
ドメインロジックとSQL
過去数十年にわたり、データベース指向のソフトウェア開発者とインメモリアプリケーションソフトウェア開発者の間のギャップは拡大してきました。これは、SQLやストアドプロシージャなどのデータベース機能の使用方法について多くの議論を引き起こしています。この記事では、シンプルながらもリッチなSQLクエリの例に基づいて、主にパフォーマンスと保守性を考慮しながら、ビジネスロジックをSQLクエリに配置するかインメモリコードに配置するかの問題を検討します。
2003年2月

Contents(内容)
エンタープライズアプリケーション構築に関する最近の書籍(私の最近の著書であるP of EAAなど)を見ると、エンタープライズアプリケーションのさまざまな部分を分離する複数のレイヤーにロジックが分割されていることがわかります。著者によって使用するレイヤーは異なりますが、共通のテーマは、ドメインロジック(ビジネスルール)とデータソースロジック(データの取得元)の分離です。エンタープライズアプリケーションデータの大部分はリレーショナルデータベースに格納されているため、このレイヤー化スキームは、ビジネスロジックをリレーショナルデータベースから分離することを目的としています。
多くのアプリケーション開発者、特に私のような強いOO開発者は、リレーショナルデータベースを隠しておくのが最善のストレージメカニズムとして扱う傾向があります。SQLの複雑さからアプリケーション開発者を保護することの利点をうたうフレームワークが存在します。
しかし、SQLは単純なデータの更新および取得メカニズム以上のものです。SQLのクエリ処理は多くのタスクを実行できます。SQLを隠すことで、アプリケーション開発者は強力なツールを除外しています。
この記事では、ドメインロジックを含む可能性のあるリッチなSQLクエリを使用することの長所と短所を探りたいと思います。私はOOバイアスを議論に持ち込むことを宣言しなければなりませんが、反対側にも住んでいました。(以前のクライアントのOOエキスパートグループは、私が「データモデラー」だったため、私を会社から追い出しました。)
複雑なクエリ
リレーショナルデータベースはすべて、標準クエリ言語であるSQLをサポートしています。基本的に、SQLはリレーショナルデータベースがこれほどまでに成功した主な理由であると私は信じています。データベースと対話するための標準的な方法は、ベンダーからの独立性を強く保証しており、これはリレーショナルデータベースの台頭を助け、OOの挑戦を乗り越えるのに役立ちました。
SQLには多くの強みがありますが、特に強力なのはデータベースをクエリする非常に強力な機能であり、クライアントは非常に少ない行数のSQLコードで大量のデータをフィルタリングおよび集計できます。しかし、強力なSQLクエリを使用すると、ドメインロジックが埋め込まれることが多く、これは階層化されたエンタープライズアプリケーションアーキテクチャの基本原則に反します。
このトピックをさらに詳しく調べるために、簡単な例で遊んでみましょう。図1のようなデータモデルから始めます。私たちの会社には、Cuillenと呼ぶ特別な割引があると想像してください。顧客は、月に5000ドル以上のタリスカーを含む注文を少なくとも1つ行うと、Cuillen割引の対象となります。同じ月に3000ドルの注文を2つ行ってもカウントされないことに注意してください。5000ドルを超える単一の注文が必要です。特定の顧客を見て、昨年Cuillen割引の対象となった月を判断したいとしましょう。ユーザーインターフェイスは無視して、必要なのは対象となる月に対応する数字のリストであると仮定します。
{kind=link}
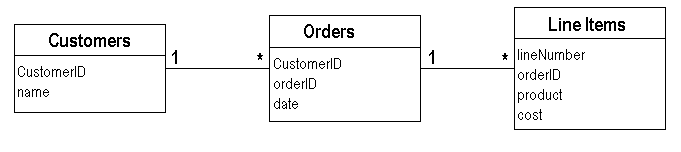
図1:例のデータベーススキーマ(UML表記)
この質問に答える方法はたくさんあります。まず、トランザクションスクリプト、ドメインモデル、複雑なSQLの3つの粗雑な代替案から始めます。
これらのすべての例について、Rubyプログラミング言語を使用して説明します。ここでは少し大胆に出ています。通常、私はJavaやC#を使用してこれらのことを説明します。ほとんどのアプリケーション開発者はCベースの言語を読むことができるからです。私はある程度実験としてRubyを選んでいます。この言語は、コンパクトでありながら適切に構造化されたコードを奨励し、OOスタイルで簡単に記述できるため、気に入っています。スクリプトを作成するための私の好みの言語です。ここで使用しているRubyに基づいて、簡単なRuby構文ガイドを追加しました。
トランザクションスクリプト
トランザクションスクリプトは、P of EAAでリクエストを処理する手続き型スタイルに私が付けたパターン名です。この場合、プロシージャは必要なすべてのデータを読み取り、メモリ内で選択と操作を行って、必要な月を特定します。
def cuillen_months name
customerID = find_customerID_named(name)
result = []
find_orders(customerID).each do |row|
result << row['date'].month if cuillen?(row['orderID'])
end
return result.uniq
end
def cuillen? orderID
talisker_total = 0.dollars
find_line_items_for_orderID(orderID).each do |row|
talisker_total += row['cost'].dollars if 'Talisker' == row['product']
end
return (talisker_total > 5000.dollars)
end
cuillen_monthsメソッドとcuillen?メソッドの2つのメソッドには、ドメインロジックが含まれています。これらは、データベースにクエリを発行する多くの「ファインダー」メソッドを使用します。
def find_customerID_named name
sql = 'SELECT * from customers where name = ?'
return $dbh.select_one(sql, name)['customerID']
end
def find_orders customerID
result = []
sql = 'SELECT * FROM orders WHERE customerID = ?'
$dbh.execute(sql, customerID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
def find_line_items_for_orderID orderID
result = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh.execute(sql, orderID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
多くの点で、これは非常に単純なアプローチであり、特にSQLの使用において非常に非効率的です。データをプルバックするために複数のクエリが必要になります(2 + N、ここでNは注文の数)。現時点ではあまり心配しないでください。後で改善方法について説明します。代わりに、アプローチの本質に集中してください。考慮する必要があるすべてのデータを読み取り、ループして必要なものを選択します。
(余談ですが、上記のドメインロジックは読みやすくするためにそのように行われています。しかし、それは私が慣用的なRubyだと感じているものではありません。Rubyの強力なブロックとコレクションメソッドをもっと活用する以下のメソッドの方が好きです。このコードは多くの人には奇妙に見えるでしょうが、Smalltalkerはそれを楽しむはずです。)
def cuillen_months2 name
customerID = find_customerID_named(name)
qualifying_orders = find_orders(customerID).select {|row| cuillen?(row['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
end
ドメインモデル
2番目の開始点として、古典的なオブジェクト指向ドメインモデルを検討します。この場合、インメモリオブジェクトを作成します。この場合、データベーステーブルをミラーリングします(実際のシステムでは、通常は正確なミラーではありません)。一連のファインダーオブジェクトがデータベースからこれらのオブジェクトをロードします。オブジェクトがメモリに読み込まれたら、それらに対してロジックを実行します。
ファインダーから始めます。これらはデータベースに対してクエリを発行し、オブジェクトを作成します。
class CustomerMapper
def find name
result = nil
sql = 'SELECT * FROM customers WHERE name = ?'
return load($dbh.select_one(sql, name))
end
def load row
result = Customer.new(row['customerID'], row['NAME'])
result.orders = OrderMapper.new.find_for_customer result
return result
end
end
class OrderMapper
def find_for_customer aCustomer
result = []
sql = "SELECT * FROM orders WHERE customerID = ?"
$dbh.select_all(sql, aCustomer.db_id) {|row| result << load(row)}
load_line_items result
return result
end
def load row
result = Order.new(row['orderID'], row['date'])
return result
end
def load_line_items orders
#Cannot load with load(row) as connection gets busy
orders.each do
|anOrder| anOrder.line_items = LineItemMapper.new.find_for_order anOrder
end
end
end
class LineItemMapper
def find_for_order order
result = []
sql = "select * from lineItems where orderID = ?"
$dbh.select_all(sql, order.db_id) {|row| result << load(row)}
return result
end
def load row
return LineItem.new(row['lineNumber'], row['product'], row['cost'].to_i.dollars)
end
end
これらのloadメソッドは、次のクラスをロードします
class Customer...
attr_accessor :name, :db_id, :orders
def initialize db_id, name
@db_id, @name = db_id, name
end
class Order...
attr_accessor :date, :db_id, :line_items
def initialize (id, date)
@db_id, @date, @line_items = id, date, []
end
class LineItem...
attr_reader :line_number, :product, :cost
def initialize line_number, product, cost
@line_number, @product, @cost = line_number, product, cost
end
cuillen月を決定するロジックは、いくつかのメソッドで記述できます。
class Customer...
def cuillenMonths
result = []
orders.each do |o|
result << o.date.month if o.cuillen?
end
return result.uniq
end
class Order...
def cuillen?
discountableAmount = 0.dollars
line_items.each do |line|
discountableAmount += line.cost if 'Talisker' == line.product
end
return discountableAmount > 5000.dollars
end
このソリューションは、トランザクションスクリプトバージョンよりも長くなっています。ただし、オブジェクトをロードするロジックと実際のドメインロジックがより分離されていることを指摘する価値があります。このドメインオブジェクトセットに対する他の処理はすべて、同じロードロジックを使用します。したがって、多くの異なるドメインロジックを実行している場合、ロードロジックの労力はすべてのドメインロジックにわたって償却されるため、問題が少なくなります。そのコストは、メタデータマッピングなどの手法によってさらに削減できます。
ここでも、多くのSQLクエリがあります(2 +注文数)。
SQLでのロジック
最初の2つの両方で、データベースは多かれ少なかれストレージメカニズムとして使用されます。私たちが行ったのは、特定のテーブルから非常に単純なフィルタリングを使用してすべてのレコードを要求することだけです。SQLは非常に強力なクエリ言語であり、これらの例で使用されている単純なフィルタリング以上のことができます。
SQLを最大限に活用することで、すべての作業をSQLで行うことができます
def discount_months customerID
sql = <<-END_SQL
SELECT DISTINCT MONTH(o.date) AS month
FROM lineItems l
INNER JOIN orders o ON l.orderID = o.orderID
INNER JOIN customers c ON o.customerID = c.customerID
WHERE (c.name = ?) AND (l.product = 'Talisker')
GROUP BY o.orderID, o.date, c.NAME
HAVING (SUM(l.cost) > 5000)
END_SQL
result = []
$dbh.select_all(sql, customerID) {|row| result << row['month']}
return result
end
これを複雑なクエリと呼んでいますが、以前の例の単純なselect句とwhere句のクエリと比較してのみ複雑です。SQLクエリはこれよりもはるかに複雑になる可能性がありますが、多くのアプリケーション開発者は、これほど最小限に複雑なクエリでさえ敬遠するでしょう。
パフォーマンスの考察
この種のことについて人々が最初に考慮する質問の1つは、パフォーマンスです。個人的には、パフォーマンスを最初の質問にするべきではないと思います。私の哲学は、ほとんどの場合、保守可能なコードを書くことに焦点を当てるべきだということです。次に、プロファイラーを使用してホットスポットを特定し、それらのホットスポットのみを高速だが明確でないコードに置き換えます。私がこれを行う主な理由は、ほとんどのシステムではコードのごく一部だけが実際にパフォーマンスクリティカルであり、適切にファクタリングされた保守可能なコードのパフォーマンスを向上させる方がはるかに簡単だからです。
しかし、いずれにせよ、最初にパフォーマンスのトレードオフを検討してみましょう。私の小さなラップトップでは、複雑なSQLクエリは他の2つのアプローチよりも20倍高速に実行されます。洗練されたが古いラップトップからデータセンターサーバーのパフォーマンスについて結論を出すことはできませんが、複雑なクエリの速度がインメモリアプローチよりも1桁遅くなることはないでしょう。
その理由の1つは、インメモリアプローチがSQLクエリの点で非常に非効率的な方法で記述されていることです。説明で指摘したように、それぞれが顧客が持っている注文ごとにSQLクエリを発行します。そして、私のテストデータベースには顧客ごとに1000件の注文があります。
インメモリプログラムを書き直して単一のSQLクエリを使用することで、この負荷を大幅に削減できます。トランザクションスクリプトから始めます。
SQL = <<-END_SQL
SELECT * from orders o
INNER JOIN lineItems li ON li.orderID = o.orderID
INNER JOIN customers c ON c.customerID = o.customerID
WHERE c.name = ?
END_SQL
def cuillen_months customer_name
orders = {}
$dbh.select_all(SQL, customer_name) do |row|
process_row(row, orders)
end
result = []
orders.each_value do |o|
result << o.date.month if o.talisker_cost > 5000.dollars
end
return result.uniq
end
def process_row row, orders
orderID = row['orderID']
orders[orderID] = Order.new(row['date']) unless orders[orderID]
if 'Talisker' == row['product']
orders[orderID].talisker_cost += row['cost'].dollars
end
end
class Order
attr_accessor :date, :talisker_cost
def initialize date
@date, @talisker_cost = date, 0.dollars
end
end
これはトランザクションスクリプトのかなり大きな変更ですが、速度は3倍になります。
ドメインモデルでも同様の手法を使用できます。ここでは、ドメインモデルのより複雑な構造の利点が見られます。ロードメソッドを変更するだけで済みます。ドメインオブジェクト自体のビジネスロジックを変更する必要はありません。
class CustomerMapper
SQL = <<-END_SQL
SELECT c.customerID,
c.NAME as NAME,
o.orderID,
o.date as date,
li.lineNumber as lineNumber,
li.product as product,
li.cost as cost
FROM customers c
INNER JOIN orders o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE c.name = ?
END_SQL
def find name
result = nil
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, name) do |sth|
sth.each do |row|
result = load(row) if result == nil
unless result.order(row['orderID'])
result.add_order(om.load(row))
end
result.order(row['orderID']).add_line_item(lm.load(row))
end
end
return result
end
(ドメインオブジェクトを変更する必要がないと言うとき、私は少し嘘をついています。まともなパフォーマンスを得るためには、注文が配列ではなくハッシュに保持されるように顧客のデータ構造を変更する必要がありました。しかし、繰り返しますが、それは非常に自己完結型の変更であり、割引を決定するためのコードには影響しませんでした。)
ここにはいくつかのポイントがあります。まず、インメモリコードは、よりインテリジェントなクエリによってブーストされることが多いことを覚えておく価値があります。データベースを複数回呼び出しているかどうか、そして代わりに1回の呼び出しで実行する方法があるかどうかを確認することは常に価値があります。これは、人々が通常一度にクラスアクセスを考えるため、ドメインモデルがある場合に見落とされがちです。(一度に1行ずつロードする場合もありますが、その病理学的行動は比較的まれです。)
トランザクションスクリプトとドメインモデルの最大の違いの1つは、クエリ構造の変更の影響です。トランザクションスクリプトの場合、それは多かれ少なかれスクリプト全体を変更することを意味します。さらに、類似のデータを使用する多くのドメインロジックスクリプトがある場合、それぞれを変更する必要があります。ドメインモデルを使用すると、コードの適切に分離されたセクションを変更し、ドメインロジック自体を変更する必要はありません。これは、多くのドメインロジックがある場合に大きな問題です。これは、トランザクションスクリプトとドメインロジックの間の一般的なトレードオフです。ドメインロジックのデータベースアクセスの複雑さには初期コストがかかります。これは、多くのドメインロジックがある場合にのみ報われます。
しかし、マルチテーブルクエリを使用しても、インメモリアプローチは複雑なSQLほど高速ではありません。私の場合は6倍です。これは理にかなっています。複雑なSQLはデータベースでコストの選択と合計を行い、クライアントに少数の値を返すだけで済みますが、インメモリアプローチでは5000行のデータをクライアントに返す必要があります。
パフォーマンスはどのルートを選択するかを決める際の唯一の要素ではありませんが、しばしば決定的な要素となります。絶対に改善する必要があるホットスポットがある場合、他の要素は二の次になります。そのため、ドメインモデルの多くの支持者は、デフォルトとしてインメモリで処理を行い、複雑なクエリのようなものはホットスポットに対してのみ、必要な場合にのみ使用するというシステムに従います。
また、この例はデータベースの強みを生かしたものであることを指摘しておく価値があります。多くのクエリは、この例のような強力な選択と集約の要素を持たず、パフォーマンスの変化はそれほど顕著ではありません。さらに、マルチユーザーシナリオでは、クエリの動作に予期しない変化が生じることが多いため、実際のプロファイリングは現実的なマルチユーザー負荷の下で行う必要があります。個々のクエリの高速化によって得られるものよりも、ロックの問題の方が重大になる可能性があります。
変更容易性
長期間運用されるエンタープライズアプリケーションでは、一つ確かなことがあります。それは、大きく変化するということです。そのため、システムが変更しやすいように編成されていることを確認する必要があります。変更の容易さは、おそらく人々がビジネスロジックをメモリに配置する主な理由でしょう。
SQLは多くのことができますが、その機能には限界があります。データセットの中央値を求めるアルゴリズムを調べればわかるように、SQLでできることの中には、非常に巧妙なコーディングが必要なものもあります。また、移植性を求める場合、非標準の拡張機能に頼らずに実現することは不可能なものもあります。
特に保留中の情報を処理する場合、データをデータベースに書き込む前にビジネスロジックを実行したいことがよくあります。保留中のセッションデータを完全に承認されたデータから分離したいことが多いため、データベースへのロードは問題となる可能性があります。このセッションデータは、多くの場合、完全に承認されたデータと同じ検証ルールに従うべきではありません。
理解容易性
SQLはしばしば特別な言語と見なされ、アプリケーション開発者が扱う必要のないものとされています。実際、多くのデータベースフレームワークは、それらを使用することでSQLを扱う必要がなくなると主張しています。私はいつも適度に複雑なSQLにかなり慣れているので、これはやや奇妙な議論だと感じてきました。しかし、多くの開発者は、SQLを従来の言語よりも扱いにくいと感じており、多くのSQLイディオムはSQLの専門家でなければ理解するのが難しいです。
良いテストは、3つのソリューションを見て、どれがドメインロジックを理解しやすく、したがって変更しやすいかを確認することです。私は、わずか数個のメソッドで構成されるドメインモデルバージョンが最も理解しやすいと思います。これは、データアクセスが分離されていることが大きな理由です。次に、インメモリトランザクションスクリプトよりもSQLバージョンを好みます。しかし、他の読者は別の好みを持っていると確信しています。
チームの大部分がSQLに慣れていない場合、それはドメインロジックをSQLから遠ざける理由となります。(少なくとも中級レベルまで、より多くの人々にSQLのトレーニングを検討する理由にもなります。)これは、チームの構成を考慮しなければならない状況の1つです。人々はアーキテクチャの決定に影響を与えます。
重複の回避
私が遭遇した最もシンプルでありながら強力な設計原則の1つは、重複を避けることです。これは、プラグマティックプログラマーによってDRY(Don't Repeat Yourself)原則として定式化されています。(プラグマティックプログラマー)
この場合のDRY原則について考えるために、このアプリケーションの別の要件を考えてみましょう。特定の月の顧客の注文リストで、注文ID、日付、総費用、およびこの注文がCuillenプランの対象となる注文かどうかを表示します。これらはすべて総費用でソートされます。
このクエリを処理するためにドメインオブジェクトアプローチを使用するには、総費用を計算するメソッドを注文に追加する必要があります。
class Order...
def total_cost
result = 0.dollars
line_items.each {|line| result += line.cost}
return result
end
それができれば、注文リストを簡単に印刷できます。
class Customer
def order_list month
result = ''
selected_orders = orders.select {|o| month == o.date.month}
selected_orders.sort! {|o1, o2| o2.total_cost <=> o1.total_cost}
selected_orders.each do |o|
result << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
end
return result
end
単一のSQLステートメントを使用して同じクエリを定義するには、相関サブクエリが必要です。これは一部の人々にとって困難です。
def order_list customerName, month
sql = <<-END_SQL
SELECT o.orderID, o.date, sum(li.cost) as totalCost,
CASE WHEN
(SELECT SUM(li.cost)
FROM lineitems li
WHERE li.product = 'Talisker'
AND o.orderID = li.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE (c.name = ?)
AND (MONTH(o.date) = ?)
GROUP by o.orderID, o.date
ORDER BY totalCost desc
END_SQL
result = ""
$dbh.select_all(sql, customerName, month) do |row|
result << sprintf("%10d %20s %10s %3s\n",
row['orderID'],
row['date'],
row['totalCost'],
row['isCuillen'])
end
return result
end
どちらの方が理解しやすいかについては、人によって意見が異なります。しかし、ここで私が考えている問題は、重複の問題です。このクエリは、月だけを提供する元のクエリのロジックを複製しています。ドメインオブジェクトアプローチにはこの重複がありません。cuillenプランの定義を変更したい場合は、`cuillen?` の定義を変更するだけで、すべての使用箇所が更新されます。
さて、重複の問題でSQLを批判するのはフェアではありません。なぜなら、リッチSQLアプローチでも重複を避けることができるからです。データベース愛好家が指摘したくてたまらないであろうコツは、ビューを使用することです。
簡潔にするためにOrders2と呼ばれるビューを、次のクエリに基づいて定義できます。
SELECT TOP 100 PERCENT
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
CASE WHEN
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker'
AND o.orderID = li2.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.orders o
INNER JOIN dbo.lineItems li ON o.orderID = li.orderID
INNER JOIN dbo.CUSTOMERS c ON o.customerID = c.customerID
GROUP BY o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
これで、このビューを使用して、月を取得し、注文リストを作成できます。
def cuillen_months_view customerID
sql = "SELECT DISTINCT month(date) FROM orders2 WHERE name = ? AND isCuillen = 'Y'"
result = []
$dbh.select_all(sql, customerID) {|row| result << row[0]}
return result
end
def order_list_from_view customerName, month
result = ''
sql = "SELECT * FROM Orders2 WHERE name = ? AND month(date) = ?"
$dbh.select_all(SQL, customerName, month) do |row|
result << sprintf("%10d %10s %10s\n",
row['orderID'],
row['date'],
row['isCuillen'])
end
return result
end
ビューは両方のクエリを簡素化し、主要なビジネスロジックを1か所にまとめます。
重複を避けるためにこのようにビューを使用することについて、人々が議論することはめったにないように思われます。私が見たSQLに関する書籍では、この種のことを議論しているようには見えません。一部の環境では、データベース開発者とアプリケーション開発者の組織的および文化的な分裂のために、これは困難です。多くの場合、アプリケーション開発者はビューを定義することを許可されておらず、データベース開発者は、アプリケーション開発者がこのようなビューを作成することを思いとどまらせるボトルネックとなっています。DBAは、単一のアプリケーションによってのみ必要とされるビューの構築を拒否することさえあります。しかし、私の意見では、SQLは他の何と同じくらい設計に注意を払うに値します。
カプセル化
カプセル化は、オブジェクト指向設計のよく知られた原則であり、一般的なソフトウェア設計にもよく当てはまると思います。基本的に、プログラムは、データ構造をプロシージャ呼び出しのインターフェースの背後に隠すモジュールに分割する必要があるとされています。この目的は、システム全体に大きな波及効果を引き起こすことなく、基盤となるデータ構造を変更できるようにすることです。
この場合、問題はデータベースをどのようにカプセル化できるかということです。優れたカプセル化スキームにより、アプリケーション全体で面倒な編集を行うことなく、データベーススキーマを変更できます。
エンタープライズアプリケーションの場合、一般的なカプセル化の形式はレイヤリングです。ここでは、ドメインロジックをデータソースロジックから分離するように努めます。そうすれば、データベース設計を変更しても、ビジネスロジックで動作するコードは影響を受けません。
ドメインモデルバージョンは、この種の カプセル化の良い例です。ビジネスロジックはインメモリオブジェクトでのみ機能します。データがそこにどのように到達するかは完全に分離されています。トランザクションスクリプトロジックは、findメソッドを通じてある程度のデータベースカプセル化を行いますが、データベース構造は返される結果セットを通じてより明らかにされます。
アプリケーションの世界では、プロシージャとオブジェクトのAPIを通じてカプセル化を実現します。SQLに相当するものはビューを使用することです。テーブルを変更する場合、古いテーブルをサポートするビューを作成できます。ここでの最大の問題は更新であり、ビューでは正しく実行できないことがよくあります。これが、多くのショップがすべてのDMLをストアドプロシージャでラップする理由です。
カプセル化は、ビューの変更をサポートするだけではありません。データへのアクセスとビジネスロジックの定義の違いについてもです。SQLでは、2つが簡単にぼやける可能性がありますが、それでも何らかの形式の分離を行うことができます。
例として、クエリの重複を避けるために上記で定義したビューを考えてみましょう。そのビューは、データソースとビジネスロジックの分離の線に沿って分割できる単一のビューです。データソースビューは次のようになります。
SELECT o.orderID, o.date, c.customerID, c.name,
SUM(li.cost) AS total_cost,
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker' AND o.orderID =li2.orderID
) AS taliskerCost
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN dbo.lineItems li ON li.orderID = o.orderID
GROUP BY o.orderID, o.date, c.customerID, c.name
次に、このビューを、ドメインロジックに焦点を当てた他のビューで使用できます。Cuillenの適格性を示すものがここにあります。
SELECT orderID, date, customerID, name, total_cost,
CASE WHEN taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
FROM dbo.OrdersTal
この種の考え方は、ドメインモデルにデータをロードする場合にも適用できます。以前、ドメインモデルのパフォーマンスの問題は、cuillen月のクエリ全体を取得し、それを単一のSQLクエリに置き換えることで対処できることについて説明しました。別の方法は、上記のデータソースビューを使用することです。これにより、ドメインロジックをドメインモデルに保持しながら、より高いパフォーマンスを維持できます。明細項目は、遅延ロードを使用して必要な場合にのみロードされますが、適切な概要情報はビューを介して取得できます。
ビュー、または実際にはストアドプロシージャを使用すると、ある程度までしかカプセル化できません。多くのエンタープライズアプリケーションでは、データは複数のソース、つまり複数のリレーショナルデータベースだけでなく、レガシーシステム、他のアプリケーション、およびファイルからもたらされます。実際、XMLの成長により、ネットワーク経由で共有されるフラットファイルからのデータが増える可能性があります。この場合、完全なカプセル化は、実際にはアプリケーションコード内のレイヤーによってのみ実行できます。これは、ドメインロジックもメモリに配置する必要があることをさらに意味します。
データベースの移植性
多くの開発者が複雑なSQLを敬遠する理由の1つは、データベースの移植性の問題です。結局のところ、SQLの約束は、多数のデータベースプラットフォームで同じ標準SQLを使用できるため、データベースベンダーを簡単に変更できることです。
実際には、それは常に少しばかりのごまかしでした。実際には、SQLはほとんど標準ですが、あらゆる種類の小さな落とし穴があります。ただし、注意すれば、データベースサーバー間で移動するのがそれほど苦痛ではないSQLを作成できます。しかし、これを行うと、多くの機能が失われます。
データベースの移植性に関する決定は、最終的にはプロジェクト固有のものとなります。最近は、以前ほど問題ではなくなっています。データベース市場は揺らいでいるため、ほとんどの場所は3つの主要な陣営のいずれかに分類されます。企業はしばしば、自分が所属する陣営に強いコミットメントを持っています。この種の投資のためにデータベースを変更する可能性が非常に低いと考えると、データベースが提供する特別な機能を活用し始めるのも良いでしょう。
複数のデータベースにインストールしてインターフェースできる製品を提供する人々など、一部の人々は依然として移植性を必要としています。この場合、安全に使用できるSQLの部分に非常に注意する必要があるため、ロジックをSQLに配置することに対するより強力な議論があります。
テスト容易性
テスト容易性は、設計に関する議論で十分に取り上げられてこなかったトピックです。テスト駆動開発(TDD)の利点の1つは、テスト容易性が設計の重要な部分であるという概念を再燃させたことです。
SQLの一般的な慣行はテストしないことのようです。実際、重要なビューやストアドプロシージャが構成管理ツールに保持されていないことさえ珍しくありません。それでも、テスト可能なSQLを持つことは確かに可能です。一般的なxunitファミリには、データベース環境内でテストに使用できる多くのツールがあります。テストデータベースなどの進化型データベース技術を使用して、TDDプログラマーが享受しているものと非常によく似たテスト可能な環境を提供できます。
違いを生む可能性のある主な領域はパフォーマンスです。直接SQLは本番環境では高速であることが多いですが、実際のデータベース接続をサービスタブに置き換えることができるようにデータベースインターフェースが設計されている場合、メモリ内のビジネスロジックでテストを実行する方がはるかに高速になる可能性があります。
まとめ
これまで問題点について話してきました。 अब निष्कर्ष निकालने का समय आ गया है। 根本的にあなたがしなければならないことは、ここで私が話してきた様々な問題を考慮し、あなたのバイアスによってそれらを判断し、リッチクエリを使用してドメインロジックをそこに配置するという方針を決定することです。
私が状況を俯瞰すると、最も重要な要素の1つは、データが単一の論理的なリレーショナルデータベースから取得されるか、それとも多くの異なる、多くの場合非SQLソースに分散しているかということです。 分散している場合は、データソースをカプセル化し、ドメインロジックをメモリ内に保持するために、メモリ内にデータソース層を構築する必要があります。 この場合、SQLの言語としての強みは問題になりません。なぜなら、すべてのデータがSQLにあるわけではないからです。
データの大部分が単一の論理データベースに存在する場合、状況は面白くなります。 この場合、考慮すべき主要な問題は2つあります。 1つは、プログラミング言語の選択です。SQLとアプリケーション言語です。 もう1つは、コードが実行される場所です。データベースのSQLか、メモリ内かです。
SQLはいくつかのことを簡単にしますが、他のことをより困難にします。 SQLを簡単に扱える人もいれば、ひどく不可解だと思う人もいます。 チームの個人的な快適さはここで大きな問題です。 SQLに多くのロジックを配置するルートを選択する場合は、移植性を期待しないでください。ベンダーのすべての拡張機能を使用し、喜んでそのテクノロジーに自分を縛り付けてください。 移植性が必要な場合は、ロジックをSQLから除外してください。
これまで、変更可能性の問題について話してきました。 これらの懸念が最初に来るべきだと思いますが、重大なパフォーマンスの問題によって覆い隠されるべきです。 メモリ内アプローチを使用していて、より強力なクエリによって解決できるホットスポットがある場合は、そうしてください。 上記で概略したように、パフォーマンスを向上させるクエリをデータソースクエリとしてどれだけ整理できるかを確認することをお勧めします。 そうすることで、ドメインロジックをSQLに配置することを最小限に抑えることができます。
重要な改訂
2003年2月