
CQRS
2011年7月14日

CQRSはコマンドクエリ責務分離(Command Query Responsibility Segregation)の略です。これは、私が初めてGreg Young(グレッグ・ヤング)氏から聞いたパターンです。その核心は、情報の更新に使用するモデルと、情報の読み取りに使用するモデルを別々に使用できるという考え方です。状況によっては、この分離は価値がありますが、ほとんどのシステムではCQRSは危険な複雑さを追加することに注意してください。
情報システムとの対話に使用される主流のアプローチは、CRUDデータストアとして扱うことです。これは、新しいレコードの作成(Create)、レコードの読み取り(Read)、既存レコードの更新(Update)、不要になったレコードの削除(Delete)ができる、ある種のレコード構造のメンタルモデルを持っていることを意味します。最も単純なケースでは、私たちの相互作用はすべてこれらのレコードの保存と取得に関するものです。
ニーズが高度になるにつれて、私たちは着実にそのモデルから離れていきます。レコードストアとは異なる方法で情報を参照したい場合があります。たとえば、複数のレコードを1つにまとめたり、異なる場所の情報を組み合わせて仮想レコードを形成したりする場合です。更新側では、特定のデータの組み合わせのみを保存できる検証ルールが見つかったり、提供されたデータとは異なるデータを保存するように推測したりする場合があります。
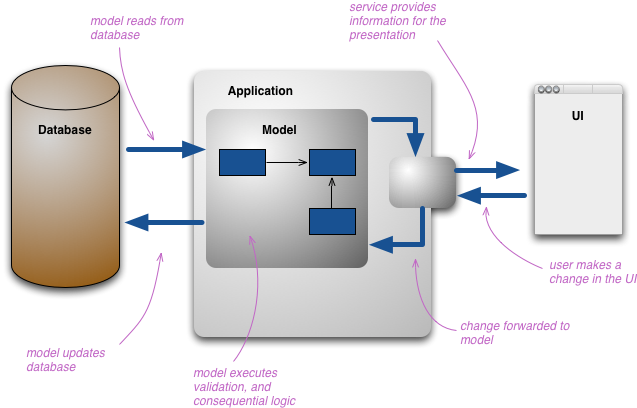
これが発生すると、情報の複数の表現が見られるようになります。ユーザーが情報と対話するとき、彼らはこれらの情報のさまざまなプレゼンテーションを使用します。それぞれが異なる表現です。開発者は通常、モデルのコア要素を操作するために使用する独自の概念モデルを構築します。ドメインモデルを使用している場合、これは通常、ドメインの概念表現です。通常、永続ストレージも概念モデルのできるだけ近くに配置します。
この複数の表現レイヤーの構造は非常に複雑になる可能性がありますが、人々はこれを行うとき、依然としてすべてのプレゼンテーション間の概念的な統合ポイントとして機能する単一の概念表現に解決します。
CQRSによって導入される変更は、その概念モデルを更新と表示のための別々のモデルに分割することです。コマンドクエリ分離(CommandQuerySeparation)の語彙に従って、それぞれコマンドとクエリと呼びます。その根拠は、多くの問題、特により複雑なドメインでは、コマンドとクエリに同じ概念モデルを使用すると、どちらも適切に機能しないより複雑なモデルになるということです。
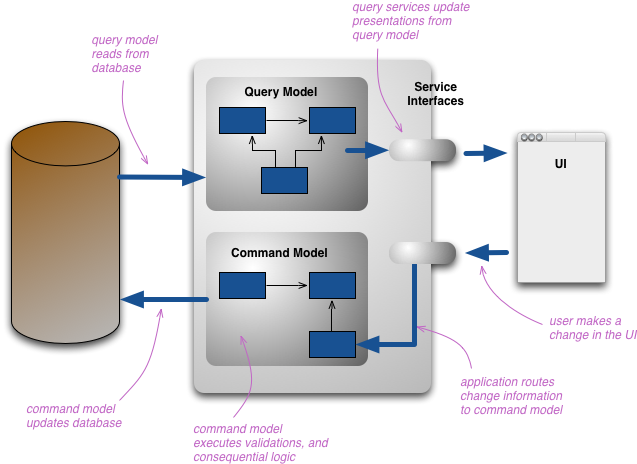
別々のモデルとは、通常、異なるオブジェクトモデルを意味し、おそらく異なる論理プロセスで、おそらく別のハードウェアで実行されます。Webの例では、ユーザーはクエリモデルを使用してレンダリングされたWebページを見ているとします。変更を開始した場合、その変更は処理のために別のコマンドモデルにルーティングされ、結果の変更は更新された状態をレンダリングするためにクエリモデルに伝達されます。
ここにはかなりのバリエーションの余地があります。インメモリモデルは同じデータベースを共有する場合があります。その場合、データベースは2つのモデル間の通信として機能します。ただし、別々のデータベースを使用することもでき、クエリ側のデータベースを effectively real-time レポーティングデータベース(ReportingDatabase)にします。この場合、2つのモデルまたはそれらのデータベース間の何らかの通信メカニズムが必要です。
2つのモデルは別々のオブジェクトモデルではないかもしれません。リレーショナルデータベースのビューと同様に、同じオブジェクトがコマンド側とクエリ側に異なるインターフェースを持っている可能性があります。しかし、通常、CQRSについて耳にするとき、それらは明確に別々のモデルです。
CQRSは、他のアーキテクチャパターンと自然に適合します。
- CRUDを介して対話する単一の表現から離れるにつれて、タスクベースのUIに簡単に移行できます。
- CQRSはイベントベースのプログラミングモデルによく適合します。イベントコラボレーション(Event Collaboration)と通信する別々のサービスにCQRSシステムを分割するのが一般的です。これにより、これらのサービスはイベントソーシング(Event Sourcing)を簡単に利用できます。
- モデルを分離すると、それらのモデルの整合性を維持することがどれほど難しいかという疑問が生じ、結果整合性(eventual consistency)を使用する可能性が高まります。
- 多くのドメインでは、更新時に多くのロジックが必要になるため、EagerReadDerivationを使用してクエリ側モデルを簡素化するのが理にかなっている場合があります。
- 書き込みモデルがすべての更新のイベントを生成する場合、読み取りモデルをEventPostersとして構造化し、MemoryImagesにすることで、多くのデータベースインタラクションを回避できます。
- CQRSは、ドメイン駆動設計(Domain-Driven Design)の恩恵を受ける複雑なドメインに適しています。
いつ使うか
他のパターンと同様に、CQRSは場所によっては役に立ちますが、そうでない場所もあります。多くのシステムはCRUDメンタルモデルに適合するため、そのスタイルで行う必要があります。CQRSは関係者全員にとって大きな精神的飛躍であるため、メリットが飛躍するだけの価値がない限り、取り組むべきではありません。CQRSの成功例に出くわしたことはありますが、これまでのところ、私が遭遇したケースの大部分はそれほど良好ではなく、CQRSはソフトウェアシステムを深刻な困難に陥れる大きな力と見なされています。
特に、CQRSはシステム全体ではなく、システムの特定の部分(DDD用語では境界づけられたコンテキスト(BoundedContext))でのみ使用する必要があります。この考え方では、各境界づけられたコンテキストは、どのようにモデル化するかについて独自に決定する必要があります。
これまでのところ、私は2つの方向にメリットを見ています。1つ目は、CQRSを使用することで、いくつかの複雑なドメインに取り組みやすくなる可能性があることです。ただし、CQRSへのそのような適合性は非常に少数のケースであることを強調しなければなりません。通常、コマンド側とクエリ側には十分な重複があるため、モデルを共有する方が簡単です。CQRSを一致しないドメインで使用すると、複雑さが増し、生産性が低下し、リスクが増加します。
もう1つの主なメリットは、高性能アプリケーションの処理にあります。CQRSを使用すると、読み取りと書き込みの負荷を分離できるため、それぞれを個別にスケーリングできます。アプリケーションで読み取りと書き込みの間に大きな差が見られる場合、これは非常に便利です。そうでなくても、2つの側に異なる最適化戦略を適用できます。この例として、読み取りと更新に異なるデータベースアクセステクニックを使用することが挙げられます。
ドメインがCQRSに適していないが、複雑さやパフォーマンスの問題を追加する要求の厳しいクエリがある場合は、レポーティングデータベース(ReportingDatabase)を使用できることを忘れないでください。CQRSは、すべてのクエリに個別のモデルを使用します。レポーティングデータベースを使用すると、ほとんどのクエリにはメインシステムを引き続き使用しますが、より要求の厳しいクエリはレポーティングデータベースにオフロードします。
これらの利点にもかかわらず、CQRSの使用には非常に注意する必要があります。多くの情報システムは、読み取られるのと同じ方法で更新される情報ベースの概念によく適合しており、そのようなシステムにCQRSを追加すると、複雑さが大幅に増す可能性があります。確かに、生産性に大きな負担をかけ、プロジェクトに不当な量のリスクを追加するケースを見てきました。優れたチームの手にかかってもです。CQRSはツールボックスに入れておくのに適したパターンですが、うまく使用するのは難しく、誤って処理すると重要な部分を簡単に切り取ってしまう可能性があることに注意してください。
参考文献
- Greg Young(グレッグ・ヤング)氏は、私がこのアプローチについて話を聞いた最初の人物です。これは、私が最も気に入っている彼からの要約です。
- Udi Dahan(ウディ・ダハン)氏はCQRSのもう1人の支持者であり、この手法の詳細な説明があります。
- このアプローチについて話し合うための活発なメーリングリストがあります。