえば、個々のテストに非常に時間がかかり、並列化や他の手法で高速化できない場合、ハードウェアリソースが限られているが、テストのリソースファイルやその他のコード以外の入力に問題がない場合などです。
誰かがTestarに新しい命を吹き込もうと思えば、Testarは復活できるのではないかと思います。また、Testarは私が発見できた最初のTIAを行う技術ですが、その概念について語られた会議で発表された論文に基づいています。ミーシャは、現在その論文を見つけることができないと言っています。
ProTest:不安定なテストはより早く失敗するべき
2007年、Thoughtworksの同僚であるKent Spillner、Dennis Byrne、Naresh Jainなどが、壊れる可能性が最も高いテストを最初に実行することを目的としたProtestをオープンソース化しました。最も可能性が高いのは、過去の破損統計と、本番ソースまたはテストソースが現在変更されているかどうかの組み合わせでした。最近変更された本番ソースファイルは、テストに影響を与えており、優先順位付けの候補となりました。変更されたテストも候補となります。歴史的に不安定なものと最近変更されたものの共通部分が、カスタムJUnitテストランナーが最初に実行するテストとなります。該当のビルドステップは全体で同じ時間がかかりますが、テスト失敗のニュースはより早く発行できます。これは、CIテクノロジーがビルドステップの終了を待たずに、テストごとにログイベントをリッスンしたり、ログ出力をスクレイピングしたりしているためです。IDE(IntelliJおよびEclipse)に統合されているランナーにも同じことが言えます。
ナレッシュの回想
私たちはASTを構築し、ビジターパターンを使用してコードをウォークスルーし、興味深い統計を収集しました。ProTestの手順は以下のとおりです。
- テスト開始段階で、ProTestはテストと本番クラスのバイトコードを処理して、本番クラスとテストのマッピングを構築します。
- ソースファイルのタイムスタンプに基づいて、ワーキングコピーの変更を計算します。
- これらの変更から、実行する必要があるテストの最小セットを算出し、最初に実行します。
- テストレポートは通常どおり発行され、セットの合否が結果として得られます。
デニスの補足
Kentは、コンドルセ投票戦略(各投票者はすべての候補者のランク付けをする必要がある)に基づいて、任意のプラガブルアルゴリズムに使用できる拡張ポイントを作成しました。私はブートストラップアルゴリズムをいくつか書きました。ASMを使用して依存関係グラフを構築し、変更されたものに近い順にテストをソートするアルゴリズムです。しかし、バージョン1.0には到達しませんでした🤔
ケントはProTestをこのように見ています
マッピングは呼び出し間で保持されませんでした。保持する必要がなかったため、どのテストを実行するかの計算は一貫性があり、非常に高速でした。ProTestに最も近いものは、Kent BeckのJUnit Maxでしたが、それはおそらくDennisがProTestのアイデアを思いついた数年後だったでしょう。ProTestをもっと完成させていればよかったと思っています。今日でも、ProTestのようなものが必要な状況によく遭遇します。ナレッシュはその後、ProTestの開発を続けるためにさらに人を募集しましたが、その努力も行き詰まりました。いつか誰かがマントルを引き継いでくれることを願っています。それがオープンソースの素晴らしさですよね?
JTestMe: "Just Test Me"
同じく2007年、Thoughtworksの他の同僚であるJosh GrahamとGianny Damourは、JTestMeと呼ばれるオープンソース技術に取り組みました。これは、AOPを使用して、本番クラスとそれらを実行するテストのリポジトリを構築するものです。失敗する可能性の高いテストの優先順位付けも目的としていたため、ProTestと非常によく似ています。
ジョシュの回想
ランタイム呼び出し分析を使用する理由は、静的分析はJavaに役立つものの、リフレクション機能を備えたプラットフォームや、静的分析がそれほど簡単ではない言語(当時のJRubyや、最近のClojureなど)を推奨するプラットフォームでは、すべてを明らかにするわけではないからです.
概念実証はシンプルで高速でした。テストスイートの実行中に、すべてのJUnitテストメソッド(つまり、テストケース)にポイントカットを作成しました。そのポイントカットは、テスト以外のクラスの非プライベートメソッドが呼び出されるたびにアドバイスを行いました。そのアドバイスは、クラスのソースファイル名と、その時点で実行されているテストを記録しました.
ソースコードファイル名とテストケースのこのマッピングにより、ソースコードファイルが変更されるたびに、どのテストケースを実行する必要があるかがわかりました。私はこれを「動的に定義されたスモークテスト」と呼びました。CIサーバーでは、リビジョン情報が抽出され、マッピングを照会して、どのテストケースを最初に実行できるかを判断するために使用されました。開発者のローカルマシンでは、inotifyベースのツールがソースコードファイルの変更を通知し、そのクラスに関連するテストケースがサイドプロセスで実行されました。IDEでは、優れたInfinitestとカスタムリスト(JTestMeへのクエリによって継続的に更新される)を使用しました。マッピング自体は、ファイルへの単純なJavaオブジェクトのシリアル化でした。ビルド間でCIのやり直しを省くため、ソース管理にコミットできました。これは、エージェントベースのビルドでは大きな問題になる可能性があります.
ロード時ウィービングを選択したので、テストスイートはインストルメンテーションの有無にかかわらず実行できました(AOPツールが誤ったテスト結果を作成した場合に備えて)。
このアプローチの明らかな欠点は、新しいテストケースが作成されたとき(多くの場合、TDDチームで)、インストルメンテーションされるまでスモークテストの候補として含まれないことです。そのため、開発パイプラインのいくつかの場所で、簡単ですが面倒なコマンドラインの変更が必要でした。この種のアプローチにもっと適した標準ツールがあれば、より多くのチームがメリットを享受できるでしょう。悲しいかな、正確な仕様と検証は、カーゴカルトと流行語を追いかけることに夢中になっているチームでは、非常に過小評価されている資産です.
余談ですが、「Clover」(その後まもなくAtlassianに買収された)を構築したチームは、ProTestの静的分析アプローチと同様のことを行いました.
Wallaby.js: 入力中にJavaScriptの継続的テストを実行
Wallaby.js は、JavaScript 用の商用統合型継続テストツールです。入力と同時にテストを実行し、実行結果(コードカバレッジ、エラー、コンソールメッセージを含む)を IDE/エディターに直接表示します。また、リアルタイムで更新される、見やすいテストとコードカバレッジレポートも提供します。可能な限り高速にテストを実行するために、静的/動的分析と多数のヒューリスティックをテストの並列化と組み合わせて使用します。 Wallaby を開発した Artem Govorov 氏にとっての課題は、すべての互換性を維持するために、テストフレームワークとトランスパイルされた言語のすべてが分析とサポートを必要とすることです。 また、Wallaby は IDE/エディター専用であり、実際に作業中のコードを優先します。 Git や基になるソースファイルを制御する VCS を認識しないため、TIA を使用してテストをサブセット化しません。 とはいえ、純粋な JavaScript テストのスイートで「すべて実行」が十分に速くないと構築されたことはありません。
脚注
1: これらの抜粋は、Pratap とのメールのやり取りからのものです。
2: 前回のブログ記事: 影響を受けるテストのみを実行することでテスト時間を短縮する - Maven & Java 向け。
3: 前回のブログ記事: 影響を受けるテストのみを実行することでテスト時間を短縮する - Python 版。
4: 記事: Microsoft.com の Visual Studio 2017 でのライブ単体テスト。
5: これらのコメントと、この付録のその他の寄稿は、さまざまな寄稿者とのメールからのものです。
主な改訂
2017 年 8 月 22 日: NCrunch と Wallaby.js を含めるように更新されました。
2017 年 8 月 7 日: 初版