
モノリスからデータリッチなサービスを抽出する方法
モノリスをより小さなサービスに分割する際、最も難しいのは、実際にはモノリスのデータベースに存在するデータを分割することです。データリッチなサービスを抽出するには、常にデータの書き込みコピーを1つ保持する一連の手順に従うと便利です。この手順は、既存のモノリスを論理的に分離することから始まります。つまり、サービス動作を別のモジュールに分割し、次にデータを別のテーブルに分割します。これらの要素は、独立した新しいサービスに個別に移行できます。
2018年8月30日

プラフル・トドカーはThoughtworksのプリンシパルコンサルタントであり、大規模な分散型ビジネスソフトウェアシステムの構築を専門としています。ソフトウェアを構築する際、彼は2つのことを愛しています。それは、ビジネス価値をできるだけ早く提供することと、複雑な問題に対するシンプルでエレガントなソリューションを構築することです。この2つを組み合わせることができれば、なお良いでしょう。
目次
- サービス抽出の指針
- サービス抽出の手順
- ステップ 1. 新しいサービスに関連するロジックとデータを特定する
- ステップ 2. モノリス内で新しいサービスのロジックを論理的に分離する
- ステップ 3. モノリス内で新しいサービスのロジックをサポートする新しいテーブルを作成する
- ステップ 4. モノリシックデータベース内のテーブルを参照する新しいサービスを構築する
- ステップ 5. クライアントを新しいサービスに向ける
- ステップ 6. 新しいサービスのデータベースを作成する
- ステップ 7. モノリスから新しいデータベースにデータを同期する
- ステップ 8. 新しいサービスを新しいデータベースに向ける
- ステップ 9. 新しいサービスに関連するロジックとスキーマをモノリスから削除する
- まとめ
業界では、モノリスからより小さなサービスへの移行が大きく進んでいます。組織がこの移行に投資する主な理由は、ビジネス機能を中心に構築されたより小さなサービスが、開発者の生産性を向上させるためです。これらのより小さなサービスを所有できるチームは、「自分の運命の支配者」になることができ、システムの他のサービスとは独立してサービスを進化させることができます。
モノリスをより小さなサービスに分割する際、最も難しいのは、実際にはモノリスのデータベースに存在するデータを分割することです。モノリスのロジックをより小さなパーツに分割するのは比較的簡単ですが、それでも同じデータベースに接続しています。この場合、データベースは本質的に統合データベースであり、独立して進化できる分散システムの印象を与えますが、実際にはデータベースレベルで密結合された単一のシステムです。サービスが真に独立しており、したがってチームが「自分の運命の支配者」であるためには、サービスの独立したデータベース(スキーマとそれに対応するデータ)も必要です。
この記事では、サービスコンシューマーへの混乱を最小限に抑えながら、モノリスからデータリッチなサービスを抽出するための一連の手順であるパターンについて説明します。
サービス抽出の指針
実際のパターンに入る前に、サービス抽出に不可欠な2つの指針について説明したいと思います。これらは、モノリスが存在する世界から複数の小さなサービスへのスムーズで安全な移行を可能にするのに役立ちます。
移行期間中、データの書き込みコピーを一つにする
移行期間中、抽出対象のサービスのデータは単一の書き込みコピーになります。クライアントが書き込むことができるデータの複数のコピーがあると、書き込み競合が発生する可能性があります。書き込み競合は、同じデータが複数のクライアントによって同時に書き込まれる場合に発生します。書き込み競合を処理するためのロジックは複雑です。たとえば、「後書き勝ち」のようなスキームを選択すると、クライアントの観点からは望ましくない結果が生じる可能性があります。また、書き込みが失敗したクライアントに通知して、修正措置を講じさせることもできます。このようなロジックを書くことは複雑さを伴い、避けるのが最善です。
ここで説明するサービス抽出パターンでは、書き込み競合の管理に伴う複雑さを回避するために、抽出対象のサービスに対して任意の時点で単一の書き込みコピーが存在することが保証されます。
「アーキテクチャ進化の原子ステップ」の原則を尊重する
私の同僚であるZhamak Dehghaniは、「アーキテクチャ進化の原子ステップ」という用語を作りました。これは、アーキテクチャ移行の過程で原子的に(すべてまたはなしで)実行される一連の手順です。一連の手順の最後に、アーキテクチャは約束された報酬を生み出します。手順が完全に実行されない場合(途中で中断された場合)、アーキテクチャは開始した状態よりも悪い状態になります。たとえば、サービスを抽出すると決定し、ロジックのみをプルしてデータはプルしない場合、データベース層で結合されたままになり、開発と実行時の結合が発生します。これにより、大きな複雑さが生じ、単一のモノリスの場合よりも、開発やデバッグの問題がはるかに難しくなる可能性があります。
以下のサービス抽出パターンでは、特定のサービスに対してリストされているすべての手順を完了することをお勧めします。サービス抽出パターンにおける最大のハードルの1つは、実際には技術的なものではなく、モノリスの既存のすべてのクライアントを新しいサービスに移行させるための組織的な調整を行うことです。これについては、ステップ5で詳しく説明します。
サービス抽出の手順
それでは、実際のサービス抽出パターンを見ていきましょう。手順を理解しやすくするために、例を挙げて、サービス抽出がどのように機能するかを理解します。
たとえば、eコマースプラットフォームに製品情報を提供するモノリシックなカタログシステムがあるとします。時間の経過とともに、カタログシステムはモノリスに成長しました。つまり、製品名、カテゴリ名、および関連するロジックなどのコア製品情報とともに、製品価格のロジックとデータも吸収しています。システムのコア製品部分と価格設定部分の間には、明確な境界線がありません。
さらに、システムの価格設定部分での変更率(システムに導入される変更率)は、コア製品よりもはるかに高くなっています。データアクセスパターンも、システムの2つの部分で異なります。製品の価格は、コア製品属性よりもはるかに動的に変化します。したがって、モノリスから価格設定部分を独立して進化できる別のサービスに引き出すことは非常に理にかなっています。
コア製品ではなく価格設定をプルアウトすることが説得力がある理由は、価格設定がカタログモノリスの「リーフ」依存関係であるためです。コア製品機能は、製品在庫、製品マーケティングなど、モノリス内の他の機能の依存関係でもあります。これらは簡単にするためにここでは示されていません。コア製品をサービスとしてプルアウトすると、同時にモノリス内のあまりにも多くの「接続」を切断することになり、移行プロセスが非常に危険になる可能性があります。まず、価格設定機能など、モノリスの依存関係グラフでリーフ依存関係である貴重なビジネス機能を分離する必要があります。
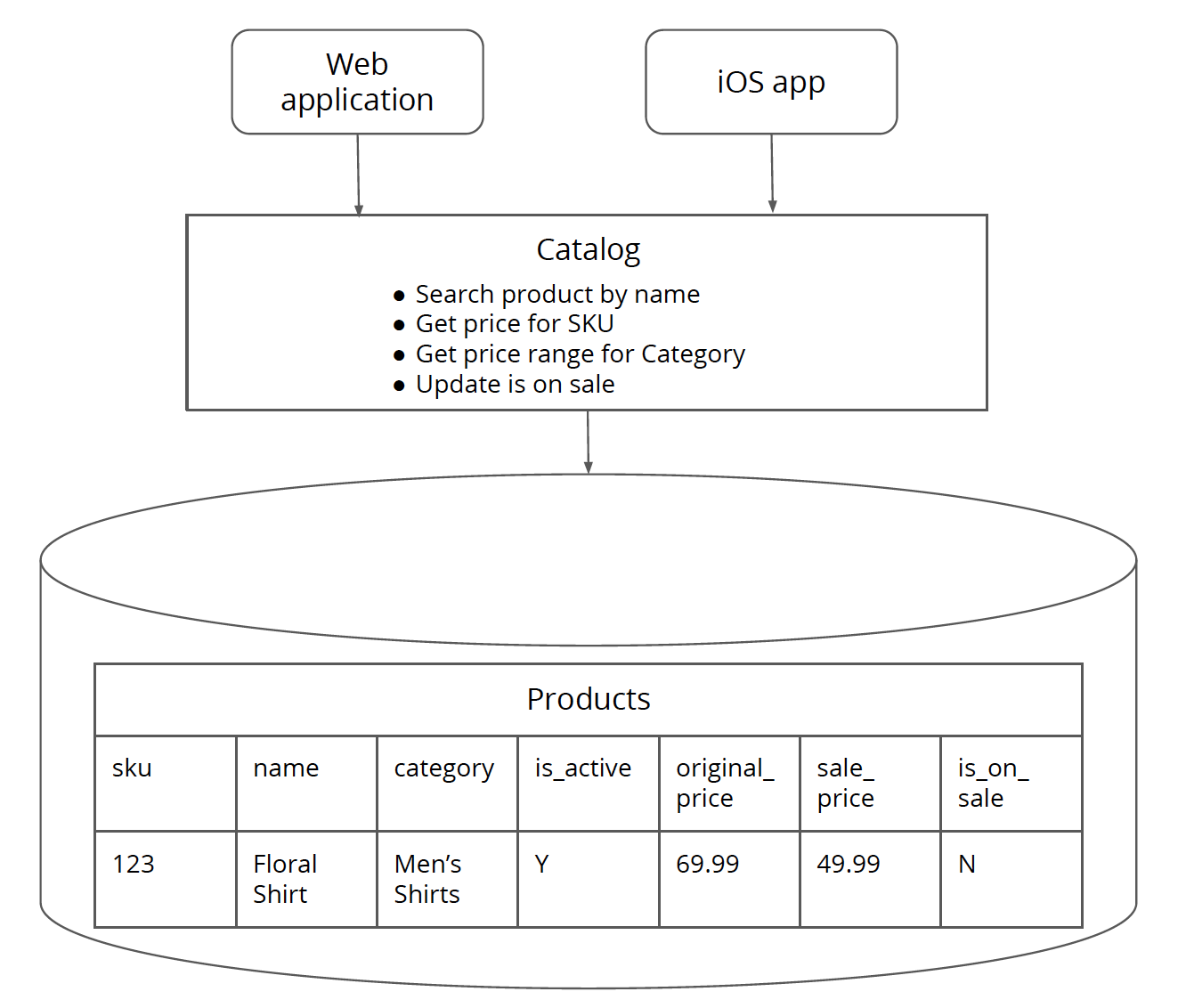
図 1: カタログモノリスは、コア製品と製品価格設定の両方のアプリケーションロジックとデータベースで構成されています。カタログモノリスには、WebアプリケーションとiOSアプリの2つのクライアントがあります。
コードの初期状態
以下は、カタログシステムのコードの初期状態です。明らかに、コードには現実世界の「乱雑さ」、つまりそのようなシステムの複雑さが欠けています。ただし、データリッチなサービスをモノリスからプルアウトするリファクタリングの精神を示すのに十分な複雑さです。以下のコードが、手順を進めるにつれてどのようにリファクタリングされるかを見ていきます。
コードは、モノリスがクライアントに提供するインターフェースを表すCatalogServiceで構成されています。データベースから状態をフェッチして永続化するために、productRepositoryクラスを使用します。Productクラスは、製品情報を含むダミーデータクラス(貧血ドメインモデルを示す)です。ダミーデータクラスは明らかにアンチパターンですが、この記事の主な焦点ではないため、この例に関する限り、これで済ませます。Sku、Price、CategoryPriceRangeは「Tiny Types」です。
class CatalogService…
public Sku searchProduct(String searchString) {
return productRepository.searchProduct(searchString);
}
public Price getPriceFor(Sku sku) {
Product product = productRepository.queryProduct(sku);
return calculatePriceFor(product);
}
private Price calculatePriceFor(Product product) {
if(product.isOnSale()) return product.getSalePrice();
return product.getOriginalPrice();
}
public CategoryPriceRange getPriceRangeFor(Category category) {
List<Product> products = productRepository.findProductsFor(category);
Price maxPrice = null;
Price minPrice = null;
for (Product product : products) {
if (product.isActive()) {
Price productPrice = calculatePriceFor(product);
if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) {
maxPrice = productPrice;
}
if (minPrice == null || productPrice.isLesserThan(minPrice)) {
minPrice = productPrice;
}
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
public void updateIsOnSaleFor(Sku sku) {
final Product product = productRepository.queryProduct(sku);
product.setOnSale(true);
productRepository.save(product);
}
「製品価格設定」サービスをカタログモノリスからプルアウトするための最初のステップを踏み出しましょう。
ステップ 1. 新しいサービスに関連するロジックとデータを特定する
最初のステップは、モノリスに存在する製品価格設定サービスに関連するデータとロジックを特定することです。カタログアプリケーションには、Productsテーブルがあり、name、SKU、category_name、およびis_activeフラグ(製品がアクティブか廃止かを示す)などのコア製品属性があります。各製品は製品カテゴリに属しています。製品カテゴリは製品のグループです。たとえば、「メンズシャツ」カテゴリには、「花柄シャツ」や「タキシードシャツ」などの製品があります。モノリスには、名前で製品を検索するなど、コア製品に関連するロジックがあります。
Productsテーブルには、original_price, sale_price、および製品がセール中かどうかを示すis_on_saleフラグなどの価格設定関連フィールドもあります。モノリスには、製品の価格を計算し、is_on_saleフラグを更新するなど、価格設定に関連するロジックがあります。カテゴリの価格範囲を取得するのは、主に製品価格設定ロジックですが、いくつかのコア製品ロジックも含まれているため、興味深いものです。
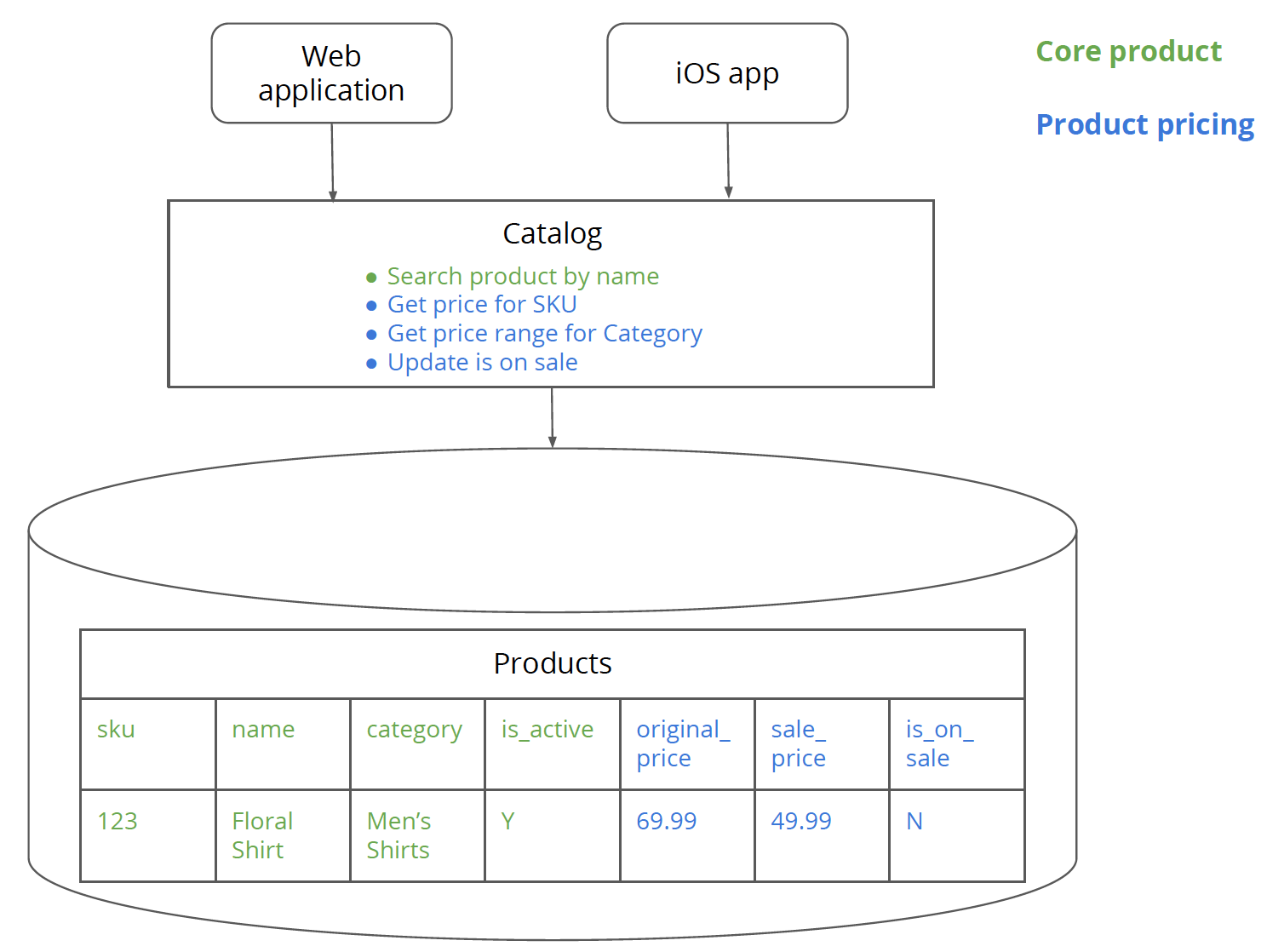
図2:コア製品のロジックとデータは緑色で強調表示され、製品価格設定のデータとロジックは青色で強調表示されています。
これは、前に見たのと同じコードですが、コア製品と製品価格設定のどちらに該当するコード部分を示すように色分けされています。
class CatalogService…
public Sku searchProduct(String searchString) { return productRepository.searchProduct(searchString); } public Price getPriceFor(Sku sku) { Product product = productRepository.queryProduct(sku); return calculatePriceFor(product); } private Price calculatePriceFor(Product product) { if(product.isOnSale()) return product.getSalePrice(); return product.getOriginalPrice(); } public CategoryPriceRange getPriceRangeFor(Category category) { List<Product> products = productRepository.findProductsFor(category); Price maxPrice = null; Price minPrice = null; for (Product product : products) { if (product.isActive()) { Price productPrice = calculatePriceFor(product); if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) { maxPrice = productPrice; } if (minPrice == null || productPrice.isLesserThan(minPrice)) { minPrice = productPrice; } } } return new CategoryPriceRange(category, minPrice, maxPrice); } public void updateIsOnSaleFor(Sku sku) { final Product product = productRepository.queryProduct(sku); product.setOnSale(true); productRepository.save(product); }
ステップ 2. モノリス内で新しいサービスのロジックを論理的に分離する
ステップ2と3は、モノリス内で作業しながら、製品価格設定サービスのロジックとデータの論理的な分離を作成することです。実際には、新しいサービスにプルアウトする前に、製品価格設定のデータとロジックをより大きなモノリスから分離します。これを行う利点は、製品価格設定サービスの境界(ロジックまたはデータ)を間違えた場合、コードを「ワイヤ越し」にプルアウトしてリファクタリングするのではなく、同じモノリスコードベース内でリファクタリングする方がはるかに簡単になるということです。
ステップ2では、製品価格とコア製品のロジックをそれぞれラップするサービス・クラスとして、ProductPricingServiceとCoreProductServiceを作成します。これらのサービス・クラスは、後のステップで見るように、「物理的な」サービスである製品価格とコア製品と一対一に対応します。また、個別のリポジトリ・クラスであるProductPriceRepositoryとCoreProductRepositoryも作成します。これらは、それぞれProductsテーブルから製品価格データとコア製品データにアクセスするために使用されます。
このステップで留意すべき重要な点は、ProductPricingServiceまたはProductPriceRepositoryがコア製品の情報のためにProductsテーブルにアクセスしないことです。代わりに、コア製品関連の情報については、製品価格コードはCoreProductServiceを介してのみアクセスする必要があります。この例は、リファクタリングされたgetPriceRangeForメソッドで後述します。
システムのコア製品部分に属するテーブルから、製品価格に属するテーブルへのテーブル結合は許可されません。同様に、コア製品データと製品価格データの間には、外部キーやデータベーストリガーなどの「ハードな」制約があってはなりません。結合と制約はすべて、データベース層からロジック層に移動する必要があります。これは残念ながら言うは易く行うは難しであり、最も難しいことの1つですが、データベースを分割するためには絶対に必要です。
そうは言っても、コア製品と製品価格は、システムの両部分でデータベースレベルまで製品を一意に識別する共通の識別子、製品SKUを持っています。この「クロスシステム識別子」は、クロスサービス通信(後のステップで実証)に使用されるため、この識別子を賢明に選択することが重要です。クロスシステム識別子を所有するのは1つのサービスである必要があります。他のすべてのサービスは、識別子を参照として使用する必要がありますが、変更してはなりません。それはそれらの観点から不変です。識別子が存在するエンティティのライフサイクルを管理するのに最適なサービスが、識別子を所有する必要があります。たとえば、この例では、コア製品が製品ライフサイクルを所有しているため、SKU識別子を所有します。
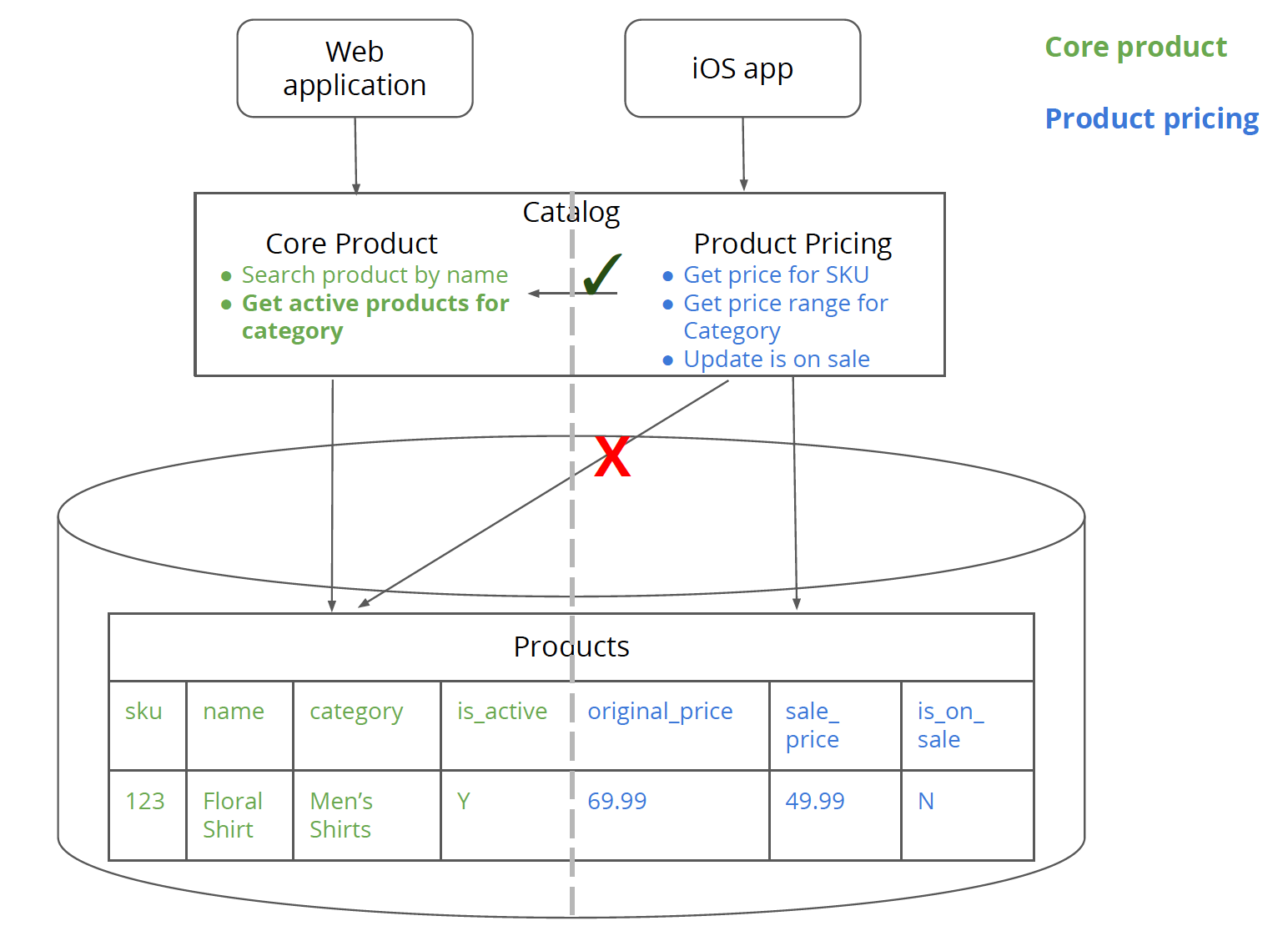
図3:同じProductsテーブルに接続しながら、コア製品ロジックと製品価格ロジック間の論理的な分離。
以下は、リファクタリングされたコードです。価格固有のロジックを保持する新しく作成されたProductPricingServiceが表示されます。また、Productsテーブルの価格固有のデータとやり取りするためのproductPriceRepositoryもあります。Productデータクラスの代わりに、それぞれ製品価格とコア製品データを保持するためのデータクラスProductPriceとCoreProductができました。
getPriceFor関数とcalculatePriceFor関数は、新しいproductPriceRepositoryクラスを指すように変換するのが非常に簡単です。
class ProductPricingService…
public Price getPriceFor(Sku sku) {
ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
return calculatePriceFor(productPrice);
}
private Price calculatePriceFor(ProductPrice productPrice) {
if(productPrice.isOnSale()) return productPrice.getSalePrice();
return productPrice.getOriginalPrice();
}
カテゴリの価格範囲を取得するロジックは、カテゴリに属する製品を知る必要があるため、より複雑になります。これはアプリケーションのコア製品部分に存在します。getPriceRangeForメソッドは、特定のカテゴリのアクティブな製品のリストを取得するために、coreProductServiceのgetActiveProductsForメソッドを呼び出します。ここで注意すべき点は、is_activeがコア製品の属性であることを考えると、isActiveチェックをcoreProductServiceに移動したことです。
class ProductPricingService…
public CategoryPriceRange getPriceRangeFor(Category category) {
List<CoreProduct> products = coreProductService.getActiveProductsFor(category);
List<ProductPrice> productPrices = productPriceRepository.getProductPricesFor(mapCoreProductToSku(products));
Price maxPrice = null;
Price minPrice = null;
for (ProductPrice productPrice : productPrices) {
Price currentProductPrice = calculatePriceFor(productPrice);
if (maxPrice == null || currentProductPrice.isGreaterThan(maxPrice)) {
maxPrice = currentProductPrice;
}
if (minPrice == null || currentProductPrice.isLesserThan(minPrice)) {
minPrice = currentProductPrice;
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
private List<Sku> mapCoreProductToSku(List<CoreProduct> coreProducts) {
return coreProducts.stream().map(p -> p.getSku()).collect(Collectors.toList());
}
特定のカテゴリのアクティブな製品を取得するための新しいgetActiveProductsForメソッドは次のようになります。
class CoreProductService…
public List<CoreProduct> getActiveProductsFor(Category category) {
List<CoreProduct> productsForCategory = coreProductRepository.getProductsFor(category);
return filterActiveProducts(productsForCategory);
}
private List<CoreProduct> filterActiveProducts(List<CoreProduct> products) {
return products.stream().filter(p -> p.isActive()).collect(Collectors.toList());
}
この例では、サービス・クラスにisActiveチェックを保持しましたが、これをデータベースクエリに簡単に移動できます。実際、機能を複数のサービスに分割するこのようなタイプのリファクタリングにより、ロジックをデータベースクエリに移動してコードのパフォーマンスを向上させる機会を簡単に見つけることができます。
updateIsOnSaleロジックも非常に簡単で、以下のようにリファクタリングする必要があります。
class ProductPricingService…
public void updateIsOnSaleFor(Sku sku) {
final ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
productPrice.setOnSale(true);
productPriceRepository.save(productPrice);
}
searchProductメソッドは、製品を検索するために新しく作成されたcoreProductRepositoryを指します。
class CoreProductService…
public Sku searchProduct(String searchString) {
return coreProductRepository.searchProduct(searchString);
}
CatalogService(モノリスへの最上位インターフェース)は、サービスメソッド呼び出しを適切なサービス(CoreProductServiceまたはProductPricingService)に委譲するようにリファクタリングされます。これは、モノリスのクライアントとの既存の契約を破らないために重要です。
searchProductメソッドは、coreProductServiceに委譲されます。
class CatalogService…
public Sku searchProduct(String searchString) {
return coreProductService.searchProduct(searchString);
}
価格関連のメソッドは、productPricingServiceに委譲されます。
class CatalogService…
public Price getPriceFor(Sku sku) {
return productPricingService.getPriceFor(sku);
}
public CategoryPriceRange getPriceRangeFor(Category category) {
return productPricingService.getPriceRangeFor(category);
}
public void updateIsOnSaleFor(Sku sku) {
productPricingService.updateIsOnSaleFor(sku);
}
ステップ 3. モノリス内で新しいサービスのロジックをサポートする新しいテーブルを作成する
このステップの一部として、価格関連のデータを新しいテーブルProductPricesに分割します。このステップの終了時に、製品価格ロジックは、Productsテーブルに直接アクセスするのではなく、ProductPricesテーブルにアクセスする必要があります。Productsテーブルからコア製品情報に関連する情報を必要とする場合は、コア製品ロジック層を介してアクセスする必要があります。このステップでは、特にサービス・クラスではなく、productPricingRepositoryクラスでのみコードを変更する必要があります。
このステップには、ProductsテーブルからProductPricesテーブルへのデータ移行が含まれることに注意することが重要です。新しいテーブルの列が、Productsテーブルの製品価格関連の列とまったく同じになるように設計してください。これにより、リポジトリコードが簡略化され、データ移行が簡単になります。productPricingRepositoryを新しいテーブルにポイントした後でバグに気付いた場合は、productPricingRepositoryコードをProductsテーブルに戻すことができます。このステップが正常に完了したら、Productsテーブルから製品価格関連のフィールドを削除することを選択できます。
ここで私たちが行っていることは、基本的に、テーブルを2つのテーブルに分割し、元のテーブルから新しく作成したテーブルにデータを移動するデータベース移行です。私の同僚であるPramod Sadalageは、このトピックについてもっと知りたい場合に確認すべき「データベースのリファクタリング」という本全体を執筆しました。簡単な参考資料として、PramodとMartin Fowlerによる進化的なデータベース設計の記事を参照してください。
このステップの終了時に、新しいサービスが機能要件、特にパフォーマンスに関するクロス機能要件の観点からシステム全体に与える可能性のある影響の兆候を得ることができるはずです。ロジック層での「インメモリデータ結合」のパフォーマンスへの影響を確認できるはずです。この例では、getPriceRangeForは、コア製品情報と製品価格情報の間でインメモリデータ結合を行います。ロジック層でのインメモリデータ結合は、データベース層でそれらの結合を行うよりも常にコストがかかりますが、それは分離されたデータシステムを持つことのコストです。この段階でパフォーマンスが低下する場合は、データがワイヤを介して物理サービス間を行き来するときに悪化します。パフォーマンス要件(またはその他の要件)が満たされていない場合は、サービス境界を再考する必要がある可能性があります。少なくとも、クライアント(WebアプリケーションとiOSアプリ)は、クライアントのやり取りをまだ変更していないため、この変更に対して大部分が透過的です。これにより、サービス境界を迅速かつ安価に実験できるという、このステップの美点が生まれます。
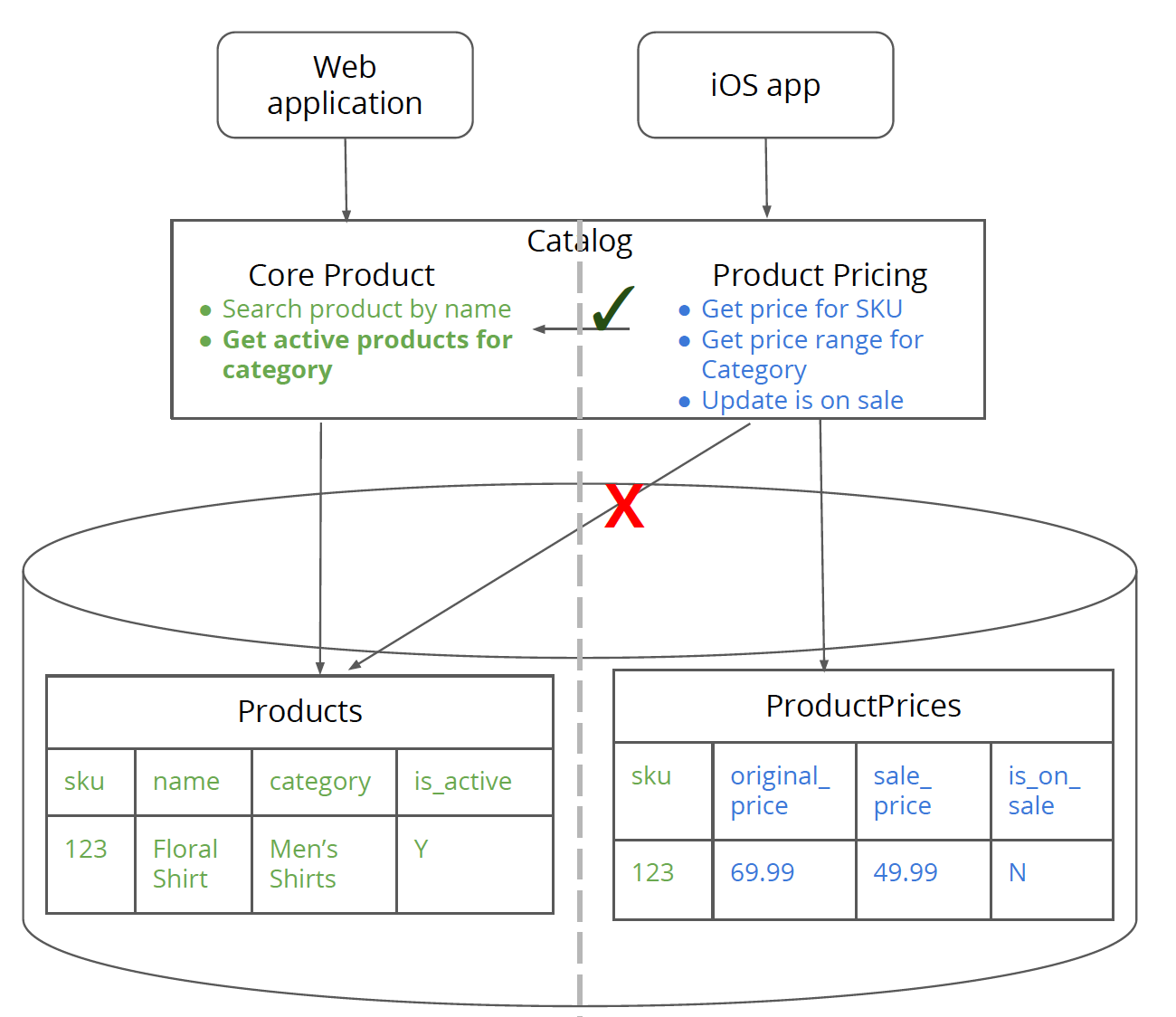
図4:コア製品ロジックとデータ、および製品価格ロジックとデータの間の論理的な分離。
ステップ 4. モノリシックデータベース内のテーブルを参照する新しいサービスを構築する
このステップでは、モノリスデータベースのProductPricesテーブルを指しながら、ProductPricingServiceのロジックを使用して、製品価格のまったく新しい「物理的な」サービスを構築します。この時点では、ProductPricingServiceからCoreProductServiceを呼び出すことはネットワーク呼び出しであり、タイムアウトなどのリモート呼び出しに関する問題を処理する必要があるため、パフォーマンスペナルティが発生します。これらは適切に処理する必要があります。
これは、ビジネスの意図ではなくソリューションのメカニズムを表すようにサービスをモデル化するために、製品価格サービスに対して「ビジネスの真実を語る」抽象化を作成する良い機会かもしれません。たとえば、ビジネスユーザーがupdateIsOnSaleフラグを更新するとき、実際には特定の製品に対してシステム内で「プロモーション」を作成しています。以下は、リファクタリング後のupdateIsOnSaleForの様子です。また、以前は利用できなかったこの変更の一部として、プロモーション価格を指定する機能も追加しました。これは、クライアントに漏れている可能性のあるサービス関連の複雑さの一部をサービスにプッシュバックすることで、インターフェースを簡略化する良い機会になる可能性があります。これは、サービスコンシューマーの観点から歓迎される変更でしょう。
class ProductPricingService…
public void createPromotion(Promotion promotion) { final ProductPrice productPrice = productPriceRepository.getPriceFor(promotion.getSku()); productPrice.setOnSale(true); productPrice.setSalePrice(promotion.getPrice()); productPriceRepository.save(productPrice); }
ただし、この制限事項は、テーブル構造やデータセマンティクスを変更してはならないということです。そうすると、モノリスの既存の機能が壊れてしまいます。サービスが完全に抽出されたら(ステップ9で)、ロジック層でコードを変更するのと同じくらい簡単にデータベースを変更できます。
クライアントに移動する前に、これらの変更を行うことをお勧めします。サービスのインターフェースを変更すると、特に大規模な組織では、さまざまなサービスコンシューマーが新しいインターフェースにタイムリーに移行するための同意が必要になるため、コストがかかり、時間がかかるプロセスになる可能性があるためです。これについては、次のステップで詳しく説明します。この新しい価格設定サービスを安全に本番環境にリリースしてテストできます。このサービスにはまだクライアントはありません。また、このステップでは、モノリス(WebアプリケーションとiOSアプリ)のクライアントに変更はありません。
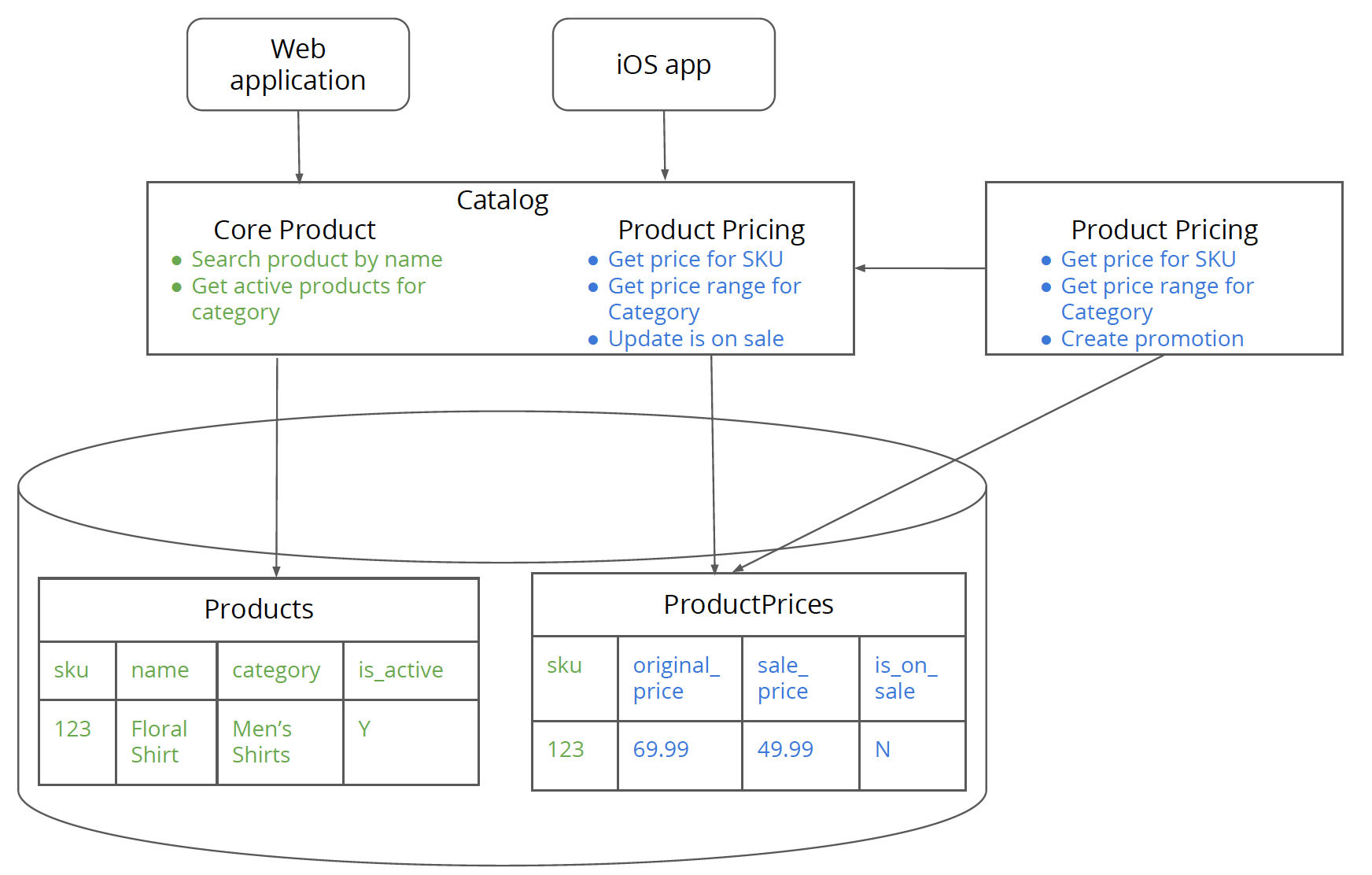
図5:コア製品機能のためにモノリスに依存しながら、モノリスのProductPricesテーブルを指す新しい物理的な製品価格設定サービス。
ステップ 5. クライアントを新しいサービスに向ける
このステップでは、製品価格機能に関心のあるモノリスのクライアントは、新しいサービスに移行する必要があります。このステップでの作業は、次の2つのことに依存します。まず、モノリスと新しいサービスの間でインターフェースがどの程度変更されたかに依存します。第二に、組織的な観点から言えば、クライアントチームがこのステップをタイムリーに完了するための帯域幅(キャパシティ)です。
このステップが長引くと、一部のクライアントは新しいサービスを指し、一部のクライアントはモノリスを指す、アーキテクチャが不完全な状態になる可能性が高くなります。これは、間違いなく、開始する前よりもアーキテクチャが悪い状態になります。これが、以前に説明した「アーキテクチャ進化の原子ステップ」原則が重要な理由です。新しいサービス機能のすべてのクライアントから、移行の旅を開始する前に、新しいサービスにタイムリーに移行するための組織的な連携があることを確認してください。アーキテクチャを中途半端な状態にしたまま、他の優先度の高い問題に気を取られやすいです。
良いお知らせとして、すべてのサービスクライアントがまったく同じタイミングで移行する必要はなく、互いに移行を調整する必要もありません。ただし、次のステップに進む前に、すべてのクライアントを移行することが重要です。もし存在しない場合は、「移行遅延者」を特定するために、価格関連のメソッドに対してサービスレベルでの監視を導入することができます。これは、新しいサービスに移行していないサービスコンシューマーのことです。
理論的には、クライアントが移行する前に、特に価格データベースの作成を含む次のステップなど、次のステップの一部に取りかかることができます。しかし、簡潔にするために、できる限り順番に進むことをお勧めします。
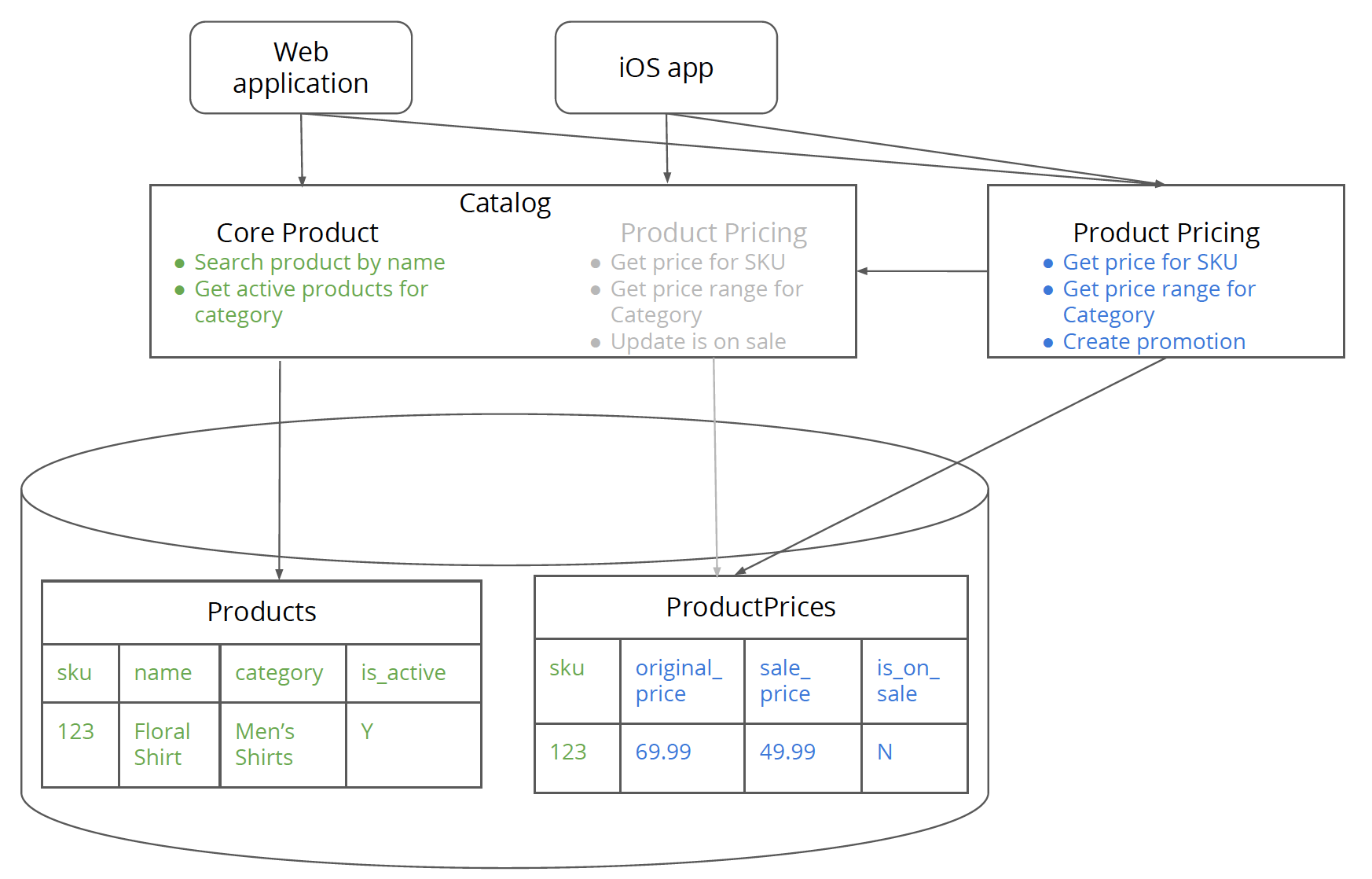
図6:価格機能に関心のあるモノリスのクライアントが、新しい製品価格サービスに移行しました。
ステップ 6. 新しいサービスのデータベースを作成する
このステップは比較的簡単で、モノリスのテーブル構造をミラーリングする価格データベースを構築します。新しいサービスを構築している際に、価格設定のためにまったく新しいスキーマを構築したくなるかもしれません。しかし、まったく新しいスキーマを持つと、後のステップでのデータ移行が難しくなります。また、新しい価格サービスは、モノリスからのスキーマと新しいデータベースからのスキーマという2つの異なるスキーマをサポートする必要があることを意味します。シンプルに保つことをお勧めします。まず、価格サービスを抽出(ここで言及したすべてのステップを完了)し、次に価格サービスの内部をリファクタリングします。価格データベースが分離されたら、クライアントが価格データベースに直接アクセスすることはないため、サービスのコードを変更するのと同じように簡単に変更できます。
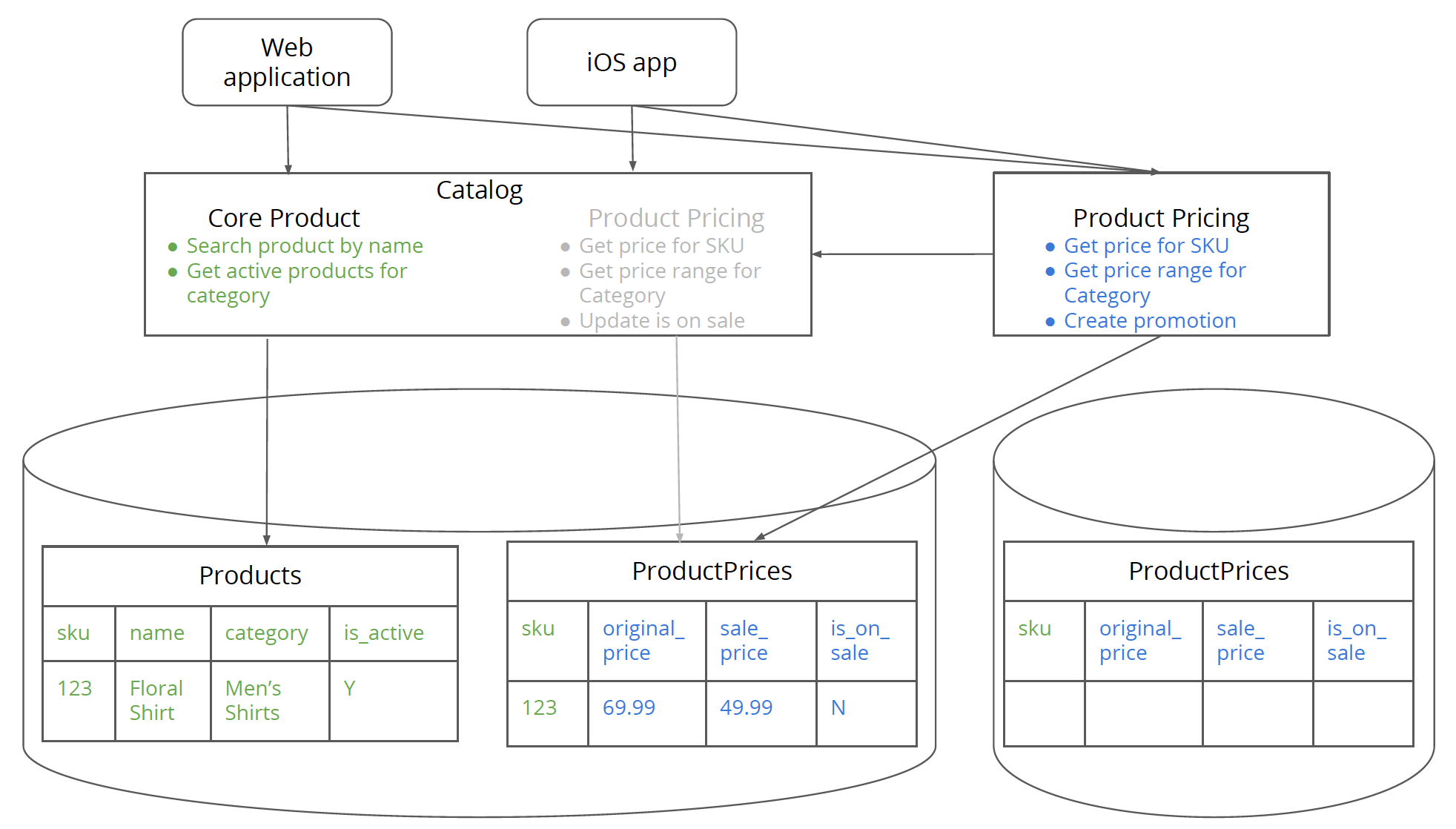
図7:新しいスタンドアロンの価格データベースが作成されました。
ステップ 7. モノリスから新しいデータベースにデータを同期する
このステップでは、モノリスデータベースの価格テーブルのデータを新しい価格データベースに同期します。新しいデータベースのスキーマがモノリスの価格テーブルと同じであれば、モノリスと新しいサービスデータベース間のデータ同期は非常に簡単です。これは、基本的には価格データベースをモノリスデータベースの「読み取り専用レプリカ」として設定するのと同じです(ただし、価格関連のテーブルのみ)。これにより、新しい価格データベースのデータが最新の状態に保たれます。
これで、次のステップで新しい価格データベースに価格サービスを接続する準備ができました。
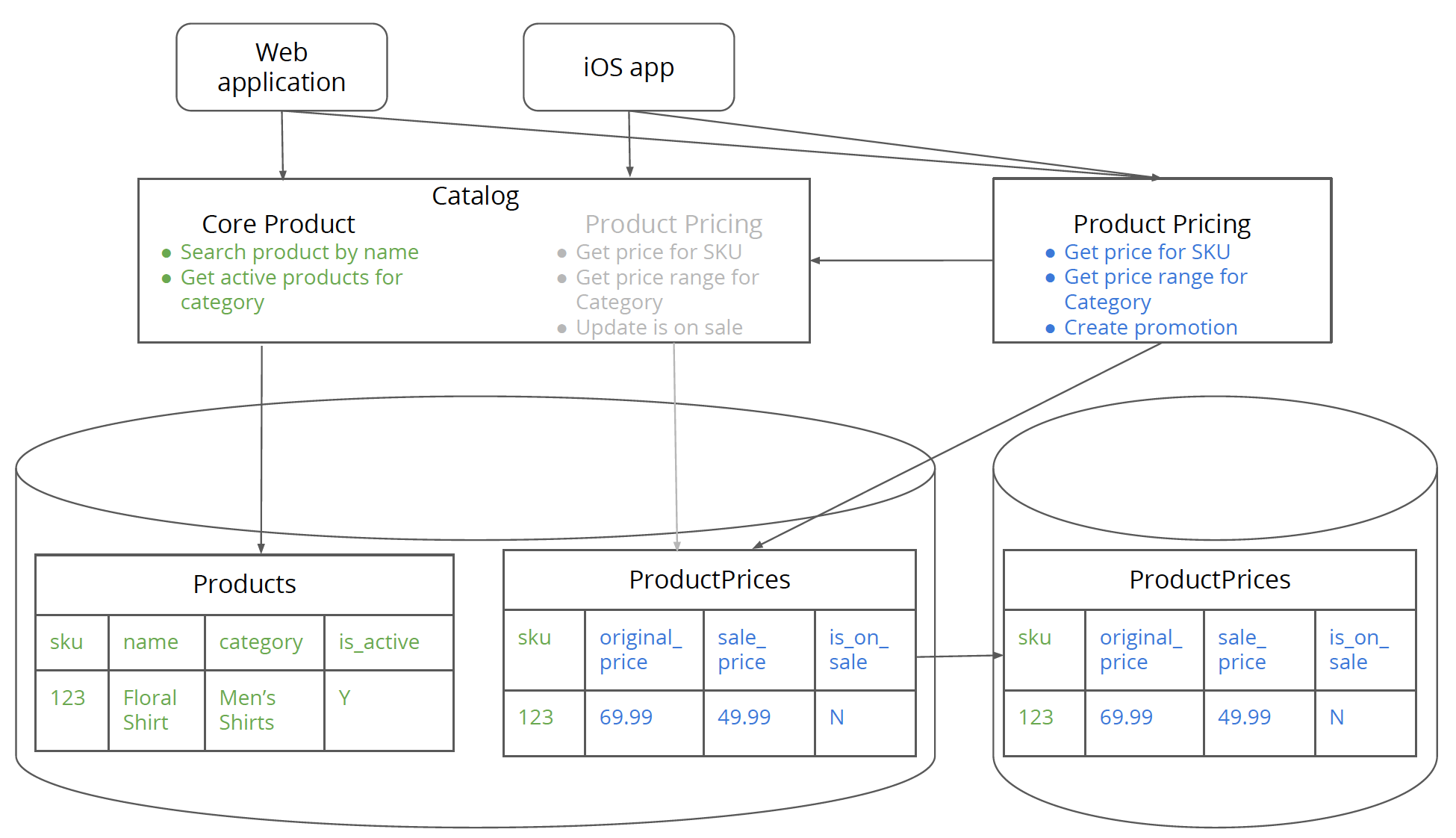
図8:製品価格関連のテーブルと新しい価格データベースのテーブル間でデータが同期されました。
ステップ 8. 新しいサービスを新しいデータベースに向ける
このステップを開始する前に、価格情報に関心のあるモノリスのすべてのクライアントが新しいサービスに移行していることが非常に重要です。そうでない場合、「データの単一書き込みコピーを持つ」という以前に議論した原則に違反する書き込み競合が発生する可能性があります。すべてのクライアントが新しいサービスに移行した後、価格サービスを新しい価格データベースに向けることができます。基本的には、モノリシックデータベースから新しいデータベースにデータベース接続を切り替えます。
この設計の利点の1つは、問題に気づいた場合に、接続を古いデータベースに簡単に切り替えることができることです。考えられる問題の1つは、新しいサービスのコードが、新しいデータベースには存在せず、古いデータベースにのみ存在するいくつかのテーブル/フィールドに依存していることです。これは、ステップ1でデータを特定できなかったために発生する可能性があります。これは、たとえばサポートされている通貨などの「参照」データで発生する可能性があります。これらの問題を正常に解決したら、次のステップに進むことができます。
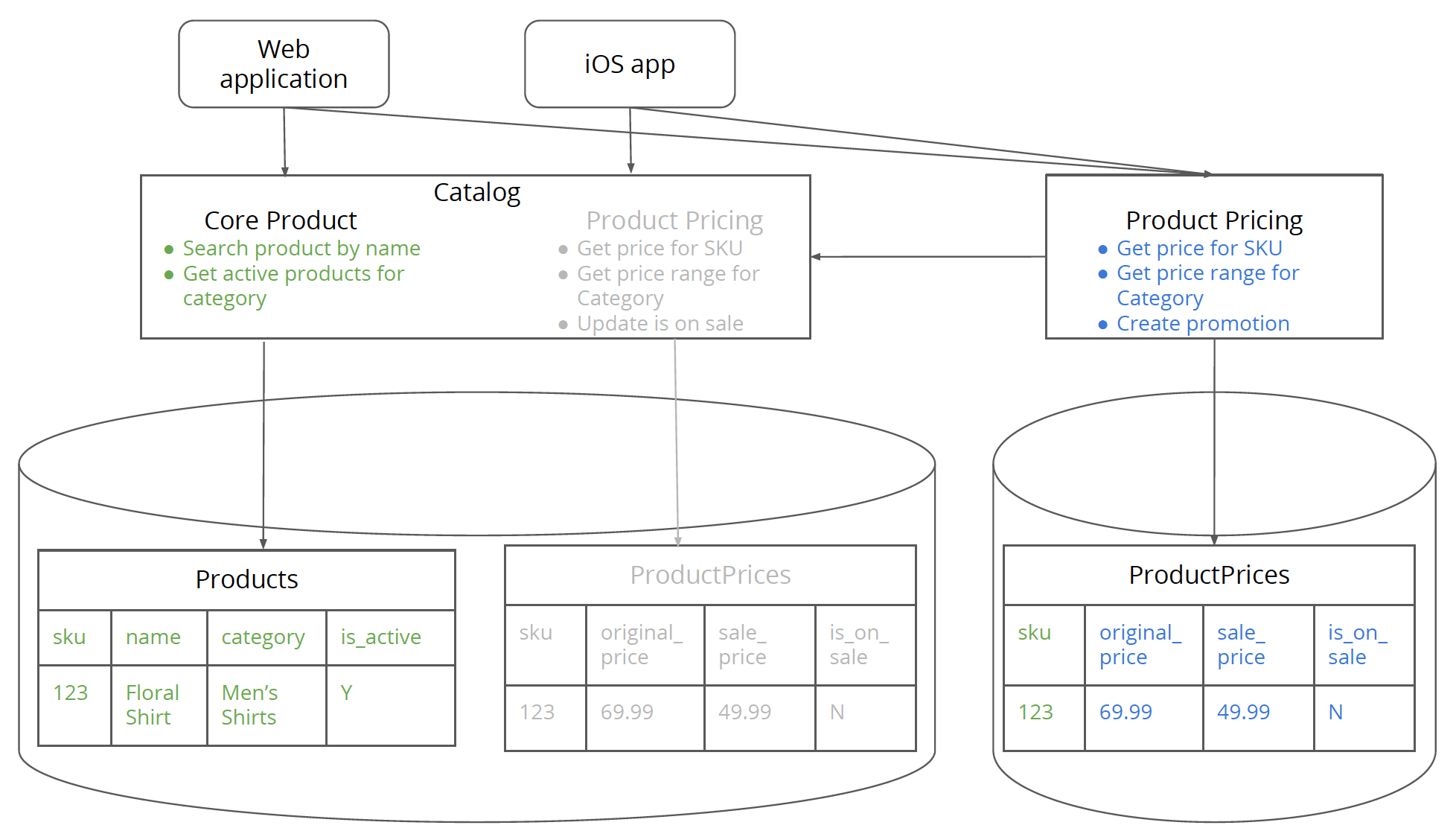
図9:製品価格サービスが価格データベースを指しています。
ステップ 9. 新しいサービスに関連するロジックとスキーマをモノリスから削除する
このステップでは、モノリスから価格関連のロジックとスキーマを削除します。チームは「いつか必要になるかもしれない」という心配から、古いテーブルをデータベースに永久に残しがちです。データベース全体のバックアップを取ることは、これらの懸念を和らげるのに役立つかもしれません。
この時点で、CatalogServiceが行っているのは、コア製品メソッドの呼び出しをCoreProductServiceに委任することだけなので、間接の層を削除し、クライアントが直接CoreProductServiceを呼び出すようにすることができます。
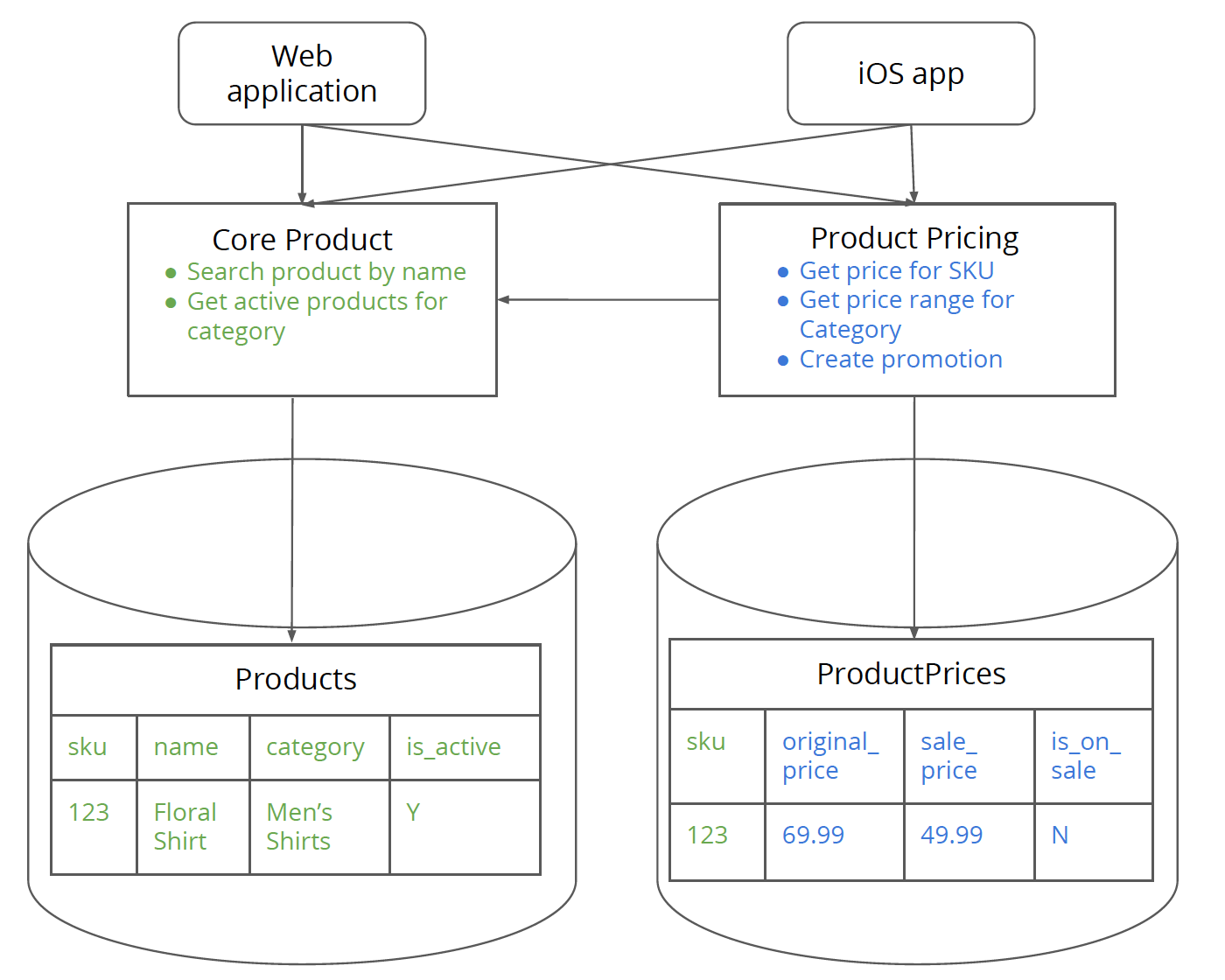
図10:コア製品にはコア製品関連のロジックとデータのみがあり、製品価格には価格関連のデータとロジックがあります。それらはロジック層を介してのみ相互に通信します。
まとめ
以上です!モノリスからデータリッチなサービスを切り離しました。やったー!
初めてこれを行うときは、大きな苦痛と貴重な教訓が学べます。これは、次のサービス抽出に役立てることができます。最初のサービス抽出では、そうしたくなるかもしれませんが、ステップを組み合わせないのが最善です。一度に1つのステップを踏むことで、モノリスを分割するプロセスは、それほど困難でなく、安全で予測可能になります。このパターンをある程度習得したら、学習に基づいてプロセスを最適化し始めることができます。
モノリスを破壊しましょう!頑張ってください!
謝辞
この記事をホストし、この記事のレビューに時間を割いてくださったMartin Fowlerに感謝します。彼のレビューコメントは、この記事を本当に次のレベルに引き上げました。重要な解説を提供してくれたJorge Leeにも感謝します。また、社内メーリングリストでコメントをくれたThoughtworksの同僚であるJoey Guerra、Matt Newman、Vanessa Towers、Ran Xiao、Kuldeep Singhにも感謝します。
大幅な修正
2018年8月30日:残りの記事を公開
2018年8月29日:6番目と7番目のステップを公開
2018年8月28日:5番目のステップを公開
2018年8月27日:4番目のステップを公開
2018年8月25日:3番目のステップを公開
2018年8月24日:2番目のステップを公開
2018年8月23日:最初のステップを公開