
データメッシュの原則と論理アーキテクチャ
ビジネスと生活のあらゆる側面をデータで拡張・改善するという私たちの願望は、大規模なデータ管理方法におけるパラダイムシフトを要求します。過去10年間の技術進歩は、データ量とデータ処理計算の規模に対処してきましたが、他の次元、つまりデータ状況の変化、データソースの増加、データユースケースとユーザーの多様性、変化への対応速度には対処できていません。データメッシュは、ドメイン指向の分散型データ所有とアーキテクチャ、データ・アズ・ア・プロダクト、セルフサービス型データインフラストラクチャ・アズ・ア・プラットフォーム、フェデレーテッド計算ガバナンスという4つの原則に基づいて、これらの次元に対処します。それぞれの原則は、技術アーキテクチャと組織構造の新しい論理的なビューを推進します。
2020年12月3日

ザマクは、Thoughtworks North Americaのイマージングテクノロジー担当ディレクターであり、分散システムアーキテクチャに重点を置き、分散型ソリューションに強い情熱を持っています。彼女はThoughtworksテクノロジー諮問委員会のメンバーであり、Thoughtworksテクノロジーレーダーの作成に貢献しています。

データメッシュの詳細については、ザマクは戦略、実装、組織設計に関する詳細を網羅した本を執筆しました。
元の文書、モノリシックなデータレイクから分散型データメッシュへの移行方法(ここに来る前に読むことをお勧めします)は、データドリブンになる、データを使って競争する、またはデータの大規模な活用による価値創出における、今日のアーキテクチャと組織上の課題という痛点を共感しました。それは、以来多くの組織の注目を集め、異なる未来への希望を与えた、代替的な視点を与えました。元の文書ではこのアプローチを説明していますが、設計と実装の多くの詳細は想像力に委ねられています。この記事では、あまりにも規定的なものになること、そしてデータメッシュ実装に関する想像力と創造性を殺してしまうことを意図していません。しかし、パラダイムを前進させるための足がかりとして、データメッシュのアーキテクチャの側面を明確にするのは責任あることだと思います。
この記事はフォローアップとして書かれています。データメッシュアプローチを、その基盤となる原則と、原則が推進する上位レベルの論理アーキテクチャを列挙することで要約しています。上位レベルの論理モデルを確立することは、将来の記事でデータメッシュの中核コンポーネントの詳細なアーキテクチャに掘り下げる前に必要な基礎です。したがって、データメッシュに関する正確なツールとレシピを探している場合は、この記事では期待外れかもしれません。単純でテクノロジーに依存しないモデルを探していて、共通の言語を確立したい場合は、一緒に進みましょう。
データの大きな分断
データとは本当に何でしょうか?答えは誰に聞くかによって異なります。今日の状況は、**運用データ**と**分析データ**に分かれています。運用データは、マイクロサービスで提供されるビジネス機能の背後にあるデータベースに存在し、トランザクション性を持ち、現在の状態を維持し、ビジネスを実行するアプリケーションのニーズに対応します。分析データは、時間の経過とともにビジネスの事実の時点的かつ集約されたビューであり、しばしば遡及的または将来的な視点の洞察を提供するようにモデル化され、MLモデルをトレーニングしたり、分析レポートに供給したりします。
現在の技術、アーキテクチャ、組織設計の状態は、これらの2つのデータプレーン―2つの存在レベル―、統合されているが別々のものの、分岐を反映しています。この分岐は、脆弱なアーキテクチャにつながっています。絶えず失敗するETL(抽出、変換、ロード)ジョブと、データパイプラインの迷路のように増え続ける複雑さは、これらの2つのプレーンを接続しようと試みる多くの人々にとって、よく見られる光景です。データは運用データプレーンから分析プレーンへ、そして分析プレーンから運用プレーンへと流れます。
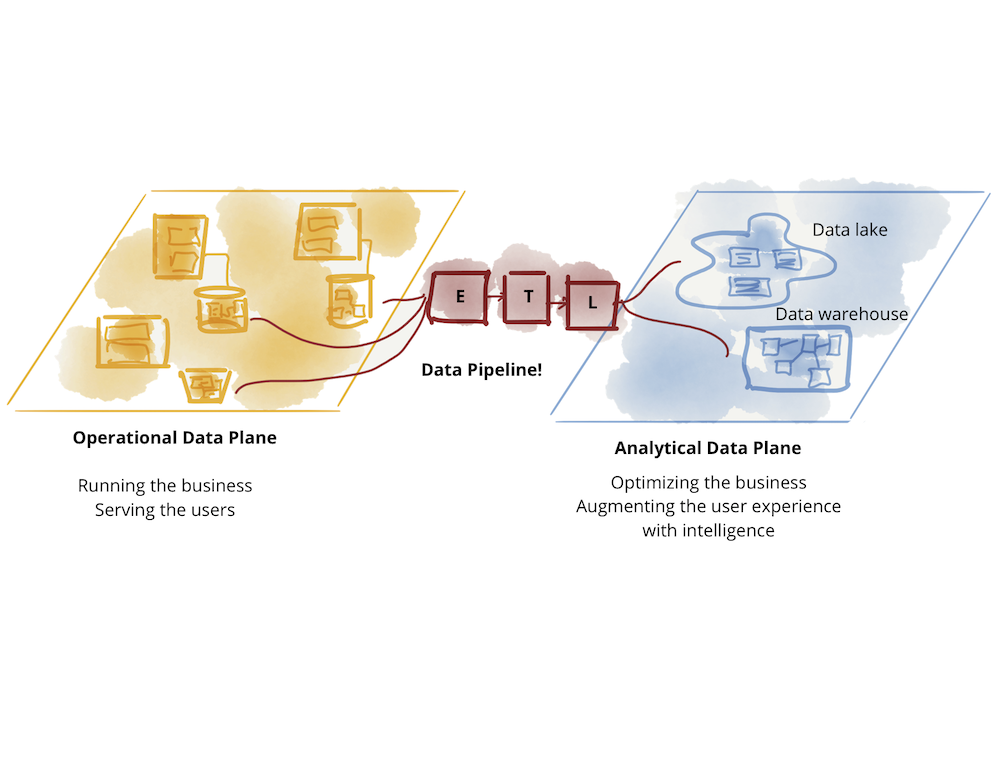
図1:データの大きな分断
分析データプレーン自体は、データレイクとデータウェアハウスという2つの主要なアーキテクチャとテクノロジースタックに分岐しています。データレイクはデータサイエンスのアクセスパターンをサポートし、データウェアハウスは分析とビジネスインテリジェンスレポートのアクセスパターンをサポートします。この会話では、データウェアハウスがデータサイエンスのワークフローを取り込もうとすることと、データレイクがデータアナリストとビジネスインテリジェンスにサービスを提供しようとすることの間のダンスを脇に置いておきます。データメッシュに関する元の文書では、既存の分析データプレーンアーキテクチャの課題を探っています。
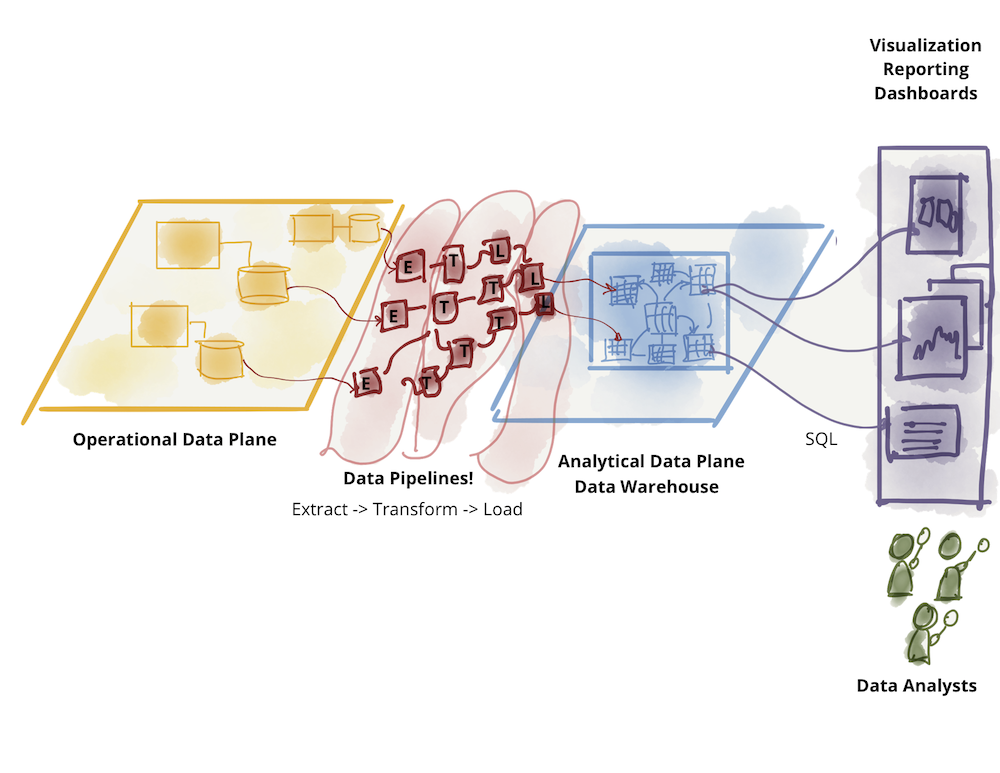
図2:分析データの更なる分断―ウェアハウス
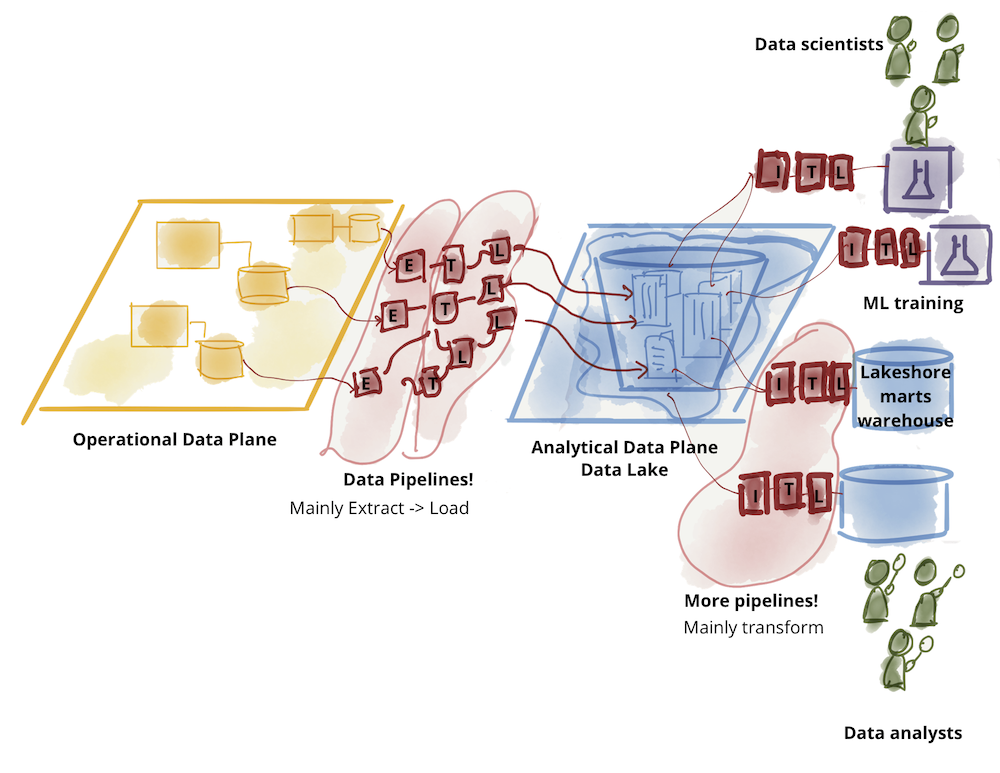
図3:分析データの更なる分断―レイク
データメッシュは、これらの2つのプレーンの違い、つまりデータの性質とトポロジー、異なるユースケース、データ消費者の個々のペルソナ、そして最終的にはそれらの多様なアクセスパターンを認識し、尊重します。しかし、それは異なる構造―**ドメインではなくテクノロジースタックに基づいた反転モデルとトポロジー**―の下でこれらの2つのプレーンを接続しようと試み、分析データプレーンに焦点を当てています。今日の2つのアーキタイプデータの管理に使用できる技術の違いは、それらに取り組む組織、チーム、人々の分離につながるべきではありません。私の意見では、運用およびトランザクションデータの技術とトポロジーは比較的成熟しており、主にマイクロサービスアーキテクチャによって推進されています。データは各マイクロサービスの内部に隠されており、マイクロサービスのAPIを介して制御およびアクセスされます。真にマルチクラウドネイティブな運用データベースソリューションを実現するためのイノベーションの余地はありますが、アーキテクチャの観点からは、ビジネスのニーズを満たしています。しかし、大規模な分析データの管理とアクセスは、摩擦のポイントのままです。これが、データメッシュが焦点を当てているところです。
将来のある時点で、私たちの技術は進化してこれらの2つのプレーンをさらに近づけるだろうと信じていますが、今のところ、それらの懸念事項は別々に保つことを提案します。
データメッシュの中核となる原則と論理アーキテクチャ
データメッシュの目的は、分析データと過去の事実から**大規模に**価値を得るための基盤を作成することです。ここでいう大規模とは、*データ状況の絶え間ない変化*、*データソースと消費者の両方の大幅な増加*、*ユースケースに必要な変換と処理の多様性*、*変化への対応速度*に適用されます。この目的を達成するために、データメッシュの実装は、規模の約束を果たしながら、データを使用可能にするために必要な品質と整合性の保証を提供するために、**4つの基盤となる原則**を具体化していると提案します。1)ドメイン指向の分散型データ所有とアーキテクチャ、2)データ・アズ・ア・プロダクト、3)セルフサービス型データインフラストラクチャ・アズ・ア・プラットフォーム、4)フェデレーテッド計算ガバナンス。
これらの原則の実践、技術、実装は時間とともに変化し、成熟すると予想されますが、これらの原則自体は変わりません。
4つの原則は、**集合的に必要十分**であることを意図しています。非互換なデータのサイロ化や運用コストの増加に関する懸念事項に対処しながら、回復力のある規模を実現できるようにします。各原則に深く掘り下げ、それをサポートする概念アーキテクチャを設計しましょう。
ドメインオーナーシップ
データメッシュは、本質的に、継続的な変化とスケーラビリティをサポートするために、データに最も近い人々に**分散化**と**責任の分散**を基盤としています。問題は、データエコシステムのコンポーネントとその所有権をどのように分解し、分散するかです。ここのコンポーネントは、*分析データ*、その*メタデータ*、そしてそれを提供するために必要な*計算*で構成されています。
データメッシュは、分解の軸として組織単位の境界に従います。今日の組織は、ビジネスドメインに基づいて分解されています。このような分解は、継続的な変化と進化の影響を―ほとんどの場合―ドメインのバウンデッドコンテキストに局限します。したがって、ビジネスドメインのバウンデッドコンテキストを、データ所有権の分散の良い候補にします。
この記事では、元の文書と同じユースケースである「デジタルメディア企業」を引き続き使用します。メディア企業は、運用、したがって運用をサポートするシステムとチームを、「ポッドキャスト」などのドメインに基づいて分割していると考えられます。ポッドキャストの公開とそのホストを管理するチームとシステム。「アーティスト」、アーティストのオンボーディングと支払いなどを管理するチームとシステムなどです。データメッシュは、分析データの所有と提供がこれらのドメインを尊重する必要があると主張しています。たとえば、「ポッドキャスト」を管理するチームは、ポッドキャストのリリースのためのAPIを提供する一方で、「時間の経過に伴うリスナー数」などの事実とともに、「時間の経過に伴うリリースされたポッドキャスト」を表す履歴データを提供する責任も負う必要があります。この原則の詳細については、ドメイン指向のデータ分解と所有権を参照してください。
論理アーキテクチャ:ドメイン指向のデータと計算
このような分解を促進するために、ドメイン別に分析データを配置するアーキテクチャをモデル化する必要があります。このアーキテクチャでは、組織の残りの部分に対するドメインのインターフェースには、運用機能だけでなく、ドメインが提供する分析データへのアクセスも含まれます。たとえば、「ポッドキャスト」ドメインは、「新しいポッドキャストエピソードを作成する」ための運用APIだけでなく、「過去
次の例は、ドメイン指向のデータ所有権の原則を示しています。図は論理的な表現と例示にすぎません。完全であることを意図していません。
各ドメインは、1つ以上の運用APIと、1つ以上の分析データエンドポイントを公開できます。
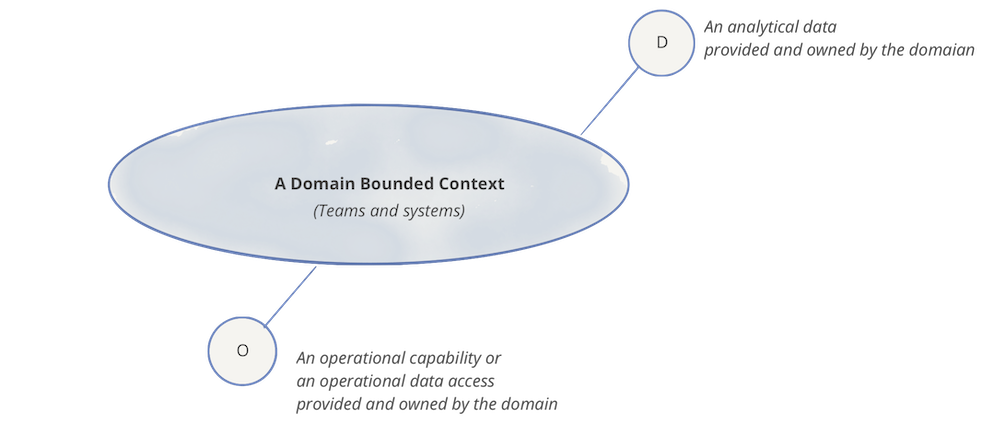
図4:表記:ドメイン、その分析データ、運用機能
当然、各ドメインは、他のドメインの運用データエンドポイントと分析データエンドポイントに依存している可能性があります。「ポッドキャスト」ドメインは、「ユーザー」ドメインから「ユーザーの更新」の分析データを使用するため、「ポッドキャストリスナーのデモグラフィック」データセットを通じてポッドキャストリスナーのデモグラフィックの状況を提供できます。
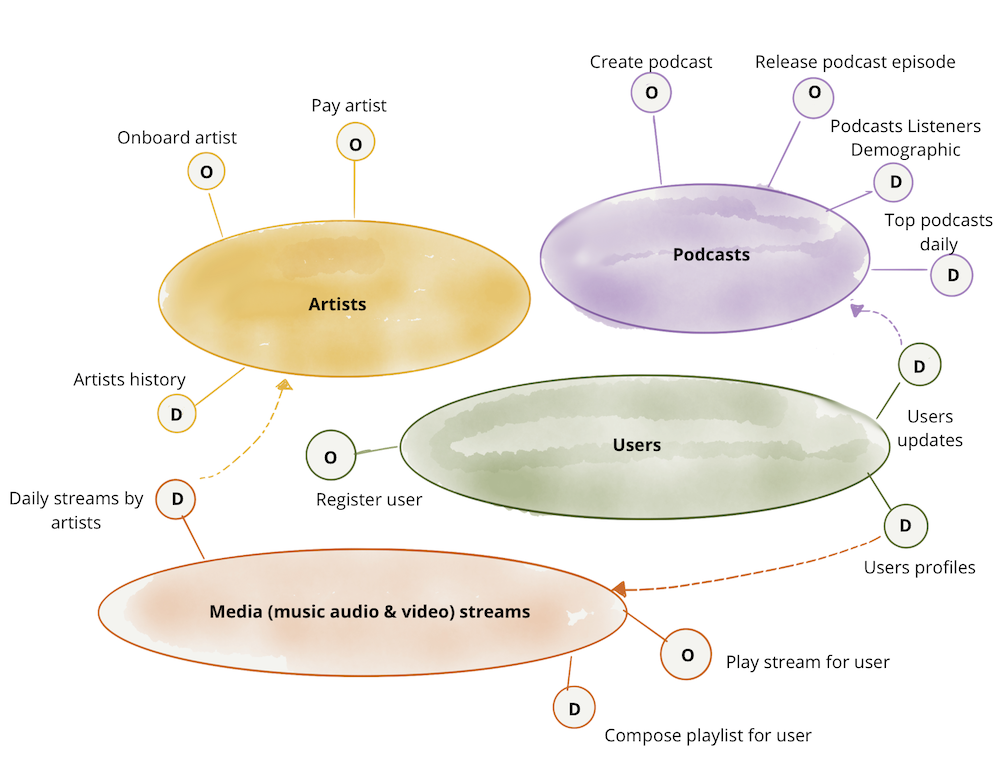
図5:例:運用機能に加えて分析データのドメイン指向の所有権
注:この例では、「アーティストへの支払い」など、運用データまたは機能にアクセスするための命令型言語を使用しています。これは単に、運用データへのアクセスと分析データへのアクセスの意図の違いを強調するためです。実際には、運用APIは、RESTfulリソースまたはGraphQLクエリへのアクセスなど、より宣言的なインターフェースを介して実装されていることを認識しています。
データ・アズ・ア・プロダクト
既存の分析データアーキテクチャの課題の1つは、**高品質なデータの発見、理解、信頼、そして最終的な使用**における高い摩擦とコストです。対処されなければ、この問題はデータメッシュとともに悪化します。データを提供する場所とチーム(ドメイン)の数が増えるためです。これは、分散化という最初の原則の結果です。データ・アズ・ア・プロダクトの原則は、データ品質と古くからのデータサイロの問題に対処するために設計されています。または、Gartnerがダークデータと呼ぶように―「組織が通常のビジネス活動中に収集、処理、保存する情報資産ですが、一般的には他の目的には使用されません」。ドメインによって提供される分析データは、製品として扱われ、そのデータの消費者は顧客として扱われる必要があります―幸せで満足している顧客として。
元の文書では、ドメインデータが製品と見なされるためにデータメッシュ実装がサポートする必要がある機能のリスト(発見可能性、セキュリティ、探索可能性、理解可能性、信頼性など)が列挙されています。また、データが製品として提供されることを保証するための客観的な指標を担当する、組織が導入しなければならない役割(**ドメインデータプロダクトオーナー**など)についても詳しく説明しています。これらの指標には、データ品質、データ消費のリードタイムの短縮、そして一般的にはネットプロモータースコアによる**データユーザーの満足度**が含まれます。ドメインデータプロダクトオーナーは、データユーザーが誰であるか、どのようにデータを使用しているか、そして彼らが快適にデータを利用できるネイティブな方法が何かを深く理解していなければなりません。そのようなデータユーザーに関する深い知識は、彼らのニーズを満たすデータ製品インターフェースの設計につながります。実際には、メッシュ上のほとんどのデータ製品においては、独自のツールと期待を持つ少数の従来のペルソナ、つまりデータアナリストとデータサイエンティストが存在します。すべてのデータ製品は、彼らをサポートするための標準化されたインターフェースを開発できます。データのユーザーとプロダクトオーナー間の対話は、データ製品のインターフェースを確立するための必要な要素です。
各ドメインには、ドメインのデータ製品の構築、維持、提供を担当する**データプロダクト開発者**の役割が含まれます。データプロダクト開発者は、ドメイン内の他の開発者と協力して作業します。各ドメインチームは、1つまたは複数のデータ製品を提供できます。既存の運用ドメインに自然に適合しないデータ製品を提供するために、新しいチームを編成することも可能です。
注:これは、過去の概念とは逆の責任モデルです。データ品質の責任は、データソースにできるだけ近い上流に移行します。
論理アーキテクチャ:データプロダクト―アーキテクチャの量子
アーキテクチャ的には、ドメインが自律的に提供または消費できる製品としてのデータのサポートのため、データメッシュは、**アーキテクチャ量子**として**データプロダクト**の概念を導入しています。進化型アーキテクチャで定義されているように、アーキテクチャ量子とは、高い機能的凝集性で独立してデプロイできるアーキテクチャの最小単位であり、その機能に必要なすべての構造要素を含んでいます。
データプロダクトは、メッシュ上のノードであり、その機能に必要な3つの構造コンポーネントをカプセル化し、ドメインの分析データへのアクセスを製品として提供します。
- **コード**:(a)上流データ(ドメインの運用システムまたは上流のデータプロダクトから受信したデータ)を消費、変換、提供するデータパイプラインのコード、(b)データ、セマンティックおよび構文スキーマ、監視メトリクス、その他のメタデータへのアクセスを提供するAPIのコード、(c)アクセス制御ポリシー、コンプライアンス、来歴などの特性を適用するコードを含みます。
- **データとメタデータ**:これは私たち全員がここにいる理由です。多様な形式の基礎となる分析データと履歴データです。ドメインデータとその消費モデルの性質に応じて、データはイベント、バッチファイル、リレーショナルテーブル、グラフなどとして提供できますが、同じセマンティクスを維持します。データを使用できるようにするには、データ計算ドキュメント、セマンティックおよび構文宣言、品質メトリクスなど、関連するメタデータセットが必要です。データに固有のメタデータ(セマンティック定義など)と、計算ガバナンスによって期待される動作を実装するために使用される特性を伝えるメタデータ(アクセス制御ポリシーなど)です。
- **インフラストラクチャ**:インフラストラクチャコンポーネントにより、データプロダクトのコードの構築、展開、実行、ビッグデータとメタデータのストレージとアクセスが可能になります。
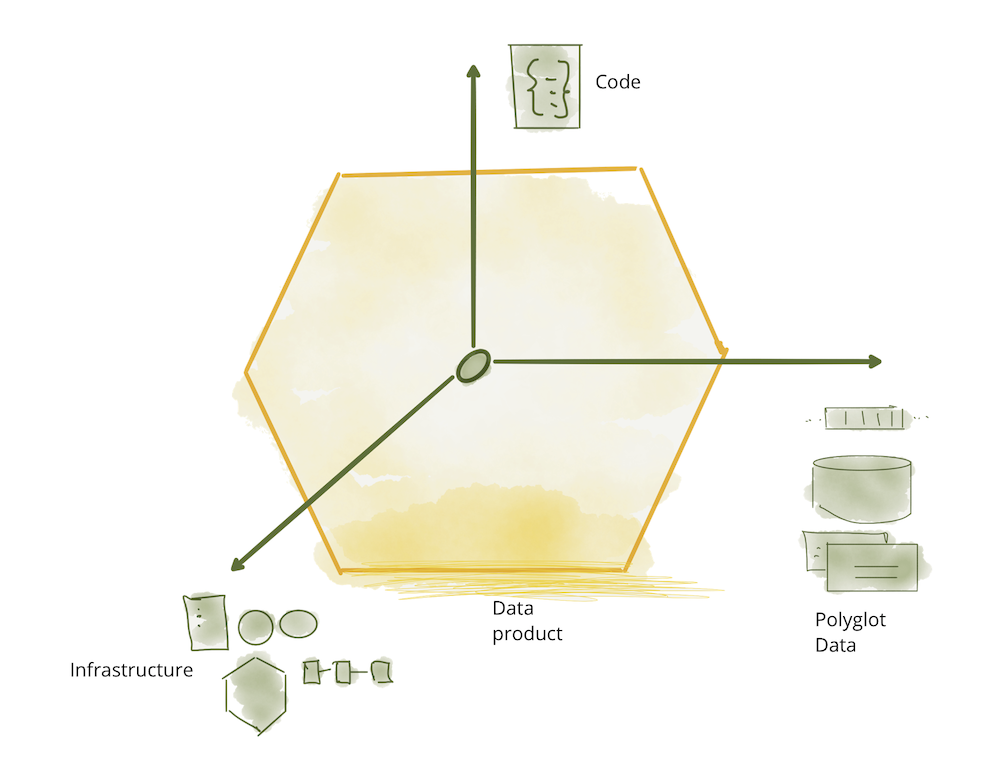
図6:アーキテクチャ量子としてのデータプロダクトコンポーネント
次の例は、前のセクションに基づいて構築され、データプロダクトをアーキテクチャ量子として示しています。この図にはサンプルコンテンツのみが含まれており、完全であることやすべての設計と実装の詳細を含めることを意図したものではありません。これはまだ論理的な表現ですが、物理的な実装に近づいています。
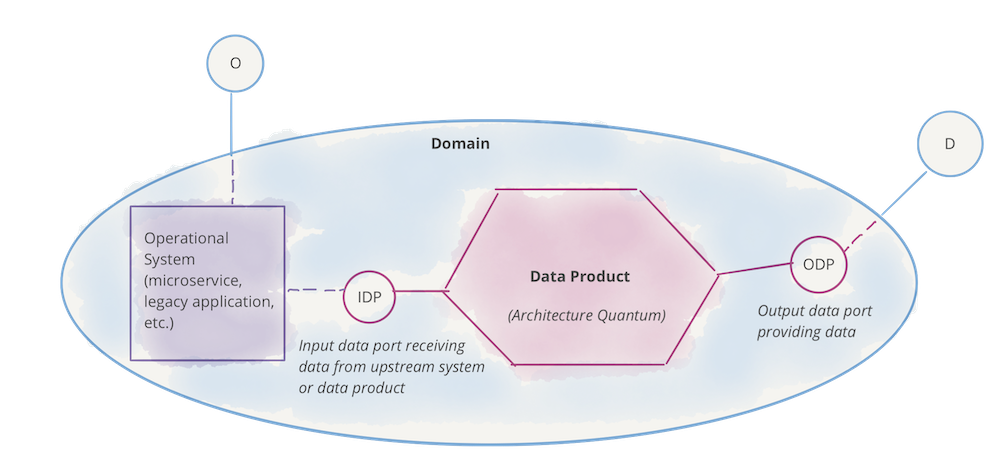
図7:表記法:ドメイン、その(分析)データプロダクト、および運用システム
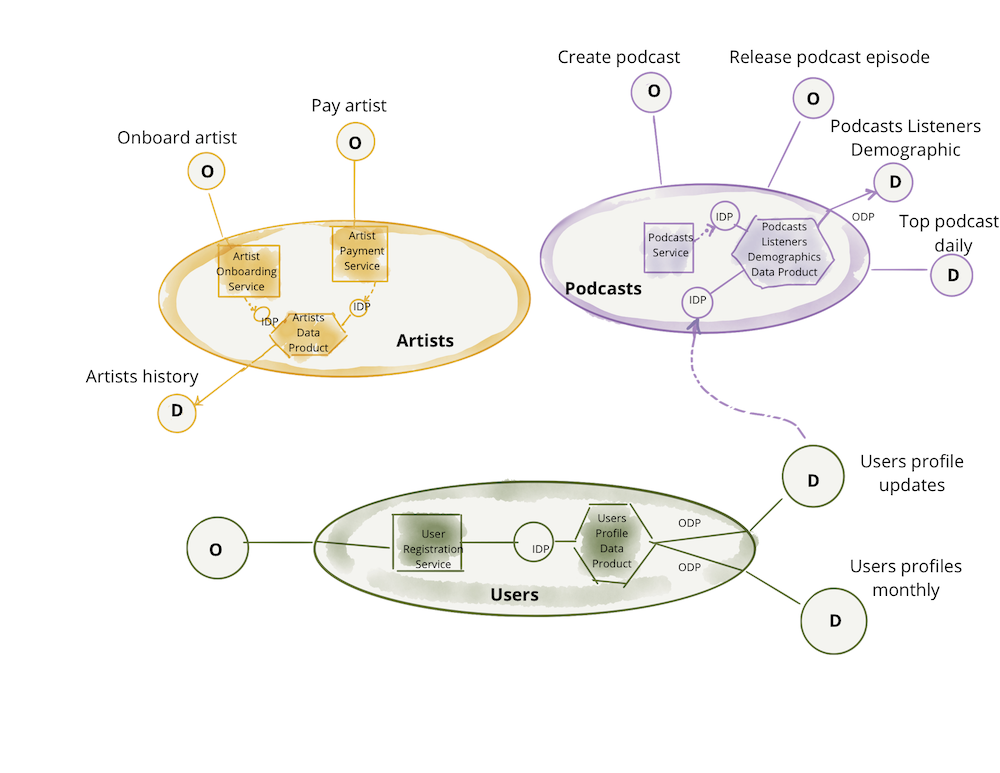
図8:ドメイン指向の分析データを提供するデータプロダクト
注:データメッシュモデルは、パイプライン(コード)が生成するデータとは独立したコンポーネントとして管理され、多くのデータセット間で共有されるウェアハウスやレイクストレージアカウントなどのインフラストラクチャが共有される過去の概念とは異なります。データプロダクトは、ドメインのバウンドコンテキストの粒度で、コード、データ、インフラストラクチャのすべてのコンポーネントを組み合わせたものです。
セルフサービス型データプラットフォーム
想像できるように、簡素な六角形(データプロダクト)を構築、展開、実行、監視、アクセスするには、かなりのインフラストラクチャをプロビジョニングして実行する必要があります。このインフラストラクチャをプロビジョニングするのに必要なスキルは専門的で、各ドメインで複製するのは困難です。最も重要なのは、チームが自律的に自分のデータプロダクトを所有できる唯一の方法は、プロビジョニングとデータプロダクトのライフサイクル管理の複雑さと摩擦を取り除く、高レベルのインフラストラクチャの抽象化にアクセスすることです。これにより、新しい原則である「**ドメインの自律性を可能にするセルフサービスデータインフラストラクチャとしてのプラットフォーム**」が必要になります。
データプラットフォームは、サービスの実行と監視のために既に存在するデリバリープラットフォームの拡張と見なすことができます。しかし、今日のデータプロダクトを運用するための基盤となるテクノロジースタックは、サービスのデリバリープラットフォームとは大きく異なります。これは、単にビッグデータテクノロジースタックが運用プラットフォームから分岐しているためです。たとえば、ドメインチームはサービスをDockerコンテナとして展開し、デリバリープラットフォームはオーケストレーションにKubernetesを使用している可能性があります。しかし、隣接するデータプロダクトは、DatabricksクラスタでSparkジョブとしてパイプラインコードを実行している可能性があります。これには、データメッシュ以前は、このレベルの相互運用性と相互接続性を必要としなかった、非常に異なる2つのインフラストラクチャセットのプロビジョニングと接続が必要です。個人的な希望としては、運用インフラストラクチャとデータインフラストラクチャが意味のあるところで収束し始めることです。たとえば、同じオーケストレーションシステム(Kubernetesなど)でSparkを実行するなどです。
実際には、汎用開発者、つまりドメインが持つ既存の開発者プロファイルに対して、分析データプロダクト開発を容易にするために、セルフサービスプラットフォームは、プロビジョニングの簡素化に加えて、新しいカテゴリのツールとインターフェースを提供する必要があります。セルフサービスデータプラットフォームは、既存のテクノロジーが想定するよりも少ない専門知識でデータプロダクトの作成、維持、実行というデータプロダクト開発者のワークフローをサポートするツールを作成する必要があります。セルフサービスインフラストラクチャには、データプロダクトの構築に必要な現在の費用と専門性を削減する機能を含める必要があります。元の記述には、セルフサービスデータプラットフォームが提供する機能のリスト(**スケーラブルな多様なデータストレージ、データプロダクトスキーマ、データパイプラインの宣言とオーケストレーション、データプロダクトの系統、計算とデータの局所性**など)が含まれています。
論理アーキテクチャ:マルチプレーンのデータプラットフォーム
セルフサービスプラットフォームの機能は、モデルで呼ばれているように、複数のカテゴリまたはプレーンに分類されます。注:プレーンは存在レベルを表します。統合されているが、別個です。物理と意識の平面、またはネットワークの制御平面とデータ平面に似ています。プレーンはレイヤーでもなく、強力な階層型アクセスモデルを意味するものでもありません。
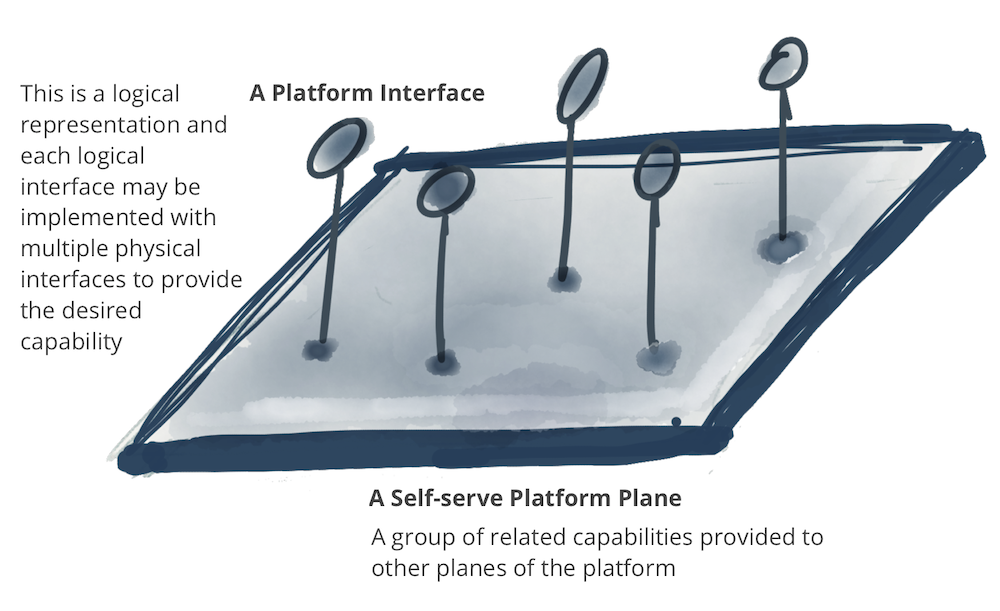
図9:表記法:セルフサービスインターフェースを介して多数の関連機能を提供するプラットフォームプレーン
セルフサービスプラットフォームには、異なるユーザーのプロファイルをそれぞれ提供する複数のプレーンを持つことができます。次の例では、3つの異なるデータプラットフォームプレーンを示しています。
- **データインフラストラクチャプロビジョニングプレーン**:データプロダクトのコンポーネントと製品のメッシュを実行するために必要な基盤となるインフラストラクチャのプロビジョニングをサポートします。これには、分散ファイルストレージ、ストレージアカウント、アクセス制御管理システム、データプロダクトの内部コードを実行するためのオーケストレーション、データプロダクトグラフ上の分散クエリエンジンのプロビジョニングなどが含まれます。他のデータプラットフォームプレーン、または高度なデータプロダクト開発者のみが、このインターフェースを直接使用すると思います。これは、かなり低レベルのデータインフラストラクチャライフサイクル管理プレーンです。
- **データプロダクト開発者エクスペリエンスプレーン**:これは、一般的なデータプロダクト開発者が使用する主なインターフェースです。このインターフェースは、データプロダクト開発者のワークフローをサポートするために必要な多くの複雑さを抽象化します。「プロビジョニングプレーン」よりも高いレベルの抽象化を提供します。データプロダクトのライフサイクルを管理するために、単純な宣言型インターフェースを使用します。すべてのデータプロダクトとそのインターフェースに適用される一連の標準とグローバルな規約として定義されている、クロスカットに関する懸念事項を自動的に実装します。
- **データメッシュ監視プレーン**:メッシュレベル(接続されたデータプロダクトのグラフ)でグローバルに最適に提供される一連の機能があります。これらのインターフェースの実装は個々のデータプロダクトの機能に依存する可能性がありますが、これらの機能をメッシュレベルで提供する方が便利です。たとえば、特定のユースケースのデータプロダクトを発見する機能は、データプロダクトのメッシュの検索または参照によって最適に提供されます。または、複数のデータプロダクトを関連付けてより高度な洞察を作成することは、メッシュ上の複数のデータプロダクトで動作できるデータセマンティッククエリの実行によって最適に提供されます。
次のモデルは例示的なものであり、完全であることを意図したものではありません。プレーンの階層は望ましいものですが、以下に厳密なレイヤーは暗示されていません。
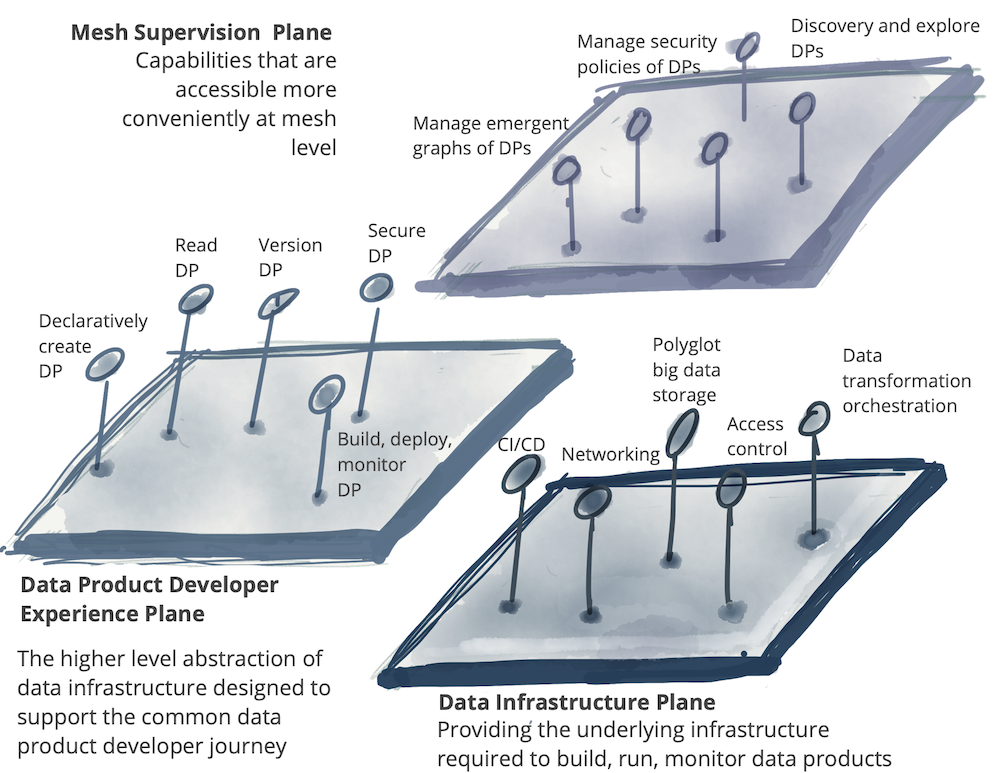
図10:セルフサービスデータプラットフォームの複数のプレーン *DPはデータプロダクトを表します
フェデレーテッド計算ガバナンス
ご覧のとおり、データメッシュは分散システムアーキテクチャに従います。独立したライフサイクルを持つ独立したデータプロダクトのコレクションであり、おそらく独立したチームによって構築および展開されます。ただし、ほとんどのユースケースでは、より高次のデータセット、洞察、または機械知能の形式で価値を得るために、これらの独立したデータプロダクトが相互運用する必要があります。それらを関連付け、結合を作成し、交点を検出し、それらに対してグラフまたは集合演算を大規模に実行できるようにします。これらの操作を行うには、データメッシュ実装に、**分散化とドメインの自己主権、グローバル標準化による相互運用性、動的なトポロジ、そして最も重要なのはプラットフォームによる意思決定の自動実行**を受け入れるガバナンスモデルが必要です。これを連邦計算ガバナンスと呼びます。ドメインデータプロダクトオーナーとデータプラットフォームプロダクトオーナーの連邦が主導する意思決定モデルであり、自律性とドメインローカルの意思決定権を持ちながら、一連のグローバルルール(すべてのデータプロダクトとそのインターフェースに適用されるルール)を作成および遵守して、健全で相互運用可能なエコシステムを構築します。このグループは、**集中化と分散化のバランス**を維持するという難しい仕事を抱えています。どの意思決定を各ドメインに局在化し、どの意思決定をすべてのドメインに対してグローバルに行うべきかです。最終的に、グローバルな意思決定には、データプロダクトの発見と構成を通じて、**相互運用性**と**複合的なネットワーク効果**を創出するという1つの目的があります。
データメッシュにおけるガバナンスの優先順位は、従来の分析データ管理システムのガバナンスとは異なります。どちらも最終的にはデータから価値を得ることを目的としていますが、従来のデータガバナンスは意思決定の集中化と、変更へのサポートを最小限に抑えたデータのグローバルな標準表現の確立を通じてそれを達成しようとします。対照的に、データメッシュの連邦計算ガバナンスは、変化と複数の解釈コンテキストを受け入れます。
システムを不変性の制約に置くことは、脆弱性の進化を引き起こす可能性があります。
— C.S. ホーリング(生態学者)
論理アーキテクチャ:メッシュに埋め込まれた計算ポリシー
フェデレーテッドガバナンスモデルが機能するためには、組織構造、インセンティブモデル、アーキテクチャを支える仕組みが必要です。これは、ローカルドメインの自律性を尊重しながら、相互運用性に関するグローバルな意思決定と標準化を行い、グローバルポリシーを効果的に実装するためです。
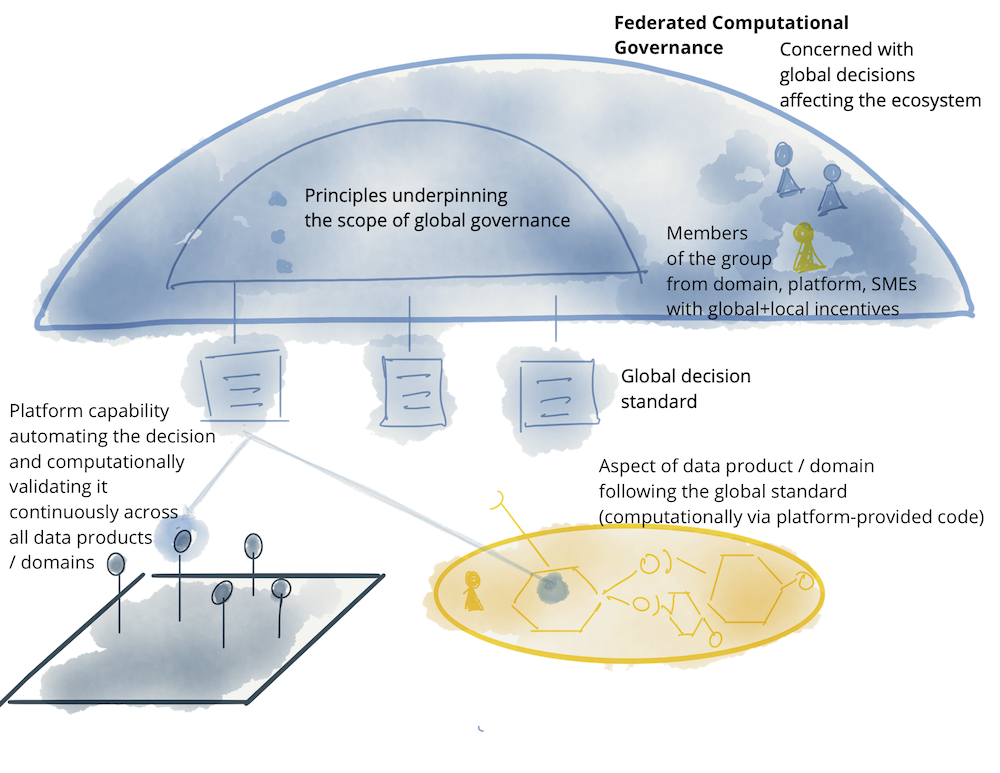
図11:表記:フェデレーテッド計算ガバナンスモデル
前述のように、グローバルに標準化され、プラットフォームによってすべてのドメインとそのデータ製品に実装および適用されるものと、ドメインが決定するものとのバランスを取ることは、一種の芸術です。例えば、ドメインデータモデルは、最も精通しているドメインにローカライズされるべき懸念事項です。「ポッドキャストオーディエンス」データモデルのセマンティクスと構文の定義方法は、「ポッドキャストドメイン」チームに委ねる必要があります。しかし、対照的に、「ポッドキャストリスナー」の識別方法は、グローバルな懸念事項です。ポッドキャストリスナーは、「ユーザー」の母集団(その上流のバウンドコンテキスト)のメンバーであり、ドメインの境界を越えて、「ユーザーはストリームを再生する」などの他のドメインに見られる可能性があります。統一された識別により、「ポッドキャストリスナー」と「ストリームリスナー」の両方である「ユーザー」に関する情報を関連付けることができます。
以下は、データメッシュガバナンスモデルに含まれる要素の例です。これは包括的な例ではなく、グローバルレベルで関連する懸念事項を示すためのものです。
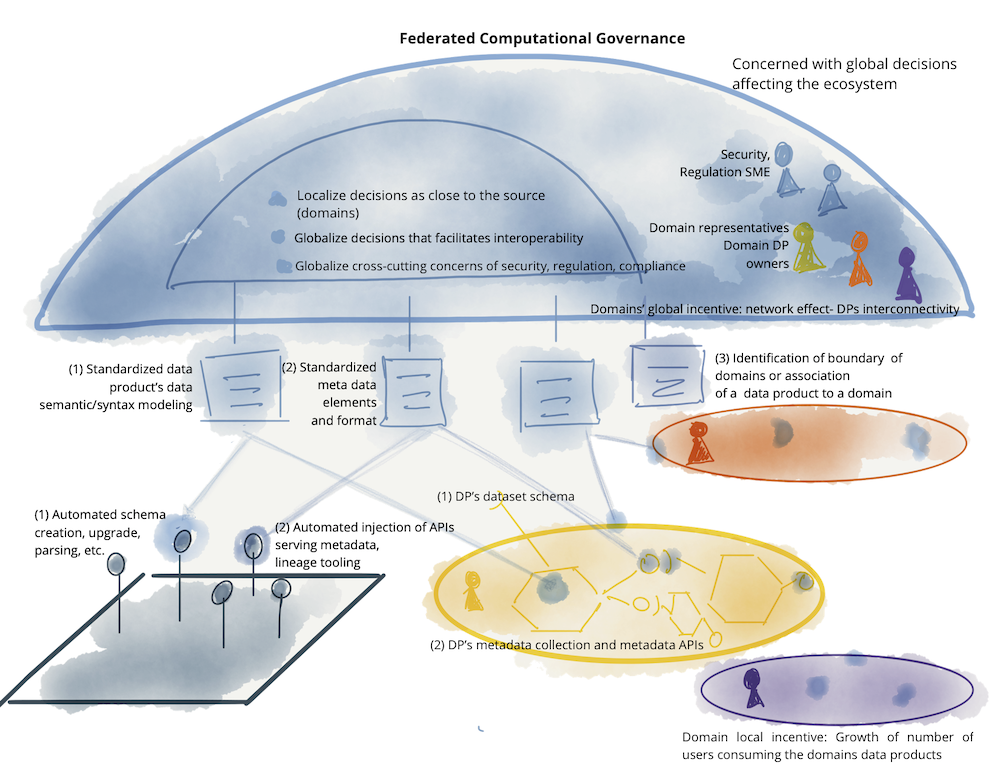
図12:フェデレーテッド計算ガバナンスの要素の例:チーム、インセンティブ、自動実装、およびデータメッシュのグローバルに標準化された側面
データメッシュ以前のガバナンスの多くの慣習は、中央集権的な機能として、データメッシュのパラダイムではもはや適用できません。例えば、過去に重視されていた、中央集権的な品質管理と認証のプロセスを経て信頼できるものとしてマークされたゴールデンデータセット(ゴールドスタンダードなデータセット)の認証は、ガバナンスの中心的な機能として、もはや関連性がありません。これは、以前のデータ管理パラダイムでは、どのような品質や形式のデータであっても、運用ドメインのデータベースから抽出され、ウェアハウスまたはレイクに一元的に格納され、そこで中央チームがクレンジング、調和化、暗号化プロセスを適用する必要があったためです。多くの場合、これは中央ガバナンスグループの管理下で行われていました。データメッシュはこの懸念事項を完全に分散化します。ドメインデータセットは、期待されるデータ製品品質指標とグローバル標準化ルールに従って、ドメイン内でローカルに品質保証プロセスを経て初めてデータ製品になります。ドメインデータ製品所有者は、最初にデータを生成するドメイン操作の詳細を知っているため、ドメインのデータ品質を測定する方法を決定するのに最適な立場にあります。このようなローカライズされた意思決定と自律性にもかかわらず、グローバルなフェデレーテッドガバナンスチームによって定義され、プラットフォームによって自動化されたグローバル標準に基づいて、品質のモデリングとSLOの仕様を遵守する必要があります。
次の表は、データガバナンスの中央集権型モデル(データレイク、データウェアハウス)とデータメッシュの対比を示しています。
| データメッシュ以前のガバナンスの側面 | データメッシュガバナンスの側面 |
|---|---|
| 中央集権型チーム | フェデレーテッドチーム |
| データ品質の責任者 | 品質の構成方法を定義する責任者 |
| データセキュリティの責任者 | データセキュリティの側面(プラットフォームが自動的に組み込み、監視するデータの機密レベルなど)を定義する責任者 |
| 規制への準拠の責任者 | プラットフォームが自動的に組み込み、監視する規制要件を定義する責任者 |
| データの中央集権的な管理 | ドメインによるデータのフェデレーテッド管理 |
| グローバルな標準データモデリングの責任者 | 複数のドメインの境界を越えるデータ要素であるポリセミーのモデリングの責任者 |
| ドメインから独立したチーム | ドメイン代表者で構成されるチーム |
| 明確に定義された静的なデータ構造を目指して | メッシュの継続的に変化する動的なトポロジーを受け入れる効果的なメッシュ運用を目指して |
| モノリシックなレイク/ウェアハウスで使用される中央集権的なテクノロジー | 各ドメインで使用されるセルフサービスプラットフォームテクノロジー |
| ガバナンス対象データ(テーブル)の数またはボリュームに基づいて成功を測定 | ネットワーク効果(メッシュ上のデータ消費を表す接続)に基づいて成功を測定 |
| 人間の介入を伴う手動プロセス | プラットフォームによって実装された自動化プロセス |
| エラーの予防 | プラットフォームの自動化された処理によるエラーの検出と回復 |
原則のサマリーと上位レベルの論理アーキテクチャ
それでは、データメッシュを支える4つの原則についてまとめてみましょう。
| ドメイン指向の分散型データ所有権とアーキテクチャ | そのため、データソースの数、ユースケースの数、データへのアクセスモデルの多様性が増加するにつれて、データを作成および消費するエコシステムをスケールアウトできます。単にメッシュ上の自律ノードを増やすだけです。 |
| データ・アズ・ア・プロダクト | そのため、データユーザーは、多くのドメインに分散されたデータを使用して、簡単に発見、理解、安全に利用でき、素晴らしいエクスペリエンスを得ることができます。 |
| セルフサービスデータインフラストラクチャとしてのプラットフォーム | そのため、ドメインチームは、プラットフォームの抽象化を使用して、安全で相互運用可能なデータ製品の構築、実行、保守の複雑さを隠しながら、自律的にデータ製品を作成および消費できます。 |
| フェデレーテッド計算ガバナンス | そのため、データユーザーは、独立したデータ製品の集約と相関関係から価値を得ることができます。メッシュは、プラットフォームに計算的に組み込まれたグローバルな相互運用性標準に従うエコシステムとして機能しています。 |
これらの原則は、分析データと運用データを同じドメインの下でより近づける一方で、それらの根本的な技術的な違いを尊重する論理的なアーキテクチャモデルを推進します。このような違いには、分析データのホスティング場所、運用サービスと分析サービスの処理のための異なる計算テクノロジー、データのクエリとアクセスの異なる方法などがあります。
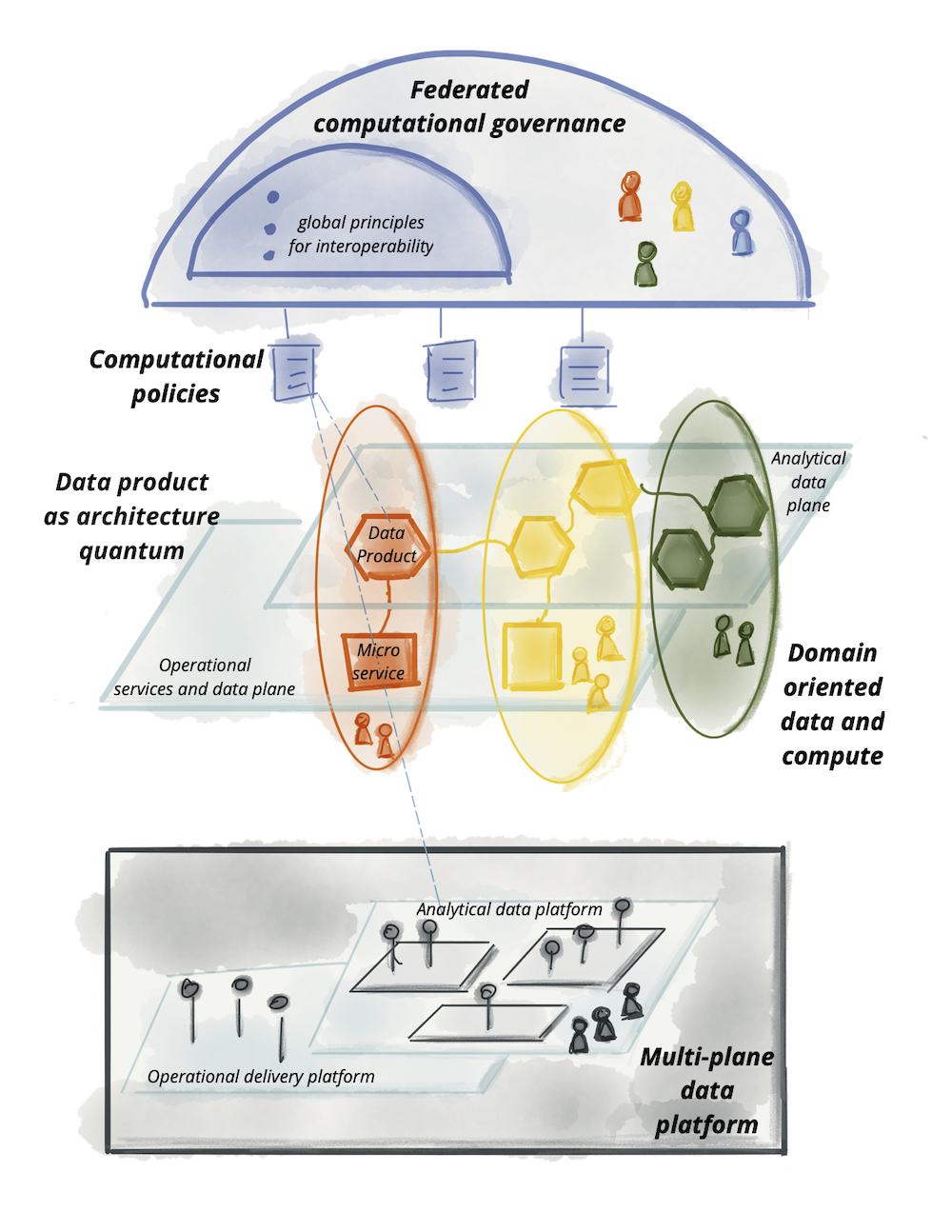
図13:データメッシュアプローチの論理アーキテクチャ
この時点で、データ製品、プラットフォーム、必要な標準化など、メッシュのコンポーネントの設計図を詳細に説明するために、私たちが共同で進めることができる共通の言語と論理的なメンタルモデルを確立できたことを願っています。
謝辞
この記事のナラティブと構造を洗練し、ホスティングしてくれたMartin Fowler氏に感謝申し上げます。
クライアント実装とワークショップを通じてこの記事のアイデアの作成と蒸留を支援してくれた多くのThoughtWorkersに特別な感謝を申し上げます。
また、貴重なフィードバックを提供してくれた以下の初期レビューアーにも感謝申し上げます:Chris Ford、David Colls、Pramod Sadalage。
重要な改訂
2020年12月3日:公開