
メインフレームの漸進的近代化のためのシームの発見
レガシー置換の事例研究
メインフレームシステムは、世界中のコンピューティングワークロードの大部分を依然として実行していますが、増加するビジネスニーズに対応するために新しい機能を追加することはしばしば困難です。さらに、それらを強化するのが遅いアーキテクチャ上の課題は、それらを置き換えることも困難にします。関与するリスクを軽減するために、レガシー置換に対する漸進的なアプローチを使用し、レガシー機能を最新のテクノロジーによる実装に段階的に置き換える必要があります。この戦略では、メインフレームシステムにシームを導入する必要があります。これは、新しいサービスにロジックフローを転用できるポイントです。最近のプロジェクトでは、長期間稼働しているメインフレームシステムにこれらのシームを導入するためのいくつかのアプローチを調査しました。
2024年4月10日

Alessio Ferriは、Thoughtworksのテクニカルリードです。彼は開発者であり、情熱的な技術者であり、実践的な経験を活かして、クライアントとデリバリーチームが目標を達成するのを支援しています。

最近のプロジェクトでは、メインフレームシステムをクラウドネイティブアプリケーションに置き換える方法、ロードマップの構築、および必要な複数年にわたる近代化の取り組みのための資金調達を確保するためのビジネスケースの設計という課題を負いました。私たちは、ビッグデザインアップフロントのリスクと潜在的な落とし穴を懸念していたため、クライアントに最初の段階でエンジニアリングを行う「必要十分かつ適時」なアップフロント設計に取り組むようアドバイスしました。クライアントは私たちのアプローチを気に入り、パートナーとして私たちを選びました。
このシステムは、英国に拠点を置くクライアントのデータプラットフォームと顧客向けの製品向けに構築されました。これは、40年以上にわたって構築されたメインフレームの規模、そして最初にリリースされてから大きく変化したさまざまなテクノロジーを考慮すると、非常に複雑で困難な作業でした。
私たちのアプローチは、メインフレームからクラウドへの機能を段階的に移行することに基づいており、「ビッグバン」による一括移行ではなく、段階的なレガシー置換を可能にします。これを行うために、メインフレームの設計において、シームを作成できる場所、つまり、メインフレームのコードに最小限の変更で新しい動作を挿入できる場所を特定する必要がありました。次に、これらのシームを使用してクラウド上に重複機能を作成し、メインフレームとデュアルランさせて動作を確認し、メインフレームの機能を廃止することができます。
Thoughtworksはプログラムの最初の年に参加し、その後、クライアントに作業を引き継ぎました。その期間内に、私たちの作業を本番環境に投入したわけではありませんが、より迅速に開始し、独自のメインフレーム近代化の取り組みを容易にするのに役立つ複数の方法を試行しました。この記事では、私たちが作業したコンテキストの概要を示し、メインフレームから機能を段階的に移行するために私たちが従ったアプローチの概要を示します。
コンテキスト背景
メインフレームは、クライアントのビジネス運用に不可欠なさまざまなサービスをホストしていました。私たちのプログラムは、英国とアイルランドの消費者に関するインサイトを目的としたデータプラットフォームに特に焦点を当てていました。メインフレーム上のこの特定のサブシステムは、40年以上にわたって開発された約700万行のコードで構成されていました。これは、英国とアイルランドの資産の機能のおよそ50%を提供していましたが、ランタイムの観点からMIPS(1秒あたりの命令数)のおよそ80%を占めていました。システムは非常に複雑で、その複雑さは、レガシー環境の複数のレイヤーにわたって広がるドメインの責任と懸念によってさらに悪化していました。
クライアントがメインフレーム環境から移行することを決定した理由はいくつかあります。それらは次のとおりです。
- システムへの変更は遅く、高価でした。そのため、ビジネスは急速に進化する市場に遅れをとっており、イノベーションを妨げていました。
- メインフレームシステムを実行することに伴う運用コストは高かった。クライアントは、主要なソフトウェアベンダーからの差し迫った価格上昇により、商業的なリスクに直面していました。
- クライアントはメインフレームを実行するための必要なスキルセットを持っていましたが、このテクノロジースタックに精通した新しい専門家を見つけるのは困難であることが証明されました。この分野の熟練したエンジニアのプールは限られているからです。さらに、ジョブマーケットではメインフレームの機会はそれほど多くないため、人々はそれらの開発と運用方法を学ぶ動機がありません。
消費者サブシステムの概要
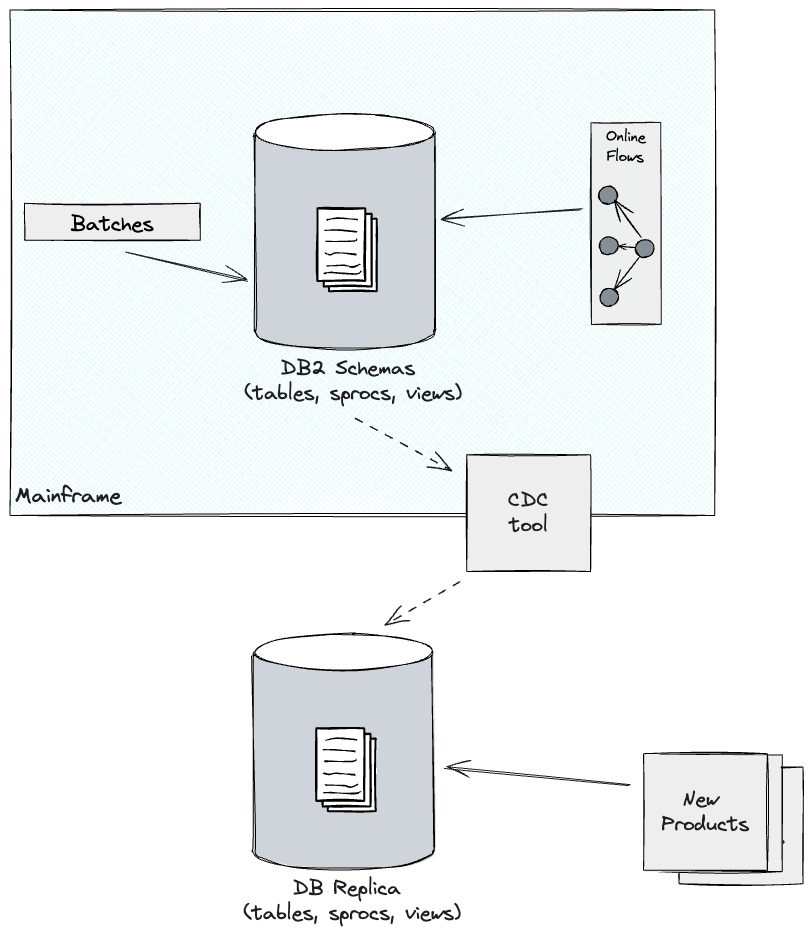
次の図は、消費者サブシステムのさまざまなコンポーネントとアクタの概要を示しています。
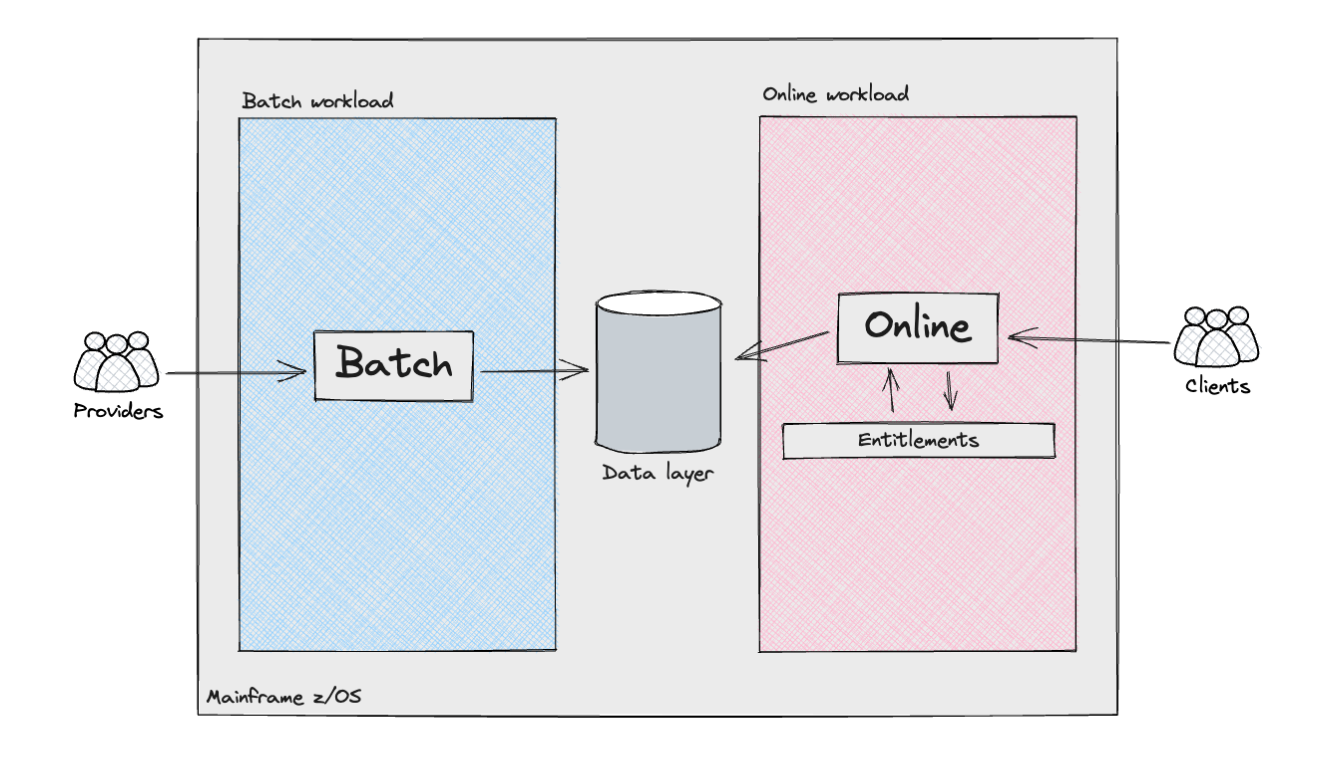
メインフレームは、バッチ処理と、製品APIレイヤーのオンライントランザクションという2種類のワークロードをサポートしていました。バッチワークロードは、一般的にデータパイプラインと呼ばれるものに類似していました。これには、外部プロバイダー/ソースまたは他の内部メインフレームシステムからの半構造化データの取り込み、それに続くデータクレンジングとモデリングが含まれ、消費者サブシステムの要件に合わせます。これらのパイプラインには、ID検索ロジックの実装など、さまざまな複雑さが含まれていました。英国では、米国のような社会保障番号とは異なり、住民を識別する普遍的に一意の識別子はありません。そのため、英国とアイルランドで事業を展開する企業は、そのデータに関連付けられた個人のIDを正確に判断するために、カスタマイズされたアルゴリズムを使用する必要があります。
オンラインワークロードも大きな複雑さを示しました。APIリクエストのオーケストレーションは、内部で開発された複数のフレームワークによって管理されていました。これにより、データストアのルックアップによってプログラムの実行フローが決定され、コードの出力を分析することによって条件付き分岐が処理されました。このフレームワークが各顧客に適用したカスタマイズのレベルを見過ごすことはできません。たとえば、一部のフローはアドホック構成でオーケストレーションされ、クライアントのオンライン製品と対話するシステムの実装の詳細や特定のニーズに対応していました。これらの構成は最初は例外的なものでしたが、クライアントがオンラインサービスを増強するにつれて、時間の経過とともに標準になった可能性があります。
これは、レイヤー全体で動作して、製品と基盤となるデータにアクセスする顧客が、生データまたは集約データのいずれかを取得する認証と承認を受けていることを確認する、権限エンジンを通じて実装されました。その後、APIレスポンスを通じて公開されます。
漸進的レガシー置換:原則、メリット、および考慮事項
消費者サブシステムの範囲、リスク、および複雑さを考慮して、次の原則がプログラムの成功と密接に関連していると信じていました。
- 早期リスク軽減:最初からエンジニアリングを行うことで、「Fail-Fast」アプローチの実装により、潜在的な落とし穴と不確実性を早期に特定し、プログラムのデリバリーの観点から遅延を防ぐことができます。これらは
- 成果のパリティ:クライアントは、既存のレガシーシステムと新しいシステムの間で成果のパリティを維持することの重要性を強調しました(この概念は機能のパリティとは異なることに注意することが重要です)。クライアントのレガシーシステムでは、各消費者に対してさまざまな属性が生成され、厳しい業界規制を考慮すると、契約上のコンプライアンスを確保するために継続性を維持することが不可欠でした。私たちは、データの不一致を早期に積極的に特定し、迅速に解決または説明し、早期の段階でクライアントとその顧客の両方との信頼関係を確立する必要がありました。
- クロスファンクショナルな要件:メインフレームは非常に高性能なマシンであり、クラウド上のソリューションがクロスファンクショナルな要件を満たすという不確実性がありました。
- 早期の価値提供:クライアントとの協業により、最も重要なビジネス機能のサブセットを早期に提供できることを特定し、システムをより小さな増分に分けることができるようにします。これらは、システム全体の薄いスライスを表していました。私たちの目標は、これらのスライスを繰り返し頻繁に構築することで、ドメインにおける全体的な学習を加速することでした。さらに、薄いスライスを通して作業することで、チームから要求される認知負荷を軽減し、分析の停滞を防ぎ、価値が継続的に提供されるようにします。これを実現するために、クライアントの移行戦略をより適切に制御できるメインフレームを基盤としたプラットフォームが重要な役割を果たします。ダークローンチやカナリアリリースなどのパターンを使用すると、クラウドへのスムーズな移行を主導できます。私たちの目標は、顧客がシステム間をシームレスに移行し、目に見える影響がないサイレント移行プロセスを実現することでした。これは、包括的な比較テストと両方のシステムからの出力の継続的な監視を通じてのみ実現可能です。
上記の原則と要件を考慮して、デュアルランと組み合わせて漸進的なレガシー置換アプローチを選択しました。効果的に、クラウド上で再構築したシステムのスライスごとに、新しいシステムと現状のシステムの両方に同じ入力を供給し、並列で実行する計画を立てました。これにより、両方のシステムの出力を抽出し、それらが同じであるか、少なくとも許容範囲内にあるかどうかを確認できます。このコンテキストでは、増分デュアルランを次のように定義しました。レガシー環境から機能のスライスごとの置換をサポートする移行アーキテクチャを使用して、ターゲットシステムと現状のシステムを一時的に並列で実行し、価値を提供します。
私たちは、価値の提供、早期のリスク発見と管理、成果の均等性、そしてプログラム期間を通じてクライアントへの円滑な移行を確保するために、このアーキテクチャパターンを採用することにしました。
漸進的レガシー置換アプローチ
ターゲットアーキテクチャへの機能のオフロードを実現するために、チームはメインフレームSME(専門家)とクライアントのエンジニアと緊密に連携しました。この連携により、技術的およびビジネス的な機能の両方の観点から、現状の状況を十分に理解することができました。これにより、既存のメインフレームをクラウドベースのシステム(プログラム内の他のデリバリーワークストリームによって開発されている)に接続するための移行アーキテクチャを設計することができました。
私たちの取り組みは、コンシューマサブシステムをデータロード、データ取得と集約、外部向けAPIを通じてアクセス可能なプロダクトレイヤーを含む、特定のビジネスおよびテクニカルドメインに分解することから始まりました。
クライアントのビジネス目的から、プログラムの編成に主要な技術的境界を利用できることを早期に認識しました。クライアントのワークロードは主に分析的なもので、主に外部データの処理を行い、クライアントに販売されるインサイトを生成していました。そのため、変革プログラムをデータキュレーションを中心とした部分と、データインタラクションを境界線として、データ提供と製品ユースケースを中心とした部分の2つのパートに分割する機会がありました。これは最初に特定された上位レベルの境界線でした。
その後、プログラムをさらに小さな増分単位に分割する必要がありました。
データキュレーション側では、データセットは互いにほぼ独立して管理されていることがわかりました。つまり、上流と下流の依存関係はあったものの、キュレーション中にデータセットが絡み合っていることはなく、つまり取り込まれたデータセットは入力ファイルと一対一のマッピングを持っていました。
その後、SMEと緊密に協力して、技術的な実装における境界線(下記に示す)を特定し、任意のデータセットのクラウド移行をどのように提供するかを計画しました。最終的には、任意の順序で提供できるレベルまで到達しました(データベースライター処理パイプライン境界線、粗い境界線:バッチパイプラインステップハンドオフとしての境界線、および最も細かい境界線:データ特性境界線)。上流と下流の依存関係が新しいクラウドシステムからデータ交換できれば、これらのワークロードは互いに独立して近代化できます。
サービスと製品の側では、特定の製品がクライアントが作成した機能とデータセットの80%を使用していることがわかりました。異なるアプローチを見つける必要がありました。顧客へのアクセスの販売方法を調査した結果、「顧客セグメント」アプローチを採用して作業を増分的に提供できることがわかりました。これには、機能とデータの割合が小さい割合の顧客の初期サブセットを見つけることが含まれ、最初の増分を提供するために必要な範囲と時間を削減します。後続の増分は以前の作業の上に構築され、さらに顧客セグメントを現状のアーキテクチャからターゲットアーキテクチャに移行できるようにします。これには、異なる境界線と移行アーキテクチャを使用する必要があり、データベースリーダーと下流処理としての境界線で説明します。
事実上、ビジネスの観点からまとまった全体として機能するが、クラウドに独立して移行できる別個の要素として構築されたコンポーネントを徹底的に分析し、これをシーケンスされた増分プログラムとして展開しました。
シーム
私たちの移行アーキテクチャは、主にメインフレーム内で発見できるレガシー境界線の影響を受けています。これらは、コード、プログラム、またはモジュールが出会う接合点と考えてください。レガシーシステムでは、より良いモジュール性、拡張性、保守性を確保するために、戦略的な場所に意図的に設計されている場合があります。これが当てはまる場合、コード全体で目立つ可能性がありますが、システムが数十年にわたって開発されてきた場合、これらの境界線はコードの複雑さの中に隠れる傾向があります。境界線は、アプリケーションの動作を変更するために戦略的に使用できるため、特に価値があります。たとえば、メインフレーム内のデータフローをインターセプトして、新しいシステムに機能をオフロードできます。
技術的な境界線と価値のあるデリバリー増分の決定は共生的なプロセスでした。技術分野の可能性は、増分の計画に使用できるオプションに影響を与え、それは次にプログラムをサポートするために必要な移行アーキテクチャを推進しました。ここでは、クライアントの増分レガシー置換を可能にするために計画および設計されたソリューションについて、技術的な詳細を1レベル下げて説明します。これらのアプローチは、より多くの知識を獲得するにつれて、エンゲージメント全体を通して継続的に洗練されてきたことに注意することが重要です。いくつかはテスト環境に展開されるまでになりましたが、その他はスパイクでした。他の大規模なメインフレーム近代化プログラムでこのアプローチを採用するにつれて、これらのアプローチは最新の直接的な経験によってさらに洗練されます。
外部インターフェース
メインフレームからデータプロバイダーとクライアントの顧客に公開されている外部インターフェースを調べました。これらの統合ポイントでイベントインターセプションを適用して、外部向けワークロードのクラウドへの移行を可能にすることで、彼らの視点からは移行がシームレスになります。メインフレームへのインターフェースには2つのタイプがありました。プロバイダーがクライアントにデータを提供するためのファイルベースの転送と、顧客がプロダクトレイヤーと対話するためのWebベースのAPIセットです。
バッチ入力としてのシーム
最初に発見した外部境界線は、ファイル転送サービスでした。
プロバイダーは、半構造化形式のデータを含むファイルを2つのルートを介して転送できます。基盤となるファイル転送サービスと対話するファイルアップロード用のWebベースのGUI(グラフィカルユーザーインターフェース)、またはプログラムによるアクセスのためのサービスへのFTPベースのファイル転送です。
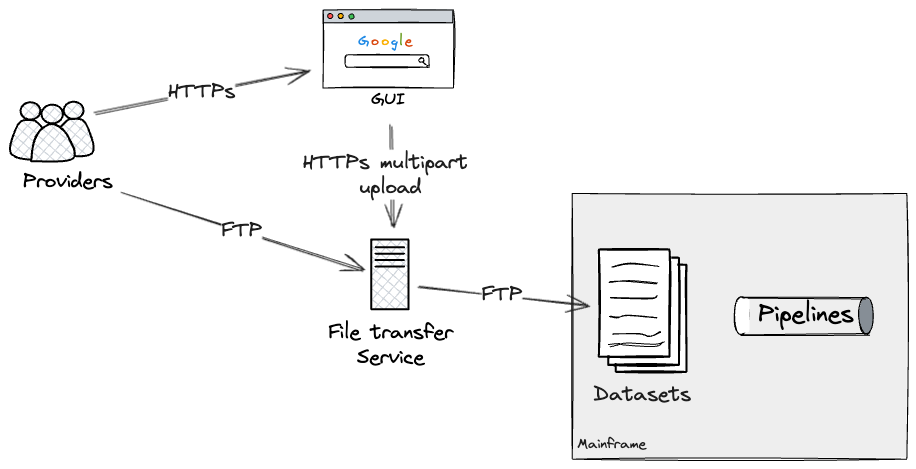
ファイル転送サービスは、プロバイダーとファイルごとに、メインフレーム上のどのデータセットを更新する必要があるかを決定します。これにより、バッチジョブスケジューラで構成されたデータセットトリガーを介して関連するパイプラインが実行されます。
各パイプラインをクラウド全体で再構築できると仮定すると(後で、より大きなパイプラインを扱いやすいチャンクに分割することに関してさらに詳しく説明します)、クラウド上に個々のパイプラインを構築し、メインフレームとデュアルランして、同じ出力が生成されていることを確認するというアプローチを採用しました。私たちのケースでは、ファイル転送サービスに追加の構成を適用することでこれを実現でき、メインフレームとクラウドの両方にアップロードをフォークしました。テスト環境で実行されているダミーデータを使用して、本番環境のようなファイル転送サービスを使用してこのアプローチをテストすることができました。
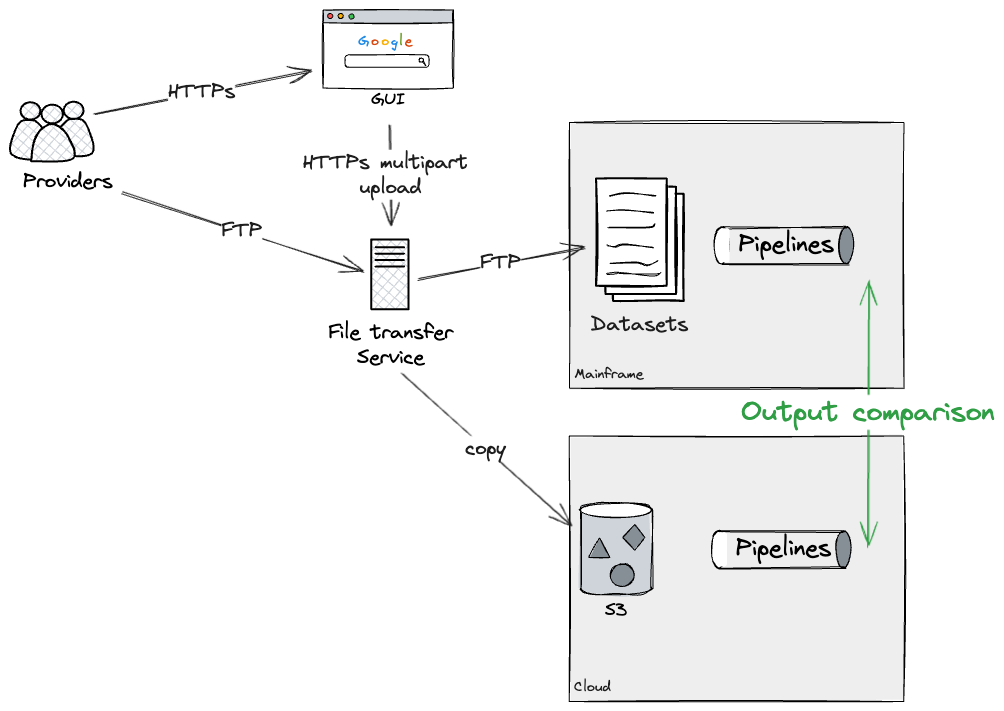
これにより、必要な期間、クラウドとメインフレームの両方で各パイプラインをデュアルランして、食い違いがないことを確認できます。最終的には、ファイル転送サービスに追加の構成を適用して、メインフレームデータセットへのさらなる更新を防止し、現状のパイプラインを非推奨にするというアプローチを採用することになります。パイプライン全体をエンドツーエンドで再構築しなかったため、この最後のステップを自分でテストすることはできませんでしたが、私たちの技術的なSMEは、メインフレームパイプラインを効果的に非推奨にするためにファイル転送サービスに必要な構成に精通していました。
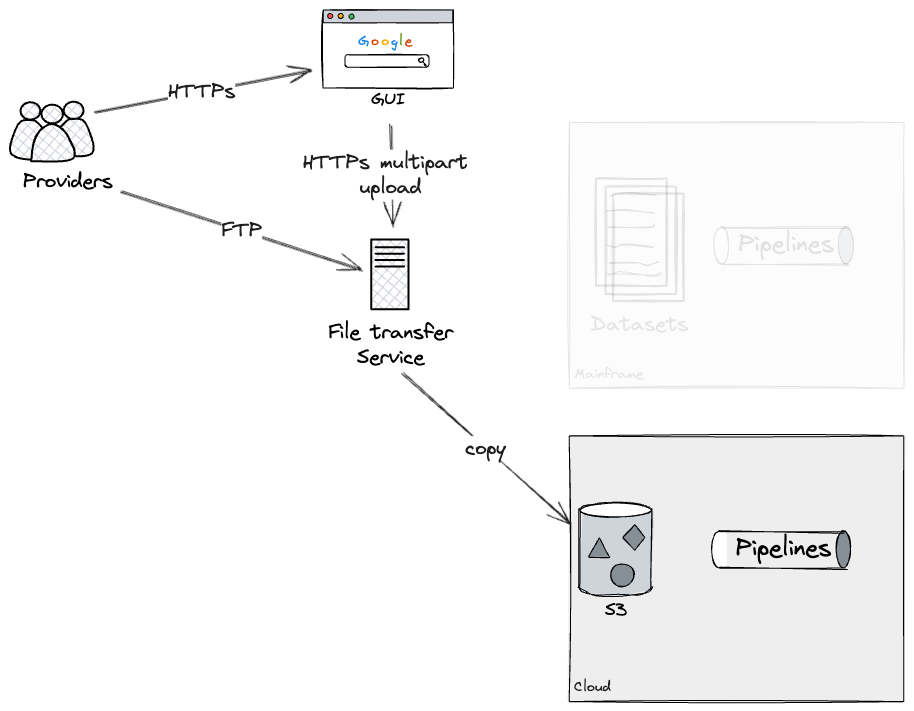
APIアクセスとしてのシーム
さらに、外部に公開されているAPIゲートウェイの周りの境界線を特定し、顧客へのコンシューマサブシステムのエントリポイントを表すことで、外部向けAPIについても同様の戦略を採用しました。
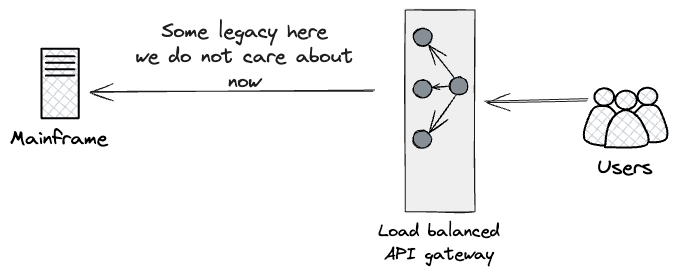
デュアルランから得た知見に基づき、設計したアプローチは、HTTPS呼び出しのチェーンの上位、ユーザーにできるだけ近い場所にプロキシを配置することでした。私たちは、(現状のメインフレームとクラウド上に新しく構築されたAPIの両方)の呼び出しストリームを並列実行し、その結果を報告できるものを探していました。
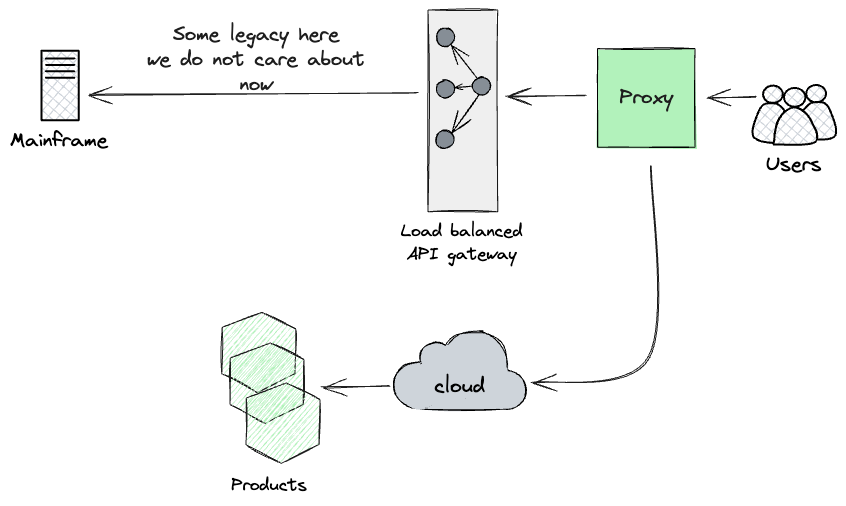
事実上、アーティファクトの出力を広範囲かつ継続的に監視することで、早期に信頼性を高めるために、新しいプロダクトレイヤーにダークローンチを使用する計画でした。最初の年にはこのプロキシの構築を優先しませんでした。その価値を活用するには、製品レベルで大部分の機能を再構築する必要がありました。ただし、APIレイヤーで意味のある比較テストを実行できるようになるとすぐに構築する意図がありました。これは、ダークローンチの比較テストを調整するために重要な役割を果たすコンポーネントであるためです。さらに、分析により、プロダクトレイヤーによって生成される副作用に注意する必要があることが強調されました。私たちのケースでは、メインフレームは課金イベントなどの副作用を生成しました。その結果、重複を防ぎ、顧客が2回請求されないようにするために、メインフレームコードに侵入的な変更を加える必要がありました。
バッチ入力境界線と同様に、必要な限りこれらの要求を並列実行できます。しかし、最終的には、プロキシレイヤーでカナリアリリースを使用して、顧客ごとにクラウドに切り替えることで、メインフレームで実行されるワークロードを徐々に削減します。
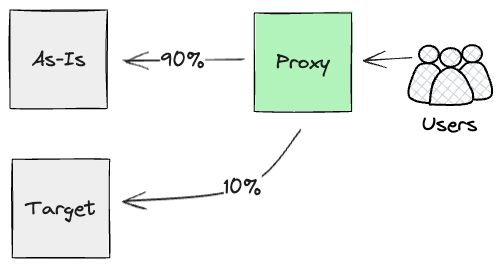
内部インターフェース
その後、メインフレーム内の内部コンポーネントを分析して、より細かい機能をクラウドに移行するために活用できる特定の境界線を特定しました。
粗粒度シーム:データインタラクションとしてのシーム
主な焦点は、プログラム全体にわたる広範なデータベースアクセスでした。ここでは、データベースに書き込んでいる、読み込んでいる、またはその両方を行っているプログラムを特定することから分析を開始しました。データベース自体を境界線として扱うことで、データベースをプログラム間の接続として依存しているフローを分離できました。
データベースリーダー
データベースリーダーに関しては、クラウド環境で新しいデータAPI開発を可能にするために、メインフレームとクラウドシステムの両方が同じデータにアクセスする必要がありました。最初の顧客セグメントの移行のために最初の候補として選択した製品によってアクセスされるデータベーステーブルを分析し、クライアントチームと協力してデータレプリケーションソリューションを提供しました。これにより、変更データキャプチャ(CDC)技術を使用してソースとターゲットを同期することで、テストデータベースからクラウドに必要なテーブルをレプリケートしました。CDCツールを利用することで、クラウド上のターゲットストア間で必要なデータサブセットをほぼリアルタイムでレプリケートすることができました。また、データのレプリケーションにより、クライアントはリレーショナルなものだけでなく、他のストアにもアクセスできるようになるため、データモデルを再設計する機会が得られました(たとえば、ドキュメントストア、イベント、キーバリュー、グラフが考慮されました)。アクセスパターン、クエリ複雑さ、スキーマの柔軟性などの基準に基づいて、データの各サブセットについて、どのテクノロジースタックにレプリケートするかを決定しました。最初の年には、DB2からKafkaとPostgresの両方にレプリケーションストリームを構築しました。
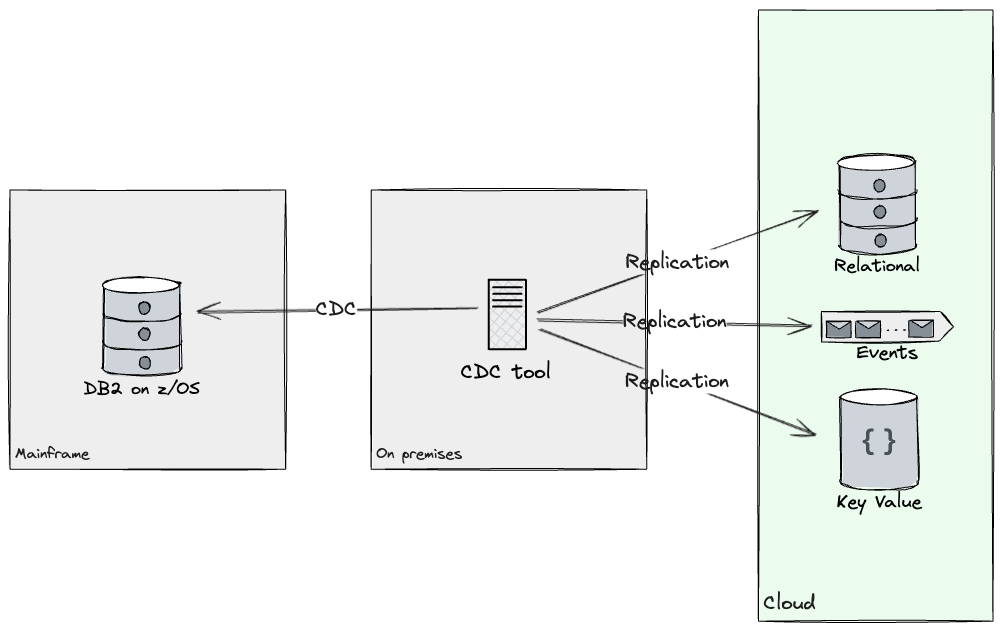
この時点で、データベースから読み取るプログラムを通じて実装された機能は、段階的に再構築され、後でクラウドに移行できる可能性があります。
データベースライター
データベースへの書き込みに関しては、主にメインフレーム上で実行されるバッチワークロードで構成されていました。それらを通過するデータとそこから出力されるデータを慎重に分析した結果、「製品ラインの抽出」を適用して、互いに独立して実行できる個別のドメインを特定することができました(同じフローの一部として実行されることは、変更できる実装の詳細でした)。
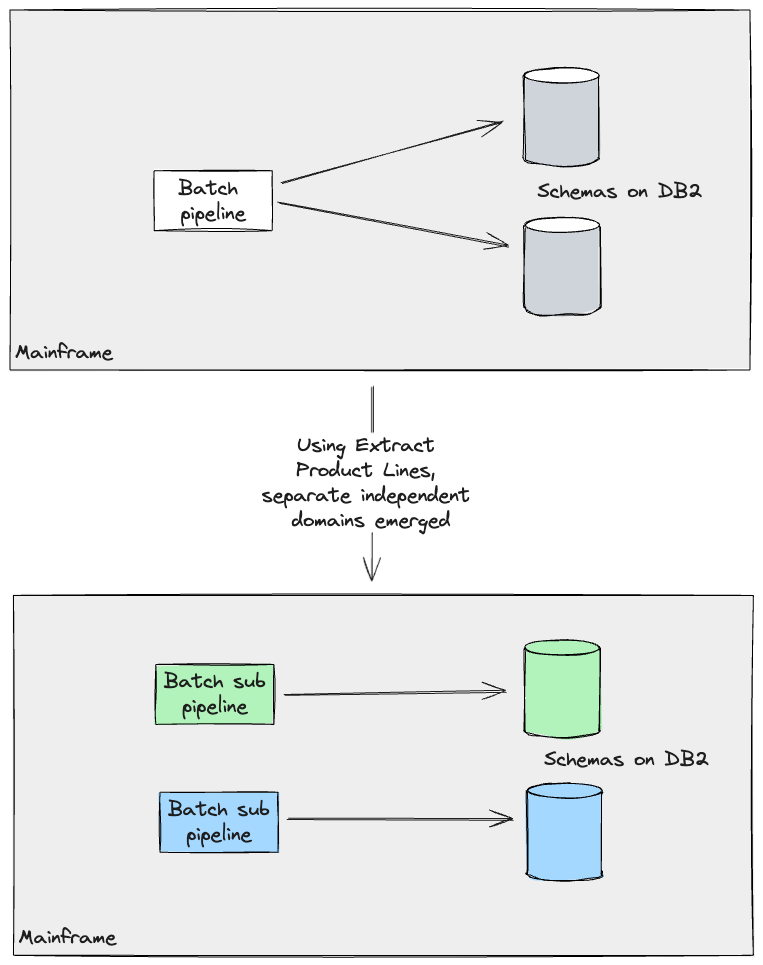
このような原子単位とそのそれぞれの境界を操作することで、他のワークストリームがこれらのパイプラインの一部をクラウド上で再構築し始め、メインフレームの結果と比較することができました。
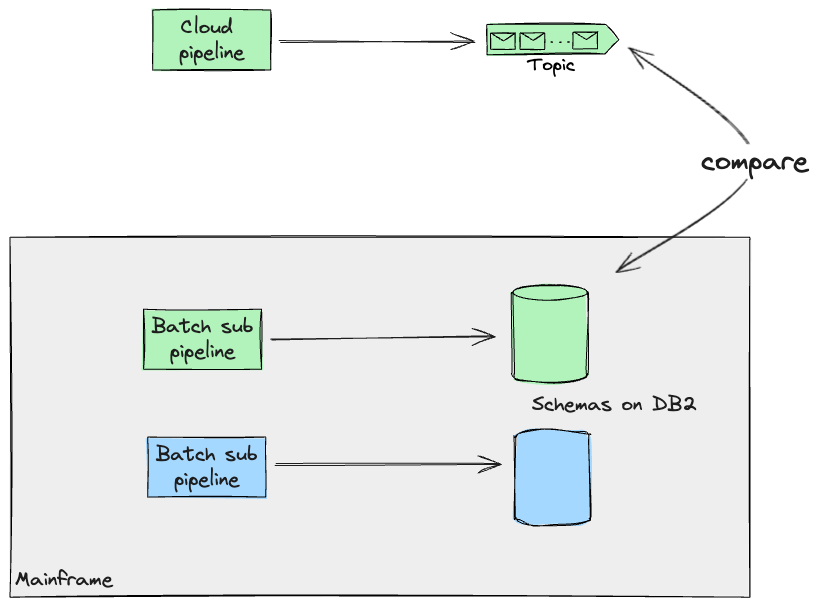
移行アーキテクチャの構築に加えて、私たちのチームは、他のワークストリームがデータパイプラインと製品を設計するために使用するさまざまなサービスを提供する責任がありました。この具体的なケースでは、ファイル転送サービスにファイルをドロップすることでプログラムによって実行されるメインフレーム上のバッチジョブを構築し、それらのパイプラインがメインフレームで生成するジャーナルを抽出してフォーマットしました。これにより、同僚は自動比較テストを通じて作業に対する緊密なフィードバックループを持つことができました。結果が同じであることを確認した後、将来のアプローチとしては、他のチームが各サブパイプラインを1つずつ段階的に移行できるようにすることでした。
サブパイプラインによって生成されたアーティファクトは、さらなる処理(例:オンライントランザクション)のためにメインフレームで必要になる場合があります。したがって、これらのパイプラインが後で完了し、クラウド上に存在する場合、私たちが選択したアプローチは、「レガシーミミック」を使用してデータをメインフレームに複製することでした。これは、このデータに依存する機能がクラウドに移行されるまで行われます。これを実現するために、クラウドへのレプリケーションには同じCDCツールを使用することを検討していました。このシナリオでは、クラウドで処理されたレコードはストリーム上のイベントとして保存されます。メインフレームがこのストリームを直接消費することは、システムの回帰テストを構築およびテストする両方において複雑であり、レガシーコードに対するより侵襲的なアプローチを要求しました。このリスクを軽減するために、まるでそのデータがメインフレーム自体によって生成されたかのように、データをメインフレームが処理できる形式に変換する適応レイヤーを設計しました。これらの変換関数は、単純な場合は、選択したレプリケーションツールでサポートされる場合がありますが、私たちのケースでは、クラウドからの追加の要件に対応するために、レプリケーションツールとともにカスタムソフトウェアを構築する必要があると想定しました。これは、既存の処理をゼロから再構築することから生まれる機会を企業が活用して、それらを改善する(例:効率化)際に一般的に見られるシナリオです。
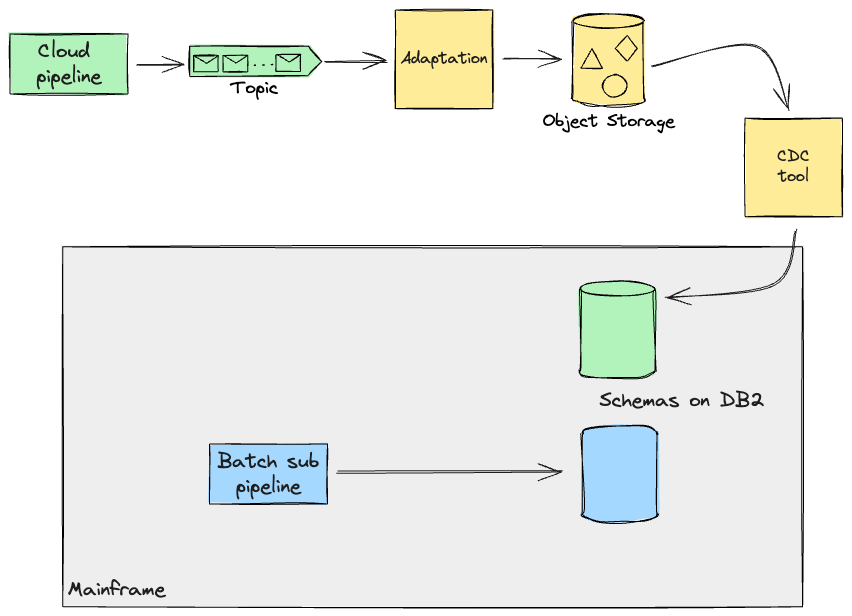
要約すると、クライアント側のSMEと緊密に協力することで、メインフレーム上のバッチワークロードの既存の実装に異議を唱え、データ境界が明確な代替の個別パイプラインを考案することができました。私たちが扱っていたパイプラインは、定義した境界のために同じレコードで重複していなかったことに注意してください。後のセクションでは、私たちが対処しなければならなかったより複雑なケースについて調べます。
粗粒度シーム:バッチパイプラインステップハンドオフ
おそらく、データベースだけが操作できる境界ではないでしょう。私たちのケースでは、出力データベースに永続化するだけでなく、ダウンストリームパイプラインにキュレーションされたデータをさらに処理するために提供するデータパイプラインがありました。
これらのシナリオでは、まずパイプライン間のハンドシェイクを特定しました。これらは通常、フラットファイル/VSAM(仮想記憶アクセス方式)ファイル、またはTSQ(一時記憶キュー)に永続化された状態から構成されます。以下は、パイプラインステップ間のこれらのハンドオフを示しています。

例として、アップストリームに格納されているキュレーションされたフラットファイルを読み取るダウンストリームパイプラインの移行設計を検討していました。メインフレーム上のこのダウンストリームパイプラインは、オンライントランザクションによってクエリされるVSAMファイルを生成しました。このイベント駆動型のパイプラインをクラウド上に構築することを計画していたため、CDCツールを利用してメインフレームからこのデータを取得し、クラウドデータパイプラインが消費するイベントストリームに変換することにしました。これまで報告してきたものと同様に、移行アーキテクチャでは、適応レイヤー(例:スキーマ変換)とCDCツールを使用して、クラウドで生成されたアーティファクトをメインフレームにコピーする必要がありました。
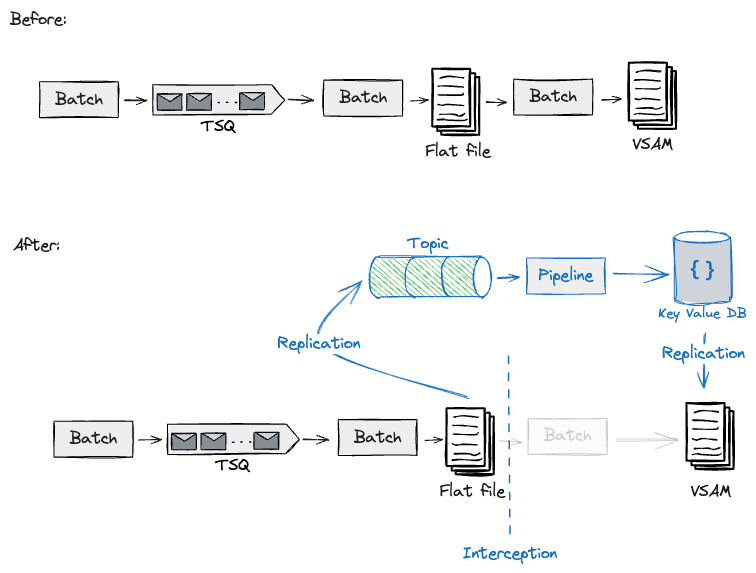
これまでに特定したこれらのハンドシェイクを活用することで、1つの例示的なパイプラインに対してこのインターセプションを構築およびテストし、ダウンストリーム処理を続行するために必要なデータでメインフレームにフィードバックするレガシーミミックを使用して、同じアプローチでクラウド上のアップストリーム/ダウンストリームパイプラインのさらなる移行を設計することができました。これらのハンドシェイクに隣接して、データを抽出およびフィードバックできるように、メインフレームに重要な変更を加えました。ただし、エッジで異なるジョブトリガーを使用することで、コアで同じバッチワークロードを再利用することにより、リスクを最小限に抑えていました。
細粒度シーム:データ特性
場合によっては、上記の内部境界の発見と移行戦略のアプローチでは不十分な場合があり、私たちのプロジェクトでも、移行しようとしていたワークロードの規模のために発生し、ビジネスにとってより高いリスクにつながりました。私たちのシナリオの1つでは、データロードパイプラインからデータを取得する個別モジュールである「IDキュレーション」に取り組んでいました。
顧客IDキュレーションは複雑な領域であり、私たちのケースではクライアントの差別化要因でした。したがって、彼らは、新しいシステムの結果が英国およびアイルランドの人口についてメインフレームよりも精度が低いことを許容できませんでした。モジュール全体をクラウドに正常に移行するには、数十のID検索ルールとその必要なデータベース操作を構築する必要があります。したがって、変更を小さく保ち、頻繁に配信できるようにしてリスクを低く抑えるために、これをさらに分割する必要がありました。
私たちは、SMEとエンジニアリングチームと緊密に協力して、データとルールの特性を特定し、それらを境界として使用して、このモジュールをクラウドに段階的に移行できるようにしました。分析の結果、これらのルールを「単純」と「複雑」の2つの異なるグループに分類しました。
単純なルールは、異なるデータセグメント(つまり、アップストリームの個別のパイプライン)に依存している場合、両方のシステムで実行できます。したがって、これらはIDモジュール空間をさらに分割する機会を表していました。これらは、ファイルの取り込み中にトリガーされた大部分(約70%)を占めていました。これらのルールは、既に存在するIDと新しいデータレコードとの間の関連付けを確立する役割を果たしていました。
一方、複雑なルールは、データレコードがIDの変更(作成、削除、または更新など)の必要性を示す場合にトリガーされました。これらのルールには慎重な処理が必要であり、段階的に移行することはできませんでした。これは、IDへの更新が複数のデータセグメントによってトリガーされる可能性があり、両方のシステムでこれらのルールを並行して操作すると、IDのずれとデータ品質の低下につながる可能性があるためです。これらには、ある時点で1つのシステムがIDを生成することが必要でした。そのため、ビッグバン移行アプローチを設計しました。
メインフレーム上のIDモジュールの元の理解では、データを取り込むパイプラインがDB2で変更をトリガーし、ID、データレコード、およびそれらの関連付けの最新ビューが生成されました。
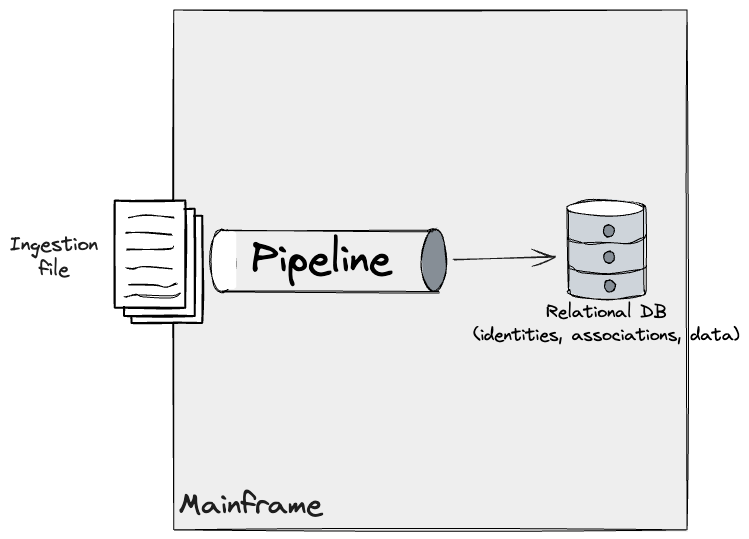
さらに、個別のIDモジュールを特定し、SMEで発見したシステムのより深い理解を反映するようにこのモデルを改良しました。このモジュールは複数のデータパイプラインからデータを取得し、DB2に単純なルールと複雑なルールを適用しました。
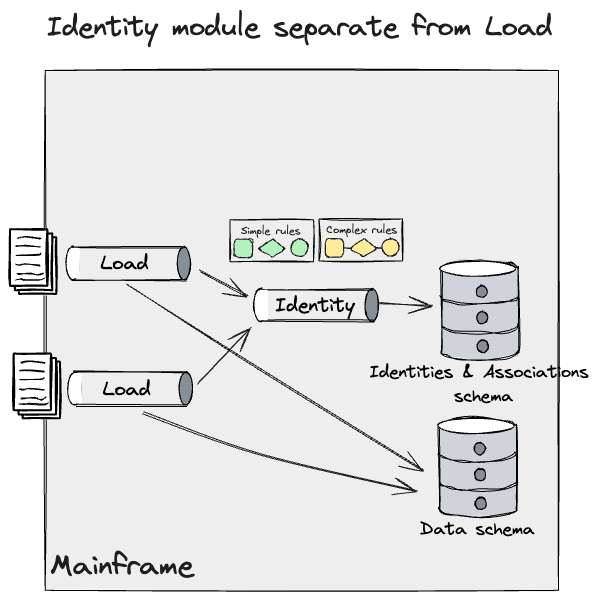
ここで、データパイプラインについて前に書いたのと同じテクニックを適用できますが、IDについてはより粒度が高く段階的なアプローチが必要でした。
異なるデータセグメントで動作するという条件付きで、両方のシステムで実行できる単純なルールに取り組む計画を立てました。これは、IDデータを維持するシステムが1つしかないという制約があったためです。私たちは、バッチパイプラインステップハンドオフを使用し、イベントインターセプトを適用して、データを取り込み、フォークする(システムハンドオフ間でデータが失われないことを確認できるようになるまで一時的に)設計に取り組みました。これにより、取り込まれたファイルに対して分割統治のアプローチを採用し、クラウド上で並列ワークロードを実行して単純なルールを実行し、メインフレーム上のIDに変更を適用し、それを段階的に構築することができます。単純なバケットに分類されるルールが多くありました。したがって、まだ実装されていないルールをトリガーする必要がある場合に、メインフレームにフォールバックする機能がターゲットIDモジュールに必要でした。これは次のようになります。
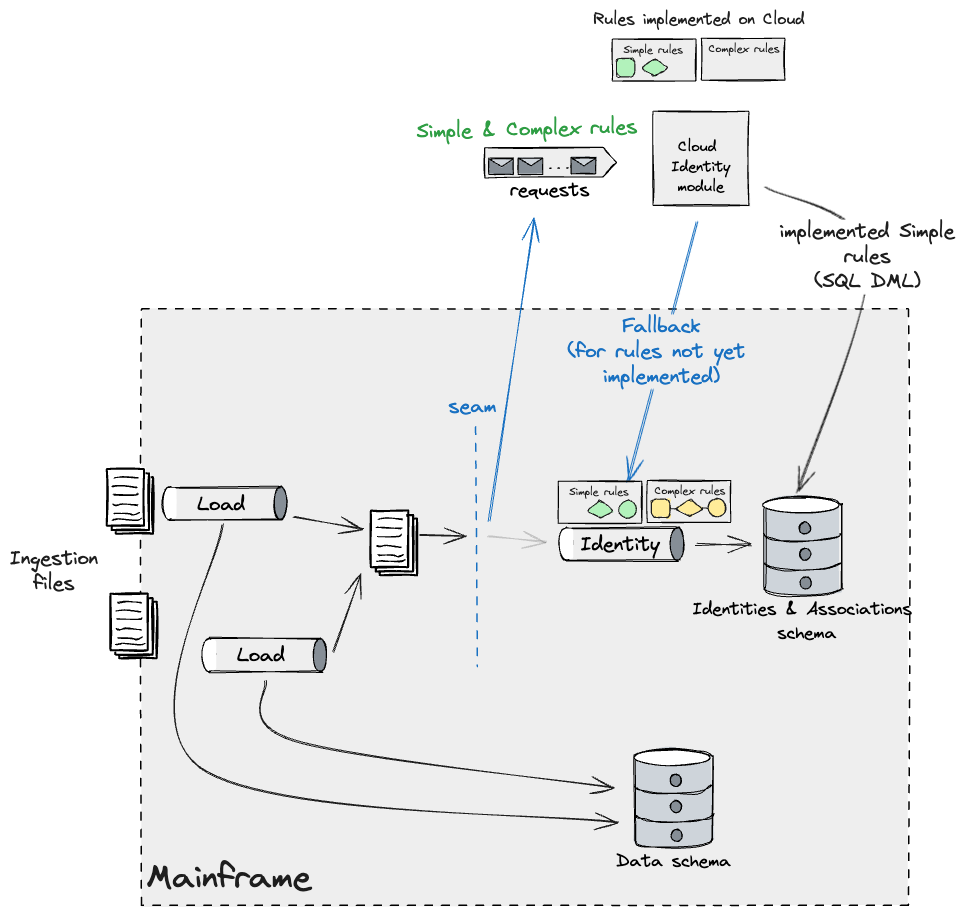
クラウドIDモジュールの新しいビルドがリリースされると、フォールバックメカニズムを通じて適用される単純なバケットに属するルールが少なくなります。最終的には、その段階を通して観測されるのは複雑なものだけになります。前に述べたように、これらはIDのずれの影響を最小限に抑えるために、すべて一度にマイグレーションする必要がありました。私たちの計画は、クラウドデータベースレプリカに対して複雑なルールを段階的に構築し、広範な比較テストを通じて結果を検証することでした。
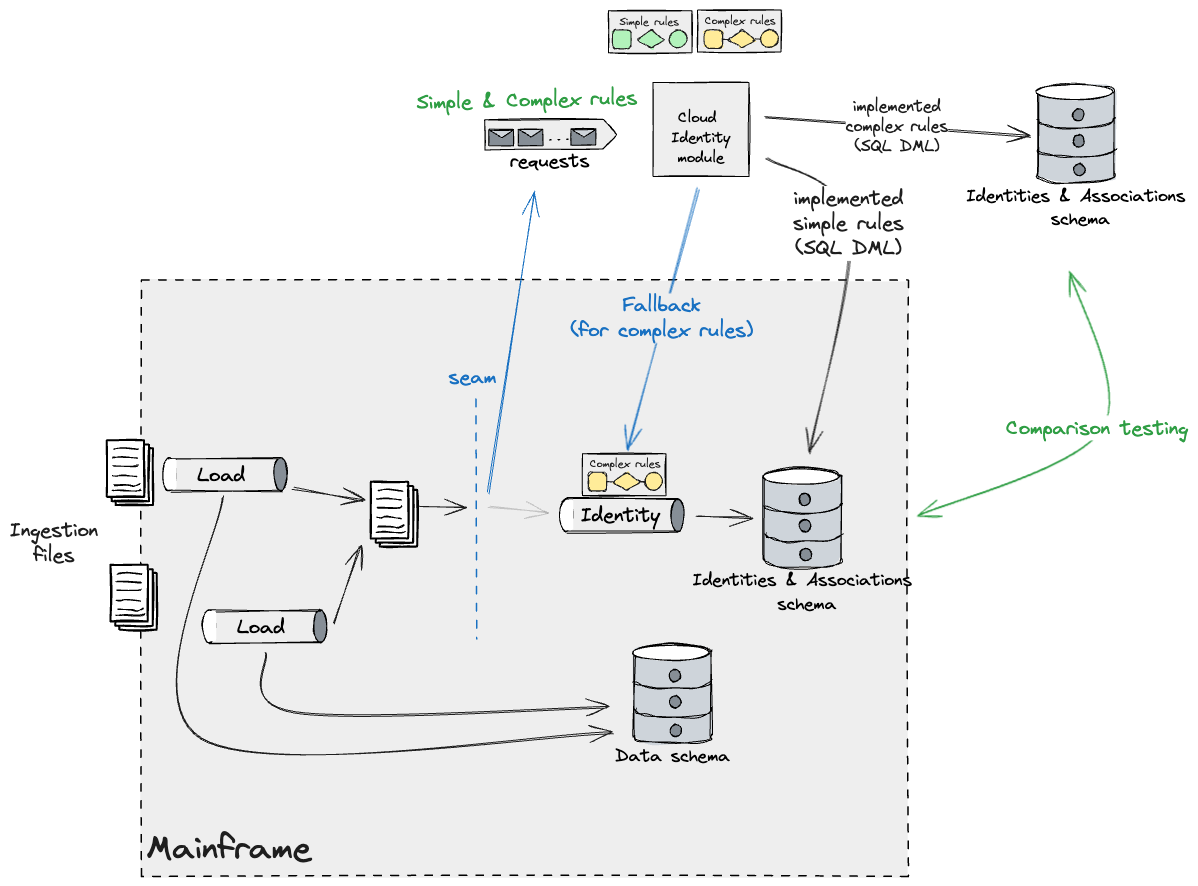
すべてのルールが構築されたら、このコードをリリースし、メインフレームへのフォールバック戦略を無効にします。これのリリース後、メインフレームのIDと関連付けデータは、クラウドIDモジュールによって管理される新しいプライマリストアのレプリカになります。したがって、メインフレームを機能させたままにするにはレプリケーションが必要です。
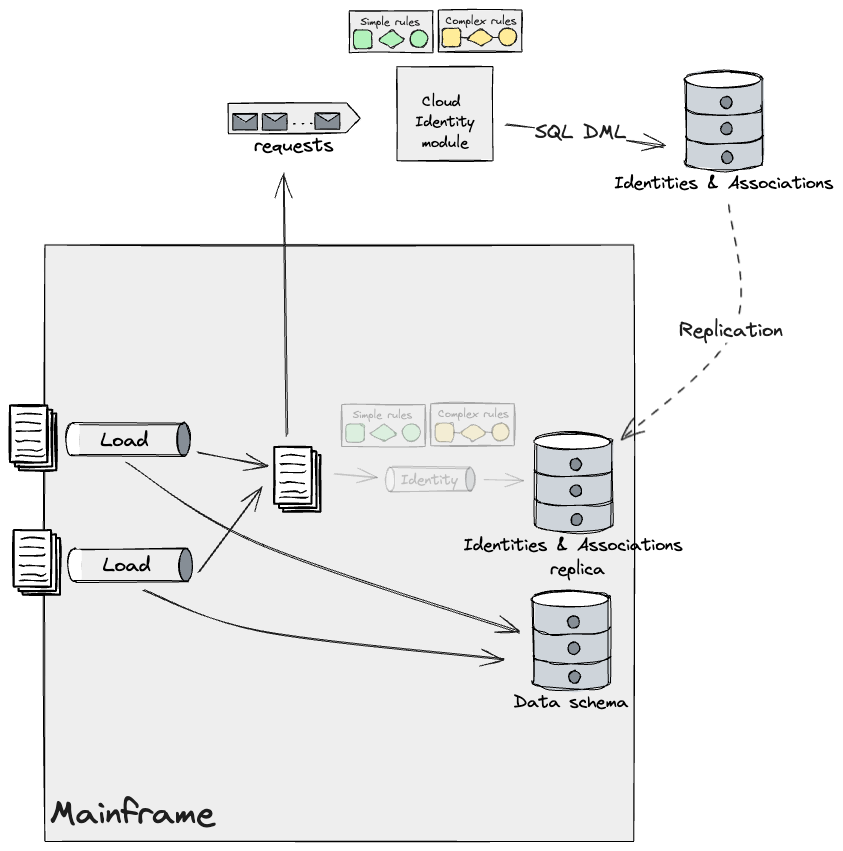
他のセクションで前述したように、私たちの設計ではレガシーミミックとアンチ腐敗レイヤーを採用し、メインフレームからクラウドモデルへのデータ、およびその逆の変換を行いました。このレイヤーは、システム全体にアダプターのシリーズで構成されており、データはイベント駆動型データパイプラインを使用してクラウドが消費するためにメインフレームからストリームとして流れ出し、既存のバッチジョブが処理できるようにメインフレームにフラットファイルとして戻されます。簡潔にするために、上記の図にはこれらのアダプターは示されていませんが、境界がどれだけ細かいかに関係なく、データがシステム間を流れるたびに実装されます。残念ながら、ここでの私たちの仕事は主に分析と設計であり、CDCツールとファイル転送サービスを使用して、必要な形式でメインフレームに出入りするデータを送信できることを確認するスパイクを実行する以外に、エンドツーエンドで仮定を検証する次のステップに進むことができませんでした。メインフレームの周りの必要な足場を構築し、要件を収集するために現状のパイプラインをリバースエンジニアリングするのに必要な時間は相当なものであり、プログラムの最初のフェーズのタイムフレームを超えていました。
細粒度シーム:ダウンストリーム処理ハンドオフ
ダウンストリームのバッチワークロードを供給するためのアップストリームパイプラインで採用されたアプローチと同様に、オンラインフローの移行にはレガシーミミックアダプターが使用されました。既存システムでは、顧客API呼び出しによって一連のプログラムがトリガーされ、課金や監査証跡などの副作用が発生し、メインフレーム上の適切なデータストア(主にジャーナル)に永続化されます。
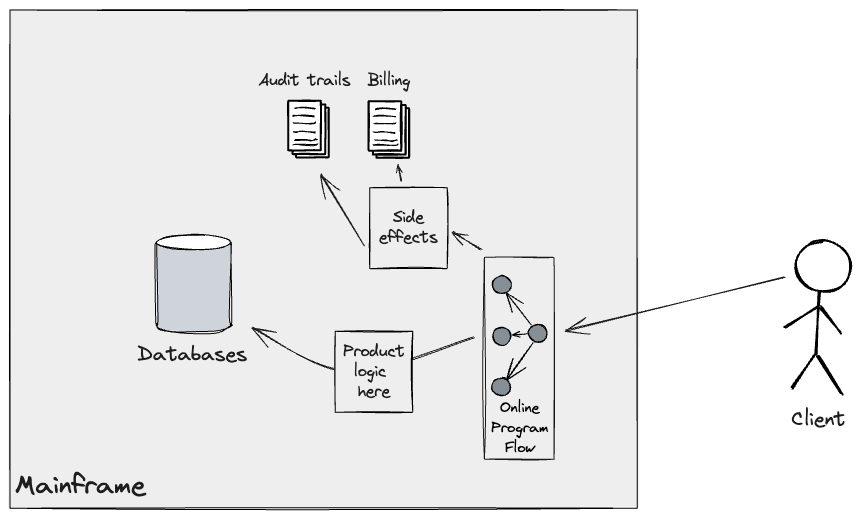
オンラインフローをクラウドに段階的に移行するには、これらの副作用を新しいシステムで直接処理するか(これによりクラウドの範囲が拡大します)、またはメインフレームにアダプターを戻して、それらに関連する基盤となるプログラムフローを実行およびオーケストレーションするかを確保する必要がありました。当社では、CICS Webサービスを使用して後者を選択しました。構築したソリューションは機能要件についてテストされましたが、最初の段階では本番環境のようなメインフレームのテスト環境を用意することが困難だったため、クロスファンクショナルな要件(レイテンシやパフォーマンスなど)は検証できませんでした。次の図は、アダプターの実装に従って、移行された顧客のフローを示しています。
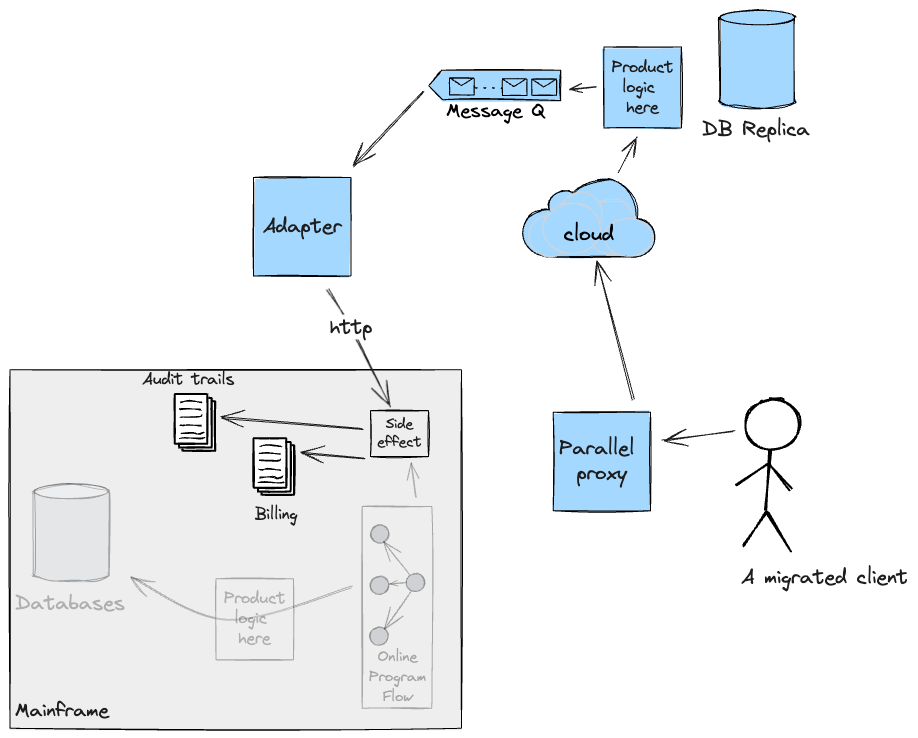
アダプターは一時的な足場として計画されていたことに注意することが重要です。クラウドがこれらの副作用を自分で処理できるようになった後は、継続性のために必要な限りデータをメインフレームに複製する計画だったため、アダプターには有効な目的はありませんでした。
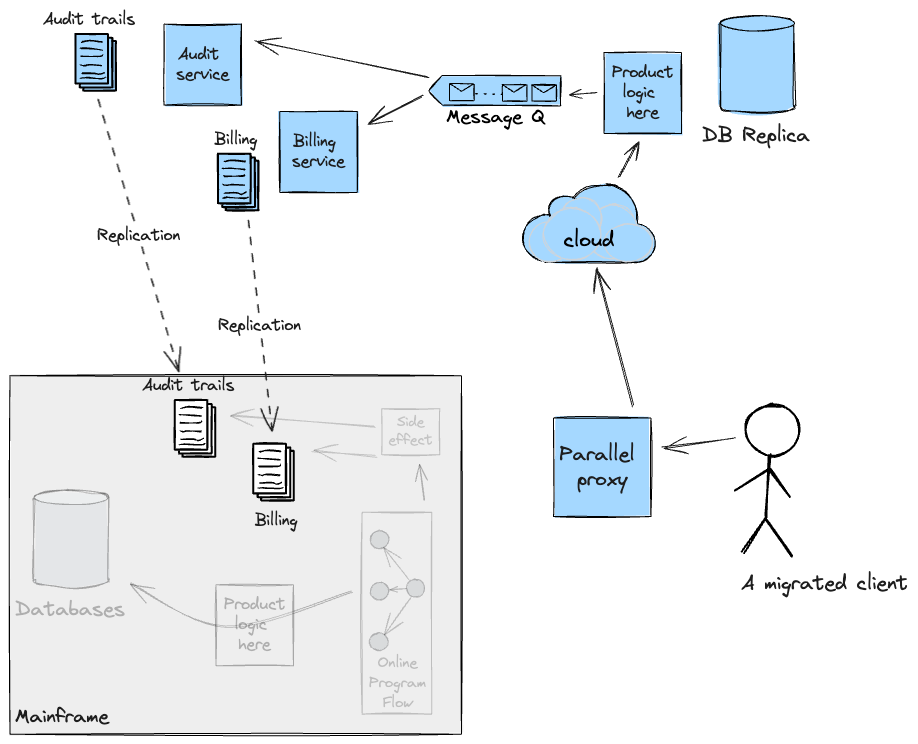
新規製品開発を可能にするためのデータレプリケーション
上記の手法を基に、組織は、メインフレームに保持されているコアデータからの分析データまたは集計データを中心とした製品アイデアを持つ場合があります。これらは通常、レポート作成のユースケースや、過去期間にわたるデータのサマリーなど、最新の情報がそれほど必要ない場合です。このような状況では、データレプリケーションの適切な使用を通じて、早期にビジネス上のメリットを得ることができます。
うまく行けば、これは比較的少ない初期投資で新しい製品開発を可能にし、ひいてはモダナイゼーションの取り組みにも弾みがつきます。
最近のプロジェクトでは、クライアントはすでにこの取り組みを開始しており、CDCツールを使用してDB2のコアテーブルをクラウドにレプリケートしていました。
これは新しい製品の発売を可能にするという点で素晴らしいことでしたが、欠点もありませんでした。
データベースを複製する際にスキーマを抽象化する手順を実行しない限り、新しいクラウド製品は構築されるとすぐにレガシー・スキーマに依存することになります。これは、ターゲット環境で今後行う可能性のあるイノベーションを阻害する可能性があります。なぜなら、アプリケーションのコアを変更するという追加の抵抗要因が生まれたからです。しかし、これはさらに悪いことで、ちょうど資金を投入したばかりの新しい製品の変更に再び投資したくはないでしょう。したがって、提案された設計は、レプリカデータベースから最適化されたストアとスキーマへのさらなるプロジェクションで構成されており、その上に新しい製品が構築されます。
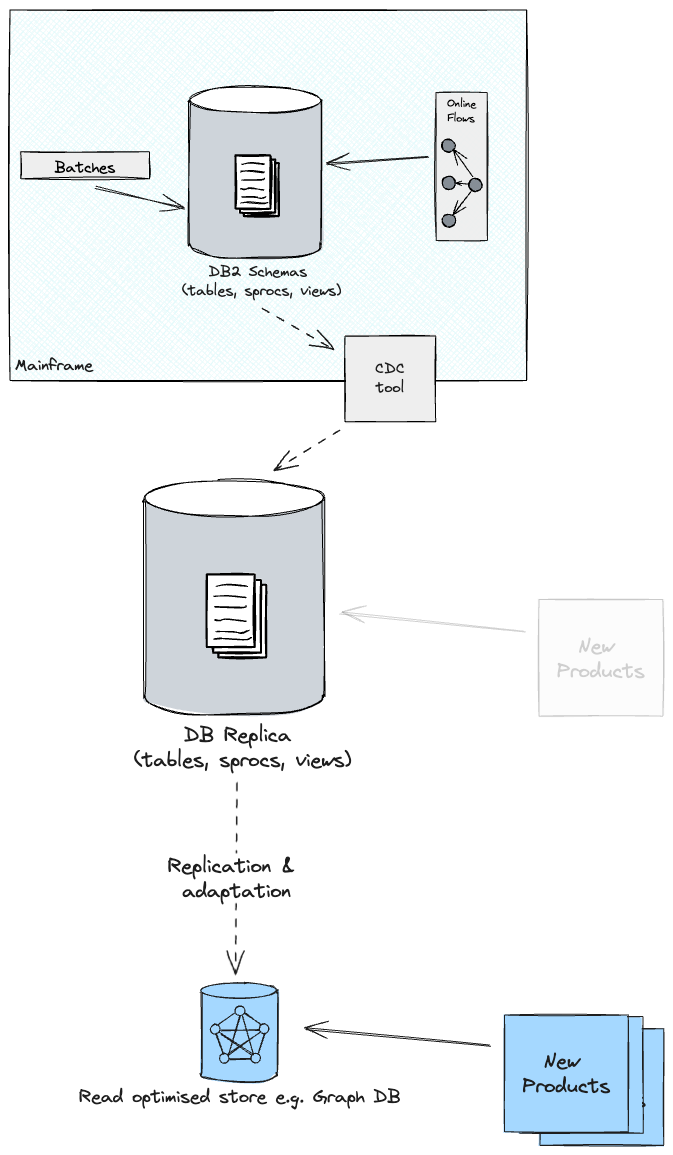
これにより、スキーマをリファクタリングし、場合によってはデータモデルの一部を非リレーショナルストアに移行する機会が得られます。これにより、SMEで観察されたクエリパターンがより適切に処理されます。
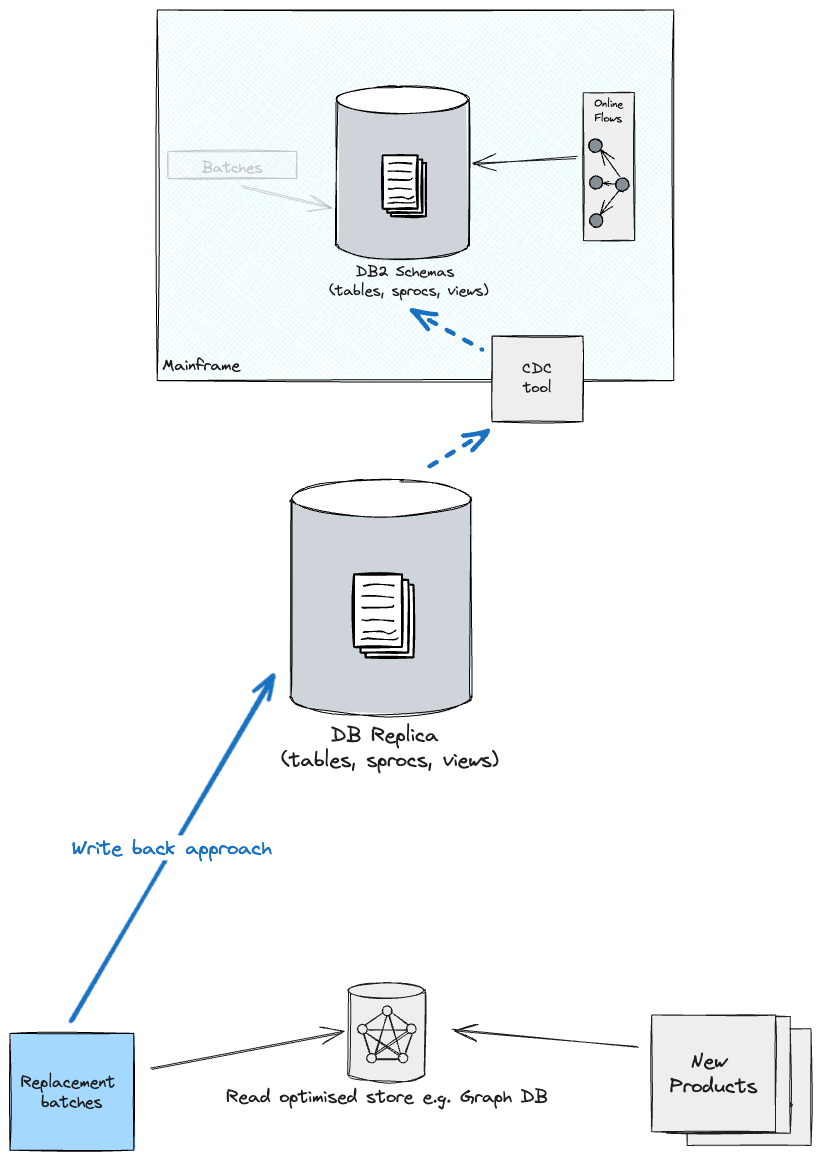
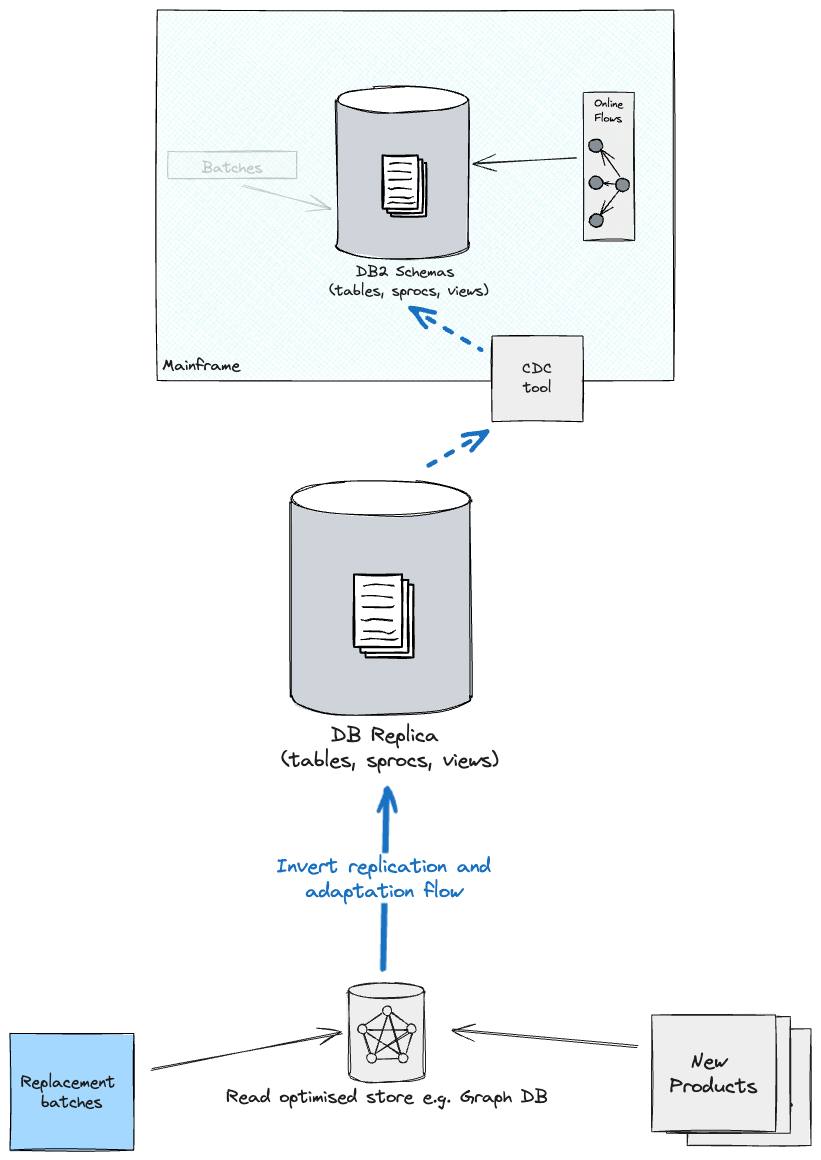
バッチワークロードの移行後、すべてのストアを同期状態に保つために、新しいプライマリ(以前はレプリカとして知られていたもの)へのライトバック戦略を検討するか(これにより、メインフレーム上のDB2にフィードバックされますが、バッチから古いスキーマへの依存関係が高くなります)、または最適化されたストアをソースとして、新しいプライマリをターゲットとしてCDCとアダプテーションレイヤーの方向を逆にします(各データセグメントごとにレプリケーションを個別に管理する必要がある可能性があります。つまり、あるデータセグメントはレプリカから最適化されたストアにレプリケートされ、別のセグメントは反対方向にレプリケートされます)。
結論
メインフレームからのオフロードには、考慮すべき点が複数あります。メインフレームから移行するシステムのサイズによっては、この作業にかなりの時間がかかる可能性があり、増分デュアルランのコストは無視できません。これにかかる費用はさまざまな要因によって異なりますが、2つのシステムを並行してデュアルランすることでコスト削減を期待することはできません。したがって、ビジネスは早期に価値を生み出し、関係者からの承認を得て、複数年にわたるモダナイゼーションプログラムに資金を提供する必要があります。当社は増分デュアルランを、チームがビジネスの需要に迅速に対応するためのイネーブラーと見なしており、アジャイルおよび継続的デリバリーのプラクティスと連携しています。
まず、システム全体の状況とシステムへのエントリポイントを理解する必要があります。これらのインターフェースは、構築中の新しいシステムへの外部ユーザー/アプリケーションの移行を可能にする上で重要な役割を果たします。この移行を通じて外部契約を自由に再設計できますが、メインフレームとクラウドの間にアダプテーションレイヤーが必要です。
| シーム | レガシー置換のパターン | 概要 |
|---|---|---|
| バッチ入力 | イベントインターセプト、デュアルラン | バッチシステムへの外部入力のキャプチャとリダイレクト |
| APIアクセス | イベントインターセプト、ダークローンチ、デュアルラン、カナリアリリース | APIへの呼び出しのキャプチャとリダイレクト |
次に、メインフレームシステムが提供するビジネス機能を特定し、それらを実装する基盤となるプログラム間のシームを特定する必要があります。機能主導型のアプローチは、別の複雑なシステムを構築していないことを保証し、責任と懸念事項を適切なレイヤーで分離するのに役立ちます。APIを公開したり、イベントを消費したり、データをメインフレームに複製したりする一連のアダプターを構築することになります。これにより、メインフレームで実行されている他のシステムは、そのまま機能し続けることができます。これらのアダプターを再利用可能なコンポーネントとして構築するのがベストプラクティスです。なぜなら、特定の要件に応じてシステムの複数の領域でそれらを使用できるからです。
| シーム | レガシー置換のパターン | 概要 |
|---|---|---|
| データのやり取り | 製品ラインの抽出、デュアルラン、レガシーミミック | リーダーとライターを特定し、それらを切り離し、必要に応じてバックフィルします。 |
| バッチパイプラインステップのハンドオフ | レガシーミミック、トランジショナルアーキテクチャ | 既存のバッチフロー内に新しいステップを挿入します。 |
| データ特性 | イベントインターセプト、トランジショナルアーキテクチャ | データをセグメント化することにより、ワークロードを段階的にモダナイズします。 |
| ダウンストリーム処理のハンドオフ | レガシーミミック、トランジショナルアーキテクチャ | 必要な副作用を保持するためにレガシーにコールバックします。 |
第三に、移行しようとしている機能がステートフルであると仮定すると、メインフレームがアクセスできるデータのレプリカが必要になる可能性があります。ここでは、データをレプリケートするCDCツールを使用できます。データレプリケーションのCFR(クロスファンクショナル要件)を理解することが重要です。一部のデータはクラウドへの高速レプリケーションレーンを必要とする可能性があり、選択したツールは理想的にはこれらを提供する必要があります。特定のシナリオに考慮し、調査すべきツールやフレームワークは現在多数存在します。例えば、DB2テーブルにはQlik Replicate、VSAMストアにはPrecisely Connectをより具体的に検討しました。多数のCDCツールを評価できます。
クラウドサービスプロバイダーもこの分野で新しいオファリングを立ち上げています。たとえば、Google Cloudによるデュアルランは最近、独自のデータレプリケーションアプローチを立ち上げました。
この規模の作業プログラムを提供するためにチームのチームを動員することについてより包括的な見解を得るには、同僚のソフィー・ホールデンによる記事“ゾウを食べる”を参照してください。
最終的に、この記事の一部として簡単に触れられた、考慮すべきことが他にもあります。その中で、テスト戦略は、新しいシステムを正しく構築していることを確認するために非常に重要な役割を果たします。自動化されたテストは、ターゲットシステムを構築するデリバリーチームのフィードバックループを短縮します。比較テストは、両方のシステムが技術的な観点から同じ動作を示すことを保証します。これらの戦略は、合成データ生成と本番データの難読化技術と併用することで、トリガーしようとするシナリオをより細かく制御し、その結果を検証できます。最後に、本番環境での比較テストにより、デュアルランで実行されているシステムは、時間の経過とともに、レガシーシステム単体と同じ結果を生み出すことが保証されます。必要に応じて、少なくとも顧客がシステムとやり取りするなど、外部の観測者の視点から結果を比較します。さらに、中間システムの結果を比較することもできます。
この記事が、メインフレームのオフロードの取り組みを開始する際に考慮すべき点を明確に示していることを願っています。私たちの関与は複数年にわたるプログラムの最初の数ヶ月であり、私たちが議論したソリューションの一部は、開始の非常に初期の段階にありました。それにもかかわらず、この作業から多くのことを学び、これらのアイデアを共有する価値があると確信しています。取り組みを価値のある実行可能なステップに分割するには常にコンテキストが必要ですが、私たちの学びとアプローチが開始に役立ち、本番環境まで進め、独自のロードマップを実現できることを願っています。
重要な改訂
2024年4月10日: データレプリケーションの使用に関する最終回を公開
2024年4月4日: バッチパイプラインに関する内部シームを公開
2024年4月2日: データベースに関する内部シームを公開
2024年3月27日: 外部インターフェースに関するシームを公開
2024年3月26日: 第1回を公開