
サーキットブレーカー
2014年3月6日

ソフトウェアシステムが、異なるプロセスで実行されている、おそらくネットワークを介して異なるマシン上のソフトウェアへのリモート呼び出しを行うことは一般的です。インメモリ呼び出しとリモート呼び出しの大きな違いの1つは、リモート呼び出しは失敗したり、応答がないままタイムアウト制限に達するまでハングしたりする可能性があることです。さらに悪いことに、応答のないサプライヤーに多くの呼び出し元がいる場合、重要なリソースを使い果たし、複数のシステムにわたってカスケード障害を引き起こす可能性があります。彼の優れた著書「Release It」で、Michael Nygardは、この種の壊滅的なカスケードを防ぐためのサーキットブレーカーパターンを普及させました。
サーキットブレーカーの背後にある基本的な考え方は非常にシンプルです。保護された関数呼び出しをサーキットブレーカーオブジェクトでラップします。これは、障害を監視します。障害が特定の閾値に達すると、サーキットブレーカーはトリップし、保護された呼び出しがまったく行われずに、サーキットブレーカーへのそれ以降のすべての呼び出しがエラーで返されます。通常、サーキットブレーカーがトリップした場合の何らかの監視アラートも必要になります。
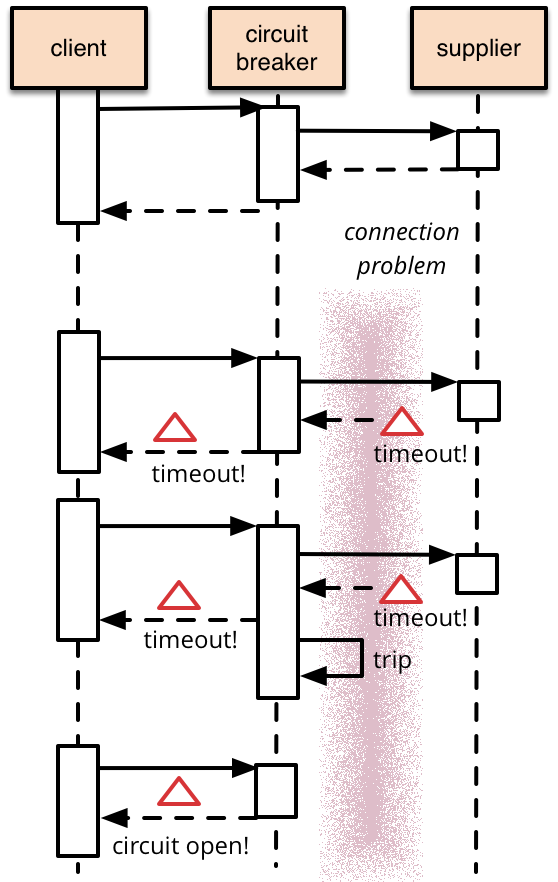
これが、タイムアウトに対する保護を備えたRubyでのこの動作の簡単な例です。
ブレーカーは、保護された呼び出しであるブロック(ラムダ)で設定します。
cb = CircuitBreaker.new {|arg| @supplier.func arg}
ブレーカーはブロックを格納し、さまざまなパラメーター(閾値、タイムアウト、監視用)を初期化し、ブレーカーを閉じた状態にリセットします。
class CircuitBreaker...
attr_accessor :invocation_timeout, :failure_threshold, :monitor
def initialize &block
@circuit = block
@invocation_timeout = 0.01
@failure_threshold = 5
@monitor = acquire_monitor
reset
end
サーキットブレーカーを呼び出すと、サーキットが閉じている場合は基礎となるブロックが呼び出されますが、開いている場合はエラーが返されます。
# client code
aCircuitBreaker.call(5)
class CircuitBreaker...
def call args
case state
when :closed
begin
do_call args
rescue Timeout::Error
record_failure
raise $!
end
when :open then raise CircuitBreaker::Open
else raise "Unreachable Code"
end
end
def do_call args
result = Timeout::timeout(@invocation_timeout) do
@circuit.call args
end
reset
return result
end
タイムアウトが発生すると、失敗カウンターが増加し、成功した呼び出しによって0に戻されます。
class CircuitBreaker...
def record_failure
@failure_count += 1
@monitor.alert(:open_circuit) if :open == state
end
def reset
@failure_count = 0
@monitor.alert :reset_circuit
end
失敗回数を閾値と比較して、ブレーカーの状態を決定します。
class CircuitBreaker...
def state
(@failure_count >= @failure_threshold) ? :open : :closed
end
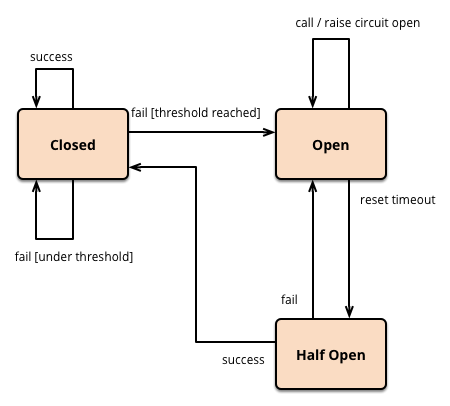
この単純なサーキットブレーカーは、サーキットが開いている場合に保護された呼び出しを行うのを回避しますが、状況が改善されたときにリセットするには外部の介入が必要です。これは、建物の電気サーキットブレーカーでは妥当なアプローチですが、ソフトウェアサーキットブレーカーの場合、ブレーカー自体が基礎となる呼び出しが再び機能しているかどうかを検出できます。適切な間隔後に保護された呼び出しを再度試行し、成功した場合はブレーカーをリセットすることで、この自己リセット動作を実装できます。
この種のブレーカーを作成するには、リセットを試行するための閾値を追加し、最後のエラーの時間を保持する変数を設定する必要があります。
class ResetCircuitBreaker...
def initialize &block
@circuit = block
@invocation_timeout = 0.01
@failure_threshold = 5
@monitor = BreakerMonitor.new
@reset_timeout = 0.1
reset
end
def reset
@failure_count = 0
@last_failure_time = nil
@monitor.alert :reset_circuit
end
これで、3番目の状態(半開)が追加されます。これは、サーキットが問題が解決されたかどうかを確認するためのトライアルとして実際の呼び出しを行う準備ができていることを意味します。
class ResetCircuitBreaker...
def state
case
when (@failure_count >= @failure_threshold) &&
(Time.now - @last_failure_time) > @reset_timeout
:half_open
when (@failure_count >= @failure_threshold)
:open
else
:closed
end
end
半開状態で呼び出しが要求されると、トライアル呼び出しが行われ、成功した場合はブレーカーがリセットされ、失敗した場合はタイムアウトが再開されます。
class ResetCircuitBreaker...
def call args
case state
when :closed, :half_open
begin
do_call args
rescue Timeout::Error
record_failure
raise $!
end
when :open
raise CircuitBreaker::Open
else
raise "Unreachable"
end
end
def record_failure
@failure_count += 1
@last_failure_time = Time.now
@monitor.alert(:open_circuit) if :open == state
end
この例は単純な説明的なものであり、実際にはサーキットブレーカーはさらに多くの機能とパラメーター化を提供します。多くの場合、保護された呼び出しが発生させる可能性のあるさまざまなエラー(ネットワーク接続エラーなど)から保護します。すべてのエラーがサーキットをトリップするわけではなく、一部は通常のエラーを反映し、通常のロジックの一部として処理する必要があります。
トラフィックが多い場合、最初のタイムアウトを待っている多くの呼び出しで問題が発生する可能性があります。リモート呼び出しは多くの場合遅いため、結果が返ってきたときに処理するために、FutureまたはPromiseを使用して各呼び出しを別のスレッドに配置することをお勧めします。これらのスレッドをスレッドプールから取得することにより、スレッドプールが使い果たされたときにサーキットがブレークするように配置できます。
この例は、ブレーカーをトリップする簡単な方法を示しています。成功した呼び出しでリセットされるカウントです。より高度なアプローチでは、エラーの頻度を確認し、たとえば50%の失敗率に達するとトリップする可能性があります。タイムアウトの場合は10の閾値、接続エラーの場合は3の閾値など、エラーごとに異なる閾値を設定することもできます。
私が示した例は同期呼び出し用のサーキットブレーカーですが、サーキットブレーカーは非同期通信にも役立ちます。ここでの一般的なテクニックは、すべての要求をキューに配置することであり、サプライヤーはその速度で消費します。これは、サーバーの過負荷を防ぐのに役立つテクニックです。この場合、キューがいっぱいになるとサーキットがブレークします。
サーキットブレーカー単体で、失敗する可能性のある操作に関連付けられたリソースの削減に役立ちます。クライアントはタイムアウトを待つ必要がなくなり、ブレークしたサーキットは苦戦しているサーバーに負荷をかけるのを回避します。ここでは、サーキットブレーカーの一般的なケースであるリモート呼び出しについて説明していますが、システムの一部を他の部分の障害から保護したい場合に、どの状況でも使用できます。
サーキットブレーカーは監視にとって貴重な場所です。ブレーカーの状態の変更はすべてログに記録する必要があり、ブレーカーはより詳細な監視のためにその状態の詳細を表示する必要があります。ブレーカーの動作は、環境のより深い問題に関する警告の優れた情報源になることがよくあります。運用担当者は、ブレーカーをトリップまたはリセットできる必要があります。
ブレーカー単体でも価値がありますが、それらを使用するクライアントはブレーカーの障害に対応する必要があります。リモート呼び出しの場合と同様に、失敗した場合に何をするかを検討する必要があります。実行中の操作に失敗しますか、それとも回避策がありますか?クレジットカードの承認は後で処理するためにキューに配置できますが、一部のデータを取得できないことは、表示するのに十分な古いデータを表示することで軽減される場合があります。
参考資料
Netflixのテクノロジーブログには、多くのサービスを持つシステムの信頼性を向上させるための多くの役立つ情報が含まれています。彼らの依存関係コマンドは、サーキットブレーカーとスレッドプール制限の使用について説明しています。
Netflixは、分散システムのレイテンシとフォールトトレランスに対処するための洗練されたツールであるHystrixをオープンソース化しました。これには、スレッドプール制限付きのサーキットブレーカーパターンの実装が含まれています。
サーキットブレーカーパターンの他のオープンソース実装は、Ruby、Java、Grailsプラグイン、C#、AspectJ、およびScalaにあります。