
サーバーレスアーキテクチャ
サーバーレスアーキテクチャは、サードパーティの「Backend as a Service」(BaaS)サービスを組み込んだり、「Functions as a Service」(FaaS)プラットフォームで管理された一時的なコンテナでカスタムコードを実行したりするアプリケーション設計です。これらのアイデアや、シングルページアプリケーションなどの関連するアイデアを使用することで、従来の常時稼働型サーバーコンポーネントの必要性を大幅に削減できます。サーバーレスアーキテクチャは、運用コスト、複雑さ、エンジニアリングリードタイムの大幅な削減というメリットがありますが、ベンダー依存の増加と、比較的未成熟なサポートサービスというコストがかかります。
2018年5月22日

Mike Robertsは、クラウドアーキテクチャとその企業やチームへの影響を専門とするコンサルティング会社Symphoniaのパートナー兼共同創設者です。
Mikeは、キャリアの中でエンジニア、CTO、その他様々な職種を経験してきました。彼は長年アジャイルとDevOpsの価値観を支持しており、クラウドテクノロジーが多くの高機能ソフトウェアチームでそのような価値観を実現する上で果たしてきた役割に情熱を注いでいます。彼は、サーバーレスをクラウドシステムの次の進化と捉え、それがチームとその顧客が素晴らしい成果を出すのを支援する能力に興奮しています。
サーバーレスコンピューティング、または簡単にサーバーレスは、ソフトウェアアーキテクチャの世界でホットな話題です。「Big Three」と呼ばれる主要な3つのクラウドベンダー(Amazon、Google、Microsoft)はサーバーレスに多額の投資を行っており、このテーマに特化した多くの書籍、オープンソースプロジェクト、カンファレンス、ソフトウェアベンダーが登場しています。しかし、サーバーレスとは何か、そして検討する価値がある(またはない)のはなぜでしょうか?この記事では、これらの疑問について少しばかり解き明かしたいと考えています。
まず、サーバーレスの「何」について見ていきましょう。このアプローチのメリットとデメリットについては後で詳しく説明します。
サーバーレスとは何か?
ソフトウェアにおける多くのトレンドと同様に、サーバーレスが何かについて明確な見解はありません。まず、それは2つの異なるが重複する領域を包含しています。
- サーバーレスという用語は、サーバー側のロジックと状態を管理するために、サードパーティのクラウドホスト型アプリケーションやサービスを大幅に、または完全に組み込んだアプリケーションを最初に記述するために使用されました。これらは通常、「リッチクライアント」アプリケーション(シングルページWebアプリやモバイルアプリなど)であり、クラウドアクセス可能なデータベース(例:Parse、Firebase)、認証サービス(例:Auth0、AWS Cognito)などを幅広く利用しています。これらのタイプのサービスは以前、「(Mobile) Backend as a Service」と呼ばれており、この記事の残りの部分では「BaaS」という略語を使用します。
- サーバーレスは、サーバー側のロジックがアプリケーション開発者によって記述されるアプリケーションを意味することもありますが、従来のアーキテクチャとは異なり、イベントトリガー型、一時的(1回の呼び出しでしか持続しない可能性がある)、完全にサードパーティによって管理されるステートレスなコンピューティングコンテナで実行されます。これを考える1つの方法は、「Functions as a Service」または「FaaS」です。(注:この名前の元のソースである@marakによるツイートは、現在公開されていません。) AWS Lambdaは現在、Functions-as-a-Serviceプラットフォームの最も人気のある実装の1つですが、他にも多くのものがあります。
この記事では、主にFaaSに焦点を当てます。それは、サーバーレスの中で新しく、多くの話題を呼んでいる分野であるだけでなく、従来の技術アーキテクチャの考え方と大きく異なるからです。
BaaSとFaaSは、運用属性(例:リソース管理なし)において関連しており、頻繁に一緒に使用されます。主要なクラウドベンダーはすべて、BaaSとFaaS製品の両方を含む「サーバーレスポートフォリオ」を提供しています。たとえば、Amazonのサーバーレス製品ページをご覧ください。GoogleのFirebase BaaSデータベースは、Google Cloud Functions for Firebaseを通じて明示的にFaaSをサポートしています。
小規模な企業からも、この2つの分野を結びつける同様の動きが見られます。Auth0は、ユーザー管理の多くの機能を実装したBaaS製品から始まり、その後、コンパニオンFaaSサービスであるWebtaskを作成しました。同社はこのアイデアをExtendでさらに推し進め、他のSaaSおよびBaaS企業が既存の製品にFaaS機能を簡単に追加できるようにして、統合されたサーバーレス製品を作成できるようにしました。
いくつかの例
UI駆動型アプリケーション
従来の3層クライアント指向システムでサーバー側のロジックを考えてみましょう。良い例は、典型的なECアプリです。オンラインペットショップと言えるでしょうか?
従来、アーキテクチャは下の図のようになります。サーバー側ではJavaまたはJavascriptで実装され、クライアントとしてHTML + Javascriptコンポーネントを使用しているとします。

このアーキテクチャでは、クライアントは比較的単純で、システム内の多くのロジック(認証、ページナビゲーション、検索、トランザクション)はサーバーアプリケーションによって実装されます。
サーバーレスアーキテクチャでは、これは次のようになります。

これは非常に簡略化されたビューですが、ここでもいくつかの重要な変更が見られます。
- 元のアプリケーションの認証ロジックを削除し、サードパーティのBaaSサービス(例:Auth0)に置き換えました。
- BaaSの別の例として、クライアントがデータベースのサブセット(製品リスト用)に直接アクセスできるようにしました。これは、サードパーティ(例:Google Firebase)によって完全にホストされています。この方法でデータベースにアクセスするクライアントと、データベースにアクセスするサーバーリソースでは、セキュリティプロファイルが異なる可能性があります。
- 上記の2点は、非常に重要な3点目を意味します。ペットストアサーバーにあったロジックの一部がクライアント内にあるということです。たとえば、ユーザーセッションの追跡、アプリケーションのUX構造の理解、データベースからの読み取りと使用可能なビューへの変換などです。クライアントはシングルページアプリケーションになる一歩手前です。
- 例えば、計算負荷が大きい場合や大量のデータへのアクセスが必要な場合など、UX関連の機能の一部をサーバー側に保持したい場合があります。ペットストアの例では、「検索」機能が該当します。元のアーキテクチャにあった常時稼働サーバーではなく、APIゲートウェイ(後述)を介してHTTPリクエストに応答するFaaS関数を実装できます。クライアントとサーバーの両方の「検索」関数は、製品データについて同じデータベースから読み取ります。
- 最後に、「購入」機能を別のFaaS関数に置き換えることもできます。クライアント側で再実装するのではなく、セキュリティ上の理由からサーバー側に保持することを選択します。これもAPIゲートウェイを介してアクセスされます。異なる論理的な要件を別々にデプロイされたコンポーネントに分割することは、FaaSを使用する場合の非常に一般的なアプローチです。
FaaSプラットフォームとしてAWS Lambdaを使用する場合、LambdaはJavaとJavascript(元の開発言語)をサポートしているので、元のPet Storeサーバーから新しいPet Store検索関数に検索コードを完全な書き換えなしに移植できます。
少し戻って、この例はサーバーレスアーキテクチャに関するもう一つの重要な点を示しています。元のバージョンでは、すべてのフロー、制御、セキュリティは中央サーバーアプリケーションによって管理されていました。サーバーレスバージョンには、これらの懸念事項の中央調整役がありません。代わりに、**オーケストレーションよりもコレオグラフィー**を優先し、各コンポーネントがよりアーキテクチャ的に意識した役割を果たします。これは、マイクロサービスアプローチでも一般的な考え方です。
このようなアプローチには多くの利点があります。Sam Newmanが著書『Building Microservices』で述べているように、このように構築されたシステムは、全体として、そしてコンポーネントへの独立したアップデートを通じて、「より柔軟で変更に適応しやすい」ことが多く、懸念事項の分離が向上し、魅力的なコストメリットもあります。Gojko Adzicがこの優れた講演で論じています。
もちろん、このような設計はトレードオフです。より高度な分散監視(後述)が必要になり、基盤となるプラットフォームのセキュリティ機能に大きく依存します。さらに根本的には、元のモノリシックアプリケーションと比較して、理解すべき移動部分がはるかに多くなります。柔軟性とコストの利点が、複数のバックエンドコンポーネントによる追加の複雑さを上回るかどうかは、コンテキストに大きく依存します。
メッセージ駆動型アプリケーション
別の例として、バックエンドデータ処理サービスがあります。
UIリクエストに迅速に応答する必要があり、同時に、その後の処理のために発生しているさまざまな種類のユーザーアクティビティをすべてキャプチャする必要があるユーザー中心のアプリケーションを作成しているとします。オンライン広告システムを考えてみましょう。ユーザーが広告をクリックすると、その広告のターゲットに非常に迅速にリダイレクトする必要があります。同時に、広告主に請求できるように、クリックが発生したという事実を収集する必要があります。(この例は仮説ではありません。私の以前のチームであるIntent Mediaには、まさにこのニーズがあり、サーバーレスの方法で実装しました。)
従来のアーキテクチャは、以下のようになります。「広告サーバー」はユーザー(図示せず)に同期的に応答し、「クリックメッセージ」をチャネルに投稿します。このメッセージは、データベースを更新する(例えば、広告主の予算を減らす)「クリックプロセッサ」アプリケーションによって非同期的に処理されます。

サーバーレスの世界では、次のようになります。

違いがわかりますか?アーキテクチャの変更は、最初の例と比較してはるかに小さいです。これが、非同期メッセージ処理がサーバーレステクノロジーの非常に一般的なユースケースである理由です。長期間稼働するメッセージコンシューマのアプリケーションをFaaSの関数に置き換えました。この関数は、ベンダーが提供するイベント駆動型コンテキスト内で実行されます。クラウドプラットフォームベンダーは、メッセージブローカーとFaaS環境の両方を提供します。これら2つのシステムは密接に関連しています。
FaaS環境は、関数のコードのコピーを複数インスタンス化することで、複数のメッセージを並列処理することもできます。元のプロセスをどのように記述したかによっては、考慮する必要がある新しい概念になる可能性があります。
「Function as a Service」の解説
すでにFaaSについて何度も言及していますが、それが実際に何を意味するのかを掘り下げる時間です。そのためには、AmazonのFaaS製品であるLambdaの導入説明を見てみましょう。いくつかのトークンを追加し、それについて詳しく説明します。
AWS Lambdaを使用すると、サーバーのプロビジョニングや管理なしにコードを実行できます。(1) ...Lambdaを使用すると、事実上あらゆる種類のアプリケーションやバックエンドサービスのコードを実行できます(2) - すべて管理なしで。コードをアップロードするだけで、Lambdaは実行に必要なすべて(3)と、高可用性でのスケーリング(4)を処理します。他のAWSサービスから自動的にトリガーされるようにコードを設定したり(5)、任意のウェブまたはモバイルアプリから直接呼び出したりできます(6)。
- **基本的に、FaaSは独自のサーバーシステムや長期間稼働するサーバーアプリケーションを管理せずにバックエンドコードを実行することです。** 2番目の句 - 長期間稼働するサーバーアプリケーション - は、コンテナやPaaS(Platform as a Service)などの他の最新のアーキテクチャトレンドと比較する場合の重要な違いです。
- FaaSオファリングでは、特定のフレームワークやライブラリへのコーディングは必要ありません。FaaS関数は、言語と環境に関して、通常のアプリケーションです。例えば、AWS Lambda関数は、Javascript、Python、Go、任意のJVM言語(Java、Clojure、Scalaなど)、または任意の.NET言語で「ファーストクラス」で実装できます。ただし、Lambda関数はデプロイメントアーティファクトにバンドルされた別のプロセスを実行することもできるので、Unixプロセスにコンパイルできる言語であれば実際には何でも使用できます(この記事の後半でApexを参照)。
- デプロイメントは、自分で実行するサーバーアプリケーションがないため、従来のシステムとは大きく異なります。FaaS環境では、関数のコードをFaaSプロバイダーにアップロードし、プロバイダーはリソースのプロビジョニング、VMのインスタンス化、プロセスの管理など、その他すべてを処理します。
- 水平スケーリングは完全に自動化され、弾力性があり、プロバイダーによって管理されます。システムが100個のリクエストを並列処理する必要がある場合、プロバイダーは追加の構成なしでそれを処理します。関数を実行する「コンピューティングコンテナ」は一時的なもので、FaaSプロバイダーは実行時のニーズに基づいてそれらを純粋に作成および破棄します。最も重要なのは、FaaSではベンダーがすべての基盤となるリソースのプロビジョニングと割り当てを処理するということです。ユーザーはクラスタやVMの管理をまったく行う必要がありません。
- FaaSの関数は、通常、プロバイダーによって定義されたイベントタイプによってトリガーされます。Amazon AWSでは、このような刺激には、S3(ファイル/オブジェクト)の更新、時間(スケジュールされたタスク)、メッセージバスに追加されたメッセージ(例えば、Kinesis)などがあります。
- ほとんどのプロバイダーは、インバウンドHTTPリクエストへの応答として関数をトリガーすることも許可しています。AWSでは、通常、APIゲートウェイを使用してこれを有効にします。「検索」関数と「購入」関数では、Pet Storeの例でAPIゲートウェイを使用しました。関数は、プラットフォームが提供するAPIを介して、外部からでも、同じクラウド環境内からでも直接呼び出すことができますが、これは比較的まれな使用方法です。
前のクリック処理の例に戻ると、FaaSはクリック処理サーバー(物理マシンである可能性がありますが、特定のアプリケーションであることは確かです)を、プロビジョニングされたサーバーも、常に実行されているアプリケーションも必要としないものに置き換えます。
ただし、FaaS関数には、特に状態と実行時間に関連して、重要なアーキテクチャ上の制限があります。すぐにそれについて説明します。
もう一度クリック処理の例を考えてみましょう。FaaSに移行する際に変更が必要なコードは、「mainメソッド」(スタートアップ)コードだけで、削除され、おそらく最上位のメッセージハンドラ(「メッセージリスナーインターフェース」の実装)である特定のコードも変更されますが、これはメソッドシグネチャの変更だけかもしれません。残りのコード(例えば、データベースに書き込むコード)は、FaaSの世界では変わりません。
クリックプロセッサに戻りましょう。好調で、通常よりも10倍多くの広告がクリックされているとします。従来のアーキテクチャの場合、クリック処理アプリケーションはこの状況に対処できますか?例えば、一度に複数のメッセージを処理できるようにアプリケーションを開発しましたか?開発したとしても、アプリケーションの実行インスタンス1つで負荷を処理できますか?複数のプロセスを実行できる場合、自動スケーリングは自動ですか、それとも手動で再構成する必要がありますか?FaaSアプローチでは、これらの質問すべてにすでに回答されています。事前に水平スケーリングされた並列処理を想定して関数を記述する必要がありますが、そこから先はFaaSプロバイダーがすべてのスケーリングニーズを自動的に処理します。
状態
FaaS関数は、ローカル(マシン/インスタンスにバインドされた)状態(つまり、メモリ内の変数に格納するデータ、またはローカルディスクに書き込むデータ)に関して、大きな制限があります。そのようなストレージは利用できますが、複数の呼び出し間でその状態が保持されるとは保証されず、さらに強く、関数の1回の呼び出しの状態が同じ関数の別の呼び出しで使用できると想定すべきではありません。そのため、FaaS関数はステートレスと呼ばれることがよくありますが、永続的である必要があるFaaS関数の状態は、FaaS関数インスタンスの外部に外部化する必要があると言う方が正確です。
本質的にステートレスなFaaS関数(つまり、入力を出力に純粋に機能的に変換する関数)の場合、これは問題になりません。しかし、他の関数の場合、これはアプリケーションアーキテクチャに大きな影響を与える可能性がありますが、これはユニークなものではありません。「Twelve-Factor app」の概念にはまったく同じ制限があります。このような状態指向の関数は、通常、データベース、アプリケーション間キャッシュ(Redisなど)、またはネットワークファイル/オブジェクトストレージ(S3など)を使用して、リクエスト間で状態を格納したり、リクエストを処理するために必要なさらなる入力を提供したりします。
実行時間
FaaS関数は、各呼び出しの実行が許可される時間の長さに制限があります。現在、AWS Lambda関数がイベントに応答するための「タイムアウト」は、終了する前に最長5分です。Microsoft AzureとGoogle Cloud Functionsにも同様の制限があります。
これは、アーキテクチャの再設計なしではFaaS関数に適さない長期間のタスクの特定のクラスがあることを意味します。従来の環境では1つの長期間タスクで調整と実行の両方を同時に行うことができるのに対し、複数の異なる調整されたFaaS関数を作成する必要がある場合があります。
起動遅延と「コールドスタート」
FaaSプラットフォームは、各イベントの前に関数のインスタンスを初期化するのに時間がかかります。このスタートアップレイテンシは、特定の関数でも、多くの要因によって大きく異なり、数ミリ秒から数秒の範囲になる可能性があります。悪く聞こえますが、AWS Lambdaを例に、もう少し具体的に見てみましょう。
Lambda関数の初期化は、「ウォームスタート」(前のイベントからLambda関数とそのホストコンテナのインスタンスを再利用する)または「コールドスタート」(新しいコンテナインスタンスを作成し、関数ホストプロセスを開始するなど)のいずれかになります。当然のことながら、スタートアップレイテンシを考慮すると、これらのコールドスタートが最も懸念事項となります。
コールドスタートのレイテンシは、使用する言語、使用するライブラリの数、コードの量、Lambda関数環境自体の構成、VPCリソースに接続する必要があるかどうかなど、多くの変数によって異なります。これらの側面の多くは開発者の制御下にあるため、コールドスタートで発生するスタートアップレイテンシを削減することが可能です。
コールドスタートの期間と同様に、コールドスタートの頻度も変数です。例えば、関数が毎秒10個のイベントを処理し、各イベントの処理に50ミリ秒かかる場合、Lambdaでは約10万〜20万イベントごとにコールドスタートが発生する可能性があります。一方、1時間に1回イベントを処理する場合、Amazonは数分後に非アクティブなLambdaインスタンスを終了するため、すべてのイベントでコールドスタートが発生する可能性があります。これを理解することで、コールドスタートが全体としてどのように影響するか、そしてコールドスタートを回避するために関数のインスタンスの「キープアライブ」を実行する必要があるかどうかを理解できます。
コールドスタートは懸念事項でしょうか?それは、アプリケーションのスタイルとトラフィックの形状によって異なります。Intent Mediaでの私の以前のチームでは、Java(通常は起動時間が最も遅い言語)で実装された非同期メッセージ処理Lambdaアプリケーションがあり、これは1日に数億件のメッセージを処理しますが、このコンポーネントの起動レイテンシについては懸念していません。とは言え、低レイテンシの取引アプリケーションを作成する場合、実装に使用する言語に関係なく、現時点ではクラウドホスト型FaaSシステムを使用したくないでしょう。
アプリケーションにこのような問題が発生するかどうかを判断するには、本番環境のような負荷でパフォーマンスをテストする必要があります。ユースケースが現在機能しない場合は、数ヶ月後に再度試すことができます。これは、FaaSベンダーによる継続的な改善の主要な分野であるためです。
コールドスタートの詳細については、このトピックに関する私の記事を参照してください。
APIゲートウェイ

以前に簡単に触れたサーバーレスの1つの側面は、「APIゲートウェイ」です。APIゲートウェイは、ルートとエンドポイントが構成で定義されたHTTPサーバーであり、各ルートは、そのルートを処理するリソースに関連付けられています。サーバーレスアーキテクチャでは、このようなハンドラーは多くの場合、FaaS関数です。
APIゲートウェイがリクエストを受信すると、リクエストに一致するルーティング構成を見つけ、FaaSバックエンドのルートの場合は、元のリクエストを表す情報と共に関連するFaaS関数を呼び出します。通常、APIゲートウェイは、HTTPリクエストパラメーターからFaaS関数のより簡潔な入力へのマッピングを許可するか、通常はJSONオブジェクトとして、HTTPリクエスト全体を通過させることを許可します。FaaS関数はロジックを実行し、結果をAPIゲートウェイに返し、APIゲートウェイは結果を変換して、元の呼び出し元に返すHTTPレスポンスにします。
Amazon Web Servicesには独自のAPIゲートウェイ(やや紛らわしいことに「API Gateway」という名前)があり、他のベンダーも同様の機能を提供しています。AmazonのAPI Gatewayは、それ自体が構成する必要があるものの、自分で実行またはプロビジョニングする必要がない外部サービスであるため、BaaS(そうです、BaaS!)サービスです。
リクエストのルーティング以外にも、APIゲートウェイは、認証、入力検証、レスポンスコードマッピングなどを実行することもできます。(これが本当に良いアイデアかどうかを検討するときに、あなたのスパイダーセンスがくすぐられる場合は、その考えを保留してください!後で詳しく検討します。)
FaaS関数を使用したAPIゲートウェイの1つのユースケースは、FaaS関数から得られるスケーリング、管理、その他のメリットをすべて備えた、サーバーレスの方法でHTTPフロントエンドのマイクロサービスを作成することです。
この記事を最初に書いたとき、少なくともAmazonのAPI Gatewayのツールは非常に未熟でした。それ以来、そのようなツールは大幅に改善されています。AWS API Gatewayのようなコンポーネントはまだ完全に「主流」ではありませんが、以前よりも少し使いやすくなっており、今後も改善を続けるでしょう。
ツール
ツールの成熟度に関する上記のコメントは、サーバーレスFaaS全般にも当てはまります。2016年は状況がかなり困難でしたが、2018年には目覚ましい改善が見られ、ツールはさらに改善されると予想されます。
FaaSの世界における優れた「開発者UX」の注目すべき例を2つ紹介します。まず、Auth0 Webtaskは、ツールの開発者UXを最優先事項としています。2つ目は、Azure Functions製品を備えたMicrosoftです。Microsoftは常に、緊密なフィードバックループを備えたVisual Studioを開発製品の最前線に置いており、Azure Functionsも例外ではありません。クラウドトリガーイベントからの入力を受け付けて、関数をローカルでデバッグできる機能は非常に優れています。
まだ大幅な改善が必要な分野は監視です。後でそれについて説明します。
オープンソース
これまで、主に独自のベンダー製品とツールについて説明してきました。サーバーレスアプリケーションの大部分はこれらのサービスを使用していますが、この分野にはオープンソースプロジェクトもあります。
サーバーレスにおけるオープンソースの最も一般的な用途は、FaaSツールとフレームワーク、特に人気の高いServerless Frameworkです。これは、AWSが提供するツールを使用するよりもAWS API GatewayとLambdaの操作を容易にすることを目的としています。また、一部のユーザーにとって貴重なクロスベンダーツールの抽象化も提供します。同様のツールの例としては、ClaudiaやZappaなどがあります。もう1つの例はApexで、これはAmazonが直接サポートする言語以外の言語でLambda関数を開発できるため特に興味深いです。
しかし、大手ベンダー自身もオープンソースツールのパーティーで遅れをとっていません。AWS独自のデプロイメントツールであるSAM(Serverless Application Model)もオープンソースです。
独自のFaaSの主な利点の1つは、基盤となるコンピューティングインフラストラクチャ(マシン、VM、コンテナーを含む)を気にする必要がないことです。しかし、そのようなことを気にする必要がある場合はどうでしょうか?クラウドベンダーでは満たすことができないセキュリティ上のニーズがある場合、またはすでに購入済みで廃棄したくないサーバーラックがいくつかある場合があります。これらのシナリオでは、オープンソースが役立ち、独自の「Serverful」FaaSプラットフォームを実行できますか?
はい、この分野では多くの活動が行われています。オープンソースFaaSの初期リーダーの1つはIBM(OpenWhisk、現在はApacheプロジェクト)であり、驚くべきことに(少なくとも私にとっては!)Microsoftは、Azure Functionsプラットフォームの多くをオープンソース化しました。他の多くのセルフホスト型FaaS実装は、基盤となるコンテナープラットフォーム(多くの場合Kubernetes)を使用しており、多くの理由から理にかなっています。Galactic Fog、Fission、OpenFaaSのようなプロジェクトを検討する価値があります。これは大きく、急速に変化する世界であり、Cloud Native Computing Federation(CNCF)のServerless Working Groupが行った作業を調べることをお勧めします。
サーバーレスではないもの
この記事ではこれまで、サーバーレスを2つのアイデアの組み合わせとして説明してきました。Backend as a ServiceとFunctions as a Serviceです。また、後者の機能についても詳しく説明しました。サーバーレスサービスの重要な属性(およびS3のような古いサービスをサーバーレスと見なす理由)に関するより正確な情報については、私の別の記事を参照してください。Defining Serverless
メリットとデメリットという非常に重要な分野について検討する前に、定義についてもう1つ簡単に説明したいと思います。サーバーレスとは何かを定義しましょう。
PaaSとの比較
サーバーレスFaaS関数はTwelve-Factorアプリケーションと非常によく似ているため、"Platform as a Service"(PaaS)であるHerokuの別の形式にすぎませんか?簡潔な回答として、Adrian Cockcroftを参照します。
PaaSが0.5秒間実行されるインスタンスを20msで効率的に起動できる場合は、サーバーレスと呼びましょう。
つまり、ほとんどのPaaSアプリケーションは、イベントに応じてアプリケーション全体を起動および停止するように設計されていませんが、FaaSプラットフォームはまさにそれを行います。
優れたTwelve-Factorアプリケーション開発者であれば、これは必ずしもアプリケーションのプログラミングやアーキテクチャに影響を与えませんが、アプリケーションの運用方法には大きな違いがあります。私たちは皆、優れたDevOpsに精通したエンジニアであるため、開発と同じくらい運用についても考えていますよね?
FaaSとPaaSの主な運用上の違いはスケーリングです。一般的に、PaaSでは、スケーリング方法について依然として考える必要があります。たとえば、Herokuでは、実行するDynosの数について考える必要があります。FaaSアプリケーションでは、これは完全に透過的です。PaaSアプリケーションを自動スケールするように設定した場合でも、非常に特殊なトラフィックプロファイルでない限り、個々のリクエストレベルでこれを行うことはなく、FaaSアプリケーションの方がコスト効率がはるかに優れています。
この利点を考えると、なぜPaaSを使用するのでしょうか?理由はいくつかありますが、ツールが最も大きな理由でしょう。また、一部の人はCloud FoundryなどのPaaSプラットフォームを使用して、ハイブリッドパブリッククラウドとプライベートクラウド全体で共通の開発エクスペリエンスを提供します。執筆時点では、これほど成熟したFaaS同等物は存在しません。
コンテナとの比較
サーバーレスFaaSを使用する理由の1つは、オペレーティングシステムレベルでのアプリケーションプロセスの管理を回避することです。HerokuなどのPaaSサービスもこの機能を提供し、上記でPaaSがサーバーレスFaaSとどのように異なるかを説明しました。プロセスのもう1つの一般的な抽象化はコンテナーであり、Dockerはそのようなテクノロジーの最も目に見える例です。個々のアプリケーションをOSレベルのデプロイメントから抽象化するMesosやKubernetesなどのコンテナーホスティングシステムは、ますます人気が高まっています。さらに進んで、サーバーレスFaaSと同様に、チームが独自のサーバーホストを管理する必要がないAmazon ECSやEKS、Google Container Engineなどのクラウドホスティングコンテナープラットフォームを見てみましょう。コンテナーに関する勢いを考えると、サーバーレスFaaSを検討する価値はまだありますか?
主に、PaaSについて行った議論は、コンテナーでも依然として有効です。サーバーレスFaaSの場合、スケーリングは自動的に管理され、透過的で、きめ細かいものであり、これは前に述べた自動リソースのプロビジョニングと割り当てに関連付けられています。コンテナープラットフォームでは、従来からクラスターのサイズと形状を管理する必要がありました。
また、コンテナーテクノロジーはまだ成熟しておらず安定しているとは言えませんが、それに近づきつつあるとも主張します。もちろん、サーバーレスFaaSが成熟しているわけではありませんが、どの粗いエッジを選択するかは依然として重要なことです。
また、自己スケーリングコンテナーのクラスターは、現在コンテナープラットフォームで使用できることも言及しておくことが重要です。Kubernetesには「Horizontal Pod Autoscaling」が組み込まれており、AWS Fargateなどのサービスも「サーバーレスコンテナー」を約束しています。
サーバーレスFaaSとホスト型コンテナの管理とスケーリングのギャップが狭まっていることから、両者の選択はアプリケーションのスタイルと種類に左右されるようになるでしょう。例えば、イベント駆動型でアプリケーションコンポーネントごとのイベントの種類が少ない場合はFaaSが、同期リクエスト駆動型で多くのエントリポイントを持つコンポーネントの場合はコンテナがより良い選択肢と見なされるかもしれません。比較的短期間のうちに、多くのアプリケーションとチームが両方のアーキテクチャアプローチを使用するようになり、そのような使用方法のパターンが現れるのは興味深いでしょう。
#NoOps
サーバーレスは「運用不要」という意味ではありません。ただし、サーバーレスの深みにどれほど深く入り込むかによって、「システム管理不要」という意味になるかもしれません。
「運用」はサーバー管理以上の多くのことを意味します。少なくとも、監視、デプロイ、セキュリティ、ネットワーク、サポート、そして多くの場合、ある程度の運用時のデバッグとシステムスケーリングも含まれます。これらの問題はサーバーレスアプリでも依然として存在し、それらに対処するための戦略が必要になります。ある意味、これらの多くが非常に新しいものであるため、サーバーレスの世界では運用はより困難です。
システム管理自体は依然として行われています。サーバーレスではそれをアウトソーシングしているだけです。それは必ずしも悪い(または良い)ことではありません。私たちは多くのことをアウトソーシングしており、その良し悪しは、正確に何をしようとしているかによって異なります。いずれにしても、抽象化は最終的に漏洩する可能性があり、どこかで人間のシステム管理者があなたのアプリケーションをサポートしていることを知る必要があります。
Charity Majors氏は、最初のServerlessconfでこのトピックに関する素晴らしい講演を行いました。(彼女の2つの記事も読むことができます:WTF is operations? と Operational Best Practices。)
Stored Procedures as a Service
サーバーレスサービスは、すぐに大きな技術的負債に変わる良いアイデアであるストアドプロシージャのようなものになるのだろうか。
私が見てきたもう一つのテーマは、サーバーレスFaaSが「ストアドプロシージャ・アズ・ア・サービス」であるということです。これは、FaaS関数の多くの例(この記事で使用した例もいくつかあります)が、データベースと緊密に統合された小さなコード片であるという事実から来ていると思います。それがFaaSに使用できるすべてであれば、その名前は有用だと思いますが、それはFaaSの能力のごく一部に過ぎないため、FaaSをそのような観点から考えることは有用ではないと思います。
とは言え、FaaSには、Camilleが上記のツイートで言及している技術的負債の問題など、ストアドプロシージャと同じような問題がいくつか伴うかどうかを検討する価値があります。ストアドプロシージャの使用から得られる多くの教訓は、FaaSの文脈で検討し、適用されるかどうかを確認する価値があります。ストアドプロシージャは
- 多くの場合、ベンダー固有の言語、または少なくともベンダー固有のフレームワーク/言語拡張機能を必要とします。
- データベースのコンテキストで実行する必要があるため、テストが困難です。
- バージョン管理が難しく、第一級のアプリケーションとして扱うことが困難です。
これらがすべてのストアドプロシージャの実装に必ずしも適用されるとは限りませんが、確かに遭遇する可能性のある問題です。FaaSにも適用されるかどうかを見てみましょう。
(1)は、これまで私が見たFaaSの実装では明らかに懸念事項ではないため、すぐにリストから削除できます。
(2)については、「単なるコード」を扱っているため、ユニットテストは他のコードと同様に簡単です。しかし、統合テストは別の話であり(正当な懸念事項ですが)、後で説明します。
(3)については、FaaS関数は「単なるコード」であるため、バージョン管理は問題ありません。最近まではアプリケーションのパッケージングも懸念事項でしたが、AmazonのServerless Application Model (SAM)や先に述べたServerless Frameworkなどのツールが登場したことで、成熟しつつあります。2018年の初めには、AmazonはAWSサーバーレスサービス上に構築されたアプリケーションやアプリケーションコンポーネントを配布する方法を提供する「Serverless Application Repository (SAR)」も開始しました。(SARについては、適切なタイトルの記事Examining the AWS Serverless Application Repositoryをご覧ください。)
メリット
これまで、主にサーバーレスアーキテクチャが何を意味するのかを定義し、説明することに努めてきました。今度は、そのようなアプリケーションの設計と展開方法の利点と欠点について説明します。サーバーレスを使用する決定は、利点と欠点を十分に考慮して行うべきです。
虹とユニコーンの国から始め、サーバーレスの利点を見てみましょう。
運用コストの削減
サーバーレスは、最も単純に言えば、アウトソーシングソリューションです。自分で管理する可能性のあるサーバー、データベース、さらにはアプリケーションロジックの管理を誰かに委託することができます。多くの人が使用する事前定義されたサービスを使用しているため、規模の経済効果が見られます。つまり、1つのベンダーが数千もの非常に類似したデータベースを実行しているため、管理対象データベースのコストが削減されます。
コスト削減は、2つの側面の合計として表示されます。1つは、インフラストラクチャ(ハードウェア、ネットワークなど)を他の人と共有することから得られるインフラストラクチャコストの削減です。もう1つは人件費の削減です。自分で開発およびホストする同等のシステムよりも、アウトソーシングされたサーバーレスシステムに費やす時間を短縮できます。
しかし、この利点は、Infrastructure as a Service (IaaS)やPlatform as a Service (PaaS)から得られるものとあまり変わりません。しかし、サーバーレスBaaSとFaaSのそれぞれについて、この利点を2つの重要な方法で拡張できます。
BaaS:開発コストの削減
IaaSとPaaSは、サーバーとオペレーティングシステムの管理をコモディティ化できるという前提に基づいています。一方、サーバーレスBackend as a Serviceは、アプリケーションコンポーネント全体がコモディティ化された結果です。
認証はその良い例です。多くのアプリケーションは独自の認証機能をコード化しており、サインアップ、ログイン、パスワード管理、その他の認証プロバイダーとの統合などの機能が含まれることがよくあります。全体として、このロジックはほとんどのアプリケーションで非常に似ており、Auth0などのサービスは、私たちが自分で開発する必要なく、すぐに使える認証機能をアプリケーションに統合できるようにするために作成されました。
FirebaseのデータベースサービスのようなBaaSデータベースも同様です。一部のモバイルアプリケーションチームは、クライアントがサーバー側のデータベースと直接通信することが理にかなっていると判断しています。BaaSデータベースは、データベース管理のオーバーヘッドの大部分を削減し、通常、サーバーレスアプリで期待されるパターンに従って、さまざまなタイプのユーザーに対して適切な承認を実行するメカニズムを提供します。
あなたのバックグラウンドによっては、これらのアイデアに違和感を感じるかもしれませんが(おそらく欠点のセクションで説明する理由からですが)、独自のサーバーサイドコードをほとんど使用せずに魅力的な製品を生み出せた成功企業の数は否定できません。Joe Emison氏は、最初のServerless Conferenceでこのことについていくつかの例を挙げました。
FaaS:スケーリングコスト
サーバーレスFaaSの利点の1つは、この記事の冒頭で述べたように、「水平スケーリングは完全に自動化され、弾力性があり、プロバイダーによって管理される」ことです。これにはいくつかの利点がありますが、基本的なインフラストラクチャの面では、**最大の利点は、必要なコンピューティングリソースに対してのみ料金を支払うこと**です。AWS Lambdaの場合、100ms単位で料金が計算されます。トラフィックの規模と形状によっては、これは大きな経済的メリットとなります。
例:断続的なリクエスト
1分間に1つのリクエストしか処理しないサーバーアプリケーションを実行しているとします。各リクエストの処理には50msかかり、1時間あたりの平均CPU使用率は0.1%です。このアプリケーションが独自の専用ホストにデプロイされている場合、これは非常に非効率です。他の1000個の同様のアプリケーションは、すべてその1台のコンピューターを共有できます。
サーバーレスFaaSはこの非効率性を解消し、コスト削減という形でそのメリットをユーザーに提供します。上記の例では、1分間に100msのコンピューティングリソースに対してのみ料金を支払うことになります。これは、全体時間の0.15%です。
これには、次の追加の利点があります。
- 負荷要件が非常に小さいマイクロサービスについては、そのような細かい粒度の運用コストがそうでなければ法外であったとしても、ロジック/ドメイン別にコンポーネントを分割することをサポートします。
- このようなコストメリットは、優れた民主化要因となります。企業やチームが新しいものを試したい場合、コンピューティングニーズにFaaSを使用すると、「水を試す」ことにかかわる運用コストが非常に小さくなります。実際、総ワークロードが比較的少ない場合(ただし全く無視できるほどではない場合)、一部のFaaSベンダーが提供する「無料枠」により、コンピューティングリソースの料金を支払う必要がない可能性があります。
例:不安定なトラフィック
別の例を見てみましょう。トラフィックプロファイルが非常にスパイク状であるとします。たとえば、基本的なトラフィックは1秒あたり20リクエストですが、5分ごとに10秒間、通常の数(1秒あたり20リクエスト)の10倍である1秒あたり200リクエストを受信するとします。また、この例のために、基本的なパフォーマンスが優先されるホストサーバータイプの上限に達しており、トラフィックスパイクフェーズ中の応答時間を短縮したくないと仮定しましょう。これをどのように解決しますか?
従来の環境では、スパイクに対処するために、そうでなければ必要な数の10倍のハードウェア数を増やす必要があるかもしれません。これは、スパイクの総継続時間がマシンの総稼働時間の4%未満である場合でも同様です。サーバーの新しいインスタンスの起動に時間がかかるため、自動スケーリングはここでは適切な選択肢ではない可能性があります。新しいインスタンスが起動するまでに、スパイクフェーズは終了しているでしょう。
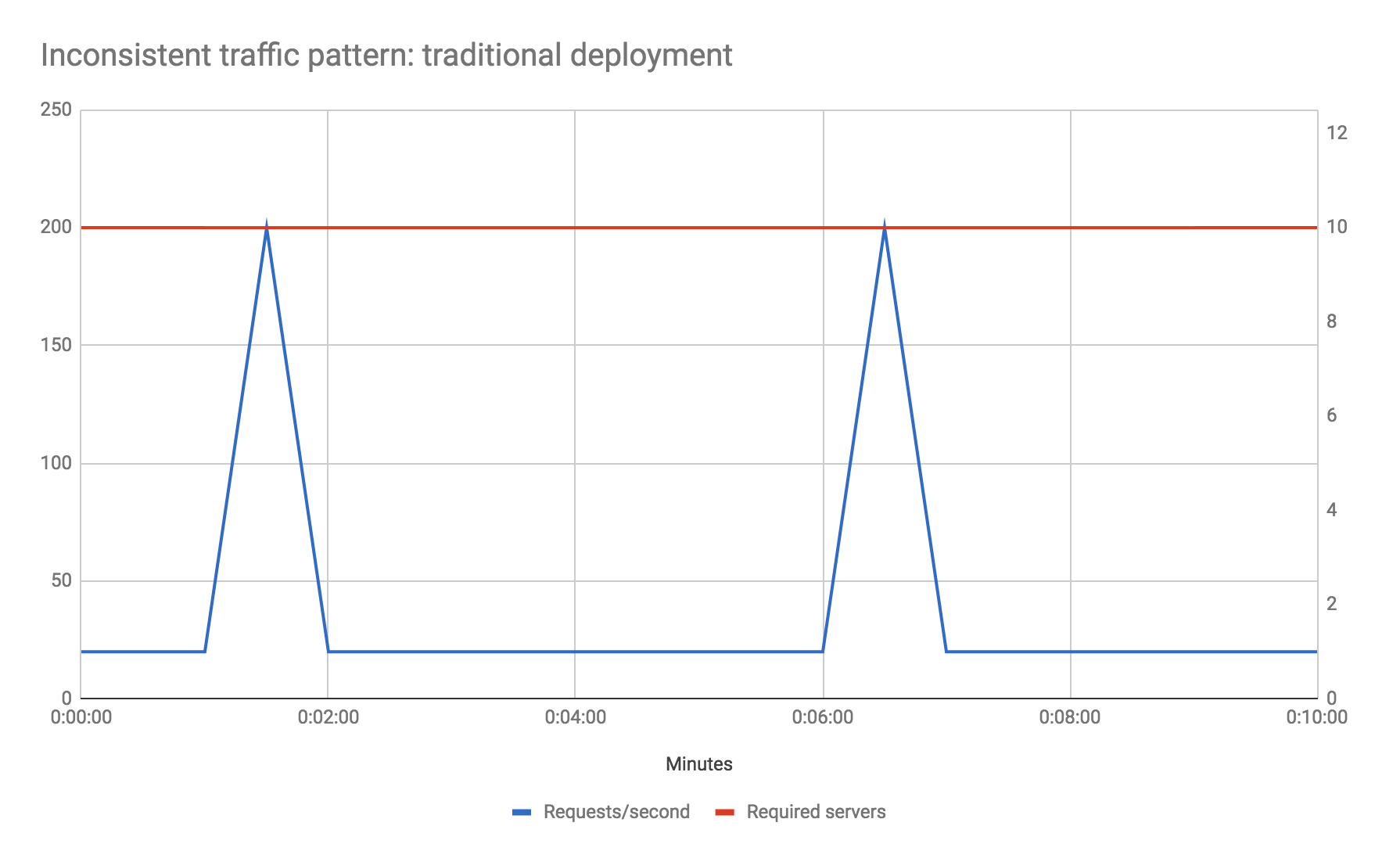
しかし、サーバーレスFaaSを使用すると、これは問題になりません。トラフィックプロファイルが均一な場合と全く同じように動作し、スパイクフェーズ中の追加のコンピューティング容量に対してのみ料金を支払います。
明らかに、ここではサーバーレスFaaSが大幅なコスト削減をもたらす例を意図的に選択していますが、重要なのは、スケーリングの観点から、サーバーホストの容量全体を常に使用する非常に安定したトラフィック形状でない限り、FaaSを使用することでコストを削減できる可能性があることを示すことです。
上記の注意点は、トラフィックが均一であり、稼働中のサーバーを常に適切に使用する場合、このコストメリットは見られない可能性があり、実際にはFaaSを使用することでコストが増加する可能性があることです。現在のプロバイダーのコストとフルタイムでサーバーを実行する同等のものを比較して、コストが許容範囲内かどうかを確認するために計算を行う必要があります。
FaaSのコストメリットの詳細については、Gojko Adzic氏とRobert Chatley氏による論文「Serverless Computing: Economic and Architectural Impact」をお勧めします。
最適化はコスト削減の根幹
FaaSのコストに関して、もう一つ興味深い点があります。コードのパフォーマンス最適化を行うと、アプリケーションの速度が向上するだけでなく、ベンダーの課金体系の粒度に応じて、運用コストの削減にも直接的に、そして即座に繋がります。たとえば、アプリケーションがイベントを処理するのに1秒かかるとします。コードの最適化によってこれを200msに削減した場合、(AWS Lambdaでは)インフラストラクチャに変更を加えることなく、即座に計算コストを80%削減できます。
運用管理の容易化
次のセクションは大きなアスタリスク付きです。サーバーレスでは運用上のいくつかの側面が依然として難しいですが、ここではユニコーンと虹の友達と共に進めていきます…
サーバーレスBaaS側では、運用管理が他のアーキテクチャよりもシンプルである理由はかなり明白です。サポートするコンポーネントが少ないほど、作業量が少なくなります。
FaaS側では、いくつかの側面が関わっており、そのうちいくつかを詳しく見ていきます。
インフラストラクチャコストを超えたFaaSのスケーリングメリット
前のセクションでスケーリングについて説明したばかりですが、FaaSのスケーリング機能は計算コストを削減するだけでなく、スケーリングが自動化されるため、運用管理も削減できることに注意する価値があります。
最適なケースでは、スケーリングプロセスが手動の場合(たとえば、人間が明示的にサーバーの配列にインスタンスを追加および削除する必要がある場合)、FaaSではそれを忘れて、FaaSベンダーにアプリケーションのスケーリングを任せることができます。
非FaaSアーキテクチャで自動スケーリングを使用するようになったとしても、それでも設定とメンテナンスが必要です。この作業はFaaSでは不要になります。
同様に、スケーリングはプロバイダーによってすべてのリクエスト/イベントで実行されるため、**メモリ不足になったり、パフォーマンスに大きな影響が出たりする前に、処理できる同時リクエスト数の問題について考える必要がなくなります。**少なくともFaaSでホストされているコンポーネント内では。ダウンストリームのデータベースや非FaaSコンポーネントは、負荷の著しい増加を考慮して再検討する必要があります。
パッケージングとデプロイの複雑さの軽減
FaaS関数のパッケージ化とデプロイは、サーバー全体をデプロイするよりも簡単です。行うのは、すべてのコードをzipファイルにパッケージ化してアップロードすることだけです。Puppet/Chefも、start/stopシェルスクリプトも、マシンにコンテナを1つまたは複数デプロイするかどうかについての決定もありません。初めての場合は、何もパッケージ化する必要はありません。ベンダーのコンソール自体でコードを記述できる場合もあります(これは、本番コードにはお勧めできません!)。
このプロセスは説明するのに時間はかかりませんが、一部のチームにとってはこの利点が非常に大きいかもしれません。**完全にサーバーレスなソリューションでは、システム管理が不要になります。**
PaaSソリューションにも同様のデプロイメント上の利点がありますが、前述のように、PaaSとFaaSを比較した場合、スケーリングの利点はFaaS特有です。
市場投入時間と継続的な実験
運用管理の容易さは、エンジニアとして私たちが理解している利点ですが、ビジネスにとってそれはどういう意味でしょうか?
明白な理由はコストです。運用に費やす時間が少なくなれば、運用に必要な人員も少なくなります。すでに説明したとおりです。しかし、私の考えでは、はるかに重要な理由は市場投入時間です。チームと製品がリーンでアジャイルなプロセスを重視するようになるにつれて、私たちは継続的に新しいことを試み、既存のシステムを迅速に更新したいと考えています。継続的デリバリーのコンテキストでのシンプルな再デプロイメントにより、安定したプロジェクトの反復を迅速に行うことができますが、優れた新しいアイデアから最初のデプロイメントまでの機能を使用することで、摩擦が少なく、コストを抑えて新しい実験を試すことができます。
FaaSの場合、新しいアイデアから最初のデプロイメントまでのストーリーは、特にベンダーのエコシステムで十分に定義されたイベントによってトリガーされる単純な関数の場合、多くの場合優れています。たとえば、組織がすでにAWS Kinesis(Kafkaに似たメッセージングシステム)を使用して、インフラストラクチャを通じてさまざまな種類のリアルタイムイベントをブロードキャストしているとします。AWS Lambdaを使用すると、そのKinesisストリームに対して新しい本番イベントリスナーを数分で開発およびデプロイできます。1日でいくつかの異なる実験を試すことができます!
コスト上の利点は、サーバーレスによる最も簡単に表現できる改善点ですが、**リードタイムの短縮こそが、私を最も興奮させるものです。**これにより、継続的な実験という製品開発の考え方を実現でき、企業でのソフトウェア提供方法に真の革命をもたらします。
「より環境に優しい」コンピューティング?
過去数十年の間に、世界中のデータセンターの数と規模は大幅に増加しました。これらのセンターを構築するために必要な物理的なリソースに加えて、関連するエネルギー需要は非常に大きいため、Apple、Googleなどは、そうでなければ必要なそのようなサイトの化石燃料の燃焼による影響を軽減するために、再生可能エネルギー源の近くに一部のデータセンターをホストすることについて話しています。
アイドル状態だが電源が入っているサーバーは、膨大な量のエネルギーを消費します。そして、これらは、私たちがこれほど多くの、そしてより大きなデータセンターを必要とする大きな理由の一部です。
ビジネスおよびエンタープライズデータセンターの一般的なサーバーは、年間を通して最大計算出力の5〜15%を平均して提供します。
-- Forbes
これは非常に非効率的で、環境に大きな影響を与えます。
一方で、クラウドインフラストラクチャは、企業が絶対必要な場合にのみオンデマンドでより多くのサーバーを「購入」できるため、事前に必要となる可能性のあるすべてのサーバーをプロビジョニングするのではなく、すでにこの影響を軽減している可能性があります。しかし、それらのサーバーの多くが適切な容量管理なしに残されている場合、サーバーのプロビジョニングの容易さによって状況が悪化している可能性があると主張することもできます。
自己ホスト型サーバー、IaaS、またはPaaSインフラストラクチャソリューションを使用する場合でも、アプリケーションに関する容量に関する決定を手動で行っており、多くの場合、数か月または数年続きます。通常、私たちは容量管理について慎重であり、当然のことながら、過剰にプロビジョニングし、上記の非効率性を招きます。サーバーレスのアプローチでは、**そのような容量の決定を自分自身で行うことはなくなります。**サーバーレスベンダーが必要な計算能力をリアルタイムでプロビジョニングできるようにします。その後、ベンダーは顧客全体で独自の容量決定を行うことができます。
この違いにより、データセンター全体のリソースの利用効率が大幅に向上し、従来の容量管理アプローチと比較して環境への影響が軽減されるはずです。
デメリット
ですから、読者の皆様、虹、ユニコーン、そしてあらゆるものが美しく輝いている世界での時間を楽しんでいただけたことを願っています。なぜなら、私たちは現実の冷たい水しぶきを浴びようとしているからです。
サーバーレスアーキテクチャには多くの利点がありますが、重要なトレードオフも伴います。これらのトレードオフの一部は概念に固有のものであり、進歩によって完全に修正することはできず、常に考慮する必要があります。その他は現在の実装に関連しており、時間とともに解決されることが期待できます。
固有のデメリット
ベンダーコントロール
アウトソーシング戦略では、システムの一部をサードパーティベンダーに委ねることになります。このような制御の欠如は、システムのダウンタイム、予期しない制限、コストの変更、機能の損失、強制的なAPIのアップグレードなどとして現れる可能性があります。先に引用したCharity Majorsは、この記事のトレードオフセクションで、この問題をより詳細に説明しています。
スマートな[ベンダーサービス]は、使用できる方法に強力な制約を設けるため、信頼性目標の達成可能性が高くなります。ユーザーに柔軟性と選択肢があると、混沌と信頼性の欠如が生じます。プラットフォームがあなたの幸福と他の何千人もの顧客の幸福のどちらかを選択しなければならない場合、彼らは常に多数の人を選択するでしょう。当然のことです。
マルチテナントの問題
マルチテナントとは、複数の異なる顧客(またはテナント)のソフトウェアの複数のインスタンスが同じマシン上で、場合によっては同じホスティングアプリケーション内で実行される状況を指します。これは、前に説明した規模の経済効果を実現するための戦略です。サービスベンダーは、各顧客がシステムを使用している唯一の顧客であるように感じさせるために最善を尽くしており、通常、優れたサービスベンダーはそれをうまく実行しています。しかし、完璧な人はいません。マルチテナントソリューションでは、セキュリティ(ある顧客が別の顧客のデータを見ることができる)、堅牢性(ある顧客のソフトウェアのエラーが別の顧客のソフトウェアの障害を引き起こす)、パフォーマンス(高負荷の顧客が別の顧客の速度を低下させる)に問題が発生することがあります。
これらの問題は、サーバーレスシステム特有のものではありません。マルチテナントを使用する他の多くのサービス提供にも存在します。AWS Lambdaは現在十分に成熟しているため、このような問題が発生するとは期待していませんが、AWSまたは他のベンダーからの成熟度の低いサービスでは、そのような問題に注意する必要があります。
ベンダーロックイン
あるベンダーから使用しているサーバーレス機能は、別のベンダーによって異なる方法で実装される可能性が非常に高いです。ベンダーを切り替えたい場合は、運用ツール(デプロイメント、監視など)を更新する必要がある場合があり、コードを変更する必要がある場合(たとえば、異なるFaaSインターフェースを満たすため)、競合するベンダーの実装の動作に違いがある場合は、設計やアーキテクチャを変更する必要がある場合もあります。
エコシステムの一部を簡単に移行できたとしても、別のアーキテクチャコンポーネントによってより大きな影響を受ける可能性があります。たとえば、AWS Kinesisメッセージバスのイベントに応答するためにAWS Lambdaを使用しているとします。AWS Lambda、Google Cloud Functions、Microsoft Azure Functionsの違いは比較的少ないかもしれませんが、それでも後者の2つのベンダーの実装をAWS Kinesisストリームに直接接続することはできません。つまり、**あるソリューションから別のソリューションにコードを移動したり、移植したりするには、インフラストラクチャの他の部分も移動する必要があります。**
多くの人がこの考えに不安を感じています。今日選択したクラウドベンダーを明日変更する必要が生じた場合、多くの作業が必要になることは、決して心地よいことではありません。そのため、「マルチクラウド」アプローチを採用し、使用する実際のクラウドベンダーに依存しない方法でアプリケーションを開発・運用する人がいます。多くの場合、これはシングルクラウドアプローチよりもコストがかかります。ベンダーロックインは正当な懸念事項ですが、それでも私は、満足できるベンダーを選択し、その機能を最大限に活用することをお勧めします。その理由については、この記事で詳しく説明しています。
セキュリティ上の懸念
サーバーレスアプローチを採用すると、多くのセキュリティ上の問題に直面します。以下は考慮すべき事項のごく一部です。他にどのような影響があるかを必ず調査してください。
- 使用するサーバーレスベンダーが増えるごとに、エコシステムで採用されるセキュリティ実装の数も増加します。これにより、悪意のある行為の対象範囲が広がり、攻撃が成功する可能性が高まります。
- モバイルプラットフォームから直接BaaSデータベースを使用する場合、従来のアプリケーションでサーバーサイドアプリケーションが提供する保護障壁を失います。これは決定的な問題ではありませんが、アプリケーションの設計と開発において十分な注意が必要です。
- 組織でFaaSを採用すると、社内にFaaS関数が急増する可能性があります(カンブリアン爆発)。これらの関数はそれぞれ、問題の新たな要因となります。たとえば、AWS Lambdaでは、各Lambda関数は通常、設定されたIAMポリシーと密接に関連しており、誤設定しやすいものです。これは単純な問題ではなく、無視できるものでもありません。IAM管理は、少なくとも本番AWSアカウント内では、慎重に検討する必要があります。
クライアントプラットフォーム間でのロジックの重複
完全なBaaSアーキテクチャでは、サーバーサイドにカスタムロジックは記述されず、すべてクライアント側にあります。最初のクライアントプラットフォームではこれで問題ないかもしれませんが、次のプラットフォームが必要になった時点で、そのロジックのサブセットを実装し直す必要が生じます。従来のアーキテクチャでは、この繰り返しは必要ありませんでした。たとえば、この種のシステムでBaaSデータベースを使用する場合、すべてのクライアントアプリ(Web、ネイティブiOS、ネイティブAndroidなど)がベンダーデータベースと通信できる必要があり、データベーススキーマからアプリケーションロジックへのマッピング方法を理解する必要があります。
さらに、いずれかの時点で新しいデータベースに移行する場合、そのコーディング/調整の変更をすべての異なるクライアントで複製する必要があります。
サーバー最適化の損失
完全なBaaSアーキテクチャでは、クライアントのパフォーマンスに合わせてサーバー設計を最適化することはできません。「Backend For Frontend(BFF)」パターンは、システム全体の特定の基礎となる側面をサーバー内で抽象化するために存在します。これは、クライアントがより迅速に操作を実行し、モバイルアプリケーションの場合、バッテリー消費量を削減するためでもあります。完全なBaaSでは、このようなパターンは利用できません。
この欠点と前の欠点は、カスタムロジックがすべてクライアント側にあり、バックエンドサービスがベンダー提供のみである完全なBaaSアーキテクチャに存在します。これら両方の軽減策として、FaaSまたはその他の軽量なサーバーサイドパターンを採用して、特定のロジックをサーバーに移行することをお勧めします。
サーバーレスFaaSにおけるサーバー内状態の欠如
BaaS固有の欠点をいくつか説明した後、FaaSについて少し説明しましょう。前述のように
FaaS関数は、ローカル状態に関して大きな制限があります。関数の1回の呼び出しからの状態が、同じ関数の別の呼び出しで使用できるとは想定しないでください。
この想定の理由は、FaaSでは、通常、関数のホストコンテナの起動と停止を制御できないためです。
また、ローカル状態の代替策として、Twelve-Factor Appのファクター6に従うこと、つまりこの制約を受け入れることを前述しました。
Twelve-Factor Appのプロセスはステートレスで、共有しません。永続化する必要があるデータは、ステートフルなバッキングサービス(通常はデータベース)に保存する必要があります。
Herokuはこの考え方を推奨していますが、Heroku Dynoの起動と停止を制御できるため、そのPaaSで実行する場合はルールを曲げることができます。FaaSでは、ルールを曲げることはできません。
では、メモリに保持できない場合、FaaSの状態はどこに格納されるのでしょうか?上記の引用では、データベースの使用について言及しており、多くの場合、高速なNoSQLデータベース、プロセス外のキャッシュ(例:Redis)、または外部オブジェクト/ファイルストア(例:S3)が選択肢となります。しかし、これらはすべて、インメモリまたはオンマシン永続化よりもはるかに遅くなります。アプリケーションがこれに対応しているかどうかを検討する必要があります。
この点でのもう1つの懸念事項は、インメモリキャッシュです。外部に格納されている大規模なデータセットから読み取る多くのアプリは、そのデータセットの一部をインメモリキャッシュに保持します。データベース内の「参照データ」テーブルから読み取り、Ehcacheのようなものを使用している可能性があります。あるいは、キャッシュヘッダーを指定するHTTPサービスから読み取っている可能性があり、その場合、インメモリHTTPクライアントがローカルキャッシュを提供できます。
FaaSではローカルキャッシュの使用が可能であり、関数が十分に頻繁に使用される場合は役立つ場合があります。たとえば、AWS Lambdaでは、関数のインスタンスが数分おきに少なくとも1回使用される限り、数時間保持されることが一般的です。つまり、Lambdaが提供する(構成可能な)3 GBのRAMまたは512 MBのローカル「/tmp」領域を使用できます。一部のキャッシュではこれで十分かもしれません。そうでない場合は、インプロセスカッシュを想定せず、RedisやMemcachedなどの低遅延の外部キャッシュを使用する必要があります。ただし、これには追加の作業が必要であり、ユースケースによっては非常に遅くなる可能性があります。
実装上のデメリット
前述の欠点は、サーバーレスでは常に存在する可能性が高いです。軽減策は改善されますが、常に存在するでしょう。
しかし、残りの欠点は、現状の技術レベルに完全に依存します。ベンダーや熱心なコミュニティの努力と投資によって、これらはすべて解消される可能性があります。実際、この記事の最初のバージョン以降、このリストは縮小されています。
設定
この記事の最初のバージョンを書いたとき、AWSはLambda関数の構成に関してほとんど何も提供していませんでした。それが改善されたことを嬉しく思います。しかし、それほど成熟していないプラットフォームを使用する場合は、依然として確認する価値があります。
自己DoS
以下は、FaaSを扱う際には「買主責任」が重要なフレーズである理由の一例です。AWS Lambdaは、特定の時間に実行できるLambda関数の同時実行数を制限しています。この制限が1000の場合、一度に1000個の関数インスタンスを実行できます。それを超える必要がある場合、例外、キューイング、または一般的な速度低下が発生する可能性があります。
問題は、この制限がAWSアカウント全体に適用されることです。一部の組織では、本番環境とテスト環境の両方で同じAWSアカウントを使用しています。つまり、組織内のどこかの誰かが新しい種類の負荷テストを実行し、1000個の同時実行Lambda関数の実行を試行すると、誤って本番アプリケーションにDoS攻撃を行う可能性があります。うっかりミスです。
本番環境と開発環境で異なるAWSアカウントを使用する場合でも、過負荷になった本番Lambda(例:顧客からのバッチアップロードの処理)によって、個別のリアルタイムLambda対応本番APIが応答しなくなる可能性があります。
Amazonは、予約された同時実行によって、この問題に対する保護を提供しています。予約された同時実行を使用すると、Lambda関数の同時実行数を制限して、アカウントの残りの部分に影響を与えないようにしながら、他の関数が行う処理に関係なく、常に容量を確保できます。ただし、予約された同時実行はアカウントでデフォルトで有効になっておらず、慎重な管理が必要です。
実行時間
この記事の前の方で、AWS Lambda関数は5分以上実行されると中断されると述べました。これは2年間ほど一貫しており、AWSは変更の兆候を見せていません。
起動遅延
以前、コールドスタートについて説明し、このトピックに関する記事に言及しました。AWSはこの分野を時間の経過とともに改善してきましたが、特に、まれにしかトリガーされないJVM実装関数や、VPCリソースへのアクセスが必要な関数では、依然として大きな懸念事項があります。この分野では継続的な改善が期待されます。
さて、AWS Lambdaに関する指摘はこれくらいにしておきましょう。他のベンダーにも、隠された問題を抱えていることでしょう。
テスト
サーバーレスアプリの単体テストは、前述の理由から比較的簡単です。記述するコードは「単なるコード」であり、ほとんどの場合、使用するカスタムライブラリや実装するインターフェースは多くありません。
一方、サーバーレスアプリの統合テストは困難です。BaaSの世界では、独自のデータベースではなく、外部で提供されるシステムに故意に依存しています。そのため、統合テストでも外部システムを使用する必要がありますか?使用する場合は、それらのシステムはテストシナリオに対してどの程度対応していますか?状態を簡単に破棄して再構築できますか?ベンダーは負荷テストのための異なる課金戦略を提供できますか?
統合テストのためにこれらの外部システムをスタブ化する場合、ベンダーはローカルスタブシミュレーションを提供していますか?提供している場合は、スタブの忠実度はどの程度ですか?ベンダーがスタブを提供しない場合、どのように自分で実装しますか?
FaaSの世界でも同様の問題が存在しますが、この分野は改善されています。現在では、LambdaとMicrosoft Azureの両方でFaaS関数をローカルで実行することが可能です。ただし、ローカル環境ではクラウド環境を完全にシミュレートすることはできません。ローカルFaaS環境のみに依存することはお勧めしません。実際、自動化された統合テストを実行する標準環境は、少なくともデプロイメントパイプラインの一部として、クラウドであるべきであり、ローカルテスト環境は主にインタラクティブな開発とデバッグに使用することをお勧めします。これらのローカルテスト環境は継続的に改善されています。たとえば、SAM CLIは、Lambda対応のHTTP APIアプリケーションの開発を迅速に行うためのフィードバックを提供します。
また、数セクション前述のクロスアカウント実行制限について、クラウドで統合テストを実行する場合にも覚えておいてください。少なくとも、そのようなテストを本番クラウドアカウントから分離し、さらに細かいアカウントを使用することを検討する必要があります。
統合テストが重要な理由の一部として、サーバーレスFaaSとの統合単位(つまり、各関数)は他のアーキテクチャよりもはるかに小さいため、他のアーキテクチャスタイルよりも統合テストに多く依存していることが挙げられます。
すべてをローカルのラップトップで実行するのではなく、クラウドベースのテスト環境に依存することは、私にとって大きな衝撃でした。しかし、時代は変わり、クラウドから得られる機能は、Googleなどのエンジニアが10年以上前から持っていたものと同様です。Amazonは現在、クラウドでIDEを実行することもできます。まだその段階には達していませんが、そう遠くないかもしれません。
デバッグ
FaaSでのデバッグは興味深い分野です。この分野では進歩が見られ、主に上記のテストの更新と同様に、FaaS関数をローカルで実行することに関連しています。前述のように、Microsoftは、ローカルで実行されるがリモートイベントによってトリガーされる関数に対して優れたデバッグサポートを提供しています。Amazonも同様のものを提供していますが、本番イベントによってトリガーされるものではありません。
本番クラウド環境で実際に実行されている関数のデバッグは、別の話です。少なくともLambdaはまだそのようなサポートを提供していませんが、そのような機能が提供されることを期待しています。
デプロイ、パッケージング、バージョン管理
これは現在積極的に改善されている分野です。AWSはこの分野の改善に大きく貢献しており、後ほど「サーバーレスの将来」セクションでさらに詳しく説明します。
検出
「サービスディスカバリ」は、マイクロサービスの世界で頻繁に議論されるトピックです。これは、あるサービスが別のサービスの正しいバージョンを呼び出す方法に関する問題です。サーバーレスの世界では、ディスカバリに関する議論はほとんどありませんでした。最初は懸念していましたが、今はそれほど心配していません。サーバーレスの多くの用途は本質的にイベント駆動型であり、ここではイベントのコンシューマは通常ある程度自己登録を行います。FaaSのAPI指向の用途では、通常、APIゲートウェイの背後で使用します。このコンテキストでは、APIゲートウェイの前にDNSを使用し、ゲートウェイの背後で自動化されたデプロイ/トラフィックシフトを行います。APIゲートウェイの前にさらにレイヤーを使用する場合もあります(例:AWS CloudFrontを使用)して、クロスリージョン耐障害性をサポートします。
これはまだ実証されていないため、「制限事項」としてこの考えを残していますが、結局は問題ないかもしれません。
監視と可観測性
コンテナの一時的な性質により、FaaSのモニタリングは難しい分野です。ほとんどのクラウドベンダーは一定量のモニタリングサポートを提供しており、従来型のモニタリングベンダーからも多くのサードパーティの取り組みが見られています。それでも、彼らとあなたが最終的に実行できることは、ベンダーが提供する基本的なデータによって異なります。場合によってはこれで問題ないかもしれませんが、少なくともAWS Lambdaでは非常に基本的です。この分野で本当に必要なのは、オープンAPIと、サードパーティサービスがより多く支援できる機能です。
APIゲートウェイの定義と野心的なAPIゲートウェイ
Thoughtworksは、そのテクノロジーレーダーの出版物の中で、野心的なAPIゲートウェイについて議論しています。このリンクは一般的にAPIゲートウェイ(例:従来配置されたマイクロサービスの前にあるもの)を参照していますが、HTTPフロントエンドからFaaS関数へのAPIゲートウェイの使用にも確実に適用できます。問題は、APIゲートウェイが独自の構成/定義ドメイン内で多くのアプリケーション固有のロジックを実行する機会を提供することです。このロジックは、通常、テスト、バージョン管理、そして場合によっては定義が困難です。通常、このようなロジックは、アプリケーションの他の部分と同じように、プログラムコード内に残しておく方がはるかに優れています。
しかし、ここには確かに緊張関係があります。APIゲートウェイをBaaSと考えると、作業を節約するために、それが提供するすべてのオプションを検討することは価値がありませんか?そして、CPU使用率ではなくリクエストごとにAPIゲートウェイの使用料金を支払っている場合、APIゲートウェイの機能を最大限に活用する方がコスト効率が高くありませんか?
私のアドバイスは、拡張されたAPIゲートウェイ機能を慎重に使用し、デプロイ、監視、テストの方法を含め、長期的には本当に労力を節約できる場合にのみ使用することです。ソース管理可能な構成ファイルまたはデプロイメントスクリプト内で表現できないAPIゲートウェイ機能は絶対に使用しないでください。
定義の難しさに関して、AmazonのAPIゲートウェイは以前、HTTPリクエストとレスポンスをLambda関数との間でマッピングするためのトリッキーな構成を作成することを強制していました。その多くはLambdaプロキシ統合によって簡素化されましたが、時折トリッキーなニュアンスを理解する必要があります。これらの要素自体は、Serverless FrameworkやClaudia.js、またはAmazonのServerless Application Modelなどのオープンソースプロジェクトを使用することで容易になります。
操作の遅延
前述のように、サーバーレスは「ノーオプス」ではありません。監視、アーキテクチャのスケーリング、セキュリティ、ネットワークの観点から、まだやるべきことがたくさんあります。しかし、始めるときは運用を無視しがちです(「ほらお母さん、オペレーティングシステムがない!」)。ここで危険なのは、安心感に酔いしれることです。アプリケーションが稼働しているかもしれませんが、予期せずHacker Newsに掲載され、突然10倍のトラフィックを処理することになり、うっかりDoS攻撃を受けてしまい、対処方法が分からなくなる可能性があります。
解決策は教育です。サーバーレスシステムを使用するチームは、運用活動を早期に検討する必要があり、ベンダーとコミュニティは、それが何を意味するのかを理解するための教育を提供する責任があります。予防的な負荷テストやカオスエンジニアリングなどの分野も、チームが自習するのに役立ちます。
サーバーレスの未来
サーバーレスアーキテクチャの世界への旅も終わりに近づいてきました。最後に、今後数か月から数年でサーバーレスの世界が発展する可能性のあるいくつかの分野について説明します。
デメリットの軽減
サーバーレスはまだ比較的新しい世界です。そのため、欠点に関する前のセクションは広範囲にわたっており、考えられるすべてのことを網羅していません。サーバーレスの最も重要な発展は、固有の欠点を軽減し、実装上の欠点を排除するか、少なくとも改善することです。
ツール
ツールはサーバーレスでは依然として懸念事項であり、それは多くのテクノロジーとテクニックが新しいためです。ServerlessフレームワークとAmazonのServerless Application Modelが牽引役となり、過去2年間でデプロイ/アプリケーションバンドリングと構成の両方が改善されました。しかし、「最初の10分」のエクスペリエンスは、まだ理想的なほどには普遍的に素晴らしいとは言えず、AmazonとGoogleは、より多くのインスピレーションを得るためにMicrosoftとAuth0を参考にできるでしょう。
クラウドベンダーが積極的に取り組んでいると見てきた分野の1つは、より高レベルなリリースアプローチです。従来のシステムでは、チームは通常、「トラフィックシフト」のアイデア(ブルーグリーンデプロイメントやカナリアリリースなど)を処理するための独自のプロセスをコーディングする必要がありました。これを踏まえ、AmazonはLambdaとAPI Gatewayの両方に対して自動トラフィックシフトをサポートしています。多くの個別にデプロイされたコンポーネントがシステムを構成するサーバーレスシステムでは、このような概念はさらに役立ちます。一度に100個のLambda関数をアトミックにリリースすることは不可能です。Nat Pryceは、コンポーネントのグループをトラフィックフローに徐々に投入したり取り除いたりできる「ミキシングデスク」アプローチのアイデアを私に説明してくれました。
分散モニタリングはおそらく、最も大幅な改善が必要な分野です。AmazonのX-Rayやさまざまなサードパーティ製品による初期段階の取り組みが見られていますが、これは明らかに解決済みの問題ではありません。
リモートデバッグも、より広範に見られることを期待しています。Microsoft Azure Functionsはこれをサポートしていますが、Lambdaはサポートしていません。リモートで実行されている関数のブレークポイントを設定できることは、非常に強力な機能です。
最後に、「メタオペレーション」のツール改善を期待しています。つまり、数百または数千ものFaaS関数、構成済みサービスなどをより効果的に管理する方法です。たとえば、組織は特定のサービスインスタンスが使用されなくなった時点を確認する必要があり(セキュリティ上の理由だけでも)、サービス間の費用をより適切にグループ化して可視化する必要があります(特に費用に関する責任を負う自律的なチームの場合)。
状態管理
FaaSのサーバー内永続状態の欠如は、多くのアプリケーションにとって問題ありませんが、大規模なキャッシュセットやセッション状態への高速アクセスなど、多くの他のアプリケーションにとっては致命的です。
高スループットアプリケーションの1つの回避策は、ベンダーがイベント間の関数インスタンスをより長くアクティブに維持し、通常のインプロセスキャッシングアプローチが機能するようにすることです。キャッシュはすべてのイベントに対してウォームではないため、これは常に機能するわけではありませんが、これは自動スケーリングを使用する従来のアプリケーションにも既に存在する懸念事項です。
より良い解決策は、プロセス外のデータへの非常に低遅延アクセス、たとえば、非常に低いネットワークオーバーヘッドでRedisデータベースをクエリできることです。Amazonは既にElasticache製品でホストされたRedisソリューションを提供しており、配置グループを使用してEC2(サーバー)インスタンスの相対的な共存を既に許可しているため、これはそれほど難しいことではありません。
しかし、より可能性が高いのは、外部化された状態の制約を考慮するために、さまざまな種類のハイブリッド(サーバーレスとサーバーレスではない)アプリケーションアーキテクチャが採用されるようになると思います。たとえば、低遅延アプリケーションの場合、通常の長時間実行されるサーバーが最初のリクエストを処理し、そのローカル状態と外部状態からそのリクエストを処理するために必要なすべてのコンテキストを収集し、次に外部からデータを検索する必要のないFaaS関数のファームに完全にコンテキスト化されたリクエストを渡すアプローチが見られるかもしれません。
プラットフォームの改善
現在のサーバーレスFaaSの特定の欠点は、プラットフォームの実装方法に起因しています。実行時間、起動遅延、関数間の制限は、3つの明白な例です。これらは、新しいソリューションによって修正されるか、追加コストの可能性のある回避策が提供される可能性があります。たとえば、顧客が低遅延で2つのFaaS関数のインスタンスを常に利用できるように要求し、顧客がその可用性に対して支払うことを許可することで、起動遅延を軽減できると想像できます。Microsoft Azure Functionsは、Durable FunctionsとApp Serviceプランでホストされる関数で、このアイデアの要素を備えています。
もちろん、現在の欠陥の修正だけにとどまらず、プラットフォームの改善も見られるでしょうし、それらはエキサイティングなものです。
教育
サーバーレスにおける多くのベンダー固有の固有の欠点は、教育を通じて軽減されています。このようなプラットフォームを使用するすべての人は、エコシステムの多くが1つまたは複数のアプリケーションベンダーによってホストされていることを積極的に考える必要があります。「1つが利用できなくなった場合に、異なるベンダーからの並列ソリューションを検討すべきか?」や「部分的な停止の場合、アプリケーションをどのようにしてスムーズに劣化させるか?」などの疑問について考える必要があります。
教育のもう1つの分野は技術運用です。多くのチームは以前よりも少数のシステム管理者を抱えるようになり、サーバーレスはこの変化を加速させるでしょう。しかし、システム管理者はUnixボックスとChefスクリプトを構成するだけではありません。彼らはしばしば、サポート、ネットワーク、セキュリティなどの最前線にいる人々です。
真のDevOps文化は、サーバーレスの世界ではさらに重要になります。他のシステム管理者以外の活動はまだ行う必要があり、多くの場合、開発者がそれらの責任を負うことになるからです。これらの活動は多くの開発者や技術リーダーにとって自然なことではない可能性があるため、運用担当者との教育と緊密な協力が非常に重要です。
ベンダーからの透明性の向上と明確な期待
最後に、軽減策に関して言えば、ベンダーは、ホスティング機能の多くを依存するにつれて、プラットフォームに期待できることをより明確にする必要があります。プラットフォームの移行は困難ですが、不可能ではありません。信頼できないベンダーは、顧客が他の場所にビジネスを移すのを見ることになります。
パターンの出現
サーバーレスアーキテクチャの使用方法と時期に関する私たちの理解はまだ初期段階にあります。現在、チームはあらゆる種類のアイデアをサーバーレスプラットフォームに投入し、何がうまくいくかを確認しています。パイオニアのおかげです!推奨される実践のパターンが見え始めており、この知識はさらに成長するでしょう。
私たちが見るパターンの一部は、アプリケーションアーキテクチャにあります。たとえば、FaaS関数は大きくなりすぎると扱いにくくなるまでどのくらい大きくなることができますか?FaaS関数のグループをアトミックにデプロイできると仮定すると、そのようなグループを作成する良い方法は?それらは、現在ロジックをマイクロサービスにどのようにまとめるかとうまく一致していますか、それともアーキテクチャの違いによって別の方向に進むのでしょうか?
サーバーレスアプリケーションアーキテクチャで活発に議論されている特に興味深い分野の1つは、それがイベント思考とどのように相互作用するかです。AWS LambdaのプロダクトヘッドであるAjay Nairは、2017年にこの点について素晴らしい講演を行いました。これは、CNCFサーバーレスワーキンググループの主要な議論の分野の1つです。
さらに踏み込んで、FaaSと従来の「常時稼働」型の永続的なサーバーコンポーネント間のハイブリッドアーキテクチャを構築する良い方法とは何でしょうか?既存のエコシステムにBaaSを導入する良い方法は何でしょうか?そして、その逆として、完全に、または大部分がBaaSシステムであるものが、より多くのカスタムサーバーサイドコードを採用または使用する必要がある警告サインは何でしょうか?
また、多くの使用パターンが議論されるようになっています。FaaSの標準的な例の一つにメディア変換があります。例えば、大規模なメディアファイルがS3バケットに保存されるたびに、別のバケットに小さいバージョンを作成するプロセスを自動的に実行します。しかし、現在では、データ処理パイプライン、高度にスケーラブルなWeb API、運用における汎用的な「接着剤」コードとして、Serverlessの重要な利用も見られます。これらのパターンのいくつかは、組織に直接展開できる汎用コンポーネントとして実装できます。AmazonのServerless Application Repositoryについて書いた記事 は、このアイデアの初期段階を示しています。
最後に、ツールの改善に伴い、推奨される運用パターンが出始めています。FaaS、BaaS、従来のサーバーのハイブリッドアーキテクチャのログを論理的に集約するにはどうすればよいでしょうか?FaaS関数を最も効果的にデバッグするにはどうすればよいでしょうか?これらの質問に対する多くの回答、そして出現しつつあるパターンは、クラウドベンダー自身から出てきており、この分野の活動は増加すると予想されます。
グローバル分散アーキテクチャ
先に挙げたペットストアの例では、単一のペットストアサーバーがいくつかのサーバーサイドコンポーネントと、クライアントまで完全に移動したロジックに分割されましたが、基本的にこれは依然としてクライアント、または既知の場所にあるリモートサービスに焦点を当てたアーキテクチャでした。
Serverlessの世界では、責任の分散がはるかに曖昧になりつつあります。一例として、AmazonのLambda@Edge製品があります。これは、AmazonのCloudFrontコンテンツ配信ネットワークでLambda関数を実行する方法です。Lambda@Edgeを使用すると、Lambda関数はグローバルに分散されるため、エンジニアによる単一のアップロードアクティビティによって、関数が世界中の100以上のデータセンターに展開されます。これは、私たちが慣れ親しんでいる設計ではなく、制約と機能の両方を伴います。
さらに、Lambda関数はデバイス上で実行でき、機械学習モデルはモバイルクライアント上で実行でき、気づけば「クライアントサイド」と「サーバーサイド」の二分法が意味をなさなくなります。実際、今ではコンポーネントの局所性のスペクトルが、人間のユーザーから広がっているのが見えます。Serverlessはリージョンレスになります。
「FaaS化」を超えて
これまで私が見たFaaSのほとんどの用途は、既存のコードと設計のアイデアを取り入れて「FaaS化」すること、つまりステートレスな関数セットに変換することに重点が置かれています。これは強力ですが、FaaSを基礎となる実装として使用し、開発者にFaaSのメリットを提供しながら、アプリケーションを個別の関数セットとして考える必要がない、より多くの抽象化、そしておそらく言語が登場すると予想されます。
例として、GoogleがDataflow製品にFaaS実装を使用しているかどうかはわかりませんが、同様のことを行う製品またはオープンソースプロジェクトを作成し、FaaSを実装として使用することは想像できます。Apache Sparkのようなものがここに比較できます。Sparkは大規模データ処理のためのツールであり、Amazon EMRとHadoopを基礎となるプラットフォームとして使用できる非常に高レベルの抽象化を提供します。
テスト
Serverlessシステムの統合テストと受け入れテストには、さらに作業が必要だと思いますが、この作業の多くは、より従来の方法で開発された「クラウドネイティブ」なマイクロサービスシステムと同じです。
本番環境でのテストやモニタリング主導の開発などのアイデアを採用するという抜本的なアイデアがあります。コードが基本的な単体テスト検証に合格したら、トラフィックのサブセットに展開し、前のバージョンと比較してみます。これは、前に述べたトラフィックシフトツールと組み合わせることができます。これはすべての状況で有効なわけではありませんが、多くのチームにとって驚くほど効果的なツールになる可能性があります。
移植可能な実装
チームは、特定のクラウドベンダーにあまり依存せずにServerlessを使用できる方法がいくつかあります。
ベンダー実装を抽象化
Serverless Frameworkは主にServerlessアプリケーションの運用タスクを容易にするために存在しますが、そのようなアプリケーションがどこでどのように展開されるかについても中立性を提供します。たとえば、運用機能に応じて、AWS API Gateway + LambdaとAuth0 webtaskの間を簡単に切り替えることができるのは素晴らしいことです。
これは、標準化のアイデアなしに抽象化されたFaaSコーディングインターフェースをモデリングするという難しい側面ですが、それはまさにCloudEventsに関するCNCF Serverlessワーキンググループの仕事です。
ただし、運用上の複雑さが露呈すると、複数のプラットフォームへの展開抽象化を提供することの価値は疑問視されます。たとえば、あるクラウドでセキュリティを正しく設定することは、別のクラウドでは常に異なる可能性があります。
デプロイ可能な実装
サードパーティのプロバイダーを使用せずにServerlessテクニックを使用することを提案するのは奇妙に聞こえるかもしれませんが、これらの考え方を検討してください。
- 大規模な技術組織であり、すべてのモバイルアプリケーション開発チームにFirebaseのようなデータベースエクスペリエンスを提供したいが、既存のデータベースアーキテクチャをバックエンドとして使用したいと考えているかもしれません。
- 以前、「Serverful」FaaSプラットフォームについて話しました。つまり、一部のプロジェクトにFaaSスタイルのアーキテクチャを使用できますが、コンプライアンス、法的などによる理由で、オンプレミスでアプリケーションを実行する必要があります。
どちらの場合も、ベンダーホスティングから得られるものがないServerlessアプローチを使用することには多くのメリットがあります。ここには前例があります。プラットフォームとしてのサービス(PaaS)を考えてみましょう。初期の人気PaaSはすべてクラウドベースでした(例:Heroku)が、すぐに、独自のシステムでPaaS環境を実行することのメリットが認識されました。いわゆる「プライベート」PaaS(例:Cloud Foundry、この記事で先に述べたように)。
プライベートPaaSの実装と同様に、特にKubernetesなどのコンテナプラットフォームと統合されたBaaSとFaaSの概念のオープンソース実装と商用実装の両方が普及すると想像できます。
コミュニティ
すでに、複数のカンファレンス、多くの都市でのミートアップ、さまざまなオンライングループを持つ、かなりの規模のServerlessコミュニティがあります。これは、DockerやSpringのようなコミュニティと同じように成長し続けると予想されます。
結論
Serverlessは、その紛らわしい名前にもかかわらず、従来よりもアプリケーションの一部として独自のサーバーサイドシステムの実行に依存するアーキテクチャスタイルです。これは、サードパーティのリモートアプリケーションサービスをアプリのフロントエンドに直接緊密に統合するBaaS、およびサーバーサイドコードを長時間実行されるコンポーネントから一時的な関数インスタンスに移動するFaaSという2つの手法を通じて行われます。
Serverlessはすべての問題に対する正しいアプローチではありません。そのため、既存のアーキテクチャのすべてを置き換えると言う人には注意してください。特にFaaS領域では、今Serverlessシステムに飛び込む場合は注意してください。スケーリングと保存された展開作業という富が手に入る一方で、デバッグとモニタリングというドラゴンが次の角のすぐ後ろに潜んでいます。
しかし、その富はすぐに無視すべきではありません。なぜなら、Serverlessアーキテクチャには、運用コストと開発コストの削減、運用管理の容易化、環境への影響の低減など、重要な利点があるからです。しかし、最も重要な利点は、新しいアプリケーションコンポーネントを作成するフィードバックループの短縮だと思います。「リーン」アプローチの大ファンであるのは、エンドユーザーの前にできるだけ早くテクノロジーを提供して早期フィードバックを得ることには多くの価値があると考えるからです。Serverlessによる市場投入までの時間の短縮は、この哲学にぴったり合っています。
Serverlessサービスとその使用方法に関する理解は、現在(2018年5月)「ややぎこちない思春期」の成熟度にあります。今後数年間でこの分野には多くの進歩があり、Serverlessが私たちのアーキテクチャツールキットにどのように適合するのかを見るのは興味深いでしょう。
謝辞
この記事へのご意見をいただいた皆様に感謝いたします:Obie Fernandez、Martin Fowler、Paul Hammant、Badri Janakiraman、Kief Morris、Nat Pryce、Ben Rady、Carlos Nunez、John Chapin、Robert Bagge、Karel Sague Alfonso、Premanand Chandrasekaran、Augusto Marietti、Roberto Sarrionandia、Donna Malayeri。
用語の起源に関するサイドバーへのご意見をいただいたBadri JanakiramanとAnt Stanleyに感謝します。
適切な懐疑的な熱意を持ってこの新しいテクノロジーに取り組んでくれた、以前のIntent Mediaのチームメンバーに感謝します:John Chapin、Pete Gieser、Sebastián Rojas、Philippe René。
校正を行ってくれたSid Orlandoに感謝します。
最後に、Serverlessコミュニティの友人や同僚、特にこの記事でリンクされているコンテンツの皆様に感謝します。
重要な改訂
2018年5月22日:記事全体の重要な更新。この更新の詳細については、こちらをご覧ください。
2016年8月4日:「将来」と「結論」を追加
2016年7月25日:起源のサイドバーと「コンテナとの比較」セクションを追加
2016年7月18日:「欠点」を追加
2016年7月13日:「利点」を追加
2016年6月17日:「Serverlessではないもの」を追加
2016年6月16日:「Function as a Serviceの解明」を追加
2016年6月15日:最初の回を公開 - いくつかの例