
プレゼンテーションロジックの整理
プレゼンテーションのロジックを分割するにはいくつかの方法があります。
2006年7月11日

これは、私が2000年代半ばに行っていた「エンタープライズアプリケーションアーキテクチャ開発のさらなる発展」に関する記述の一部です。残念ながら、それ以来、他の多くのことに気を取られてしまい、さらに取り組む時間がありません。また、近い将来、それに取り組む時間を見つけることができるとは思えません。そのため、この資料は非常にドラフト版であり、再び取り組む時間を見つけることができるまで、修正や更新は行いません。
プレゼンテーションレイヤーを設計する際に最も役立つことの一つは、Separated Presentationを強制することです。これを実行したら、次のステップは、プレゼンテーションロジック自体をどのように編成するかを考えることです。単純なウィンドウの場合は、単一のクラスで十分かもしれません。しかし、より複雑なロジックは、より幅広い分解につながります。
最も一般的なアプローチは、アプリケーションの各ウィンドウに対して1つのクラスを設計することです。このクラスは通常、GUIライブラリのウィンドウクラスを継承し、そのウィンドウを処理するために必要なすべてのコードを含みます。ウィンドウに複雑なパネルが含まれている場合は、そのパネル用に別のクラスを用意することがあります。これにより、複合構造になります。この種の複合構造については、かなり簡単なので詳しく説明しません。代わりに、単一のウィンドウ内の基本的な動作を整理する方法に焦点を当てます。
アルバムリストの実行例
ここでの多くの議論と例では、発生する問題を議論するために、単一の例の画面(図1)を使用します。ウィンドウには音楽録音に関する情報が表示されます。各アルバムについて、アーティスト、タイトル、クラシック録音かどうか、クラシックの場合は作曲家を表示します。プレゼンテーションロジックの要素をいくつか含めるために例を選択しました。
{kind=link}
- リストの選択によって、どのアルバムのデータがフィールドに表示されるかが決まります。
- ウィンドウのタイトルは、現在表示されているアルバムのタイトルから派生します。
- 作曲家フィールドは、クラシックチェックボックスがオンの場合にのみ有効になります。
- 適用ボタンとキャンセルボタンは、データが編集された場合にのみ有効になります。
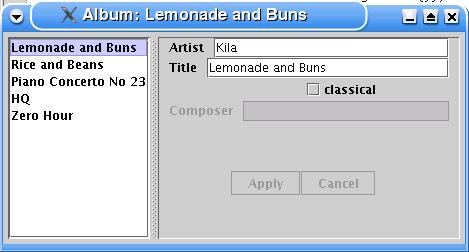
図1:シンプルなアルバム情報ウィンドウ
プレゼンテーションロジックをViewから分離する
Autonomous Viewにすべてのプレゼンテーションロジックを配置することは一般的で実用的ですが、欠点もあります。Autonomous Viewで最近よく話題になる欠点は、テストに関することです。GUIウィンドウを介してプレゼンテーションをテストすることは、多くの場合、面倒であり、場合によっては不可能です。GUIを駆動する何らかのUIドライバを作成する必要があります。一部の人は、生のマウスイベントやキーボードイベントをシミュレートするGUIツールを使用しますが、これらのツールは通常、プレゼンテーションにわずかな変更があった場合に偽陽性を返す、壊れやすいテストを作成します。より詳細なツールは、UIコントロールをより直接的にアドレス指定します。これらは壊れにくいですが、それでも厄介です。また、GUIフレームワークがAPIを介した直接制御アクセスを十分にサポートしている必要がありますが、そうでないものもあります。
その結果、プログラマーベースのテストを提唱する多くの人は、humble dialog(ウルトラシンGUIとも呼ばれる)を提唱しています。ここでの中心的な考え方は、すべてのロジックを他のプレゼンテーションレイヤークラスに移動することで、UIコントロールを含むクラスを可能な限り小さく、単純にすることです。このGUIコントロールクラスは通常、後で説明する理由でビューと呼ばれます。次に、GUIコントロールを使用せずに、必要な場合は控えめなビューをスタブ化して、インテリジェントクラスに対してテストを実行できます。ビューは非常に単純なので、うまくいかないことはほとんどなく、インテリジェントクラスで作業することでほとんどのバグを見つけることができます。このスタイルのテストに使用したい用語は皮下テストです。テストはアプリケーションの皮膚のすぐ下で動作するためです。
皮下テストは、最近プレゼンテーションクラスを分割する主な理由ですが、このような分割を検討する価値がある他のいくつかの理由があります。インテリジェントクラスは、コントロールの選択、コントロールのレイアウト、さらには正確なUIフレームワーク自体など、ビューのいくつかの側面から独立させることができます。これにより、同じ論理動作で複数の異なるビューをサポートできます。これは、アプリケーションの複数の「スキン」をサポートするのに役立ちますが、控えめなビューを置き換えるだけで、限られたバリエーションしか実行できません。
ある意味では、プレゼンテーションロジックを分離すると、プレゼンテーションのプログラミングが容易になります。動作を記述している間、ビューのレイアウトの詳細を無視することができ、ビューのコントロールに対してより快適なAPIを提供します。しかし、これに対して、プレゼンテーションロジックを分離すると、分離をサポートするための余分な仕組みが必要になるという事実があります(その性質は、どのパターンを使用するかによって異なります)。その結果、分離がプレゼンテーションを簡素化するか複雑化するかについて、両方向に合理的な議論があります。
この分割を行うための歴史的な先例があります。それはModel View Controller(MVC)の一部でした。[P of EAA]で説明したように、MVCアプローチでは2つの分離を行いました。最も重要な分離はSeparated Presentationでした。これは、モデルをビュー/コントローラーから分離することです。ビューとコントローラーのもう1つの分離は、リッチクライアントGUIフレームワークでは一般的ではありませんでしたが、Webベースのユーザーインターフェイスで復活しました。MVCでは、ビューはモデル内の情報の単純な表示であり、コントローラーはさまざまなユーザー入力イベントを処理しました。UIコントロールがユーザー入力イベントを表示および受信するように設計されているため、これはほとんどのGUIフレームワークではうまく機能しません。
控えめなビューを作成するには、設計は、ユーザーイベントの処理とドメイン情報の表示ロジックの両方で、ビューからすべての動作を移動する必要があります。これを行うための主な方法は2つあります。1つ目は、動作がプレゼンターに移動されるModel-View-Presenterスタイルです。これは、コントローラーの一種と考えることができます。プレゼンターはユーザーイベントを処理し、ビューの更新にもある程度の役割を果たします。Supervising ControllerとPassive Viewは、このアプローチの2つのスタイルです。Supervising Controllerは、ビューに単純なビューロジックを配置し、Passive Viewは、すべてのビューロジックをコントローラーに配置します。もう1つのスタイルは、すべてのデータと動作をキャプチャするモデルの一種を作成するPresentation Modelです。これにより、ビューに必要なのは単純な同期のみになります。
どちらのスタイルでも、ビューはユーザーイベントの初期ハンドラーですが、すぐにコントローラーに制御を渡します。
これら3つのパターンはすべて、追加のクラスを導入することで、間違いなくより複雑な設計になります。責任を果たすために、過剰なことをするクラスを別々のクラスに分割することは良い習慣ですが、問題は、Autonomous Viewが複雑すぎるかどうかということです。確かに、他のパターンは、他のテストオプションと、複数のビューをサポートする機能を提供します。複数のビューが必要なく、ビューを介したテストに満足している場合は、特にウィンドウが複雑すぎない場合は、Autonomous Viewで問題ないでしょう。
Presentation Model、Supervising Controller、Passive Viewの選択は、より恣意的です。これは、GUI環境でパターンを実行するのがどれほど簡単か、個人の好みに依存します。
MVCの用語を使用するたびに、必然的にモデルとは何かという疑問が生じます。古典的なSmalltalk MVCでは、モデルはドメインモデルでした。一般的に、最近のMVCの議論におけるモデルは、ドメインレイヤーへのインターフェイスを意味します。これは、古典的なドメインモデル、サービスレイヤー、トランザクションスクリプト、テーブルモジュール、またはドメインの他の表現である可能性があります。実際、別のドメインレイヤーがない場合、モデルはデータベースへのインターフェイスである可能性が高くなります。
画面、レイヤー、データ
ほとんどのエンタープライズアプリケーションでは、データの編集が行われます。このデータは通常、アプリケーションの複数のレイヤー間でコピーされ、おそらく同じシステムを使用する複数のユーザー間でコピーされます。エンタープライズアプリケーションの動作の多くは、このデータの変更がどのように調整され、データがレイヤー間でどのように同期されるかに依存します。これについて考えるための一般的に受け入れられている用語はありません。この本の目的のために、以下を課します。
データのレイヤー
最初に考えるべき問題は、異なるレイヤーにあるデータの異なるコピーです。これを物理的な用語で考えると、通常、メモリ内のデータとデータベースまたはファイル内のデータの間に違いがあります。これは、一時的なデータと永続的なデータの違いと考えることができます。しかし、私はそれが通常これよりも少し多いことに気づきました。メモリ内のデータでさえ、多くの場合2つの場所にあります。多くの場合、画面上のデータと、画面をバックアップする何らかの形式のインメモリストアの間に違いがあります。これは、データベースから取得された(ただし、まだデータベースにコミットされていない)レコードセット、またはドメインモデルである可能性があります。
ワードプロセッサでドキュメントを操作することを考えてみましょう。ドキュメントはディスク上にあり、ワードプロセッサでドキュメントを開いてドキュメントのテキストを編集しました。これにより、ディスク上のテキストとは異なるメモリ内のテキストが得られます。次に、ダイアログボックスを開いて、テキストの一部の書式を変更します。多くの場合、ダイアログボックスで書式を変更できますが、適用ボタンを押すまで、基になるテキストは変更されません。ダイアログボックスの書式設定データはインメモリデータですが、メインのインメモリドキュメントのデータとは異なります。
この本で使用する用語は、画面状態、セッション状態、およびレコード状態です。画面状態は、ユーザーインターフェイスに表示されるデータです。セッション状態は、ユーザーが現在作業しているデータです。セッション状態は、ユーザーには一時的なものとして認識され、通常、作業を保存または破棄する機能があります。レコード状態は、より永続的なデータ、セッション間で存在することが期待されるデータを指します。
セッション状態は主にメモリ内で作用しますが、多くの場合、ディスクに保存されます。最新のワードプロセッサでは、停電やシステムクラッシュによる作業の損失を回避するために、救助ファイルが保存されることがよくあります。エンタープライズアプリケーションは、ローカルのチェックポイントファイルにセッション状態を保存したり、サーバーがリクエスト間で状態をディスクに保存したりする場合があります。
エンタープライズアプリケーションでは、セッション状態とレコード状態の特定の区別は、レコード状態がシステムの複数のユーザー間で共有されるのに対し、セッション状態は、作業中のユーザーのみに表示されるプライベート状態であるということです。したがって、ユーザーは変更をより永続的な形式で保存することを決定するだけでなく、同僚と共有することも決定しています。セッション状態は、多くの場合、単一のビジネストランザクションと相関しますが、多くの場合、複数のシステムトランザクションにまたがります。この状況では、オフライン同時実行が必要になることがよくあります。
すべてのアプリケーションがセッション状態を持つわけではありません。画面状態とレコード状態だけを持つものもあります。保存時にデータへの変更が直接レコード状態に反映される場合です。このような場合、セッション状態が全くないか、変更が即座にレコード状態に書き込まれるため、セッション状態は常にレコード状態と同期しています。セッション状態がないと、セッション状態の管理を気にする必要がないため、アプリケーションは大幅に簡素化されます。ユーザーが作業内容の消失を心配する必要がないため、多くのアプリケーションでユーザーにも好まれます。しかし、セッション状態を省くことは、すべてがバラ色というわけではありません。ユーザーは、作業中のシナリオを試行錯誤し、気に入らなければ破棄するという操作ができなくなります。また、複数のユーザーが同時に作業するアプリケーションでは、ユーザーが独立して作業することができなくなります。
さらに、状態のレイヤーを追加することもできます。その一例が、クライアント層とサーバー層の両方にセッション状態が保存される場合です。これらの状態は独立して変更できますが、通常は同期方法に関するかなり厳しいルールがあり、管理は非常に簡単になっています。
追加レイヤーの例としては、開発者がチームで作業する場合が挙げられます。この場合、レコード状態は共有ソースコードリポジトリの状態です。開発者のローカルマシン上の作業コピーは、ディスク上にあるセッション状態の一種です。この場合、それ自体がやや一時的なものです。さらに、IDEには他の表現もあります。最新のIDEでは、メモリ内に構文ツリーを保持し、常に更新します。さらに、画面に表示されるテキストもあります。この場合、3つ以上のレイヤーがありますが、開発者が画面で見るもの、プライベートなセッションデータ、共有の永続的なデータについて考えることは依然として有用です。効果的に推論するために、各データセットに名前を付け、それらを別々のレイヤーとして扱います。特定のアプリケーションには常に独自のセットがありますが、この説明では、画面、セッション、レコード状態という一般的な3つ組に焦点を当てます。
ほとんどの場合、ユーザーは一度に1つのセッションで作業します。時折、複数のセッションで同時に作業することがあります。1つのセッションでの変更が、両方がレコード状態と同期するまで他のセッションに表示されないため、混乱を招くことがよくあります。2つのセッションを同期することでこれを回避できますが、通常は煩雑になります。
これらの複数の状態は、エンタープライズアプリケーションのさまざまなレイヤーに対応することがよくあります。プレゼンテーション層、ドメイン層、データソース層を使用する理想的なアプリケーションでは、ドメインロジックはセッション状態でのみ動作します。実際には、この区別は曖昧になることが多く、通常は悪い理由ですが、良い理由もあります。ドメイン層がプレゼンテーションとは別のプロセスにあるアプリケーションでは、アプリケーションを適切に応答させるために、プレゼンテーションプロセスでドメインロジックの一部を実行したい場合があります。そのようなロジックには、メインのドメインプロセスからセッション状態の一部をコピーしたり、プレゼンテーションのコントロール内のデータに対してドメインロジックを実行したりすることが含まれる場合があります。同様に、大量のデータを操作する必要がある場合は、ストアドプロシージャなどを介してドメインロジックをデータベースに埋め込む必要がある場合があります。このようなロジックはレコード状態で動作します。ただし、ほとんどの場合、ドメインロジックはセッション状態で動作するようにします。
レイヤー間の同期
これらの異なるコンテキスト間でデータを同期することは、アプリケーションを構築する上で重要な部分です。ユーザーインターフェイスを操作している場合、画面状態を2つの異なる深さ(セッション状態またはレコード状態)に同期できます。セッション状態に同期する場合は、ユーザーがセッション状態をレコード状態に保存するためのコントロールが必要です。
同期はさまざまな頻度で発生する可能性があります。私は次の3つが便利だと考えています。キー同期は、キーを押すたびに、またはマウスをクリックするたびに同期することを意味します。フィールド同期は、フィールドの編集が完了したときに同期することを意味します。画面同期は、画面の情報が完了したときに、UIの一部の特別なボタン(通常は「適用」、「OK」、「キャンセル」、「送信」とラベル付けされている)を押したときに同期することを意味します。
同期が必要になったら、次に、どの程度同期するかという問題があります。画面データをセッションデータと同期することを検討している場合、私は2つの主要なスキームを考えています。粗粒度同期は、UIで何かを変更するたびに、UI全体が同期されることを意味します。つまり、アーティストフィールドを変更すると、他の何も変更する必要がない場合でも、ウィンドウ全体が同期されます。細粒度同期は、実際に更新する必要のあるフィールドのみを変更することを意味します。したがって、タイトルフィールドを変更すると、タイトルフィールド、ウィンドウタイトル、リストボックスが同期されますが、他のものは同期されません。
セッションデータとレコードデータ間の同期には、通常、異なるアプローチが使用されます。セッションデータは通常、複数のユーザーが同時に使用することはないため、同時実行の問題を心配する必要はありません。セッションデータとレコードデータ間の同期は、通常、画面の同期で発生し、通常は時間がかかります。その結果、データ要素をダーティとしてマークしたり、Unit of Workを使用したりします。
これらのすべての側面は、内部設計とUIの相互作用設計の両方で互いにトレードオフの関係にあります。最も明らかなトレードオフは、同期の頻度と深さの間で発生します。キー同期をレコード状態まで行うと、パフォーマンスが許容できないなどの弊害が生じます。その結果、ほとんどの場合、画面同期がその深さで使用されています。実際、画面同期はセッションの深さでも最も一般的です。通常、最も簡単に行うことができ、多くのアプリケーションがそのように動作するため、ユーザーは慣れています。ただし、インタラクションデザインでフィールド同期が本当に必要な場合も非常に一般的です。ドメインロジックがプレゼンテーションと同じプロセスにある場合、フィールド同期は非常に簡単ですが、別のプロセスにある場合は、パフォーマンスを向上させるのがかなり難しくなります。したがって、ドメイン層では、画面同期が妥当なデフォルトですが、フィールド同期もかなり頻繁に行う必要があります。
キー同期はまれなようですが、ドメインが同じプロセスにある場合はかなり簡単に行うことができます。
タイミングの選択は、深さとアプリケーション設計によって異なりますが、私はほとんどの場合、画面状態とセッション状態間の粗粒度同期を支持します。多くの人が、パフォーマンスへの影響を懸念して、粗粒度同期を避けます。しかし、細粒度同期は、頻繁な重複を伴うコードがたくさんあるため、維持するのが困難です。このすべてにおけるバグは発見して修正するのが困難です。ほとんどの場合、粗粒度同期は十分にパフォーマンスが高いため、まずは常にそれを使用することをお勧めします。パフォーマンスの問題が発生し、それが同期によるものであることをプロファイリングで確認した場合は、その問題を修正するために、少し細粒度同期を導入する必要があります。その時点で、パフォーマンスの問題に対処するために必要な最小限の操作を実行してください。
この同期の必要性は非常に一般的であるため、人々がそれを処理するためのフレームワークを開発するのは必然です。多くの注目を集めているものの1つが、.NETのデータバインディングフレームワークであり、画面状態とセッション状態を自動的に同期します。データバインディングには多くの優れた特性があり、理論的には同期をうまく処理できるはずです。これまでのところ(バージョン1.0まで)、単純なケースではうまく機能しますが、中程度に複雑なケースでは機能しないことがわかりました。データバインディングから始めたプロジェクトは、バインディングの動作を制御する方法が十分にないため、しばらくすると断念することになりました。そのため、ニーズが非常に単純でない限り、慎重に扱うことをお勧めします。ただし、後のバージョンで再評価してください。これは、同期の問題に対する非常に効果的なソリューションになる可能性が十分にあります。
同期と複数の画面
同期の一部は、状態のレイヤー間の同期に関するものであり、別の部分は、同じレイヤーの複数のストランド間の同期に対処することです。単一のレコード状態の上に複数のセッション、各セッションの上に複数の画面があることがよくあります。これらのそれぞれが別のコンテキストであり、1つのコンテキストでの変更が他のコンテキストにどのように伝播されるかを考える必要があります。
ここではプレゼンテーションについて説明しているので、複数のセッションの同期についてはあまり触れません。いずれにせよ、それはよりよく理解されており、比較的簡単なトピックです。ほとんどの場合、セッションは相互に分離されており、レコード状態とのみ同期します。トランザクションまたは何らかの形式のオフライン同時実行制御を使用してそれを行います。
プレゼンテーションは、ユーザーが隔離をあまり期待せず、より迅速な同期を期待するため、より複雑になります。
複数の画面を最適に同期する方法は、画面の構成方法と画面間のフローの構造に大きく依存します。両極端から見てみると、ウィザードと、ファイルシステムエクスプローラのような完全非モーダルインターフェイスを対比して考えることができます。
ウィザードユーザーインターフェースでは、システムは非常に制御された画面のフローを通じてユーザーをガイドします。常に1つの画面のみが表示され、通常、ユーザーは各画面から前後にのみ移動できます。この状況では、画面の設計者は、表示されるデータと、画面が開閉されるタイミングを正確に知っています。
ファイルシステムエクスプローラでは、ユーザーは画面間を自由に移動できます。さらに重要なことに、ユーザーは同じファイルを表示する複数のエクスプローラウィンドウを開くことができます。ユーザーが1つのウィンドウでフォルダの名前を変更した場合、他のウィンドウも更新する必要があります。UIのプログラマーは、ウィンドウがいつ開かれるか、同じデータが複数のウィンドウに表示されるかどうかを実際には知りません。
これら2つの極端な例は、画面間で情報を調整する2つの異なる方法を示唆しています。「フロー同期」では、アプリケーションのフローに基づいて、各画面が自身の画面状態を基盤となるセッション状態と同期するタイミングを決定します。例えば、ウィザードの場合、画面は通常、ある画面から別の画面に移動するときに同期します。古い画面を書き出し、新しい画面のデータを読み込みます。「フロー同期」は、画面間のフローが単純で、画面の状態からセッションの状態へのデータの保存と読み込みを行う明確なポイントがある場合に最適です。
ファイルエクスプローラーの場合、「フロー同期」は困難です。ある画面が、別の画面が基盤となるデータを変更したかどうかを判断することはできません。この場合、画面はお互いを意識せず、基盤となるデータが変更されるたびに同期する必要があります。「オブザーバー同期」では、基盤となる画面状態がデータのマスターソースとして機能します。画面状態が変更されるたびに、表示する画面に通知が行われ、通常はオブザーバーパターンを使用して、画面の状態を更新できます。この形式の「オブザーバー同期」は、モデルビューコントローラースタイルの基本的な部分です。
「オブザーバー同期」の優れた点は、すべての画面が常にお互いに完全に独立していることです。同期するために相互に認識する必要がなく、同期イベントについて相互に通知する必要もありません。これにより、アプリケーション内で非常にアドホックで複雑なフローを持つことが容易になります。「オブザーバー同期」の欠点は、オブザーバーの使用に依存しており、制御不能になると非常に複雑になる可能性がある暗黙的な動作が導入されることです。
しかし、全体的に見ると、「オブザーバー同期」は複雑なUIの支配的な選択肢です。「フロー同期」は、アプリケーションのフローが非常に単純な場合にのみ使用できます。通常は一度に1つのアクティブな画面であり、画面間のフローは単純です。それでも、「オブザーバー同期」に慣れてしまえば、これらの単純なケースでもそれを使用することを好むかもしれません。
Observerの落とし穴
リッチクライアントプレゼンテーションの多くのインタラクションでは、オブザーバーパターンが使用されます。オブザーバーは便利なパターンですが、注意する必要のあるいくつかの重要な問題があります。
オブザーバーの最大の強みであり弱みは、制御が暗黙的にサブジェクトからオブザーバーに渡されることです。オブザーバーが起動することをコードを読んでも判断できません。何が起こっているかを確認する唯一の方法は、デバッガーを使用することです。その結果、複雑なオブザーバーの連鎖は、アクションが他のアクションをトリガーし、理由があまり示されないため、解明、変更、デバッグが困難になる可能性があります。そのため、オブザーバーは非常に単純な方法でのみ使用することを強くお勧めします。
- オブジェクトが他のオブジェクトを監視し、さらに他のオブジェクトを監視するような連鎖は避けてください。オブザーバー関係は1つの層に限定するのが最適です(イベントアグリゲーターを使用する場合を除く)。
- 同じ層のオブジェクト間でのオブザーバー関係は避けてください。ドメインオブジェクトは他のドメインオブジェクトを監視すべきではなく、プレゼンテーションは他のプレゼンテーションを監視すべきではありません。オブザーバーは層の境界を越えて使用するのが最適です。古典的な使用例は、プレゼンテーションがドメインを監視することです。
オブザーバーのもう1つの問題は、メモリ管理にあります。いくつかの画面がいくつかのドメインオブジェクトを監視していると仮定します。画面を閉じると、削除したいのですが、ドメインオブジェクトは実際にはオブザーバー関係を通して画面への参照を保持しています。メモリ管理環境では、長寿命のドメインオブジェクトが多くのゾンビ画面を保持し、重大なメモリリークを引き起こす可能性があります。したがって、削除したい場合は、オブザーバーがサブジェクトから登録解除することが重要です。
ドメインオブジェクトを削除する場合にも、同様の問題がよく発生します。ドメインオブジェクト間のすべてのリンクを解除することに依存している場合、画面がドメインを監視している可能性があるため、これだけでは十分ではない場合があります。実際には、画面が終了し、ドメインオブジェクトの寿命が通常データソース層によって制御されるため、これは問題になることはあまりありません。しかし、一般的には、オブザーバー関係が忘れられたまま残ることが多く、ゾンビの頻繁な原因となることを覚えておく価値があります。イベントアグリゲーターを使用すると、これらの関係を簡略化できることがよくあります。これは解決策ではありませんが、生活を楽にすることができます。
特に、ウィンドウナビゲーションとデータ同期に関する彼の経験の分析で、この章の思考を促進してくれた同僚のXiao Guoに感謝したいと思います。Patrik Nordwallはオブザーバーとメモリリークの問題を指摘しました。
重要な改訂
2006年7月11日: MVPスタイルの分割に対応するための最初の更新
2004年11月20日: フロー同期の議論を追加。
2004年8月4日: Xiao Guoとの会話に触発された、画面、レイヤー、データに関する資料を追加。
2004年7月19日: 最初の公開リリース。主にプレゼンテーションモデルとMVPの比較について。
2004年5月15日: TWへの内部リリース