
ソースコードブランチ管理のパターン
最新のソースコード管理システムは、ソースコードでブランチを簡単に作成できる強力なツールを提供します。しかし、最終的にはこれらのブランチをマージする必要があり、多くのチームは絡み合ったブランチの処理に膨大な時間を費やしています。複数の開発者の作業を効果的に統合し、本番リリースへのパスを整理するために、チームがブランチを効果的に使用できるいくつかのパターンがあります。全体的なテーマは、ブランチを頻繁に統合し、最小限の労力で本番環境にデプロイできる健全なメインラインに注力することです。
2020年5月28日

ソースコードは、あらゆるソフトウェア開発チームにとって重要な資産であり、数十年にわたって、コードを良好な状態に保つためのソースコード管理ツールが開発されてきました。これらのツールを使用すると、変更を追跡できるため、以前のバージョンのソフトウェアを再現し、時間の経過とともにどのように開発されたかを確認できます。これらのツールは、共通のコードベースで作業する複数のプログラマのチームの調整にも不可欠です。各開発者が行った変更を記録することにより、これらのシステムは一度に多くの作業ラインを追跡し、開発者がこれらの作業ラインをマージする方法を理解するのに役立ちます。
この開発を分割してマージする作業ラインへの分割は、ソフトウェア開発チームのワークフローの中心にあり、このすべての活動を管理するのに役立ついくつかのパターンが進化してきました。ほとんどのソフトウェアパターンと同様に、すべてのチームが従うべきゴールドスタンダードはほとんどありません。ソフトウェア開発のワークフローは、コンテキスト、特にチームの社会的構造とチームが従うその他のプラクティスに大きく依存しています。
この記事での私の仕事は、これらのパターンについて説明することですが、私はパターンを説明する記事のコンテキストで行っており、パターン説明の中に、コンテキストとそれらの間の相互関係をよりよく説明する記述セクションを散りばめています。それらを区別しやすくするために、パターンセクションには「✣」の記号を付けています。
基本パターン
これらのパターンについて考える際に、私は2つの主要なカテゴリを開発することが役立つと考えています。1つのグループは統合、つまり複数の開発者がどのようにして自分の作業を首尾一貫した全体に組み合わせるかを見ています。もう1つは本番へのパスを見ており、ブランチを使用して統合されたコードベースから本番環境で実行される製品へのルートを管理しています。いくつかのパターンはこれらの両方を支えており、これらのパターンを基本パターンとして最初に扱います。残りのパターンは、基本的なものではなく、2つの主要なグループのどちらにも当てはまらないため、最後に残します。
ソースブランチ
コピーを作成し、そのコピーへのすべての変更を記録します。
複数の人が同じコードベースで作業すると、同じファイルで作業することがすぐに不可能になります。コンパイルを実行したい場合に、同僚が式を入力している最中だと、コンパイルは失敗します。「コンパイル中だから、何も変更しないで」と互いに叫ぶ必要があります。2人でもこれは維持するのが難しく、チームが大きくなると理解不能になります。
これに対する簡単な解決策は、各開発者がコードベースのコピーを作成することです。これで、自分の機能を簡単に作業できますが、新しい問題が発生します。作業が完了したら、2つのコピーをどのようにマージしますか?
ソースコード管理システムは、このプロセスをはるかに容易にします。重要なのは、各ブランチに加えられたすべての変更をコミットとして記録することです。これにより、`utils.java`に加えた小さな変更を誰も忘れないだけでなく、変更を記録することで、特に複数の人が同じファイルを変更した場合に、マージが容易になります。
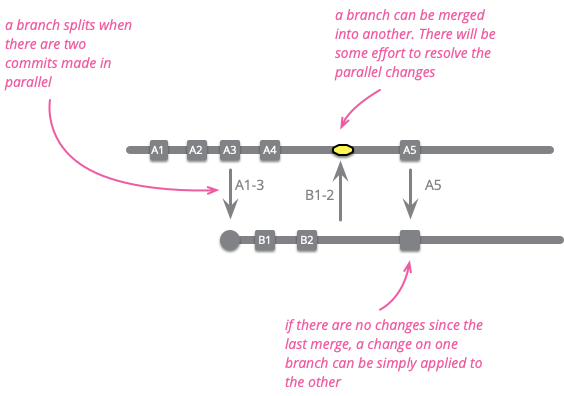
これにより、この記事で使用しているブランチの定義につながります。私は**ブランチ**を、コードベースへのコミットの特定のシーケンスとして定義します。ブランチの**ヘッド**または**先端**は、そのシーケンスの最新のコミットです。

名詞ですが、動詞「ブランチする」もあります。これによって、新しいブランチを作成することを意味しますが、元のブランチを2つに分割することと考えることもできます。ブランチは、1つのブランチからのコミットが別のブランチに適用されるとマージされます。
私が「ブランチ」に使用している定義は、私がほとんどの開発者がそれらについて話しているのを観察した方法に対応しています。しかし、ソースコード管理システムは、「ブランチ」をより具体的な方法で使用することがあります。
これは、共有gitリポジトリにソースコードを保持している最新の開発チームにおける一般的な状況で説明できます。開発者の1人であるスカーレットは、いくつかの変更を加える必要があるため、そのgitリポジトリをクローンしてmasterブランチをチェックアウトします。彼女はいくつかの変更を加え、masterに戻ってコミットします。一方、別の開発者(バイオレットと呼びましょう)は、リポジトリを自分のデスクトップにクローンしてmasterブランチをチェックアウトします。スカーレットとバイオレットは同じブランチで作業していますか、それとも異なるブランチで作業していますか?どちらも「master」で作業していますが、それらのコミットは互いに独立しており、共有リポジトリにそれらの変更をプッシュするときにマージする必要があります。スカーレットが自分の行った変更について確信が持てないことにした場合、彼女は最後のコミットにタグを付け、masterブランチをorigin/master(共有リポジトリからクローンした最後のコミット)にリセットします。
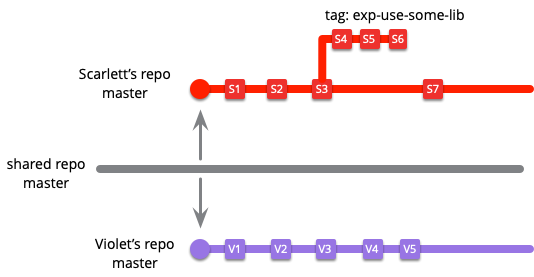
私が前に説明したブランチの定義によると、スカーレットとバイオレットは別々のブランチで作業しており、互いに別々であり、共有リポジトリのmasterブランチからも別々です。スカーレットがタグで作業を脇に置くと、私の定義によると(そして彼女はブランチと考えている可能性があります)それでもブランチですが、gitの言い回しでは、タグ付けされたコードラインです。
gitのような分散型バージョン管理システムでは、リポジトリをさらにクローンするたびに、追加のブランチも得られます。スカーレットが自宅への電車で使用するラップトップにローカルリポジトリをクローンすると、3つ目のmasterブランチが作成されます。GitHubでのフォークでも同じ効果が発生します。フォークされた各リポジトリには、独自の追加のブランチセットがあります。
この用語の混乱は、さまざまなバージョン管理システムを使用すると悪化します。それらすべてには、ブランチを構成するものに関する独自の定義があるためです。Mercurialのブランチはgitのブランチとはかなり異なり、Mercurialのブックマークにより近いです。Mercurialは名前のないヘッドでブランチを作成することもでき、Mercurialのユーザーはリポジトリをクローンしてブランチを作成することがよくあります。
この用語の混乱すべてにより、一部の人は用語の使用を避けるようになります。ここで役立つより一般的な用語はコードラインです。私は**コードライン**を、コードベースの特定のバージョンのシーケンスとして定義します。それはタグで終わったり、ブランチになったり、gitのreflogで失われたりする可能性があります。私のブランチとコードラインの定義の間に強い類似性があることに気付くでしょう。コードラインは多くの点でより有用な用語であり、私も使用していますが、実際にはそれほど広く使用されていません。そのため、この記事では、git(または他のツールの)用語の特定のコンテキストでない限り、ブランチとコードラインを交換可能に使用します。
この定義の結果として、使用しているバージョン管理システムに関係なく、ローカルの変更を行うとすぐに、各開発者には少なくとも1つの個人コードラインが自分のマシンの作業コピーにあります。プロジェクトのgitリポジトリをクローンし、masterをチェックアウトして、いくつかのファイルを更新すると、何もコミットする前でも新しいコードラインになります。同様に、Subversionリポジトリのトランクの独自の作業コピーを作成した場合、Subversionブランチが関与していなくても、その作業コピーは独自のコードラインです。
いつ使用するのか
古いジョークで、高い建物から落ちた場合、落下は痛くないが、着地が痛いと言われています。ソースコードでも同じです。ブランチングは簡単ですが、マージは困難です。
コミットごとにすべての変更を記録するソース管理システムは、マージのプロセスを容易にしますが、自明にするわけではありません。ScarlettとVioletが両方とも変数の名前を変更した場合、異なる名前に変更した場合、ソース管理システムが人間の介入なしに解決できない競合が発生します。さらに厄介なことに、この種の**テキストの競合**は、少なくともソースコード管理システムが検出して人間に確認を求めることができるものです。しかし、多くの場合、テキストは問題なくマージされるにもかかわらず、システムが依然として動作しないという競合が発生します。Scarlettが関数の名前を変更し、Violetがその関数を古い名前で呼び出すコードを彼女のブランチに追加したと想像してみてください。これが私が**セマンティックコンフリクト**と呼ぶものです。このような競合が発生すると、システムのビルドに失敗するか、ビルドされるが実行時に失敗する可能性があります。
この問題は、並行コンピューティングや分散コンピューティングに取り組んだことがある人なら誰でも知っている問題です。開発者が並行して更新を行う共有状態(コードベース)があります。変更を何らかの合意された更新にシリアル化することで、これらを組み合わせる必要があります。私たちのタスクは、システムが正しく実行されるためには、その共有状態に対して非常に複雑な有効性基準が暗示されているという事実によってさらに複雑になります。合意を見つける決定論的なアルゴリズムを作成する方法はありません。人間が合意を見つける必要があり、その合意には、異なる更新の選択部分を混合することが含まれる場合があります。合意は、多くの場合、競合を解決するための元の更新によってのみ達成できます。
私は「分岐がなかったらどうなるか」から始めます。誰もがライブコードを編集し、中途半端な変更がシステムを壊し、人々が互いに踏みつけ合うでしょう。そこで、私たちは個人に凍結された時間の錯覚を与え、彼らがシステムを変更している唯一の人であり、それらの変更はシステムを危険にさらす前に完全に完成するまで待つことができるという錯覚を与えます。しかし、これは錯覚であり、最終的にはその代償を払うことになります。誰が支払うのか?いつ?いくら?これらのパターンは、パイプ奏者への支払いの代替案について議論しています。
-- Kent Beck
したがって、この記事の残りの部分では、快適な隔離と髪をなびかせる風の勢いを維持しながら、避けられない硬い地面との接触の結果を最小限に抑えるさまざまなパターンを説明します。
メインライン
製品の現在の状態として機能する単一の共有ブランチ
**メインライン**は、チームのコードの現在の状態と見なされる特別なコードラインです。新しい作業を開始したいときはいつでも、作業を開始するためにメインラインからコードをローカルリポジトリにプルします。チームの他のメンバーと作業を共有したいときはいつでも、できれば後ほど説明するメインライン統合パターンを使用して、そのメインラインを自分の作業で更新します。
異なるチームはこの特別なブランチに異なる名前を使用しており、多くの場合、使用されているバージョン管理システムの規則によって推奨されています。gitユーザーはしばしば「master」と呼び、Subversionユーザーは通常「trunk」と呼びます。
ここで強調しなければならないのは、メインラインは*単一の共有*コードラインであるということです。人々がgitで「master」について話すとき、すべてのレポジトリのクローンが独自のローカルmasterを持っているため、いくつかの異なる意味を持つ場合があります。通常、このようなチームには**中央リポジトリ**があります。これは、プロジェクトの単一の情報源として機能し、ほとんどのクローンの起点となる共有リポジトリです。ゼロから新しい作業を開始することは、その中央リポジトリをクローンすることを意味します。すでにクローンがある場合は、中央リポジトリからmasterをプルして、メインラインと最新の状態にします。この場合、メインラインは中央リポジトリのmasterブランチです。
機能に取り組んでいる間は、ローカルmasterである可能性のある独自の個人開発ブランチを持っています。または、個別のローカルブランチを作成することもできます。しばらくの間これに取り組んでいる場合は、定期的にメインラインの変更をプルして個人開発ブランチにマージすることで、メインラインの変更を最新の状態に保つことができます。
同様に、製品の新しいバージョンをリリースしたい場合は、現在のメインラインから始めることができます。製品をリリースするのに十分安定させるためにバグを修正する必要がある場合は、リリースブランチを使用できます。
いつ使用するのか
2000年代初頭、クライアントのビルドエンジニアと話に行ったことを覚えています。彼の仕事は、チームが取り組んでいる製品のビルドを組み立てることでした。彼はチームのすべてのメンバーにメールを送信し、彼らは統合の準備ができたコードベースからさまざまなファイルを送信することで返信します。彼はそれらのファイルを統合ツリーにコピーし、コードベースをコンパイルしようとします。通常、コンパイルできるビルドを作成し、何らかのテストの準備をするには、数週間かかります。
これとは対照的に、メインラインを使用すると、誰でもメインラインの先端から製品の最新のビルドを迅速に開始できます。さらに、メインラインはコードベースの状態を簡単に確認できるだけでなく、すぐに説明する他の多くのパターンの基礎にもなります。
メインラインの代替案の1つはリリース電車です。
健全なブランチ
各コミットで、通常はビルドとテストの実行を行い、ブランチに欠陥がないことを確認するための自動化されたチェックを実行します。
メインラインにはこの共有された承認済みの状態があるため、安定した状態に保つことが重要です。2000年代初頭、私は、各製品の毎日のビルドを行うことで有名だった別の組織のチームと話したことを覚えています。これは当時非常に高度な実践と考えられており、この組織はその実践で称賛されました。そのような記事では言及されていなかったのは、これらの毎日のビルドが常に成功したわけではないということです。実際、毎日のビルドが数ヶ月間コンパイルされなかったチームを見つけるのは珍しいことではありませんでした。
これに対抗するために、ブランチを健全に保つよう努めることができます。つまり、正常にビルドされ、ソフトウェアはほとんどバグがないか、まったくバグがない状態で実行されることを意味します。これを確実にするために、私は自己テストコードを書くことが不可欠であることがわかりました。この開発プラクティスは、プロダクションコードを作成するときに、包括的な自動テストスイートも作成することを意味します。これにより、これらのテストに合格した場合、コードにバグが含まれていないことを確信できます。これを行うと、すべてのコミットでビルドを実行することでブランチを健全に保つことができます。このビルドには、このテストスイートの実行が含まれます。システムのコンパイルに失敗した場合、またはテストに失敗した場合、私たちの最優先事項は、そのブランチで他のことを行う前にそれらを修正することです。多くの場合、これはブランチを「凍結する」ことを意味します。健全な状態に戻すための修正を除いて、そのブランチへのコミットは許可されません。
健全性に対する十分な信頼を提供するテストの程度に関して、緊張があります。より徹底的なテストの多くを実行するには多くの時間がかかるため、コミットが健全かどうかについてのフィードバックが遅れます。チームは、デプロイメントパイプラインでテストを複数の段階に分割することによってこれに対処します。これらのテストの最初の段階は迅速に実行する必要があり、通常は10分以内ですが、それでも合理的に包括的である必要があります。私はそのようなスイートを**コミットスイート**と呼びます(コミットスイートは通常主に単体テストであるため、「単体テスト」と呼ばれることがよくあります)。
理想的には、すべてのコミットでテストの全範囲を実行する必要があります。ただし、サーバーを数時間浸す必要があるパフォーマンステストなど、テストが遅い場合は、実際的ではありません。今日では、チームは通常、すべてのコミットで実行できるコミットスイートを構築し、可能な限り頻繁にデプロイメントパイプラインの後の段階を実行できます。
コードがバグなしで実行されるだけでは、コードが良いとは言えません。着実な配信ペースを維持するには、コードの内部品質を高く維持する必要があります。それを行う一般的な方法は統合前レビューを使用することですが、後ほど説明するように、他の代替案もあります。
いつ使用するのか
各チームは、開発ワークフローにおける各ブランチの健全性に関する明確な基準を持っている必要があります。メインラインを健全に保つことには計り知れない価値があります。メインラインが健全であれば、開発者は現在のメインラインをプルするだけで新しい作業を開始でき、作業の邪魔になる欠陥に巻き込まれることはありません。私たちは、新しい作業を始める前に、プルしたコードのバグの修正や回避に何日も費やしている人々をよく耳にします。
健全なメインラインは、プロダクションへのパスも円滑にします。新しいプロダクション候補は、いつでもメインラインの先頭から構築できます。最高のチームは、そのようなコードベースを安定させるためにほとんど作業を行う必要がないことを発見しており、多くの場合、メインラインからプロダクションに直接リリースできます。
健全なメインラインを持つためには、数分で実行されるコミットスイートを備えた自己テストコードが不可欠です。この機能を構築するには大きな投資が必要になる場合がありますが、数分以内に自分のコミットが何も壊していないことを確認できるようになると、私たちの開発プロセス全体が完全に変化します。変更をはるかに迅速かつ自信を持って行い、リファクタリングして作業しやすくし、必要な機能からプロダクションで実行されるコードまでのサイクルタイムを大幅に短縮できます。
個人開発ブランチの場合、それによりDiffデバッグが可能になるため、健全に保つことが賢明です。しかし、その願望は、現在の状態をチェックポイントするための頻繁なコミットを行うこととは相反します。異なるパスを試そうとしている場合、コンパイルに失敗していてもチェックポイントを作成することがあります。私がこの緊張を解決する方法はそのような不健全なコミットを、直近の作業が終わった時点でまとめて処理することです。そうすれば、数時間後には、ブランチには健全なコミットのみが残ります。
自分の個人ブランチを健全に保つと、メインライン統合で発生するエラーが、私のコードベース単体のエラーではなく、統合の問題にのみ起因することがわかるため、メインラインへのコミットがはるかに容易になります。これにより、それらを見つけて修正する速度と容易性が大幅に向上します。
統合パターン
ブランチとは、分離と統合の相互作用を管理することです。誰もが常に単一の共有コードベースで作業することは機能しません。なぜなら、あなたが変数名を入力している途中でプログラムをコンパイルできないからです。したがって、少なくともある程度は、しばらくの間作業できるプライベートワークスペースの概念が必要です。最新のソースコード管理ツールを使用すると、ブランチの作成とそれらのブランチへの変更の監視が容易になります。しかし、ある時点で統合する必要があります。ブランチ戦略について考えることは、実際には、いつどのように統合するかを決定することです。
メインライン統合
開発者は、メインラインからプルし、マージし、健全であればメインラインにプッシュすることで作業を統合します。
メインラインは、チームのソフトウェアの現在の状態を明確に定義します。メインラインを使用することの最大の利点の1つは、統合が簡素化されることです。メインラインがない場合、上記で説明したように、チームの全員と調整するという複雑なタスクになります。しかし、メインラインを使用すると、各開発者は独自に統合できます。
これがどのように機能するかについて、例を説明します。Scarlettと呼ぶ開発者は、メインラインを自分のリポジトリにクローンすることで作業を開始します。gitの場合、中央リポジトリのクローンがまだない場合は、それをクローンしてmasterブランチをチェックアウトします。クローンが既に存在する場合は、メインラインからローカルmasterにプルします。その後、ローカルで作業し、ローカルmasterにコミットできます。

スカーレットが作業している間、同僚のバイオレットがメインラインにいくつかの変更をプッシュします。スカーレットは自身のコードラインで作業しているので、自身のタスクに取り組んでいる間、これらの変更に気付かない可能性があります。

ある時点で、スカーレットは統合したい時点に到達します。最初のステップは、現在のメインラインの状態をローカルのマスターブランチにフェッチすることです。これにより、バイオレットの変更が取り込まれます。ローカルのマスターで作業しているので、コミットはorigin/masterに別のコードラインとして表示されます。
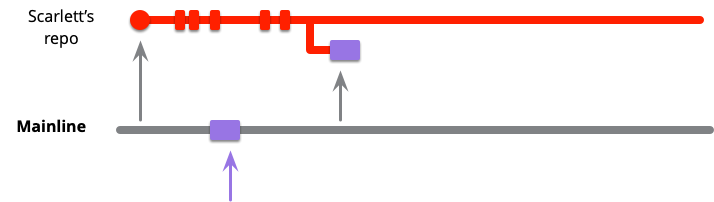
次に、スカーレットは自身の変更とバイオレットの変更を組み合わせる必要があります。いくつかのチームはマージによってこれを行うことを好みますが、他のチームはリベースを使用します。一般的に、人々はブランチをまとめることを話すときは「マージ」という言葉を使用しますが、実際にはgit merge操作やリベース操作を使用しているかどうかは関係ありません。「マージ」と「リベース」の違いについて議論している場合を除き、「マージ」をどちらでも実装できる論理的なタスクとみなします。
標準のマージを使用するかどうか、高速フォワードマージを使用または回避するかどうか、リベースを使用するかどうかについては、別の議論があります。これはこの記事の範囲外ですが、もし十分な量のトリプル・カルメリエを送ってくれる人がいれば、その問題に関する記事を書くかもしれません。結局のところ、quid-pro-quos(見返り)は最近流行っています。
スカーレットが幸運であれば、バイオレットのコードのマージはクリーンなマージになります。そうでない場合は、いくつかの競合を処理する必要があります。これらはテキストの競合である可能性があり、そのほとんどはソース管理システムが自動的に処理できます。しかし、セマンティックな競合ははるかに対処が難しく、ここで自己テストコードが非常に役立ちます。(競合はかなりの量の作業を生み出し、常に多くの作業のリスクを伴うため、黄色い塊で警告します。)
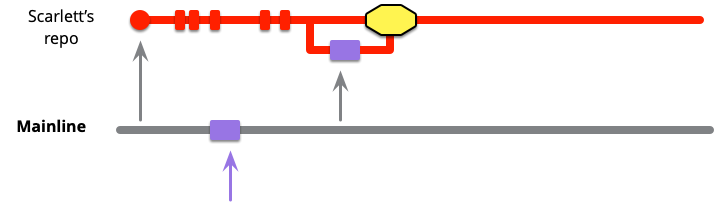
この時点で、スカーレットはマージされたコードがメインラインの健全性基準を満たしていることを確認する必要があります(メインラインが健全なブランチであると仮定します)。これは通常、コードをビルドし、メインラインのコミットスイートを構成するテストを実行することを意味します。クリーンなマージであっても、クリーンなマージでもセマンティックな競合が隠れている可能性があるため、これを行う必要があります。コミットスイートの失敗は、マージにのみ起因する必要があります。なぜなら、両方のマージ親は正常である必要があるからです。これを認識することで、手がかりとなる差分を確認できるため、問題の追跡に役立ちます。
このビルドとテストにより、スカーレットはメインラインを自身のコードラインに正常に取り込みましたが、—そしてこれは重要であり、しばしば見落とされます—まだメインラインとの統合を完了していません。統合を完了するには、変更をメインラインにプッシュする必要があります。これを行わない限り、チームの他の全員がスカーレットの変更から隔離され、本質的に統合されません。統合はプルとプッシュの両方です。スカーレットがプッシュした後にのみ、彼女の作業がプロジェクトの残りの部分と統合されます。
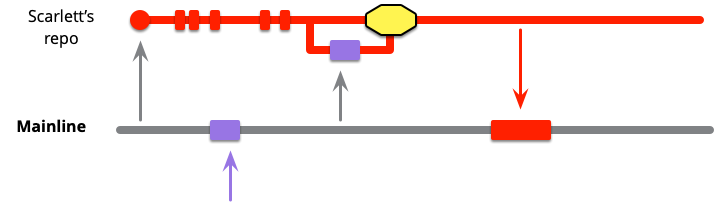
最近の多くのチームは、コミットがメインラインに追加される前にコードレビューステップを要求しています。これは私が統合前レビューと呼ぶパターンであり、後で説明します。
時折、スカーレットがプッシュする前に、他の誰かがメインラインと統合する場合があります。その場合、彼女は再度プルしてマージする必要があります。通常、これは時折の問題に過ぎず、さらなる調整なしで解決できます。ビルド時間が長いチームが統合バトンを使用しているのを見たことがあります。そのため、バトンを持っている開発者だけが統合できます。しかし、ビルド時間が改善された近年では、それほど多くは聞いていません。
いつ使用するのか
名前が示すように、製品でもメインラインを使用している場合にのみ、メインライン統合を使用できます。
メインライン統合を使用するもう1つの代替手段は、メインラインからプルし、これらの変更を個人の開発ブランチにマージすることです。これは役立ちます。プルによって、少なくともスカーレットは他のユーザーが統合した変更を認識し、自分の作業とメインラインの間の競合を検出できます。しかし、スカーレットがプッシュするまで、バイオレットは自分が作業しているものとスカーレットの変更の間の競合を検出できません。
人々が「統合」という言葉を使うとき、彼らはしばしばこの重要な点を欠いています。メインラインを自分のブランチに統合していると言う人がいますが、単にプルしているだけです。私はそれに警戒し、プルだけなのか適切なメインライン統合なのかを確認するためにさらに調査するようにしています。2つの結果は大きく異なるため、用語を混同しないことが重要です。
もう1つの選択肢は、スカーレットがチームの残りの部分との完全な統合の準備ができていない作業の途中にあるが、バイオレットと重複しており、彼女と共有したい場合です。その場合、彼らはコラボレーションブランチを開くことができます。
フィーチャーブランチング
フィーチャーのすべての作業を独自のブランチに配置し、フィーチャーが完了したらメインラインに統合します。
フィーチャーブランチングでは、開発者はフィーチャーの作業を開始するときにブランチを開き、完了するまでそのフィーチャーで作業を続け、次にメインラインと統合します。
たとえば、スカーレットを追跡しましょう。彼女は、ウェブサイトへの地方税の徴収を追加するというフィーチャーに取り組みます。彼女は製品の現在の安定バージョンから開始し、メインラインをローカルリポジトリにプルしてから、現在のメインラインの先端から始まる新しいブランチを作成します。彼女は必要なだけフィーチャーで作業し、そのローカルブランチに一連のコミットを行います。
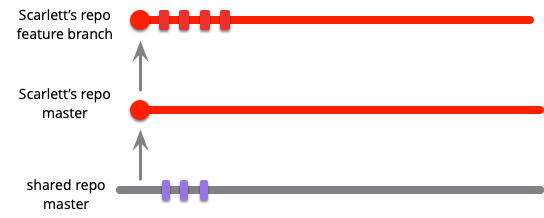
他のユーザーが変更を確認できるように、そのブランチをプロジェクトリポジトリにプッシュする場合があります。
作業中に、他のコミットがメインラインに着陸します。そのため、時折メインラインからプルして、そこに変更がある場合に自分のフィーチャーに影響する可能性があるかどうかを確認することができます。
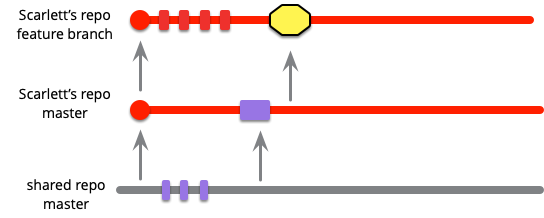
これは上記で説明した統合ではありません。なぜなら、彼女はメインラインにプッシュバックしていないからです。現時点では、彼女だけが自分の作業を見ており、他のユーザーは見ていません。
統合されているかどうかに関係なく、すべてのコードを中央リポジトリに保持することを好むチームもあります。この場合、スカーレットはフィーチャーブランチを中央リポジトリにプッシュします。これにより、他のチームメンバーも彼女の作業内容を確認できます。他の人の作業にまだ統合されていない場合でもです。
フィーチャーの作業が完了したら、メインライン統合を実行して、製品にフィーチャーを取り込みます。
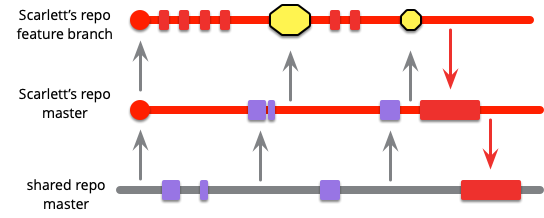
スカーレットが同時に複数のフィーチャーで作業する場合は、それぞれに別のブランチを開きます。
いつ使用するのか
フィーチャーブランチングは、今日の業界で人気のあるパターンです。いつそれを使用するかについて話すには、その主な代替手段である継続的インテグレーションを紹介する必要があります。しかし、まず統合頻度の役割について説明する必要があります。
統合頻度
統合を行う頻度は、チームの運営方法に驚くほど強力な影響を与えます。DevOpsレポートの状態の調査によると、エリート開発チームは低パフォーマンスのチームよりも統合の頻度が著しく高いことが示されています。これは私の経験や多くの業界の同僚の経験とも一致しています。スカーレットとバイオレットを主演させる統合頻度の2つの例を検討することで、これがどのように展開されるかを示します。
低頻度統合
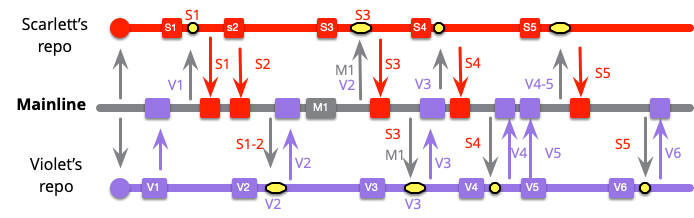
低頻度のケースから始めます。ここでは、2人の主人公がメインラインをブランチに複製することから作業のエピソードを開始し、次にまだプッシュしたくないローカルコミットをいくつか行います。
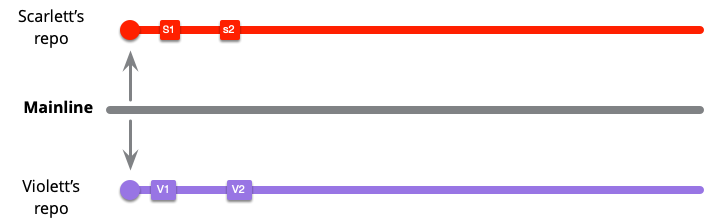
作業中に、他の誰かがメインラインにコミットを追加します。(色の名前で、すぐに思いつく人がいません—グレイハムかな?)
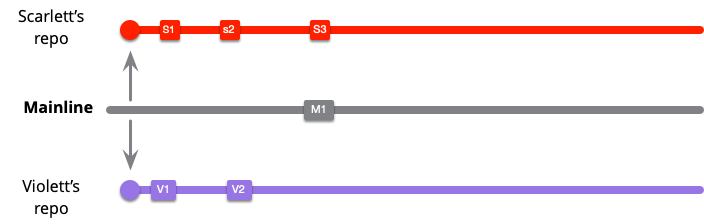
このチームは、健全なブランチを維持し、各コミット後にメインラインからプルすることで作業します。スカーレットは、最初の2つのコミットではメインラインに変更がなかったため、プルするものは何もありませんでしたが、今度はM1をプルする必要があります。
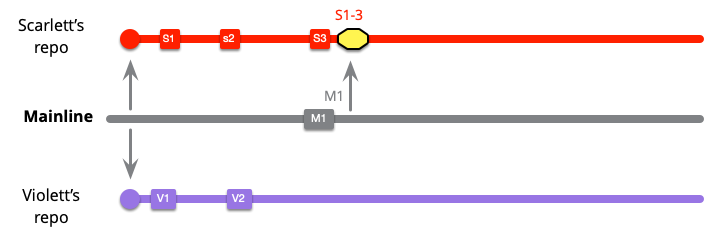
マージには黄色のボックスを付けています。これは、コミットS1..3をM1とマージします。すぐにバイオレットも同じことをする必要があります。
この時点で、両方の開発者はメインラインと最新の状態になっていますが、互いに隔離されているため、統合されていません。スカーレットは、バイオレットが行ったV1..3の変更には気付かないでしょう。
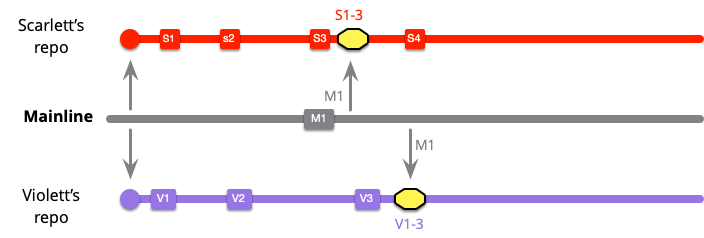
スカーレットはさらにローカルコミットをいくつか行い、メインライン統合の準備が整います。これは、以前にM1をプルしたため、彼女にとって簡単なプッシュです。
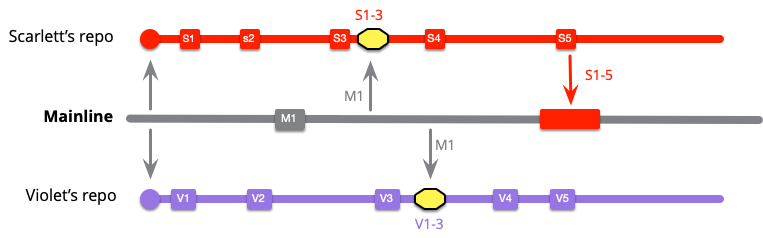
しかし、バイオレットはより複雑な作業を行います。メインライン統合を行うとき、彼女はS1..5とV1..6を統合する必要があります。
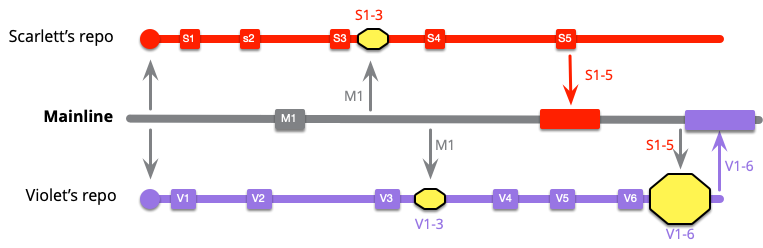
関与するコミットの数に基づいて、マージのサイズを科学的に計算しました。しかし、私の頬の舌状の膨らみを無視しても、バイオレットのマージが最も困難になる可能性が高いことは理解していただけるでしょう。
高頻度統合
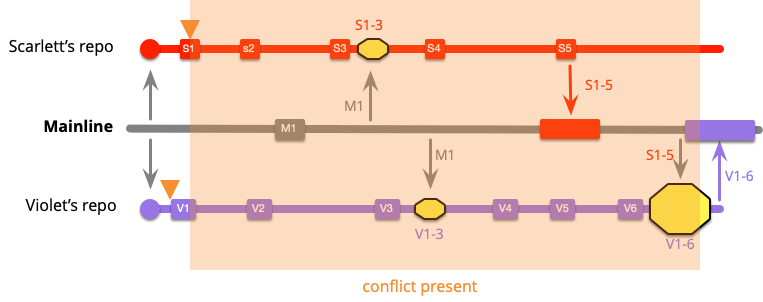
前の例では、2人のカラフルな開発者は、いくつかのローカルコミット後に統合しました。各ローカルコミット後にメインライン統合を行うとどうなるかを見てみましょう。
最初の変更は、バイオレットの最初のコミットで明らかです。なぜなら、彼女はすぐに統合するからです。メインラインに変更がないため、これは単純なプッシュです。

スカーレットの最初のコミットもメインライン統合を行いますが、バイオレットが先に到達したため、マージする必要があります。しかし、V1とS1だけをマージするため、マージは小さくなります。

スカーレットの次の統合は単純なプッシュであり、バイオレットの次のコミットもスカーレットの最新の2つのコミットとマージする必要があります。しかし、それはまだかなり小さなマージです。バイオレットの1つとスカーレットの2つです。
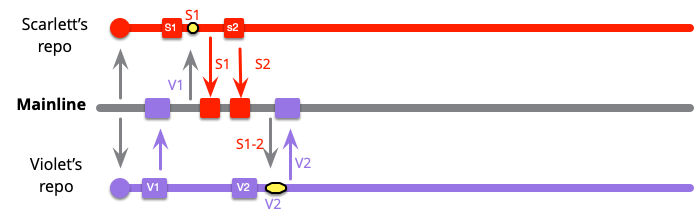
メインラインへの外部プッシュが表示されると、スカーレットとバイオレットの統合の通常のリズムでピックアップされます。
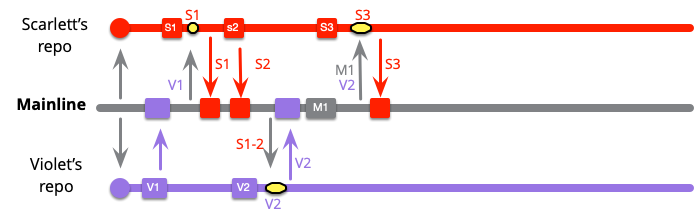
以前と似ていますが、統合は小さくなっています。スカーレットは今回はS3とM1だけを統合する必要があります。なぜなら、S1とS2はすでにメインラインにあるからです。これは、グレイハムはM1をプッシュする前に、すでにメインラインにあるもの(S1..2、V1..2)を統合する必要があったことを意味します。
開発者は残りの作業を続け、各コミットと統合します。
統合頻度の比較
2つの全体像をもう一度見てみましょう
低頻度
高頻度
ここに2つの非常に明白な違いがあります。まず、高頻度統合は、その名前が示すように、はるかに多くの統合(このおもちゃの例だけでも2倍)を持っています。しかし、さらに重要なのは、これらの統合は低頻度の場合よりもはるかに小さいということです。統合が小さくなると、コードの変更が少なくなり、競合が発生する可能性が低いため、作業量が少なくなります。しかし、作業量の削減よりも重要なのは、リスクの軽減です。大きなマージの問題は、作業量ではなく、その作業の不確実性にあります。ほとんどの場合、大きなマージでもスムーズに進みますが、まれに非常に、非常に悪く終わることもあります。そのまれな苦痛は、通常の痛みよりも悪化します。統合ごとに10分余計にかかることと、50回に1回の確率で6時間かけて統合を修正することのどちらが良いでしょうか?努力だけを見ると、6時間より8時間20分の方が良いですが、不確実性のために、50回に1回の場合の方がはるかに悪く感じます。その不確実性が、統合への恐怖につながります。
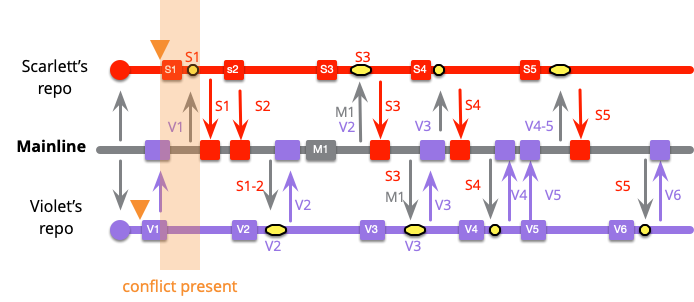
これらの頻度の違いを別の視点から見てみましょう。スカーレットとバイオレットが最初のコミットで競合した場合、どうなるでしょうか?彼らはいつ競合が発生したことに気付くでしょうか?低頻度の場合、バイオレットの最終的なマージまで検出されません。これは、S1とV1が初めてまとめられる時点だからです。しかし、高頻度の場合、スカーレットの最初のマージで検出されます。
低頻度
高頻度
頻繁な統合はマージの頻度を高めますが、その複雑さとリスクを軽減します。また、頻繁な統合は、チームに競合をはるかに迅速に警告します。もちろん、これら2つのことは関連しています。厄介なマージは通常、チームの作業に潜んでいた競合が、統合されたときに初めて表面化した結果です。
バイオレットは請求計算を見て、著者が特定の課税メカニズムを想定していた場所に、評価税が含まれていることに気付いたかもしれません。彼女の機能は税金に異なる処理を必要とするため、直接的な方法は、請求計算から税金を削除し、後で別の関数として実行することでした。請求計算は数カ所だけで呼び出されるため、
自己テストコードはここで私たちの命綱です。強力なテストスイートがあれば、それを健全なブランチの一部として使用することで競合を発見できるため、バグが本番環境に侵入する可能性が大幅に低くなります。しかし、メインラインへのゲートキーパーとして機能する強力なテストスイートがあっても、大規模な統合は作業を困難にします。統合するコードが多ければ多いほど、バグを見つけるのが難しくなります。また、理解が非常に困難な、複数の干渉するバグが発生する可能性も高くなります。コミットが小さくなると、確認するものが少なくなるだけでなく、差分デバッグを使用して、どの変更によって問題が発生したかを絞り込むこともできます。
多くの人が認識していないのは、ソース管理システムはコミュニケーションツールであるということです。これにより、スカーレットはチームの他のメンバーが何をしているかを確認できます。頻繁な統合により、競合が発生したときにすぐに警告されるだけでなく、全員が何をしているか、そしてコードベースがどのように進化しているかをよりよく認識できます。私たちは独立して作業する個人のようではなく、一緒に働くチームのようになります。
統合の頻度を高めることは、機能のサイズを小さくするための重要な理由ですが、他にも利点があります。機能が小さければ小さいほど、構築が速くなり、本番環境への導入が速くなり、価値の提供が速くなります。さらに、より小さな機能はフィードバック時間を短縮し、顧客に関する情報をより多く学習することで、チームがより良い機能の意思決定を行うことができます。
継続的インテグレーション
開発者は、共有できる健全なコミットを作成したらすぐに、通常は1日分の作業量未満で、メインラインへの統合を行います。
チームが高頻度統合がより効率的でストレスが少ないことを経験すると、「どのくらいの頻度でできるか?」という自然な疑問が生じます。機能ブランチは、変更セットのサイズの下限を意味します。まとまりのある機能よりも小さくすることはできません。
継続的インテグレーションは、統合のための異なるトリガーを適用します。機能で一定の進捗があり、ブランチの状態が良好な場合に統合します。機能が完了している必要はなく、コードベースに価値のある変更が加えられていることだけです。経験則としては、"全員が毎日メインラインにコミットする"、より正確には、*ローカルリポジトリに統合されていない作業が1日分以上残るべきではない*ということです。実際には、継続的インテグレーションの実践者のほとんどは、1時間分の作業量以下の作業でも喜んで統合を行うため、1日に何度も統合を行います。
継続的インテグレーションを使用する開発者は、部分的に構築された機能で頻繁な統合ポイントに到達するという考えに慣れる必要があります。稼働中のシステムで部分的に構築された機能を公開せずにこれを行う方法を検討する必要があります。多くの場合、これは簡単です。クーポンコードに依存する割引アルゴリズムを実装していて、そのコードが有効なリストにまだない場合、たとえ本番環境にあっても、コードは呼び出されません。同様に、保険請求者に喫煙者かどうかを尋ねる機能を追加する場合、コードの背後にあるロジックを構築およびテストし、機能の構築の最終日まで質問するUIを残しておくことで、本番環境で使用されないようにすることができます。キーストーンインターフェースを最後に接続することで、部分的に構築された機能を隠すことは、多くの場合効果的な手法です。
部分的な機能を簡単に隠す方法がない場合は、機能フラグを使用できます。部分的に構築された機能を隠すだけでなく、このようなフラグを使用すると、機能をユーザーのサブセットに選択的に公開することもできます。これは、新しい機能を徐々に展開する場合に役立ちます。
部分的に構築された機能の統合は、特にメインラインにバグのあるコードがあることを心配する人を懸念させます。その結果、継続的インテグレーションを使用する人は、自己テストコードも必要です。これにより、部分的に構築された機能をメインラインに含めても、バグが発生する可能性が高まらないという確信を持つことができます。このアプローチでは、開発者は、機能コードを作成するときに部分的に構築された機能のテストを作成し、機能コードとテストの両方を同時にメインラインにコミットします(おそらくテスト駆動開発を使用します)。
ローカルリポジトリに関して言えば、継続的インテグレーションを使用するほとんどの人は、作業を行うために個別のローカルブランチを使用しません。通常は、ローカルマスターにコミットし、完了したらメインライン統合を実行するのは簡単です。ただし、開発者が好む場合は、機能ブランチを開いてそこで作業を行い、頻繁な間隔でローカルマスターとメインラインに統合しても問題ありません。機能ブランチと継続的インテグレーションの違いは、機能ブランチがあるかどうかではなく、開発者がいつメインラインに統合するかです。
いつ使用するのか
継続的インテグレーションは、機能ブランチの代替手段です。これら2つの間のトレードオフは、この記事の別のセクションに値するほど複雑であり、今こそそれを取り組む時です。
フィーチャブランチと継続的インテグレーションの比較
機能ブランチは現在、業界で最も一般的なブランチ戦略ですが、継続的インテグレーションが通常は優れたアプローチであると主張する実践者の声も大きくなっています。継続的インテグレーションが提供する主な利点は、より高い、多くの場合はるかに高い統合頻度をサポートすることです。
統合頻度の違いは、チームが機能をどれほど小さくできるかによって異なります。チームの機能をすべて1日以内に行うことができる場合、機能ブランチと継続的インテグレーションの両方を実行できます。しかし、ほとんどのチームはこれよりも長い機能の長さを持っており、機能の長さが長くなるほど、これら2つのパターン間の違いは大きくなります。
すでに述べたように、統合頻度が高いほど、統合にかかる作業が少なくなり、統合への恐怖が少なくなります。これは、多くの場合、伝えにくいことです。数週間または数か月ごとに統合する世界で生活してきた場合、統合は非常に困難な作業になる可能性があります。それが1日に何度も行えるものだと信じるのは非常に難しい場合があります。しかし、統合は頻度が難易度を下げるものの1つです。「痛いなら…もっと頻繁にやる」という直感に反する考え方です。しかし、統合が小さければ小さいほど、悲しみと絶望の壮大なマージになる可能性は低くなります。機能ブランチでは、これはより小さな機能(数週間ではなく数日、そして数か月は論外)を主張します。
継続的インテグレーションにより、チームは高頻度の統合の利点を享受しながら、機能の長さと統合の頻度を切り離すことができます。チームが1週間または2週間の機能の長さを好む場合、継続的インテグレーションを使用すると、最高レベルの統合頻度のすべての利点を享受しながら、これを行うことができます。マージは小さくなり、処理する作業量が少なくなります。さらに重要なのは、上記で説明したように、マージをより頻繁に行うことで、厄介なマージのリスクが軽減され、これによって生じる不測の事態が解消され、マージ全体の恐怖も軽減されます。コードに競合が発生した場合、高頻度の統合によって、それらが厄介な統合問題につながる前に、迅速に検出されます。これらの利点は非常に強力であるため、わずか数日しかかからない機能を持つチームでも、継続的インテグレーションを行っているチームがあります。
継続的インテグレーション(CI)の明白な欠点は、メインラインへの統合というクライマックスにおける「完了感」が欠如していることです。これは単なる祝祭の喪失ではなく、チームが健全なブランチを維持することに長けていない場合、リスクとなります。機能のすべてのコミットをまとめておくことで、今後のリリースに機能を含めるかどうかを最終的に決定することも可能になります。フィーチャフラグを使用すると、ユーザーの視点からは機能のオンオフを切り替えることができますが、機能のコードは製品に残ります。これに関する懸念はしばしば誇張されています。結局のところ、コードには重さがないからです。しかし、これは、継続的インテグレーションを行いたいチームは、1日に多くの統合が行われてもメインラインが健全な状態を保てるように、強力なテスト体制を構築する必要があることを意味します。一部のチームはこのスキルを想像するのが難しいと感じますが、他のチームはそれが可能で解放的であると感じています。この前提条件は、健全なブランチを強制せず、リリース前にコードを安定させるためのリリースブランチを必要とするチームには、フィーチャブランチの方が適していることを意味します。
フィーチャブランチにおける最大の課題は、マージの規模と不確実性ですが、おそらくリファクタリングを妨げる可能性があるという点でしょう。リファクタリングは、定期的に、そして摩擦の少ない状況で行われた場合に最も効果的です。リファクタリングはコンフリクトを引き起こしますが、これらのコンフリクトが迅速に発見され解決されない場合、マージは困難になります。したがって、リファクタリングは高頻度の統合で最も効果を発揮するため、エクストリームプログラミングの一部として普及したのも当然です。エクストリームプログラミングは、継続的インテグレーションも初期のプラクティスの一つとしています。フィーチャブランチはまた、構築中の機能の一部と見なされない変更を開発者が行うことを妨げ、コードベースを着実に改善するリファクタリングの能力を損ないます。
トランクリポジトリにマージされるまでのブランチまたはフォークのライフタイムが非常に短い(1日未満)、アクティブなブランチの総数が3つ未満であることが、継続的デリバリーの重要な側面であり、すべてより高いパフォーマンスに貢献することを発見しました。毎日コードをトランクリポジトリまたはマスターブランチにマージすることも同様です。
-- DevOpsレポート2016
ソフトウェア開発プラクティスの科学的研究に遭遇すると、その方法論に深刻な問題があるため、通常は納得できません。State Of Dev Ops レポートはその例外です。同レポートは、ソフトウェアデリバリーのパフォーマンスの指標を開発し、それをより広範な組織パフォーマンスの尺度と関連付け、さらに投資収益率や収益性などのビジネス指標と関連付けました。2016年、同レポートは最初に継続的インテグレーションを評価し、それがより高いソフトウェア開発パフォーマンスに貢献することを発見しました。この発見は、それ以降のすべての調査で繰り返されています。
継続的インテグレーションを使用しても、機能を小さく保つことの他の利点は失われません。小さな機能を頻繁にリリースすることで、迅速なフィードバックサイクルが提供され、製品の改善に驚くほどの効果を発揮します。継続的インテグレーションを使用する多くのチームは、薄いプロダクトスライスを構築し、可能な限り頻繁に新しい機能をリリースしようと努めています。
フィーチャーブランチング
- 機能内のすべてのコードは、単一単位として品質評価を受けることができます。
- 機能コードは、機能が完了したときのみ製品に追加されます。
- マージ頻度が低くなります。
継続的インテグレーション
- 機能の長さよりも高い頻度の統合をサポートします。
- コンフリクトを発見するまでの時間が短縮されます。
- マージが小さくなります。
- リファクタリングを促進します。
- 健全なブランチ(および自己テストコード)へのコミットが必要です。
- より高いソフトウェアデリバリーパフォーマンスに貢献することが科学的に証明されています。
フィーチャブランチとオープンソース
多くの人が、フィーチャブランチの人気はGitHubとプルリクエストモデルに起因すると考えており、このモデルはオープンソース開発から生まれました。それを考えると、オープンソース開発と多くの商用ソフトウェア開発の間にある非常に異なるコンテキストを理解することが重要です。オープンソースプロジェクトはさまざまな方法で構成されていますが、一般的な構造は、ほとんどのプログラミングを行うメンテナとして機能する1人または少人数のグループです。メンテナは、より多くのプログラマーである貢献者と協力します。メンテナは通常、貢献者を知らないため、貢献者のコードの品質については分かりません。メンテナはまた、貢献者が実際に作業に費やす時間、ましてや作業効率についてはほとんど確信を持てません。
このコンテキストでは、フィーチャブランチは非常に理にかなっています。誰かが大小に関わらず機能を追加しようとしていて、それがいつ(またはそれが)完了するのか分からない場合、統合する前に完了するまで待つのが理にかなっています。また、コードベースに設定した品質基準を満たしていることを確認するために、コードをレビューすることがより重要になります。
しかし、多くの商用ソフトウェアチームは、非常に異なる作業コンテキストを持っています。フルタイムでソフトウェアにコミットする(通常はフルタイム)人材のフルタイムチームが存在します。プロジェクトのリーダーは、(開始時を除き)これらのメンバーをよく知っており、コードの品質と納入能力について信頼できる期待を持つことができます。彼らは有給の従業員であるため、リーダーはプロジェクトへの投入時間、コーディング標準、グループの習慣などについてもより大きな制御権を持っています。
この非常に異なるコンテキストを考えると、このような商用チームのブランチ戦略は、オープンソースの世界で機能する戦略と同じである必要がないことは明らかです。継続的インテグレーションは、オープンソース作業への時折の貢献者にはほぼ不可能ですが、商用作業には現実的な代替手段です。チームは、オープンソース環境で機能するものが、自動的に異なるコンテキストでも正しいと仮定すべきではありません。
統合前レビュー
メインラインへのすべてのコミットは、コミットが承認される前にピアレビューされます。
コードレビューは、コードの品質向上、モジュール化の向上、可読性の向上、欠陥の除去の方法として長く推奨されてきました。それにもかかわらず、商用組織は、ソフトウェア開発ワークフローに適合させることが困難であることがよくありました。しかし、オープンソースの世界では、プロジェクトへの貢献は承認する前にレビューされるべきであるという考えが広く採用され、このアプローチは近年、特にシリコンバレーで開発組織に広く普及しています。このようなワークフローは、GitHubのプルリクエストメカニズムと特に適合します。
このワークフローは、スカーレットが統合したい作業を完了したときに始まります。メインラインにプッシュする前ですが、正常にビルドされた後、メインライン統合を行う(彼女のチームがそれを実践している場合)と、彼女はレビューのためにコミットを送信します。チームの他のメンバー、例えばバイオレットは、そのコミットをコードレビューします。彼女がコミットに問題がある場合、コメントを行い、スカーレットとバイオレットの両方が満足するまでやり取りが行われます。完了してから初めて、コミットがメインラインに配置されます。
統合前レビューはオープンソースで人気が高まり、コミットされたメンテナと時折の貢献者の組織モデルと非常によく適合しています。それらは、メンテナがすべての貢献を綿密に監視できるようにします。また、フィーチャブランチともよく調和します。完了した機能は、このようなコードレビューを行う明確なポイントを示すためです。貢献者が機能を完了するかどうかが確実でない場合、部分的な作業をレビューする理由は何でしょうか?機能が完了するまで待つ方が良いでしょう。このプラクティスは、より大規模なインターネット企業にも広く普及しており、GoogleとFacebookはどちらも、この作業を円滑に進めるための特別なツールを構築しています。
タイムリーな統合前レビューのための規律を開発することが重要です。開発者が作業を完了し、数日間他の作業に移行した場合、レビューのコメントが返ってきたとき、その作業はもはや彼らの念頭にありません。これは完了した機能ではイライラしますが、レビューが確認されるまでさらに進めるのが困難な可能性がある、部分的に完了した機能ではさらに悪化します。原則として、統合前レビューで継続的インテグレーションを行うことは可能であり、実際には可能です。Googleはこのアプローチに従っています。しかし、これは可能ですが、困難であり、比較的まれです。統合前レビューとフィーチャブランチは、より一般的な組み合わせです。
いつ使用するのか
OSSと非公開ソフトウェア開発チームのニーズを混同することは、現在のソフトウェア開発の儀式における最初の罪のようなものです。
統合前レビューは過去10年間で一般的なプラクティスになっていますが、欠点と代替手段があります。うまく行われたとしても、統合前レビューは常に統合プロセスに遅延をもたらし、統合頻度の低下を促します。ペアプログラミングは、コードレビューを待つよりも速いフィードバックサイクルで、継続的なコードレビュープロセスを提供します。(継続的インテグレーションとリファクタリングと同様に、エクストリームプログラミングの初期のプラクティスの一つです)。
統合前レビューを使用する多くのチームは、十分に迅速にレビューを行っていません。提供できる貴重なフィードバックは、役に立つには遅すぎます。その時点で、多くの修正作業を行うか、機能する可能性はあるがコードベースの品質を損なうものを受け入れるかの難しい選択があります。
コードレビューは、コードがメインラインに到達する前だけに限定されません。多くのテクノロジーリーダーは、コミット後にコードをレビューし、懸念事項が見つかったときに開発者に連絡をとることを役立つと考えています。リファクタリングの文化はここで価値があります。うまく行けば、これは、チームの誰もが定期的にコードベースをレビューし、見つけた問題を修正するコミュニティを構築します。私はこのプラクティスを洗練されたコードレビューと呼んでいます。
プリインテグレーションレビューに関するトレードオフは、主にチームの社会構造に依存します。既に述べたように、オープンソースプロジェクトは、少数の信頼できるメンテナと多くの信頼できないコントリビュータという構造を持つことが一般的です。商用チームは多くの場合、全員がフルタイムですが、同様の構造を持つ場合があります。プロジェクトリーダー(メンテナのような)は、少数の(おそらく単一の)メンテナグループを信頼し、チームの他のメンバーから提供されたコードには警戒します。チームメンバーは複数のプロジェクトに同時に割り当てられることがあり、オープンソースコントリビュータと非常に似ています。このような社会構造が存在する場合、プリインテグレーションレビューとフィーチャーブランチングは非常に理にかなっています。しかし、より高い信頼度のチームは、統合プロセスに摩擦を追加することなく、コードの品質を維持する他のメカニズムを見つけることがよくあります。
したがって、プリインテグレーションレビューは貴重なプラクティスになり得ますが、特に初期のリーダーに過度に依存しないバランスの取れたチームを育成しようとしている場合、健全なコードベースへの必要経路というわけではありません。
統合における摩擦
プルリクエストは、低信頼度の状況に対処するためのオーバーヘッドを追加します。例えば、知らない人が自分のプロジェクトに貢献できるようにするためです。
自分のチームの開発者にプルリクエストを課すことは、家族に自宅に入るために空港のセキュリティチェックポイントを通過させるようなものです。
-- Kief Morris
プリインテグレーションレビューの問題の1つは、統合をより面倒にすることが多いことです。これは**統合摩擦**の一例です。統合に時間がかかったり、努力が必要になったりする活動です。統合摩擦が多ければ多いほど、開発者は統合頻度を下げる傾向があります。メインラインへのすべてのコミットに30分かかって記入する必要があるフォームが必要だと主張する(機能不全の)組織を想像してみてください。そのような体制は、人々が頻繁に統合することを妨げます。フィーチャーブランチングと継続的インテグレーションに対するあなたの態度は何であれ、この種の摩擦を追加するものを調べることは有益です。明確な価値を追加しない限り、そのような摩擦はすべて取り除くべきです。
手動プロセスは、特に別の組織との調整が含まれる場合、ここでの摩擦の一般的な原因です。この種の摩擦は、自動化されたプロセスの使用、開発者教育の改善(必要性をなくすため)、デプロイメントパイプラインまたは本番環境でのQAの後のステップへのステップのプッシュによって軽減されることがよくあります。継続的インテグレーションと継続的デリバリーに関する資料で、この種の摩擦を解消するためのアイデアをさらに見つけることができます。この種の摩擦は、本番環境へのパスにも発生し、同じ困難と処理方法があります。
継続的インテグレーションを検討することに抵抗する人々の1つの理由は、高い統合摩擦のある環境でのみ作業したことがある場合です。統合に1時間かかる場合、1日に数回行うのは明らかにばかげています。統合が些細なことで、数分で済ませることができるチームに参加することは、別の世界のように感じます。フィーチャーブランチングと継続的インテグレーションの長所に関する議論の多くは、人々がこれらの両方の世界を経験しておらず、したがって両方の観点を完全に理解できないため、曖昧になっていると疑っています。
文化的要因は統合摩擦に影響を与えます。特にチームメンバー間の信頼です。私がチームリーダーであり、同僚がまともな仕事をすることを信頼していない場合、コードベースを損傷するコミットを防ぎたいと思うでしょう。これは当然、プリインテグレーションレビューの推進要因の1つです。しかし、同僚の判断を信頼するチームにいる場合、コミット後のレビュー、またはレビューを完全に省略して定期的なリファインメントレビューに頼って問題を解決することに、より快適に感じるでしょう。この環境での私の利点は、プリコミットレビューが導入する摩擦を取り除き、より高い統合頻度を促進することです。多くの場合、チームの信頼は、フィーチャーブランチ対継続的インテグレーションの議論において最も重要な要素です。
必要な場合にプリインテグレーションレビューを維持しながら、より少ない摩擦のパスを促進する興味深いアプローチは、Rouan WilsenachのShip/Show/Askです。これは、変更をShip(メインラインに統合)、Show(メインラインに統合するが、変更を伝え議論するためのプルリクエストを開く)、またはAsk(プリインテグレーションレビューのためにプルリクエストを開く)のいずれかに分類します。
モジュール化の重要性
ソフトウェアアーキテクチャに関心のあるほとんどの人は、動作のよいシステムにはモジュール化が重要であると強調しています。モジュール性が低いシステムに小さな変更を加える必要がある場合、小さな変更でもコードベースの多くの部分に波及する可能性があるため、ほぼすべてを理解する必要があります。しかし、モジュール性が優れている場合、1つか2つのモジュール内のコード、さらにいくつかのインターフェースのみを理解する必要があり、残りの部分は無視できます。必要な理解の労力を削減できるこの能力こそ、システムが成長するにつれてモジュール化に多くの労力を費やす価値がある理由です。
モジュール化は統合にも影響を与えます。システムに優れたモジュールがある場合、ほとんどの場合、ScarlettとVioletはコードベースの完全に分離された部分で作業しており、変更が競合することはありません。優れたモジュール化は、ブランチが提供する分離の必要性を回避するために、キーストーンインターフェースやブランチバイアブストラクションなどのテクニックも強化します。多くの場合、チームは、モジュール性の欠如により他の選択肢が不足しているため、ソースブランチを使用せざるを得ません。
フィーチャーブランチングは貧者のモジュールアーキテクチャです。実行時/デプロイ時に機能を簡単に交換できるシステムを構築する代わりに、手動マージを通じてこのメカニズムを提供するソースコントロールに自身を結合します。
-- Dan Bodart
サポートは双方向に行われます。多くの試みにもかかわらず、プログラミングを開始する前に優れたモジュールアーキテクチャを構築することは非常に困難なままです。モジュール化を実現するには、システムが成長するにつれて常に監視し、よりモジュール化された方向に調整する必要があります。リファクタリングはこれを達成するための鍵であり、リファクタリングには高頻度の統合が必要です。したがって、モジュール化と迅速な統合は、健全なコードベースで互いに支え合っています。
つまり、モジュール化は達成が難しいものの、努力する価値があります。努力には、優れた開発プラクティス、デザインパターンの学習、コードベースの経験からの学習が含まれます。混乱したマージは、それらを忘れるという理解できる願望で閉じ込めるべきではありません。代わりに、なぜマージが混乱しているのかを尋ねてください。これらの答えは、多くの場合、モジュール性をどのように改善できるかという重要な手がかりとなり、コードベースの健全性を向上させ、チームの生産性を向上させます。
統合パターンに関する個人的な意見
筆者としての私の目的は、特定のパスに従うように説得することではなく、あなたがどのパスに従うかを決定する際に考慮すべき要素について知らせることです。それにもかかわらず、ここで、以前に示したパターンで私が好むものについての私の意見を追加します。
全体として、私は継続的インテグレーションを使用するチームで働く方がはるかに好きです。コンテキストが重要であり、継続的インテグレーションが最適な選択肢ではない状況はたくさんあることを認識していますが、私の反応は、そのコンテキストを変更するための作業を行うことです。誰もがコードベースを簡単にリファクタリングし、モジュール性を向上させ、健全性を維持し、変化するビジネスニーズに迅速に対応できるようにしたいので、この好みがあります。
最近は開発者よりもライターですが、それでもThoughtworksで働くことを選択しています。これは、この作業方法を好む人々がたくさんいる会社です。これは、このエクストリームプログラミングスタイルは、ソフトウェアを開発できる最も効果的な方法の1つであると考えており、チームがさらにこのアプローチを開発して専門家の効果を高めることを観察したいからです。
メインラインから本番リリースまでのパス
メインラインはアクティブなブランチであり、新しいコードと修正されたコードが定期的に追加されます。人々が新しい作業を開始する際に安定した基盤から開始できるように、メインラインを健全に保つことが重要です。十分に健全であれば、メインラインから直接コードを本番環境にリリースすることもできます。

メインラインを常にリリース可能な状態に保つというこの哲学は、継続的デリバリーの中心的な教義です。これを行うには、メインラインを健全なブランチとして維持するための決意とスキルが必要です。通常は、必要な集中的なテストをサポートするためにデプロイメントパイプラインを使用します。
このようにして作業するチームは、通常、各リリースバージョンにタグを使用することでリリースを追跡できます。しかし、継続的デリバリーを使用しないチームは、別のアプローチが必要です。
リリースブランチ
リリースの準備ができた製品のバージョンを安定させるために承認されたコミットのみを受け入れるブランチ。
一般的なリリースブランチは現在のメインラインからコピーされますが、新しい機能を追加することは許可されません。メイン開発チームは引き続きメインラインにそのような機能を追加し、これらは将来のリリースで採用されます。リリースに取り組んでいる開発者は、リリースが本番環境で使用できる状態になるのを妨げる欠陥を排除することにのみ重点を置いています。これらの欠陥に対する修正は、リリースブランチで作成され、メインラインにマージされます。対処すべき欠陥がなくなると、ブランチは本番リリースの準備が整います。
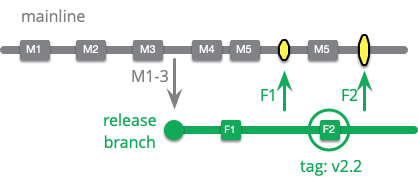
リリースブランチでの修正の作業範囲は(うまくいけば)新しい機能コードよりも小さいですが、時間が経つにつれてメインラインにマージすることがますます困難になります。ブランチは必然的に分岐するため、より多くのコミットがメインラインを変更するにつれて、リリースブランチをメインラインにマージすることが困難になります。
この方法でコミットをリリースブランチに適用することの問題点は、特に分岐によって困難になるにつれて、メインラインにコピーすることを怠りやすいことです。その結果生じる回帰は非常に恥ずかしいものです。そのため、一部の人はメインラインでコミットを作成することを好み、動作するようになったら、それらをリリースブランチにチェリーピックします。
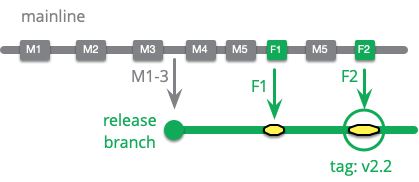
**チェリーピック**とは、コミットが1つのブランチから別のブランチにコピーされますが、ブランチはマージされません。つまり、ブランチポイント以降の前のコミットではなく、1つのコミットのみがコピーされます。この例では、F1をリリースブランチにマージした場合、M4とM5が含まれます。しかし、チェリーピックはF1のみを取得します。チェリーピックはM4とM5で行われた変更に依存する可能性があるため、リリースブランチにはきれいに適用されない可能性があります。
メインラインにリリース修正を書き込むことの欠点は、多くのチームがそれを実行するのが難しく、メインラインで一方的に修正し、リリース前にリリースブランチで修正し直さなければならないことに不満を抱くことです。これは、リリースを迅速に出荷する必要がある場合、特に当てはまります。
一度に本番環境で1つのバージョンしか運用していないチームは、単一のリリースブランチだけで済みますが、一部の製品では、本番環境で使用されているリリースが多数存在します。顧客のキット上で実行されるソフトウェアは、顧客が希望する場合にのみアップグレードされます。多くの顧客は、アップグレードの失敗によって痛い目に遭っているため、魅力的な新機能がない限り、アップグレードを嫌がります。しかし、そのような顧客も、特にセキュリティの問題に関連するバグ修正を必要としています。このような状況では、開発チームは、使用されている各リリースに対してリリースブランチを開いたままにし、必要に応じて修正を適用します。
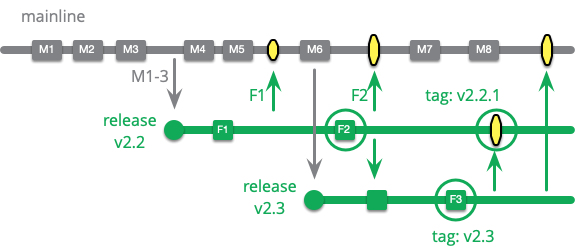
開発が進むにつれて、古いリリースに修正を適用することがますます困難になりますが、それは多くの場合、ビジネスのコストです。これは、顧客に最新のバージョンに頻繁にアップグレードすることを促すことによってのみ軽減できます。製品の安定性を維持することはこれにとって不可欠です。一度痛い目に遭った顧客は、二度と不要なアップグレードを行うことをためらいます。
(リリースブランチの他の名称として、「リリース準備ブランチ」、「安定化ブランチ」、「候補ブランチ」、「強化ブランチ」などを聞いたことがあります。「リリースブランチ」が最も一般的なようです。)
いつ使用するのか
メインラインの状態を良好に維持できない場合、リリースブランチは貴重なツールとなります。これにより、チームの一部は、本番環境の準備に必要なバグ修正に集中できます。テスターは、このブランチの先端から最も安定した最新の候補を取得できます。誰もが製品の安定化のために何がなされたかを確認できます。
リリースブランチの価値にもかかわらず、本番環境で単一の製品しか運用していないほとんどの優秀なチームはこのパターンを使用しません。なぜなら、必要がないからです。メインラインを十分に良好な状態に保つことができれば、メインラインへのコミットを直接リリースできます。その場合、リリースには、公開されているバージョンとビルド番号をタグ付けする必要があります。
前の段落に「single-production(単一製品本番環境)」という不器用な形容詞を入れたことに気づかれたかもしれません。これは、チームが本番環境で複数のバージョンを管理する必要がある場合に、このパターンが不可欠になるためです。
リリースプロセスに大きな摩擦がある場合(たとえば、すべての本番リリースを承認しなければならないリリース委員会など)にも、リリースブランチが役立つ場合があります。Chris Oldwoodが述べているように、「このような場合、リリースブランチは、企業の歯車がゆっくりと回転している間に、一種の検疫ゾーンとして機能します」。一般的に、このような摩擦は、統合の摩擦を取り除く必要があるのと同様に、リリースプロセスからできる限り取り除く必要があります。ただし、モバイルアプリストアなど、それが不可能な状況もあります。これらの多くの場合、ほとんどの場合タグで十分であり、ソースに不可欠な変更が必要な場合にのみブランチを開きます。
リリースブランチは環境ブランチになる場合もあり、そのパターンの使用に関する懸念事項が適用されます。また、長期的なリリースブランチのバリエーションもあり、すぐに説明します。
成熟度ブランチ
そのヘッドがコードベースの成熟度のレベルの最新バージョンを示すブランチ。
チームは、ソースの最新バージョンを知りたいことがよくあります。これは、成熟度のレベルが異なるコードベースでは複雑になる可能性があります。QAエンジニアは製品の最新のステージングバージョンを確認したい場合があり、本番環境の障害をデバッグしている人は最新のバージョンを確認したい場合があります。
成熟度ブランチは、この追跡を行う方法を提供します。コードベースのあるバージョンが特定のレベルの準備状態に達すると、特定のブランチにコピーされるという考え方です。
本番環境用の成熟度ブランチを考えてみましょう。本番リリースの準備ができたら、製品を安定化するためにリリースブランチを開きます。準備ができたら、それを長期間実行される本番ブランチにコピーします。これはマージではなくコピーとして考えています。本番コードは、上流ブランチでテストされたものとまったく同じである必要があるためです。
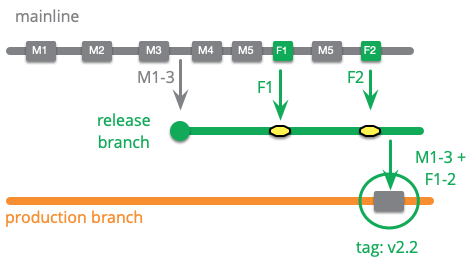
成熟度ブランチの魅力の1つは、リリースワークフローのその段階に達したコードの各バージョンを明確に示すことです。したがって、上記の例では、本番ブランチには、コミットM1〜3とF1〜2を組み合わせた単一のコミットのみが必要です。これを実行するためのSCMのちょっとした細工がありますが、いずれの場合も、メインラインのきめ細かいコミットへのリンクが失われます。これらのコミットは、後で人々がそれらを追跡するのを助けるために、コミットメッセージに記録する必要があります。
成熟度ブランチは、通常、開発フローの適切な段階にちなんで名付けられています。したがって、「本番ブランチ」、「ステージングブランチ」、「QAブランチ」などの用語があります。時々、本番成熟度ブランチを「リリースブランチ」と呼ぶ人もいます。
いつ使用するのか
ソース管理システムは、コードベースの共同作業と履歴の追跡をサポートします。成熟度ブランチを使用すると、リリースワークフローの特定の段階のバージョン履歴を示すことで、いくつかの重要な情報を取得できます。
現在実行中の本番コードなど、最新バージョンは、関連するブランチのヘッドを確認することで見つけることができます。以前に存在しなかったバグが発生した場合、ブランチにある以前のバージョンを確認し、本番環境での特定のコードベースの変更を確認できます。
自動化は、特定のブランチへの変更に関連付けることができます。たとえば、自動化されたプロセスは、本番ブランチにコミットが行われるたびに、バージョンを本番環境にデプロイできます。
成熟度ブランチを使用する代わりに、タグ付けスキームを適用できます。バージョンがQAの準備ができたら、ビルド番号を含む方法でタグ付けされます。したがって、ビルド762がQAの準備ができたら「qa-762」とタグ付けされ、本番の準備ができたら「prod-762」とタグ付けされます。次に、タグ付けスキームに一致するタグをコードリポジトリで検索して、履歴を取得できます。自動化も同様にタグの割り当てに基づいて行うことができます。
したがって、成熟度ブランチはワークフローにいくつかの利便性を追加できますが、多くの組織はタグ付けが完全に機能することを発見しています。そのため、私はこれを、強い利点もコストもないパターンの1つと考えています。ただし、多くの場合、このような追跡にソースコード管理システムを使用する必要があることは、チームのデプロイメントパイプラインのツールの貧弱さの兆候です。
バリエーション:長期的なリリースブランチ
これはリリースブランチパターンのバリエーションとして考えることができます。これは、リリース候補の成熟度ブランチと組み合わされています。リリースを行うには、メインラインをこのリリースブランチにコピーします。リリースごとのブランチと同様に、安定性を向上させるためにのみ、リリースブランチにコミットが行われます。これらの修正もメインラインにマージされます。リリースが行われたときにタグを付け、別のリリースを行う必要があるときにメインラインを再度コピーできます。
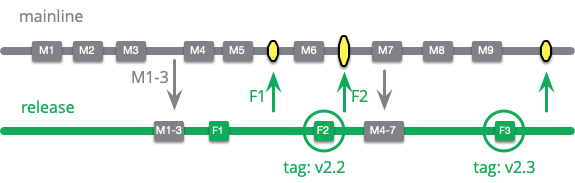
コミットは、成熟度ブランチで一般的であるようにそのままコピーすることも、マージすることもできます。マージする場合は、リリースブランチのヘッドがメインラインのヘッドと正確に一致するように注意する必要があります。これを行う1つの方法は、マージする前にメインラインに適用されたすべての修正を元に戻すことです。各コミットが完全なリリース候補を表すように、マージ後にコミットを圧縮するチームもあります。(これを難しいと感じる人には、リリースごとに新しいブランチを作成することを好む正当な理由があります。)
このアプローチは、一度に本番環境で1つのリリースのみを実行する製品にのみ適しています。
チームがこのアプローチを好む理由の1つは、リリースブランチのヘッドが常に次のリリース候補を指すことを保証することです。最新のリリースブランチのヘッドを探し出す必要はありません。ただし、少なくともgitでは、チームが新しいリリースブランチを作成するときにハードリセットで移動する「release」ブランチ名を持つことで同じ効果を実現し、古いリリースブランチにタグを残します。
環境ブランチ
ソースコードコミットを適用して、新しい環境で製品を実行するように構成します。
ソフトウェアは、通常、開発者のワークステーション、本番サーバー、およびさまざまなテストとステージング環境など、異なる環境で実行する必要があります。通常、これらの異なる環境で実行するには、データベースにアクセスするために使用されるURL、メッセージングシステムの場所、および主要なリソースのURLなど、いくつかの構成変更が必要です。
環境ブランチとは、製品を異なる環境で実行するように再構成するためにソースコードに適用されるコミットを含むブランチです。メインラインでバージョン2.4を実行しており、ステージングサーバーで実行したいとします。これを行うには、バージョン2.4から始まる新しいブランチを作成し、適切な環境変更を適用し、製品を再構築してステージング環境にデプロイします。
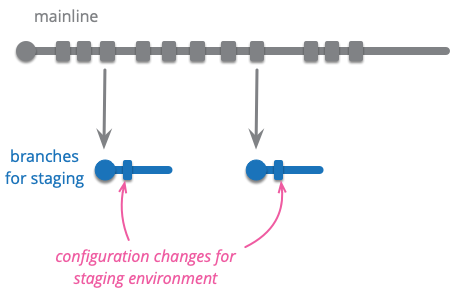
変更は通常手動で適用されますが、担当者がgitに精通している場合は、以前のブランチから変更をチェリーピックすることもできます。
環境ブランチパターンは、多くの場合、成熟度ブランチと組み合わされます。長期間実行されるQA成熟度ブランチには、QA環境の構成調整が含まれている場合があります。このブランチへのマージは、構成変更を取得します。同様に、長期間実行されるリリースブランチには、これらの構成変更が含まれている場合があります。
いつ使用するのか
環境ブランチは魅力的なアプローチです。これにより、新しい環境の準備をするために必要な方法でアプリケーションを調整できます。それらの変更をdiffに保持し、製品の将来のバージョンにチェリーピックできます。しかし、これはアンチパターンの典型的な例です。開始時には魅力的に見えますが、すぐに悲しみ、ドラゴン、そしてコロナウイルスの世界につながります。
環境の変更に伴う差し迫った危険は、アプリケーションの動作が、ある環境から別の環境に移動するときに変化する場合です。本番環境で実行されているバージョンを開発者のワークステーションでデバッグできない場合、問題の修正がはるかに困難になります。特定の環境、特に本番環境でのみ表示されるバグを導入する可能性があります。この危険性のため、可能な限り、他の場所と同じコードが本番環境で実行されるようにする必要があります。
環境ブランチの問題は、それらを非常に魅力的にする柔軟性です。それらのdiffではコードのあらゆる側面を変更できるため、さまざまな動作とそれに伴うバグにつながる構成パッチを簡単に導入できます。
その結果、多くの組織は、実行ファイルがコンパイルされた後、あらゆる環境で同一の実行ファイルが実行されるという鉄則を賢明にも主張しています。構成の変更が必要な場合は、明示的な構成ファイルや環境変数などのメカニズムによって隔離する必要があります。そうすることで、実行中に変化しない定数の設定という単純なものに最小限に抑えることができ、バグの温床となる余地を減らすことができます。
実行ファイルと構成の単純な区別は、ソースコードを直接実行するソフトウェア(例:JavaScript、Python、Ruby)では容易に曖昧になりますが、同じ原則が当てはまります。環境の変化を最小限に抑え、ソースブランチを使用して適用しないでください。経験則として、製品の任意のバージョンをチェックアウトして任意の環境で実行できるようにする必要があります。したがって、展開環境の違いによってのみ変化するものは、ソース管理に含めるべきではありません。デフォルトパラメータの組み合わせをソース管理に保存するという議論もありますが、アプリケーションの各バージョンは、環境変数などの動的要因に基づいて、必要に応じてこれらの異なる構成を切り替えることができる必要があります。
環境ブランチは、ソースブランチを貧者のモジュールアーキテクチャとして使用することの例です。アプリケーションが異なる環境で実行する必要がある場合、異なる環境間を切り替える機能は、その設計の最優先事項である必要があります。環境ブランチは、そのような設計が不足しているアプリケーションのための場当たり的なメカニズムとして役立つ可能性がありますが、持続可能な代替手段で置き換えることを最優先事項とする必要があります。
ホットフィックスブランチ
緊急の製品の欠陥を修正するための作業を記録するブランチ。
本番環境に重大なバグが発生した場合、できるだけ早く修正する必要があります。このバグに対する作業は、チームが行っている他の作業よりも優先順位が高く、他の作業はこのホットフィックスの作業を遅らせるようなことはあってはなりません。
ホットフィックスの作業はソース管理で行う必要があるため、チームはそれを適切に記録し、共同作業を行うことができます。これを行うには、最新のリリースバージョンでブランチを作成し、そのブランチにホットフィックスの変更を適用します。
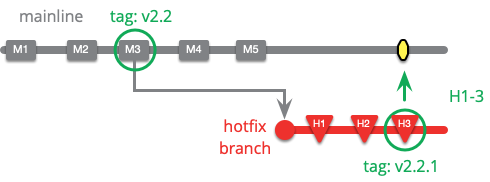
修正が本番環境に適用され、全員が十分な睡眠時間を確保した後、次のバージョンで回帰がないことを確認するために、ホットフィックスをメインラインに適用できます。次のバージョン用にリリースブランチが開いている場合は、ホットフィックスもそこに適用する必要があります。リリース間の時間が長い場合、ホットフィックスは変更されたコードの上に作成される可能性が高いため、マージがより困難になります。この場合、バグを明らかにする優れたテストが非常に役立ちます。
チームがリリースブランチを使用している場合、ホットフィックスの作業はリリースブランチで行うことができ、完了時に新しいリリースを作成できます。基本的に、これは古いリリースブランチをホットフィックスブランチに変えます。
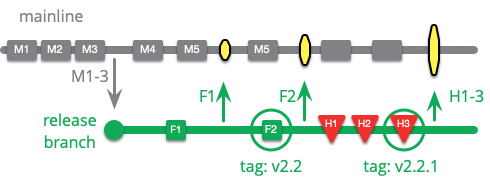
リリースブランチと同様に、メインラインでホットフィックスを作成し、それをリリースブランチにチェリーピックすることもできます。しかし、ホットフィックスは通常、強い時間的制約の下で行われるため、これはあまり一般的ではありません。
チームが継続的デリバリーを使用している場合、メインラインから直接ホットフィックスをリリースできます。ホットフィックスブランチを使用することもありますが、最後のリリースコミットではなく、最新のコミットから開始します。
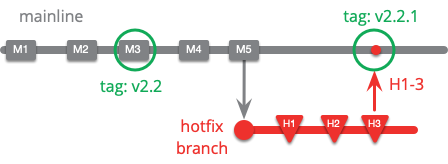
新しいリリースを2.2.1とラベル付けしました。チームがこの方法で作業している場合、M4とM5は新しい機能を公開していない可能性が高いためです。もし新しい機能を公開している場合、ホットフィックスは2.3リリースに統合される可能性が高いです。これはもちろん、継続的デリバリーでは、ホットフィックスは通常のリリースプロセスを回避する必要がないことを示しています。チームのリリースプロセスが十分に迅速であれば、ホットフィックスは通常の処理と同じように処理できます。これは継続的デリバリーの考え方における大きな利点です。
継続的デリバリーチームに適した特別な処理の1つは、ホットフィックスが完了するまでメインラインへのコミットを許可しないことです。これは、「誰もがメインラインを修正することよりも重要なタスクを持っていない」という信念に合致しており、実際には、本番環境にまだ送信されていないものも含め、メインラインで見つかったすべての欠陥に当てはまります。(なので、それほど特別な処理ではないのかもしれません。)
いつ使用するのか
ホットフィックスは通常、相当なプレッシャーがかかっている状況で行われ、チームが最もプレッシャーを感じているときに間違いを犯す可能性が高くなります。そのような状況では、ソースコントロールを使用し、妥当と思われるよりも頻繁にコミットすることは、これまで以上に価値があります。この作業をブランチ上で行うことで、問題に対処するために何が行われているかが全員にわかります。例外は、メインラインに直接適用できる単純な修正だけです。
ここでより興味深い問題は、修正すべき緊急のバグと、通常の開発ワークフローに任せておけるものを決定することです。チームがより頻繁にリリースするほど、本番環境のバグ修正を通常の開発のリズムに任せておくことができます。ほとんどの場合、決定は主にバグのビジネスへの影響と、それがチームのリリース頻度とどのように適合するかによって決まります。
リリース列車
定期的な時間間隔でリリースする。列車が定期的に出発するスケジュールのように。開発者は、機能を完了したときにどの列車に乗るかを選択します。
リリース列車を使用するチームは、2週間ごとまたは6か月ごとなど、定期的なリリースサイクルを設定します。列車のスケジュールという比喩に従って、チームが各リリースのリリースブランチをカットする日が設定されます。担当者は、どの列車に乗せたい機能を決定し、その列車を目標に作業を行い、列車が積み込み中に適切なブランチにコミットします。列車が出発したら、そのブランチはリリースブランチになり、修正のみを受け付けます。
毎月列車を使用するチームは、2月のリリースに基づいて3月のブランチを開始します。そして、月が進むにつれて新しい機能を追加します。特定の日付、おそらく月の第3水曜日に、列車は出発し、そのブランチの機能は凍結されます。彼らは4月の列車のための新しいブランチを開始し、そこに新しい機能を追加します。一方、一部の開発者は3月の列車を安定させ、準備が整ったら本番環境にリリースします。3月の列車に適用された修正は、4月の列車にチェリーピックされます。
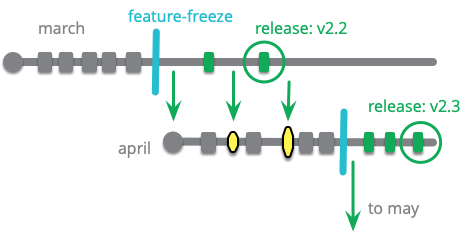
リリース列車は通常、フィーチャブランチと共に使用されます。スカーレットが自分の機能がいつ完了するかを察知したら、どの列車に乗るかを決定します。3月のリリースに間に合うと思うなら3月の列車に統合しますが、そうでなければ次の列車を待ち、そこで統合します。
一部のチームは、列車が出発する数日前(ハードフリーズ)にソフトフリーズを使用します。リリース列車がソフトフリーズ状態になったら、開発者は、自分の機能が安定していてリリースの準備ができていると確信していない限り、その列車に作業をプッシュすべきではありません。ソフトフリーズ後に追加されたバグを示す機能は、列車上で修正するのではなく、元に戻されます(列車から外されます)。
最近、「リリース列車」という言葉は、SAFeのアジャイルリリース列車の概念を指していることがよくあります。SAFeのアジャイルリリース列車はチーム組織構造であり、共通のリリース列車スケジュールを共有する大規模なチームオブチームを指します。リリース列車パターンを使用していますが、ここで説明するものとは異なります。
いつ使用するのか
リリース列車パターンの中心的な概念は、リリースプロセスの規則性です。リリース列車がいつ出発するかを事前に知っていれば、その列車に間に合うように機能を計画できます。3月の列車に間に合わないと思うなら、次の列車に乗車することがわかります。
リリース列車は、リリースプロセスに大きな摩擦がある場合に特に役立ちます。リリースの検証に数週間かかる外部テストグループ、または製品の新しいバージョンを作成する前に合意が必要なリリースボードなどです。このような場合は、リリースの摩擦を取り除き、より頻繁なリリースを可能にする方が賢明なことがよくあります。もちろん、モバイルデバイスのアプリストアで使用される検証プロセスなど、これがほぼ不可能な状況もあります。そのようなリリースの摩擦に合わせるようにリリース列車を調整することで、状況を最適化できる場合があります。
リリース列車のメカニズムは、すべての人の注意をいつどの機能が表示されるべきかに集中させ、機能がいつ完了するかの予測可能性を高めるのに役立ちます。
このアプローチの明確な欠点は、列車期間の初めに完了した機能が、出発を待つ間、列車の中で本を読んでいる状態になることです。これらの機能が重要である場合、製品は数週間または数か月間、重要な機能を欠いた状態になります。
リリース列車は、チームのリリースプロセスの改善において貴重な段階となる可能性があります。チームが安定したリリースを行うのに苦労している場合、継続的デリバリーに一気に移行するのはあまりにも大きな飛躍となる可能性があります。困難ではあるが実現可能な適切なリリース列車期間を選択することは、最初のステップとして良い方法です。チームがスキルを身につけるにつれて、列車の頻度を高め、最終的には能力が向上するにつれて継続的デリバリーのために列車を廃止することができます。
バリエーション:将来の列車の積み込み
フィーチャートレインの基本的な例では、新しい列車がプラットフォームに到着し、前の列車が出発するのと同時に機能を積み込みます。しかし、別の方法として、同時に複数の列車が機能を受け入れる方法があります。スカーレットが自分の機能が3月の列車に間に合わないと思う場合でも、ほとんど完成した機能を4月の列車にプッシュし、出発する前にさらにコミットをプッシュして完成させることができます。
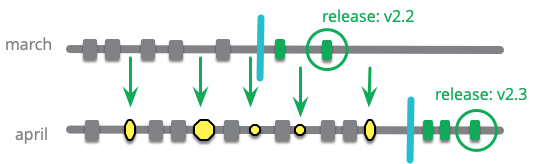
定期的に、3月の列車から4月の列車にプルします。一部のチームは、3月の列車が出発したときのみこれを行うことを好むため、マージは1回だけですが、小さなマージの方がはるかに簡単であることを知っている私たちは、できる限り早くすべての3月のコミットをプルすることを好みます。
将来の列車に積み込むことで、4月の機能に取り組んでいる開発者は、3月の列車の作業を邪魔することなく共同作業を行うことができます。ただし、4月の担当者が3月の作業と競合する変更を加えた場合、3月の担当者はフィードバックを受け取らないため、将来のマージが複雑になるという欠点があります。
メインラインからの通常のリリースと比較
リリース列車の主な利点の1つは、本番環境への定期的なリリースサイクルです。しかし、新しい開発のために複数のブランチを持つことは複雑さを増します。目標が定期的なリリースである場合、メインラインを使用して同じように達成できます。リリーススケジュールを決定し、メインラインの先端にあるものからそのスケジュールでリリースブランチをカットします。
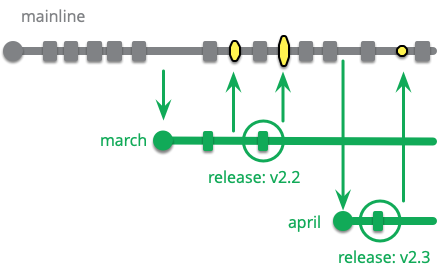
もしリリース可能なメインラインがあれば、リリースブランチは必要ありません。このような定期的なリリースでは、定期リリース直前にメインラインにプッシュしなければ、開発者はほぼ完成した機能を次のリリースまで保留しておくことができます。継続的インテグレーションを用いれば、皆はいつでもキーストーンの配置を遅らせたり、機能フラグをオフにして、機能を次の予定されたリリースまで待つことができます。
リリース可能なメインライン
メインラインを十分に健全な状態に保ち、メインラインの先頭を常に本番環境に直接配置できるようにする
このセクションを始めたとき、メインラインを健全なブランチにし、ヘルスチェックを十分に厳しくすれば、いつでもメインラインから直接リリースし、タグでリリースを記録できる、とコメントしました。
この単純なメカニズムの代替となるパターンについて長々と説明してきましたので、チームがこれを実行できるならば、これは優れた選択肢であることを強調したいと思います。
メインラインへのすべてのコミットがリリース可能だからといって、すべてをリリースする必要があるわけではありません。これは継続的デリバリーと継続的デプロイの微妙な違いです。継続的デプロイを使用するチームは、メインラインに承認された変更をすべてリリースしますが、継続的デリバリーでは、すべての変更がリリース可能である一方で、リリースするかどうかはビジネス上の意思決定です。(したがって、継続的デプロイは継続的デリバリーのサブセットです。)継続的デリバリーはいつでもリリースできる選択肢を与えてくれると考えることができ、その選択肢を実行するかどうかは、より広範な問題によって決まります。
いつ使用するのか
継続的デリバリーの一部として継続的インテグレーションと組み合わせることで、リリース可能なメインラインは高性能チームの共通の特徴です。それを踏まえ、私が継続的デリバリーに強い熱意を持っていることを考えると、リリース可能なメインラインは、このセクションで説明してきた代替策よりも常に優れた選択肢であると言うことを期待するかもしれません。
しかし、パターンはすべてコンテキストに関するものです。あるコンテキストでは優れたパターンが、別のコンテキストでは落とし穴になる可能性があります。リリース可能なメインラインの有効性は、チームの統合頻度によって左右されます。チームがフィーチャブランチを使用し、通常は月に1回しか新しい機能を統合しない場合、チームはまずい状態にある可能性が高く、リリース可能なメインラインへの固執は、改善の障壁となる可能性があります。まずい状態とは、製品ニーズの変化に対応できないということです。なぜなら、アイデアから本番環境までのサイクルタイムが長すぎるからです。また、各機能が大きいため、複雑なマージと検証が必要となり、多くの競合が発生する可能性があります。これらは統合時に発生したり、開発者がメインラインからフィーチャブランチにプルするときの継続的な負担となる可能性があります。この遅れはリファクタリングを妨げ、モジュール性を低下させ、問題を悪化させます。
この落とし穴から脱出するための鍵は、統合頻度を高めることですが、多くの場合、リリース可能なメインラインを維持しながらこれを実現するのは困難です。この場合、リリース可能なメインラインを諦め、より頻繁な統合を促し、リリースブランチを使用して本番環境のためにメインラインを安定させる方が良いことがよくあります。もちろん、時間をかけてデプロイパイプラインを改善することで、リリースブランチの必要性をなくしたいと考えています。
高頻度の統合というコンテキストでは、リリース可能なメインラインはシンプルさという明白な利点があります。説明してきたさまざまなブランチの複雑さをすべて気にする必要はありません。ホットフィックスでさえ、メインラインに適用してから本番環境に適用できるため、もはや特別な名前を付けるほどのものではありません。
さらに、メインラインをリリース可能な状態に保つことは、貴重な規律を促します。本番環境への対応準備を開発者の最優先事項に保ち、バグや製品のサイクルタイムを遅らせるプロセス上の問題など、問題が徐々にシステムに忍び込むのを防ぎます。継続的デリバリーの完全な規律―開発者が毎日何度もメインラインに統合しても壊れないようにする―は、多くの人にとって非常に困難に思えます。しかし、一度達成して習慣になると、チームはそれがストレスを著しく軽減し、維持が比較的容易であることに気付きます。それが、アジャイル・フルエンシー®モデルのデリバリーゾーンの重要な要素である理由です。
その他のブランチパターン
この記事の主な目的は、チームの統合と本番環境へのパスに関するパターンについて議論することです。しかし、他にも言及したいパターンがいくつかあります。
実験ブランチ
製品に直接マージされる予定のないコードベースの実験的な作業を集めます。
実験ブランチは、開発者がいくつかのアイデアを試したいが、変更が単純にメインラインに統合されるとは期待していない場合に使用します。すでに使用しているライブラリの優れた代替として考えられる新しいライブラリを発見したかもしれません。切り替えるかどうかを決定するために、ブランチを作成し、関連するシステムの一部をその新しいライブラリを使用して記述したり、書き直したりしてみます。この演習の目的は、コードベースにコードを貢献することではなく、特定のコンテキストで新しいツールの適用可能性について学ぶことです。これは一人で実行することも、同僚と協力して実行することもできます。
同様に、実装する新しい機能があり、それをアプローチするいくつかの方法を見ることができます。どちらの方法を採用するかを決定するために、各代替案に数日費やします。
ここでの重要な点は、実験ブランチのコードは放棄され、メインラインにマージされないという期待があることです。これは絶対的なものではありません。結果が気に入っていて、コードを簡単に統合できる場合は、その機会を無視することはありませんが、そうなることを期待していません。通常の習慣をいくつか緩めるかもしれません。テストを少なくしたり、きれいにリファクタリングしようとするのではなく、無秩序なコードの複製をいくつか行うかもしれません。実験が気に入ったら、実験ブランチをリマインダーとガイドとして使用しますが、コミットは使用せずに、アイデアを本番コードに適用してゼロから作業すると予想しています。
実験ブランチでの作業が完了したら、通常はgitでタグを追加してブランチを削除します。タグは、後で再検討したい場合にコードラインを保持します。その性質を明確にするために、「exp」で始まるタグ名を使用するなどの規則を使用します。
いつ使用するのか
実験ブランチは、何かを試したいが、最終的に使用するかどうか分からない場合に役立ちます。このようにして、どんなに奇抜なことをしても、簡単に脇に置けるという確信を持つことができます。
通常の作業をしているつもりなのに、実際には実験をしていることに気づく場合があります。そのような場合は、新しい実験ブランチを開き、メインの作業ブランチを最後の安定したコミットにリセットできます。
将来ブランチ
他のアプローチでは処理できないほど侵入性の高い変更に使用される単一のブランチ。
これはまれなパターンですが、人々が継続的インテグレーションを使用しているときに時々発生します。チームは、コードベースに非常に侵入性の高い変更を加える必要があり、進行中の作業を統合するための通常のテクニックがうまく適用されない場合があります。この場合、チームはフィーチャブランチによく似たことを行い、将来ブランチを切り出し、メインラインからのみプルし、最後にメインライン統合を行うまで行いません。
将来ブランチとフィーチャブランチの大きな違いは、将来ブランチが1つしかないことです。その結果、将来ブランチで作業する人はメインラインからあまり離れることがなく、対処する必要がある他の分岐ブランチはありません。
将来ブランチで複数の開発者が作業する場合、将来ブランチで継続的インテグレーションを行います。統合を行う際には、変更を統合する前に、まずメインラインから将来ブランチにプルします。これにより統合プロセスは遅くなりますが、将来ブランチを使用するコストです。
いつ使用するのか
これはまれなパターンであることを強調しておきます。継続的インテグレーションを行うほとんどのチームは、これを使用する必要がないと思います。システムのアーキテクチャに特に侵入性の高い変更を加えるために使用されているのを見ました。一般的に、これは最後の手段であり、代わりに抽象化によるブランチを使用する方法が見つからない場合にのみ使用されます。
将来ブランチも可能な限り短くしておく必要があります。なぜなら、チームにパーティションを作成し、他の分散システムのパーティションと同様に、それを絶対最小限に抑える必要があるからです。
共同作業ブランチ
開発者が正式な統合なしにチームの他のメンバーと作業を共有するために作成されたブランチ。
チームがメインラインを使用する場合、ほとんどの共同作業はメインラインを介して行われます。開発者が何をしているかをチームの他のメンバーが認識するのは、メインライン統合が発生した場合のみです。
開発者は統合前に自分の作業を共有したい場合があります。共同作業用のブランチを開くと、アドホックにこれを行うことができます。ブランチはチームの中央リポジトリにプッシュすることも、共同作業者は個人リポジトリから直接プルおよびプッシュすることも、共同作業を処理するための短期的なリポジトリを設定することもできます。
共同作業ブランチは通常一時的なものであり、作業がメインラインに統合されると閉じられます。
いつ使用するのか
共同作業ブランチは、統合頻度が低下するにつれて、徐々に有用になります。長期間存続するフィーチャブランチは、チームメンバーが複数の人に重要なコード領域の変更を調整する必要がある場合、非公式な共同作業が必要になることがよくあります。しかし、継続的インテグレーションを使用するチームは、互いに作業内容が見えない期間が短いため、共同作業ブランチを開く必要がほとんどありません。この主な例外は、定義上統合されない実験ブランチです。複数の人が実験で協力する場合は、実験ブランチを共同作業ブランチにする必要があります。
チーム統合ブランチ
サブチームがメインラインと統合する前に、互いに統合できるようにする。
大規模なプロジェクトでは、単一の論理コードベースで動作する複数のチームがある場合があります。チーム統合ブランチを使用すると、チームメンバーはメインラインを使用するプロジェクトのすべてのメンバーと統合することなく、互いに統合できます。
効果的に、チームはチーム統合ブランチをチーム内のメインラインとして扱い、全体的なプロジェクトのメインラインと同様に統合します。これらの統合に加えて、チームはプロジェクトのメインラインと統合するための個別の作業を実行します。
いつ使用するのか
チーム統合ブランチを使用する明白な推進力は、非常に多くの開発者によって積極的に開発されているコードベースであり、それらを個別のチームに分割することが理にかなっている場合です。しかし、私は単一のメインラインから作業するには大きすぎるように見える多くのチームに出くわしていますが、それでも同じように管理できているため、その仮定には注意する必要があります。(最大100人の開発者でこれが報告されています。)
チーム統合ブランチにとってより重要な推進要因は、望ましい統合頻度の違いです。プロジェクト全体でチームが数週間の長さのフィーチャーブランチを作成することが期待されているのに、サブチームが継続的インテグレーションを好む場合、チームはチーム統合ブランチを設定し、それを使用して継続的インテグレーションを行い、作業中のフィーチャーを完了したらメインラインに統合できます。
同様の効果は、プロジェクト全体で使用されている健全なブランチの基準と、サブチームの健全性基準との間に違いがある場合にも見られます。より広範なプロジェクトがメインラインを十分な安定度に維持できない場合、サブチームはより厳格なレベルの健全性で運用することを選択する場合があります。同様に、サブチームがコミットを十分に健全なものにして制御されたメインラインにするのに苦労している場合、チーム統合ブランチを使用して、メインラインに移行する前に独自のリリースブランチを使用してコードを安定化することを選択する場合があります。通常はそうした状況を好むわけではありませんが、特に困難な状況では必要になる場合があります。
チーム統合ブランチは、アドホックな共同作業ではなく、正式なプロジェクト組織に基づいた、より構造化された形式の共同作業ブランチと考えることもできます。
いくつかのブランチポリシーを見てみましょう
この記事では、ブランチをパターンの観点から説明しました。これは、ブランチへの唯一のアプローチを推奨するのではなく、人々がこれを行う一般的な方法を示し、ソフトウェア開発で見られるさまざまなコンテキストにおけるトレードオフについて考察するためです。
長年にわたって、多くのブランチアプローチが記述されてきました。それらがどのように機能し、いつ最適に使用されるかを理解しようとした結果、私はそれらを自分の頭の中の半ば形成されたパターンを通して評価しました。これらのパターンを最終的に開発して書き留めた今、これらのポリシーの一部を見て、パターンに関してどのように考えているかを検討することは有益だと思います。
Git-flow
Git-flowは、私が遭遇した最も一般的なブランチポリシーの1つになっています。それは2010年にVincent Driessenによって記述され、gitが人気になり始めた頃に登場しました。git以前は、ブランチは高度なトピックと見なされることがよくありました。Gitは、ファイルの移動のより良い処理などのツールが改善されたこと、そしてリポジトリのクローン作成が本質的にブランチであり、中央リポジトリにプッシュバックする際の同様の考え方のマージの問題が必要になるため、ブランチをより魅力的にしました。
Git-Flowは、単一の"origin"リポジトリでメインライン(「develop」と呼びます)を使用します。複数の開発者を調整するためにフィーチャーブランチを使用します。開発者は、同様の作業を行っている他の開発者と調整するために、個人用リポジトリを共同作業ブランチとして使用することが推奨されています。
gitの従来の名前の付いたコアブランチは「master」ですが、git-flowでは、masterはプロダクション成熟ブランチとして使用されます。Git-Flowはリリースブランチを使用するため、作業は「develop」からリリースブランチを経て「master」に渡されます。ホットフィックスはホットフィックスブランチを介して整理されます。
Git-Flowは、フィーチャーブランチの長さ、したがって期待される統合頻度については何も述べていません。メインラインが健全なブランチであるべきかどうか、そしてそうである場合、どのレベルの健全性が必要であるかについても沈黙しています。リリースブランチの存在は、それがリリース可能なメインラインではないことを意味しています。
Driessenが今年付録で指摘したように、git-flowは、顧客サイトにインストールされたソフトウェアなど、本番環境で複数のバージョンがリリースされる種類のプロジェクト向けに設計されました。複数のライブバージョンを持つことは、もちろん、リリースブランチを使用するための主なトリガーの1つです。しかし、多くのユーザーは、単一のプロダクションウェブアプリというコンテキストでgit-flowを採用しました。その時点で、そのようなブランチ構造は簡単に必要以上に複雑になります。
git-flowは非常に人気がありますが、多くの人が使用していると述べているという意味で、git-flowを使用していると述べている人々が実際にはかなり異なることを行っていることはよくあります。多くの場合、彼らの実際のアプローチはGitHub Flowにより近いです。
GitHub Flow
Git-flowは本当に普及しましたが、ウェブアプリケーションのブランチ構造の不要な複雑さにより、多くの代替案が奨励されました。GitHubの人気が高まるにつれて、その開発者によって使用されるブランチポリシーが広く知られるポリシーになることは驚きではありません。それはGitHub Flowと呼ばれています。最良の説明はScott Chaconによるものです。
GitHub Flowという名前なので、それがgit-flowに基づいており、それに対する反応であったことは驚くべきことではありません。この2つの間の本質的な違いは、異なる種類の製品であるということです。つまり、異なるコンテキスト、したがって異なるパターンを意味します。Git-Flowは、本番環境に複数のバージョンを持つ製品を想定していました。GitHub Flowは、リリース可能なメインラインへの高頻度の統合を持つ単一のバージョンを本番環境で想定しています。そのコンテキストでは、リリースブランチは必要ありません。本番環境の問題は通常のフィーチャーと同じ方法で修正されるため、ホットフィックスブランチは、ホットフィックスブランチが通常、通常のプロセスからの逸脱を意味するという意味では必要ありません。これらのブランチを削除すると、ブランチ構造がメインラインとフィーチャーブランチに大幅に簡素化されます。
GitHub Flowはメインラインを「master」と呼びます。開発者はフィーチャーブランチを使用します。可視性をサポートするために、フィーチャーブランチを定期的に中央リポジトリにプッシュしますが、フィーチャーが完了するまでメインラインとの統合はありません。Chaconは、フィーチャーブランチは1行のコードでも、数週間実行するものでもよいと示唆しています。どちらの場合でも、プロセスは同じように機能するように設計されています。GitHubであるため、プルリクエストメカニズムはメインライン統合の一部であり、統合前レビューを使用します。
Git-flowとGitHub Flowは混同されることが多いため、これらのことについてはいつもどおり、名前よりも深く掘り下げて、何が起こっているかを本当に理解する必要があります。それらの一般的なテーマは、メインラインとフィーチャーブランチを使用することです。
トランクベース開発
前述したように、私は「トランク駆動開発」を継続的インテグレーションの同義語として聞くことが多いです。しかし、トランク駆動開発を、git-flowおよびGitHub Flowに対するブランチポリシーの代替手段と見なすことも合理的です。Paul Hammantは、このアプローチを説明するために詳細なウェブサイトを作成しました。PaulはThoughtworksの私の長年の同僚であり、彼の信頼できる+4のマチェーテを使ってクライアントの骨化したブランチ構造に踏み込むという確かな実績がありました。
トランクベース開発は、すべての作業をメインライン(「トランク」と呼ばれ、「メインライン」の一般的な同義語です)で行い、長寿命のブランチを回避することに重点を置いています。小規模なチームはメインライン統合を使用して直接メインラインにコミットし、大規模なチームは、「短い」とは数日以内を意味する短期的なフィーチャーブランチを使用する場合があります。これは実際には継続的インテグレーションに相当する可能性があります。チームはリリースブランチ(「リリース用ブランチ」と呼ばれます)またはリリース可能なメインライン(「トランクからのリリース」)を使用する場合があります。
最終的な考察と推奨事項
初期のプログラム以来、人々は、既存のプログラムとは少し異なることを行うプログラムが必要な場合、ソースのコピーを作成して必要に応じて調整するのが簡単であることに気づきました。すべてのソースがあれば、必要な変更を行うことができます。しかし、その行動によって、私のコピーが元のソースの新しいフィーチャーやバグ修正を受け入れるのが難しくなります。時間の経過とともに、多くの企業が初期のCOBOLプログラムで発見したように、そして今日では広範囲にカスタマイズされたERPパッケージで苦しんでいるように、不可能になる可能性があります。名前が使用されていなくても、ソースコードをコピーして変更するたびに、バージョン管理システムが関与していなくても、ソースブランチになります。
この長い記事の冒頭で述べたように、ブランチは簡単ですが、マージはより困難です。ブランチは強力なテクニックですが、goto文、グローバル変数、同時実行のためのロックを思い出させます。強力で使いやすく、しかし過剰に使用しやすく、しばしば不注意で経験の浅い人の落とし穴になります。ソースコード管理システムは、変更を注意深く追跡することでブランチを制御するのに役立ちますが、最終的には問題の目撃者としてのみ機能できます。
ブランチが悪だと主張する人ではありません。単一のコードベースに複数の開発者が貢献するなど、ブランチの慎重な使用が不可欠な日常的な問題があります。しかし、常に警戒し、パラケルススの観察、「有益な薬と毒の違いは用量である」ことを覚えておく必要があります。
そのため、ブランチに関する私の最初のヒントは、**ブランチの使用を検討する場合は常に、どのようにマージするかを把握すること**です。テクニックを使用するたびに、代替手段とトレードオフしています。テクニックのすべての費用を理解せずに、賢明なトレードオフの決定を行うことはできません。ブランチの場合、マージ時にパイプ奏者は料金を請求します。
したがって、次のガイドラインは、**ブランチの代替手段を理解すること、通常はそれらが優れていることです**。Bodartの法則を覚えていますか。モジュール性を向上させることで問題を解決する方法はありませんか?デプロイメントパイプラインを改善できますか?タグで十分ですか?このブランチを不要にするプロセスへの変更は何ですか?実際には、ブランチが現在最適なルートである可能性は非常に高いですが、今後数ヶ月で対処する必要があるより深い問題を警告する匂いです。ブランチの必要性をなくすことは通常、良いことです。
LeRoyの図解を覚えていますか。ブランチは統合せずに実行されると指数関数的に分岐します。そのため、ブランチを統合する頻度を検討してください。**統合頻度を2倍にすることを目指しましょう。**(明らかに限界がありますが、継続的インテグレーションの領域にない限り、それに近づくことはありません。)より頻繁に統合するには障壁がありますが、それらの障壁は多くの場合、開発プロセスを改善するために過剰な量のダイナマイトを与える必要があるものです。
マージはブランチの難しい部分であるため、**マージを困難にしているものに注意を払ってください。**場合によっては、プロセス上の問題であり、場合によってはアーキテクチャの欠陥です。それが何であれ、ストックホルム症候群に屈しないでください。特に危機を引き起こすマージの問題は、チームの効率性を向上させるための道標です。間違いは、そこから学ぶ場合にのみ価値があることを覚えておいてください。
ここで説明したパターンは、私と私の同僚の旅の中で遭遇したブランチの一般的な構成の概要を示しています。それらに名前を付け、説明し、そして何よりも、それらがいつ役立つのかを説明することで、それらを使用する時期を評価するのに役立つことを願っています。どのパターンでも、普遍的に良いか悪いということはめったにありません。あなたにとっての価値は、あなたが置かれているコンテキストによって異なります。ブランチポリシー(git-flowやトランクベース開発などのよく知られたもの、または開発組織で独自に作成されたもの)に遭遇したとき、それらの内部のパターンを理解することで、それらがあなたの状況に適しているかどうか、そして他のどのパターンが混合に役立つのかを決定するのに役立つことを願っています。
謝辞
Badri Janakiraman、Brad Appleton、Dave Farley、James Shore、Kent Beck、Kevin Yeung、Marcos Brizeno、Paul Hammant、Pete Hodgson、およびTim Cochranは、この記事のドラフトを読み、改善方法に関するフィードバックを提供してくれました。
Peter Beckerは、フォークもブランチの一種であることを指摘するよう思い出させてくれました。「メインライン」という名前は、Steve BerczukのSoftware Configuration Management Patternsから借用しました。
さらに読む
ブランチに関する文献は膨大であり、網羅的な調査を行う立場にはありません。しかし、Steve Berczukの著書「Software Configuration Management Patterns」を特筆したいと思います。Steveと共同執筆者のBrad Appletonによる著作は、私のソースコード管理に対する考え方に永続的な影響を与えてきました。
重要な改訂
2021年1月4日: プルリクエストに関するサイドバーを追加
2021年1月2日: パターン「Reviewed Commits」をより明確な名称である「Pre-Integration Reviews」に改名
2020年5月28日: 最終稿の公開
2020年5月27日: いくつかのブランチポリシーに関する考察を公開
2020年5月21日: Collaboration BranchとTeam Integration Branchを公開
2020年5月20日: 最終的な考察の草稿作成
2020年5月19日: Future Branchを公開
2020年5月18日: Experimental Branchを公開
2020年5月14日: Release-Ready Mainlineを公開
2020年5月13日: ブランチポリシーに関するセクションの草稿作成
2020年5月13日: Release Trainを公開
2020年5月12日: Hotfix Branchを公開
2020年5月11日: Release-Ready Mainlineの草稿作成
2020年5月11日: Environment Branchを公開
2020年5月7日: Maturity Branchを公開
2020年5月6日: Release Branchを公開
2020年5月5日: Integration Friction、モジュール化の重要性、および統合パターンに関する私見を公開
2020年5月4日: Reviewed Commitsを公開
2020年4月30日: 継続的インテグレーションとフィーチャーブランチの比較を公開。
2020年4月29日: 継続的インテグレーションを公開
2020年4月28日: 下書き:モジュール化に関するセクションを追加
2020年4月28日: Integration Frequencyを公開
2020年4月27日: 下書き:Production BranchをMaturity Branchに一般化
2020年4月27日: Feature Branchを公開
2020年4月23日: Mainline Integrationを公開
2020年4月22日: Healthy Branchを公開
2020年4月21日: Mainlineを公開。
2020年4月20日: 第一稿の公開:Source Branching。
2020年4月5日: 第五稿:リリースパターンに関するレビューコメントを処理、Release Trainの作成、Source Branchingの改訂。
2020年3月30日: 第四稿:基本部分と統合部分に関するレビューコメントの大部分を処理。Source Branchingをパターンとして作成。
2020年3月12日: 第三稿:パターンを特別なセクションとして再構成
2020年3月5日: 第二稿:テキストを統合パターンと本番環境へのパスに再編成。リリースブランチとホットフィックスの図を追加し、それに合わせてテキストを書き換え
2020年2月24日: 第一稿:レビュー担当者と共有
2020年1月28日: 執筆開始