
データレイク
2015年2月5日

データレイクとは、ビッグデータの世界におけるデータ分析パイプラインの重要な構成要素を指す言葉として、この10年間に登場しました。組織内の誰もが分析する必要のあるすべての生データを単一のストアに格納するという考え方です。一般的に、人々はHadoopを使用してレイク内のデータを処理しますが、この概念はHadoopだけにとどまりません。
組織が分析したいすべてのデータをまとめる単一のポイントについて聞くと、私はすぐにデータウェアハウス(およびデータマート[1])の概念を思い浮かべます。しかし、データレイクとデータウェアハウスの間には重要な違いがあります。データレイクは、データソースが提供する形式にかかわらず、生データを格納します。データのスキーマに関する前提条件はなく、各データソースは好きなスキーマを使用できます。そのデータを理解して活用するのは、データの利用者の責任です。
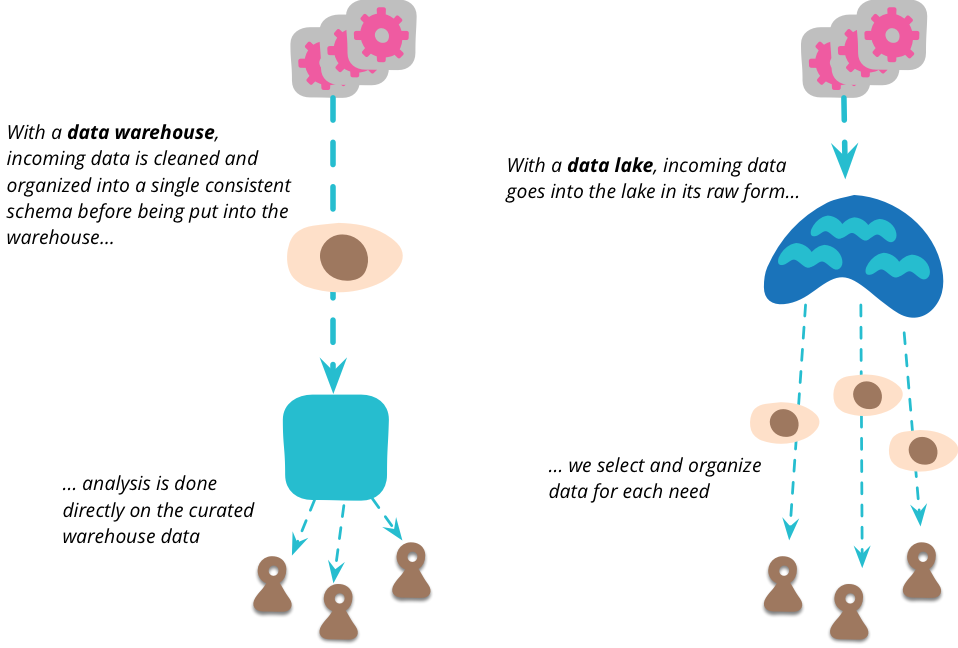
これは重要なステップです。多くのデータウェアハウス構想は、スキーマの問題のためにあまり進んでいませんでした。データウェアハウスは、すべての分析ニーズに対して単一のスキーマを使用するという概念を採用する傾向がありますが、私は、単一の統合データモデルは、ごく小規模な組織以外には実用的ではないという見解をとっています。少しでも複雑なドメインをモデル化するには、それぞれ独自のデータモデルを持つ複数の境界づけられたコンテキストが必要です。分析の観点から見ると、各分析ユーザーは、実行している分析に適したモデルを使用する必要があります。生データのみを格納するように変更することで、この責任はデータアナリストに明確に委ねられます。
データウェアハウス構想におけるもう1つの問題点は、データ品質の確保です。信頼できる単一のデータソースを取得するには、さまざまなシステムによってデータがどのように取得され、使用されるかを詳細に分析する必要があります。システムAは一部のデータに適しており、システムBは別のデータに適している場合があります。システムAは最近の注文には適していますが、返品がない限り、1か月以上前の注文にはシステムBの方が適しているというルールに遭遇します。さらに、データ品質は主観的な問題であることが多く、分析によってデータ品質の問題に対する許容範囲が異なったり、品質が良いという概念自体が異なったりします。
これは、データレイクに対する一般的な批判につながります。つまり、データレイクは、品質が大きく異なるデータの単なるゴミ捨て場であり、データの沼地と呼ぶ方が適切であるというものです。この批判は、的を射ていると同時に、無関係でもあります。新しい分析のホットな肩書きは「データサイエンティスト」です。これは乱用されている肩書きですが、これらの多くの人々は科学の確かなバックグラウンドを持っています。そして、真面目な科学者は皆、データ品質の問題をよく知っています。時間の経過に伴う気温の測定値を分析するという、単純に見えるかもしれない問題を考えてみてください。一部の気象観測所は、測定値に微妙な影響を与える可能性のある方法で移転されていること、機器の問題による異常、センサーが機能していない期間の欠落などを考慮する必要があります。既存の多くの高度な統計的手法は、データ品質の問題を解決するために作成されています。科学者は常にデータ品質に懐疑的であり、疑わしいデータを扱うことに慣れています。そのため、彼らにとってレイクは重要です。なぜなら、彼らは生データを扱うことができ、おそらく害をもたらす不透明なデータクレンジングメカニズムではなく、データを理解するための手法を意図的に適用できるからです。
データウェアハウスは通常、クレンジングだけでなく、分析しやすいようにデータを集計します。しかし、科学者はこれも反対する傾向があります。集計はデータを捨てることを意味するからです。データレイクにはすべてのデータが含まれている必要があります。なぜなら、今日でも数年後でも、何が価値があるとわかるかわからないからです。
私の同僚の1人は、最近の例でこの考え方を説明しました。「私たちは、自動予測モデルと、会社の契約マネージャーが手動で行った予測を比較しようとしていました。これを行うために、1年前のデータでモデルをトレーニングし、その時点でマネージャーが行った予測と比較することにしました。正しい結果がわかったので、これは精度の公平なテストになるはずです。私たちがこれを始めたとき、マネージャーの予測はひどいものであり、わずか2週間で作成された単純なモデルでさえ、それらを圧倒しているように見えました。私たちは、このアウトパフォーマンスは良すぎるのではないかと疑っていました。多くのテストと調査の後、これらのマネージャーの予測に関連付けられたタイムスタンプが正しくないことがわかりました。それらは、月末処理レポートによって変更されていました。つまり、データウェアハウスのこれらの値は役に立たなかったのです。この比較を実行する方法がないのではないかと恐れていました。さらに調査した結果、これらのレポートが保存されていたことがわかり、その時点で実際に行われた予測を抽出することができました。(私たちは再び彼らを圧倒していますが、そこに到達するまでには何ヶ月もかかりました)。」
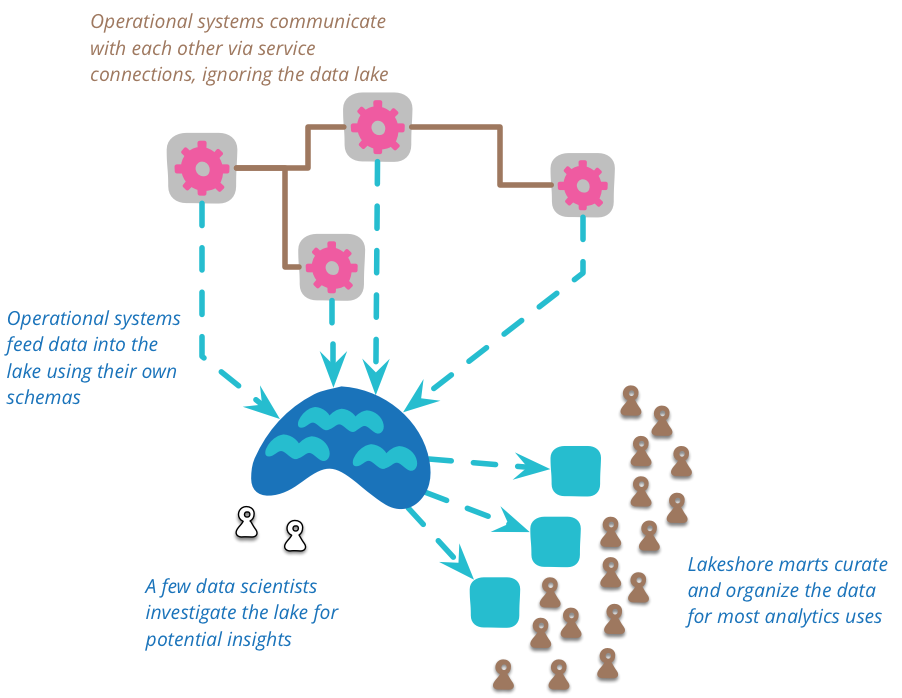
この生データの複雑さから、データをより管理しやすい構造にキュレーションする(そして、かなりの量のデータを削減する)ための余地があります。データレイクには、直接アクセスすることはあまりありません。データが生であるため、それを理解するには多くのスキルが必要です。データレイクで作業する人は比較的少なく、レイク内の一般的に役立つデータビューを発見すると、それぞれが単一の境界づけられたコンテキストの特定のモデルを持つ多数のデータマートを作成できます。その後、多数のダウンストリームユーザーは、これらのレイクショアマートをそのコンテキストの信頼できるソースとして扱うことができます。
これまでのところ、データレイクを企業全体のデータを統合するための単一のポイントとして説明してきましたが、それが本来の意図ではなかったことに言及する必要があります。この用語は、2010年にJames Dixonによって造られました。彼がそうしたとき、彼はデータレイクを単一のデータソースに使用することを意図しており、複数のデータソースは代わりに「ウォーターガーデン」を形成します。元の定式化にもかかわらず、現在の一般的な用法は、データレイクを多くのソースを組み合わせたものとして扱うことです。[2]
データレイクは、運用システム間の連携のためではなく、分析目的で使用してください。運用システムが連携する場合、RESTful HTTP呼び出しや非同期メッセージングなど、その目的のために設計されたサービスを通じて連携する必要があります。レイクは複雑すぎて、運用コミュニケーションのためにトロールすることはできません。レイクの分析から新しい運用コミュニケーションルートが生まれる可能性がありますが、これらはレイクではなく直接構築する必要があります。
レイクに配置されるすべてのデータは、時間と場所において明確な来歴を持っている必要があります。すべてのデータ項目は、どのシステムから来たのか、いつデータが生成されたのかを明確に追跡できる必要があります。したがって、データレイクには履歴レコードが含まれています。ドメインイベントをレイクにフィードすることで、これはイベントソーシングシステムと自然に適合します。しかし、これは、ソースシステムが現在の状態をレイクに定期的にダンプすることからもたらされる可能性があります。このアプローチは、ソースシステムに時間的な機能がないが、データの時間的分析が必要な場合に役立ちます。この結果、レイクに配置されたデータは不変になります。一度記述された観測値は削除できません(後で反駁される可能性はありますが)、矛盾する観測値も予期する必要があります。
データレイクはスキーマレスです。使用するスキーマを決定するのはソースシステム次第であり、結果として生じる混沌に対処する方法を理解するのはコンシューマー次第です。さらに、ソースシステムは流入データスキーマを自由に 변경できます。ここでも、コンシューマーは対処する必要があります。明らかに、私たちは solchen 変更をできるだけ混乱を少なくすることを好みますが、科学者はデータを失うよりも厄介なデータを好みます.
データレイクは非常に大きくなり、ストレージの多くは、大規模なスキーマレス構造の概念に基づいて方向付けられています。そのため、HadoopとHDFSは通常、人々がデータレイクに使用するテクノロジーです。レイクショアマートの重要なタスクの1つは、処理する必要があるデータの量を削減することです。そのため、ビッグデータ分析では、大量のデータを処理する必要はありません。
データレイクが生データの洪水に対して持つ欲求は、プライバシーとセキュリティに関する厄介な疑問を提起します。データ倹約の原則は、データサイエンティストが今すぐすべてのデータをキャプチャしたいという欲求と大きく緊張しています。データレイクは、選択したビットを公共の海に吸い込みたいクラッカーにとって、魅力的なターゲットになります。レイクへの直接アクセスを小さなデータサイエンスグループに制限することで、この脅威を軽減できる可能性がありますが、そのグループが航海するデータのプライバシーについてどのように説明責任を負わせるかの問題を回避することはできません。
注記
1: 通常の違いは、データマートは組織内の単一部門用であるのに対し、データウェアハウスはすべての部門にわたって統合されていることです。データウェアハウスはすべてのデータマートの結合であるべきか、データマートはデータウェアハウス内のデータの論理的なサブセット(ビュー)であるべきかについては、意見が分かれています。
2: 後のブログ投稿で、Dixonはレイクとウォーターガーデンの違いを強調していますが(コメントでは)、それはマイナーな変更だと言っています。私にとって重要な点は、レイクは自然の状態の大量のデータを格納することであり、フィーダーストリームの数は大したことではないということです。