
DevOps 文化におけるコンプライアンス
CI/CD プロセスへのコンプライアンス制御と監査の統合
DevOps 文化において、コンプライアンス要件を満たすために必要なセキュリティ制御と監査機能を統合することで、CI/CD パイプラインの自動化を活用できますが、組織の規模拡大に伴い独自の課題も生じます。効果的で安全かつスケーラブルなソリューションを構築するには、選択した実装によって引き起こされる二次的な影響と意図しない結果を理解することが重要です。
2021年11月2日

カール・ナイガードは、Thoughtworksのテクニカルプリンシパルです。カールは20年以上にわたり、GIS/リモートセンシング、サプライチェーン、リアルタイム制御、オンライン教育、小売、政府など、さまざまな分野のスタートアップ企業と大企業のプロジェクトをリードしてきました。彼は、組織がテクノロジー戦略を策定し、デジタル変革目標を実現するための最適なテクノロジー投資を決定する支援を行っています。
多くの業界では、さまざまな規制へのコンプライアンスを義務付ける規制基準が存在します。例としては、財務システムの制御を定義するサーベンス・オクスリー法、情報セキュリティマネジメントシステム(ISMS)を定義するISO-27001、または政府機関における運用許可(ATO)などがあります。これらの環境内でソフトウェアを構築および展開するチームは、ソフトウェアを本番環境で使用できる前に、関連する基準と要件を遵守する必要があります。
DevOps の目標の1つは、「左シフト」によってクロスファンクショナルな要件をより効果的かつ効率的に満たすことであり、本質的にはセキュリティと品質に関する懸念事項を通常の開発フィードバックサイクルの一部にすることです。しかし、コンプライアンス制御と監査活動は、規制基準を満たすために不可欠です。
規制要件へのコンプライアンスを証明するために、さまざまな方法論が開発されており、それぞれに独自の利点とトレードオフがあります。この記事では、4つの主要な実装方法論を検討し、さまざまな条件下での各アプローチのトレードオフと利点を調べます。
理論
コンプライアンスプロセスの基本的な理論を確認することから始めましょう。そうすることで、チームが機能するコンテキストを理解するためのコンプライアンス目標、プロセスコンポーネント、および用語に関する共通の認識を持つことができます。
目標
私たちの目標は、関連する規制に準拠して本番環境にリリースを展開することにより、システムへの変更を安全に配信できるようにすることです。これらの規制は、組織固有の内部要件である場合もあれば、業界全体の規制または政府の命令である場合もあります。
規制とコンプライアンス構造は、システムの品質と正確性を確保することを目的としており、リスク管理の一形態です。
コンテキスト
当社の開発チームは、チーム中心の機能(チームの自律性、小さな価値単位の頻繁なリリース、平均修復時間(MTTR)の短縮など)を重視するDevOps文化の中で活動しており、リスクを最小限に抑えながらソフトウェアデリバリーを加速しています。
プロセスオーナー
当組織には、コンプライアンスオフィス(OoC)があり、達成すべき成果のセット(方法ではなく目的)と、システムが本番環境に展開される前に検証する必要があるプロセスを定義しています。これにより、チームはOoCがソリューションが目的の成果につながると合意した場合、成果を達成するための自己解決が可能になります。
たとえば、成果の1つは「高品質なソフトウェア」であり、チームはCodeClimateによって報告されたコードカバレッジ>80%が成果を満たすとOoCから合意を得る可能性があります。
より複雑な例として、「すべての変更が必要な変更である」という成果があります。これにより、すべてのコミットを製品オーナーによって優先順位付けされた関連するJIRAチケットに関連付け、別の開発者によってPRレビューを行う必要があるソリューションにつながる可能性があります。PRレビューの代わりに、別のチームはペアプログラミングとトランクベース開発を組み合わせ、コミットログに両方の開発者とJIRAの問題を特定するだけです。
コンプライアンスプロセス
高いレベルから見ると、コンプライアンスの状態を評価するには、システムのプロパティを測定し、この証拠を制約のセットに対して検証し、結果を記録する必要があります。
- プロパティ:客観的に測定可能なシステムの属性
- 測定:システムのプロパティを測定するテスト
- 証拠:プロパティの測定された値の結果。通常は真または偽(真偽値)または数値。
- 制約:要件を満たすためにプロパティ値が収まる必要がある範囲。
- 検証:証拠を特定の制約と比較することで、システムが特定の要件に関して「コンプライアンスに準拠している」ことを証明します。
注:適合関数[1]の概念は、2つのタスク、つまり証拠を取得するための測定と、証拠が特定のしきい値または値の制約を満たすことの検証で構成されています。
簡単な例としては、Kubernetes の構成から(測定)開いているポートのリスト(証拠)を抽出し、ポート 80 または 443 のみが開いていることを検証する(制約)ことです。
より包括的な適合関数としては、コードカバレッジを測定する(JaCoCo、SonarQube、CodeClimate など、さまざまな利用可能なツールのいずれかを使用)、レポートを検査する(証拠)、および報告された値を 80%(制約)の目的のコードカバレッジレベルに対して検証することです。
共通脆弱性と露出(CVE)リストのような可変制約を含むより複雑な例としては、コンテナをスキャンして(測定)CVE の存在を確認し(証拠)、既知のリスクとして受け入れられていない CVE が存在しないことを検証することです(可変制約)。
脅威モデル
コンプライアンスプロセスにおける懸念事項の1つは、結果の妥当性とシステムの整合性です。言い換えれば、コンプライアンスプロセスにどの程度の信頼を置くことができるでしょうか?
コンプライアンスプロセスに対する特定のリスクを特定するために、脅威モデルを作成することが重要です。多くの企業は開発者が侵害される可能性があると仮定しており、これにより、「最終システムに導入される変更で、可視化または監査できないものはありますか?」などの疑問が生じます。たとえば、開発者がビルドインフラストラクチャにアクセスできる場合、ビルドプロセス中にログインしてコードを変更し、SCMや監査ログに反映されないようにすることができます。
脅威モデルを理解することで、組織はリスクを軽減するために実装する必要がある戦略(適切なCI/CDインフラストラクチャセキュリティの実装など)の方向性を示すことができます。ただし、脅威モデルは組織や使用されている特定のコンプライアンス方法論によって異なり、この記事の範囲外です。
監査プロセス
監査プロセスはメタコンプライアンスの一形態であり、本質的にはコンプライアンスプロセスが実際には機能しており、定義された要件を首尾一貫して正確に遵守していることを検証します。これはコンプライアンスプロセス自体のテストであるため、より高いレベルで発生しますが、上記で説明したのと同じパターンに従います。ルールと要件のセットは小さくシンプルで、一般的にはすべてのコンプライアンス活動の網羅的な検証ではなく、ランダムサンプルの評価によって行われます。
パターン
コンプライアンスプロセスの基本的なコンポーネントを理解したので、このレンズを使用して一般的な実装パターンを調べることができます。各パターンが基本的な概念にどのようにマッピングされるかを理解することで、各パターンを評価および比較し、各実装に固有のトレードオフの根本原因を理解するのに役立ちます。
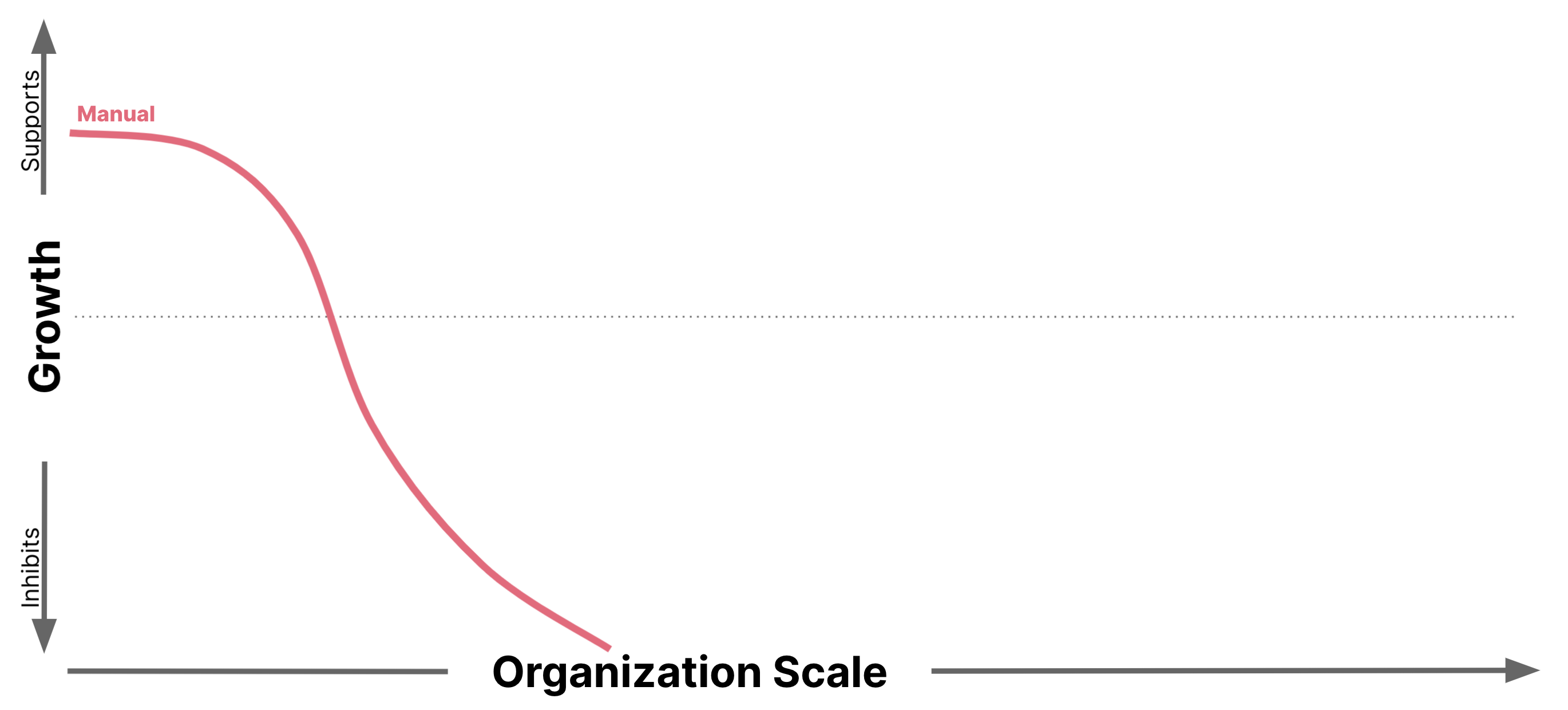
パターンは単純なものから始まり、組織とデリバリーの規模の拡大によって生じる二次的な影響に対処するために徐々に複雑になります。最も単純な形式である手動コンプライアンスから始めます。組織が成長するにつれて、コンプライアンス活動はビルドパイプラインに組み込まれる可能性があります。ビジネスを実行するために必要なソリューションの範囲が拡大するにつれて、共有機能を活用する方法を探すことが一般的になり、多くの場合、準拠したコンテナイメージの構成を活用することにつながります。最後に、単一責任の原則が、コンプライアンス検証を変更時点にシフトするにつれて、コンプライアンスドメインの境界の完全な再編成につながる方法について説明します。
手動コンプライアンス
通常、チェックリストの支援を受けて、人がコンプライアンスチェックを実行します。
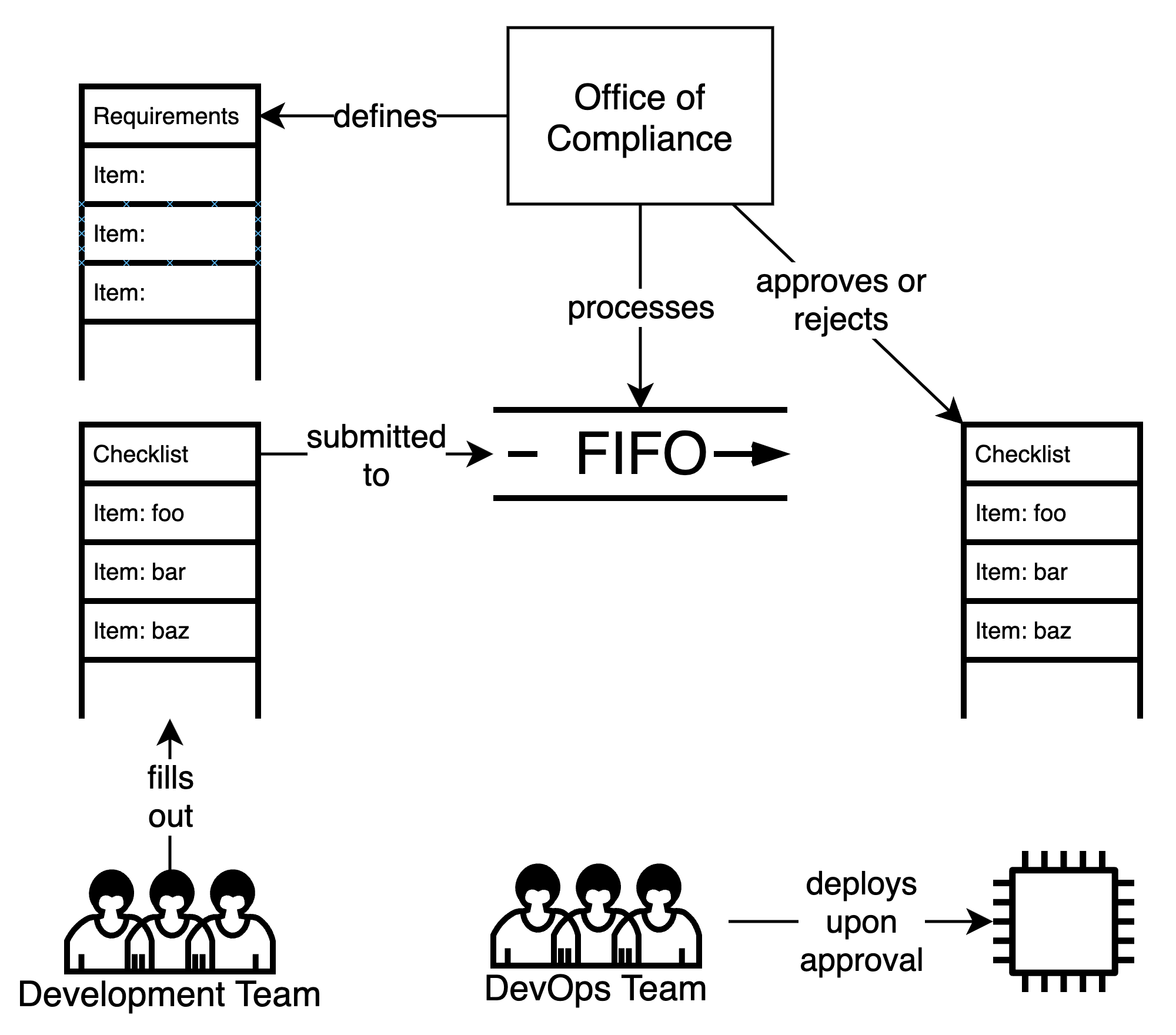
手動コンプライアンスはおそらく最も単純な形式のコンプライアンスプロセスです。この方法論では、コンプライアンスオフィスは測定するプロパティのセットを定義し、フォームまたはアンケートのセットとして測定を実装しています。これらのアンケートの質問には、はい/いいえのチェックボックス、開いているポートまたはURLのリストなどの単純な応答が含まれている場合もあれば、たとえばセキュアアクセスルールやバックアップとリカバリ手順などの記述的な説明が必要な場合もあります。
各リリースのシステムプロパティの測定は、開発チームがフォームまたはアンケートに記入し、各項目に回答するときに書面で証拠を提供することで手動で行われます。
証拠の検証行為はコンプライアンス担当者によって行われ、開発チームによって提供された証拠に比較ヒューリスティックを適用して提出書類を確認します。このルブリックは項目によって異なります。たとえば、フォームに80と443以外のポートがリストされていないことを確認したり、フォームに「承認されていない」CVEがリストされていないことを確認したりします。ルブリックに関係なく、そのような検証はすべて客観的である必要があります。
コンプライアンスプロセスの監査も、コンプライアンスフォームのランダムな選択をレビューして、フォームの情報が現実の正確な表現であり、すべての回答が検証ルブリックに合格していることを確認する比較的簡単な作業です。ただし、このプロセスの非常に手動的な性質により、その適用と結果の両方で非常に矛盾する可能性があります。目的のレベルのレポートの一貫性を達成するために、監査プロセスをより頻繁に、より詳細なレベルで実行する必要がある場合があります。
いつ使用するのか
測定対象のプロパティ数が少なく、リリース頻度が低く、レスポンスがシンプルな場合、このプロセスはシンプルで容易になります。小規模なコンプライアンスプロセスにこのプロセスを実装するには、多大なリソースや時間を投資する必要はありません。チームが記入して提出するGoogleフォームを作成するくらい簡単な場合もあります。通常、このタイプの導入には、レビュー会議に関連付けられた正式な承認として実装されることが多い手動レビュープロセスも含まれます。
組織がスケールアップするにつれて、このプロセスは非常に迅速に困難なものになる可能性があります。規模の拡大により、ワークロードと複雑性の増加を原因とする複数の側面に現れる課題が生じます。
組織の規模拡大に伴うワークロードの増加により、キャパシティの課題が生じます。組織が成長するにつれて、コンプライアンス承認の追加要求を処理するために、コンプライアンスプロセスの運用能力も比例して成長する必要があります。展開承認要求のランダムな性質により、中央コンプライアンスチームへのワークフローは非常に変動するため、迅速な対応のために中央チームの規模を決定することはコストがかかります。組織が成長するにつれて、この問題は拡大します。
組織がスケールアップするにつれて、複雑性の課題が生じ、新しくエキサイティングな障害モードが発生し、それがコンプライアンスプロセスの変更を促進します。コンプライアンスフォームはサイズと複雑さが増し、開発チームとコンプライアンスチームの両方にとってプロセスを完了するのにより多くの時間と労力を必要とします。
コンプライアンスプロセスが規模に対して非効率性を示し、開発チームがビジネス価値を迅速に提供できる速度を制限要因になり始めると、二次的な影響が現れる可能性があります。
チームは、リリースされる価値を開発するための作業が、それらの変更を本番環境に展開するために必要な総コストのかなりの部分を占めるような方法で、展開における変更をバッチ処理することにより、コスト効率に焦点を当てる場合があります。
コンプライアンスプロセスのリードタイムは、バッチサイズも決定します。コンプライアンス部門の作業能力の制限により、特定の期間に処理できる展開要求の数の上限が決まるからです。展開数が制限されている場合、顧客に提供される価値を増やす唯一の方法は、バッチサイズを増やすことです。
コンプライアンス部門が(何らかの理由で)過負荷になると、コンプライアンスの結果を待っているチームのキューが増加します。コンプライアンスプロセス自体が、価値提供を制限するボトルネックになります。多くの場合、デリバリーのプレッシャーがコンプライアンスプロセスを圧倒し、開発チームはコンプライアンスプロセスを積極的に悪用、迂回、または回避し、「シャドーIT」、妥協された設計とアーキテクチャの決定、さらにはコンプライアンスレスポンスの改ざんを引き起こします。
私たちは、商業および政府の両方の分野の組織内でこれらのすべての行動を見てきました。新しいサービスまたはシステムを本番環境に展開する前に、現実的に6〜9か月かかる手動コンプライアンスプロセスを見てきました。別のクライアントでは、彼らのプロセスが組織が提供できる速度と規模を制限するだけでなく、その適用と結果に非常に矛盾があることを示すことができました。
残念な現実として、私たちの経験では、手動コンプライアンスプロセスは、システムの安全性とセキュリティを大幅に向上させることなく、価値の提供を遅らせる「セキュリティシアター」の一種であることを示しています。また、これらのプロセスはデリバリープロセスをはるかに超えて不均衡な影響を与え、組織構造、アーキテクチャの決定、ドメイン境界、さらには人員配置と人材定着に影響を与えることも見てきました。
パイプラインコンプライアンス
展開パイプラインにコンプライアンスチェックを埋め込む。
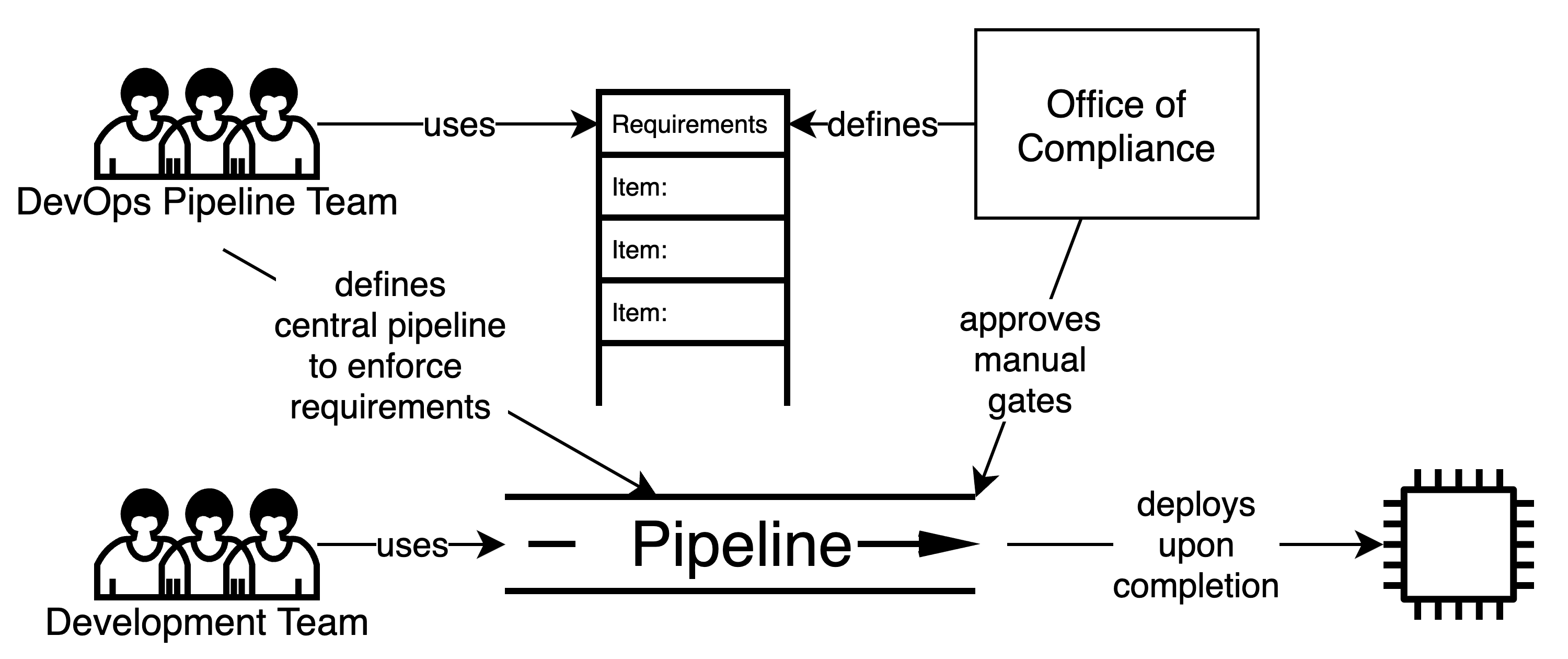
この方法では、コンプライアンスプロセスは、適合性関数とパイプラインステージ間のマニュアルゲートのセットとして、CI/CD 展開パイプライン に埋め込まれています。パイプラインは、証拠を取得し、しきい値に対して検証するために、ビルドパイプラインの一部として適合性関数を実行します。
開いているポートのチェック、ソフトウェアサプライチェーンの検証、コードカバレッジの検証などの適合性関数の場合、パイプラインに組み込むことは比較的簡単です。ただし、一部の検証では、自動化に課題がある場合があります(たとえば、特定のアーティファクトについてどのCVEが「承認」されているかを決定する方法)。これにより、パイプラインに手動ゲートが生じます。
適合性関数が失敗すると、パイプラインが失敗し、コンプライアンス検証に失敗した場合、リリースが本番環境に展開されるのを効果的に防ぎます。
このように、パイプラインを正常に実行することで、システムリリースがパイプラインに組み込まれている自動的に検証可能なコンプライアンス要件を満たしていることが暗黙的に証明されます。パイプラインステージ間のマニュアルゲートに合格することは、手動で検証可能なコンプライアンス要件も満たされていることを明示的に示しています。
いつ使用するのか
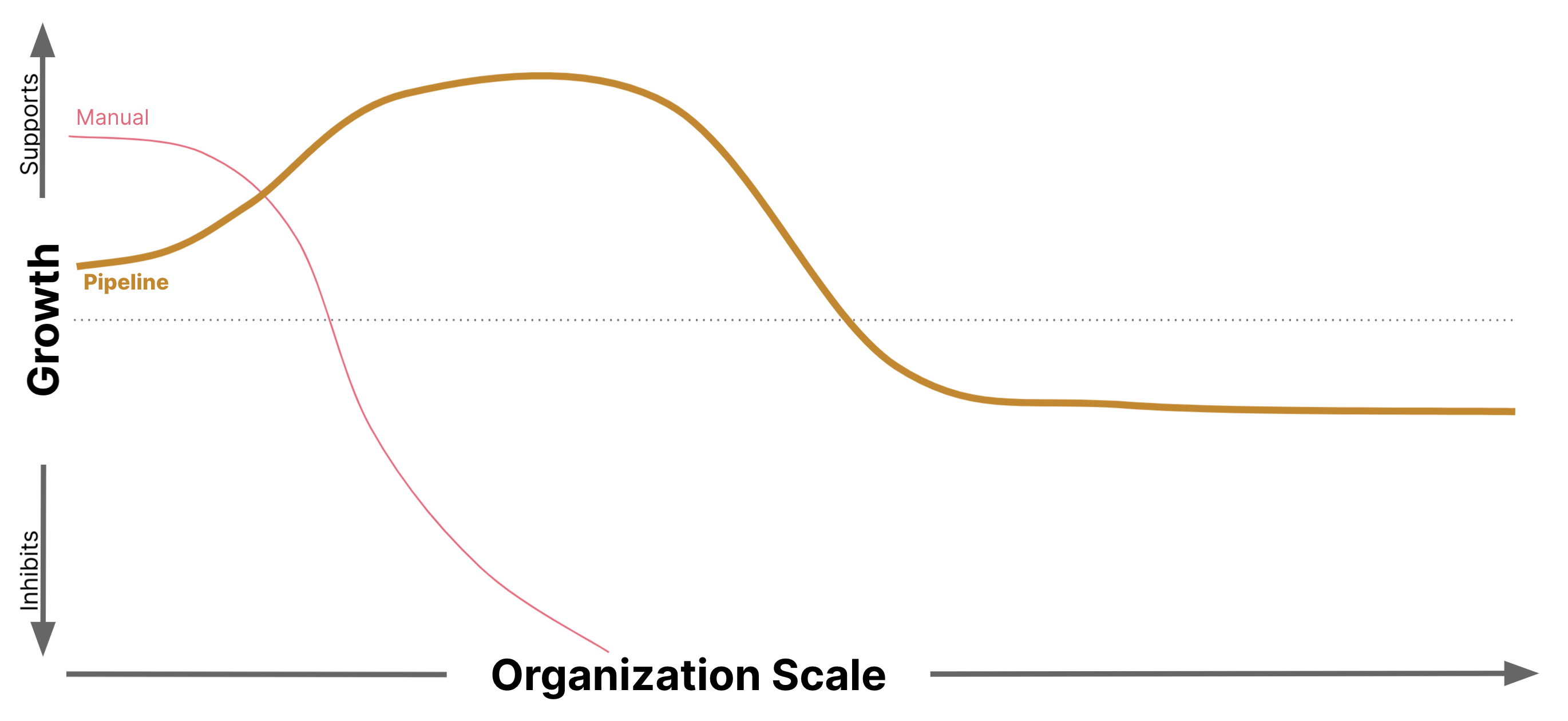
明らかに、コンプライアンステストの自動化は、コンプライアンス部門とチームの開発者の両方にとって大きなメリットです。
コンプライアンス部門は、適切なコンプライアンス適合性関数が実行されていることを保証でき、パイプラインログは適合性関数の実行と結果を記録する監査証跡を提供できます。チームは、パイプラインに必要なことを確実に実行することにより、個々の変更をゲートキーピングするのではなく、ビジネス価値の提供に集中できます。
チームの開発者は、システムリリースがコンプライアンス要件を満たしているかどうか(少なくとも適合性関数として自動化されている要件については)に関して、はるかに迅速なフィードバックを得ることができます。パイプラインの失敗は、コンプライアンスを満たしていないことを示しているためです。
すべてのチームが同じスタックを使用し、ほぼ同じタイプのシステム(RESTサービスなど)を構築している同種の開発環境では、チームは標準パイプラインをコピーすることにより効率の向上を実現できます。少なくとも、同じコンプライアンス適合性関数を共有することで、同種の環境で規模の経済効果が得られます。
本番環境での失敗に対する一般的な組織の対応は、展開プロセスに手動検証手順を追加することです。「すべての作業が完了し、ロールバック計画が存在する」という適合性関数を定義し、チームマネージャーとセキュリティ担当者の両方によって手動で検証する必要がある場合があります。これは、システムに対して名目上責任を負っているが、実際には責任を負っていない(つまり、変更に精通していない)役割の作業キューが発生するため、理想的ではありません。[2] その結果、追加の遅延が発生しますが、システムのセキュリティや安定性は見事に改善されません。
もう1つの一般的な対応は、コンプライアンスを保証するためにパイプラインをロックダウンすることです。これは、本番環境で何らかの失敗が発生し、おそらくチーム固有の標準パイプラインからの逸脱にまでさかのぼることができる場合に発生する可能性があります。組織は、すべてのチームのシステムリリースを同じ「ゴールデン」パイプラインに送ることを意図して、パイプラインコンプライアンスプロセスの責任を1つの中央チームに移行します。
私たちの経験では、チームのパイプライン内の変更頻度が高いことから、パイプラインの中央管理は、開発プロセスの最大の摩擦源の1つです。この中央管理により、中央チームがチームのシステムを進化させる能力を制限するボトルネックになっているため、開発全体が遅くなります。
二次的な影響は、手動ソリューションと同様です。「シャドーIT」、妥協された設計とアーキテクチャの決定、または更新されたコンプライアンスパイプラインなしでの本番環境への展開です。
リリースを遅らせるという明確な目的で、このような中央「所有権」の決定が行われている事例を認識しています。公開されることはほとんどありませんが、組織は、より頻繁なリリースは、その開発プロセスの体系的な未熟さをしばしば明らかにすることを認識しています。中央制御への移行は、多くの場合、エンジニアリングおよび開発チームからコンプライアンス組織へのデリバリー品質の責任を移行しようとする試みです。
時間の経過とともに生じる摩擦のレベルは、軽視することはできません。パイプラインが存在する主な理由は、ソフトウェア開発プロセスの中央ツールを提供することです。それが横断的な目標のために乗っ取られ、制御されると、開発者の懸念事項は、パイプラインチーム(多くの場合、DevOpsチーム)のスタッフ、組織、インセンティブ、運用方法に基づいて、優先順位が低下する傾向があります。
コンポジションコンプライアンス
すでにコンプライアンスと決定されているコンポーネントを組み合わせる。
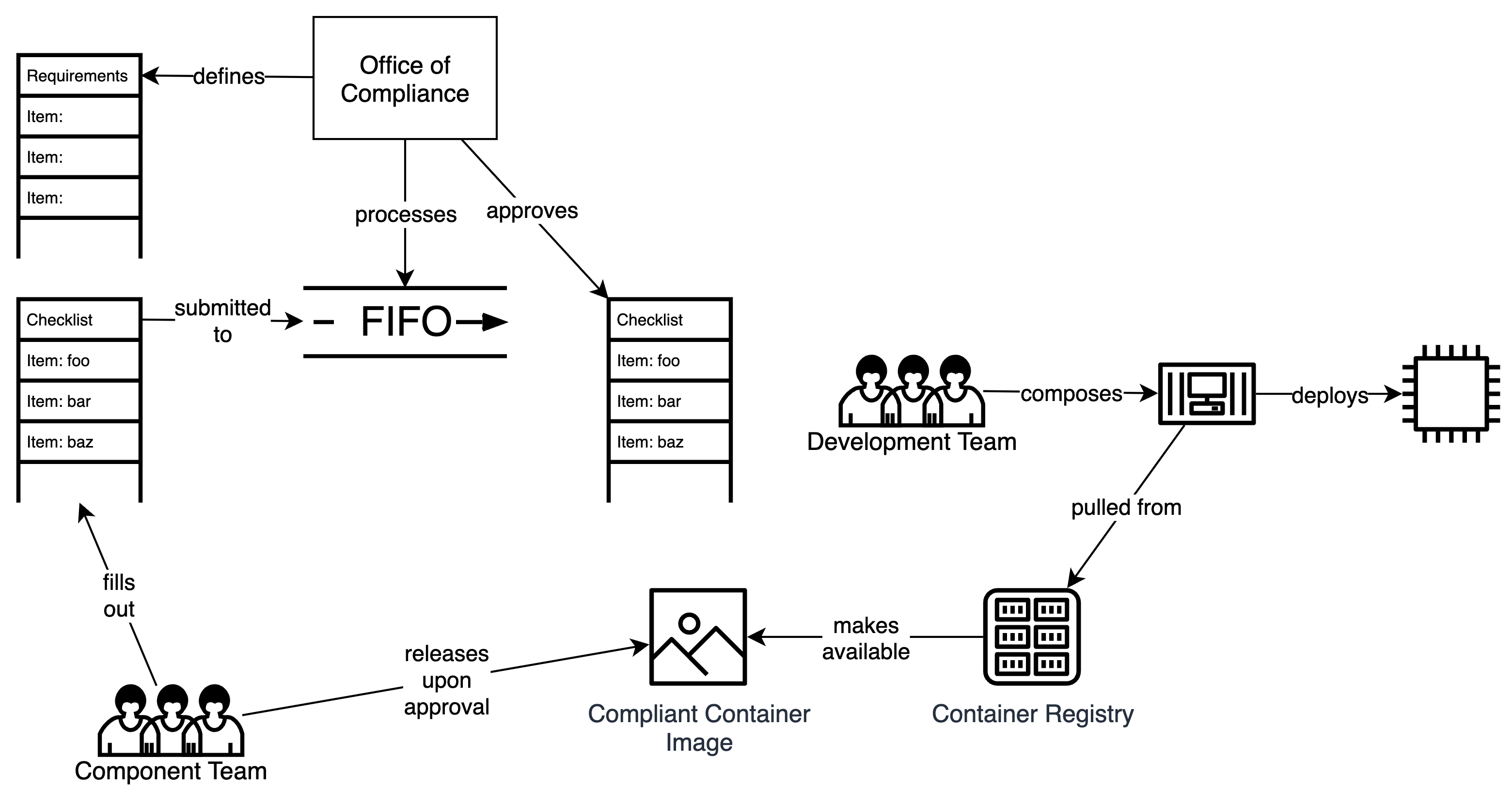
この方法は、コンプライアンスが分散型であるという前提に基づいており、コンプライアンス済みコンポーネントを構成することでコンプライアンス済みシステムを構築することが可能です。たとえば、数学における分配法則では、関数Cが「加算に対して分配的」である場合、C(A) + C(B) = C(A+B)となります。同様に、コンプライアンスは同様の方法で構成に対して分配的であると仮定できるため、組織はコンテナ化の再利用可能で構成可能な性質を活用して、幅広いソリューションのコンプライアンスを効率的に実現できます。
実際には、「コンプライアンス済み」であるとテスト済みのビジネスまたはテクノロジー機能は、コンテナイメージとして開発チームに提供されます。時間の経過とともに、組織のさまざまな部分が、利用可能なイメージのセットに新しい機能を追加または進化させる可能性があります。これらのイメージのコンプライアンスステータスは、従来のコンプライアンスプロセス(手動プロセスまたはパイプラインベースのプロセス)によって達成されます。これらの「ゴールデンイメージ」はロックダウンされており、個別に、その時点でのコンプライアンスプロセスの要件を満たしています。
期待としては、トレーニングにより、チームはこれらの「ゴールデンイメージ」を特定の方法で構成して、システムリリースを構築および展開できるようになります。たとえば、永続性を必要とするチームは、PostgreSQLイメージとCassandraイメージのどちらかを選択できます。ニーズが「ゴールデンイメージ」が提供する範囲内にある限り(たとえば、PIIなし、静止時の暗号化など)、彼らはコンプライアンス要件を満たしています。
「ゴールデンイメージ」がコンプライアンス要件を継続的に満たしていることを保証するプロセスは、このプロセスの重要な部分です。たとえば、現在「ゴールデン」であるイメージに影響を与えるCVEが発見される可能性があり、問題を解決する更新されたイメージが必要になります。これには、(現在ゴールデンではない)イメージを使用しているすべてのチームが、新しくリリースされたイメージで更新およびテストすることが必要になります。
コンプライアンスの監査は2段階のプロセスです。チームの観点から見ると、チーム固有のソリューションのコンプライアンスを実現するには、インフラストラクチャ構成が「ゴールデンイメージ」のみを使用しており、イメージのコンプライアンスステータスに違反する可能性のあるカスタマイズされた構成を追加していないことを検証するだけで済みます。
「ゴールデンイメージ」の監査は、手動プロセスまたはパイプラインベースのプロセスによって認証されたかどうかによって異なるプロセスに従い、イメージを提供するチームの懸念事項です。
いつ使用するのか
構築ブロックの機能範囲内で要件を満たすチームにとって、これは優れたソリューションです。「ゴールデンイメージ」は、チームが別途実装する必要のあるビジネスまたは技術機能を表し、これらのイメージは既にコンプライアンス要件を満たしています。例えば、ゴールデンPostgreSQLイメージに依存することで、チームはバックアップ/リストア、データベースチューニング、デプロイ、ロギング、運用上の考慮事項について考える必要がなくなります。それらすべてのアクティビティは、コンプライアンスに合格したPostgreSQL構築ブロックの一部として既に完了しています。
成熟した構築ブロックのコレクション、均質な開発環境、そしてばらつきの少ないビジネスニーズが与えられた場合、これは多くの開発チーム間での重複作業を回避することで、効率性の向上をもたらす可能性があります。
コンポーネント構成戦略に関連する摩擦は、これらの基本的な前提と制約が侵害された場合に発生します。既存の「ゴールデンイメージ」の範囲外の機能を必要とする製品開発では、開発チームがシステムのこれらの「非ゴールデン」コンポーネントについても、同じ煩雑なコンプライアンスプロセスを経る必要があります。そのため、一部のチームは相当なスケジュールリスクを認識し、システムのアーキテクチャと設計に不当な影響を与える可能性があります。
さらに、これは滑りやすい坂道です。その底では、組織は各チームが独自の特殊なソリューションのコンプライアンスを管理しているため、何ら改善されていません。コンプライアンスに合格したイメージをカスタマイズの基礎として使用することで、コンプライアンスの努力を漸進的な変更に限定できると主張する人もいるかもしれません。しかし、これらの共有された「ベースライン」イメージによるチーム間の結合は増加します。コンプライアンスの単位は依然としてイメージ全体であるため、時間の経過に伴うコンプライアンスの限界費用は、思っているよりも大きくなる可能性があります。
コンプライアンスに合格したイメージを提供する責任を中央チームに移行することには、パイプラインが集中化されている場合と同様に、上記で述べたすべての特性があります。
コンポーネント構成ソリューションは、規模が大きくなると非効率性を示し始め、開発チームがビジネス価値を提供する速度を制限する要因になり始めます。二次的な影響は、手動およびパイプラインベースのソリューションと同様です。「シャドーIT」、妥協された設計およびアーキテクチャ上の決定、またはコンプライアンス要件に合格していないコンポーネントの運用環境へのデプロイなどです。
このパターンに従うシステムでは、組織の規模に応じて異なる動作が観察されています。小規模の場合、またはこのパターンの実装の初期段階では、同様のニーズを持つチームを見つけることが容易であり、コンプライアンスに合格した構築ブロックに依存することによる経済効果は明らかであり、チームの加速に役立ちます。しかし、ある規模を超えると、提供されるソリューションのニーズは分散し、チームがコンプライアンスに合格した構築ブロックに依存できない場合に、同様の摩擦源が発生します。
注記:コンプライアンスが、コンプライアンスに合格したコンテナイメージのセットに対して実際に構成に対して分配可能かどうかという問題については、故意に回避しています。それが真実であると仮定すると、それはカスタマイズがゼロの正確なコンテナイメージに対してのみ真実であり、それは結果としてソリューション空間を非常に制限し、実際には何の効用も提供しない可能性があります。ユースケースに関連して、構成可能なコンプライアンスの範囲内でどのような種類の構成可能性が達成可能かをよく検討することをお勧めします。
変更時点コンプライアンス
変更が行われた時点でコンプライアンスチェックを実行します。
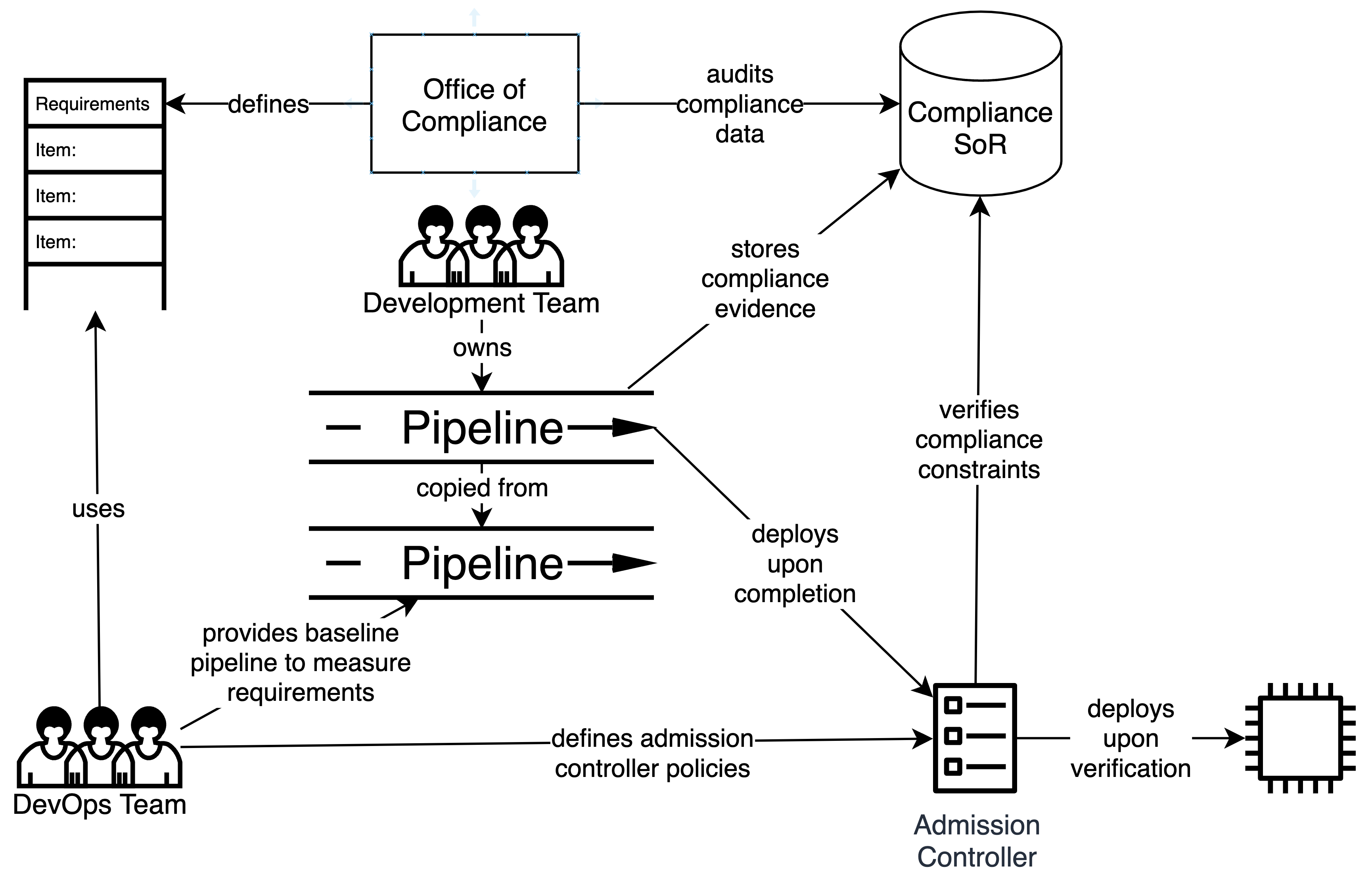
この方法では、変更が行われる時点、変更が行われる前にコンプライアンスが適用されます。すべてのコンプライアンス関連の制約と要件が満たされていることを検証することにより、目的の結果(品質、セキュリティ、監査可能性など)が達成されることを保証できます。
コンプライアンスの検証を変更時点に移行するには、プロセスを基本的なステップに分割する必要があります。適合性関数の適用を、測定と検証という基本的な単一責任のアクションにリファクタリングします。この分割により、新しいドメイン境界を作成するための接合部が提供され、より柔軟で効率的なコンプライアンスプロセスを実装できるようになります。
このプロセスでは、開発チームは証拠(つまり、従来の適合性関数の前半)を収集する責任があり、通常はパイプラインの自動化を介して行われます。たとえば、チームは、Kubernetes構成ファイルから開いているポートのリストを抽出したり、コードカバレッジを測定したり、CVEスキャンを実行したりするためのステップをパイプラインに追加する可能性があります。
開発チームが収集した証拠を保存するためのシステムオブレコード(SoR)という概念を導入します。記録されているデータや実行されているテストに応じて、SoRは1つ以上ある場合があります。たとえば、コードカバレッジやCVEスキャンはSaaSツールによって実行される可能性があり、それらのデータ要素のSoRとして論理的な選択肢になります。
コンプライアンスの検証は、変更時点(たとえば、Kubernetes以外のインフラストラクチャコンポーネントを管理するKubernetesオペレーター、またはKubernetesクラスタ内のアドミッションコントローラー)で検証されます。各アプリケーションには、マスターコントロールリストに対する独自の例外セットがあり、チームとコンプライアンスオフィスによって共同で管理されるため、証拠がコンプライアンスに違反していることを示していても、デプロイが可能です。たとえば、システムには、適用されないコントロールに対する永続的な例外のセットがある場合があります。また、新しく発見されたCVEなどの一時的な例外のセットがあり、チームは受け入れられたリスクを解決するために時間を与えられ、価値の提供が遅れることはありません。
測定の行為と検証の行為を分離したため、測定の行為がSoRによって直接管理されていない場合(たとえば、チームがKubernetes構成から開いているポートを抽出するパイプラインステップを作成した場合)、プロセスに不確実性が導入されています。SoRで証拠を照会する場合、証拠の出所、または証拠の信頼性をどのように確認しますか?パイプライン適合性関数で測定と検証がバンドルされていた場合、測定が有効であることがわかりました。この不確実性のリスクを軽減するために、暗号化署名された証拠の概念を導入して、データの来歴を検証し、一貫性のある信頼できる分散型プロセスを実現します。
まとめると、コンプライアンス検証には、すべての証拠がSoRに存在すること、SoRの外で収集された証拠には暗号で検証可能な署名があること、そしてすべての証拠のコンプライアンス検証が成功することが必要です。本質的に、Policy-as-Codeの原則を使用してコンプライアンス検証プロセスを外部化しました。このソリューションによって実現される強力な機能の1つは、コンプライアンスポリシーを独立して変更する機能であり、既存のSoRに保存されている既存の証拠に対して新しいコンプライアンスポリシーを評価して、ポリシーの変更が現在デプロイされているシステムに与える影響を理解することです。
スターターキット、または中央で開発されたベースラインパイプラインは、コンプライアンスプロセスに対して既に承認されているベースライン測定テストのセットを提供できます。このベースラインリソースのセットは、チームを特定のプロセス制約にロックすることなく、開発チーム全体で規模の経済を実現します。
チームが測定プロセスの部分を自己管理したい場合、新しい測定テストはコンプライアンスオフィスによって承認され、チームの開発プロセス(おそらくパイプライン)に統合される必要があります。新しい方法を使用したいチームは、その承認プロセスを所有する必要がありますが、増分作業は最小の変更単位(つまり、コンテナイメージではなく、個々の測定テスト)に削減されます。複数のチームで使用されることを目的とした測定は、完全にAPIで利用可能な方法で実装する必要があります。これにより、コンシューマー全体でセルフサービス導入が可能になります。
プロセスの監査も、デプロイメントステップのログの簡単なレビューになり、承認された証明書によって暗号化的に署名された証拠によってすべての結果が検証されていることを確認します。
いつ使用するのか
このソリューションは、前に説明したソリューションに存在するボトルネックを最小限に抑えるのに役立ちます。上記で説明したソリューションと比較して本質的に複雑であるため、組織の規模がこの方法で解決できるタイプのボトルネックを作成する環境に限定される可能性があります。
コンプライアンスの懸念事項を分離することにより、中央で管理されるコンプライアンス方法論に関連する摩擦を回避するために必要な疎結合を実現できます。チームは、中央で提供される一連のパイプラインコントロールを採用しながら、チームが持つ可能性のある独自の要件を効率的に自己管理することもできます。
コンプライアンスの制約が頻繁に変更される場合、組織は既存のシステムへの影響を効率的に判断し、計画の努力を削減し、実装プロセスを簡素化できます。Policy-as-Codeの原則により、測定テストを適用することで証拠を収集するプロセスに変更がないため、チームに追加の作業が回避されます。
コンプライアンスプロセスのすべての入力はデータと構成に基づいているため、監査プロセスは大幅に簡素化されます。任意の時点で、証拠のセットと検証プロセスの結果は、SoRを照会することで取得できます。
上記のように、このソリューションは懸念事項の分離のためにやや複雑です。ただし、複雑さは組織全体のすべての開発チームに委任されるのではなく、コンプライアンスオフィス内に適切に存在します。
プロセスに対する信頼の問題は、SoRおよび関連する秘密鍵管理の一部として明示的に対処する必要があり、これはコンプライアンスオフィスによって管理する必要があります。新しい測定テストの承認プロセスには既知のボトルネックがありますが、個々の作業項目(つまり、測定テストの適合性に関する合意)が大幅に小さいため、これらのボトルネックの範囲はより限定的であり、チームの開発を大幅に妨げることはありません。
「シャドーIT」やコンプライアンス要件に合格していないコンポーネントの運用環境へのデプロイのリスクはまだあります。ただし、設計とアーキテクチャの決定が妥協されるリスクは大幅に軽減されます。
私たちは長年にわたって複数のクライアントでこのパターンを実装してきました。ある大企業組織では、デプロイメント要件、セキュリティ、および証明書への準拠を確保し、CVEスキャンされたコンテナを提供する信頼できるコンテナレジストリを使用し、適切なドキュメントの存在を確認(または作成)するカスタムアドミッションコントローラーを実装しました。別の組織では、デプロイメント前にKubernetes構成でCISベンチマークテストを実行するPolicy-as-Codeソリューションを統合することに加えて、同様の機能を実装しました。
観察と経験
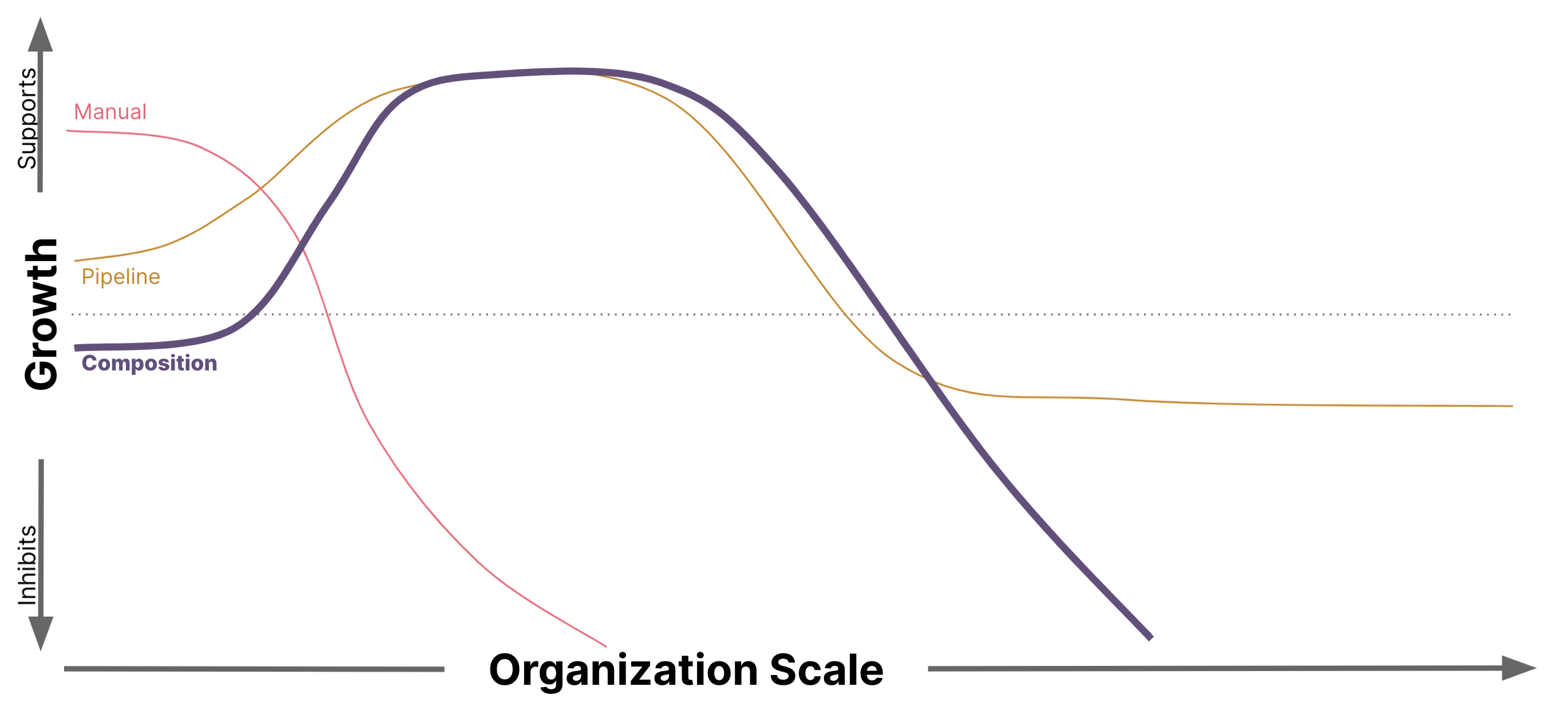
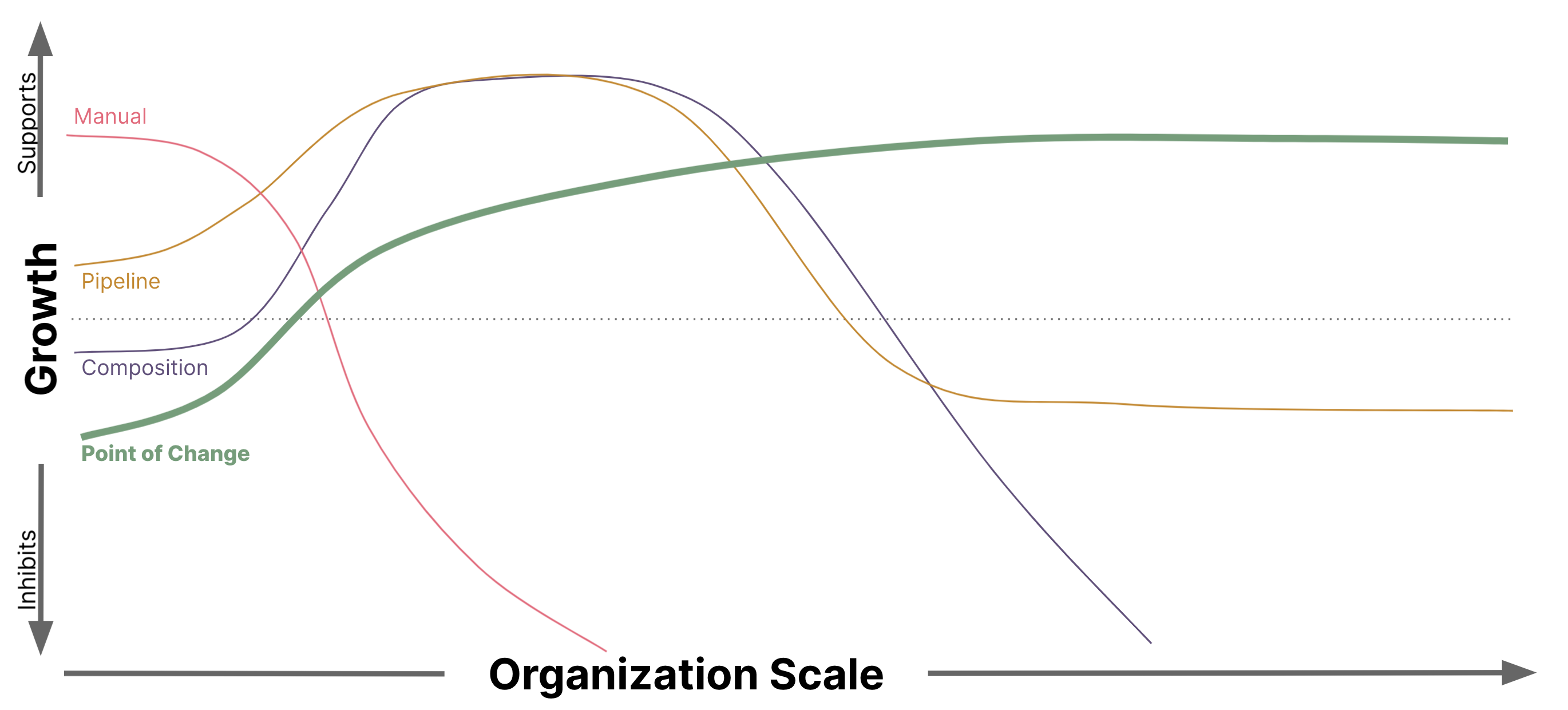
一歩下がってソリューションの範囲を見ると、パターンが明確になり始めます。私の同僚であるZhamak Dehganiは、Data Meshを支える概念に関する議論で、アーキテクチャの単位の概念をラベル付けするためにアーキテクチャクォンタ[3]という概念を使用しており、同様のアイデアを私たちのコンプライアンスドメインに適用するのは興味深いと思います。アーキテクチャとコンプライアンスのクォンタという観点から考えると、いくつかの有用な洞察が得られます。
マニュアルコンプライアンス プロセスでは、各システムをアーキテクチャ量子とコンプライアンス量子の両方として扱います。これは、システムが独自のエンティティであることを意味します。システムがどれだけ似ていても、各システムには独自のコンプライアンス作業/出力が必要です。システム間の類似点は、特に大規模なコンプライアンス作業において、無駄な作業を表しています。
パイプラインコンプライアンス プロセスでは、アーキテクチャ量子とコンプライアンス量子を区別し始めます。各システムは独自のアーキテクチャ量子ですが、コンプライアンス量子をフィットネス関数でカプセル化されたより小さな単位に分割します。これにより、組織は(共有されている可能性のある)パイプラインにおける共通の共有フィットネス関数によって、これらの新しいコンプライアンス量子をシステム間で共有できるようになります。チームは、独自のチーム固有のフィットネス関数については引き続き責任を負います。
コンポジションコンプライアンス プロセスは、さらに一歩進んで、それぞれ独自のコンプライアンスを持つ、より小さなコンポーザブルなアーキテクチャ量子にシステムを分解します。これで、これらのアーキテクチャ量子で構成されるシステムは、検証プロセス全体を実行する責任を負わなくなります。コンポーザブルな準拠コンテナイメージという形で、コンプライアンスプロセスの結果を共有するようになったためです。チームは、独自のチーム固有のコンテナイメージのコンプライアンスについてのみ責任を負います。
最後に、変更時コンプライアンス(Point-of-Change Compliance) は、コンプライアンス量子を結果を予測する個々のプロパティに分解し、フィットネス関数を個別の測定と検証手順に分解する最後のステップです。これにより、コンプライアンス量子(測定と検証)の再利用性を最大化しながら、各開発チームが独自に管理する必要があるもの(カスタム測定)を最小限に抑えることができます。
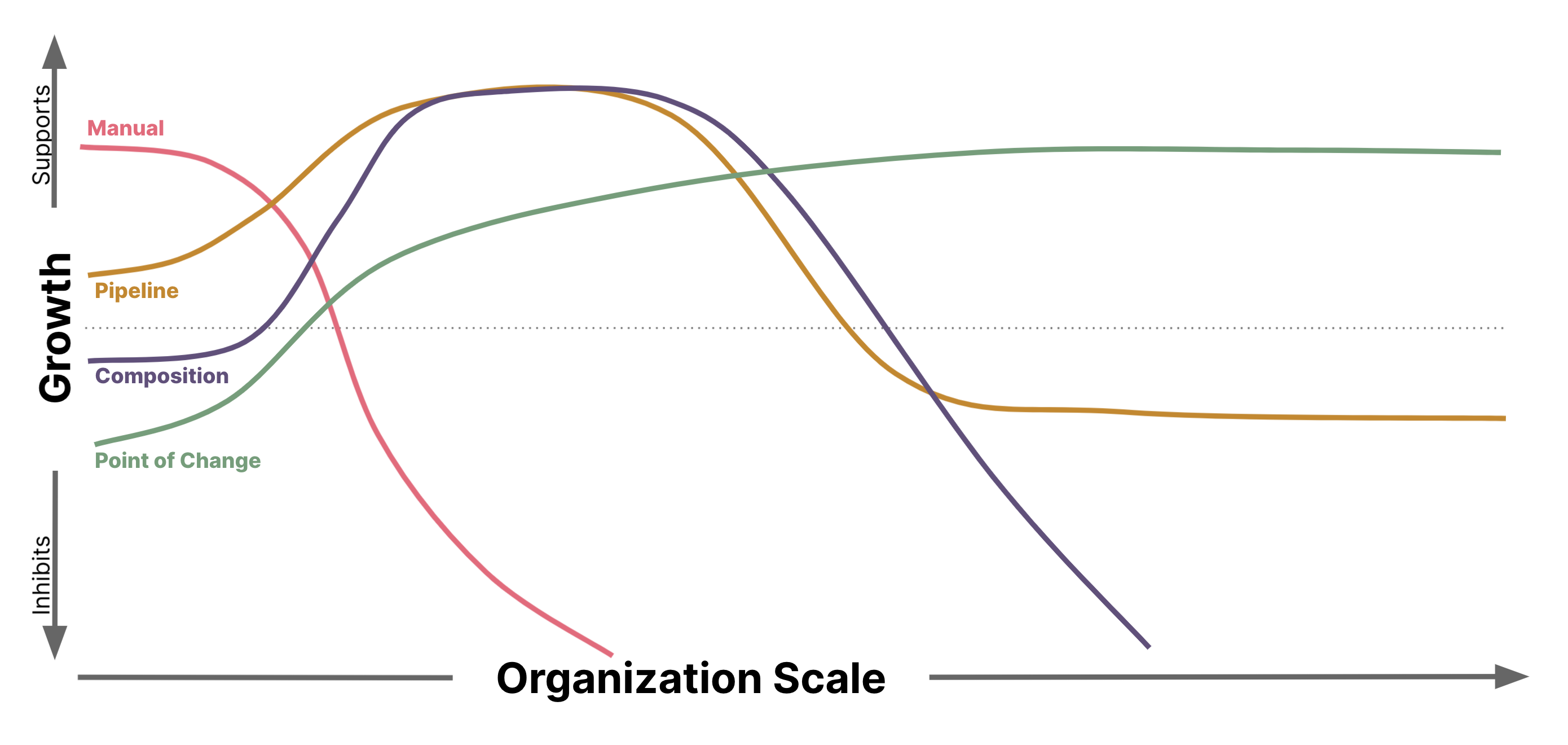
各ソリューションは、各プロセスに必要なアーキテクチャ量子とコンプライアンス量子の範囲を縮小することにより、コンプライアンスを検証するために必要な独自の作業を徐々に削減します。独自の作業が最小化されると、二次的な影響も軽減されます。さらに、再編成されたドメイン境界の結果として、新しい機能が出現します。このプロセスでは、パイプラインの所有権を開発チームに返却しながら、適切な場所に規模の経済性を維持しています。
Thoughtworksのデジタルプラットフォーム戦略エンゲージメントでは、開発者の摩擦の原因に細心の注意を払っています。クライアントに導入する広範な変更の中で、開発チームへのパイプライン所有権の返却という加速要因は、エンジニアリング組織が実行できる上位3つの価値ある投資に常に含まれています。
結論
すべてのアーキテクチャ上の意思決定と同様に、完璧なソリューションを見つけるよりも、トレードオフを評価することが重要です。コストとベネフィットを評価した後に得られる結論は、行われている作業の種類、組織の規模と規模、顧客に提供されるソリューションの複雑さによって、組織ごとに異なります。
ただし、アーキテクチャの観点から見ると、コンプライアンスアーキテクチャにおいて基本的な懸念事項の分離を採用すれば、組織のニーズを満たすようにソリューションを進化させる可能性を高めることができます。組織に基づいて緊密な結合が理にかなう場合、パイプラインでフィットネス関数を生成するために、測定と検証をバンドルする自由があります。そして、組織がある程度の規模に達すると、これらの原則により、組織はコンプライアンスソリューションをリファクタリングして、大規模なチーム効率を促進する疎結合を実現できます。
脚注
1: Building Evolutionary Architecturesの第2章を参照してください。
2: Accelerateの第7章を参照してください。
3: 彼女の議論では、アーキテクチャ量子(Architectural Quantum)はもともとBuilding Evolutionary Architectureから来ていると述べています。
謝辞
この記事は、多くの同僚からのコメント、提案、建設的な批判によって非常に多くの恩恵を受けています。Tim Cochran、Martin Fowler、Neal Ford、Nic Cheneweth、Dan Kunnath、Kief Morris、Ranbir Chawla、Brandon Byars、Andrew Buchanan、Jim Gumbley、Patrick McFadden、Shree Damaniに感謝します。
重要な改訂
2021年11月2日:公開