

このパターンは"レガシー置き換えのパターン"の一部です
ソースに戻す
データの元のソースを特定し、それに統合します
2022年7月7日
多くの組織では、新しいシステムをメインフレームなどに統合する作業が完了すると、毎回統合を繰り返すよりも、メインフレームを介してそのシステムと対話する方がはるかに簡単になります。モノリシックアーキテクチャを持つ多くのレガシーシステムでは、これは理にかなっていました。同じシステムを同じモノリスに複数回統合することは無駄であり、おそらく混乱を招くでしょう。時間の経過とともに、他のシステムは、元の統合システムがしばしば「忘れ去られた」状態で、このデータを取得するためにレガシーシステムにアクセスし始めます。
通常、これはレガシーシステムが複数のシステムの単一統合ポイントになり、したがって、そのデータを必要とするビジネスプロセスの主要なアップストリームデータソースになることにつながります。侵襲的なクリティカルアグリゲーターのように、このアプローチを数回繰り返して、レガシーデータ表現への緊密な結合を追加すると、レガシーの置き換えに大きな課題が生じる可能性があります。
データソースと統合ポイントをレガシー資産の「向こう側」まで遡ることで、レガシーの置き換えの取り組みのソースに「戻る」ことができます。これにより、レガシーへの依存を早期に軽減できるだけでなく、より近代的な統合技術を活用できるため、データの品質と適時性を向上させる機会が得られます。
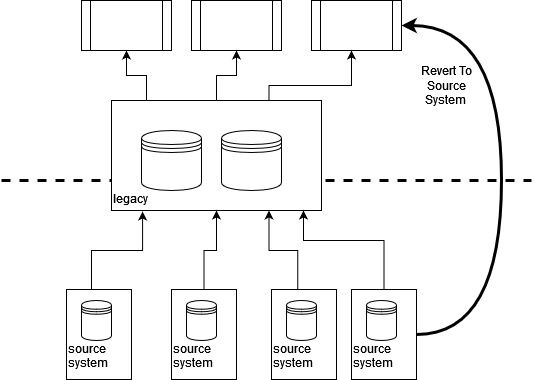
GDPRなどのビジネス上および法的理由から、データの真のソースを理解することがますます重要になっていることに注意することも重要です。大規模なレガシー資産を持つ多くの組織では、障害または問題が発生した場合にのみ、データの真のソースが明確になります。
仕組み
レガシーの置き換え作業の一環として、主要なデータフローの発生源とシンクを追跡する必要があります。問題をどのように分割するかによって、すべてのシステムとデータに対して一度にこれを行う必要はない場合があります。ただし、実行する作業の全体的な規模を把握するには、主要なフローを理解することが非常に役立ちます。
私たちの目標は、ある種のデータフローマップを作成することです。使用される実際の形式はそれほど重要ではありません。重要なのは、この発見がレガシーシステムで止まるのではなく、基礎となる統合ポイントをより深く掘り下げることです。私たちはクライアントと協力している間、多くのアーキテクチャ図を見てきましたが、レガシーの背にあるものが無視されていることが驚くほど多いです。
システムを介してデータを追跡するためのいくつかの手法があります。大まかに言って、これらをアップストリームまたはダウンストリームのパスを追跡するものと見なすことができます。基礎となるソースシステムとの間でデータが双方向に流れることがよくありますが、組織はデータソースの観点からのみ考える傾向があります。おそらく、レガシーシステムのレンズを通して見ると、これは統合の中で最も目に見える部分でしょうか?レガシーからソースシステムに戻るデータの流れが、統合の中で最も理解されておらず、最も文書化されていない部分であることは珍しくありません。
アップストリームの場合、多くの場合、ビジネスプロセスから始めて、レガシーへのデータの流れを追跡しようとします。これは、特に古いシステムでは、統合テクノロジーの多くの異なる組み合わせがあるため、困難な場合があります。使用できる便利な手法の1つは、主要なビジネスプロセスステップのシーケンス図とともにデータフロー図を作成することを目標としたCRCカードを使用することです。どの手法を使用する場合でも、適切な人々、理想的にはレガシーシステムに最初に携わった人々、より一般的には現在それらをサポートしている人々を関与させることが不可欠です。これらの人々が利用できず、物事の仕組みの知識が失われている場合は、ソースから始めてダウンストリームで作業する方が適切かもしれません。
統合のダウンストリームの追跡も非常に役立ち、私たちの経験ではしばしば無視されます。その理由の一部は、機能パリティが有効な場合、焦点は既存のビジネスプロセスにのみ向けられる傾向があるためです。ダウンストリームを追跡する場合、基礎となる統合ポイントから始めて、それがサポートする主要なビジネス機能とプロセスまで追跡しようとします。地質学者が川の可能性のある発生源に染料を導入し、染料が最終的にダウンストリームのどの小川や支流に現れるかを確認するのとよく似ています。このアプローチは、レガシー統合と対応するシステムに関する知識が不足している場合に特に役立ち、新しいコンポーネントまたはビジネスプロセスを作成する場合に特に役立ちます。ダウンストリームを追跡すると、このデータが正確なパスを最初に知らなくてもどこで機能するのかを発見できる場合があります。ここでは、元のソースデータと比較して、途中で変更されたかどうかを確認することをお勧めします。
データの流れを理解したら、ソースでデータの傍受またはコピーを作成できるかどうかを確認できます。これは、新しいソリューションに流れ込む可能性があります。したがって、レガシーに統合する代わりに、新しいコンポーネントがソースに戻ることを可能にする新しい統合を作成します。アップストリームとダウンストリームの両方のフローを考慮する必要がありますが、以下の例で示すように、これらを一緒に実装する必要はありません。
新しい統合が不可能な場合は、イベントインターセプトなどを使用してデータフローのコピーを作成し、それを新しいコンポーネントにルーティングできます。既存のレガシー動作への依存を減らすために、できるだけ上流で行いたいと考えています。
使用時期
ソースへの復帰は、最終的にレガシーシステムの「背後に隠れている」統合ポイントから供給されるデータに依存する特定のビジネス機能またはプロセスを抽出する場合に最も役立ちます。データが変更されずにレガシーを通過する場合、つまり消費前にほとんど処理やエンリッチメントが行われない場合に最適です。実際にはありそうにないように聞こえるかもしれませんが、レガシーが統合ハブとして機能している多くのケースが見つかります。これらの状況でデータに発生する主な変更は、データの損失とデータの適時性の低下です。データの損失は、フィールドと要素がレガシーシステムで表現する方法がなかったため、または必要な変更を加えるのに費用とリスクがかかりすぎたためにフィルタリングされることが多いためです。多くのレガシーシステムはデータインポートにバッチジョブを使用するため、適時性が低下します。クリティカルアグリゲーターで説明したように、「安全なデータ更新期間」はしばしば事前に定義されており、変更することはほぼ不可能です。
ソースへの復帰と並列実行と調整を組み合わせて、レガシー内でデータに追加の変更が発生していないことを検証できます。これは一般的に使用するのに適したアプローチですが、データが異なるパスを介して異なるエンドポイントに流れるが、最終的には同じ結果を生成する必要がある場合に特に役立ちます。
より豊富でタイムリーなデータが利用できることが多いため、ソースへの復帰を使用するための強力なビジネスケースを作成することもできます。ソースシステムが数回アップグレードまたは変更され、これらの変更がレガシーの背後に効果的に隠されたままになることはよくあります。データの改善が実際にはこれらのアップグレードの主な理由であったが、より頻繁で豊富な更新をレガシーパスを介して利用できなかったため、メリットが完全には実現されなかった例を複数見てきました。
基礎となる統合ポイントとのデータの双方向フローがある場合にも、このパターンを使用できますが、ここではより注意が必要です。最終的にソースシステムに向かう更新は、最初にレガシーシステムを通過する必要があります。ここでは、他のプロセスがトリガーまたは更新される場合があります。幸いなことに、アップストリームとダウンストリームのフローを分割することは可能です。そのため、たとえば、ソースシステムに戻る変更はレガシーを介して流れ続けることができますが、更新はソースから直接取得できます。
ソースシステムに存在する可能性のある機能横断的な要件と制約に注意することが重要です。そのシステムに過負荷をかけたり、必要なデータを直接提供するのに十分な信頼性や可用性がないことを発見したくありません。
小売店の例
ある小売クライアントの場合、ソースへの復帰を使用して、新しいコンポーネントを抽出すると同時に、既存のビジネス機能を向上させることができました。クライアントには、広大な店舗と、より最近作成されたオンラインショッピング用のWebサイトがありました。当初、新しいWebサイトはすべての在庫情報をレガシーシステムから取得していました。このデータは、倉庫在庫追跡システムと店舗自体から取得されました。
これらの統合は、夜間バッチジョブを介して実行されました。倉庫の場合、在庫は1日に1回しか倉庫から出荷されないため、ビジネスは毎朝受信するバッチ更新が約18時間有効であることを確認できました。店舗の場合、在庫は明らかに営業日のいつでも店舗から出荷される可能性があるため、これは問題を引き起こしました。
この制約を考えると、ウェブサイトは倉庫にある在庫のみを販売用に提供しました。翌日受信した店舗在庫データと組み合わせたサイトからの分析によると、その結果、売上が失われていることが明らかになりました。必要な在庫は1日中店舗で入手可能でしたが、レガシー統合のバッチの性質上、これを活用することは不可能でした。
このケースでは、最初はウェブサイト専用に新しい在庫コンポーネントが作成されましたが、最終的には組織全体の新しい記録システムとなることを目標としていました。このコンポーネントは、販売が行われた時点でほぼリアルタイムの更新を提供できる、店舗内のレジシステムと直接統合されていました。実際、ビジネスは電子決済をサポートするために店舗を接続する信頼性の高いネットワークに投資しており、このネットワークには十分な余剰容量がありました。倉庫の在庫レベルは、最初はレガシーシステムから取得されましたが、長期的な目標として、後段階でこれもソースに戻すことが計画されていました。
その結果、ウェブサイトは、店舗在庫を店頭予約とオンライン販売の両方に安全に提供できるようになりました。また、新しい在庫コンポーネントは、在庫移動に関するより豊富でタイムリーなデータを提供しました。新しい在庫コンポーネントのソースに戻すことで、組織ははるかにタイムリーな販売データにアクセスできることに気付きました。当時、販売データはバッチプロセスを介してレガシーシステムにのみ更新されていました。製品ラインや価格などの参照データは、メインフレームを介して店舗内システムに引き続き流れ込んでいましたが、これは変更頻度が低いことを考えると全く問題ありませんでした。
重要な改訂
2022年7月7日:公開