エンジニアが個々のチーム内で個別にコスト最適化を急ぐ前に、クロスファンクショナルなチームを編成してコスト最適化の取り組みの分析と実行を主導することが最善です。通常、スタートアップ企業のコスト効率は、プラットフォームエンジニアリングチームの責任となります。彼らは最初に問題に気付くからです。しかし、多くの分野からの関与が必要です。インフラストラクチャスキルを持つ技術者と、バックエンドおよびデータシステムに関するコンテキストを持つ技術者で構成される**コスト最適化チーム**を編成することをお勧めします。彼らは影響を受けるチーム間の取り組みを調整し、レポートを作成する必要があるため、テクニカルプログラムマネージャーが役立ちます。
主要なコストドライバーの特定
主要なコスト要因の特定から始めることが重要です。まず、コスト最適化チームは関連する請求書を収集する必要があります。これらは、クラウドプロバイダーおよびSaaSプロバイダーからのものになります。スプレッドシート、BIツール、Jupyter Notebookなど、分析ツールを使用してコストを分類することが役立ちます。さまざまな次元で集計してコストを分析することで、最大の効果を達成するための作業の特定と優先順位付けに役立つ独自の洞察が得られます。たとえば
**アプリケーション/システム:** 一部のアプリケーション/システムは、他のシステムよりもコストに大きく寄与することがあります。タグ付けは、コストをさまざまなシステムに関連付けるのに役立ち、作業に関与するチームを特定するのに役立ちます。
**コンピューティング vs ストレージ vs ネットワーク:** 一般的に、コンピューティングコストはストレージコストよりも高くなる傾向があり、ネットワーク転送料は予想以上に高コストになることがあります。これは、ホスティング戦略またはアーキテクチャの変更が役立つかどうかを特定するのに役立ちます。
**事前本番環境 vs 本番環境:** 事前本番環境のコストは、本番環境のコストよりもかなり低くなければなりません。しかし、事前本番環境ではアクセス制御が緩んでいる傾向があるため、予想以上にコストが高くなることは珍しくありません。これは、非本番環境にデータが蓄積されすぎている、または一時的またはPoCインフラストラクチャのクリーンアップが不足していることを示している可能性があります。
**運用 vs 分析:** 企業の運用システムのコストが分析システムのコストと比べてどの程度であるべきかという経験則はありませんが、エンジニアリングリーダーは、実際の支出と比較して適切な比率を特定するために、企業における運用環境と分析環境の規模と価値を把握しておく必要があります。
**サービス/機能プロバイダー:** プロジェクト管理、製品ロードマッピング、監視、インシデント管理、開発ツールなど、エンジニアリングリーダーは、使用中のツールのサブスクリプションとライセンスの数、およびそのコストに驚くことがよくあります。これは、統合の機会を特定するのに役立ち、交渉力とコスト削減にもつながる可能性があります。
ドライバーのインベントリとその関連コストの結果により、コスト最適化チームは、どのタイプのコストが最も高く、企業のアーキテクチャがどのようにそれらに影響を与えているかをよりよく理解できるようになります。この演習は、過去3~6ヶ月のコストなど、履歴データを使用してコストの変化と特定の製品または技術的な決定を関連付けることで、根本原因を特定する際にさらに効果的です。
主要なコストドライバーに対するコスト削減レバーの特定
コスト、トレンド、およびその推進要因を特定した後、次の質問は、コストを削減するためにどのような調整策を使用できるかということです。より一般的な方法の一部を以下に示します。もちろん、以下のリストは網羅的なものではなく、適切な調整策は多くの場合、状況によって大きく異なります。
**サイズ変更:** サイズ変更とは、ワークロードのリソース構成を利用率に近づけることです。
エンジニアは、ワークロードに必要なリソース構成を確認するために、多くの場合見積もりを実行します。ワークロードが時間とともに進化するにつれて、初期の見積もりは、初期の仮定が正しかったか、またはまだ適用できるかどうかを確認するために、フォローアップされることはめったになく、潜在的に利用率の低いリソースが残される可能性があります。
VMまたはコンテナ化されたワークロードのサイズを変更するには、プロビジョニングされたものと比較して、CPU、メモリ、ディスクなどの利用率を比較します。より抽象的なレベルでは、Azure SynapseやDynamoDBなどのマネージドサービスには、プロビジョニングされたインフラストラクチャの独自のユニットと、リソースの過小利用を強調する独自の監視ツールがあります。一部のツールは、特定のワークロードに対して最適なリソース構成を推奨するまでになっています。
リソースの割り当てを厳密に削減することなく、リソース構成を変更することでコストを削減する方法があります。クラウドプロバイダーには複数のインスタンスタイプがあり、通常、複数のインスタンスタイプが異なる価格帯で特定のリソース要件を満たすことができます。たとえば、AWSでは、新しいバージョンは一般的に安価であり、t3.smallはt2.smallよりも約10%安価です。またはAzureでは、紙面上の仕様は高いように見えますが、EシリーズはDシリーズよりも安価です。私たちは、クライアントがEシリーズに切り替えることでVMコストを30%削減するのを支援しました。
最後のヒントとして、特定のワークロードのサイズ変更を行う際に、コスト最適化チームは事前に購入したコミットメントを常に把握しておく必要があります。予約インスタンスなどの事前購入コミットメントは、特定のインスタンスタイプまたはファミリに関連付けられているため、特定のワークロードのインスタンスタイプを変更することでその特定のワークロードのコストを削減できる場合でも、予約インスタンスコミットメントの一部が未使用または無駄になる可能性があります。
**エフェメラルインフラストラクチャの使用:** コンピューティングリソースは、必要な時間よりも長く動作することがよくあります。たとえば、特定のタイムゾーンで作業するデータサイエンティストが使用する対話型データ分析クラスタは、データサイエンティストの勤務時間外に使用されない場合でも、24時間365日稼働している可能性があります。同様に、エンジニアが作業に使用しているにもかかわらず、開発環境が毎日終日稼働しているのを目撃してきました。
多くのマネージドサービスは、実際に使用したコンピューティング時間に対してのみ料金を支払うことを保証する自動終了またはサーバーレスコンピューティングオプションを提供しています。これらはすべて、覚えておくべき便利な調整策です。VMやディスクなどの他の、よりインフラストラクチャレベルのリソースについては、設定された基準(例:X分のアイドル時間)に基づいて、リソースのシャットダウンまたはクリーンアップを自動化できます。
エンジニアリングチームは、エフェメラルコンピューティングをさらに採用する方法として、FaaSへの移行を検討する可能性があります。これは、大幅なアーキテクチャの変更と成熟した開発者エクスペリエンスプラットフォームを必要とする重大な取り組みであるため、注意深く検討する必要があります。私たちは、FaaSに飛び込むことで多くの不要な複雑さを導入した企業を見てきました(極端な例:lambda pinball)。
**スポットインスタンスの活用:** スポットインスタンスの単位コストは、オンデマンドインスタンスよりも最大約70%低くなる可能性があります。もちろん、欠点としては、クラウドプロバイダーが短時間でスポットインスタンスを要求できるため、そこで実行されているワークロードが中断されるリスクがあります。したがって、クラウドプロバイダーは一般的に、ステートレスなWebサービス、CI/CDワークロード、アドホックな分析クラスタなど、中断からより簡単に復旧できるワークロードにスポットインスタンスを使用することを推奨しています。
上記のワークロードタイプの場合でも、中断からの復旧には時間がかかります。特定のワークロードが時間制約されている場合、スポットインスタンスは最適な選択肢ではない可能性があります。逆に、時間制約がそれほど厳しくない事前本番環境には、スポットインスタンスが簡単に適合する可能性があります。
**コミットメントベースの価格設定の活用:** スタートアップ企業が規模に達し、使用パターンを明確に理解している場合、チームが契約にコミットメントベースの価格設定を取り入れることをお勧めします。オンデマンド価格は、通常、事前購入コミットメントで得られる価格よりも高くなります。ただし、スケールアップの場合でも、使用パターンが安定していない、より実験的な製品やサービスには、オンデマンド価格設定が依然として役立つ可能性があります。
コミットメントベースの価格設定には複数の種類があります。これらはすべてオンデマンド価格よりも割引価格で提供されますが、特性が異なります。クラウドインフラストラクチャの場合、予約インスタンスは一般的に、特定のインスタンスタイプまたはファミリに関連付けられた使用量のコミットメントです。セービングプランは、時間あたりの特定のリソース(例:コンピューティング)単位の使用量に関連付けられた使用量のコミットメントです。どちらも1年から3年のコミットメント期間を提供しています。ほとんどのマネージドサービスにも、独自のコミットメントベースの価格設定バージョンがあります。
アーキテクチャ設計: マイクロサービスの普及に伴い、企業はより細かい粒度のアーキテクチャアプローチを採用しています。デジタルネイティブ企業の中期段階において、60個のサービスに遭遇することは珍しくありません。
しかし、消費者視点で設計されていないAPIは、消費者がそのデータの小さな部分しか必要としない場合でも、大量のペイロードを消費者に送信します。さらに、一部のサービスは、特定のタスクを独立して実行できる代わりに、分散モノリスを形成し、タスクを完了するために他のサービスへの複数回の呼び出しを必要とします。これらのシナリオで示されているように、ドメイン境界の不適切さや複雑すぎるアーキテクチャは、高いネットワークコストとして現れる可能性があります。
システム間のドメイン境界を改善するためにアーキテクチャやマイクロサービス設計をリファクタリングすることは大規模なプロジェクトになりますが、コスト削減以外にも、多くの点で長期的な大きな影響を与えます。そのような取り組みを始める準備ができていない組織や、これらのアーキテクチャの問題によるコストへの影響に対処するための戦術的なアプローチを探している組織は、戦略的なキャッシングを使用して、通信の頻度を最小限に抑えることができます。
データのアーカイブと保持ポリシーの適用: どのストレージシステムにおいても、ホット層は純粋なストレージにとって最も高価な層です。あまり頻繁に使用されないデータについては、クール層、コールド層、またはアーカイブ層に配置してコストを抑えることを検討してください。
まず、アクセスパターンを確認することが重要です。私たちのチームの1つは、大量のデータをコールド層に保存していたにもかかわらず、ストレージコストが増加しているプロジェクトに遭遇しました。プロジェクトチームは、コールド層に配置したデータに頻繁にアクセスしていたことに気づかず、それがコスト増加につながっていました。
重複ツールの統合: サービスプロバイダーの観点からコスト要因を列挙する際に、コスト最適化チームは、会社が同じカテゴリ(例:監視)内で複数のツールに対して料金を支払っていることに気づいたり、あるいは特定のツールを実際に使用しているチームがあるかどうか疑問に思ったりする可能性があります。未使用のリソース/ツールを削除し、カテゴリ内の重複ツールを統合することは、間違いなくコスト削減のもう一つの手段です。
統合後の使用量によっては、より有利な価格帯を利用できるようになったり、交渉力が高まったりすることで、さらなるコスト削減が期待できます。
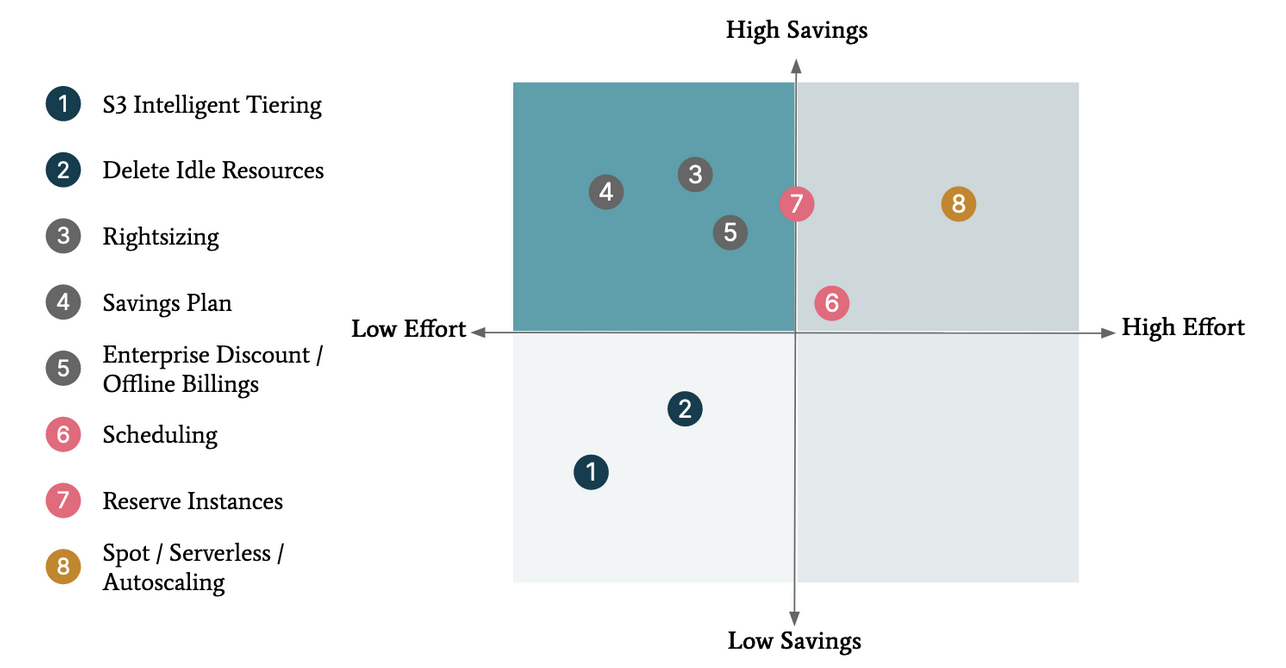
努力と影響度に基づいた優先順位付け
コスト削減の可能性のある機会には、2つの重要な特性があります。潜在的な影響(潜在的なコスト削減の規模)と、それらを現実のものにするために必要な努力のレベルです。
会社が迅速にコスト削減を必要とする場合、50,000ドルかかるカテゴリから10%削減することは、5,000ドルかかるカテゴリから10%削減することよりも自然に効果があります。
しかし、コスト削減の機会は、実現するために異なるレベルの努力を必要とします。最適なサイズ変更やコミットメントベースの価格設定の利用などの構成変更よりも、コードやアーキテクチャの変更を必要とする機会もあります。必要な労力を正しく理解するために、コスト最適化チームは関連チームからの意見を得る必要があります。
この演習の終わりには、コスト最適化チームは、潜在的なコスト削減、実現するための努力、そして実装までのリードタイムに関連する遅延コスト(低/高)を伴う機会のリストを作成する必要があります。より複雑な機会については、後で説明するように、適切な財務分析を指定する必要があります。次に、コスト最適化チームは、イニシアチブを支援するリーダーとレビューを行い、どの機会に取り組むかを優先順位付けし、実行に必要なリソース要求を行います。
コスト最適化チームは、必要な行動と理由(潜在的な影響と優先順位)について十分な文脈を与えた後、影響を受ける製品およびプラットフォームチームと協力して実行するのが理想的です。ただし、必要に応じて、コスト最適化チームは能力やガイダンスを提供することができます。実行が進むにつれて、チームは、実現した節約と予想された節約、およびビジネスの優先順位からの学びに基づいて優先順位を再設定する必要があります。