スタートアップは、システムが既にダウンした時になって初めてレジリエンスに対処することが多く、非常にリアクティブなアプローチをとることが多いです。スケールアップにとって、過剰なシステムダウンタイムは、機能復旧に費やされる労力と、顧客の不満という点の両方から、組織にとって大きなボトルネックとなります。
これを乗り越えるには、レジリエンスをビジネス目標に組み込む必要があります。これにより、ビジネスシステムのアーキテクチャ、設計、プロダクトマネジメント、ガバナンスに影響を与えます。この記事では、レジリエンスとオブザーバビリティのボトルネックについて探ります。どのようにそれを認識し、既に発生していることに気付き、ボトルネックを乗り越えるために何ができるのかを説明します。
ボトルネックに陥った原因は?
スタートアップの最初の目標の1つは、最初の製品を市場に投入することです。できるだけ多くのユーザーに製品を届けてフィードバックを得ることが、通常は最優先事項です。顧客が製品を使用し、提供する独自の価値を認識すれば、スタートアップは市場シェアを獲得し、信頼できる収益源を持つことができます。しかし、そこへ到達するには、製品のレジリエンスを犠牲にすることがよくあります。
スタートアップは、リカバリプロセスの自動化をスキップすることを決定することがあります。小規模な場合は、組織はシステムをよく知っている開発者を通じてレジリエンスを提供できると考えているためです。インシデントはリアクティブに処理され、解決策は手動で行われます。増加した負荷に対処するために別のインスタンスをスピンアップしたり、サービスが失敗したときに再起動したりすることが考えられます。最初の顧客は、システムの停止を経験することで、真のレジリエンスの不足を認識しているかもしれません。
私たちのスケールアップエンゲージメントの1つで、クライアントはシステムを迅速に本番環境に投入するために、クラスタ内のヘルスチェックメカニズムの優先順位を下げました。開発者は、必要な数回、スタートアッププロセスを正常に管理しました。重要なデモでは、システムのパフォーマンスに影響を与える外部要因がないように、新しいクラスタをスピンアップすることにしました。残念ながら、クラスタで実行されているすべてのサービスのステータスを積極的に管理することが見過ごされました。システムが完全に稼働する前にデモが開始され、システムの重要なコンポーネントが潜在的な顧客の前で失敗しました。
基本的に、組織は、手動介入によってダウンタイムから回復できると確信し、ユーザー向け機能をレジリエンスの自動化よりも優先するという明示的なトレードオフを行いました。これは、管理可能な規模のスタートアップの間は許容できるトレードオフである可能性があります。しかし、高い成長率を経験し、スタートアップからスケールアップへと変化するにつれて、レジリエンスの欠如はスケーリングのボトルネックとなることが証明され、サービス中断の増加として現れ、DevOpsチームのOps側の作業が増加し、チームの生産性が低下します。その影響は突然現れるように見えます。なぜなら、その効果は顧客ベースの成長に対して非線形になる傾向があるからです。最近まで管理可能だったものが、突然非常に大きな影響を与えるようになります。最終的に、システムの規模がチームの能力を超える手動作業を生み出し、顧客体験に影響を与えるようになります。生産性の低下と顧客の不満が組み合わさって、生き残りが困難なボトルネックにつながります。
では、製品がスケーリングのボトルネックに遭遇しようとしているかどうかを知るにはどうすればよいのでしょうか?さらに、これらの兆候を知っていれば、どのようにボトルネックを回避したり、スケールに追いついたりできるのでしょうか?クライアントで経験した一般的な課題と、最も効果的であると判明した解決策について説明する際に、それらに答えていきます。
スケーリングのボトルネックが近づいている兆候
ビジネスの規模が急速に変化する環境で運用することは常に困難です。早期に高トラフィック量に対処するための投資は、リソースの無駄遣いになります。遅すぎる投資は、顧客がすでにスケーリングのボトルネックの影響を感じていることを意味します。
運用モデルをリアクティブからプロアクティブにシフトするには、重要なビジネス上の意思決定をサポートするのに十分な信頼レベルで将来の行動を予測できる必要があります。データに基づいた意思決定を行うことは常に目標です。重要なのは、ボトルネックに反応するのではなく、ボトルネックに備え、できれば回避するための指針となる先行指標を見つけることです。私たちの経験に基づいて、このボトルネックに近づく際の一般的な前提条件に関連する一連の指標を見つけました。
レジリエンスが第一級の考慮事項になっていない
これは最も分かりにくい兆候かもしれませんが、おそらく最も重要です。レジリエンスは純粋に技術的な問題であり、製品の機能ではないと考えられています。新しい機能や機能強化のために優先順位が低くなります。場合によっては、優先順位付けされるべき懸念事項でさえありません。
簡単なテストがあります。チーム内で発生するさまざまな議論に耳を傾け、レジリエンスが議論される文脈に注意してください。スタンドアップの一部としては含まれていないが、開発者会議では取り上げられることが分かるかもしれません。開発チームが運用を担当していない場合、レジリエンスは事実上サイロ化されます。そのような場合は、レジリエンスがどのように議論されているかに注意深く耳を傾けてください。
レジリエンスへの取り組みが不十分であるという証拠は、しばしば間接的なものです。あるクライアントでは、優先順位付けされていないだけでなく、絶えず増加している技術的負債カードの形で現れているのを見てきました。別のクライアントでは、運用チームのバックログは純粋に顧客インシデントで埋められており、その大部分はシステムが稼働していないか、リクエストを処理できないかのどちらかでした。レジリエンスに関する懸念事項がチームのバックログとロードマップの一部になっていない場合、それは製品の中核ではないという証拠となります。
手動によるレジリエンスの解決策(リアクティブな手動レジリエンス)
組織がサービスの停止をどのように解決するかは、製品が効果的にスケールアップできるかどうかを示す重要な指標となる可能性があります。ここで説明する特性は、根本的に自動化の不足によって引き起こされ、過剰な手動作業につながります。サービスの停止は開発者による再起動によって解決されていますか?高負荷時には、コンピューティングインスタンスをスケーリングするために調整が必要ですか?
一般的に、これらのアプローチは持続可能な運用プラクティスに従っておらず、次のシステム停止に対する脆弱な解決策です。これらには、症状を軽減する一時しのぎの解決策が含まれていますが、将来のレジリエンスを可能にする方法で真に解決することは決してありません。
システムのオーナーシップが明確に定義されていない
組織が迅速に新しいサービスや機能を開発している場合、サービスエコシステムの重要な部分、またはインフラストラクチャ自体が「孤児」になることがよくあります。つまり、運用責任が明確にないということです。その結果、顧客が反応するまで、運用上の問題は気付かれないままになる可能性があります。問題が発生した場合、トラブルシューティングに時間がかかり、停止の解決が遅れる原因となります。責任者を特定するためにチーム間で問題を解決しようとする際に、解決が遅れ、問題がチーム間を行き来する際に全員の時間を無駄にします。
この問題は、マイクロサービス環境特有のものではありません。あるエンゲージメントでは、システムの一部に明確な所有権がないモノリスアーキテクチャで同様の状況を目撃しました。「泥団子」モノリスでは、所有権の問題の明確さがシステム境界の欠如に由来していました。
分散システムの現実を無視している
効果的なシステムを開発することの一部は、複雑なシステムを開発者の頭の中に収まる程度に簡素化できる抽象化を定義して使用することです。これにより、開発者はビジネスに新しい価値と機能を提供するために必要な将来の変更について決定を下すことができます。しかし、他のすべてのことと同様に、行き過ぎることがあり、これらの簡素化が実際にはシステムに影響を与える重要な制約を隠している仮定であることに気付かない場合があります。分散コンピューティングの誤謬を引用すると
- ネットワークは信頼できません。
- あなたのシステムは光の速度の影響を受けます。レイテンシはゼロではありません。
- 帯域幅は有限です。
- ネットワークは本質的に安全ではありません。
- トポロジーは常に設計によって変化します。
- ネットワークとシステムは異種混合です。異なるシステムは負荷下で異なる動作をします。
- 仮想マシンは、最も予期しないタイミングで、まさに間違ったタイミングで消えます。
- 人々がキーボードとマウスにアクセスできるため、ミスは起こります。
- 顧客は(そして実際に)、500ミリ秒以内に次の行動を起こす可能性があります。
多くの場合、テスト環境は理想的な条件を提供するため、これらの仮定に違反することはありません。これらの現実世界の特性を考慮せず(そしてテストせず)設計されたシステムは、何も悪いことが起こらない世界のために設計されています。その結果、システムが隠された仮定に違反し始めると、システムは予期しない、そして一見非決定的な動作を示します。これは、顧客にとってのパフォーマンスの低下と、信じられないほど困難なトラブルシューティングプロセスに繋がります。
潜在的なトラフィックを計画していない
将来のトラフィック量を推定することは困難であり、私たちは正しいよりも間違っていることが多いことに気付きます。トラフィックを過大評価すると、組織は存在しない現実のために設計することに努力を無駄にします。トラフィックを過小評価すると、さらに壊滅的な結果になる可能性があります。予期しない高トラフィック負荷はさまざまな理由で発生する可能性があり、予期せずバズったソーシャルメディアマーケティングキャンペーンはその良い例です。突然、システムは着信トラフィックを処理できなくなり、コンポーネントが停止し始め、すべてが停止します。
スタートアップ企業にとって、新規顧客の獲得と市場シェア拡大は常に課題です。しかし、それがいつ、どのように実現するかは予測が非常に困難です。インターネット規模のビジネスでは、何が起こるか分かりません。あらゆる事態を想定しておくべきです。
顧客からの通知によって警告を受ける
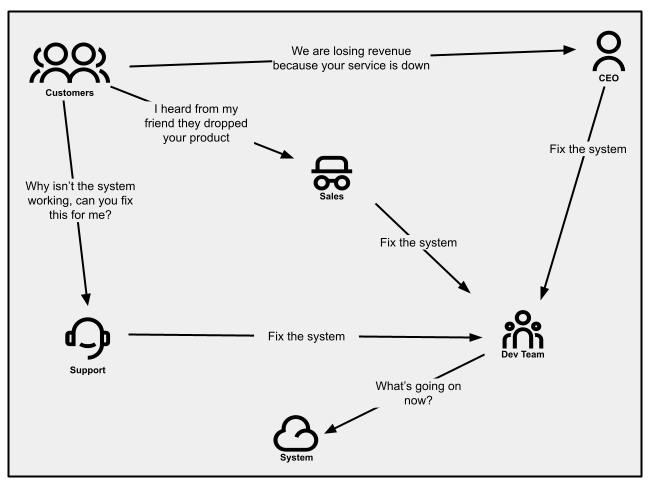
顧客が製品に投資しており、問題が解決可能だと信じている場合、サポートスタッフに助けを求めるかもしれません。それは、メール、電話、またはサポートチケットの発行などを通して行われます。サービス障害は、通話量やメールトラフィックの急増を引き起こします。営業担当者もこれらのメッセージを中継することがあるかもしれません。(潜在的な)顧客から営業担当者に直接伝えられる場合もあるからです。そして、サービス停止が戦略的顧客に影響を与える場合、CEOから直接伝えられることもあります(初期段階では許容できるかもしれませんが、長期的に望ましい状態ではありません)。
顧客からの連絡は、常に明確で分かりやすいとは限りません。顧客の独自の体験に基づいており、顧客成功担当者がこれがレジリエンスの問題を示していることに気づかなければ、通常通りの業務を続け、エンジニアリングチームにフィードバックが届きません。適切に特定および管理されない場合、通知は非言語的なものになる可能性があります。例えば、顧客の解約率が突然増加するといったことです。
小規模な顧客基盤の場合、顧客を通して問題を知ることは「ほぼ」管理可能です。顧客は比較的寛容だからです(結局のところ、彼らはあなたと共にこの旅を歩んでいるのです)。しかし、顧客基盤が拡大すると、通知が管理できない状態にまで積み重なり始めます。
ボトルネックから脱出するには?
一度障害が発生したら、できるだけ早く復旧し、その原因を詳細に理解してシステムを改善し、二度と起こらないようにする必要があります。
ボトルネックにある製品やサービスのレジリエンスに取り組むことは困難です。場当たり的な解決策では、延々と火消しに追われることになります。しかし、戦略的に管理すれば、ボトルネック中でもチームの負担を軽減できるだけでなく、過去の復旧努力から学び、ハイパー成長段階とその先も乗り切ることができます。
以下の5つのセクションは、組織が実装できる効果的な戦略です。これらは順序立てて提示されており、全体として取り組むべきだと考えています。ただし、組織の成熟度によっては、一部の戦略だけを利用することもできます。各戦略には、それぞれの戦略を実現するためのいくつかのソリューションを提示します。
基本的なレジリエンス技術を実装していることを確認する
アーキテクチャから組織編成まで、レジリエンスを向上させるための基本的な技術がいくつかあります。これらは製品を適切な位置に維持し、組織が効果的にスケールアップできるようにします。
リージョン内で複数のゾーンを使用する
非常に重要なサービス(とそのデータ)については、複数のゾーンにまたがって実行できるように設定および有効化します。これにより、システムの可用性が向上し、(ゾーン内での)障害発生時のレジリエンスが向上します。
適切なコンピューティングインスタンスの種類と仕様を指定する
ビジネスにクリティカルなサービスには、適切にコンピューティング能力を割り当てる必要があります。サービスが24時間365日稼働する必要がある場合、インフラストラクチャはその要件を反映する必要があります。
重要なサービス層への投資を合わせる
多くの組織は、重要なサービス層を特定することで投資を管理しています。すべてのビジネスシステムが、顧客体験の提供や収益のサポートという点で同じ重要性を共有するわけではないという理解に基づいています。サービスレベルアグリーメント(SLA)によって情報を得たサービス層と関連するレジリエンスの成果を特定し、成果をサポートするアーキテクチャと設計パターンを組み合わせることで、製品開発チームにとって役立つガードレールとガバナンスが提供されます。
システム全体でオーナーを明確に定義する
システム内の各サービスには、明確に定義されたオーナーが必要です。この情報は、問題を適切な場所に、そして効果的に解決できる人に伝えるのに役立ちます。開発者ポータルを実装して、明確に定義されたチームの所有権を持つソフトウェアサービスカタログを提供することで、社内コミュニケーションのパターンが改善されます。
手動のレジリエンスプロセスを自動化する(タイムボックス内で)
手動で解決されてきた特定のレジリエンス問題は自動化できます。サービスの再起動、新しいインスタンスの追加、データベースバックアップの復元などの操作です。多くの操作は簡単に自動化できるか、クラウドサービスプロバイダー内の設定変更だけで済みます。ボトルネックにある場合、これらの機能を実装することで、チームに必要な余裕と根本原因の解決時間を提供できます。
これらの実装はできるだけシンプルで、タイムボックス(最大数日)内に収めるようにしてください。これらは当初、応急処置として開始されたものであり、それらを自動化することは、別の(より良いとは言え)応急処置であることを念頭に置いてください。これらを監視ソリューションに統合することで、システムが自動的に復旧する頻度とそのにかかる時間を把握できます。同時に、これらの指標により、これらの応急処置への依存から脱却し、システム全体をより堅牢にすることを優先できます。
オブザーバビリティとモニタリングで平均復旧時間(MTTR)を改善する
ボトルネックから抜け出すには、現在の状態を理解して、どこに投資すべきかについて効果的な意思決定を行う必要があります。「ファイブナイン」を目指したいが、実際に提供されているナインの数が分からなければ、どのような道筋を進むべきかさえ分かりません。
現状を知るには、オブザーバビリティに投資する必要があります。オブザーバビリティにより、管理不能になる前にレジリエンスへの投資のタイミングをより積極的に決定できます。
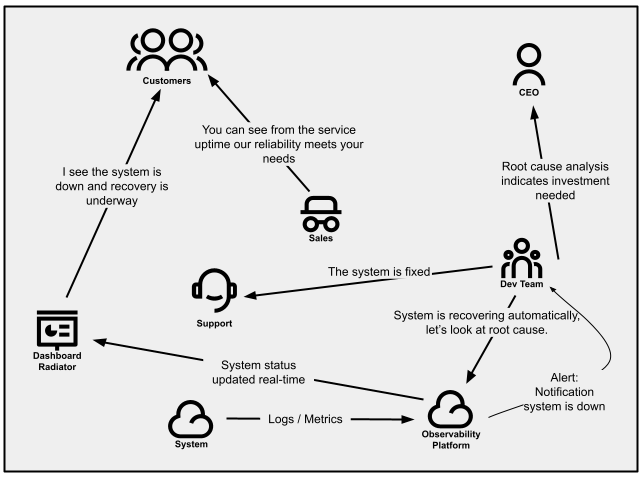
ログを一元化して単一のインターフェースから表示できるようにする
コアサービスとシステムからのログを集約して、中央インターフェースからアクセスできるようにします。これにより、複数の担当者が簡単にアクセスでき、トラブルシューティングの労力が軽減され(平均修復時間(MTTR)の短縮につながる可能性があります)。
顧客体験に近いオブザーバビリティを追加する
測定されたものは管理される。
—— ピーター・ドラッカー
インフラストラクチャの指標とサービスメッセージログは有用ですが、かなり低レベルであり、実際の顧客体験のコンテキストを提供しません。一方、顧客からの通知は問題の直接的な兆候ですが、通常は逸話的で、パターンに関する情報はほとんど提供しません(パターンを見つけるための作業を行わない限り)。
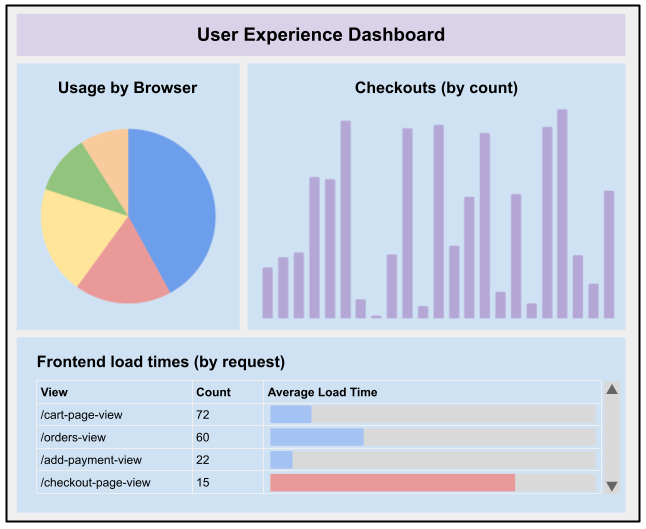
コアビジネスメトリクスの監視により、チームは顧客の体験を観察できます。製品の要件と機能によって定義され、多くの顧客体験に関する高レベルのコンテキストを提供します。これらは、完了したトランザクション、ビデオの開始と停止率、APIの使用状況、応答時間メトリクスなどのメトリクスです。フロントエンドのロード時間や検索の応答時間など、暗黙的なメトリクスも顧客体験の測定に役立ちます。観察されている内容を、顧客が製品を体験する方法に直接関連付けることが不可欠です。また、B2B環境では、システムの個々のコンポーネントのみを測定した場合に顧客の問題を認識するために必要なデータポイントの数が不足している可能性があるため、顧客体験に合わせたメトリクスがさらに重要になります。
あるクライアントでは、サービスは製品体験に関連するドメインイベント(カートに追加、カートへの追加失敗、トランザクション完了、支払承認など)を公開し始めました。これらのイベントは、オブザーバビリティプラットフォーム(Splunk、ELK、Datadogなど)によって取得され、ダッシュボードに表示され、さらに分類および分析されます。エラーをキャプチャして分類することにより、予期せぬ顧客体験に関連するエラーに関する問題解決を改善できます。
コアビジネスメトリクスから収集されたデータは、何が失敗しているのかだけでなく、システムのしきい値と、そのしきい値を超えた場合の管理方法を理解するのに役立ちます。これにより、ボトルネックをどのように乗り越えることができるかについてのさらなる洞察が得られます。
ステータスインジケーターを使用して顧客に製品ステータスの情報を提供する
顧客が直面しているさまざまな問題に関する問い合わせの増加に対処することは困難であり、サポートサービスはすぐに火消しに追われることを発見します。問題量の管理はスタートアップの成功に不可欠ですが、ボトルネック内では、そのトラフィックを削減するための体系的な方法を探す必要があります。サポートから通話トラフィックをそらす機能は、余裕を生み出し、適切な問題を解決する可能性を高めます。
サービスステータスインジケーターは、サポートに連絡しなくても顧客が必要とする情報を提供できます。これは、パブリックダッシュボード、メールメッセージ、ツイートなどの形で提供できます。これらは、バックエンドサービスの正常性と準備状況チェック、またはメトリクスの組み合わせを利用して、サービスの可用性、パフォーマンスの低下、および停止を判断できます。インシデント発生時には、ステータスインジケーターを使用して、製品のステータスについて多くの顧客に同時に情報を提供できます。
顧客との信頼関係を構築することは、信頼性が高くレジリエントなサービスを作成することと同じくらい重要です。顧客がサービスのステータスと予想される解決のタイムフレームを理解できるようにする方法を提供することで、透明性を通じて信頼を構築し、同時にサポートスタッフに問題解決の余地を与えることができます。
明示的なレジリエンスに関するビジネス要件へのシフト
スタートアップ企業では、レジリエンスに関連する作業を含む技術的負債よりも、新しい機能の方がしばしば価値が高いと考えられます。そして、前述のように、これは当初は確かに理にかなっていました。新しい機能と強化は、顧客を維持し、新規顧客を獲得するのに役立ちます。新しい機能を提供するための作業は、理論的には収益の増加につながるはずです。
組織が成長し、収益増加に対する新しい課題を発見するにつれて、これは必ずしも当てはまりません。レジリエンスの失敗はそのような課題の1つの原因です。これを乗り越えるには、製品のレジリエンスに対する価値観を変える必要があります。
サービス障害のコストを理解する
スタートアップ企業にとって、今四半期の収益目標未達成の影響は、スケールアップ企業や成熟した製品とは異なる場合があります。しかし、よくあることですが、当初の「技術的負債よりも新機能の方が価値がある」という判断は、実際の収益への影響が証明できるかどうかに関わらず、あるいは計算されたかどうかに関わらず、組織文化に恒久的に定着してしまいます。スタートアップからスケールアップへの移行に必要な成熟度の側面の一つは、意思決定におけるデータ主導の要素です。組織は、出荷されたすべての新機能の価値をトラッキングしていますか?そして、組織は運用投資を単なるコストセンターではなく、新たな収益に貢献するものとして分析していますか?また、内部労働時間の無駄と収益損失の両方の観点から、停止または繰り返し発生する停止のコストは把握されていますか?スタートアップ企業であれば、これらのほとんどにおいて、失うものは何もありません。しかし、成長するにつれて、これは真実ではなくなります。
したがって、サービス障害のコストを、全体的なプロダクトマネジメントと収益認識バリューストリームの一部として分析し始めることが重要です。収益の「速度」を理解することで、ダウンタイムの直接コスト(分単位)を簡単に定量化できます。顧客サポートの電話から開発者、管理者、広報/マーケティング、さらには営業に至るまで、停止インシデントに関与した全員のチームへのコストを追跡することは、目から鱗が落ちる経験となる可能性があります。顧客へのアウトリーチの拡大や新機能の提供ではなく、停止への対応にかかる機会費用を加えると、レジリエンスの欠陥の真の範囲と影響が明らかになります。
レジリエンスを機能として管理する
レジリエンスを単なる技術的な期待以上のものとして扱い始めましょう。それは顧客が期待するようになるコア機能です。そして、顧客がそれを期待するのであれば、他の機能と同様に第一級の考慮事項となるべきです。この進化の一部は、責任の所在の変更に関するものです。純粋に技術部門の責任ではなく、プロダクト部門とビジネス部門の責任となります。組織内の複数の層が、レジリエンスを優先事項と考える必要があります。これは、レジリエンスが他のどの機能と同じだけの注意を払われていることを示しています。
プロダクトとテクノロジーの緊密な連携は、ストーリーの定義、実装、組織の他の部分へのコミュニケーションにおいて、正しい期待値を設定できるようにするために不可欠です。レジリエンスはコア機能ですが、顧客には(UIやAPIへの追加などの新機能とは異なり)見えないものです。これらの2つのグループは、レジリエンスが適切に優先され、効果的に実装されるように協力する必要があります。
ここでの目的は、レジリエンスを反応的な懸念事項から積極的なものへとシフトさせることです。そして、チームが積極的に対応できるようになれば、ビジネスに重大な事態が発生した場合にも、より適切に対応できます。
要件は現実的な期待を反映する必要があります
要件と顧客の期待に対するレジリエンスの現実的な期待を理解することは、エンジニアリングの努力を費用対効果の高いものにするための鍵となります。稼働時間と可用性によって測定されるさまざまなレベルのレジリエンスには、非常に異なるコストがかかります。可用性の「スリーナイン」と「フォーナイン」(99.9%対99.99%)のコスト差は、10倍になる可能性があります。
各ビジネス機能に対する顧客の要件を理解することが重要です。あなたとあなたの顧客は、24時間365日の体験を期待していますか?顧客はどこに拠点を置いていますか?特定の地域に限定されていますか、それともグローバルですか?主にモバイルデバイスを介してサービスを利用していますか、それともパブリックAPIを介して統合されていますか?たとえば、携帯電話の信頼性の限界により99.9%の稼働時間しか享受できないモバイルデバイスを介して提供されるサービスに、99.999%の稼働時間を提供することは、資本を非効率的に使用することになります。
これらは、レジリエンスについて考える際に重要な質問です。なぜなら、顧客に認識される価値のないレベルのレジリエンスの実装に費用を支払いたくないからです。また、構築されている製品、それを構築および維持しているチーム、それを販売している組織の人々、そしてそれを利用している顧客に対する期待を設定および管理するのにも役立ちます。
まず問題を把握し、過剰な設計を避ける
手動でレジリエンスの問題を解決している場合、最初の本能はそれを自動化することかもしれません。なぜ駄目なのか?役に立つ場合もありますが、実装が非常に短い期間(最大数日)に制限されている場合に最も効果的です。より多くの時間を費やすと、実際には単なる症状であった領域で過剰な設計につながる可能性が高くなります。多大な時間、エネルギー、そしてお金が、単なるばんそうこうであり、おそらく持続不可能なもの、あるいはさらに悪いことに、独自の二次的な課題を引き起こすものに投資されます。
戦術的な解決策に直接進むのではなく、問題を本当に把握する機会とします。どこに断層が存在するか、オブザーバビリティは何を伝えようとしているか、そしてどの設計上の選択がこれらの障害に関連しているか。ストレステスト、カオスエンジニアリング、または探索的テストを通じて、これらの断層を発見できるかもしれません。この機会を利用して、他のシステムのストレスポイントを発見し、投資に対して最大の価値を得られる場所を特定しましょう。
ビジネスが成長してスケールするにつれて、過去の決定を再評価することが重要です。スタートアップ段階で意味があったことが、ハイパーグロース段階でも通用するとは限りません。
要件収集には複数のテクニックを活用する
技術指向の機能の要件収集は困難な場合があります。レジリエンスの命名法に精通していないプロダクトマネージャーやビジネスアナリストは、理解するのが難しい場合があります。これは、多くの場合、「xサービスのレジリエンスを高める」や「100%の稼働時間が私たちの目標です」といった曖昧な要件に変わります。定義する要件は、結果として得られる実装と同じくらい重要です。これらの要件を収集するのに役立つ多くのテクニックがあります。
要件を書く前に、プリモーテムを実行してみましょう。この軽量な活動では、さまざまな役割の人々が、何が失敗する可能性があるか、または何が失敗しているかについての見解を示します。プリモーテムは、人々が潜在的な失敗原因とその関連コストをどのように認識しているかについての貴重な洞察を提供します。その後の議論は、失敗が発生する前に、レジリエンスを強化する必要があることを優先するのに役立ちます。少なくとも、システムのレジリエンスをさらに検証するための新しいテストシナリオを作成できます。
もう1つの選択肢は、テクニカルリードとアーキテクチャの専門家と一緒に要件を作成することです。効果的なレジリエンスシステムを作成する責任は、チームのリーダー間で共有されるようになり、それぞれが設計のさまざまな側面について話すことができます。
これらの2つのテクニックは、レジリエンス機能の要件収集が単一の責任ではないことを示しています。チーム内のさまざまな役割で共有されるべきです。試行するすべてのテクニックを通して、誰が関与すべきか、そして彼らがどのような視点をもたらすかを念頭に置いてください。
レジリエンスのニーズを満たすためにアーキテクチャとインフラストラクチャを進化させる
スタートアップ企業の場合、アーキテクチャの設計は、市場に出せるスピードによって決まります。つまり、最初に機能した設計が、スケールアップへの移行におけるボトルネックになる可能性があるということです。製品のレジリエンスは、最終的に選択するテクノロジーによって決まります。それは、システム全体の設計とアーキテクチャを検討し、製品のレジリエンスのニーズを満たすように進化させることを意味する可能性があります。先に述べたことの多くは、ボトルネック内のデータポイントと余裕を与えるのに役立ちます。その中で、アーキテクチャを進化させ、真にレジリエントな製品を実現するパターンを組み込むことができます。
アーキテクチャを広く見て、適切なトレードオフを決定する
暗黙的または明示的に、初期アーキテクチャの作成時には、トレードオフが行われました。スタートアップの試行錯誤とトラクション獲得フェーズでは、何かを迅速に市場に投入すること、開発コストを低く保つこと、製品の方向性を容易に変更または変更することなどに重点が置かれています。トレードオフは、理想的なアーキテクチャから得られるレジリエンスの利点を犠牲にすることです。
Functions as a Service(FaaS)をバックエンドとするAPIを考えてみましょう。このアプローチは、実行されるインフラストラクチャの管理をほとんどまたはまったく行わずに何かを作成する優れた方法であり、私たちの焦点領域の3つのボックスすべてにチェックを入れる可能性があります。一方、それは実行が許可されているインフラストラクチャ、サービスの時間的制約、および多くの異なる関数間の潜在的な通信の複雑さに基づいて制限されています。達成不可能ではないにしても、アーキテクチャの制約により、製品に必要なレジリエンスを実現することが困難または複雑になる可能性があります。
製品と組織が成長し、成熟するにつれて、その制約も進化します。初期の設計上の決定が現在の運用環境にはもはや適切ではないことを認め、その結果、新しいアーキテクチャとテクノロジーを導入する必要があることが重要です。対処しないと、早期に講じたトレードオフは、ハイパーグロースフェーズでのボトルネックをさらに拡大するだけです。
効果的なエラー回復戦略でレジリエンスを強化する
モニターから収集されたデータは、サードパーティの統合、バックアップされたキュー、バックオフなど、高い失敗率の原因はどこにあるかを示すことができます。このデータは、実装する適切な回復戦略に関する意思決定を促進できます。
適切な場所にキャッシングを使用する
情報を取得する場合、キャッシング戦略は2つの方法で役立ちます。主に、同じクエリに対してキャッシュされた結果を提供することにより、サービスの負荷を軽減するために使用できます。キャッシングは、バックエンドサービスが正常に返答できない場合のフォールバック応答としても使用できます。
トレードオフは、顧客に古いデータを提供する可能性があるため、ユースケースが古いデータに敏感ではないことを確認してください。たとえば、リアルタイムの株価クエリには、キャッシュされた結果を使用することは避けるべきです。
適切な場所にデフォルト応答を使用する
クエリに対する最後の既知の応答を提供するキャッシングの代わりに、バックエンドサービスが正常に返答できない場合に静的なデフォルト値を提供できます。たとえば、価格割引サービスのフォールバック応答として小売価格を提供することは、取引で損失を出すリスクを冒すよりも、販売を失うリスクを冒す方が良い場合、害はありません。
べき等性を使用してエラー回復を簡素化する
あらゆる種類の再試行戦略を実装するクライアントは、複数の同一のリクエストを生成する可能性があります。サービスが複数の同一の変更リクエストを処理でき、また複数ステップのワークフローを障害点から再開できることを確認してください。
ビジネスに適した障害モードを設計する
システムにおいて、障害は避けられないものであり、あなたの目標はエンドユーザーエクスペリエンスを可能な限り保護することです。特に、ダウンストリームサービスでサポートされている場合、(可観測性を通じて)障害を予測し、代替フローを提供できる可能性があります。これらの統合を活用する基盤となるサービスは、ビジネスに適した障害モードで設計できます。
マイクロサービスアーキテクチャによってサポートされているeコマースシステムを考えてみましょう。注文機能をサポートするダウンストリームサービスが過負荷になった場合、注文ボタンを一時的に無効にし、顧客に簡潔なエラーメッセージを表示するのがより適切でしょう。これはユーザーに明確なフィードバックを提供しますが、売上コンバージョンを懸念するプロダクトマネージャーは、注文を捕捉し、注文確認の遅延を顧客に警告する方が良いかもしれません。
ビジネスの継続性と顧客満足度を確保するために、障害モードはアップストリームシステムに組み込む必要があります。アーキテクチャによっては、リクエストがサブシステムをオーバーロードしている場合、CDNまたはAPIゲートウェイがキャッシュされたレスポンスを返す場合があります。または、上記のように、システムは特定の障害モードに対して最終的な整合性への代替パスを提供する場合があります。「何かがうまくいかなかった」という一般的なエラーページの表示よりも、はるかに効果的で顧客中心的なアプローチです。
単一障害点を解消する
単一のサービスは、製品の単一責任から複数の責任を管理するまで容易に拡張できます。スタートアップ企業では、インフラストラクチャと展開パスが既に解決されているため、既存のサービスに追加することが多くの場合最も簡単なアプローチです。しかし、サービスは簡単に肥大化し、モノリス化して、製品の多くの部分またはすべてをダウンさせる可能性のある障害点を作成します。このような場合、製品全体を機能させたまま、アーキテクチャを分割する方法を理解する必要があります。
フィンテックのクライアントでは、急成長期にモノリシックシステムへの負荷が急激にスパイクしました。モノリシックな性質のため、すべての機能が同時に停止し、収益の損失と顧客の不満につながりました。長期的な解決策は、モノリスを水平方向にスケーリングできるいくつかの独立したサービスに分割することでした。さらに、トランザクションが失われないようにイベントキューを導入しました。
マイクロサービスアプローチの実装は簡単ではなく、時間と労力を要します。回復力強化が必要なドメインを定義し、その機能を少しずつ抽出して開始します。新しいサービスをロールアウトし、必要に応じてインフラストラクチャ構成を調整(プロビジョニングされた容量の増加、自動スケーリングの実装など)し、監視します。ユーザーエクスペリエンスに影響がなく、全体的な回復力が向上していることを確認します。安定性が達成されたら、ドメイン内の各機能を繰り返し処理します。クライアントの例で述べたように、これはシステムの全体的な回復力を高めるアーキテクチャ要素を導入する機会でもあります。イベントキュー、サーキットブレーカー、バルクヘッド、アンチコラップションレイヤーは、システム全体の信頼性を高めるのに役立つアーキテクチャコンポーネントです。
レジリエンスを継続的に最適化する
ボトルネックを乗り越えることと、ボトルネックに陥らないようにすることは別問題です。成長するにつれて、システムの回復力は継続的にテストされます。新しい機能は、システム負荷の増加につながる新しい経路をもたらします。アーキテクチャの変更により、システムの安定性が不明になります。組織は、最終的に何が起こるかを先取りする必要があります。組織が成熟し成長するにつれて、回復力への投資も増やす必要があります。
システムの回復力を検証するために、定期的にカオステストを実行する
カオスエンジニアリングは、真に回復力のある製品の基礎です。その核心的な価値は、思いもよらない方法で障害を発生させる能力です。そして、そのカオスが障害を引き起こしている間、同時にユーザーシナリオを実行することで、ユーザーエクスペリエンスを理解するのに役立ちます。これにより、システムが予期せぬカオスに耐えることができるという自信を得ることができます。同時に、どのユーザーエクスペリエンスがシステム障害の影響を受けているかを特定し、次に何を改善すべきかという文脈を提供します。
開発またはQA環境に対してテストする方が快適に感じるかもしれませんが、カオステストの価値は本番環境または本番環境のような環境から得られます。目標は、カオスに直面したときのシステムの回復力の程度を理解することです。初期の環境は(通常)、本番環境で見られるものと同じ構成でプロビジョニングされていないため、必要な信頼を提供しません。本番環境でこのようなテストを実行することは困難な場合があるため、サービスを復旧する能力に自信を持っていることを確認してください。これは、システム全体をスピンバックアップし、必要に応じてデータを復元できることを意味し、すべて自動化を通じて行われます。
役立つデータを提供できる、小さく理解しやすいシナリオから始めましょう。経験と自信を深めるにつれて、カオステストを実行する際にユーザーをシミュレートするために、負荷/パフォーマンステストを使用することを検討してください。実験の実行が間近に迫っていることをチームと関係者に知らせ、(問題が発生した場合に備えて)監視できるようにしてください。LitmusやGremlinなどのフレームワークは、カオスエンジニアリングに構造を提供できます。回復力に対する自信と成熟度が高まるにつれて、事前にチームに通知しない実験を実行できるようになります。
大規模な回復力に関する知識を持つ専門家を募集する
最初の製品を構築および提供する際に、ジェネラリストを採用することは理にかなっています。時間とお金は非常に貴重なため、ジェネラリストがいることで、市場に迅速に参入し、初期投資を損なわないようにするための柔軟性が得られます。しかし、チームは処理できる以上のものを引き受けており、製品がスケールアップするにつれて、かつて十分だったものがもはや十分ではなくなっています。市場に出たやや不安定なシステムは、スケールアップするにつれてさらに不安定になります。なぜなら、それを管理するのに必要なスキルが既存チームのスキルを上回っているからです。技術的負債と同様に、これは滑りやすい坂であり、対処しなければ問題は悪化する一方です。
製品の回復力を維持するには、その専門知識に焦点を当てるために専門家を募集する必要があります。専門家は、既存のシステムについて新しい視点と、ギャップや改善領域を特定する能力をもたらします。彼らの過去の経験は、チームに2つの効果をもたらします。それは、切実に必要な領域で必要なガイダンスを提供し、従業員の成長へのさらなる投資を行うことです。
常に信頼性を維持または向上させる
2021年、State of Devopsレポートは可用性から信頼性への第5の主要指標を拡大しました。運用パフォーマンスの下で、製品が約束を維持する能力を主張しています。回復力は、信頼性を確保できる主要なビジネス機能であるため、直接的に関連しています。多くの組織がより頻繁に本番環境にプッシュしているため、信頼性が同じままであるか、向上していることを保証する必要があります。
可観測性と監視が整っていることを確認し、それがサービスレベル目標(SLO)で述べられている内容と一致していることを確認してください。本番環境へのすべての展開において、モニターはSLAが保証する内容から逸脱してはなりません。ブルー/グリーンまたはカナリア(ある程度)などの特定の展開構造は、幅広いオーディエンスにリリースする前に変更を検証するのに役立ちます。本番環境で効果的にテストを実行することで、合意が揺るがず、回復力が同じかそれ以上になっているという自信を高めることができます。
組織の成長に伴うレジリエンスとオブザーバビリティ
フェーズ1
実験
製品を迅速に市場に投入することに重点を置いて、ソリューションのプロトタイプを作成する
フェーズ2
トラクション獲得
回復力と可観測性は、開発者の介入によって手動で実装される
回復力の解決のための優先順位付けは、主に技術的負債から行われる
ダッシュボードは、CPUやRAMなどの低レベルのサービス統計を反映する
サポートの問題の大部分は、顧客からの電話やテキストメッセージを介して寄せられる
フェーズ3
(急激な)成長
回復力は顧客に提供されるコア機能であり、機能と同じように優先される
可観測性は、ダッシュボードと監視を介して反映される全体的な顧客エクスペリエンスを反映できる
問題のあるサービスを再設計または再作成し、その過程で回復力を向上させる
フェーズ4
最適化
プラットフォームは内部向けサービスから進化し、可観測性とコンピューティング環境を製品化する
事前に通知なしで、定期的にカオスエンジニアリング演習を実行する
大規模な回復力に精通したエンジニアをチームに追加する