
モノリシックなデータレイクから分散型データメッシュへの移行方法
多くの企業は、大規模なデータ民主化によるビジネスインサイトの提供、そして最終的には自動化されたインテリジェントな意思決定を目指して、次世代データレイクへの投資を行っています。データレイクアーキテクチャに基づくデータプラットフォームには、大規模な導入において約束を果たせない共通の失敗パターンがあります。これらの失敗パターンに対処するために、レイクの中央集権的なパラダイム、またはその前身であるデータウェアハウスからシフトする必要があります。現代の分散型アーキテクチャからヒントを得たパラダイムへのシフトが必要です。ドメインを第一級の懸念事項として考慮し、プラットフォーム思考を適用してセルフサービスデータインフラストラクチャを作成し、データをプロダクトとして扱う必要があります。
2019年5月20日

Zhamakは、Thoughtworksのプリンシパルテクノロジーコンサルタントであり、エンタープライズにおける分散システムアーキテクチャとデジタルプラットフォーム戦略に焦点を当てています。彼女はThoughtworksテクノロジーアドバイザリーボードのメンバーであり、Thoughtworksテクノロジーレーダーの作成に貢献しています。
データドリブンな組織になることは、私が仕事をしている多くの企業の主要な戦略目標の1つです。私のクライアントは、インテリジェントなエンパワーメントになることのメリットを十分に理解しています。データとハイパーパーソナライゼーションに基づいた最高の顧客体験を提供すること、データドリブンな最適化による運用コストと時間の削減、トレンド分析とビジネスインテリジェンスによる従業員の能力向上などです。彼らは、データとインテリジェンスプラットフォームなどのイネーブラーの構築に多額の投資を行ってきました。このようなイネーブラープラットフォームの構築への努力と投資が増加しているにもかかわらず、組織は結果が平凡であることに気づいています。

データメッシュの詳細については、Zhamakは戦略、実装、組織設計に関する詳細を網羅した書籍を執筆しました。
私は、組織がデータドリブンになるための変革において多面的な複雑さに直面していることに同意します。数十年にわたるレガシーシステムからの移行、レガシーカルチャーのデータへの依存への抵抗、そして常に競合するビジネス上の優先事項などです。しかし、皆さんと共有したいのは、多くのデータプラットフォームイニシアチブの失敗の根底にあるアーキテクチャの視点です。大規模な分散型アーキテクチャ構築における過去10年間の教訓をデータの領域に適用してどのように適応できるかを示し、データメッシュと呼ぶ新しいエンタープライズデータアーキテクチャを紹介します。
読み進める前に、現在の従来のデータプラットフォームアーキテクチャのパラダイムが確立した深い仮定とバイアスを一時的に中断してください。モノリシックで中央集権的なデータレイクを超えて、意図的に分散されたデータメッシュアーキテクチャに移行する可能性にオープンになりましょう。データの常に存在する、遍在する、分散された性質を受け入れましょう。
現在のエンタープライズデータプラットフォームアーキテクチャ
それは中央集権型、モノリシックであり、ドメイン非依存、つまりデータレイクです。
私が仕事をしているほとんどすべてのクライアントは、過去の世代の失敗を認めながら、3世代目のデータとインテリジェンスプラットフォームを計画または構築しています。
- 第1世代:独自のエンタープライズデータウェアハウスとビジネスインテリジェンスプラットフォーム。高額な価格で、企業に同等の量の技術的負債を残したソリューション。数千ものメンテナンス不可能なETLジョブ、テーブル、レポートという技術的負債は、少数の専門家しか理解しておらず、ビジネスへのプラスの影響が十分に実現されていませんでした。
- 第2世代:データレイクを万能薬としたビッグデータエコシステム。高度に専門化されたデータエンジニアの中央チームによって運用される複雑なビッグデータエコシステムと長時間実行されるバッチジョブは、せいぜいR&D分析の一部の領域を可能にしたデータレイクモンスターを作成しました。過剰な約束と不十分な実現。
第3世代、現在の世代のデータプラットフォームは、前の世代とほぼ同じですが、(a)Kappaなどのアーキテクチャによるリアルタイムデータ可用性のためのストリーミング、(b)Apache Beamなどのフレームワークによるデータ変換のためのバッチ処理とストリーム処理の統合、(c)ストレージ、データパイプライン実行エンジン、機械学習プラットフォームのためのクラウドベースのマネージドサービスを完全に採用するという現代的なひねりが加えられています。第3世代のデータプラットフォームは、リアルタイムデータ分析、ビッグデータインフラストラクチャ管理コストの削減など、以前の世代のいくつかのギャップに対処していることは明らかです。しかし、以前の世代の失敗につながった多くの根本的な特性を引き継いでいます。
アーキテクチャの失敗パターン
すべての世代のデータプラットフォームが抱える根本的な限界を解き明かすために、そのアーキテクチャとその特性を見てみましょう。この文書では、Spotify、SoundCloud、Apple iTunesなどのインターネットメディアストリーミングビジネスのドメインを例として使用して、いくつかの概念を明確にします。
中央集権型およびモノリシック
3万フィート上空から見ると、データプラットフォームアーキテクチャは下の図1のようになります。その目標は
- ビジネスを運営する運用システムやトランザクションシステム、および企業の知識を拡張する外部データプロバイダーなど、企業のあらゆる方面からデータをインジェストすることです。たとえば、メディアストリーミングビジネスでは、データプラットフォームはさまざまな種類のデータをインジェストする役割を担います。「メディアプレーヤーのパフォーマンス」、「ユーザーがプレーヤーとどのようにやり取りするか」、「再生する曲」、「フォローするアーティスト」、ビジネスがオンボーディングした「レーベルとアーティスト」、「アーティストとの財務取引」、および「顧客の人口統計」情報などの外部の市場調査データなどです。
- さまざまな消費者のニーズに対応できる信頼できるデータにソースデータをクレンジング、エンリッチ、変換することです。私たちの例では、変換の1つは、ユーザーインタラクションのクリックストリームを、ユーザーの詳細でエンリッチされた意味のあるセッションに変換します。これは、ユーザーのジャーニーと行動を集計ビューに再構築しようと試みます。
- さまざまなニーズを持つさまざまなコンシューマーにデータセットを提供することです。これは、データを探求してインサイトを見つけるための分析的な消費から、ビジネスのパフォーマンスをまとめたビジネスインテリジェンスレポート、機械学習ベースの意思決定まで多岐にわたります。メディアストリーミングの例では、プラットフォームはKafkaなどの分散ログインターフェースを介して世界中のメディアプレーヤーに関するリアルタイムのエラーと品質情報を提供したり、特定のアーティストのレコードの再生に関する静的な集計ビューを提供して、アーティストとレーベルへの財務支払いの計算を促進したりできます。
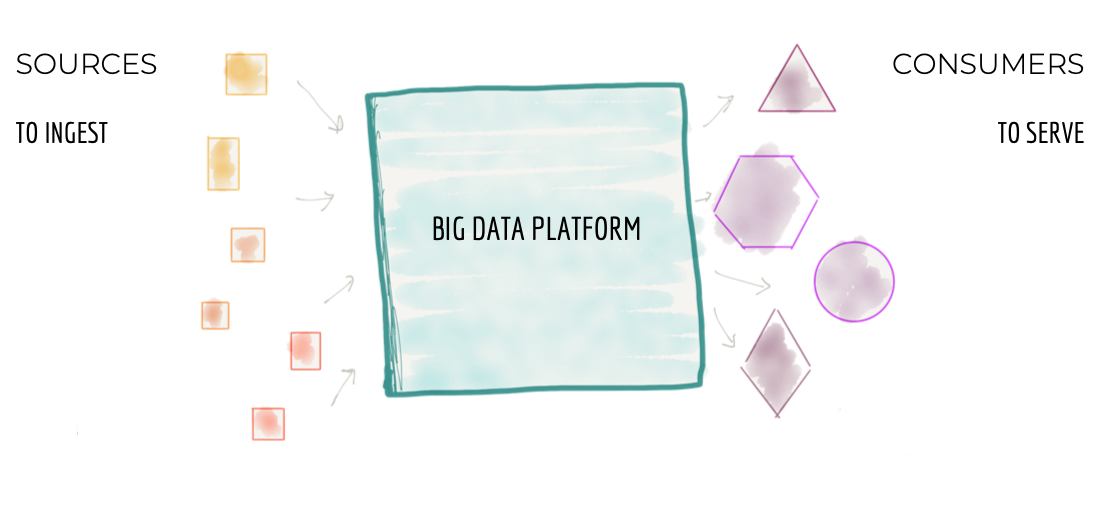
図1:モノリシックデータプラットフォームの3万フィートビュー
モノリシックデータプラットフォームが、論理的に異なるドメインに属するデータをホストして所有するということが一般的な慣例です。たとえば、「再生イベント」、「売上KPI」、「アーティスト」、「アルバム」、「レーベル」、「オーディオ」、「ポッドキャスト」、「音楽イベント」など、多数の異なるドメインからのデータです。
過去10年間、私たちはドメイン駆動設計とバウンデッドコンテキストを運用システムに成功裏に適用してきましたが、データプラットフォームではドメインの概念を大きく無視してきました。私たちは、ドメイン指向のデータ所有権から、中央集権的なドメイン非依存のデータ所有権に移行しました。私たちは、最大のモノリスであるビッグデータプラットフォームを作成することに誇りを持っています。
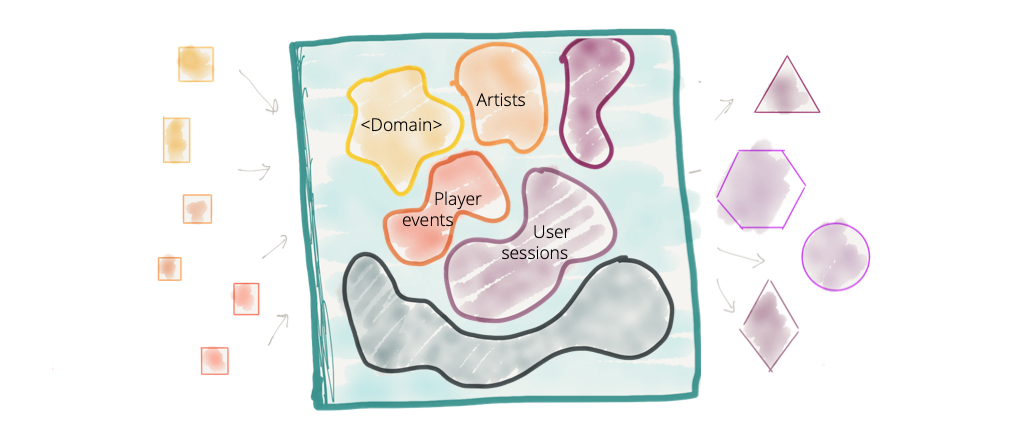
図2:明確なデータドメイン境界がなく、ドメイン指向データの所有権がない中央集権型データプラットフォーム
この中央集権型のモデルは、より単純なドメインと少数の多様な消費事例を持つ組織では機能しますが、豊富なドメイン、多数のソース、多様なコンシューマーを持つ企業では失敗します。
中央集権的なデータプラットフォームのアーキテクチャと組織構造には、その失敗につながる2つの圧力ポイントがあります。
- 遍在的なデータとソースの増加:より多くのデータが遍在的に利用可能になるにつれて、それをすべて消費し、1つの場所で1つのプラットフォームの制御下に調和させる能力は低下します。「顧客情報」のドメインだけでも、組織の内外に、既存の顧客と潜在的な顧客に関する情報を提供するソースが増えています。さまざまなソースから価値を得るために、データを1か所にインジェストして保存する必要があるという仮定は、データソースの増加に対応する能力を制限することになります。データサイエンティストやアナリストなどのデータユーザーがオーバーヘッドの低いさまざまなデータセットを処理する必要があること、運用システムのデータ使用と分析目的で消費されるデータを分離する必要があることを認識しています。しかし、既存の中央集権的なソリューションは、豊富なドメインと継続的に追加される新しいソースを持つ大企業にとって最適な答えではないと提案します。
- 組織のイノベーションアジェンダとコンシューマーの増加:組織の迅速な実験の必要性は、プラットフォームからのデータ消費のためのユースケースの数を増やします。これは、データの変換(集計、投影、スライス)がイノベーションのテストと学習サイクルを満たすことを意味します。データコンシューマーのニーズを満たすための長い応答時間は、歴史的に組織的な摩擦のポイントであり、現代のデータプラットフォームアーキテクチャでもそうしたままです。
まだ私の解決策を明かしたいわけではありませんが、運用システムの奥深くに隠された、断片化され、サイロ化されたドメイン指向データ(発見、理解、利用が困難なサイロ化されたドメインデータ)を推奨しているわけではないことを明確にしておく必要があります。長年の技術的負債の結果として生まれた、複数の断片化されたデータウェアハウスを推奨しているわけでもありません。これは、業界のリーダーたちが声を上げている懸念事項です。しかし、私は、これらのアクセス不能なデータの偶発的なサイロへの対応策は、すべてのドメインからのデータを所有し、管理する集中化されたチームを持つ集中化されたデータプラットフォームを作成することではないと主張します。これは、上記で学習し、実証したように、組織的にスケールしません。
結合されたパイプラインの分解
従来のデータプラットフォームアーキテクチャの2つ目の失敗モードは、アーキテクチャの分解方法に関連しています。集中化されたデータプラットフォームに1万フィートの高さからズームインすると、取り込み、クレンジング、集計、提供などの機械的な機能を中心としたアーキテクチャの分解が見られます。組織のアーキテクトと技術リーダーは、プラットフォームの成長に応じてアーキテクチャを分解します。前のセクションで説明したように、新しいソースのオンボーディングや新しいコンシューマーへの対応には、プラットフォームの成長が必要です。アーキテクトは、システムをアーキテクチャの量子に分割することでシステムをスケールする必要があります。Building Evolutionary Architecturesで説明されているように、アーキテクチャの量子とは、高い機能的凝集性を持つ独立して展開可能なコンポーネントであり、システムが適切に機能するために必要なすべての構造要素が含まれています。システムをアーキテクチャの量子に分割することの動機は、それぞれがアーキテクチャの量子を構築および運用できる独立したチームを作成することです。これらのチーム間で作業を並列化して、より高い運用上のスケーラビリティと速度を実現します。
以前の世代のデータプラットフォームアーキテクチャの影響を考えると、アーキテクトはデータプラットフォームをデータ処理ステージのパイプラインに分解します。非常に高いレベルでは、データ処理の技術的な実装を中心とした機能的凝集性を実装するパイプラインです。つまり、取り込み、準備、集計、提供などの機能です。
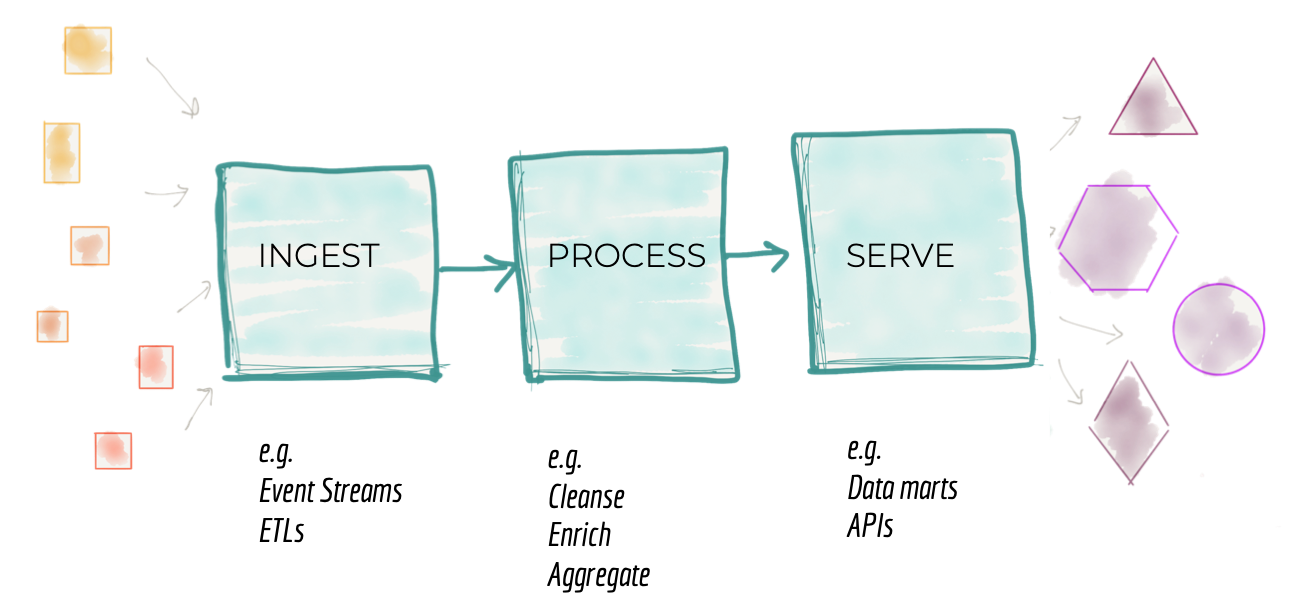
図3:データプラットフォームのアーキテクチャ分解
このモデルは、チームをパイプラインの異なるステージに割り当てることで、ある程度のスケールを提供しますが、機能の提供速度を低下させる固有の制限があります。独立した機能や価値を提供するには、パイプラインのステージ間で高い結合性が存在します。これは、変化の軸に直交して分解されています。
メディアストリーミングの例を見てみましょう。インターネットメディアストリーミングプラットフォームは、提供するメディアの種類を中心とした強力なドメイン構造を持っています。多くの場合、「曲」や「アルバム」からサービスを開始し、その後「音楽イベント」、「ポッドキャスト」、「ラジオ番組」、「映画」などに拡張します。「ポッドキャスト再生率」の可視化など、単一の新しい機能を有効にするには、パイプラインのすべてのコンポーネントを変更する必要があります。チームは、ポッドキャスト再生率を表示するための新しい取り込みサービス、新しいクレンジングと準備、および集計を導入する必要があります。これには、異なるコンポーネントの実装と、チーム間のリリース管理全体にわたる同期が必要です。多くのデータプラットフォームは、新しいソースの追加や既存のソースの変更を容易にするなど、拡張に対応できる汎用的で構成ベースの取り込みサービスを提供します。しかし、これは、新しいデータセットの導入に関するエンドツーエンドの依存関係管理を消費者の視点から排除するものではありません。表面的には、パイプラインアーキテクチャはパイプラインステージのアーキテクチャの量子を実現したように見えるかもしれませんが、実際には、モノリシックプラットフォームである全体パイプラインが、新しい機能に対応するために変更する必要がある最小単位です。つまり、新しいデータセットのロックを解除し、新規または既存の消費に使用できるようにすることです。これは、新しいコンシューマーやデータソースに対応して、より高い速度とスケールを実現する能力を制限します。
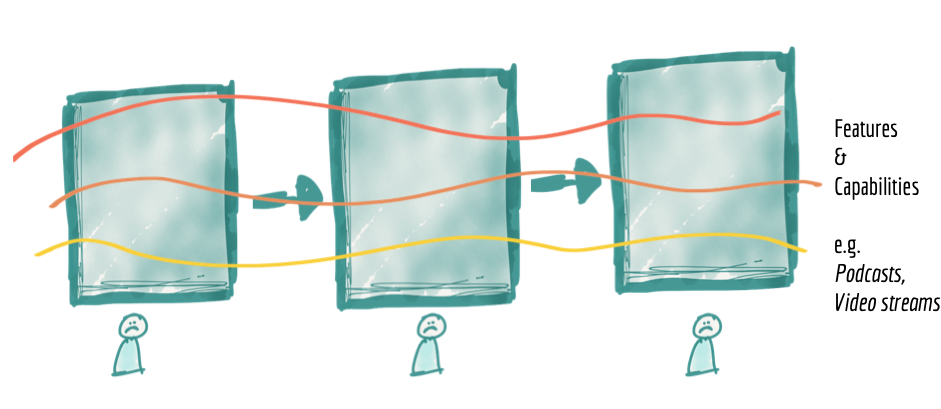
図4:新しい機能の導入または拡張時に、アーキテクチャの分解は変化の軸に直交しており、結合と配信速度の低下につながります。
サイロ化され、高度に専門化された所有権
今日のデータプラットフォームの3つ目の失敗モードは、プラットフォームを構築および所有するチームの構造に関連しています。データプラットフォームを構築および運用する人々の生活を十分に観察すると、組織の運用ユニット(データの発生源またはデータが使用され、行動や意思決定に役立てられる場所)から分離された、高度に専門化されたデータエンジニアのグループが見られます。データプラットフォームエンジニアは、組織的にサイロ化されているだけでなく、ビッグデータツールの技術的専門知識に基づいてチームに分割され、ビジネスやドメインに関する知識が不足していることがよくあります。
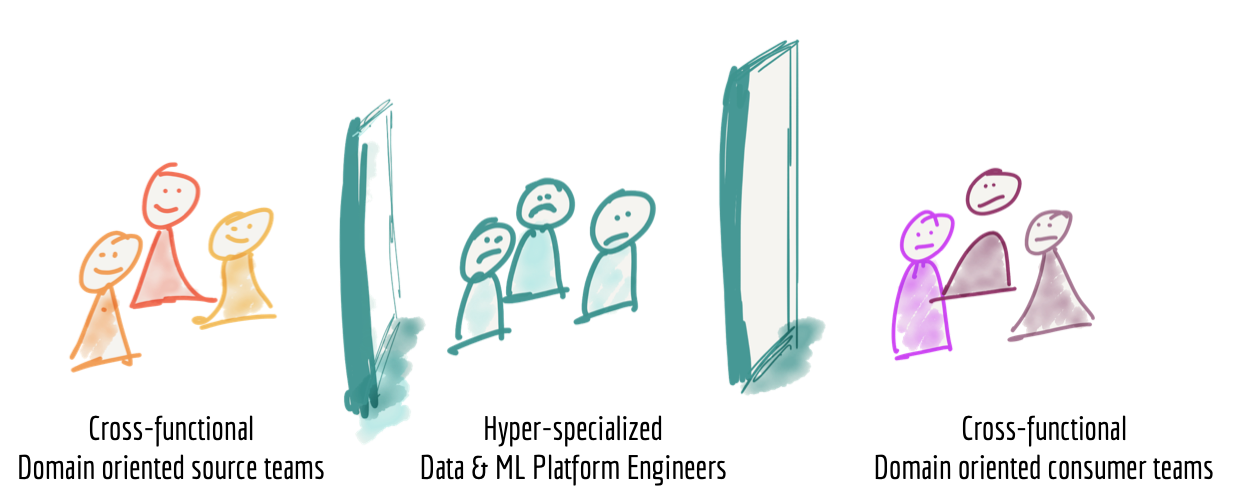
図5:サイロ化された高度に専門化されたデータプラットフォームチーム
私は、データプラットフォームエンジニアの生活を羨ましく思いません。彼らは、意味のある、真実で正確なデータを提供するインセンティブのないチームからデータを取り込む必要があります。彼らは、データを生成するソースドメインをほとんど理解しておらず、チームにドメインの専門知識が不足しています。彼らは、データの適用と消費ドメインの専門家へのアクセスを明確に理解せずに、運用上または分析上の様々なニーズに対してデータを提供する必要があります。
たとえば、メディアストリーミングドメインでは、ソース側には、ユーザーが提供する特定の機能とのインタラクションに関するシグナル(例:「曲再生イベント」、「購入イベント」、「オーディオ品質の再生」など)を提供するクロスファンクショナルな「メディアプレーヤー」チームがあり、もう一方の端には、「曲推薦」チーム、「営業チーム」(営業KPIの報告)、「アーティスト支払いチーム」(再生イベントに基づいてアーティストへの支払い計算)など、コンシューマーのクロスファンクショナルなチームがいます。悲しいことに、その間に、膨大な努力で、すべてのソースと消費に適したデータを提供するデータプラットフォームチームが存在します。
実際には、接続されていないソースチーム、データプラットフォームチームのバックログの上位に位置しようと競い合うフラストレーションを感じているコンシューマー、そして過剰に負担がかかっているデータプラットフォームチームが存在します。
私たちは、スケールせず、データドリブンな組織の作成という約束された価値を提供しないアーキテクチャと組織構造を作成しました。
次世代エンタープライズデータプラットフォームアーキテクチャ
それは、分散型データメッシュによるユビキタスデータを採用しています。
では、上記で説明した失敗モードと特性に対する答えは何でしょうか?私の意見では、パラダイムシフトが必要です。大規模な最新の分散型アーキテクチャの構築に役立ってきた技術の交差点におけるパラダイムシフトです。テクノロジー業界全体が加速したペースで採用し、成功した結果を生み出してきた技術です。
次のエンタープライズデータプラットフォームアーキテクチャは、分散型ドメイン駆動アーキテクチャ、セルフサービスプラットフォーム設計、データを含むプロダクト思考の融合にあると提案します。

図6:コンバージェンス:次のデータプラットフォームを構築するためのパラダイムシフト
これは1文の中に多くのバズワードが含まれているように聞こえるかもしれませんが、これらの技術のそれぞれは、運用システムの技術的基盤の近代化に具体的かつ非常に肯定的な影響を与えています。これらの各分野をデータの世界にどのように適用して、長年のレガシーデータウェアハウスアーキテクチャから引き継がれた現在のパラダイムから脱却できるかを詳しく見ていきましょう。
データと分散型ドメイン駆動アーキテクチャの融合
ドメイン指向のデータ分解と所有権
Eric Evansの著書Domain-Driven Designは、現代のアーキテクチャ思考、そして結果として組織モデリングに大きな影響を与えました。ビジネスドメイン機能を中心とした分散型サービスにシステムを分解することで、マイクロサービスアーキテクチャに影響を与えました。チームがどのように形成されるかを根本的に変え、チームがドメイン機能を独立して自律的に所有できるようにしました。
運用機能の実装においてドメイン指向の分解と所有権を採用してきたにもかかわらず、データに関してはビジネスドメインの概念を無視してきたのは奇妙です。データプラットフォームアーキテクチャにおけるDDDの最も近い適用は、ソース運用システムがビジネスドメインイベントを発行し、モノリシックデータプラットフォームがそれらをインジェストすることです。しかし、インジェストの時点を超えると、ドメインと、異なるチームによるドメインデータの所有権の概念は失われます。
ドメイン境界コンテキストは、データセットの所有権を設計するための驚くほど強力なツールです。Ben StopfordのData Dichotomyの記事では、ストリームを通じてドメインデータセットを共有するという概念を詳しく説明しています。
モノリシックデータプラットフォームを分散化するには、データ、その場所、所有権について考える方法を逆転させる必要があります。ドメインから中央で所有されるデータレイクまたはプラットフォームにデータを流すのではなく、ドメインは、簡単に消費できる方法でドメインデータセットをホストして提供する必要があります。
私たちの例では、メディアプレーヤーから何らかの集中化された場所にデータを流し込み、集中化されたチームが受け取ることを想像するのではなく、プレーヤードメインが自分のデータセットを所有し、ダウンストリームの任意のチームが任意の目的でアクセスできるようにすることを想像してみましょう。データセットが実際に存在する物理的な場所と、それらがどのように流れるかは、「プレーヤードメイン」の技術的な実装です。物理的なストレージは、Amazon S3バケットなどの集中化されたインフラストラクチャである可能性がありますが、プレーヤーデータセットのコンテンツと所有権は、それらを生成するドメインに残ります。同様に、私たちの例では、「推奨事項」ドメインは、グラフデータベースなど、そのアプリケーションに適した形式でデータセットを作成し、プレーヤーデータセットを消費します。「新しいアーティストの発見ドメイン」など、「推奨事項ドメイン」のグラフデータセットが有用だと考える他のドメインがある場合、それらはそれをプルしてアクセスすることを選択できます。
これは、時系列の再生イベントを関連アーティストのグラフに変換するなど、特定のドメインに適した形状に変換する際に、異なるドメインでデータを複製する必要があることを意味します。
これには、従来はETLを介して、最近ではイベントストリームを介して行われてきたプッシュとインジェストから、すべてのドメインにわたるサービスとプルモデルへの思考の転換が必要です。
ドメイン指向データプラットフォームにおけるアーキテクチャの量子は、パイプラインステージではなくドメインです。
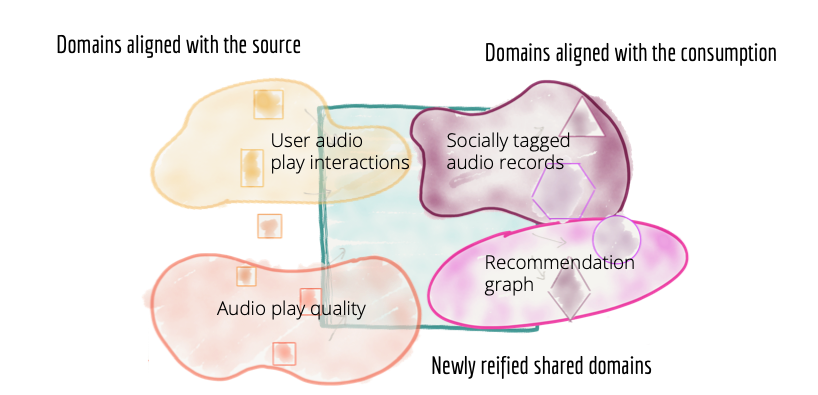
図7:ドメインに基づいてデータの所有権を持つアーキテクチャとチームの分解-ソース、コンシューマー、および新しく作成された共有ドメイン
ソース指向のドメインデータ
一部のドメインは、データの発生源であるソースと自然に整合します。 *ソースドメインデータセット* は、*ビジネスの事実と現実* を表します。 *ソースドメインデータセット* は、その起源となる運用システム(*現実のシステム*)が生成するデータに非常に密接にマッピングされたデータを捕捉します。私たちの例では、「ユーザーがサービスとどのようにやり取りしているか」や「ラベルのオンボーディングプロセス」などのビジネスの事実は、「ユーザークリックストリーム」、「オーディオ再生品質ストリーム」、「オンボードされたラベル」などのドメインデータセットの作成につながります。これらの事実は、発生源に位置する運用システムによって最もよく知られ、生成されます。例えば、メディアプレーヤーシステムは「ユーザークリックストリーム」について最もよく知っています。
成熟した理想的な状況では、運用システムとそのチームまたは組織単位は、ビジネス機能を提供する責任だけでなく、*ビジネスドメインの真実* をソースドメインデータセットとして提供する責任も負います。エンタープライズ規模では、ドメイン概念とソースシステム間に常に一対一の対応関係があるわけではありません。ドメインに属するデータの一部を提供できるシステムは、レガシーシステムと変更しやすいシステムの両方を含め、多くの場合存在します。したがって、最終的には、まとまりのあるドメインに整合したデータセットに集約する必要がある多くの*ソースに整合したデータセット*、つまり*現実データセット*が存在する可能性があります。
ビジネスの事実は、ビジネスの[ドメインイベント](https://martinfowler.dokyumento.jp/eaaDev/DomainEvent.html)として最も適切に提示され、承認されたコンシューマーがアクセスできるタイムスタンプ付きイベントの分散ログとして保存および提供できます。
タイムドイベントに加えて、ソースデータドメインは、そのドメインの変化間隔を反映した時間間隔にわたって集約された、ソースドメインデータセットの容易に消費可能な履歴スナップショットも提供する必要があります。例えば、「オンボードされたラベル」ソースドメイン(ストリーミングビジネスに音楽を提供するアーティストのラベルを示す)では、ラベルのオンボーディングプロセスを通じて生成されたイベントに加えて、月次ベースでオンボードされたラベルを集計するビューを提供することが妥当です。
ソースに整合したドメインデータセットは、内部ソースシステムのデータセットとは分離する必要があることに注意してください。ドメインデータセットの性質は、運用システムが業務を行うために使用する内部データとは大きく異なります。それらははるかに大きなボリュームを持ち、不変のタイムドファクトを表し、システムよりも変更頻度が低くなります。このため、実際の基盤となるストレージはビッグデータに適しており、既存の運用データベースとは別に存在する必要があります。セクション[データとセルフサービスプラットフォーム設計の融合](data-monolith-to-mesh.html#DataAndSelf-servePlatformDesignConvergence)では、ビッグデータストレージとサービスインフラストラクチャを作成する方法について説明します。
ソースドメインデータセットは最も基本的なデータセットであり、ビジネスの事実は頻繁に変更されないため、変更頻度も低くなります。これらのドメインデータセットは永続的にキャプチャされ、利用可能になることが期待されています。そのため、組織がその*データドリブン*および*インテリジェンス*サービスを進化させるにつれて、常にビジネスの事実に戻り、新しい集約または予測を作成できます。
ソースドメインデータセットは、作成時点での*生データ*を密接に反映しており、特定のコンシューマーに合わせて調整またはモデル化されていないことに注意してください。
分散型パイプラインをドメイン内部実装として
データセットの所有権は中央プラットフォームからドメインに委任されますが、データのクレンジング、準備、集約、提供の必要性、データパイプラインの使用は残ります。このアーキテクチャでは、データパイプラインは単なる内部的な複雑さとデータドメインの実装であり、ドメイン内で内部的に処理されます。その結果、データパイプラインの各ステージが各ドメインに分散されるようになります。
例えば、ソースドメインには、他のドメインがクレンジングを複製することなく消費できるように、ドメインイベントのクレンジング、重複除去、エンリッチメントを含める必要があります。各ドメインデータセットは、提供するデータの品質(タイムリー性、エラー率など)について*サービスレベル目標*を設定する必要があります。例えば、オーディオ「プレイクリックストリーム」を提供するメディアプレーヤー・ドメインには、組織のイベントエンコーディング標準に準拠した、重複除去されたほぼリアルタイムの「オーディオ再生クリックイベント」ストリームを提供するドメイン内のクレンジングと標準化データパイプラインを含めることができます。
同様に、集中型パイプラインの集約ステージは、消費ドメインの実装詳細に移行します。
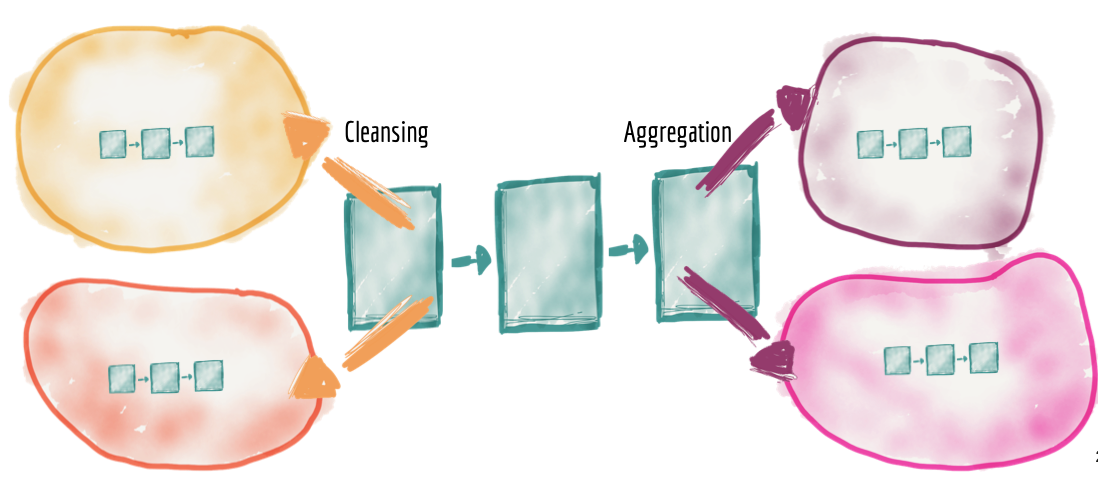
図8:パイプラインをドメインに2次的な懸念事項およびドメインの内部実装詳細として分散する
このモデルでは、各ドメインで独自のデータ処理パイプラインの実装、テクノロジースタック、ツールを作成することに重複した労力が生じる可能性があると主張する人もいるかもしれません。[データとプラットフォームの思考の融合:セルフサービス共有データインフラストラクチャ・アズ・ア・プラットフォーム](data-monolith-to-mesh.html#DataAndSelf-servePlatformDesignConvergence)について説明する際に、この懸念事項にすぐに対応します。
データとプロダクト思考の融合
データの所有権とデータパイプラインの実装をビジネスドメインに分散することは、分散型データセットのアクセシビリティ、ユーザビリティ、調和に関して重要な懸念事項を引き起こします。ここで、*プロダクト思考*とデータ資産の所有権の適用に関する学習が役立ちます。
ドメインデータをプロダクトとして
過去10年間で、運用ドメインは、組織の他の部分に提供する機能に[プロダクト思考](https://martinfowler.dokyumento.jp/articles/products-over-projects.html)を組み込んできました。ドメインチームは、これらの機能を組織内の他の開発者へのAPIとして、より高度な価値と機能を作成するための構成要素として提供します。チームは、検出可能で理解しやすいAPIドキュメント、APIテストサンドボックス、綿密に追跡された品質と採用KPIを含む、ドメインAPIの最高の開発者エクスペリエンスの作成に努めています。
分散型データプラットフォームを成功させるには、ドメインデータチームが同様の厳格さでプロダクト思考を適用し、データ資産を製品として、組織内の他のデータサイエンティスト、ML、データエンジニアを顧客として考える必要があります。
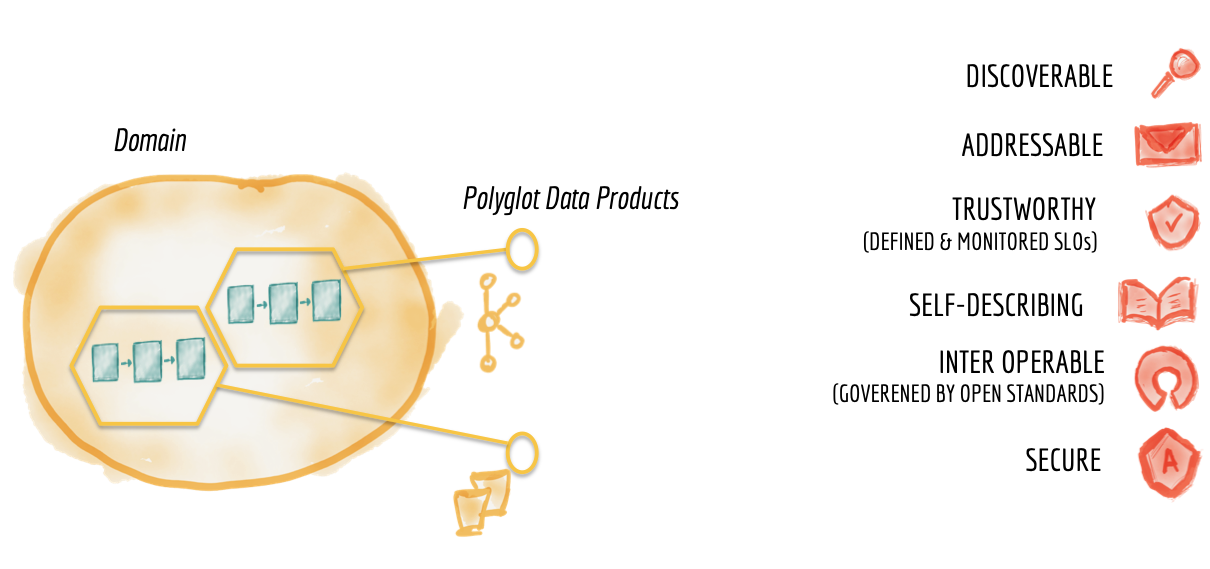
図9:製品としてのドメインデータセットの特徴
インターネットメディアストリーミングビジネスの例を考えてみましょう。その重要なドメインの1つは「再生イベント」であり、誰が、いつ、どこでどの曲を再生したかです。この重要なドメインには、組織内にさまざまなコンシューマーが存在します。例えば、ユーザーエクスペリエンスと潜在的なエラーに関心のあるほぼリアルタイムのコンシューマーは、顧客エクスペリエンスの低下や着信顧客サポートコールが発生した場合に、エラーを迅速に回復するために対応できます。また、日次または月次の曲再生イベント集計の履歴スナップショットを好むコンシューマーもいくつかいます。
この場合、「再生された曲」ドメインは、組織の残りの部分に2つの異なるデータセットを製品として提供します。イベントストリームで公開されるリアルタイム再生イベントと、オブジェクトストアでシリアル化されたファイルとして公開される集約再生イベントです。
この場合、ドメインデータ製品である、あらゆる技術製品の重要な品質は、コンシューマー、つまりデータエンジニア、MLエンジニア、またはデータサイエンティストを喜ばせることです。コンシューマーにとって最高のユーザーエクスペリエンスを提供するために、ドメインデータ製品は次の基本的な品質を備えている必要があります。
検出可能
データ製品は容易に検出可能でなければなりません。一般的な実装としては、所有者、発生源、系統、サンプルデータセットなどのメタ情報を含む、利用可能なすべてのデータ製品のレジストリ、データカタログを持つことが挙げられます。この集中型の検出可能性サービスにより、組織内のデータコンシューマー、エンジニア、科学者は、関心のあるデータセットを簡単に検索できます。各ドメインデータ製品は、容易な検出のためにこの集中型データカタログに自身を登録する必要があります。
ここでの視点のシフトは、単一の*プラットフォームがデータを取り込み、所有する*ことから、各*ドメインが検出可能な方法でデータを製品として提供する*ことにあります。
アドレス指定可能
データ製品は、一度検出されると、ユーザーがプログラムによってアクセスするのに役立つグローバルな規則に従った一意のアドレスを持つ必要があります。組織は、基盤となるストレージとデータの形式に応じて、データに異なる命名規則を採用する場合があります。使いやすさを目標として考えると、分散型アーキテクチャでは、共通の規則を開発する必要があります。異なるドメインは、データセットを異なる形式で保存および提供する場合があります。イベントはKafkaトピックなどのストリームを通じて保存およびアクセスできる可能性があり、コラムナーデータセットはCSVファイルを使用する可能性があり、またはシリアル化された[Parquet](https://parquet.apache.org/)ファイルのAWS S3バケットを使用する可能性があります。多言語環境でのデータセットのアドレス指定に関する標準は、情報の検索とアクセス時の摩擦を軽減します。
信頼できる、真実性のある
誰も信頼できない製品は使いません。従来のデータプラットフォームでは、エラーが含まれていたり、ビジネスの真実を反映していなかったり、単に信頼できないデータを抽出およびオンボードすることが許容されていました。これは、集中型データパイプラインの取り組みの大部分が、取り込み後のデータクレンジングに集中している場所です。
根本的なシフトには、データ製品の所有者が、データの真実性、および発生したイベントの現実をどの程度反映しているか、または生成されたインサイトの真実性の確率の高さを示す、許容可能な[サービスレベル目標](https://en.wikipedia.org/wiki/Service-level_objective)を提供することが必要です。データ製品の作成時点でデータクレンジングと自動化されたデータ整合性テストを適用することは、許容可能なレベルの品質を提供するための技術の1つです。[データの系統とデータの出自](https://en.wikipedia.org/wiki/Data_lineage)を各データ製品に関連付けられたメタデータとして提供することで、コンシューマーはデータ製品とその特定のニーズへの適合性について、さらに信頼を高めることができます。
データ整合性(品質)指標の目標値または範囲は、ドメインデータ製品によって異なります。「プレイイベント」ドメインでは、リアルタイムに近い精度が低く、欠落または重複イベントを含むデータ製品と、遅延が長くイベント精度が高いデータ製品の2つの異なるデータ製品を提供する場合があります。各データ製品は、SLOのセットとして、その整合性と真実性の目標レベルを定義し、保証します。
自己記述的なセマンティクスと構文
高品質の製品は、ユーザーによる特別な操作を必要としません。独立して発見、理解、利用できます。データエンジニアやデータサイエンティストが容易に利用できる製品としてのデータセットの構築には、データのセマンティクスと構文を明確に記述する必要があり、理想的にはサンプルデータセットを例として添付します。データスキーマは、セルフサービスのデータ資産を提供するための出発点です。
相互運用可能であり、グローバル標準によって管理される
分散型ドメインデータアーキテクチャにおける主要な懸念事項の1つは、ドメイン間でデータを関連付ける能力と、それらを素晴らしい洞察力のある方法で統合する能力(結合、フィルタリング、集計など)です。ドメイン間での効果的なデータ関連付けの鍵は、特定の標準と調整ルールに従うことです。このような標準化はグローバルガバナンスに属し、多様なドメインデータセット間の相互運用性を可能にする必要があります。このような標準化の取り組みの一般的な懸念事項としては、フィールドタイプのフォーマット、異なるドメイン間での多義語の識別、データセットのアドレス規則、共通のメタデータフィールド、CloudEventsなどのイベント形式などがあります。
たとえば、メディアストリーミングビジネスでは、「アーティスト」は異なるドメインに表示され、各ドメインで異なる属性と識別子を持つ場合があります。「プレイイベントストリーム」ドメインは、「アーティスト支払い」ドメイン(請求書と支払いを処理する)とは異なる方法でアーティストを認識する場合があります。ただし、異なるドメインデータ製品にわたるアーティストに関するデータを関連付けるには、多義語としてのアーティストの識別方法について合意する必要があります。1つのアプローチは、「アーティスト」をフェデレーテッドエンティティと、フェデレーテッドアイデンティティの管理方法と同様に、「アーティスト」の一意のグローバルフェデレーテッドエンティティ識別子で考慮することです。
グローバルに管理される相互運用性と通信の標準化は、分散システム構築の基盤となる柱の1つです。
安全であり、グローバルアクセス制御によって管理される
アーキテクチャが中央集権型であるかどうかにかかわらず、製品データセットへの安全なアクセスは必須です。分散型ドメイン指向データ製品の世界では、アクセス制御は、各ドメインデータ製品に対してより細かい粒度で適用されます。運用ドメインと同様に、アクセス制御ポリシーは中央で定義できますが、個々のデータセット製品へのアクセス時に適用されます。エンタープライズアイデンティティ管理システム(SSO)とロールベースのアクセス制御ポリシー定義は、製品データセットのアクセス制御を実装するための便利な方法です。
セクションデータとセルフサービスプラットフォーム設計の融合では、各データ製品に対して上記の機能を容易かつ自動的に実現する共有インフラストラクチャについて説明しています。
ドメインデータのクロスファンクショナルチーム
製品としてデータを提供するドメインは、(a) データ製品オーナーと(b) データエンジニアという新しいスキルセットで強化する必要があります。
データ製品オーナーは、データ製品のビジョンとロードマップに関する意思決定を行い、消費者の満足度を懸念し、ドメインが所有および生成するデータの品質と豊かさを継続的に測定および改善します。彼女は、ドメインデータセットのライフサイクル(データとスキーマの変更、改訂、廃止のタイミング)を担当します。彼女は、ドメインデータ消費者の競合するニーズのバランスを取ります。
データ製品オーナーは、データ製品の成功基準とビジネスに合わせた主要業績評価指標(KPI)を定義する必要があります。たとえば、データ製品の消費者がデータ製品を発見して正常に利用するまでのリードタイムは、測定可能な成功基準です。
ドメインの内部データパイプラインを構築および運用するには、チームにデータエンジニアを含める必要があります。このようなクロスファンクショナルチームの素晴らしい副次的効果は、さまざまなスキルの相互受粉です。私の現在の業界における観察では、一部のデータエンジニアは、仕事の道具の使用方法に習熟している一方で、データ資産の構築に関しては、継続的デリバリーや自動テストなどのソフトウェアエンジニアリングの標準的な慣行を欠いていることがわかります。同様に、運用システムを構築しているソフトウェアエンジニアは、多くの場合、データエンジニアリングツールセットの使用方法を経験していません。スキルセットのサイロを解消することで、組織が利用できるデータエンジニアリングのスキルセットのプールが拡大し、深化します。DevOpsムーブメントと、SREなどの新しいタイプのエンジニアの誕生でも、同じクロススキルの受粉を観察しています。
データは、あらゆるソフトウェアエコシステムの基盤となる要素として扱われる必要があります。そのため、ソフトウェアエンジニアとソフトウェアジェネラリストは、データ製品開発の経験と知識をツールベルトに追加する必要があります。同様に、インフラストラクチャエンジニアは、データインフラストラクチャの管理に関する知識と経験を追加する必要があります。組織は、ジェネラリストからデータエンジニアへのキャリア開発パスを提供する必要があります。データエンジニアリングスキルの不足により、セクションサイロ化された、そして高度に専門化された所有権で説明されているように、中央集権的なデータエンジニアリングチームを形成する局所最適化が行われています。

図10:明示的なデータ製品所有権を持つクロスファンクショナルドメインデータチーム
データとセルフサービスプラットフォーム設計の融合
データの所有権をドメインに分散することの主な懸念事項の1つは、各ドメインでデータパイプラインのテクノロジースタックとインフラストラクチャを運用するために必要な重複した努力とスキルです。幸いなことに、共通のインフラストラクチャをプラットフォームとして構築することは、よく理解され、解決された問題です。ただし、データエコシステムではツールとテクニックがそれほど成熟していないことを認めなければなりません。
ドメイン非依存のインフラストラクチャ機能をデータインフラストラクチャプラットフォームに収集して抽出することで、データパイプラインエンジン、ストレージ、ストリーミングインフラストラクチャの設定の努力を重複させる必要がなくなります。データインフラストラクチャチームは、ドメインがデータ製品のキャプチャ、処理、保存、提供に必要なテクノロジーを所有して提供できます。
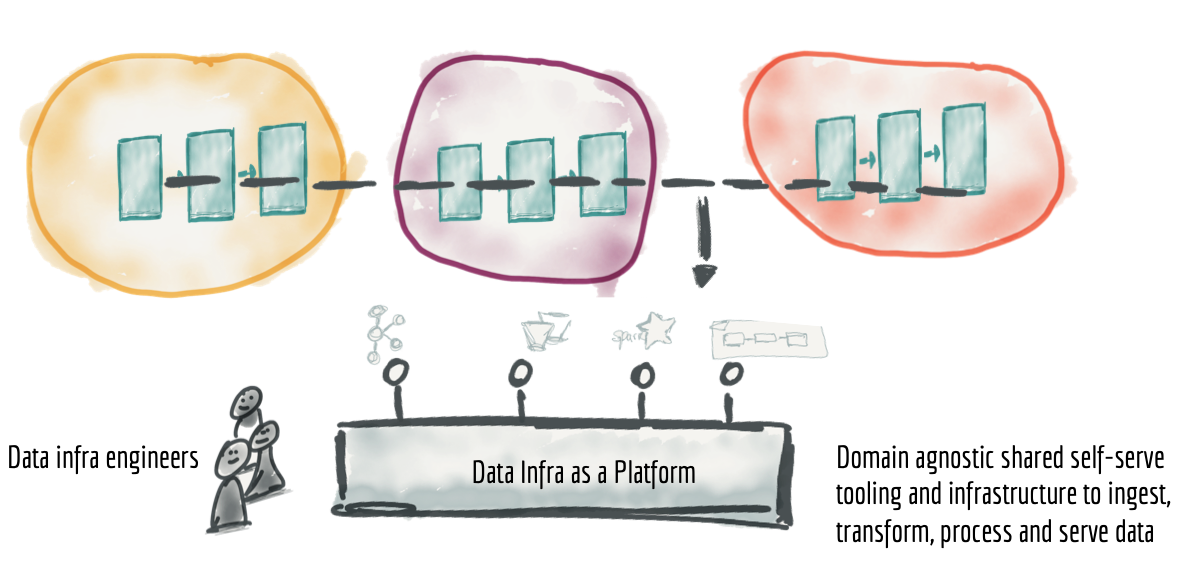
図11:ドメイン非依存のデータパイプラインインフラストラクチャとツールを別個のデータインフラストラクチャとしてプラットフォームに抽出および収集する
データインフラストラクチャ・アズ・ア・プラットフォームを構築する鍵は、(a) ドメイン固有の概念やビジネスロジックを含めず、ドメイン非依存にすること、(b) プラットフォームがすべての基礎となる複雑さを隠蔽し、セルフサービス方式でデータインフラストラクチャコンポーネントを提供することです。セルフサービス型のデータインフラストラクチャ・アズ・ア・プラットフォームがユーザー(ドメインのデータエンジニア)に提供する機能には、長いリストがあります。そのうちのいくつかを以下に示します。
- スケーラブルな多様なビッグデータストレージ
- 静止時と移動時のデータ暗号化
- データ製品のバージョン管理
- データ製品スキーマ
- データ製品の匿名化
- 統一されたデータアクセス制御とロギング
- データパイプラインの実装とオーケストレーション
- データ製品の検出、カタログ登録、公開
- データガバナンスと標準化
- データ製品の系譜
- データ製品の監視/アラート/ログ
- データ製品の品質指標(収集と共有)
- インメモリデータキャッシング
- フェデレーテッドアイデンティティ管理
- コンピューティングとデータの局所性
セルフサービスデータインフラストラクチャの成功基準は、「インフラストラクチャ上の新しいデータ製品を作成するまでのリードタイム」を短縮することです。これにより、セクションドメインデータ・アズ・ア・プロダクトで説明されている「データ製品」の機能を実装するために必要な自動化が行われます。たとえば、構成とスクリプトによるデータ取り込みの自動化、足場を配置するためのデータ製品作成スクリプト、カタログへのデータ製品の自動登録などです。
クラウドインフラストラクチャを基盤として使用すると、データインフラストラクチャへのオンデマンドアクセスを提供するために必要な運用コストと労力が削減されますが、ビジネスのコンテキストで実装する必要があるより高い抽象化が完全に削除されるわけではありません。クラウドプロバイダーに関係なく、データインフラチームが利用できる豊富で常に増加しているデータインフラストラクチャサービスのセットがあります。
データメッシュへのパラダイムシフト
長文になりました。すべてをまとめてみましょう。現在のデータプラットフォームのいくつかの基礎となる特性を見てきました。中央集権型、モノリシック、高度に結合されたパイプラインアーキテクチャで、高度に専門化されたデータエンジニアのサイロによって運用されています。共通のデータインフラストラクチャをプラットフォームとして使用して、データ資産をホスト、準備、提供する独立したクロスファンクショナルチームに埋め込まれたデータエンジニアとデータ製品オーナーを中心とした分散型データ製品として、ユビキタスなデータメッシュの構成要素を紹介しました。
データメッシュプラットフォームは、相互運用性のための集中型ガバナンスと標準化の下で、共有され、調和のとれたセルフサービスデータインフラストラクチャによって実現される、意図的に設計された分散型データアーキテクチャです。アクセスできないデータの断片化されたサイロの風景からは程遠いものであることが明確になったと思います。
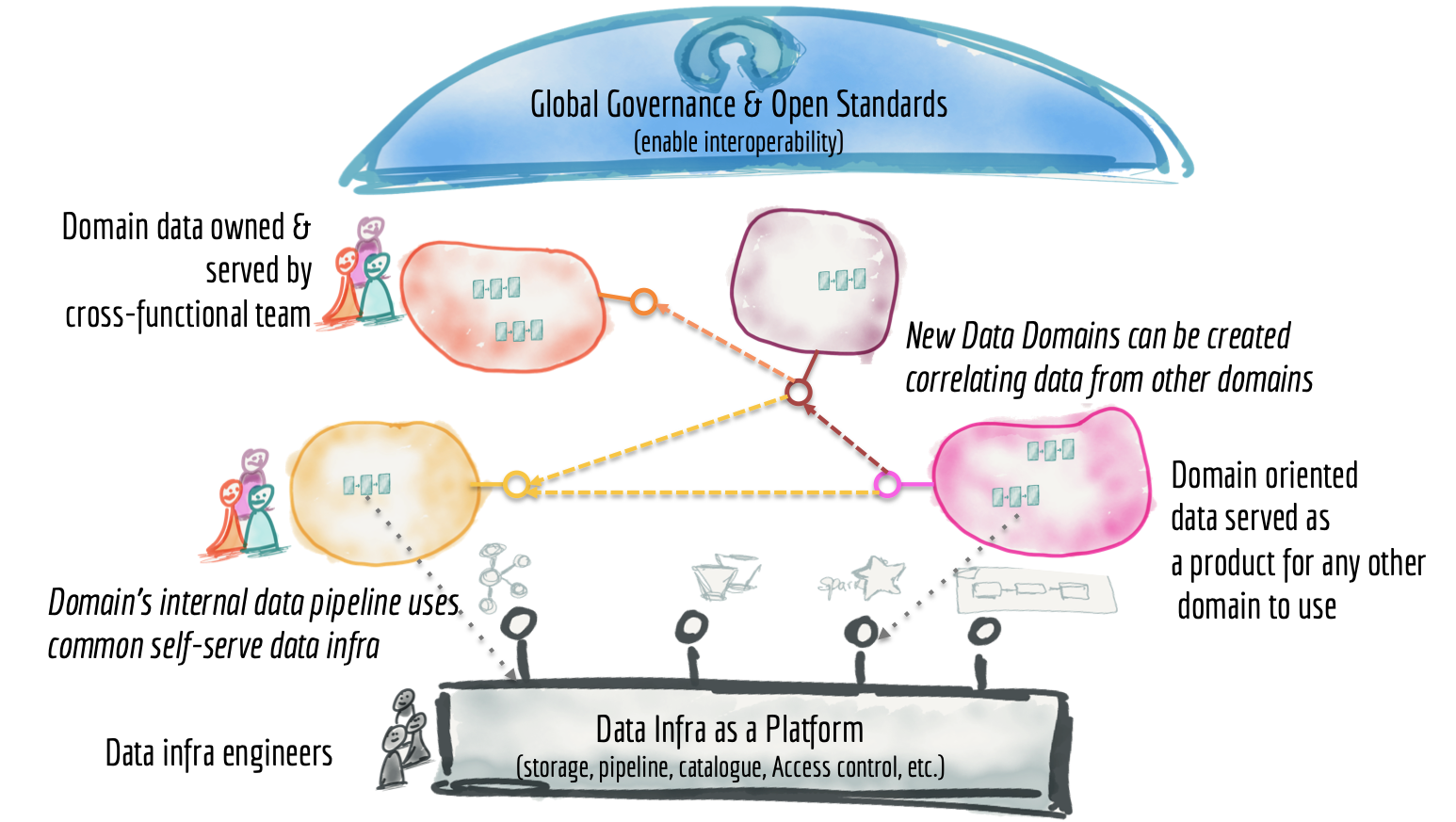
図12:3万フィートからのデータメッシュアーキテクチャ
データレイクまたはデータウェアハウスがこのアーキテクチャにどのように適合するか疑問に思うかもしれません。それらは単にメッシュ上のノードです。元のデータを保持する分散型ログとストレージは、製品としての異なるアドレス指定可能な不変データセットから探索できるため、データレイクは必要なくなる可能性が高いです。ただし、ラベリングなど、さらなる調査のためにデータの元の形式を変更する必要がある場合、そのようなニーズを持つドメインは独自のレイクまたはデータハブを作成する場合があります。
したがって、データレイクはもはや全体アーキテクチャの中心ではありません。探索と分析の使用のために不変のデータを利用可能にするなど、データレイクの原則の一部をソース指向ドメインデータ製品に適用し続けます。データレイクツールは引き続き使用しますが、データ製品の内部実装として、または共有データインフラストラクチャの一部として使用します。
これは実際、すべてが始まった場所に戻ってきます。2010年のJames Dixonは、データレイクを単一ドメインで使用することを意図していましたが、複数のデータドメインは代わりに「ウォーターガーデン」を形成します。
主な変化は、ドメインデータ製品を最優先事項として扱い、データレイクツールとパイプラインを2番目の懸念事項(実装の詳細)として扱うことです。これは、中央集権的なデータレイクから、うまく連携するデータ製品のエコシステムであるデータメッシュへの現在のメンタルモデルを反転させます。
ビジネスレポートと可視化のためのデータウェアハウスにも同じ原則が適用されます。それは単にメッシュ上のノードであり、おそらくメッシュの消費者指向のエッジ上にあります。
クライアントのポケットでデータメッシュのプラクティスが適用されているのを見ていますが、エンタープライズ規模での採用はまだ長い道のりがあることを認めます。今日の私たちが使用しているすべてのツールは、複数のチームによる分散と所有に対応できるため、技術がここでの制限であるとは考えていません。特に、バッチとストリーミングの統合とApache BeamまたはGoogle Cloud Dataflowなどのツールへの移行により、アドレス指定可能な多様なデータセットを簡単に処理できます。
Google Cloud Data Catalogなどのデータカタログプラットフォームは、分散型ドメインデータセットの中央での検出可能性、アクセス制御、ガバナンスを提供します。さまざまなクラウドデータストレージオプションにより、ドメインデータ製品は目的に合った多様なストレージを選択できます。
ニーズは現実のものであり、ツールも準備ができています。既存のビッグデータと真のビッグデータプラットフォームまたはデータレイクのパラダイムは、新しいクラウドベースのツールを使用するだけで過去の失敗を繰り返すだけであることを、組織のエンジニアとリーダーが認識することが重要です。
このパラダイムシフトには、新しい言語を伴う新しいガバナンス原則のセットが必要です。
- 取り込みよりも提供
- 抽出とロードよりも発見と利用
- 中央集権化されたパイプラインによるデータの流通よりもイベントをストリームとして公開
- 中央集権化されたデータプラットフォームよりもデータ製品のエコシステム
巨大なビッグデータモノリスを、調和のとれた、協調的な、分散型のデータメッシュのエコシステムに分解しましょう。
重要な改訂
2019年5月20日: 最終回を公開
2019年5月16日: プロダクト思考に関する回を公開
2019年5月14日: ドメイン駆動アーキテクチャに関する回を公開
2019年5月13日: 現在のエンタープライズデータプラットフォームアーキテクチャに関する回を公開