
機械学習のための継続的デリバリー
機械学習アプリケーションのエンドツーエンドのライフサイクルの自動化
機械学習アプリケーションは私たちの業界で人気が高まっていますが、それらを開発、デプロイ、継続的に改善するプロセスは、ウェブサービスやモバイルアプリケーションなどの従来のソフトウェアと比較してより複雑です。それらは、コード自体、モデル、データの3つの軸で変化します。それらの挙動はしばしば複雑で予測困難であり、テスト、説明、改善が困難です。機械学習のための継続的デリバリー(CD4ML)とは、継続的デリバリーの原則と実践を機械学習アプリケーションに適用する規律です。
2019年9月19日

バイオ
私はThoughtworksのプリンシパルコンサルタントであり、ソフトウェア、データ、インフラストラクチャ、機械学習など、アーキテクチャとエンジニアリングの多くの分野で経験があります。私は「DevOps in Practice: Reliable and Automated Software Delivery」の著者であり、ThoughtworksテクノロジーアドバイザリーボードおよびThoughtworks CTOオフィスのメンバーです。

バイオ
私はThoughtworks Germanyのコンサルタントであり、そこでデータと機械学習の活動をリードしています。影響を与えるスケーラブルなソフトウェア、そしてそのようなソフトウェアを作成するチームの構築を楽しんでいます。特に、MLアプリケーションを効果的に構築するには、データサイエンティストと開発者(私自身を含む)が緊密に協力する必要がある点に魅了されています。

バイオ
私はThoughtworksのプリンシパルコンサルタントであり、インテリジェントエンパワーメントのグローバルリードです。AIと機械学習の最新技術でクライアントとThoughtworksが価値を創造する支援をしています。ニューラルネットワークで博士号を取得した後、20年以上IT業界で働いています。Thoughtworks CTOオフィスのメンバーです。
はじめにおよび定義
2015年にSculleyらが発表した有名なGoogleの論文「Hidden Technical Debt in Machine Learning Systems」では、現実世界の機械学習(ML)システムでは、実際のMLコードで構成されているのはごく一部であることが強調されています。その進化を支える広範な周辺インフラストラクチャとプロセスが存在します。また、そのようなシステムに蓄積される可能性のある多くの技術的負債のソースについても説明されており、その中にはデータ依存関係、モデルの複雑さ、再現性、テスト、監視、外部世界の変化への対応などが含まれています。
同じ懸念の多くは従来のソフトウェアシステムにも存在し、継続的デリバリーは、ソフトウェアを本番環境にリリースするための信頼性が高く再現可能なプロセスを作成するために、自動化、品質、規律をもたらすアプローチでした。
彼らの記念碑的な書籍「Continuous Delivery」で、Jez HumbleとDavid Farleyは述べています。
「継続的デリバリーとは、新しい機能、構成変更、バグ修正、実験など、あらゆる種類の変更を、安全かつ迅速に、持続可能な方法で本番環境またはユーザーの手に届ける能力のことです。」
コードに加えて、MLモデルとそれをトレーニングするために使用されるデータへの変更は、ソフトウェアデリバリープロセスに組み込む必要がある別の種類の変更です(図1)。
{kind=link}

図1:機械学習アプリケーションの変更の3つの軸—データ、モデル、コード—およびそれらが変化するいくつかの理由
これを踏まえ、現実世界の機械学習システムに存在する新しい要素と課題を組み込むために、継続的デリバリーの定義を拡張することができます。このアプローチを「機械学習のための継続的デリバリー(CD4ML)」と呼んでいます。
**機械学習のための継続的デリバリー(CD4ML)**とは、クロスファンクショナルチームがコード、データ、モデルに基づいて機械学習アプリケーションを小規模で安全な増分で作成し、再現可能で、いつでも信頼性高くリリースできる、短い適応サイクルを実現するソフトウェアエンジニアリングアプローチです。
この定義には、すべての基本原則が含まれています。
**ソフトウェアエンジニアリングアプローチ:**チームが高品質のソフトウェアを効率的に作成できるようにします。
**クロスファンクショナルチーム:**データエンジニアリング、データサイエンス、機械学習エンジニアリング、開発、運用、その他の知識領域にわたる、異なるスキルセットとワークフローを持つ専門家が、各チームメンバーのスキルと強みを強調した協調的な方法で協力して作業します。
**コード、データ、機械学習モデルに基づいたソフトウェアの作成:**MLソフトウェア作成プロセスのすべてのアーティファクトには、適切にバージョン管理され管理される必要がある異なるツールとワークフローが必要です。
**小規模で安全な増分:**ソフトウェアアーティファクトのリリースは小さな増分に分割され、結果のばらつきのレベルに関する可視性と制御が可能になり、プロセスに安全性が追加されます。
**再現可能で信頼性の高いソフトウェアリリース:**モデルの出力は非決定論的で再現が困難な場合がありますが、MLソフトウェアを本番環境にリリースするプロセスは信頼性が高く再現可能であり、可能な限り自動化を活用しています。
**いつでもソフトウェアをリリース可能:**MLソフトウェアはいつでも本番環境に提供できることが重要です。組織が常にソフトウェアを提供したいわけではない場合でも、常にリリース可能な状態にある必要があります。これにより、いつリリースするかという決定は技術的な決定ではなく、ビジネス上の決定になります。
**短い適応サイクル:**短いサイクルとは、開発サイクルが数週間、数か月、または数年ではなく、数日または数時間であることを意味します。これを達成するには、品質を組み込んだプロセスの自動化が不可欠です。これにより、本番環境での動作から学習することでモデルを適応させることができるフィードバックループが作成されます。
この記事では、CD4MLを実装する際に重要であると判断した技術的な構成要素について、サンプルMLアプリケーションを使用して概念を説明し、さまざまなツールを組み合わせてエンドツーエンドのプロセス全体を実装する方法を示します。適切な場合は、選択したツール以外の代替ツールについても強調します。また、業界全体で実践が成熟するにつれて、さらなる開発と研究の分野についても議論します。
売上予測のための機械学習アプリケーション
私たちは2016年から機械学習システムへの継続的デリバリーの適用方法について考え始め、公開し、発表しました。AutoScoutと共同で構築したクライアントプロジェクトの事例研究で、プラットフォームに公開された車の価格を予測するものです。
ただし、実際のクライアントコードの例を使用することは許可されていないため、CD4MLの実装を示すために、公開されている問題とデータセットに基づいてサンプルMLアプリケーションを構築することにしました。このアプリケーションは、多くの小売業者が直面する一般的な予測問題、つまり過去のデータに基づいて、今後特定の製品がどれだけ販売されるかを予測しようとする問題を解決します。エクアドルの大手食料品小売業者であるCorporación Favoritaが投稿したKaggleの問題を簡略化して解決策を構築しました。私たちの目標は最高の予測を見つけること(これはデータサイエンティストの方が得意です)ではなく、CD4MLを実装する方法を示すことであるため、データセットを結合して簡素化しました。
教師あり学習アルゴリズムと人気のscikit-learn Pythonライブラリを使用して、ラベル付けされた入力データを使用して予測モデルをトレーニングし、そのモデルをシンプルなウェブアプリケーションに統合し、クラウド内の本番環境にデプロイします。図2は、上位レベルのプロセスを示しています。
{kind=link}
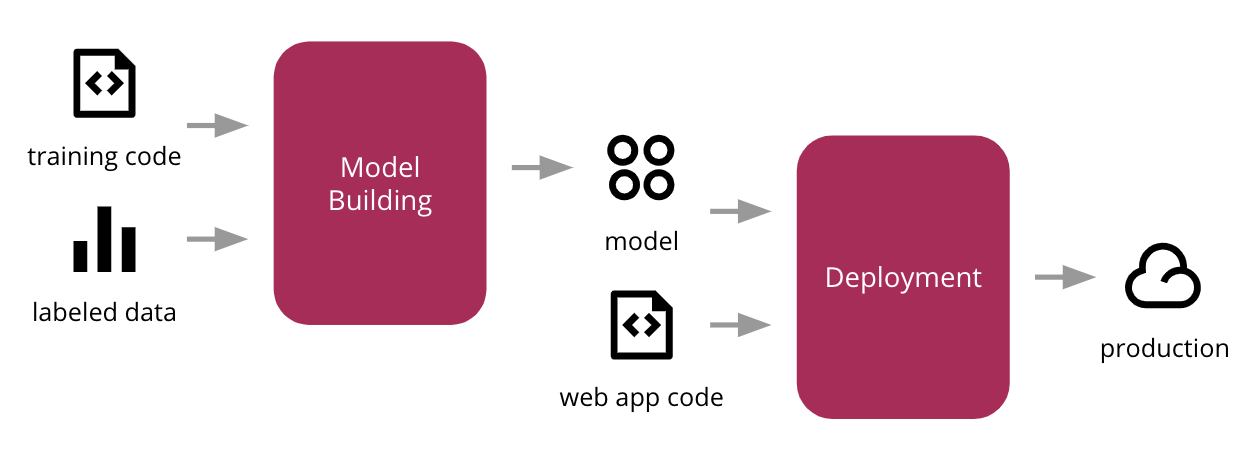
図2:MLモデルのトレーニング、ウェブアプリケーションへの統合、本番環境へのデプロイの初期プロセス
デプロイされると、私たちのウェブアプリケーション(図3)を使用すると、ユーザーは製品と将来の日付を選択でき、モデルはその製品のその日の販売数量の予測を出力します。
{kind=link}
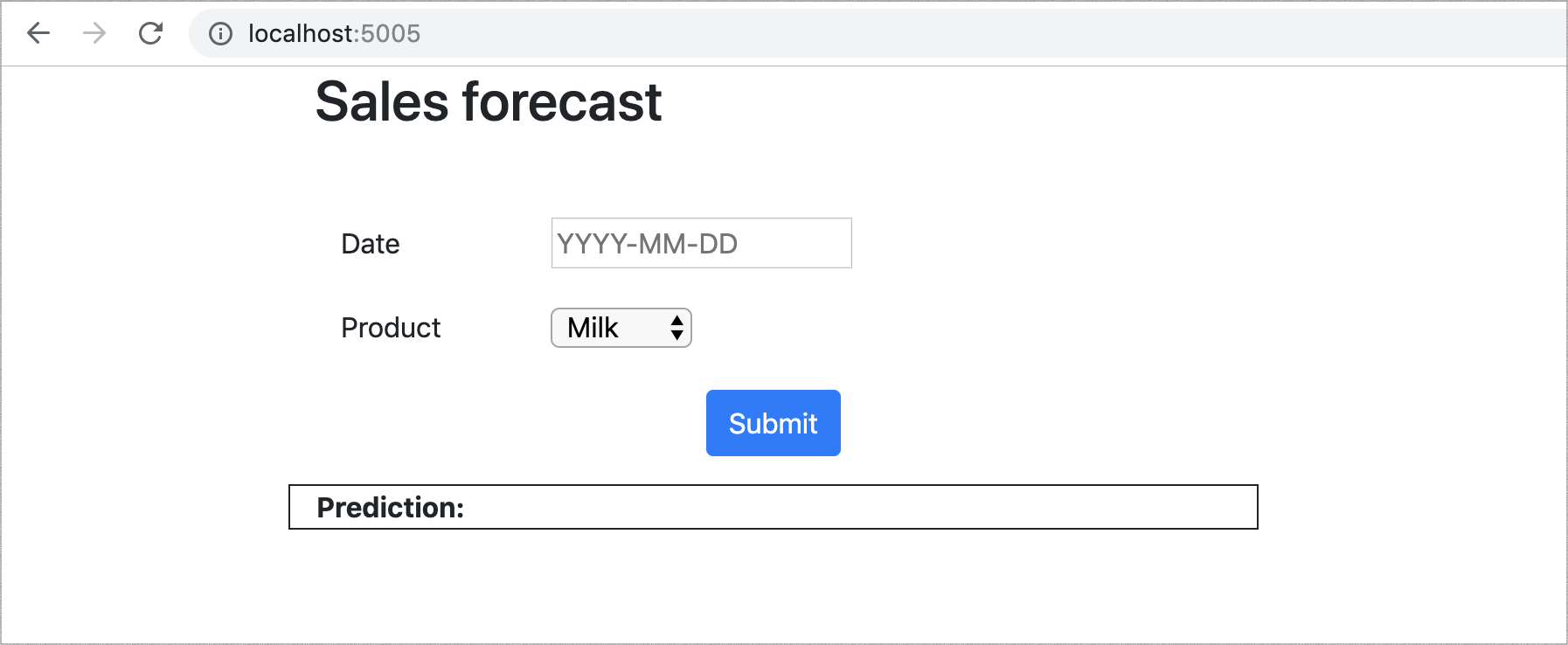
図3:モデルの動作を示すウェブUI
一般的な課題
これは議論の良い出発点ですが、このプロセスをエンドツーエンドで実装するには、すでに2つの課題が存在します。最初の課題は組織構造です。異なるチームがプロセスの異なる部分を所有している可能性があり、これらの境界を超える方法について明確な期待を持たずに、引き渡し—または通常は「壁越しに投げ渡す」—が行われます(図4)。データエンジニアはデータにアクセスできるようにパイプラインを構築している可能性がありますが、データサイエンティストはMLモデルの構築と改善を心配しています。次に、機械学習エンジニアまたは開発者は、そのモデルを統合して本番環境にリリースする方法を心配する必要があります。
{kind=link}

図4:大規模組織における一般的な機能上のサイロは障壁を作り出し、MLアプリケーションを本番環境にデプロイするエンドツーエンドのプロセスを自動化する能力を阻害する可能性があります。
これにより、遅延と摩擦が生じます。一般的な症状としては、ラボ環境でのみ機能するモデルがあり、概念実証フェーズから先に進まないことです。または、手動の一時的な方法で本番環境に到達した場合、それらは陳腐化し、更新が困難になります。
2番目の課題は技術的な課題です。プロセスを再現可能かつ監査可能にする方法です。これらのチームは異なるツールを使用し、異なるワークフローに従うため、エンドツーエンドで自動化することが困難になります。コード以外にも管理するアーティファクトが増え、それらをバージョン管理することは簡単ではありません。それらのいくつかは非常に大きいため、効率的に保存および取得するためのより高度なツールが必要です。
組織上の課題の解決は、この記事の範囲外ですが、アジャイルとDevOpsからの学びを取り入れ、エンドツーエンドのMLシステムを提供するために、さまざまな分野の専門家を含むクロスファンクショナルで成果志向のチームを構築できます。組織内でそれが不可能な場合は、少なくともそれらの障壁を打破し、プロセス全体を通じて早期かつ頻繁に協力するように促してください。
この記事の残りの部分では、技術的な課題に対して私たちが見出した解決策を探ります。各技術コンポーネントを深く掘り下げるとともに、エンドツーエンドのプロセスを徐々に改善・拡張し、より堅牢なものにしていきます。
CD4MLの技術的構成要素
機械学習を用いて需要予測問題を解決する方法を検討するにあたり、最初のステップはデータセットを理解することでした。この場合、それは以下の情報を含むCSVファイルの集合でした。
- 製品に関する情報(分類、腐敗性など)
- 店舗に関する情報(場所、クラスタリングなど)
- 特別なイベントに関する情報(祝祭日、季節イベント、2016年にエクアドルを襲ったマグニチュード7.8の地震など)
- 販売取引に関する情報(特定の製品、日付、場所における販売数量など)
この段階で、データアナリストとデータサイエンティストは通常、何らかの探索的データ分析(EDA)を実行してデータの形状を理解し、広範なパターンと外れ値を特定します。例として、販売数量が負の数になっている製品が見つかりましたが、これは返品と解釈しました。私たちは販売のみを調査することを目的としていたため、返品はトレーニングデータセットから削除しました。
多くの組織では、有用なMLモデルのトレーニングに必要なデータは、データサイエンティストが必要とする方法と完全に一致しているとは限りません。そのため、最初の技術コンポーネントとして、「発見可能かつアクセス可能なデータ」が強調されます。
発見可能かつアクセス可能なデータ
データの最も一般的なソースは、コアとなるトランザクションシステムです。しかし、組織外の他のデータソースを取り込むことにも価値があります。データレイクアーキテクチャ、より伝統的なデータウェアハウス、リアルタイムデータストリームの集合体、そして最近では分散型データメッシュアーキテクチャといった、データの収集と利用可能化のためのいくつかの共通パターンを見出しました。
どのようなアーキテクチャを使用する場合でも、データが容易に発見可能かつアクセス可能であることが重要です。データサイエンティストが必要なデータを見つけるのが難しいほど、有用なモデルを構築するのに時間がかかります。また、モデルのパフォーマンス向上に役立つ可能性のある、入力データに基づいて新しい特徴量をエンジニアリングしたいと考えていることも考慮する必要があります。
私たちの例では、最初の探索的データ分析を行った後、複数のファイルを単一のCSVファイルに非正規化し、関連のないデータポイントやモデルに不要なノイズを導入する可能性のあるデータポイント(負の販売など)をクリーンアップすることにしました。その後、Amazon S3、Google Cloud Storage、Azure Storage Accountなどのクラウドストレージシステムに出力を保存しました。
このファイルを使用して入力トレーニングデータのスナップショットを表すことで、フォルダ構造とファイル命名規則に基づいてデータセットのバージョンを管理するシンプルなアプローチを考案できます。データのバージョン管理は、スキーマへの構造的な変更と、時間経過によるデータのサンプリングという2つの異なる軸で変化するため、広範なトピックです。私たちのデータサイエンティストであるEmily Gorcenskiはこのトピックをこのブログ投稿でより詳細に説明していますが、この記事の後半では、時間経過に伴うデータセットのバージョン管理の他の方法についても説明します。
現実世界では、より複雑なデータパイプラインを使用して、複数のソースからデータサイエンティストがアクセスして使用できる場所にデータを移動する必要があることに注意することが重要です。
再現可能なモデルトレーニング
データが利用可能になると、モデル構築の反復的なデータサイエンスワークフローに移行します。これには通常、データをトレーニングセットと検証セットに分割し、アルゴリズムのさまざまな組み合わせを試行し、パラメータとハイパーパラメータを調整することが含まれます。これにより、予測の品質を評価するために検証セットに対して評価できるモデルが生成されます。このモデルトレーニングプロセスのステップバイステップが、機械学習パイプラインになります。
図5では、販売予測問題に対するMLパイプラインの構造を示し、さまざまなソースコード、データ、およびモデルコンポーネントを強調しています。入力データ、中間トレーニングデータセットと検証データセット、および出力モデルは、大きなファイルになる可能性があり、ソースコントロールリポジトリに保存したくありません。また、パイプラインの段階は常に変化しているため、データサイエンティストのローカル環境以外で再現することが困難です。
{kind=link}
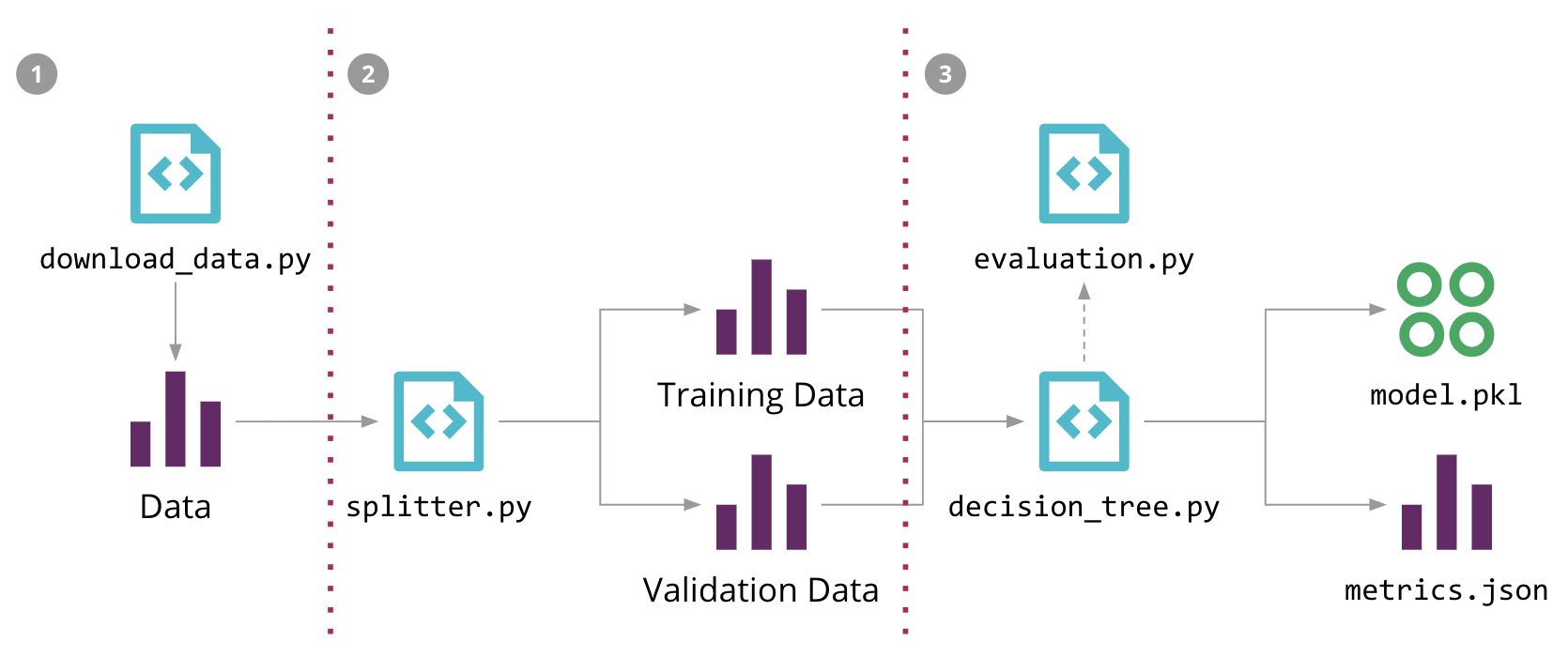
図5:販売予測問題に対する機械学習パイプライン、およびDVCによる自動化の3つのステップ
モデルトレーニングプロセスをコードで正式化するために、DVC(Data Science Version Control)というオープンソースツールを使用しました。これはGitと同様のセマンティクスを提供しますが、いくつかのML固有の問題も解決します。
- ソースコントロールリポジトリ外の外部ストレージで、大規模なファイルをフェッチおよび保存するための複数のバックエンドプラグインがあります。
- これらのファイルのバージョンを追跡し、データが変更されたときにモデルを再トレーニングできます。
- MLパイプラインの実行に使用された依存関係グラフとコマンドを追跡し、他の環境でプロセスを再現できます。
- Gitブランチと統合して、複数の実験を共存させることができます。
たとえば、図5に示す初期のMLパイプラインを、3つのdvc runコマンド(-dは依存関係を指定、-oは出力を指定、-fはそのステップを記録するファイル名、-Mは結果のメトリクス)で構成できます。
dvc run -f input.dvc \ ➊ -d src/download_data.py -o data/raw/store47-2016.csv python src/download_data.py dvc run -f split.dvc \ ➋ -d data/raw/store47-2016.csv -d src/splitter.py \ -o data/splitter/train.csv -o data/splitter/validation.csv python src/splitter.py dvc run ➌ -d data/splitter/train.csv -d data/splitter/validation.csv -d src/decision_tree.py \ -o data/decision_tree/model.pkl -M results/metrics.json python src/decision_tree.py
各実行によって対応するファイルが作成され、バージョン管理にコミットできます。これにより、dvc reproコマンドを実行することで、他のユーザーがMLパイプライン全体を再現できます。
適切なモデルが見つかったら、バージョン管理して本番環境にデプロイする必要があるアーティファクトとして扱います。DVCを使用すると、dvc pushコマンドとdvc pullコマンドを使用して、外部ストレージから公開および取得できます。
これらの問題を解決するために使用できる他のオープンソースツールがあります。Pachydermはコンテナを使用してパイプラインのさまざまなステップを実行し、データコミットを追跡し、それに基づいてパイプラインの実行を最適化することで、データのバージョン管理とデータの来歴の問題も解決します。MLflow Projectsは、環境とパイプラインのステップを指定するファイル形式を定義し、プロジェクトをローカルまたはリモートで実行するためのAPIとCLIツールの両方を提供します。私たちは、この問題の部分を非常にうまく解決するシンプルなCLIツールであるため、DVCを選択しました。
モデルサービング
適切なモデルが見つかったら、それをどのように本番環境で提供して使用するかを決定する必要があります。そのためには、いくつかのパターンがあります。
- 埋め込みモデル:これはよりシンプルなアプローチで、モデルアーティファクトを、使用アプリケーション内にビルドおよびパッケージ化される依存関係として扱います。この時点から、アプリケーションアーティファクトとバージョンを、アプリケーションコードと選択されたモデルの組み合わせとして扱うことができます。
- 別々のサービスとしてデプロイされたモデル:このアプローチでは、モデルは使用アプリケーションとは独立してデプロイできるサービスにラップされます。これにより、モデルの更新を独立してリリースできますが、各予測に何らかのリモート呼び出しが必要になるため、推論時にレイテンシが発生する可能性もあります。
- データとして公開されたモデル:このアプローチでは、モデルも独立して扱われ公開されますが、使用アプリケーションは実行時にそれをデータとして取り込みます。アプリケーションは、新しいモデルバージョンがリリースされるたびに公開されるイベントを購読し、前のバージョンを使用して予測を続けながらメモリに取り込むことができるストリーミング/リアルタイムシナリオで使用されているのを見ました。ブルーグリーンデプロイメントやカナリアリリースなどのソフトウェアリリースパターンも、このシナリオで適用できます。
私たちの例では、使用アプリケーションもPythonで記述されているため、よりシンプルな埋め込みモデルのアプローチを使用することにしました。私たちのモデルはシリアル化されたオブジェクト(pickleファイル)としてエクスポートされ、DVCによってストレージにプッシュされます。アプリケーションをビルドするときに、それをプルして同じDockerコンテナ内に埋め込みます。その時点から、Dockerイメージはバージョン管理され、本番環境にデプロイされるアプリケーション+モデルアーティファクトになります。
モデルオブジェクトをpickleでシリアル化する以外にも、埋め込みモデルパターンを実装するための他のツールオプションがあります。MLeapは、Spark、scikit-learn、Tensorflowモデルのエクスポート/インポートのための共通のシリアル化形式を提供します。モデルを共有するための言語に依存しない交換形式もあります。PMML、PFA、ONNXなどです。これらのシリアル化オプションの一部は、「データとしてのモデル」パターンを実装するためにも適用できます。
別の方法は、H2Oなどのツールを使用してモデルをJAR Javaライブラリ内のPOJOとしてエクスポートし、それをアプリケーションの依存関係として追加することです。このアプローチの利点は、PythonやRなどのデータサイエンティストに馴染みのある言語でモデルをトレーニングし、異なるターゲット環境(JVM)で実行されるコンパイル済みバイナリとしてモデルをエクスポートできることで、推論時間が短縮される可能性があることです。
「サービスとしてのモデル」パターンを実装するために、多くのクラウドプロバイダーは、Azure Machine Learning、AWS Sagemaker、Google AI PlatformなどのMLaaS(Machine Learning as a Service)プラットフォームへのモデルのデプロイをラップするためのツールとSDKを提供しています。別のオプションは、KubernetesにMLワークフローをデプロイするように設計されたプロジェクトであるKubeflowを使用することですが、これはモデル提供の部分以上の問題を解決しようとしています。
MLflowモデルは、様々なダウンストリームツールで使用される異なる形式のモデルをパッケージ化するための標準的な方法を提供しようとしています。「モデル・アズ・ア・サービス」や「組み込みモデル」パターンなどです。言うまでもなく、これは現在開発中の分野であり、様々なツールやベンダーが、この作業の簡素化に取り組んでいます。しかし、これは、明確な勝者とみなせる明確な標準(オープンなもの、またはプロプライエタリなもの)はまだ存在しないことを意味し、そのため、お客様のニーズに合った適切なオプションを評価する必要があります。
どのパターンを使用することに決定したかに関わらず、モデルとその利用者間には常に暗黙的な契約が存在することに注意する価値があります。モデルは通常、特定の形状の入力データがあると想定しており、データサイエンティストがその契約を変更して新しい入力を要求したり、新しい機能を追加したりすると、統合の問題が発生し、それを利用しているアプリケーションが破損する可能性があります。これは、テストというトピックにつながります。
機械学習におけるテストと品質
MLワークフローには、さまざまな種類のテストを導入できます。一部の側面は本質的に非決定論的で自動化が困難ですが、多くの種類の自動テストが価値を追加し、MLシステム全体の品質を向上させることができます。
- データの検証:入力データを期待されるスキーマに対して検証するテストを追加したり、有効な値に関する仮定を検証したりできます(例:期待される範囲内にある、またはnullではない)。設計された特徴量については、ユニットテストを作成して、正しく計算されていることを確認できます(例:数値特徴量はスケーリングまたは正規化されている、one-hotエンコーディングされたベクトルにはすべてのゼロと1つだけ1が含まれている、または欠損値が適切に置換されている)。
- コンポーネント統合の検証:契約テストを使用して、期待されるモデルインターフェースが利用アプリケーションと互換性があることを検証することにより、異なるサービス間の統合をテストする同様のアプローチを使用できます。モデルが異なる形式でプロダクション化される場合に関連するもう1つのテストの種類は、エクスポートされたモデルが依然として同じ結果を生成することを確認することです。これは、元のモデルとプロダクション化されたモデルを同じ検証データセットに対して実行し、結果が同じであることを比較することで実現できます。
- モデル品質の検証:MLモデルのパフォーマンスは非決定論的ですが、データサイエンティストは通常、エラー率、精度、AUC、ROC、混同行列、適合率、再現率など、モデルのパフォーマンスを評価するための多くの指標を収集して監視します。それらは、パラメーターとハイパーパラメーターの最適化中にも役立ちます。簡単な品質ゲートとして、これらの指標を使用して閾値テストまたはラチェットをパイプラインに導入し、新しいモデルが既知のパフォーマンスベースラインに対して劣化しないようにすることができます。
- モデルのバイアスと公平性の検証:全体的なテストおよび検証データセットで良好なパフォーマンスが得られる場合でも、特定のデータスライスに対するベースラインに対するモデルのパフォーマンスを確認することも重要です。たとえば、トレーニングデータに固有のバイアスがあり、現実世界の実際の分布と比較して、特定の機能値(例:人種、性別、または地域)に関するデータポイントがはるかに多い場合があります。そのため、データの異なるスライス全体でパフォーマンスを確認することが重要です。Facetsのようなツールを使用すると、これらのスライスとデータセットの特徴量全体の値の分布を視覚化できます。
私たちの例となるアプリケーションでは、Favoritaによって定義された評価指標は正規化されたエラー率です。エラー率が80%を超えた場合に中断する単純なPyUnit閾値テストを作成しました。このテストは、新しいモデルバージョンを公開する前に実行して、不良モデルがプロモーションされないようにする方法を示すことができます。
これらは自動化しやすいテストの例ですが、モデルの品質をより包括的に評価することは困難です。時間の経過とともに、常に同じデータセットに対して指標を計算する場合、過剰適合が始まる可能性があります。そして、他のモデルがすでに稼働している場合は、新しいモデルバージョンが未確認のデータに対して劣化しないようにする必要があります。したがって、テストデータの管理とキュレーションがより重要になります[2]。
モデルが配布またはエクスポートされて異なるアプリケーションで使用される場合、トレーニング時間とサービス時間の間で設計された特徴量が異なる方法で計算される問題が発生する可能性もあります。これらの種類の問題をキャッチするのに役立つアプローチは、モデルアーティファクトと一緒にホールドアウトデータセットを配布し、利用アプリケーションチームが統合後にホールドアウトデータセットに対してモデルのパフォーマンスを再評価できるようにすることです。これは、従来のソフトウェア開発における広範な統合テストに相当します。
他の種類のテストも検討できますが、モデルに関する情報を表示し、人間がプロモーションするかどうかを決定できるようにする、いくつかの手動ステージをデプロイメントパイプラインに追加することも重要だと考えています。これにより、機械学習ガバナンスプロセスをモデル化し、モデルのバイアス、モデルの公平性に関するチェックを導入したり、モデルがどのように動作しているかを人間が理解するための説明可能性情報を収集したりできます。
より多くの種類のテストを行うことで、テストピラミッドの形状を再考する必要があります。アーティファクトの種類ごとに個別のピラミッド(コード、モデル、データ)を検討することも、図6に示すようにそれらを組み合わせる方法を検討することもできます。全体として、MLシステムのテストと品質はより複雑であり、別の詳細な独立した記事の主題となるべきです。
{kind=link}
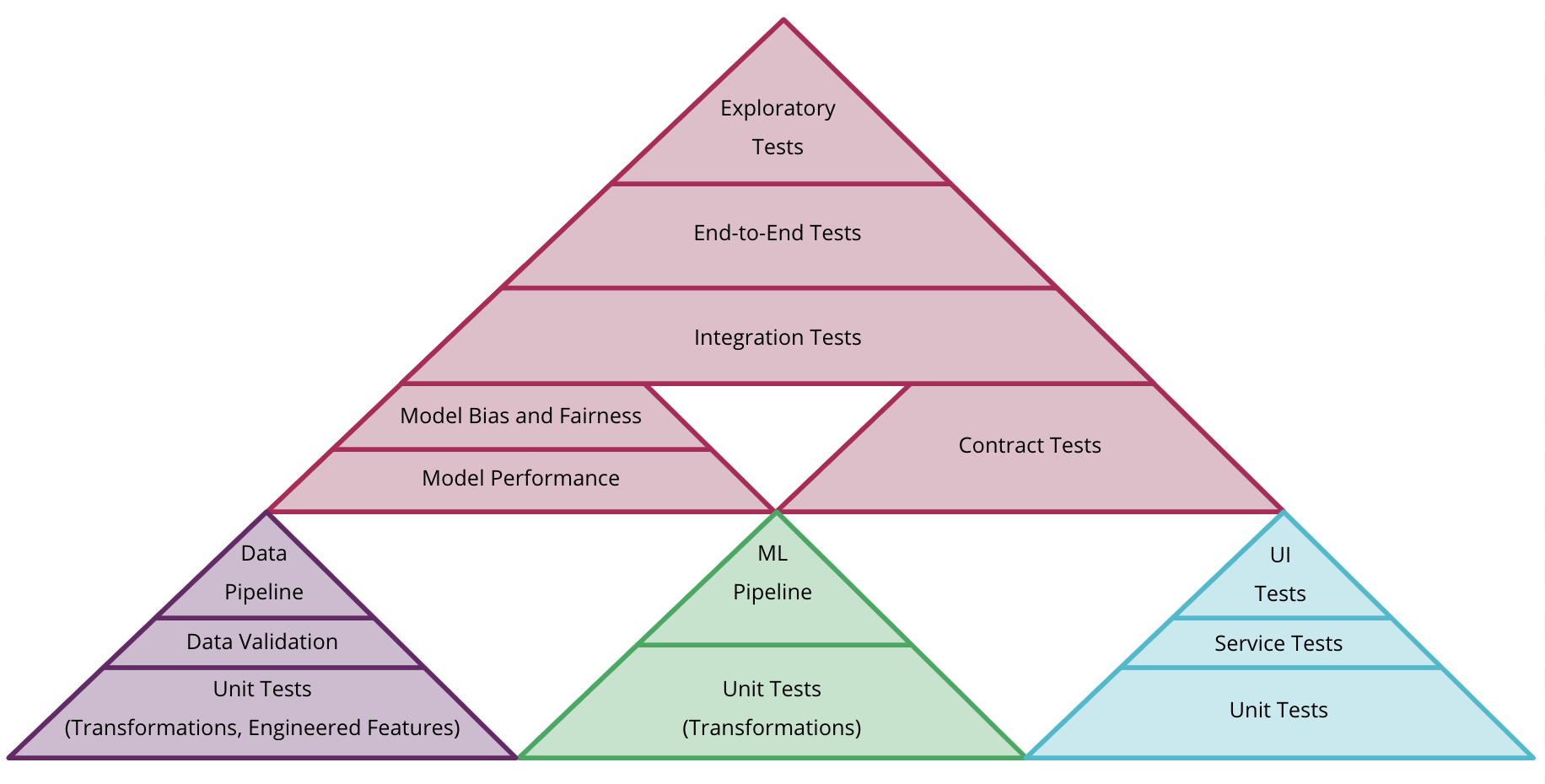
図6:CD4MLでデータ、モデル、コードの異なるテストピラミッドを組み合わせる方法の例
実験の追跡
このガバナンスプロセスをサポートするには、人間がどのモデルをプロダクションに昇格させるかを決定できるようにする情報を取得して表示することが重要です。データサイエンスのプロセスは非常に研究中心であるため、複数の実験が並行して試行されており、その多くがプロダクションに到達しないことが一般的です。
研究段階でのこの実験アプローチは、より伝統的なソフトウェア開発プロセスとは異なります。これらの実験のコードの多くは廃棄され、そのうちのほんの一部だけがプロダクションに値すると見なされると予想されるためです。そのため、それらを追跡するためのアプローチを定義する必要があります。
私たちの場合、ソース管理で異なる実験を追跡するために、DVCによって提案されたアプローチに従い、異なるGitブランチを使用することにしました。継続的インテグレーションを単一のブランチで実践するという私たちの好みには反していますが。DVCは、異なるブランチまたはタグで実行されている実験から指標を取得して表示できるため、それらの間を簡単に移動できます。
従来のソフトウェア開発でフィーチャーブランチで開発することの欠点のいくつかは、ブランチが長期間存在する場合、マージに苦労する可能性があり、変更がコードベースのより広範な領域に影響を与える可能性があるため、チームがより積極的にリファクタリングすることを妨げる可能性があり、継続的インテグレーション(CI)の実践を妨げる可能性があることです。これは、ブランチごとに複数のジョブを設定する必要があり、適切な統合はコードがメインラインにマージされるまで遅延されるためです。
ML実験の場合、ほとんどのブランチは統合されないことが予想され、実験間のコードのバリエーションは通常重要ではありません。CI自動化の観点から、実際には実験ごとに複数のモデルをトレーニングし、どのモデルがデプロイメントパイプラインの次の段階に進むことができるかを知らせる指標を収集したいと考えています。
DVC以外にも、実験追跡に役立つツールとしてMLflow Trackingを使用しました。ホスト型サービスとしてデプロイでき、APIとWebインターフェースを提供して、複数のエクスペリメント実行とそのパラメーターとパフォーマンス指標を視覚化します(図7を参照)。
{kind=link}
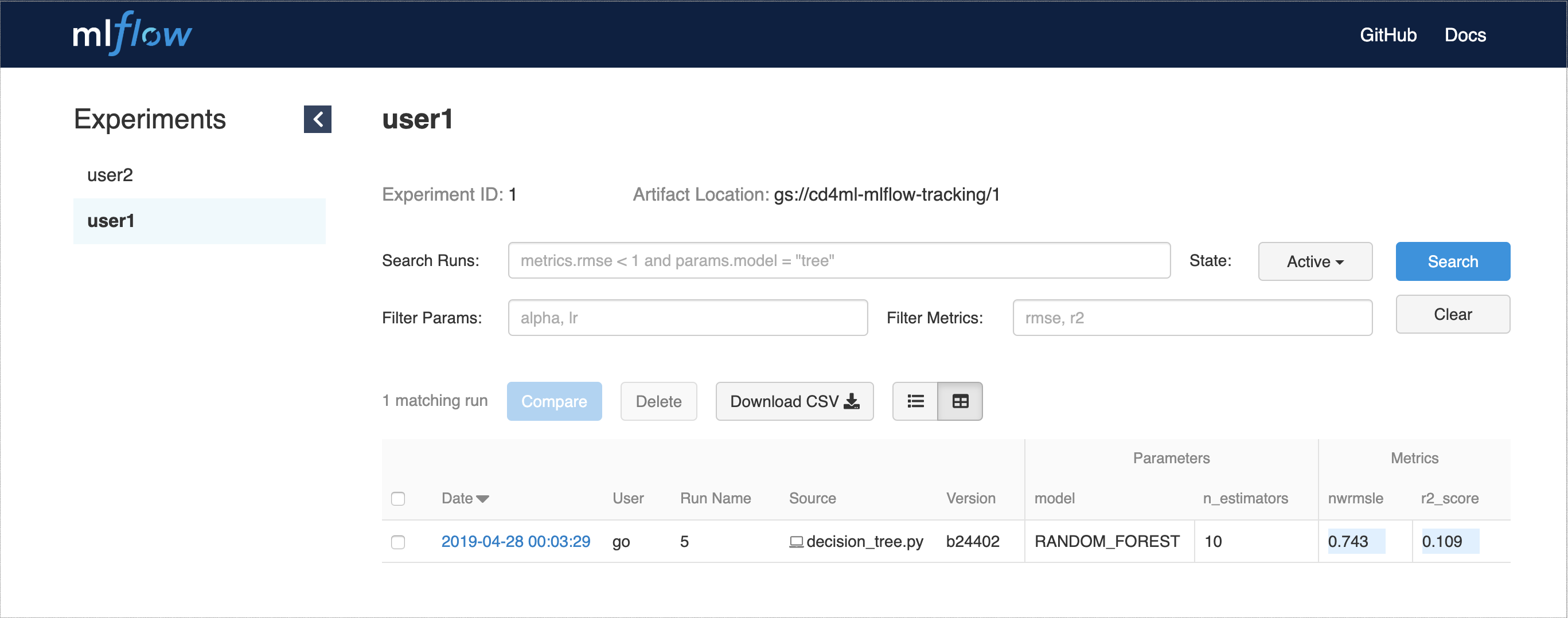
図7:実験実行、パラメーター、および指標を示すMLflow Tracking Web UI
この実験プロセスをサポートするには、トレーニングのために複数の環境(場合によっては特殊なハードウェアを使用)が必要になる可能性があるため、弾力的なインフラストラクチャを持つことの利点を強調することも重要です。クラウドベースのインフラストラクチャはこれにとって自然な適合であり、多くのパブリッククラウドプロバイダーがこのプロセスのさまざまな側面をサポートするサービスとソリューションを構築しています。
モデルのデプロイ
単純な例では、アプリケーションに埋め込まれてデプロイされる単一のモデルを作成するための実験のみを行っています。現実世界では、デプロイメントにより複雑なシナリオが生じる可能性があります。
- 複数のモデル:場合によっては、同じタスクを実行する複数のモデルを持つことがあります。たとえば、各製品の需要を予測するモデルをトレーニングできます。その場合、モデルを個別のサービスとしてデプロイすると、単一のAPIコールで予測を取得する消費アプリケーションにとって最適な場合があります。そして、その公開されたインターフェースの背後に必要なモデルの数を後で進化させることができます。
- シャドウモデル:このパターンは、プロダクションのモデルの置換を検討する場合に役立ちます。新しいモデルを現在のモデルと並行してシャドウモデルとしてデプロイし、同じプロダクショントラフィックを送信して、プロモーションする前にシャドウモデルのパフォーマンスに関するデータを集めることができます。
- 競合モデル:少し複雑なシナリオは、プロダクションで複数のバージョンのモデル(A/Bテストなど)を試して、どちらが良いかを確認する場合です。ここでの複雑さの増加は、トラフィックが正しいモデルにリダイレクトされ、統計的に有意な決定を行うのに十分なデータを収集するのに必要なインフラストラクチャとルーティングルールによるものです。これには時間がかかる場合があります。複数の競合モデルを評価するためのもう1つの一般的なアプローチは多腕バンディットであり、各モデルの使用に関連付けられた報酬を計算して監視する方法を定義する必要もあります。MLへの適用は現在研究中の分野であり、Seldon coreやAzure Personalizerなど、いくつかのツールやサービスが登場し始めています。
- オンライン学習モデル:これまでに説明したオフラインで学習し、オンラインで予測を提供するために使用されるモデルとは異なり、オンライン学習モデルは、新しいデータの到着に伴ってパフォーマンスを継続的に向上させることができるアルゴリズムと手法を使用します。これらは運用環境で常に学習しています。そのため、モデルを静的なアーティファクトとしてバージョン管理しても、同じデータが供給されない限り同じ結果は得られないため、複雑さが増します。モデルのパフォーマンスに影響を与える運用データだけでなく、トレーニングデータもバージョン管理する必要があります。
繰り返しますが、より複雑なデプロイメントシナリオをサポートするには、弾力的なインフラストラクチャを使用すると有益です。これにより、運用環境で複数のモデルを実行できるようになるだけでなく、必要に応じてインフラストラクチャをスケールアップすることで、システムの信頼性とスケーラビリティを向上させることもできます。
継続的デリバリーのオーケストレーション
主要な構成要素がすべて揃ったら、すべてを結び付ける必要があります。そこで、継続的デリバリーのオーケストレーションツールが登場します。この分野には多くのツールがあり、ほとんどのツールはデプロイメントパイプラインを構成して実行し、ソフトウェアを構築して運用環境にリリースするための手段を提供しています。CD4MLでは、インフラストラクチャのプロビジョニングと、複数のモデル実験からメトリクスをトレーニングして取得するための機械学習パイプラインの実行、データパイプラインの構築、テスト、デプロイメントプロセス、どのモデルをプロモートするかを決定するためのさまざまな種類のテストと検証、インフラストラクチャのプロビジョニングとモデルの運用環境へのデプロイメントなどをオーケストレーションするという追加の要件があります。
継続的デリバリーツールとしてGoCDを選択しました。これは、パイプラインを第一級の懸念事項として構築されたためです。それだけでなく、さまざまなパイプライン、そのトリガーを組み合わせ、パイプラインステージ間のマニュアルまたは自動プロモーションステップの両方を定義することで、複雑なワークフローと依存関係を構成することもできます。
簡略化された例では、複雑なデータパイプラインやインフラストラクチャのプロビジョニングはまだ構築していませんが、図8に示すように、2つのGoCDパイプラインを組み合わせる方法を示します。
{kind=link}
- 機械学習パイプライン:GoCDエージェント内でモデルのトレーニングと評価を実行し、モデルをプロモートできるかどうかを決定するための基本的なしきい値テストを実行します。モデルが適切な場合は、
dvc pushコマンドを実行して、アーティファクトとして公開します。 - アプリケーションデプロイメントパイプライン:アプリケーションコードを構築およびテストし、
dvc pullを使用して上流パイプラインからプロモートされたモデルを取得し、モデルとアプリケーションを含む新しい結合アーティファクトをDockerイメージとしてパッケージ化し、Kubernetes運用クラスタにデプロイします。
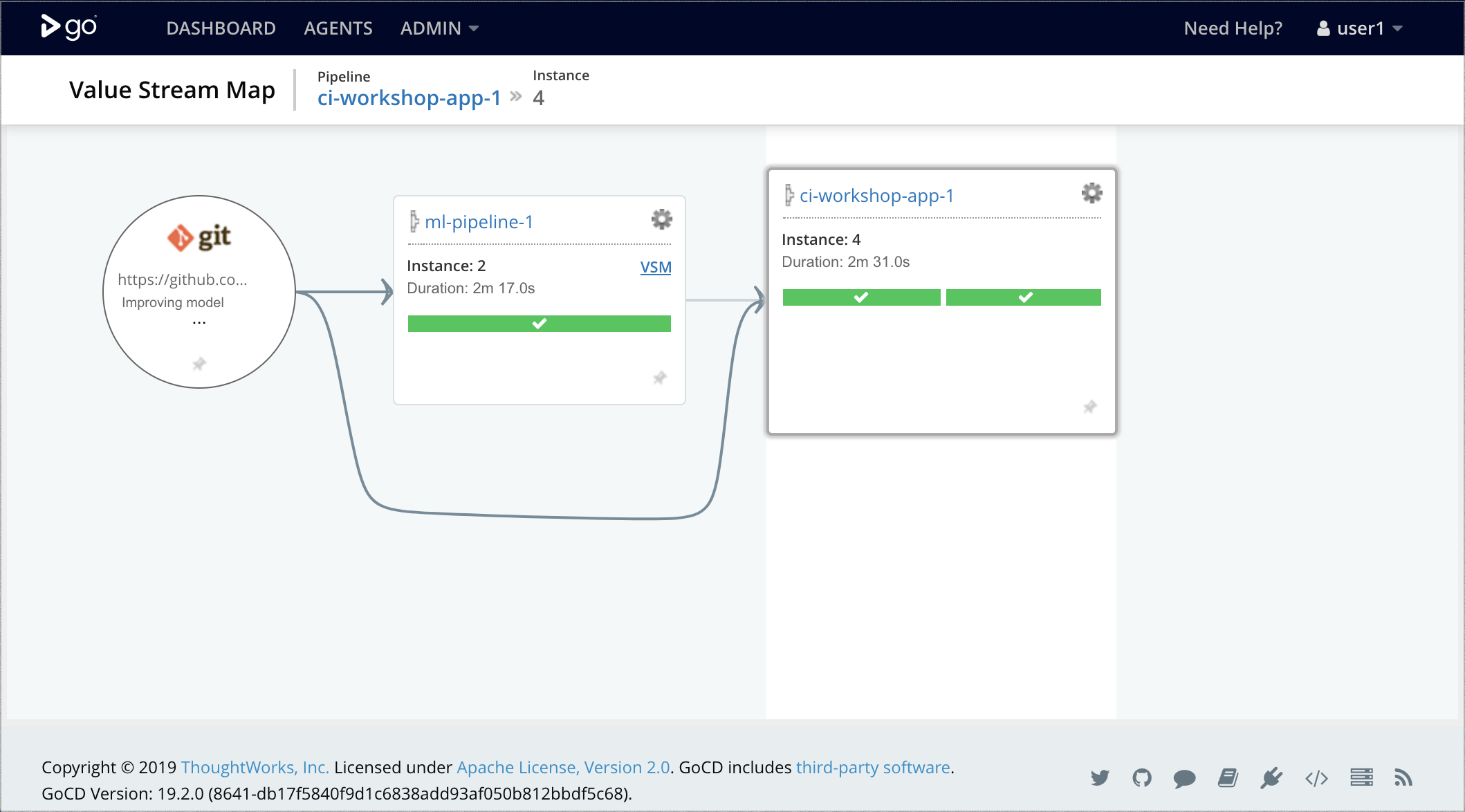
図8:GoCDでの機械学習パイプラインとアプリケーションデプロイメントパイプラインの組み合わせ
時間の経過とともに、MLパイプラインを拡張して複数のエクスペリメントを並列で実行し(GoCDのファンアウト/ファンインモデルでサポートされる機能)、バイアス、公平性、正確性などのモデルガバナンスプロセスを定義して、どのモデルをプロモートして運用環境にデプロイするかについて情報に基づいた意思決定を行うことができます。
最後に、継続的デリバリーオーケストレーションのもう1つの側面は、デプロイされたモデルが運用環境でパフォーマンスが低下したり、正しく動作しなくなったりした場合のロールバックプロセスを定義することです。これは、全体的なプロセスにさらなるセーフティネットを追加します。
モデル監視とオブザーバビリティ
モデルが稼働したら、運用環境でのパフォーマンスを理解し、データフィードバックループを閉じる必要があります。ここでは、アプリケーションやサービスにすでに存在している可能性のあるすべての監視と可観測性のインフラストラクチャを再利用できます。
ログ集約とメトリクス収集のツールは通常、ビジネスKPI、ソフトウェアの信頼性とパフォーマンスメトリクス、トラブルシューティングのためのデバッグ情報、何かが通常の状態から外れたときにアラートをトリガーする可能性のあるその他の指標など、ライブシステムからのデータの取得に使用されます。これらのツールを活用して、モデルの動作状況を理解するためのデータを取得することもできます。たとえば、
- モデル入力:モデルに供給されているデータ。トレーニングと提供のずれを可視化します。モデル出力:モデルがこれらの入力から行っている予測と推奨事項。モデルが実際のデータでどのように機能しているかを理解します。
- モデルの解釈可能性の出力:モデル係数、ELI5、またはLIMEなどのメトリクス。モデルが予測を行っている方法をさらに調査し、トレーニング中に検出されなかった可能性のある過剰適合またはバイアスを特定することができます。
- モデル出力と決定:運用入力データが与えられた場合のモデルの予測、およびそれらの予測で行われている決定。アプリケーションは、モデルを無視して、事前に定義されたルールに基づいて決定を行う場合があります(将来のバイアスを回避するため)。
- ユーザーアクションと報酬:さらなるユーザーアクションに基づいて、報酬メトリクスを取得し、モデルが期待どおりの効果を発揮しているかどうかを理解することができます。たとえば、製品の推奨事項を表示する場合、ユーザーが推奨された製品を購入することを報酬として追跡できます。
- モデルの公平性:人種、性別、年齢、所得グループなど、バイアスをかける可能性のある既知の特徴に対する入力データと出力予測の分析。
この例では、監視と可観測性のためにEFKスタックを使用しています。これは、3つの主要なツールで構成されています。
- Elasticsearch:オープンソースの検索エンジン。
- FluentD:統一されたロギングレイヤーのためのオープンソースのデータコレクター。
- Kibana:Elasticsearchによってインデックス付けされたデータを簡単に探索して視覚化できるオープンソースのWeb UI。
FluentDでモデルの入力と予測をイベントとしてログに記録するようにアプリケーションコードをインストルメントできます。
predict_with_logging.py…
df = pd.DataFrame(data=data, index=['row1'])
df = decision_tree.encode_categorical_columns(df)
pred = model.predict(df)
logger = sender.FluentSender(TENANT, host=FLUENTD_HOST, port=int(FLUENTD_PORT))
log_payload = {'prediction': pred[0], **data}
logger.emit('prediction', log_payload)
このイベントは転送され、ElasticSearchにインデックス付けされます。Kibanaを使用して、図9に示すように、Webインターフェースを介してクエリおよび分析できます。
{kind=link}

図9:Kibanaで実際の入力データに対してモデルの予測を分析する
他の一般的な監視と可観測性のツールとしては、ELKスタック(ログの取り込みと転送にFluentDの代わりにLogstashを使用するバリエーション)、Splunkなどがあります。
運用環境に複数のモデルがデプロイされている場合、監視と可観測性のデータの収集はさらに重要になります。たとえば、評価するシャドウモデルがある場合、分割テストを実行している場合、または複数のモデルを使用して多腕バンディット実験を実行している場合があります。
これは、エッジ(たとえば、ユーザーのモバイルデバイス)でフェデレーテッドモデルをトレーニングまたは実行している場合、または運用環境で新しいデータから学習するにつれて時間の経過とともに分散するオンライン学習モデルをデプロイしている場合にも関連します。
このデータを取得することで、データフィードバックループを閉じることができます。これは、より多くの実データ(たとえば、価格設定エンジンまたは推奨システム)を収集するか、運用環境から取得した新しいデータを分析し、新しいモデルの新しいトレーニングデータセットを作成するためにキュレーションを行う人間をループに追加することで実現できます。このフィードバックループを閉じることは、CD4MLの主な利点の1つであり、実際の運用データから得られた学習に基づいてモデルを適応させることができ、継続的な改善のプロセスを作成できます。
エンドツーエンドのCD4MLプロセス
それぞれの技術的な課題に段階的に取り組み、さまざまなツールとテクノロジーを使用することで、図10に示すエンドツーエンドのプロセスを作成しました。これは、コード、モデル、データの3つの軸全体でアーティファクトのプロモーションを管理します。
{kind=link}
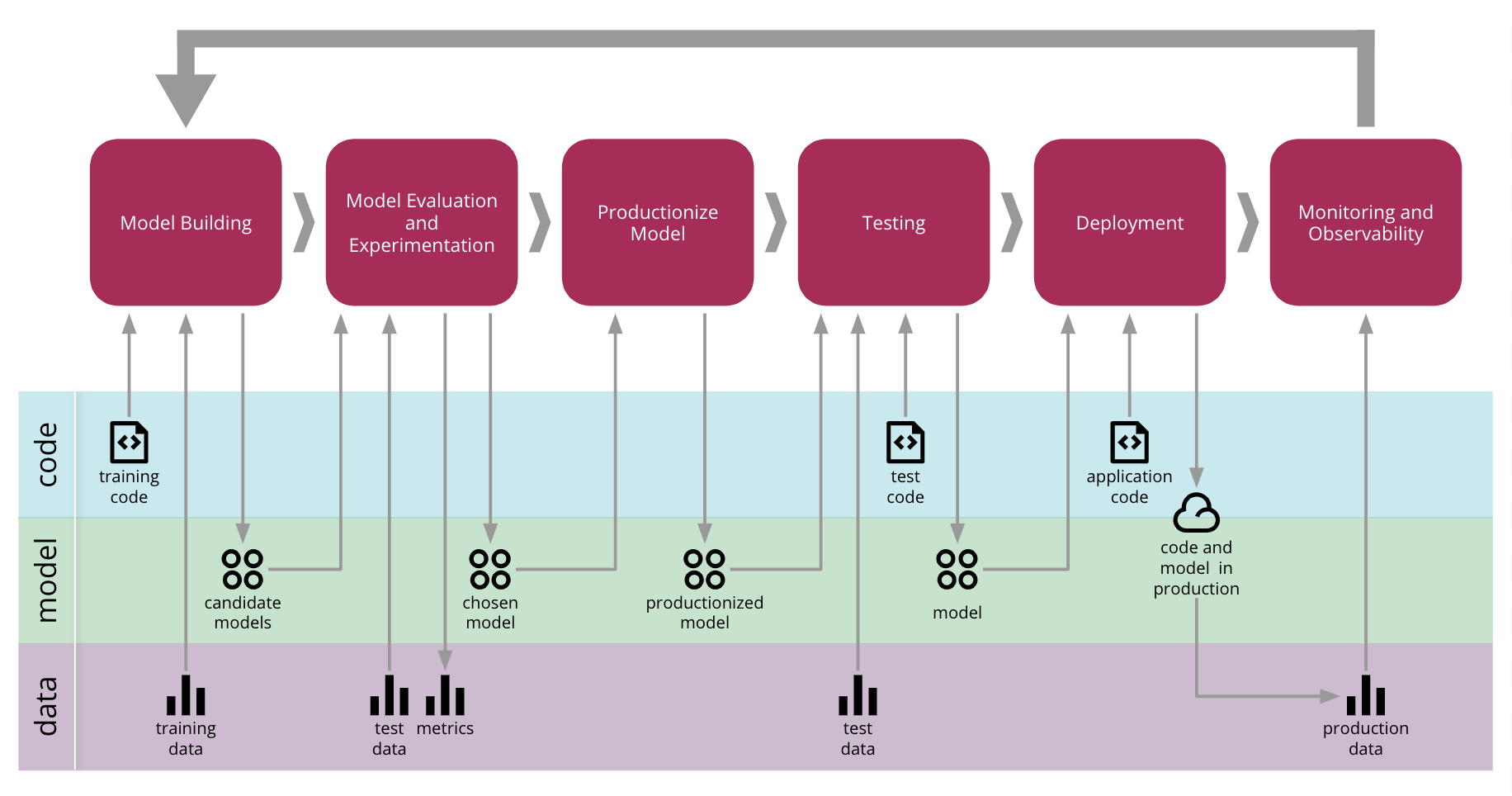
図10:機械学習のエンドツーエンドプロセスのための継続的デリバリー
基本的には、データの管理、検出、アクセス、バージョン管理を容易に行う方法が必要です。次に、モデルの構築とトレーニングのプロセスを自動化して、再現性を高めます。これにより、複数のモデルを実験してトレーニングできます。そのため、それらの実験を測定して追跡する必要があります。適切なモデルが見つかったら、そのモデルをどのように運用環境に導入して提供するかを決定できます。モデルは進化しているため、コンシューマーとの契約を破らないようにする必要があります。そのため、運用環境にデプロイする前にテストする必要があります。運用環境にデプロイされた後は、監視と可観測性のインフラストラクチャを使用して新しいデータを収集し、分析して新しいトレーニングデータセットを作成し、継続的な改善のフィードバックループを閉じることができます。
継続的デリバリーオーケストレーションツールは、エンドツーエンドのCD4MLプロセスを調整し、オンデマンドで必要なインフラストラクチャをプロビジョニングし、モデルとアプリケーションが運用環境にデプロイされる方法を管理します。
今後の展望
この記事で使用したサンプルアプリケーションとコードは、GitHubリポジトリで入手できます。これは、さまざまなカンファレンスやクライアントで発表した半日のワークショップの基礎として使用されました。CD4MLを実装する方法に関するアイデアは引き続き進化しています。このセクションでは、ワークショップ資料には反映されていない改善領域と、さらなる調査が必要な未解決の領域を強調して結論付けます。
データのバージョン管理
継続的デリバリーでは、すべてのコードコミットをリリース候補として扱い、デプロイメントパイプラインの新しい実行をトリガーします。コミットがすべてのパイプラインステージを通過すると仮定すると、運用環境にデプロイできます。CD4MLについて話すとき、私たちがよく受ける質問の1つは、「データが変更されたときにパイプラインをどのようにトリガーできますか?」です。
この例では、図5の機械学習パイプラインは、共有場所からトレーニングデータセットをダウンロードする役割を担うdownload_data.pyファイルから始まります。共有場所のデータセットの内容を変更しても、コードは変更されていないため、パイプラインはすぐにトリガーされません。DVCはそれを検出できません。データをバージョン管理するには、新しいファイルを作成するか、ファイル名を変更する必要があります。そのためには、新しいパスを使用してdownload_data.pyスクリプトを更新し、新しいコードコミットを作成する必要があります。
このアプローチの改善策としては、手書きのダウンロードスクリプトを次のように置き換えることで、DVCがファイルの内容を追跡できるようにすることです。
dvc add data/raw/store47-2016.csv ➊
これにより、図11に示すように、機械学習パイプラインの最初のステップがわずかに変更されます。
{kind=link}
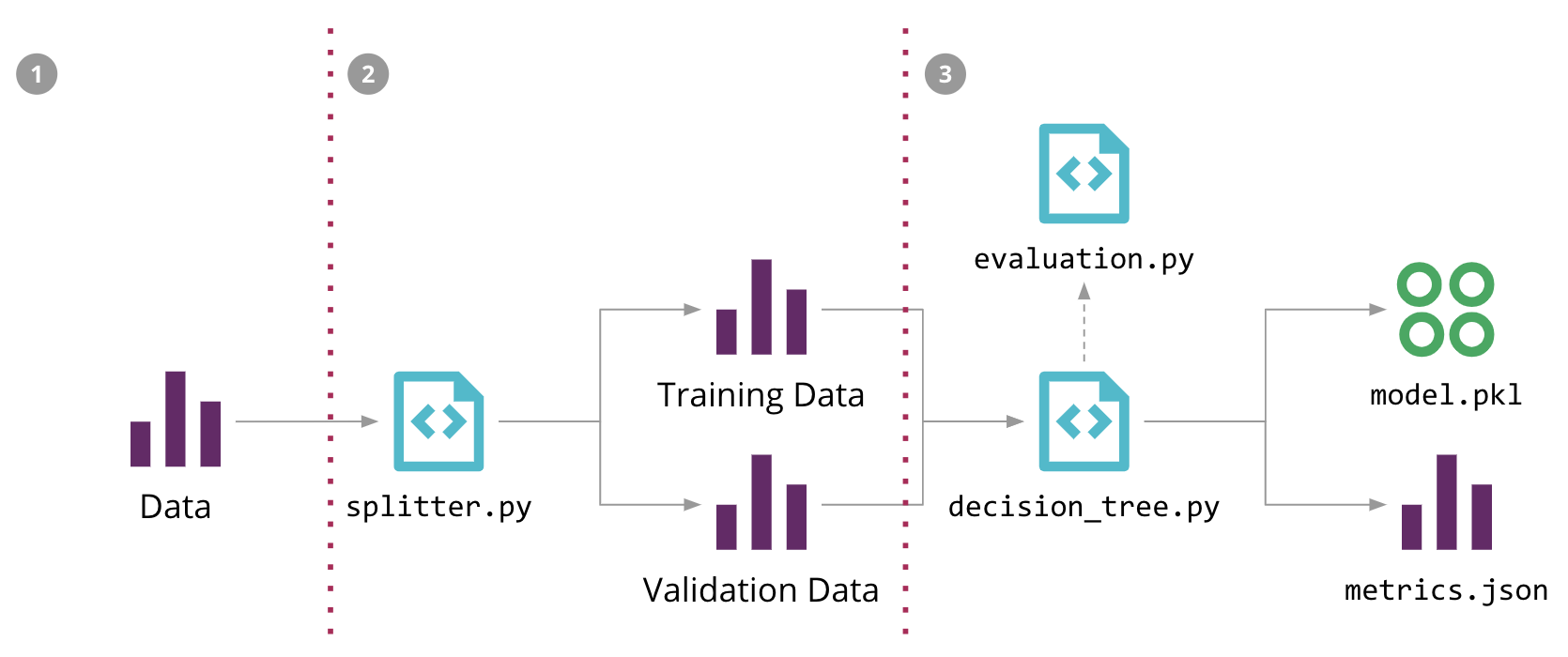
図11:最初のステップを更新してDVCがデータのバージョンを追跡できるようにし、MLパイプラインを簡素化する
これにより、ファイルの内容のチェックサムを追跡するメタデータファイルが作成され、これをGitにコミットできます。ファイルの内容が変更されると、チェックサムが変更され、DVCはそのメタデータファイルを更新します。これが、パイプライン実行をトリガーするために必要なコミットになります。
これにより、データが変更されたときにモデルを再トレーニングできますが、データのバージョン管理に関する全体像を伝えるわけではありません。1つの側面はデータの履歴です。理想的には、すべてのデータ変更の履歴全体を保持したいと考えていますが、データがどのくらいの頻度で変更されるかによっては、常に実現できるわけではありません。もう1つの側面はデータの来歴です。データが変更された原因となった処理ステップ、およびそれがさまざまなデータセットにどのように伝播するかを知る必要があります。時間の経過とともにデータスキーマを追跡および進化させること、およびそれらの変更が前向きと後ろ向きに互換性があるかどうかについても疑問があります。
ストリーミングの世界にいる場合は、データのバージョン管理のこれらの側面について推論することがさらに複雑になるため、この分野では、さらに多くのプラクティス、ツール、手法が進化すると予想されます。
データパイプライン
これまで触れてこなかったもう一つの側面は、データパイプライン自体のバージョン管理、テスト、デプロイ、監視の方法です。現実世界では、CD4MLを実現するために、いくつかのツールオプションが他のオプションよりも優れています。例えば、GUIを通して変換や処理手順を定義する必要がある多くのETLツールは、通常、バージョン管理、テスト、ハイブリッド環境へのデプロイが容易ではありません。それらのいくつかは、成果物として扱うことができ、デプロイメントパイプラインに投入できるコードを生成できます。
私たちは、データパイプラインをコードで定義できるオープンソースツールを好む傾向があります。これは、バージョン管理、テスト、デプロイが容易だからです。例えば、Sparkを使用している場合、データパイプラインをScalaで記述している可能性があり、ScalaTestまたはspark-testing-baseを使用してテストし、ジョブをJAR成果物としてパッケージ化して、GoCDのデプロイメントパイプラインでバージョン管理およびデプロイできます。
データパイプラインは通常、バッチジョブまたは長時間実行されるストリーミングアプリケーションとして実行されるため、図10のエンドツーエンドのCD4MLプロセス図には含めていませんでしたが、モデルまたはアプリケーションが期待する出力に変更を加える場合、統合の問題の別の潜在的な原因にもなります。したがって、これらの間違いをキャッチするために、デプロイメントパイプラインの一部として統合およびデータ契約テストを行うことを目指しています。
データパイプラインに関連するもう1つのテストの種類は、データ品質チェックですが、これは別の広範な議論のトピックになり、別記事で取り上げた方が良いでしょう。
プラットフォーム思考
お気づきかもしれませんが、私たちはCD4MLを実装するためにさまざまなツールとテクノロジーを使用しました。複数のチームがこれを行おうとすると、同じことをやり直したり、努力が重複したりする可能性があります。ここでプラットフォーム思考が役立ちます。単一のチームにすべての努力を集中させてボトルネックにするのではなく、基盤となる複雑さを隠蔽し、それを採用しようとするチームの速度を向上させるドメイン非依存のツールを構築することにプラットフォームエンジニアリングの努力を集中させることです。私たちの同僚であるZhamak Dehghaniが、彼女のData Meshの記事で、より詳細に説明しています。
CD4MLにプラットフォーム思考を適用することで、機械学習プラットフォームや、エンドツーエンドの機械学習ライフサイクルを管理するための単一のソリューションを提供しようとする他の製品への関心の高まりが見られます。多くの主要なテクノロジー企業は独自の社内ツールを開発していますが、これは活発な研究開発分野であり、より広く採用できるソリューションを提供する新しいツールとベンダーが登場すると予想しています。
バイアスのない進化型インテリジェントシステム
最初の機械学習システムが本番環境にデプロイされるとすぐに、予測を開始し、未知のデータに対して使用されるようになります。以前のルールベースのシステムに置き換わることさえあります。実行したトレーニングデータとモデル検証は、過去のデータに基づいており、以前のシステムの動作に基づいた固有のバイアスが含まれている可能性があることを認識することが重要です。さらに、MLシステムが今後ユーザーに与える可能性のある影響は、将来のトレーニングデータにも影響します。
影響を理解するために、2つの例を考えてみましょう。まず、この記事全体で検討した需要予測ソリューションを考えてみましょう。予測需要に基づいて製品の正確な数量を決定し、顧客に提供するアプリケーションがあると仮定します。予測需要が実際の需要よりも低い場合、販売できる商品が不足し、その製品の取引量が減少します。これらの新しい取引のみをモデルの改善のためのトレーニングデータとして使用する場合、時間の経過とともに需要予測の精度が低下します。
2つ目の例として、顧客のクレジットカード取引が不正かどうかを判断するための異常検出モデルを構築していると想像してください。アプリケーションがモデルの決定に基づいて取引をブロックした場合、時間の経過とともに、モデルによって許可された取引の「真のラベル」のみが利用可能になり、トレーニングに使用できる不正な取引は少なくなります。トレーニングデータが「良好な」取引に偏るため、モデルのパフォーマンスも低下します。
この問題に対する簡単な解決策はありません。最初の例では、小売業者は在庫切れの状況も考慮し、潜在的な不足をカバーするために予測よりも多くの商品を注文します。不正検出シナリオでは、確率分布を使用して、モデルの分類を無視したり上書きしたりすることがあります。多くのデータセットは時間的である、つまりその分布が時間とともに変化することを認識することも重要です。データのランダム分割を実行する多くの検証アプローチは、i.i.d.(独立同分布)であると仮定していますが、時間の影響を考慮すると、それは真実ではありません。
したがって、モデルの入力/出力を取得するだけでなく、モデルの出力を利用するか上書きするかを決定する消費アプリケーションによって最終的に下された決定も取得することが重要です。これにより、将来のトレーニングラウンドでこのバイアスを回避するためにデータをアノテーションできます。トレーニングデータを管理し、人間がそれらをキュレーションできるようにするシステムを備えることは、これらの問題に直面したときに必要となるもう1つの重要なコンポーネントです。
時間の経過とともにMLモデルを選択して改善するインテリジェントシステムの進化は、メタ学習の問題と見なすこともできます。この分野の最先端の研究の多くは、このような問題に焦点を当てています。たとえば、多腕バンディットなどの強化学習技術、または本番環境でのオンライン学習の使用などです。これらのタイプのMLシステムを最適に構築、デプロイ、監視する方法に関する私たちの経験と知識は、進化し続けると予想しています。
結論
機械学習技術は進化し続け、より複雑なタスクを実行するにつれて、そのようなアプリケーションを本番環境に管理および提供する方法に関する私たちの知識も進化しています。継続的デリバリーの原則と実践を取り入れ、拡張することで、機械学習アプリケーションへの変更のリリースに伴うリスクを安全かつ確実に管理できます。
この記事では、サンプルの売上予測アプリケーションを使用して、CD4MLの技術コンポーネントを示し、それらを実装した方法のいくつかのアプローチについて説明しました。この手法は進化し続け、新しいツールが出現したり消滅したりすると考えていますが、継続的デリバリーの核心となる原則は依然として関連性があり、独自の機械学習アプリケーションで考慮すべきものです。
謝辞
まず、Martin Fowler氏に、この記事のナラティブと構造の再定義とホスティングへのご協力に感謝いたします。
ワークショップやクライアントワークを通じてこの記事のアイデアの作成と精製に貢献してくれた多くの現職および元ThoughtWorkersの皆様、特にArun Manivannan氏、Danni Yu氏、David Tan氏、Emily Gorcenski氏、Emma Grasmeder氏、Jin Yang氏、Jonathan Heng氏、Juan López氏に特別な感謝を申し上げます。
また、この記事の最初のドラフトについて貴重なフィードバックを提供してくれた以下の初期レビューワーの皆様にも感謝いたします:Chris Ford氏、Fabio Kung氏、Fernando Meyer氏、Guilherme Silveira氏、Kyle Hodgson氏、Rodrigo Kumpera氏。
脚注
1: ML開発プロセスの多くの手順を自動化するための方法とツールを作成するためのAutoMLに関する取り組みがあります。
2: 新しいテストデータが必要な場合、またはモデルが過剰適合している場合の管理と理解に役立つease.ml/ciおよびease.ml/meterなどのツールとシステムに関する活発な研究があります。
重要な改訂
2019年9月19日: 最終回を公開
2019年9月18日: データのバージョン管理とデータパイプラインに関する回を公開
2019年9月11日: オーケストレーションと監視に関する回を公開
2019年9月9日: 実験の追跡とモデルのデプロイに関する回を公開
2019年9月6日: モデルの提供とテストに関する回を公開
2019年9月4日: 検索可能なデータと再現可能なトレーニングに関する回を公開
2019年9月3日: 最初の回を公開:導入と課題