
LMAXアーキテクチャ
LMAXは新しい小売金融取引プラットフォームです。そのため、低遅延で多くの取引を処理する必要があります。このシステムはJVMプラットフォーム上に構築されており、単一スレッドで毎秒600万件の注文を処理できるビジネスロジックプロセッサを中心としています。ビジネスロジックプロセッサは、イベントソーシングを使用して完全にメモリ内で実行されます。ビジネスロジックプロセッサは、ディスラプター(ロックを必要とせずに動作するキューのネットワークを実装するコンカレンシーコンポーネント)によって囲まれています。設計プロセスにおいて、チームは、キューを使用する高性能コンカレンシーモデルの最近の傾向は、最新のCPU設計と根本的に矛盾しているという結論に至りました。
2011年7月12日

ここ数年、「タダ飯はもうない[1]」という話を耳にすることが増えています。個々のCPU速度の向上は見込めません。そのため、高速なコードを書くには、並列ソフトウェアを使用して複数のプロセッサを明示的に使用する必要があります。これは良いニュースではありません。並列コードの記述は非常に困難です。ロックとセマフォは、推論もテストも困難であり、ドメイン問題の解決よりもコンピュータの要求を満たすことに時間を費やすことになります。Actorやソフトウェアトランザクショナルメモリなどのさまざまなコンカレンシーモデルは、これを容易にすることを目指していますが、バグや複雑さを導入する負担はまだ残っています。
そこで、昨年3月にロンドンのQConで行われたLMAXに関する講演を聞いて非常に興味をそそられました。LMAXは新しい小売金融取引プラットフォームです。ビジネス上の革新は、小売プラットフォームであることです。誰でもさまざまな金融デリバティブ商品を取引できます[2]。このような取引プラットフォームは、非常に低いレイテンシが必要です。市場は急速に動いているため、取引は迅速に処理する必要があります。小売プラットフォームは、多くの人々に対してこれを実行する必要があるため、複雑さが増します。その結果、多くのユーザーが多くの取引を行い、すべてを迅速に処理する必要があります[3]。
マルチコア思考への移行を考えると、この種の厳しいパフォーマンス要件は、明示的な並列プログラミングモデルを自然に示唆しますが、実際にはこれが出発点でした。しかし、QConで人々の注目を集めたのは、これが彼らが最終的にたどり着いた場所ではなかったということです。実際、彼らはプラットフォームのビジネスロジック全体を、つまりすべての顧客、すべての市場からのすべての取引を、単一のスレッドで行うことになりました。コモディティハードウェアを使用して、毎秒600万件の注文を処理するスレッドです[4]。
低遅延で大量のトランザクションを処理し、並列コードの複雑さを一切伴わない方法—そんなものに私は抵抗できません。幸いなことに、LMAXが他の金融会社と異なる点は、彼らの技術的な決定について喜んで話すことです。そこで、LMAXが本番稼働してしばらく経ったので、その魅力的な設計を探求する時期が来ました。
全体構造
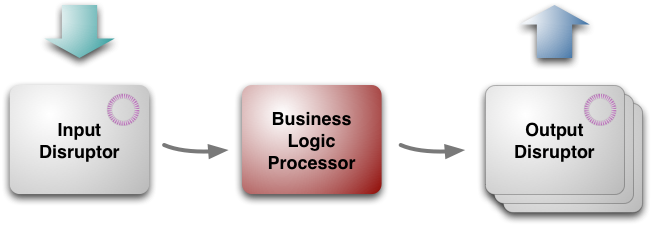
図1:3つのブロックによるLMAXのアーキテクチャ
トップレベルでは、アーキテクチャは3つの部分から構成されています。
- ビジネスロジックプロセッサ[5]
- 入力ディスラプター
- 出力ディスラプター
名前が示すように、ビジネスロジックプロセッサはアプリケーション内のすべてのビジネスロジックを処理します。前述のように、これはメソッド呼び出しに応答し、出力イベントを生成する単一スレッドのJavaプログラムとして実行されます。その結果、JVM自体以外のプラットフォームフレームワークを必要としない単純なJavaプログラムであるため、テスト環境で簡単に実行できます。
ビジネスロジックプロセッサはテストのために単純な環境で実行できますが、本番環境で実行するためのより多くの複雑な調整が必要です。入力メッセージはネットワークゲートウェイから取得され、アンマーシャリング、複製、ジャーナリングする必要があります。出力メッセージはネットワーク用にマーシャリングする必要があります。これらのタスクは、入力および出力ディスラプターによって処理されます。ビジネスロジックプロセッサとは異なり、これらはIO操作が遅く独立しているため、並列コンポーネントです。これらはLMAX向けに特別に設計および構築されましたが、(全体的なアーキテクチャと同様に)他の場所でも適用できます。
ビジネスロジックプロセッサ
すべてをメモリに保持する
ビジネスロジックプロセッサは、入力メッセージを順次(メソッド呼び出しの形式で)取得し、ビジネスロジックを実行し、出力イベントを出力します。完全にメモリ内で動作し、データベースやその他の永続的なストアはありません。すべてのデータをメモリに保持することには、2つの重要な利点があります。まず、高速であることです。アクセスするための遅いIOを提供するデータベースはなく、すべての処理が順次実行されるため、実行するトランザクション動作もありません。2つ目の利点は、プログラミングが簡素化されることです。オブジェクト/リレーショナルマッピングを行う必要はありません。すべてのコードは、データベースへのマッピングのために妥協することなく、Javaのオブジェクトモデルを使用して記述できます。
メモリ内構造を使用すると、重要な結果が生じます。すべてがクラッシュした場合どうなるでしょうか?最も堅牢なシステムでさえ、電源が切られる可能性があります。これに対処する中核となるのは、イベントソーシングです。つまり、ビジネスロジックプロセッサの現在の状態は、入力イベントを処理することで完全に導き出すことができます。入力イベントストリームを永続的なストア(入力ディスラプターのジョブの1つ)に保持する限り、イベントを再生することで、ビジネスロジックエンジンの現在の状態を常に再作成できます。
これを理解する良い方法は、バージョン管理システムについて考えることです。バージョン管理システムはコミットのシーケンスであり、いつでもこれらのコミットを適用することで作業コピーを構築できます。VCSはビジネスロジックプロセッサよりも複雑です。ブランチをサポートする必要があるのに対し、ビジネスロジックプロセッサは単純なシーケンスです。
したがって、理論的には、すべてのイベントを再処理することで、ビジネスロジックプロセッサの状態を常に再構築できます。しかし実際には、起動する必要がある場合、時間がかかりすぎます。そのため、バージョン管理システムと同様に、LMAXはビジネスロジックプロセッサの状態のスナップショットを作成し、スナップショットから復元できます。彼らは活動の少ない期間に毎晩スナップショットを取得します。ビジネスロジックプロセッサの再起動は高速であり、JVMの再起動、最近のスナップショットの読み込み、1日分のジャーナルの再生を含む完全な再起動には1分未満かかります。
スナップショットを使用すると、新しいビジネスロジックプロセッサの起動が高速化されますが、午後2時にビジネスロジックプロセッサがクラッシュした場合には十分な速度ではありません。その結果、LMAXは常に複数のビジネスロジックプロセッサを実行しています[6]。各入力イベントは複数のプロセッサによって処理されますが、1つのプロセッサを除くすべてのプロセッサの出力は無視されます。ライブプロセッサが失敗した場合、システムは別のプロセッサに切り替わります。このフェイルオーバーを処理する機能は、イベントソーシングを使用するもう1つの利点です。
レプリカへのイベントソーシングにより、マイクロ秒単位でプロセッサ間を切り替えることができます。毎晩スナップショットを取得するだけでなく、毎晩ビジネスロジックプロセッサも再起動します。複製により、ダウンタイムなしでこれを実行できるため、24時間365日取引の処理を継続できます。
イベントソーシングは、プロセッサが完全にメモリ内で実行できるようにするため価値がありますが、診断にも大きな利点があります。予期せぬ動作が発生した場合、チームはイベントのシーケンスを開発環境にコピーしてそこで再生します。これにより、ほとんどの環境では不可能なほど簡単に何が起こったかを調べることができます。
この診断機能は、ビジネス診断にも拡張されます。リスク管理など、注文処理には必要ないが、かなりの計算を必要とするビジネスタスクがあります。例としては、現在の取引ポジションに基づいて、リスクプロファイル別に上位20人の顧客のリストを取得することが挙げられます。チームは、レプリケートされたドメインモデルをスピンアップし、そこで計算を実行することでこれに対処します。これにより、コア注文処理を妨げません。これらの分析ドメインモデルは、異なるデータモデルを持つことができ、異なるデータセットをメモリに保持し、異なるマシンで実行できます。
パフォーマンスチューニング
これまでのところ、ビジネスロジックプロセッサの速度の鍵は、すべてを順次、メモリ内で行うことであると説明しました。(本当に愚かなことは何もせずに)これを行うだけで、開発者は10K TPS[7]を処理できるコードを記述できます。その後、良好なコードの単純な要素に集中することで、これを100K TPSの範囲にまで引き上げることができることがわかりました。これは、適切にファクタリングされたコードと小さなメソッドを使用するだけで済みます。基本的に、これによりHotspotは最適化をより適切に行い、CPUは実行中のコードをより効率的にキャッシュできます。
さらに桁違いに上げるには、もう少し工夫が必要でした。LMAXチームがそこで役立つと感じたことはいくつかあります。1つは、キャッシュフレンドリーでガベージに注意深く設計されたjavaコレクションのカスタム実装を作成することでした[8]。その例としては、特別に記述された配列バックアップのMap実装(LongToObjectHashMap)を使用して、プリミティブなjava longをハッシュマップキーとして使用することが挙げられます。一般的に、彼らはデータ構造の選択が大きな違いを生むことが多いことに気づきました。ほとんどのプログラマは、どの実装がこのコンテキストで適切であるかを考えるのではなく、前回使用したListを何でも取得します[9]。
その最高レベルのパフォーマンスに達するためのもう1つのテクニックは、パフォーマンステストに注意を払うことです。私は長い間、人々がパフォーマンスを向上させるテクニックについて多く話していることに気づいていましたが、実際には違いを生む唯一のことは、それをテストすることです。優れたプログラマでさえ、最終的に間違っているパフォーマンスの議論を構築するのが非常に得意であるため、最高のプログラマは憶測よりもプロファイラとテストケースを好みます[10]。LMAXチームは、最初にテストを作成することもパフォーマンステストでは非常に効果的な規律であることも発見しました。
プログラミングモデル
この処理スタイルは、ビジネスロジックの書き方と整理方法にいくつかの制約を導入します。最初の制約は、外部サービスとの相互作用をすべて明らかにする必要があることです。外部サービスへの呼び出しは遅くなり、単一のスレッドを使用すると、注文処理マシン全体が停止します。その結果、ビジネスロジック内で外部サービスを呼び出すことはできません。代わりに、出力イベントを使用してその相互作用を終了し、別の入力イベントを待って再開する必要があります。
簡単なLMAXではない例を使って説明します。クレジットカードでグミキャンディーを注文すると想像してください。単純な小売システムは、注文情報を受け取り、クレジットカード検証サービスを使用してクレジットカード番号を確認し、注文を確認します。これらすべては単一操作で行われます。注文を処理するスレッドは、クレジットカードの確認を待つ間ブロックされますが、ユーザーにとってそのブロックはそれほど長くはなく、サーバーは待機中に常にプロセッサ上で別のスレッドを実行できます。
LMAXアーキテクチャでは、この操作を2つに分割します。最初の操作は注文情報を取得し、クレジットカード会社にイベント(クレジットカード検証リクエスト)を出力することで終了します。ビジネスロジックプロセッサは、入力イベントストリームでクレジットカード検証イベントを受信するまで、他の顧客のイベント処理を続けます。そのイベントを処理することで、その注文の確認タスクを実行します。
この種のイベント駆動型非同期スタイルでの作業はやや珍しいですが、アプリケーションの応答性を向上させるために非同期を使用することは、よく知られた手法です。また、リモートアプリケーションで発生する可能性のあるさまざまなことをより明確に考える必要があるため、ビジネスプロセスがより堅牢になるのにも役立ちます。
プログラミングモデルの2番目の特徴はエラー処理にあります。セッションとデータベーストランザクションの従来のモデルは、役立つエラー処理機能を提供します。何か問題が発生した場合、これまでのやり取りですべてを破棄するのは簡単です。セッションデータは一時的なものであり、複雑な作業の途中でなくても、ユーザーのわずかな不満を招くというコストで破棄できます。データベース側でエラーが発生した場合、トランザクションをロールバックできます。
LMAXのインメモリ構造は入力イベント全体で永続的であるため、エラーが発生した場合、そのメモリを矛盾した状態のままにしないことが重要です。ただし、自動ロールバック機能はありません。その結果、LMAXチームは、インメモリ永続状態の変更を行う前に、入力イベントが完全に有効であることを確認することに多くの注意を払っています。彼らは、テストが本番環境に移行する前に、この種のバグを洗い出すための重要なツールであることを発見しました。
入出力ディスラプター
ビジネスロジックは単一のスレッドで発生しますが、ビジネスオブジェクトメソッドを呼び出す前に実行する必要があるタスクがいくつかあります。処理のための元の入力はメッセージの形でワイヤから取得されます。このメッセージは、ビジネスロジックプロセッサが使用しやすい形式にアンマーシャリングする必要があります。イベントソーシングは、すべての入力イベントの永続的なジャーナルを保持することに依存しているため、各入力メッセージを永続的なストアにジャーナリングする必要があります。最後に、アーキテクチャはビジネスロジックプロセッサのクラスタに依存しているため、このクラスタ全体で入力メッセージを複製する必要があります。同様に、出力側では、ネットワークを介して送信するために出力イベントをマーシャリングする必要があります。
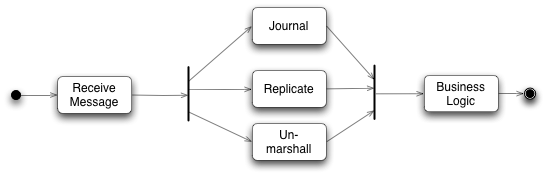
図2:入力ディスラプターによって実行されるアクティビティ(UMLアクティビティ図表記を使用)
レプリケーターとジャーナラーはIOを含み、したがって比較的遅いです。結局のところ、ビジネスロジックプロセッサの中心的なアイデアは、IOを実行しないことです。また、これらの3つのタスクは比較的独立しており、ビジネスロジックプロセッサがメッセージを処理する前にすべて実行する必要がありますが、任意の順序で実行できます。したがって、後続の取引の市場を変化させる各取引が行われるビジネスロジックプロセッサとは異なり、並行処理に自然に適合します。
この並行処理を処理するために、LMAXチームは、**ディスラプター**[11] と呼ばれる特別な並行処理コンポーネントを開発しました。
大雑把に言うと、ディスラプターは、プロデューサーがオブジェクトを配置し、すべてのコンシューマーに送信されて、個別のダウンストリームキューを介して並列に消費されるキューのマルチキャストグラフと考えることができます。内部を見ると、このキューネットワークは実際には単一のデータ構造であるリングバッファーであることがわかります。各プロデューサーとコンシューマーには、現在作業中のバッファーのスロットを示すシーケンスカウンターがあります。各プロデューサー/コンシューマーは独自のシーケンスカウンターを書き込みますが、他のシーケンスカウンターを読み取ることができます。このように、プロデューサーはコンシューマーのカウンターを読み取って、書き込みたいスロットが利用可能であることを確認できます。同様に、コンシューマーは、カウンターを監視することで、別のコンシューマーが処理を完了するまでメッセージを処理しないようにすることができます。
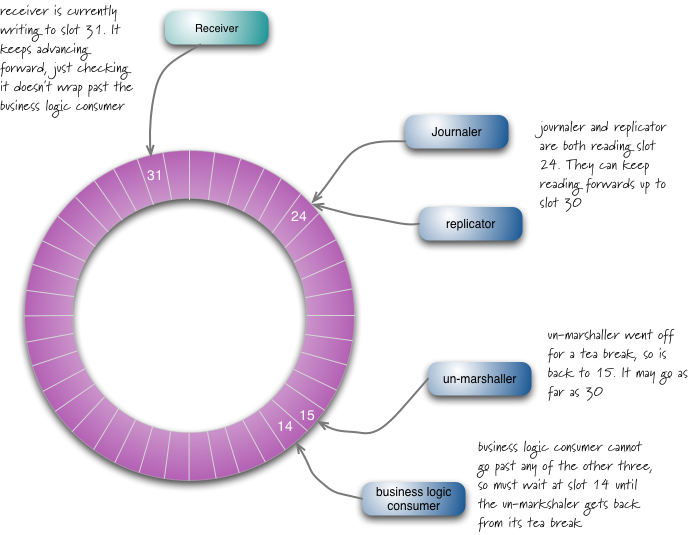
図3:入力ディスラプターは1つのプロデューサーと4つのコンシューマーを調整します
出力ディスラプターは似ていますが、マーシャリングと出力のために2つのシーケンシャルコンシューマーしかありません[12]。出力イベントは複数のトピックに整理されているため、メッセージは関心のある受信者だけに送信できます。各トピックには独自のディスラプターがあります。
説明したディスラプターは、1つのプロデューサーと複数のコンシューマーというスタイルで使用されていますが、これはディスラプターの設計の制限ではありません。ディスラプターは複数のプロデューサーでも動作し、この場合でもロックは必要ありません[13]。
ディスラプター設計の利点は、問題が発生して遅れが生じた場合でも、コンシューマーが迅速に追いつくことが容易になることです。アンマーシャラーがスロット15の処理中に問題が発生し、受信者がスロット31にいるときに戻った場合、スロット16〜30のデータを一括で読み取って追いつくことができます。ディスラプターからのデータの一括読み取りにより、遅れているコンシューマーが迅速に追いつくことが容易になり、全体的なレイテンシが減少します。
ここでは、ジャーナラー、レプリケーター、アンマーシャラーをそれぞれ1つずつ説明しましたが、これはLMAXが行っていることです。しかし、この設計では、これらのコンポーネントを複数実行できます。2つのジャーナラーを実行した場合、1つは偶数スロットを処理し、もう1つは奇数スロットを処理します。これにより、必要に応じてこれらのIO操作の並行処理がさらに可能になります。
リングバッファーは大きいです。入力バッファーには2000万スロット、各出力バッファーには400万スロットあります。シーケンスカウンターは、リングスロットがラップされても単調増加する64ビット長の整数です[14]。バッファーは2の累乗のサイズに設定されているため、コンパイラーはシーケンスカウンター番号からスロット番号へのマッピングに効率的なモジュラス演算を実行できます。システムの他の部分と同様に、ディスラプターは一晩でリスタートされます。このリスタートは主にメモリをクリアするために実行され、取引中の高価なガベージコレクションイベントの可能性が低くなります。(緊急時にも実行方法を練習するために、定期的に再起動することも良い習慣だと思います。)
ジャーナラーの役割は、すべてのイベントを永続的な形式で保存し、何か問題が発生した場合に再生できるようにすることです。LMAXはこれにはデータベースを使用せず、ファイルシステムのみを使用します。彼らはイベントをディスクにストリーミングします。現代的な観点から見ると、機械式ディスクはランダムアクセスには非常に遅いが、ストリーミングには非常に高速です。そのため、「ディスクは新しいテープ」というキャッチフレーズが付けられています[15]。
前に述べたように、LMAXは迅速なフェイルオーバーをサポートするために、システムの複数のコピーをクラスタで実行しています。レプリケーターはこれらのノードを同期状態に保ちます。LMAXのすべての通信はIPマルチキャストを使用するため、クライアントはリーダーノードがどのIPアドレスであるかを認識する必要はありません。リーダーノードだけが直接入力イベントをリッスンし、レプリケーターを実行します。レプリケーターは入力イベントをフォロワーノードにブロードキャストします。リーダーノードがダウンした場合、ハートビートの欠如が認識され、別のノードがリーダーになり、入力イベントの処理を開始し、レプリケーターを開始します。各ノードには独自の入力ディスラプターがあり、したがって独自のジャーナルを持ち、独自のアンマーシャリングを実行します。
IPマルチキャストを使用しても、IPメッセージは異なるノードで異なる順序で到着する可能性があるため、レプリケーションは依然として必要です。リーダーノードは、残りの処理のための決定論的なシーケンスを提供します。
アンマーシャラーは、ワイヤからのイベントデータを、ビジネスロジックプロセッサで動作を呼び出すために使用できるJavaオブジェクトに変換します。したがって、他のコンシューマーとは異なり、アンマーシャリングされたオブジェクトを格納できるように、リングバッファー内のデータを変更する必要があります。ここでのルールは、コンシューマーはリングバッファーに書き込むことが許可されますが、各書き込み可能なフィールドには、それに書き込むことが許可されている並列コンシューマーが1つだけ存在できます。これにより、単一のライターのみを持つという原則が維持されます。[16]
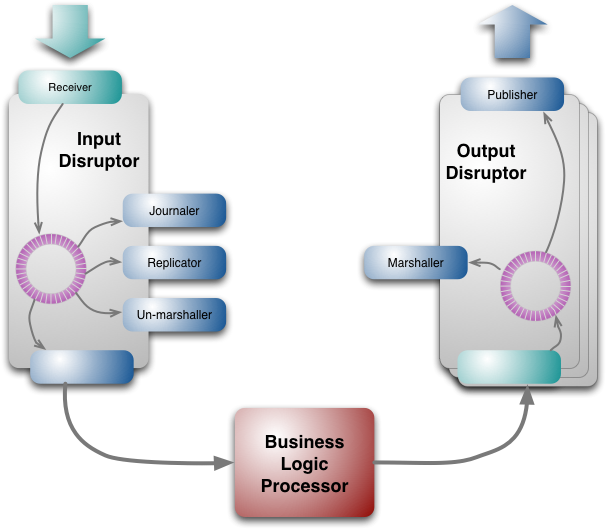
図4:ディスラプターを展開したLMAXアーキテクチャ
ディスラプターは、LMAXシステム以外でも使用できる汎用コンポーネントです。通常、金融会社はシステムについて非常に秘密主義であり、ビジネスに関係のない項目についても黙っています。LMAXは全体的なアーキテクチャについてオープンなだけでなく、ディスラプターコードをオープンソース化しました。これは私を非常に幸せにする行為です。これにより、他の組織がディスラプターを使用できるようになるだけでなく、その並行処理特性のテストも可能になります。
キューと機械的共感の欠如
LMAXアーキテクチャは、多くの人が考えているものとは非常に異なる方法で高性能システムにアプローチするため、人々の注目を集めました。これまで、その仕組みについて説明してきましたが、なぜこのように開発されたのかについてはあまり詳しく説明していません。この物語自体も興味深いものです。なぜなら、このアーキテクチャは突然現れたわけではないからです。より従来の代替案を試してみて、その欠陥を認識するのに長い時間がかかり、チームがこのアーキテクチャに落ち着くまで時間がかかりました。
現代の多くのビジネスシステムは、トランザクションデータベースによって調整された複数のアクティブセッションに依存するコアアーキテクチャを持っています。LMAXチームはこのアプローチに精通していましたが、LMAXには適していないと確信していました。この評価は、LMAXを設立した親会社であるBetfairの経験に基づいています。Betfairは、スポーツイベントへの賭けを可能にするベッティングサイトです。非常に大量のトラフィックと多くの競合を処理します - スポーツベッティングは特定のイベントを中心にバーストする傾向があります。これを機能させるために、彼らは最高のデータベースインストールの1つを持っており、機能させるために多くの非自然な行為をしなければなりませんでした。この経験に基づいて、彼らはBetfairのパフォーマンスを維持することがいかに困難であるかを知っており、この種のアーキテクチャは、取引サイトに必要な非常に低いレイテンシには適していないと確信していました。その結果、彼らは異なるアプローチを見つけなければなりませんでした。
彼らの最初の取り組みは、今日多くの人が言っていること、つまり高性能を得るには明示的な並行処理を使用する必要があるということでした。このシナリオでは、これは注文を複数のスレッドで並列に処理することを意味します。しかし、並行処理の場合によくあることですが、困難はこれらのスレッドがお互いに通信しなければならないことです。注文を処理すると市場状況が変化し、これらの状況を伝える必要があります。
彼らが初期に検討したアプローチは、アクタモデルとその近縁であるSEDAでした。アクタモデルは、独自のThreadを持ち、キューを介してお互いに通信する独立したアクティブオブジェクトに依存しています。多くの人は、この種の並行処理モデルの方が、ロックプリミティブに基づいた何かを行うよりもはるかに扱いやすいと感じています。
チームはアクタモデルを使用してプロトタイプ交換機を構築し、そのパフォーマンステストを行いました。彼らが発見したのは、プロセッサがアプリケーションの実際のロジックを実行するよりもキューの管理に多くの時間を費やしていたことです。キューへのアクセスがボトルネックでした。
このようなパフォーマンスを追求すると、最新のハードウェアの構成方法を考慮することが重要になります。マーティン・トンプソンが好んで使用するフレーズは「メカニカルシンパシー」です。この用語はレーシングカーの運転から来ており、ドライバーが車に対する生まれつきの感覚を持っていることを反映しており、最高の性能を引き出す方法を感じることができます。多くのプログラマー、そして私もこの陣営に属していると告白しますが、プログラミングがハードウェアとどのように相互作用するかについて、それほどメカニカルシンパシーを持っていません。さらに悪いことに、多くのプログラマーはメカニカルシンパシーを持っていると考えていますが、それは数年前に時代遅れになったハードウェアの動作に関する概念に基づいています。
レイテンシに影響を与える最新のCPUの支配的な要因の1つは、CPUがメモリとどのように相互作用するかです。今日では、CPUの観点から見ると、メインメモリにアクセスするのは非常に遅い操作です。CPUには複数のレベルのキャッシュがあり、それぞれがはるかに高速です。そのため、速度を上げるには、コードとデータをこれらのキャッシュに取得する必要があります。
あるレベルでは、アクタモデルはここで役立ちます。アクタを、コードとデータをクラスタ化する独自のオブジェクトと考えることができます。これはキャッシングのための自然な単位です。しかし、アクタは通信する必要があり、それはキューを介して行われます。そしてLMAXチームは、キューがキャッシングを妨げていることを観察しました。
説明は次のようになります。キューにデータを入れるには、そのキューに書き込む必要があります。同様に、キューからデータを取り出すには、削除を実行するためにキューに書き込む必要があります。これは書き込み競合です。複数のクライアントが同じデータ構造に書き込む必要がある可能性があります。書き込み競合に対処するために、キューは多くの場合ロックを使用します。しかし、ロックを使用すると、カーネルへのコンテキストスイッチが発生する可能性があります。これが発生すると、関連するプロセッサはキャッシュ内のデータを失う可能性が高くなります。
彼らが到達した結論は、最高のキャッシング動作を得るには、任意のメモリ位置に書き込むコアが1つしかない設計が必要である[17]ということです。複数の読み取りは問題ありません。プロセッサは、多くの場合、キャッシュ間に特別な高速リンクを使用します。しかし、キューは1つの書き込み元という原則に適合しません。
この分析により、LMAXチームは2つの結論に至りました。まず、単一書き込み元制約を断固として守るディスラプターの設計につながりました。次に、単一スレッドビジネスロジックアプローチを探求するというアイデアにつながり、並行処理管理から解放された単一スレッドがどれだけの速度を出せるかを問いました。
単一スレッドで作業することの本質は、1つのコアで実行される1つのスレッドを持ち、キャッシュをウォームアップし、可能な限り多くのメモリアクセスをメインメモリではなくキャッシュに移動することです。これは、コードとデータのワーキングセットの両方を可能な限り一貫してアクセスする必要があることを意味します。また、コードとデータをまとめて小さなオブジェクトを保持することで、それらを単位としてキャッシュ間でスワップすることができ、キャッシュ管理を簡素化し、パフォーマンスをさらに向上させることができます。
LMAXアーキテクチャへの道のりの重要な部分には、パフォーマンステストの使用がありました。アクタベースのアプローチの検討と放棄は、プロトタイプの構築とパフォーマンステストから生まれました。同様に、さまざまなコンポーネントのパフォーマンス向上における多くのステップは、パフォーマンステストによって可能になりました。メカニカルシンパシーは非常に価値があります。それは、どのような改善ができるかについての仮説を立てるのに役立ち、後退ではなく前進へと導きます。しかし、最終的にはテストによって説得力のある証拠が得られます。
ただし、このスタイルのパフォーマンステストは、十分に理解されていないトピックです。LMAXチームは定期的に、意味のあるパフォーマンステストを考案することは、本番コードを開発するよりも難しいことが多いと強調しています。適切なテストを開発するには、メカニカルシンパシーも重要です。CPUのキャッシング動作を考慮せずに低レベルの並行コンポーネントをテストしても意味がありません。
特に重要な教訓の1つは、パフォーマンステストが実際に実際のコンポーネントが行っていることを測定するのに十分な速度であることを確認するために、nullコンポーネントに対してテストを作成することの重要性です。高速なテストコードを書くことは、高速な本番コードを書くことと同じくらい容易ではなく、テストが測定しようとしているコンポーネントほど高速ではないため、誤った結果を得やすくなります。
このアーキテクチャを使用すべきか?
一見、このアーキテクチャは非常に小さなニッチなもののように見えます。結局のところ、それを導いたドライバーは、非常に低いレイテンシで多くの複雑なトランザクションを実行することでした。ほとんどのアプリケーションは、600万TPSで実行する必要はありません。
しかし、このアプリケーションで私を魅了するものは、多くのソフトウェアプロジェクトを悩ませるプログラミングの複雑さの大部分を排除する設計にたどり着いたことです。トランザクションデータベースを取り巻く従来の同時セッションモデルは、問題がないわけではありません。データベースとの関係には通常、取るに足りない努力が必要です。オブジェクト/リレーショナルマッピングツールは、データベースの処理に伴う多くの痛みを軽減するのに役立ちますが、すべてを解決するわけではありません。エンタープライズアプリケーションのパフォーマンスチューニングのほとんどは、SQLの微調整に関係しています。
今日では、私たち古い世代がディスク容量として入手できたよりも多くのメインメモリをサーバーに搭載できます。ますます多くのアプリケーションが、すべてのワーキングセットをメインメモリに配置できるようになり、複雑さと遅滞の両方の原因を排除しています。イベントソーシングは、インメモリシステムの耐久性問題を解決する方法を提供し、単一スレッドですべてを実行することで、並行処理の問題を解決します。LMAXの経験は、数百万TPS未満であれば、十分なパフォーマンスヘッドルームがあることを示唆しています。
CQRSへの関心の高まりと、ここではかなりの重複があります。イベントソーシングされたインメモリプロセッサは、CQRSシステムのコマンド側の自然な選択肢です。(ただし、LMAXチームは現在CQRSを使用していません。)
では、この道に進まないことを示すものは何でしょうか?これは、このあまり知られていないテクニックの場合、常に難しい質問です。なぜなら、この専門分野は境界を探求するのにさらに時間が必要だからです。しかし、出発点は、アーキテクチャを促進する特性を考えることです。
1つの特性は、これは接続されたドメインであり、1つのトランザクションを処理すると、それに続くトランザクションの処理方法が常に変更される可能性があることです。互いに独立したトランザクションが多いほど、調整の必要性が少なくなり、並列で実行される個別のプロセッサを使用することがより魅力的になります。
LMAXは、イベントが世界をどのように変えるかの結果を理解することに集中しています。多くのサイトは、既存の情報ストアを取り、その情報のさまざまな組み合わせをできるだけ多くの目に届けることに関心があります。たとえば、メディアサイトを考えてみてください。ここでは、アーキテクチャ上の課題は多くの場合、キャッシュを正しく設定することにあります。
LMAXのもう1つの特性は、バックエンドシステムであるため、対話モードで動作するものにどの程度適用できるかを検討するのは妥当です。Webアプリケーションは、このアーキテクチャにうまく適合する側面である、要求に反応するサーバーシステムに慣れさせてくれます。このアーキテクチャがほとんどのそのようなシステムよりもさらに進んでいるのは、非同期通信の絶対的な使用であり、前に概説したプログラミングモデルの変更につながります。
これらの変更には、ほとんどのチームが慣れるのに時間がかかります。ほとんどの人は同期的な観点からプログラミングすることを好み、非同期性の処理には慣れていません。しかし、非同期通信は応答性にとって不可欠なツールであることは長い間真実です。AJAXやnode.jsによるJavaScriptの世界での非同期通信のより広範な使用が、より多くの人々がこのスタイルを調査することを促すかどうかは興味深いでしょう。LMAXチームは、非同期スタイルに適応するのに少し時間がかかったものの、すぐに自然になり、多くの場合より簡単になったとわかりました。特に、このアプローチではエラー処理がはるかに簡単になりました。
LMAXチームは確かに、調整されたトランザクションデータベースの時代は数少ないと感じています。この種のアーキテクチャを使用してソフトウェアをより簡単に記述でき、より高速に実行できるという事実は、従来の中央データベースの正当性の多くを取り除きます。
私自身は、これは非常にエキサイティングなストーリーだと考えています。私の目標の多くは、複雑なドメインをモデル化するソフトウェアに集中することです。このようなアーキテクチャは懸念事項の優れた分離を提供し、ドメイン駆動設計に集中し、プラットフォームの複雑さの大部分を適切に分離することができます。ドメインオブジェクトとデータベース間の密結合は常に問題でした。このようなアプローチは、解決策を示唆しています。
脚注
1: The Free Lunch is Over(無料のランチはもうない)
これは、Herb Sutterによる有名なエッセイのタイトルです。彼は、「無料の昼食」を、毎年私たちにCPU性能を向上させてきたプロセッサのクロックスピードの継続的な向上として説明しています。彼の主張は、そのようなクロックサイクルの増加はもはや起こらなくなるということであり、代わりに性能向上はマルチコアによって実現されるということです。しかし、マルチコアを活用するには、並行して動作できるソフトウェアが必要であり、プログラミングスタイルの変化なしでは、人々はもはや無料で性能という「昼食」を得ることができなくなると述べています。
2: このイノベーションの価値に関する私の考えについては、沈黙を守ります。
3: ユーザーベース
すべての取引システムは、1回の取引が後の取引に影響を与える可能性があり、迅速な反応に基づいた競争が激しいことから、低遅延を必要とします。ほとんどの取引プラットフォームは銀行、ブローカーなどの専門家向けであり、通常は数百人のユーザーがいます。小売システムははるかに多くのユーザーを抱える可能性があり、Betfairは数百万人のユーザーを抱え、LMAXはその規模に向けて設計されています。(LMAXチームは実際の取引量を公開することを許可されていません。)
実際、小売システムは多くのユーザーを抱えているものの、アクティビティの大部分はマーケットメーカーからのものです。変動の激しい期間には、1秒間に数百回の更新が、1マイクロ秒以内に数百件のトランザクションという異常なマイクロバーストが発生することがあります。
4: ハードウェア
600万TPSのベンチマークは、32GB RAMを搭載した3GHzデュアルソケットクアッドコアNehalemベースのDellサーバーで測定されました。
5: チームは「ビジネスロジックプロセッサ」という名前を使用していません。実際、そのコンポーネントには名前がなく、ビジネスロジックまたはコアサービスとだけ呼んでいます。この記事で説明しやすくするために、私が名前を付けました。
6: 現在、LMAXはメインデータセンターに2つのビジネスロジックプロセッサ、ディザスタリカバリサイトに3つ目のプロセッサを稼働させています。3つすべてが入力イベントを処理します。
7: トランザクションの内容
トランザクションのタイミングについて話す場合、問題の1つは、トランザクションに正確に何が含まれているかということです。場合によっては、データベースに新しいレコードを挿入する以上のものはありません。LMAXのトランザクションは比較的複雑で、典型的な小売販売よりも複雑です。
取引所への注文の配置には、以下のことが含まれます。
- ターゲット市場が注文を受け付けるために開いていることを確認する
- その市場に対して注文が有効であることを確認する
- 注文の種類に適切なマッチングポリシーを選択する
- 各注文が可能な限り最良の価格で、適切な流動性とマッチングされるように、注文をシーケンス化する
- マッチングの結果として行われた取引を作成し、公開する
- 新しい取引に基づいて価格を更新する
8: このレベルのレイテンシでは、ガベージコレクタを認識する必要があります。今日のほとんどのシステムでは、最新のGC圧縮はパフォーマンスに目立った影響を与えません。しかし、最小限のジッターで1秒間に数百万件のトランザクションを処理しようとする場合、GCの一時停止が問題になります。覚えておくべきことは、短命なオブジェクトはすぐに収集されるため問題ないということです。同様に、永久的なオブジェクトも問題ありません。問題となるのは、古い世代に昇格するが、最終的には消滅するオブジェクトです。これにより古い世代領域が断片化されると、圧縮がトリガーされます。
9: パフォーマンスがクリティカルではないコードでは、どのコレクション実装を使用するかについて、めったに考えません。異なるコンテキストは、異なる動作を示唆します。
10: 興味深い補足事項です。LMAXチームは、関数型プログラミングへの現在の関心の多くを共有していますが、OOアプローチがこの種の課題にはより優れたアプローチを提供すると考えています。彼らは、より高速なコードを作成しようとすると、関数型スタイルからOOスタイルに移行することに気づきました。これは部分的に、関数型スタイルが不変性を維持するために必要とするデータのコピーによるものです。しかし、オブジェクトは、より豊富なデータ構造の選択肢を持つ複雑なドメインのより良いモデルを提供するためでもあります。
11: 「ディスラプター」という名前は、いくつかの情報源から着想を得ています。1つは、LMAXチームがこのコンポーネントを、並行処理に関する現在の考え方を混乱させるものと見なしているという事実です。もう1つは、Javaがフェーザーを導入しているという事実に対応したものであり、ディスラプターを含めるのは自然です。
12: 出力イベントもジャーナルに記録することは可能です。これには、ダウンストリームサービスのために再生する必要がある場合に再計算する必要がないという利点があります。しかし、実際には、これは価値がありません。ビジネスロジックは決定論的で非常に高速であるため、結果を保存することによる利点はありません。
13: ただし、この場合、CAS命令を使用する必要があります。ディスラプターの技術論文で詳細をご覧ください。
14: これは、1秒間に10億件のトランザクションを処理する場合、292年後にはカウンタがラップアラウンドし、大混乱を引き起こすことを意味します。彼らは、これを修正することは優先順位が高くないと判断しました。
15: SSDはランダムアクセスの方が優れていますが、ディスクのようなIOシステムは速度を低下させます。
16: フィールドを書き込む際のもう1つの複雑さは、書き込まれるフィールドを異なるキャッシュラインに分ける必要があることです。
17: メモリロケーションへのシングルライターの確保
シングルライターの原則に従う際の複雑さは、プロセッサが一度に1つのメモリロケーションを確保しないという点です。むしろ、キャッシュラインと呼ばれる複数の連続したロケーションを一度にキャッシュに読み込みます。キャッシュラインチャンクでメモリにアクセスする方が明らかに効率的ですが、異なるコアによって書き込まれたロケーションがそのキャッシュライン内に存在しないようにする必要があります。そのため、たとえば、ディスラプターのシーケンスカウンタは、別々のキャッシュラインに表示されるようにパディングされています。
謝辞
金融機関は通常、技術的な作業について秘密主義であり、通常はほとんど理由がありません。これは、専門家が経験から学ぶ能力を妨げるため、問題です。そのため、LMAXの経験について(この記事と他の資料の両方で)議論してくれたことに特に感謝しています。
ディスラプターの主要な作成者は、Martin Thompson、Mike Barker、およびDave Farleyです。
Martin ThompsonとDave Farleyは、この記事の基礎となったLMAXアーキテクチャの詳細な概要を説明してくれました。また、初期ドラフトを改善するために、メールの質問にも迅速に対応してくれました。
並行プログラミングは、熟達するには多くの注意が必要な難しい分野であり、私はその努力をしていません。その結果、私は並行処理に関する理解において完全に他者に依存しており、彼らの辛抱強いアドバイスに感謝しています。
参考文献
LMAXチームのメンバーによるLMAXアーキテクチャのビデオ説明を好む場合は、2010年にサンフランシスコで開催されたQConプレゼンテーションでMartin ThompsonとMichael Barkerが行ったプレゼンテーションが最適です。
ディスラプターのソースコードはオープンソースとして公開されています。また、より詳細な技術論文(PDF)と、それに関するブログや記事のコレクションもあります。
LMAXチームのさまざまなメンバーが独自のブログを持っています。 Martin Thompson、Michael Barker、およびTrisha Gee。
重要な改訂
2011年7月12日: 初版公開
2011年6月22日: ドラフト開始