
平均値の比較は避ける
平均値のみを使用して数値のグループを比較すると、多くの洞察が隠れてしまいます。
ビジネスミーティングでは、平均値を比較することで数値のグループを比較することが一般的です。しかし、そうすることで、これらのグループの数値の分布における重要な情報が隠されてしまうことがよくあります。この情報を明らかにするデータ視覚化の方法がいくつかあります。これには、ストリップチャート、ヒストグラム、密度プロット、ボックスプロット、バイオリンプロットなどがあります。これらは、無料で入手可能なソフトウェアを使用して簡単に作成でき、12個程度の小さなグループから数千個の大きなグループまで対応できます。
2020年9月24日

あなたは幹部であり、どの営業リーダーに大きな賞/昇進/ボーナスを与えるべきか決めなければならないと想像してください。あなたの会社は、収益しか重要視しない弱肉強食の資本主義企業なので、あなたの決定における重要な要素は、今年最も収益成長を達成した人が誰であるかです。(2020年なので、マスクを販売しているかもしれません。)
これが非常に重要な数値です。
| 名前 | 平均収益増加率 (%) |
|---|---|
| アリス | 5.0 |
| ボブ | 7.9 |
| クララ | 5.0 |
そしてカラフルなグラフ
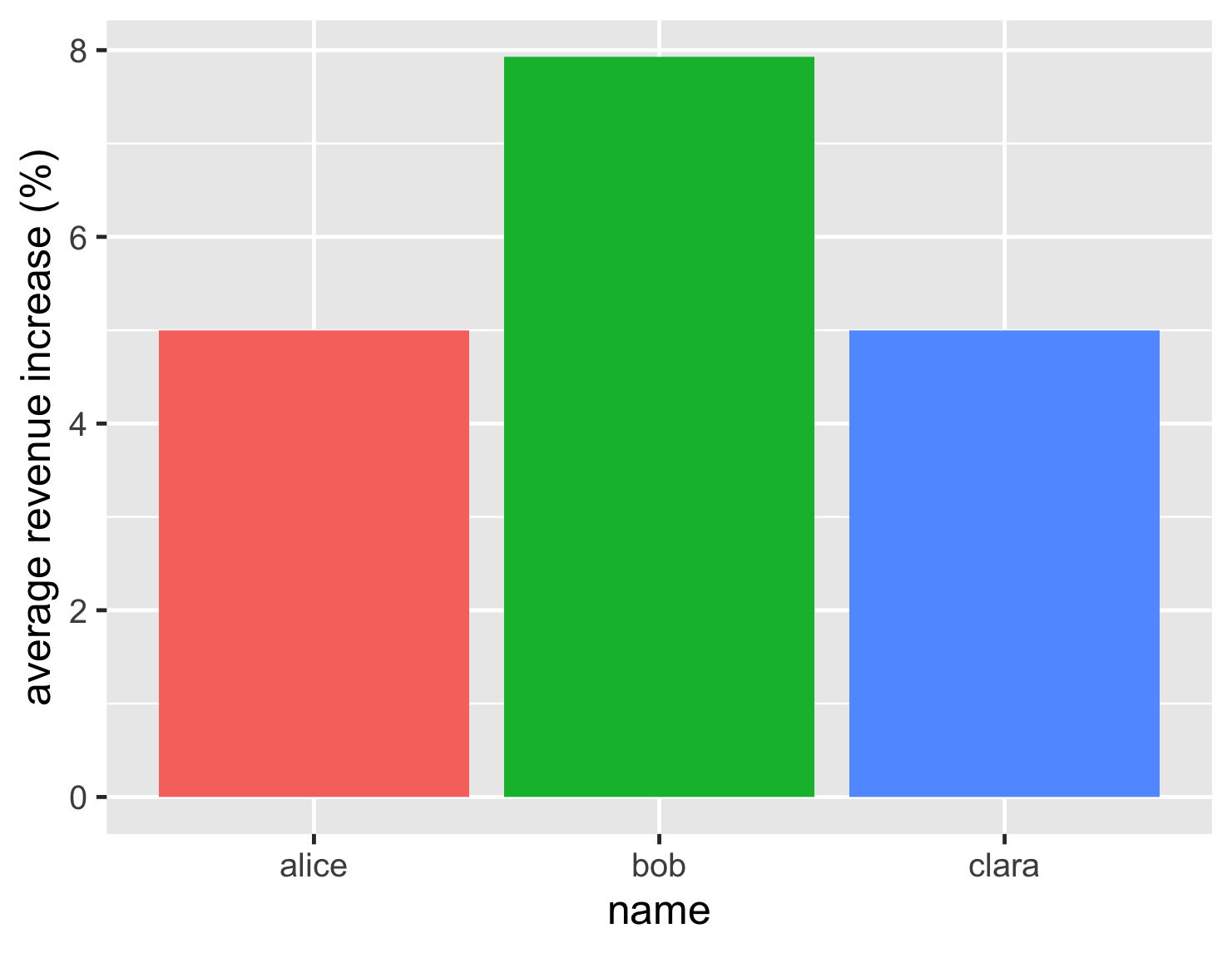
これに基づくと、決定は簡単に見えます。ボブは8%弱で、5%に低迷するライバルよりも顕著に高い収益増加率を達成しています。
しかし、さらに詳しく調べて、各営業担当者の個々のアカウントを見てみましょう。
| 名前 | アカウント収益増加率 (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| アリス | -1.0 | 2.0 | 1.0 | -3.0 | -1.0 | 10.0 | 13.0 | 8.0 | 11.0 | 10.0 |
| ボブ | -0.5 | -2.5 | -6.0 | -1.5 | -2.0 | -1.8 | -2.3 | 80.0 | ||
| クララ | 3.0 | 7.0 | 4.5 | 5.5 | 4.8 | 5.0 | 5.2 | 4.0 | 6.0 | 5.0 |
このアカウントレベルのデータは、異なるストーリーを語っています。ボブの高いパフォーマンスは、1つのアカウントが80%もの収益増加をもたらしたためです。彼の他のすべてのアカウントは縮小しました。ボブのパフォーマンスがたった1つのアカウントに基づいている場合、彼は本当にボーナスの対象となる最良の営業担当者と言えるでしょうか?
ボブの物語は、平均値を見てデータポイントのグループを比較することにおける最大の課題の1つの典型的な例です。通常平均、つまり算術平均は、1つの外れ値が全体値を大きく変動させる可能性が高いです。100人のホームレスの平均純資産が、ビル・ゲイツが加わると10億ドルになることを思い出してください。
詳細なアカウントデータは、別の違いを明らかにしています。アリスとクララは平均値が同じですが、アカウントデータは全く異なるストーリーを語っています。アリスは非常に成功している(約10%)か、平凡である(約2%)かのどちらかであり、クララは一貫して穏やかに成功している(約5%)ということです。平均値だけを見ると、この重要な違いは見過ごされてしまいます。
統計やデータ視覚化を学んだ人は、私が当たり前のことを言っていることに目玉を回しているでしょう。しかし、この知識は企業界の人々に伝わっていません。私はビジネスプレゼンテーションで、平均値を比較した棒グラフを常に見ています。そのため、この種の情報を探求するために使用できるさまざまな視覚化の方法を示し、平均値だけでは得られない洞察を得るために、この記事を書くことにしました。これを通して、平均値だけを使用することをやめ、他の人がそうしているときには平均値に疑問を持つように、何人かの人を説得できることを願っています。結局のところ、データドリブンな企業になるために必要なデータを熱心に収集しても、そのデータを正しく調べる方法が分からなければ意味がありません。
ストリップチャートは個々の数値をすべて表示します。
したがって、データの実際の分布がどのようなものか分からない場合は、平均値を比較しないようにしましょう。データをどのようにして正確に把握できるのでしょうか?
データポイントが少ない場合から始めましょう。多くの場合、これにはストリップチャートが最適です。これは、異なる母集団のすべてのデータポイントを表示します。
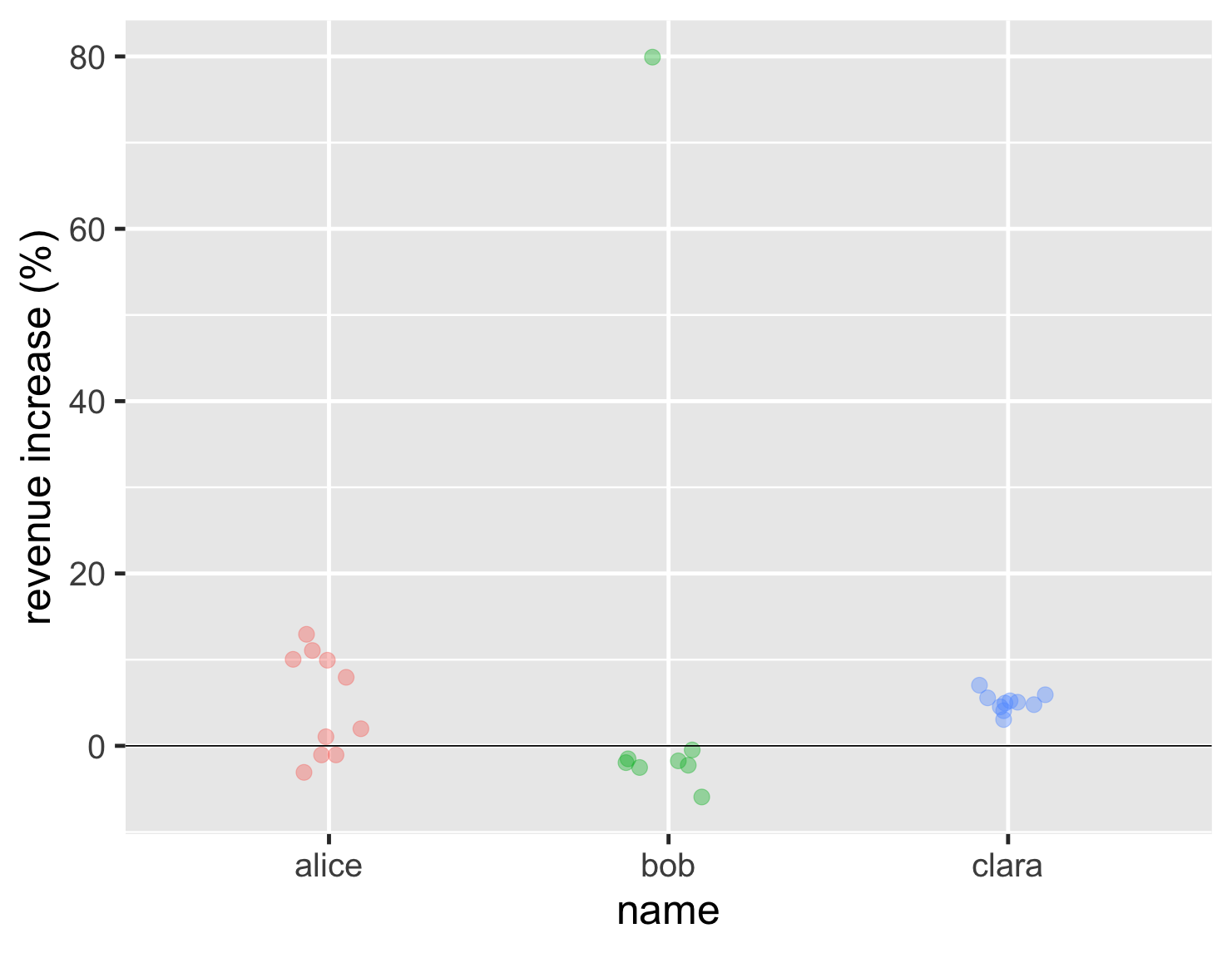
コードを表示
ggplot(sales, aes(name, d_revenue, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
このチャートでは、ボブの単独の高ポイント、彼の結果のほとんどがアリスの最悪の結果と似ていること、クララははるかに一貫していることがはっきりとわかります。これは、前の棒グラフよりもはるかに多くの情報を伝えていますが、解釈が難しいわけではありません。
次に、このきれいなストリップチャートをどのようにプロットするかを尋ねるかもしれません。簡単なグラフを描きたい人のほとんどは、Excelやその他のスプレッドシートを使用しています。私はスプレッドシートをよく使わないので、平均的なスプレッドシートでストリップチャートを描くのがどれほど簡単かは分かりません。管理プレゼンテーションで見ていることから、不可能かもしれません。なぜなら、ほとんど見たことがないからです。私のプロットにはRを使用します。これは恐ろしく強力な統計パッケージであり、「ケンドールの順位相関係数」や「マン・ホイットニーのU検定」といったフレーズに慣れている人々が使用しています。しかし、この恐ろしい兵器にもかかわらず、簡単なデータ操作とグラフプロットのためにRシステムを試すのは非常に簡単です。これは学術界によってオープンソースソフトウェアとして開発されているため、ライセンスコストや調達官僚主義を心配することなくダウンロードして使用できます。オープンソースの世界では珍しいことですが、優れたドキュメントとチュートリアルがあり、使用方法を学ぶことができます。(Python使いなら、これらすべてを行う優れたPythonライブラリもあります。ただし、私はその分野にはあまり詳しくありません。)Rに興味がある場合は、付録に私がどのようにしてRについて学んだかの概要があります。
ここで示すさまざまなチャートの生成方法に興味がある場合は、各チャートの後に「コードを表示」の公開があり、チャートのプロットコマンドが表示されます。使用されるsalesデータフレームには、nameとd_revenueの2つの列があります。
より多くのデータポイントを考慮する必要がある場合はどうでしょうか?3人組ははるかに重要になり、それぞれ数百のアカウントを処理していると想像してください。しかし、彼らの分布は依然として同じ基本的な特性を示しており、新しいストリップチャートからそれがわかります。
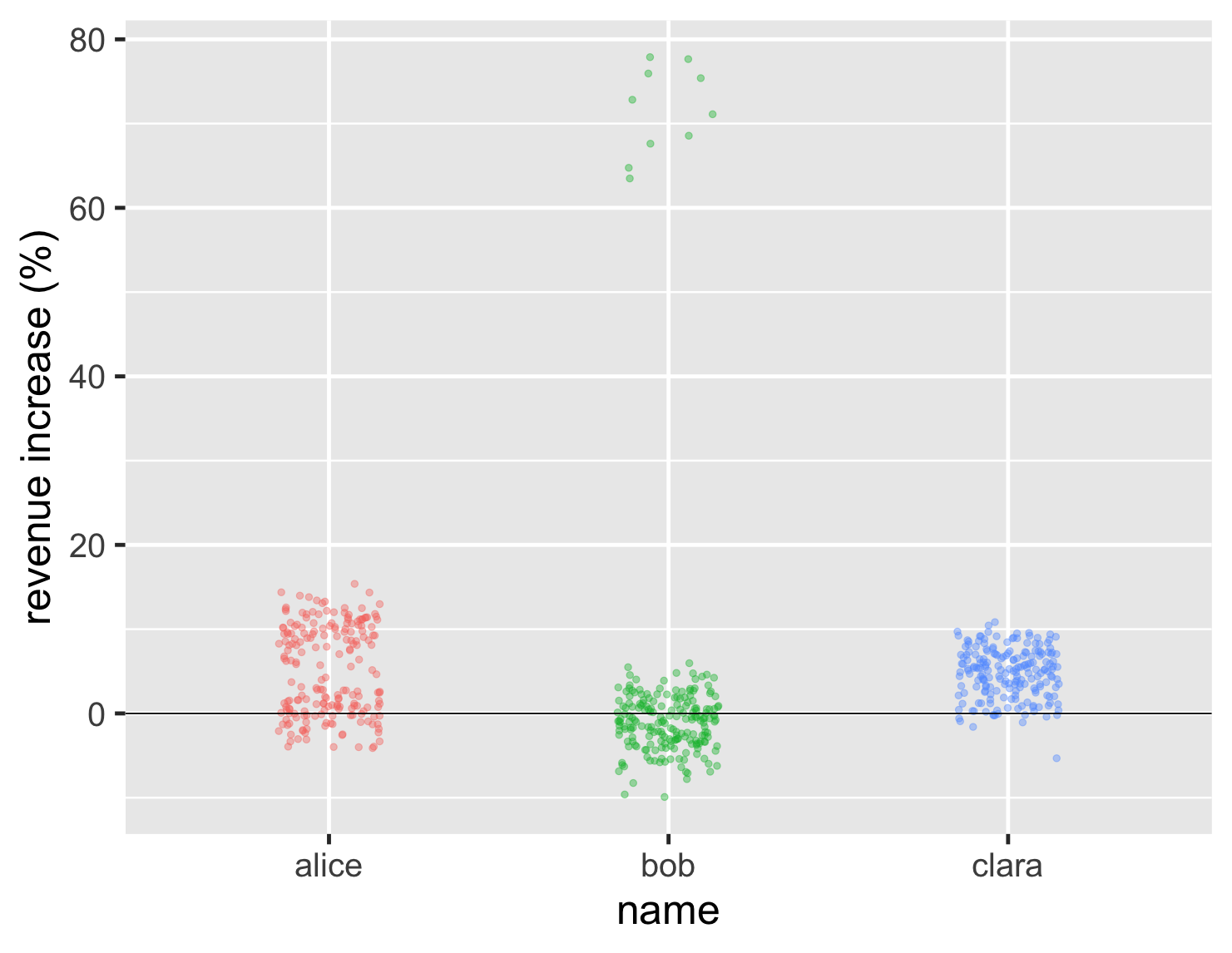
コードを表示
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
ただし、ストリップチャートの問題の1つは、平均値が見えないことです。そのため、ボブの高い値が、この一般的な低いポイントを補うのに十分かどうかを判断できません。この場合、平均点をグラフ上にプロットすることで、この問題に対処できます。この場合は黒い菱形としています。
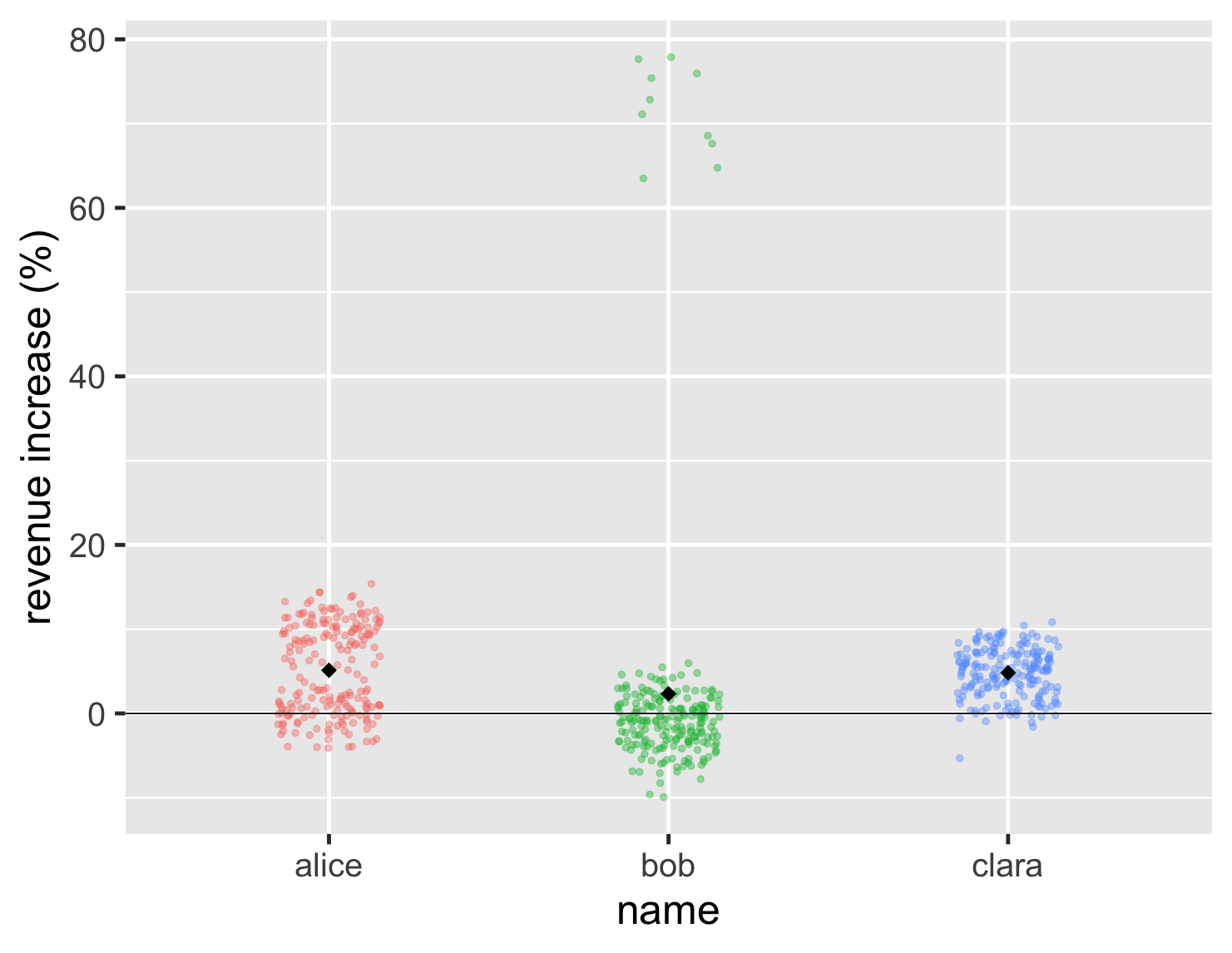
コードを表示
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + theme_grey(base_size=30)
この場合、ボブの平均値は他の2つよりも少し低くなっています。
これは、グループの比較に平均値を使用する人を軽蔑することが多い私でも、平均値が無意味とは考えていないことを示しています。私が軽蔑しているのは、平均値だけを使用する人、または全体的な分布を調べずに平均値を使用する人です。何らかの平均値は、比較の有用な要素になることがよくありますが、ほとんどの場合、中央値はボブのような大きな外れ値に耐えるため、実際にはより良い中心点です。「平均」を見るときは常に、中央値と平均値のどちらが良いかを検討する必要があります。
中央値がそれほど使用されていない理由の1つは、ツールが中央値の使用を促していないことです。主要なデータベースクエリ言語であるSQLには、平均値を計算する組み込みのAVG関数があります。ただし、中央値が必要な場合は、データベースが拡張関数をロードできる機能を持たない限り、通常は非常に醜いアルゴリズムをグーグル検索するしかありません。[1] もし将来私が最高指導者になったら、中央値も提供しない限り、どのプラットフォームにも平均値の関数を許可しないと布告します。
ヒストグラムを使用して分布の形状を確認する
ストリップチャートを使用すると、データの様子をすぐに把握するのに良い方法ですが、他のチャートを使用すると、さまざまな方法で比較できます。私が気付くことの1つは、多くの人が特定のデータセットを示す「1つのチャート」を使用したいということです。しかし、あらゆる種類のチャートはデータセットの異なる特徴を明らかにし、データが何を伝えようとしているかを把握するために、いくつかのチャートを使用するのが賢明です。データを探求して、データが何を伝えようとしているかを理解しようとする場合、これは確かに当てはまります。しかし、データの伝達に関しても、複数のチャートを使用することで、読者がデータが言っていることのさまざまな側面を見ることができます。
ヒストグラムは、分布を見るための古典的な方法です。ここに、大規模なデータセットのヒストグラムがあります。
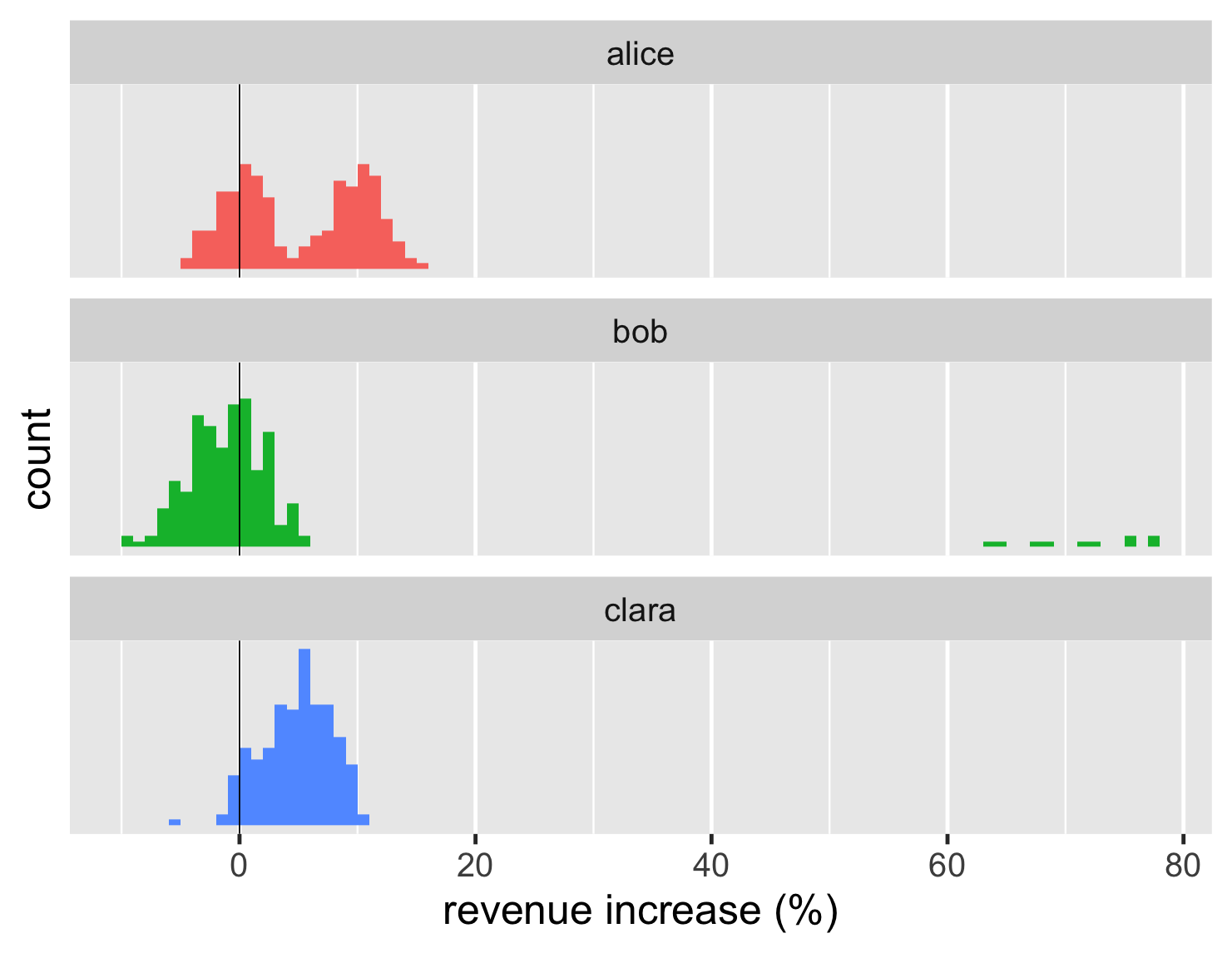
コードを表示
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 1, boundary=0, show.legend=FALSE) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(50,100)) + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
ヒストグラムは、単一の分布の形状を示すのに非常に効果的です。そのため、アリスの取引が2つの異なるブロックに固まっているのに対し、クララの取引は1つのブロックに固まっていることが簡単にわかります。これらの形状はストリップチャートからもいくらか簡単にわかりますが、ヒストグラムの方が形状が明確になります。
ヒストグラムは1つのグループしか表示しませんが、ここでは比較を行うためにいくつかまとめて表示しました。Rにはこのための特別な機能があり、ファセットプロットと呼ばれています。この種の「スモールマルチプル」(エドワード・タフティによって造られた用語)は、比較に非常に役立ちます。幸いなことに、Rを使用すると簡単にプロットできます。
分布の形状を視覚化するための別の方法は、密度プロットです。これはヒストグラムの滑らかな曲線と考えています。
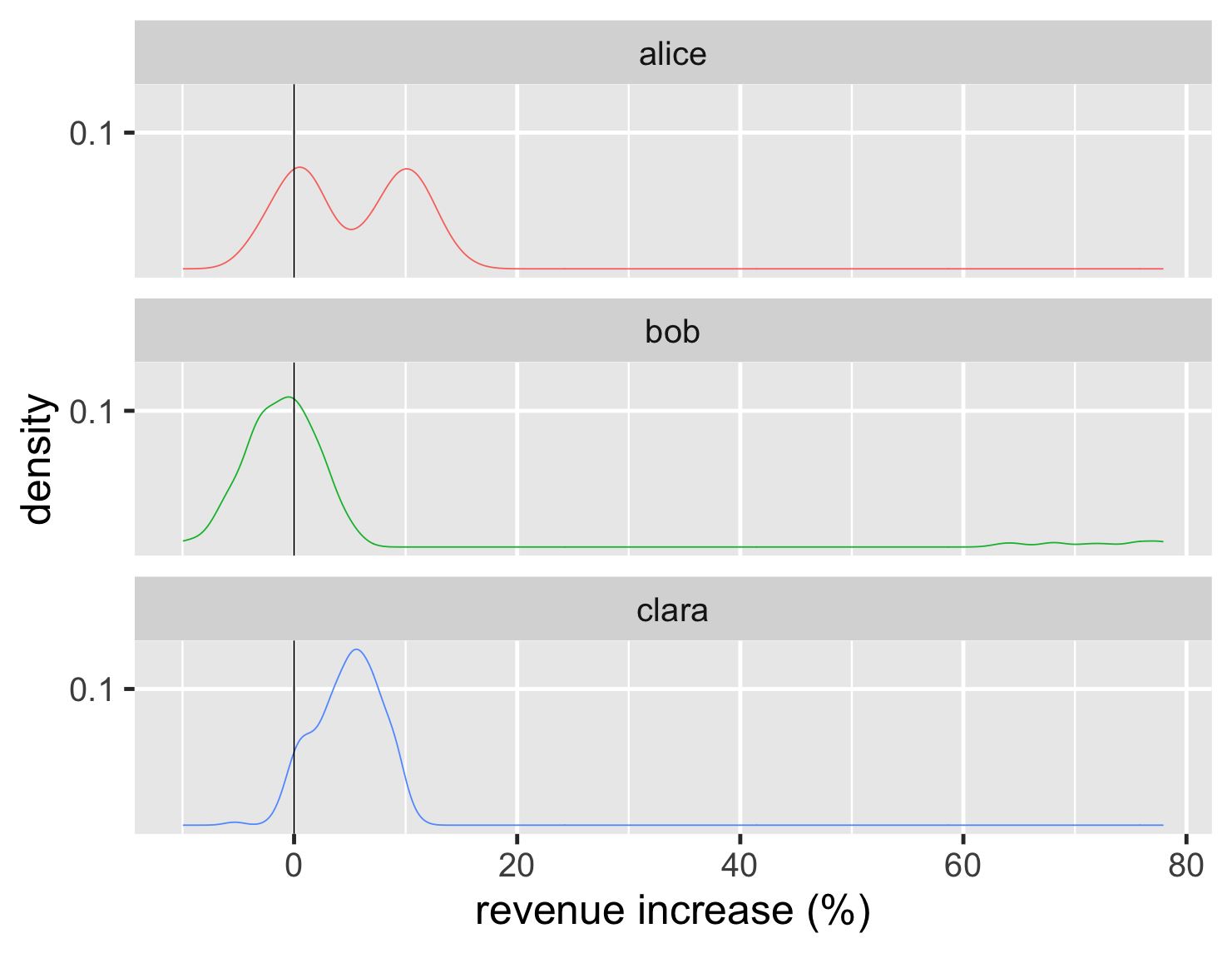
コードを表示
ggplot(large_sales, aes(value, color=name)) + geom_density(show.legend=FALSE) + geom_vline(xintercept = 0) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(0.1)) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
Y軸の密度スケールは私にとってあまり意味がないので、プロットからそのスケールを除去する傾向があります。結局のところ、これらの中心要素は分布の形状です。さらに、密度プロットは線として簡単にレンダリングできるので、すべてを1つのグラフにプロットできます。
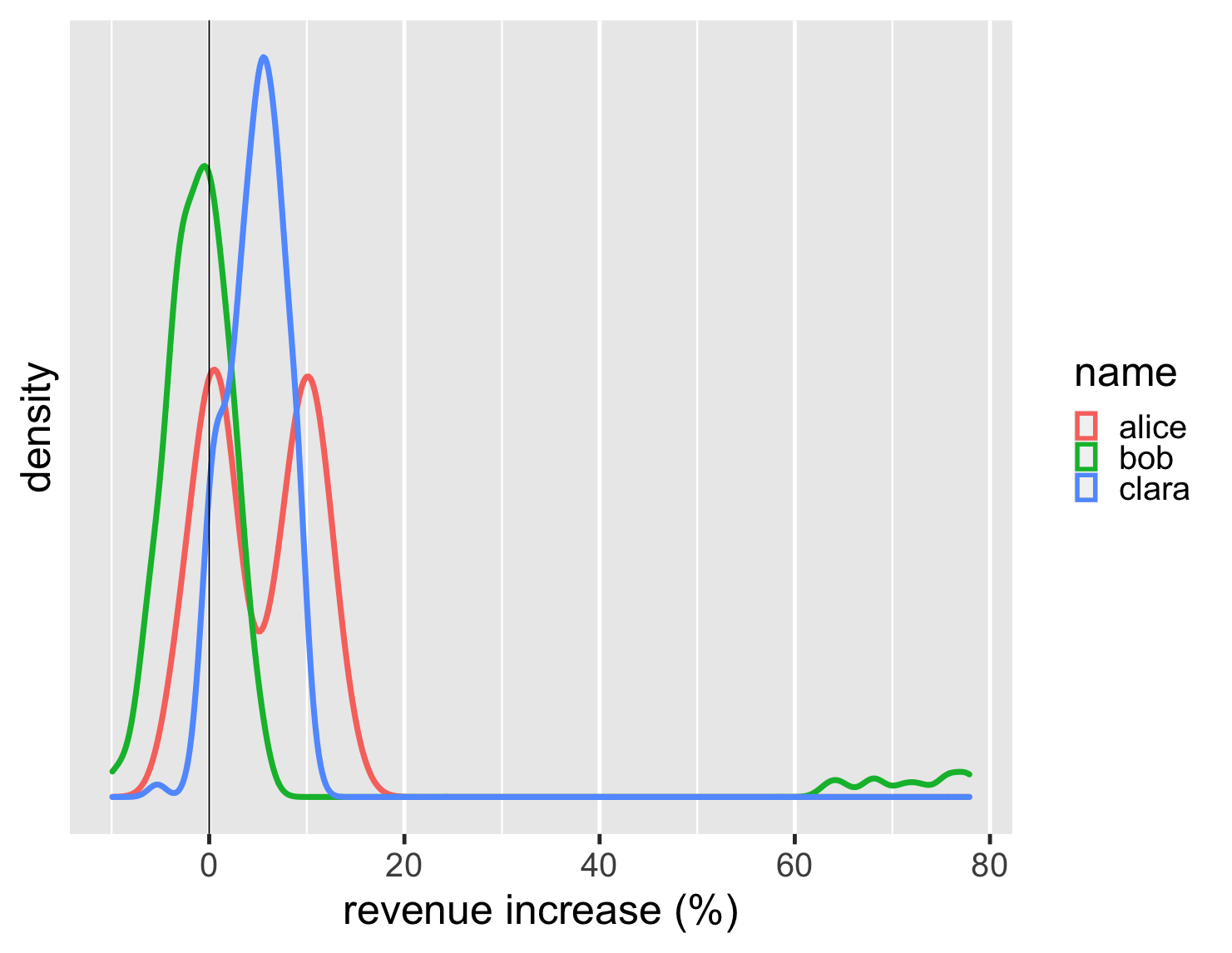
コードを表示
ggplot(large_sales, aes(value, color=name)) + geom_density(size=2) + scale_y_continuous(breaks = NULL) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30)
ヒストグラムと密度プロットは、より多くのデータポイントがある場合に効果的ですが、最初の例のようにデータポイントがわずかしかない場合はあまり役に立ちません。レビューサイトの5つ星評価など、値がわずかしかない場合は、カウントの棒グラフが役立ちます。数年前、Amazonはレビューにこのようなチャートを追加し、平均スコアに加えて分布も表示しました。
ボックスプロットは、多くの比較に適しています。
ヒストグラムと密度プロットは、異なる形状の分布を比較する良い方法ですが、グラフがいくつかを超えると比較が難しくなります。分布内の一般的に定義された範囲と位置を把握することも役立ちます。ここで、ボックスプロットが役立ちます。
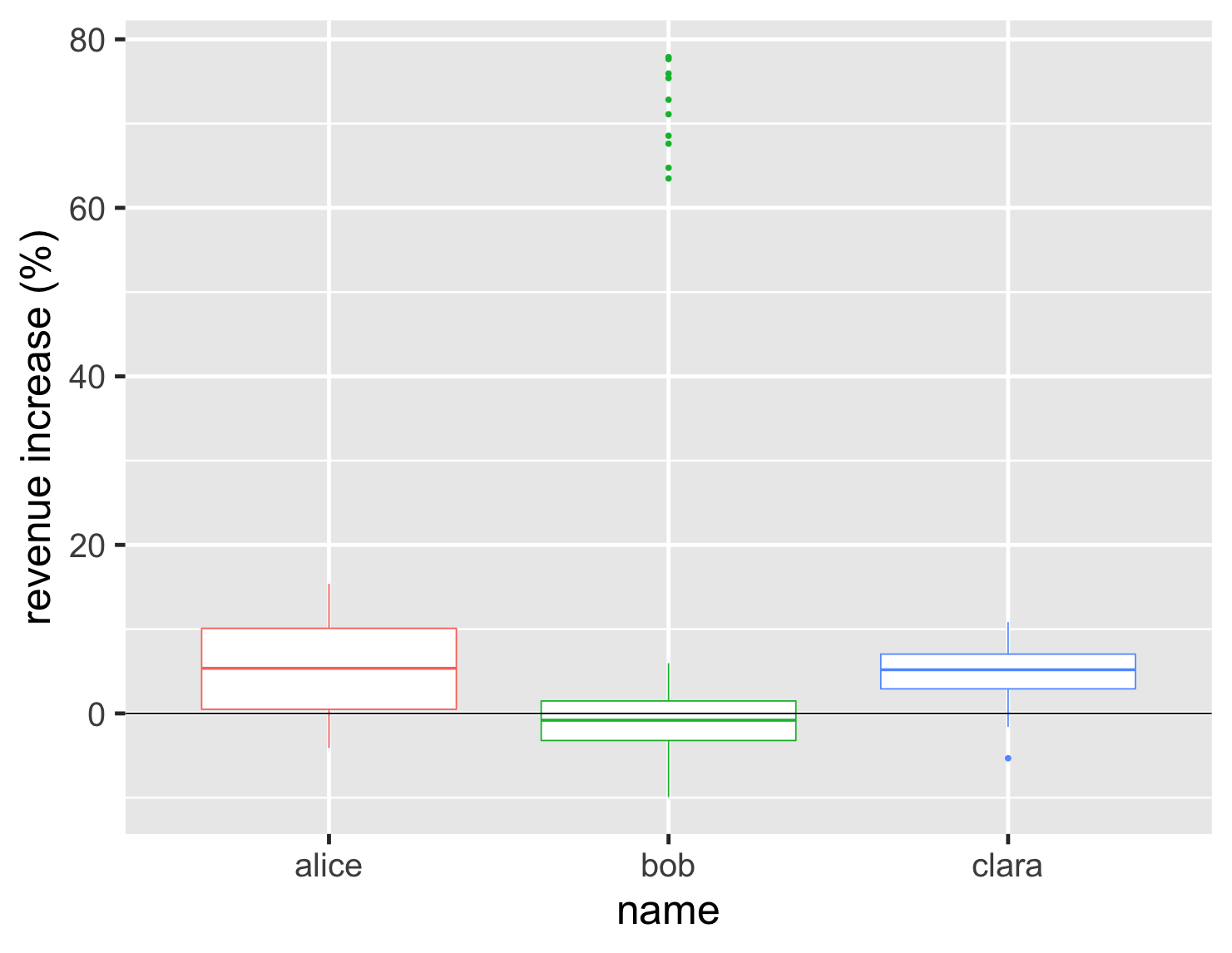
コードを表示
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
ボックスプロットは、データの中央範囲に注目を集めるため、データポイントの半分がボックス内にあります。グラフを見ると、ボブのアカウントの半分以上が縮小し、彼の第3四分位数がクララの第1四分位数よりも低いことがわかります。また、グラフの上端に彼のホットアカウントのクラスタが表示されます。
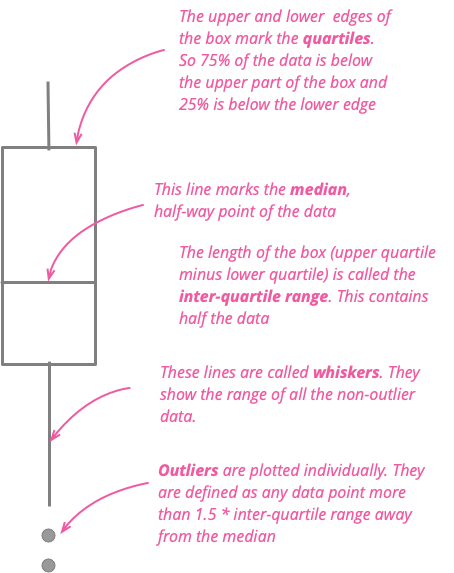
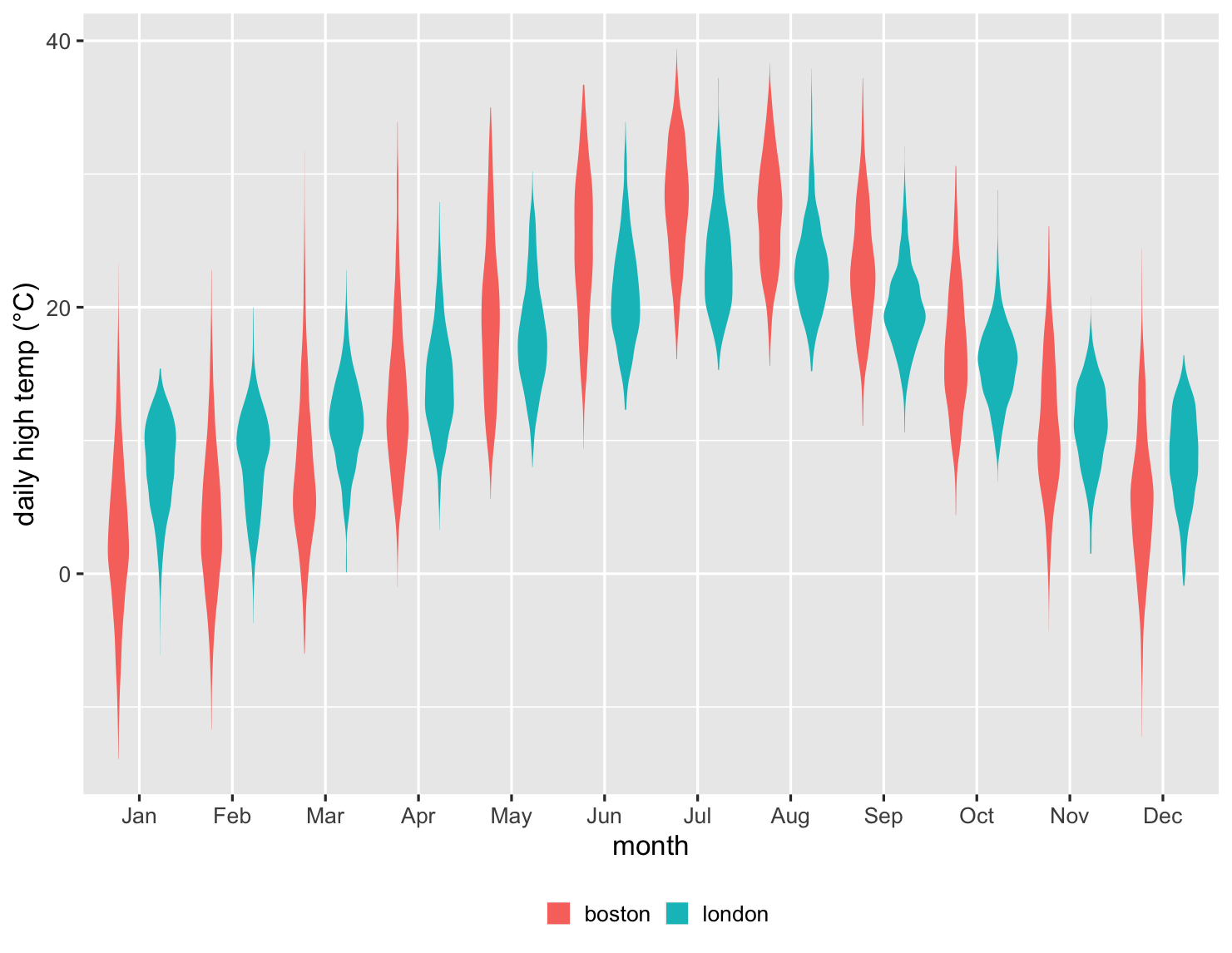
箱ひげ図は、比較する項目が数十個程度であれば効果的に機能し、基礎となるデータの概要を適切に示します。その例を以下に示します。私は1983年にロンドンに移り住み、10年後にはボストンに移りました。英国人である私は、当然のことながら、両都市の天候を比較して考えます。そこで、1983年以降の両都市の毎月の最高気温を比較したグラフを示します。
コードを表示
ggplot(temps, aes(month, high_temp, color=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + scale_x_discrete(labels=month.abb) + labs(color = NULL) + theme(legend.position = "bottom") + geom_boxplot()
これは印象的なグラフです。27,000を超えるデータポイントを要約しているからです。冬のロンドンの平均気温がボストンよりも高く、夏のロンドンの平均気温がボストンよりも低いことがわかります。しかし、各月の変動を比較することもできます。1月のボストンでは、気温が氷点下を下回らない割合が4分の1以上あることがわかります。ボストンの第3四分位数は、ロンドンの第1四分位数よりわずかに高いだけで、新しい住まいの寒さを明確に示しています。しかし、1月のボストンが、ロンドンの冬の月の最高気温よりも高い場合もあることもわかります。
しかし、箱ひげ図には弱点もあります。データの正確な形状ではなく、一般的に定義された集約点しか見えないことです。アリスとクララの比較では、ヒストグラムや密度グラフのように、アリスの分布における二峰性が見えないため、問題となる可能性があります。
これにはいくつかの回避策があります。1つは、箱ひげ図とストリップチャートを簡単に組み合わせることができることです。
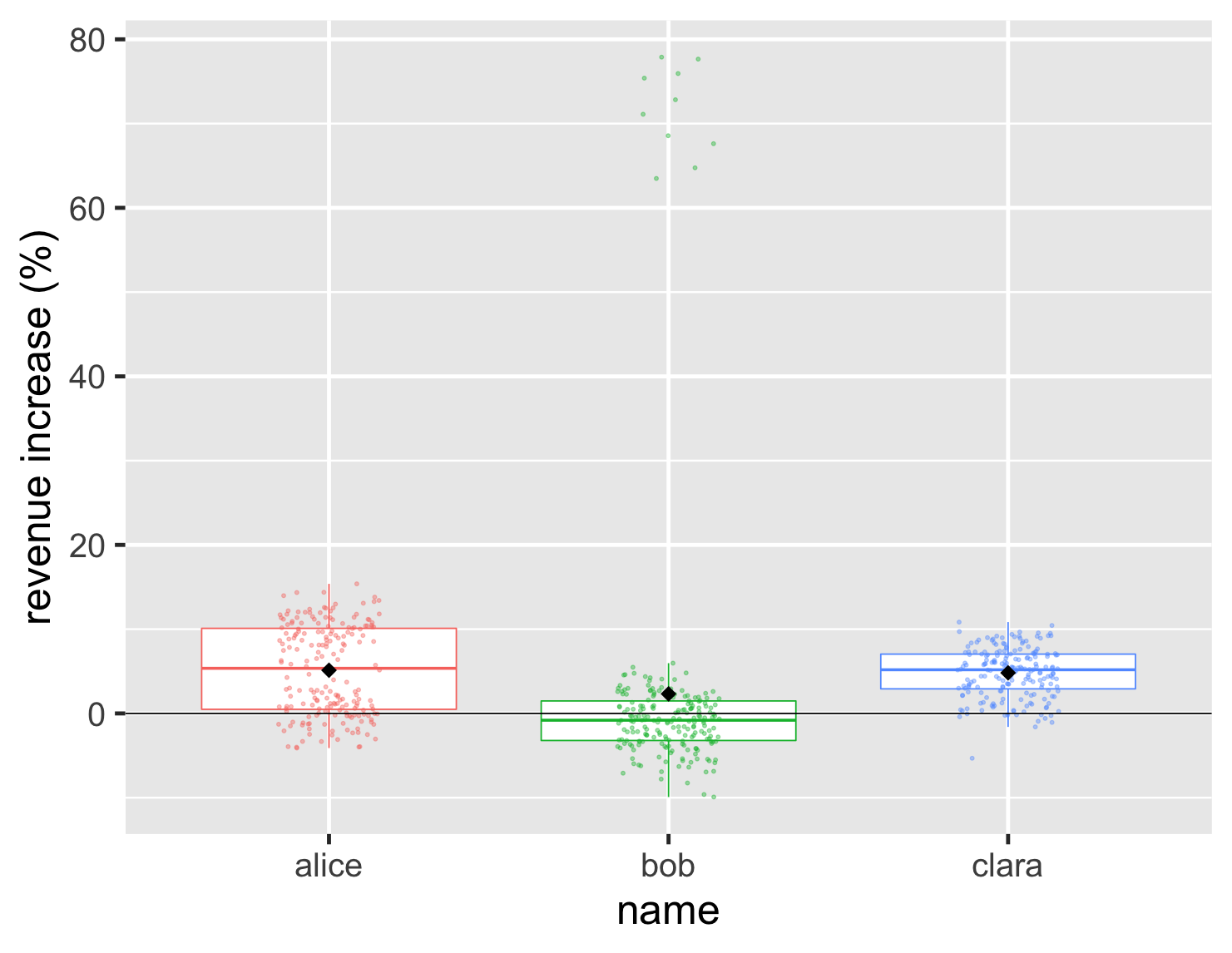
コードを表示
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE, outlier.shape = NA) + geom_jitter(width=0.15, alpha = 0.4, size=1, show.legend=FALSE) + ylab(label = "revenue increase (%)") + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + geom_hline(yintercept = 0) + theme_grey(base_size=30)
これにより、基礎となるデータと重要な集約値の両方を表示できます。このプロットでは、平均の位置を示すために以前使用した黒色のダイヤモンドも含まれています。これは、平均と中央値が大きく異なるボブのようなケースを強調するのに良い方法です。
もう1つのアプローチはバイオリンプロットです。これは、箱の側面に密度プロットを描画します。
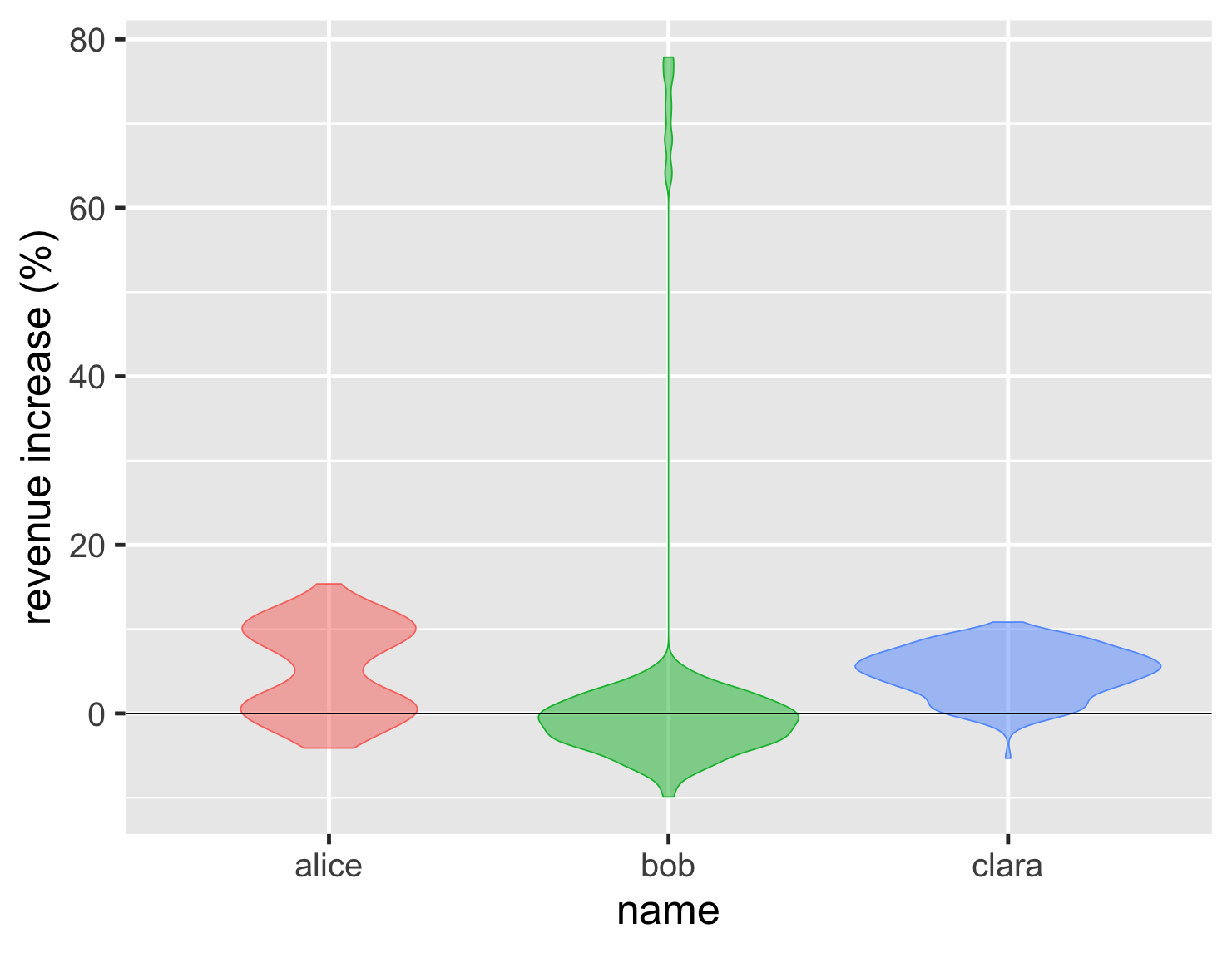
コードを表示
ggplot(large_sales, aes(name, value, color=name, fill=name)) + geom_violin(show.legend=FALSE, alpha = 0.5) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
これには、分布の形状を明確に示すという利点があるため、アリスのパフォーマンスの二峰性がすぐにわかります。密度プロットと同様に、多くのデータポイントがある場合にのみ効果的になります。売上高の例では、箱の中の点を表示した方が良いと思いますが、27,000個の気温測定値がある場合は、トレードオフが変わります。
コードを表示
ggplot(temps, aes(month, high_temp, fill=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + labs(fill = NULL) + scale_x_discrete(labels=month.abb) + theme(legend.position = "bottom") + geom_violin(color = NA)
ここでは、バイオリンプロットが各月のデータの形状をうまく示していることがわかります。しかし、全体的には、このデータの箱ひげ図の方が便利だと思います。中央値や四分位数などのデータの重要な指標を使用して比較する方が簡単です。これは、少なくともデータを探索している間は、複数のプロットが役割を果たすもう1つの例です。箱ひげ図が最も有用である場合が多いですが、バイオリンプロットをざっと見て、奇妙な形状がないかを確認する価値はあります。
まとめ
- 基礎となる分布を理解しない限り、平均値だけでグループを比較しないでください。
- 平均値だけのデータを示された場合は、「分布はどうなっていますか?」と質問してください。
- グループの比較方法を調べている場合は、いくつかの異なるプロットを使用して、その形状と最適な比較方法を調べます。
- 「平均」を求められた場合は、平均値と中央値のどちらが良いかを確認してください。
- グループ間の違いを示す場合、ここで示したグラフを少なくとも検討し、複数のグラフを使用することを恐れないでください。そして、重要な特徴を最もよく示すグラフを選択してください。
- 何よりも:**分布をプロットしましょう!**
謝辞
Adriano Domeniconi、David Colls、David Johnston、James Gregory、John Kordyback、Julie Woods-Moss、Kevin Yeung、Mackenzie Kordyback、Marco Valtas、Ned Letcher、Pat Sarnacke、Saravanakumar Saminathan、Tiago Griffo、およびXiao Guoは、社内メーリングリストでこの記事の下書きについてコメントしてくれました。
参考文献
Cédric Schererは、箱ひげ図、バイオリンプロット、ストリップチャートの特徴をコンパクトな表記で組み合わせたRaincloud Plotsのアプローチを紹介しています。彼のチュートリアルは、Allen et alの論文に基づいています。
Rを学ぶ私の経験
私が初めてRに出会ったのは約15年前、同僚と統計的問題について少し仕事をしたときです。学校では多くの数学を学びましたが、統計学は避けました。統計学が提供する洞察には非常に興味がありましたが、必要な計算量に妨げられていました。私は数学は得意でしたが、算数は苦手という奇妙な特性を持っています。
私はRが好きでした。特に、他の場所ではほとんど利用できないチャートをサポートしていたからです(そして、私はスプレッドシートの使用がそれほど好きではありませんでした)。しかし、Rは、JavaScriptを安全に見せるほど危険な近隣を持つプラットフォームです。しかし、近年、Hadley Wickham(RのBaron Haussmann)の仕事のおかげで、Rを使うことがはるかに簡単になりました。彼は「tidyverse」と呼ばれる一連のライブラリの開発を主導し、Rを非常に使いやすくしました。この記事のすべてのプロットは、彼のggplot2ライブラリを使用しています。
近年、私は定量的データを使用するレポートを作成するためにRをますます使用しており、プロットだけでなく計算にもRを使用しています。ここでは、tidyverse dplyrライブラリが大きな役割を果たしています。基本的に、表形式データに対する一連の操作を形成できます。あるレベルでは、コレクションパイプラインはテーブルの行に対して機能し、行をマップおよびフィルタリングするための関数があります。その後、結合やピボットなどのテーブル指向の操作をサポートすることで、さらに機能が拡張されます。
そのような優れたソフトウェアを作成するだけでは不十分である場合、彼はRの使用を学ぶための優れた本も共著しています。R for Data Science。これは、データ分析に関する優れたチュートリアル、tidyverseの概要、そして頻繁な参照として役立つことがわかりました。データの操作と可視化に興味があり、その仕事のための本格的なツールを実際に使用したい場合は、この本が最適です。Rコミュニティは、データサイエンスの概念とツールの両方を説明するのに役立つこの本やその他の本で素晴らしい仕事をしてきました。tidyverseコミュニティは、R Studioと呼ばれる一流のオープンソースの編集および開発環境も構築しました。Rを使用する際には、通常EmacsよりもR Studioを使用するということを付け加えておきます。
Rは確かに完璧ではありません。プログラミング言語としては驚くほど奇妙であり、単純なdplyr/ggplot2パイプラインの並木道から逸脱する勇気はありませんでした。データが豊富な環境で本格的なプログラミングを行いたい場合は、Pythonへの切り替えを真剣に検討するでしょう。しかし、私が行う種類のデータ作業では、Rのtidyverseは優れたツールであることが証明されています。
優れたストリップチャートのためのトリック
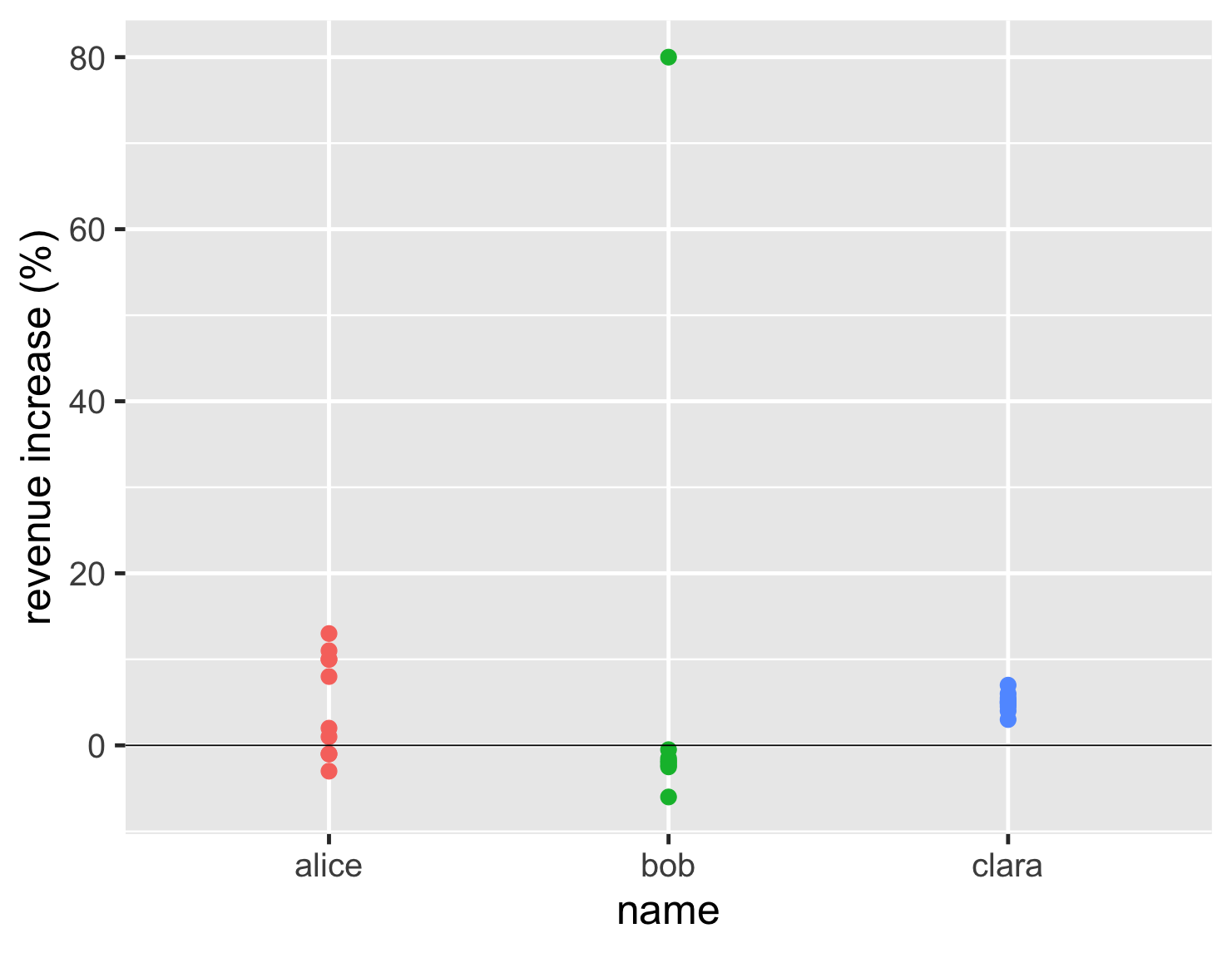
ストリップチャートを使用する際に、よく使う便利なトリックがいくつかあります。多くの場合、類似した値、またはまったく同じ値を持つデータポイントがあります。それらを単純にプロットすると、このようなストリップチャートになります。
コードを表示
ggplot(sales, aes(name, d_revenue, color=name)) + geom_point(size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_gray(base_size=30)
このプロットはまだ最初の棒グラフよりも優れており、ボブの異常値が彼の通常の成績とどのように異なるかを明確に示しています。しかし、クララには非常に多くの類似した値があるため、すべてが互いに重なり合ってしまい、いくつあるのかがわかりません。
私が使用する最初のトリックは、ジッターを追加することです。これにより、ストリップチャートの点にランダムな水平方向の動きが追加され、それらが広がり、区別できるようになります。2つ目は、点を部分的に透明にすることで、点が互いに重なっているときに確認できるようにすることです。これらの2つのトリックを使用することで、データポイントの数と位置を適切に理解できます。
ヒストグラムのビン幅の調査
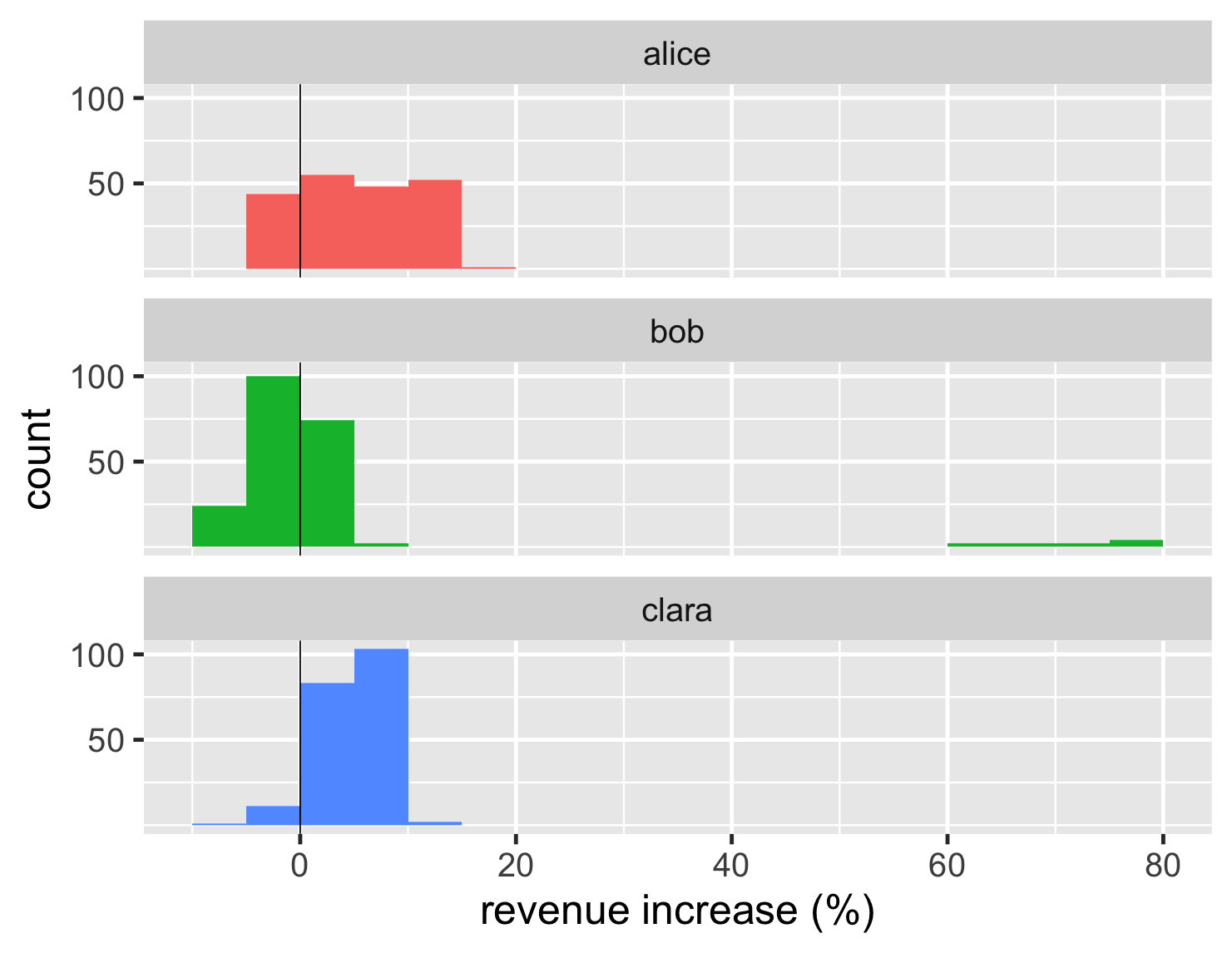
ヒストグラムは、データをビンに分割することによって機能します。したがって、ビン幅が1%の場合、収益増加率が0〜1%のすべてのアカウントは同じビンに入れられ、グラフには各ビンにあるアカウントの数がプロットされます。したがって、ビンの幅(または量)は、私たちが見るものに大きな影響を与えます。このデータセットに対して大きなビンを作成すると、次のプロットが得られます。
コードを表示
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 5, boundary=0,show.legend=FALSE) + scale_y_continuous(breaks = c(50,100)) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
ここでは、ビンが広すぎるため、アリスの分布の2つのピークを見ることができません。
反対の問題は、ビンが狭すぎるとプロットがノイズになることです。そのため、ヒストグラムをプロットする際には、ビンの幅を試行錯誤し、データの興味深い特徴を明らかにするのに役立つ値を探します。
脚注
1: SQLiteの拡張関数貢献ファイルは、中央値を含む多くの便利な関数があるので、うまく活用しました。
重要な改訂
2020年9月24日:公開
2020年9月18日:下書き開始