
タグ付け:データ分析
データメッシュの原則と論理アーキテクチャ
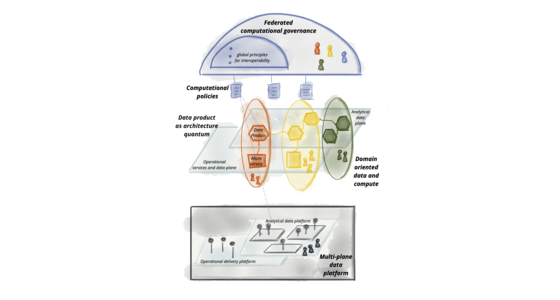
ビジネスと生活のあらゆる側面をデータで強化し改善するという私たちの願望は、大規模なデータ管理方法のパラダイムシフトを必要としています。過去10年間の技術の進歩は、データ量とデータ処理計算の規模に対処してきましたが、他の次元、つまりデータ状況の変化、データソースの増加、データユースケースとユーザーの多様性、変化への対応速度には対処できていませんでした。データメッシュは、ドメイン指向の分散型データ所有権とアーキテクチャ、データ・アズ・ア・プロダクト、セルフサービス型データインフラストラクチャ・アズ・ア・プラットフォーム、フェデレーテッドな計算ガバナンスという4つの原則に基づいて、これらの次元に対処します。各原則は、技術アーキテクチャと組織構造の新しい論理的なビューを推進します。
モノリシックなデータレイクから分散型データメッシュへの移行方法

多くの企業は、大規模なデータの民主化を図り、ビジネスインサイトを提供し、最終的には自動化されたインテリジェントな意思決定を行うことを期待して、次世代のデータレイクに投資しています。データレイクアーキテクチャに基づくデータプラットフォームには、大規模な約束を果たせない共通の失敗モードがあります。これらの失敗モードに対処するには、レイクの中央集権化されたパラダイム、またはその前身であるデータウェアハウスから移行する必要があります。現代の分散アーキテクチャを活用するパラダイムに移行する必要があります。ドメインを第一級の懸念事項として考慮し、プラットフォーム思考を適用してセルフサービス型のデータインフラストラクチャを作成し、データを製品として扱う必要があります。
平均値を比較しない
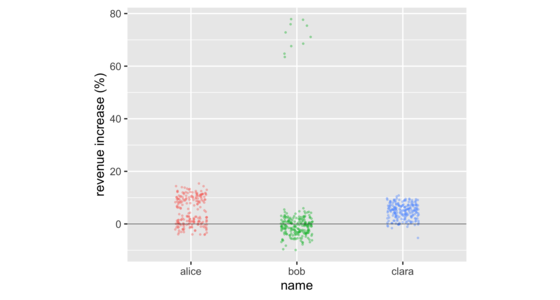
ビジネスミーティングでは、平均値を比較することで数値のグループを比較することが一般的です。しかし、そうすることで、これらのグループの数値の分布における重要な情報が隠されることがよくあります。この情報を明らかにするデータ視覚化がいくつかあります。これらには、ストリップチャート、ヒストグラム、密度プロット、ボックスプロット、バイオリンプロットが含まれます。これらは、自由に利用できるソフトウェアで簡単に作成でき、12個程度の小さなグループでも、数千個の大きなグループでも機能します。
プライバシー強化技術:技術者向け入門
プライバシー強化技術(PET)は、ソフトウェアやシステムによってデータが処理、保存、および/または収集される人のプライバシーまたは秘密性を高める技術です。価値があり、すぐに使用できる3つのPETは、差分プライバシー、分散型およびフェデレーテッド分析と学習、暗号化計算です。これらはプライバシーに関する厳格な保証を提供するため、個人データの侵害を最小限に抑えながらデータを供給するためにますます人気が高まっています。
機械学習のための継続的デリバリー
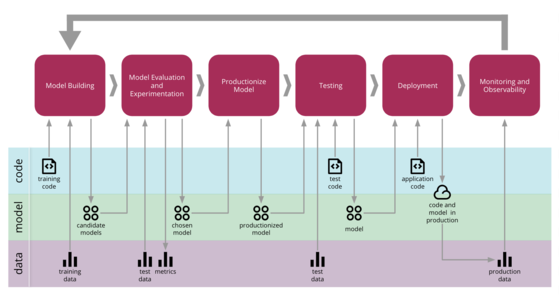
機械学習アプリケーションは私たちの業界で人気が高まっていますが、それらを開発、展開、継続的に改善するプロセスは、Webサービスやモバイルアプリケーションなどの従来のソフトウェアと比較してより複雑です。それらは、コード自体、モデル、データの3つの軸で変化の影響を受けます。それらの挙動は複雑で予測が難しく、テスト、説明、改善が困難です。機械学習のための継続的デリバリー(CD4ML)とは、機械学習アプリケーションに継続的デリバリーの原則と実践を取り入れる規律です。
バイテンポラル履歴
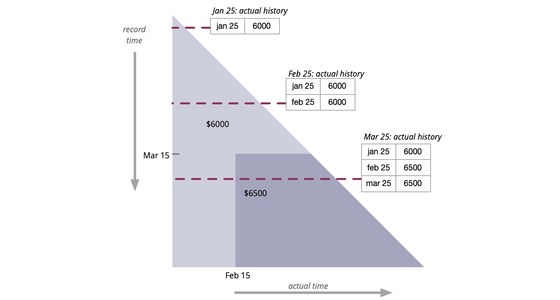
プロパティの履歴値にアクセスする必要があることはよくあります。しかし、時にはこの履歴自体が、遡及的な更新に対応して修正される必要があります。バイテンポラル履歴は時間を2つの次元として扱います。実際の履歴は、完璧な情報の伝達を前提とした履歴がどうなるべきかを記録する一方、記録履歴は、履歴に関する私たちの知識がどのように変化するかを捉えます。
データメッシュアクセラレートワークショップ

アクセラレートとは、より速く移動し、速度を得ることです。現代の世界で成功したいと考えている組織にとって、データの効果的な活用は鍵であり、データメッシュは組織がデータから大規模に価値を実現する方法を示しています。データメッシュアクセラレートワークショップは、現在の状態を理解し、次のステップがどうなるかを検討することで、チームと組織がデータメッシュの変革を加速するのに役立ちます。
データサイエンスノートブックを本番環境に投入しない
データサイエンティストが開発した計算ノートブックを取り、それを本番アプリケーションのコードベースに直接配置することに関心のある多くのクライアントに遭遇しました。データサイエンスのアイデアはノートブックから本番環境に移行する必要がありますが、そのノートブックをコードアーティファクトとして展開しようとすると、多くの優れたソフトウェアプラクティスが破られます。予測どおり、これにより、多くの問題点が観察されています。この行動は、より深い問題、つまりデータサイエンティストとソフトウェア開発者間の協力不足の症状です。
進化するデータのパノラマ
2012年のQCon Londonでの基調講演では、データが私たちの生活で果たしている役割(そしてそれが単に大きくなっているだけではないこと)を見てきました。まず、データの世界がどのように変化しているかを見ていきます。データは成長し、より分散化され、接続されています。次に、業界の対応を見ていきます。NoSQLの台頭、サービス統合への移行、イベントソーシングの出現、クラウドの影響、視覚化の役割がより大きくなった新しい分析です。現在データがどのように使用されているかを簡単に見て、特にレベッカによる開発途上国でのデータに重点を置いています。最後に、ソフトウェア専門家としての私たちの個人的な責任に、これらすべてが何を意味するかを検討します。
ビッグデータについて考える
「ビッグデータ」は、私たちの業界で最も過大宣伝されている用語の1つに急速に躍進しましたが、この過大宣伝は、これが世界におけるデータの役割に関する真に重要な変化であるという事実を人々に盲目的にさせてはいけません。データソースの量、速度、価値は急速に増加しています。データ管理は、より幅広いソースからのデータの**抽出**、新しいデータベースと統合アプローチによるデータ管理の**ロジスティクス**の変化、分析プロジェクトの実行における**アジャイル**原則の利用、ノイズから信号を分離するためのデータ**解釈**のテクニックの強調、そしてその信号をより理解しやすくするための適切に設計された**視覚化**の重要性の5つの主要な分野で変化する必要があります。要約すると、これは、大規模な分析プロジェクトは必要なく、代わりに新しいデータ思考を通常の作業に浸透させる必要があることを意味します。
BigQueryの概念実証
Googleの新しいBigQueryサービスは、高価なソフトウェアや新しいインフラストラクチャを必要とせずに、顧客にビッグデータ分析の力を提供できますか?ThoughtworksとAutoTraderは、大規模なデータセットを使用して、1週間の概念実証テストを実施しました。テストでは、7億5000万行のデータセットで、7〜10秒の範囲で一貫したクエリパフォーマンスが示されました。Java、JavaScript、Google Chartsを使用してREST APIを使用し、クエリ結果のインタラクティブな視覚化を備えたWebフロントエンドを作成しました。この演習全体は、3人の担当者によって5日間で行われました。結論:BigQueryは良好に機能し、特にデータウェアハウスを持たない組織、またはデータウェアハウスの使用が制限されている組織にとって、ビッグデータと少額の予算を持つ組織に役立ちます。
NoSQL入門
goto Aarhusでは、NoSQLに関する実践的な経験に関するトラックがありました。NoSQLデータストアの基本原則を説明するための最初の講演を行うように依頼されました。NoSQLの起源、NoSQLデータモデルの形式、多くのNoSQLデータベースが一貫性の問題をどのように考慮しているか、そしてポリグロットパーシスタンスの重要性について説明します。
Dave Farleyとのエンジニアリングルーム会話
私の旧同僚であるDave Farleyは、ソフトウェア開発に関するますます人気のあるYouTubeチャンネルを運営しています。それは良い資料であり、私の見解と非常によく合致しています。結局のところ、彼の経験は私の考え方に大きな影響を与えています。現在私がサポートしている3つの大規模な執筆プロジェクト、データメッシュ、分散システムのパターン、レガシー置換のパターンに特に焦点を当てて、ソフトウェアエンジニアリングの現在の役割に関するさまざまなトピックについて話し合います。
ソフトウェア開発におけるデータの進化する役割
2020年のXConfにオーストラリアへ旅行できなかったため、代わりにScott Shaw(Thoughtworksオーストラリアのテクノロジーヘッド)とズームで会話をしました。現代のアプリケーション開発におけるデータの役割の変化、アプリケーション開発者とデータベースの溝、大きく(そして散らかった)データの出現による変化、データリテラシーの向上、投機的なデータを収集することの社会的影響について話し合いました。
データでは異なる
私たちのヨーロッパの「データウィッチ」であるEm Grasmederと私は、ヨーロッパのXConfシリーズの基調講演を計画していました。2020年であるため、代わりにズームで話し合い、データサイエンティストの役割、実際の役割、取得する必要があるツール、その他のソフトウェア開発との関係について話し合いました。
Rのggplot2によるミュートスパゲッティラインチャート
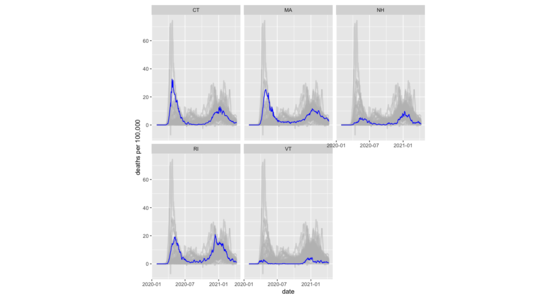
ファセットを含むRでミュートスパゲッティチャートをプロットする方法。
共有ダッシュボード

データ分析と視覚化への関心の高まりとともに、組織内を浮遊するデータから洞察を引き出すことを可能にする興味深い視覚化への努力が増えています。これらのダッシュボードのほとんどは個々の使用を目的としていますが、より共有目的で使用するための傾向が高まっています。
計算ノートブック
計算ノートブックは、散文文書を作成するための環境であり、作成者はコードを埋め込むことができ、その結果も文書に簡単に組み込むことができます。これは、特にデータサイエンスの作業に適したプラットフォームです。このような環境には、Jupyter Notebook、R Markdown、Mathematica、Emacsのorg-modeなどがあります。
データレイク

データレイクは、ビッグデータの世界におけるデータ分析パイプラインの重要なコンポーネントとして、この10年で登場した用語です。その考え方は、組織内の誰でも分析する必要がある可能性のあるすべての生データの単一ストアを持つことです。一般的に、人々はHadoopを使用してレイク内のデータに取り組んでいますが、この概念はHadoopだけにとどまりません。
データ節約(Datensparsamkeit)

Datensparsamkeitは、ドイツ語で、英語に適切に翻訳するのが難しい単語です。これは、データの取得と保存の方法に対する姿勢であり、本当に必要なデータだけを扱うべきだということを意味します。
機械による正当化
私は十代の頃、人工知能(AI)が今後数年間で素晴らしいことをするだろうと聞かされました。数十年後、それらのいくつかが実現しつつあります。最近の成功例としては、コンピューター同士が互いに対戦することで囲碁のプレイを学び、人間の専門家よりも急速に熟練し、人間の専門家がほとんど理解できない戦略を生み出したことが挙げられます。今後数年間で何が起こるのか、コンピューターはすぐに人類よりも高い知性を獲得するのでしょうか?(最近の選挙結果を考えると、それほど高いハードルではないかもしれません。)
しかし、これらの話を聞くと、数十年前のパブロ・ピカソのコンピューターに関するコメントを思い出します。「コンピューターは無益だ。答えしか与えてくれない」。機械学習などの技術によって得られる推論の種類は、その結果において非常に印象的で、ソフトウェアのユーザーや開発者にとって役立つでしょう。しかし、答えは役に立つものの、常に全体像を表しているわけではありません。私は学生時代にそれを学びました。数学の問題の答えを出すだけでは、ほんの数点しか取れませんでした。満点を取得するには、どのように答えを導き出したかを示す必要がありました。答えに至るまでの推論は、結果それ自体よりも価値がありました。それが、自己学習型の囲碁AIの限界の1つです。彼らは勝つことができますが、自分の戦略を説明することはできません。
確率的無知
米国大統領選挙の結論に向けてこれを書いているところですが、Nate Silverが作成した予測に関する傍論が出てきています。多くの共和党員は、彼が民主党員の回し者であり、オバマ氏の勝利の確率を85%と予測しているのはでたらめだと主張しています。私の一部は、私が賭けができる算数のできない共和党員をもっと知っていればよかったと思っています。おそらく、より良い願いは、私がより民主党寄りの友人を多く持っているため、世論調査が逆であればよかったということです。実際には、どちらの場合でも、私の知り合いはほとんどが算数ができるため、あまり得をすることはありません。悲しいことに、これは一般的には当てはまりません。この傍論は、ほとんどの人が確率について深く無知であることを示しており、社会一般、特にソフトウェア開発に重要な影響を与えています。